diff --git a/docs/Apollo/Apollo简单入门.md b/docs/Apollo/Apollo简单入门.md
index b45a890..3e1d91a 100644
--- a/docs/Apollo/Apollo简单入门.md
+++ b/docs/Apollo/Apollo简单入门.md
@@ -8,8 +8,7 @@ categories:
- Apollo
keywords: Apollo,配置中心。
description: Apollo简单入门及和SpringBoot集成。
-cover: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img_003/Apollo/logo.png'
-top_img: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/blog/top_img.jpg'
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@master/Apollo/logo.png'
abbrlink: 10d32fba
date: 2020-12-29 11:31:58
---
@@ -77,7 +76,7 @@ date: 2020-12-29 11:31:58
不过,解决一个问题的同时,往往会诞生出很多新的问题,所以微服务化的过程中伴随着很多的挑战,其中一个挑战就是有关服务(应用)配置的。当系统从一个单体应用,被拆分成分布式系统上一个个服务节点后,配置文件也必须跟着迁移(分割),这样配置就分散了,不仅如此,分散中还包含着冗余,如下图:
- +
+ 配置中心将配置从应用中剥离出来,统一管理,优雅的解决了配置的动态变更、持久化、运维成本等问题。
@@ -87,7 +86,7 @@ date: 2020-12-29 11:31:58
在系统架构中,配置中心是整个微服务基础架构体系中的一个组件,如下图,它的功能看上去并不起眼,无非就是配置的管理和存取,但它是整个微服务架构中不可或缺的一环。
-
配置中心将配置从应用中剥离出来,统一管理,优雅的解决了配置的动态变更、持久化、运维成本等问题。
@@ -87,7 +86,7 @@ date: 2020-12-29 11:31:58
在系统架构中,配置中心是整个微服务基础架构体系中的一个组件,如下图,它的功能看上去并不起眼,无非就是配置的管理和存取,但它是整个微服务架构中不可或缺的一环。
- +
+ @@ -172,7 +171,7 @@ Apollo简介
### Apollo简介
-
@@ -172,7 +171,7 @@ Apollo简介
### Apollo简介
- +
+ **Apollo - A reliable configuration management system**
@@ -222,7 +221,7 @@ Apollo快速入门
### 执行流程
-
**Apollo - A reliable configuration management system**
@@ -222,7 +221,7 @@ Apollo快速入门
### 执行流程
- +
+ 操作流程如下:
@@ -263,7 +262,7 @@ Apollo的表结构对`timestamp`使用了多个default声明,所以需要5.6.5
2. 打开1.3发布链接,下载必须的安装包:[https://github.com/ctripcorp/apollo/releases/tag/v1.3.0](https://github.com/ctripcorp/apollo/releases/tag/v1.3.0)。三个都要下
-
操作流程如下:
@@ -263,7 +262,7 @@ Apollo的表结构对`timestamp`使用了多个default声明,所以需要5.6.5
2. 打开1.3发布链接,下载必须的安装包:[https://github.com/ctripcorp/apollo/releases/tag/v1.3.0](https://github.com/ctripcorp/apollo/releases/tag/v1.3.0)。三个都要下
- +
+ 解压安装包后将apollo-configservice-1.3.0.jar, apollo-adminservice-1.3.0.jar, apollo-portal-1.3.0.jar放置于apollo目录下
@@ -350,11 +349,11 @@ Apollo服务端共需要两个数据库:`ApolloPortalDB`和`ApolloConfigDB`,
1. 也可以使用提供的runApollo.bat快速启动三个服务(修改数据库连接地址,数据库以及密码)
-
解压安装包后将apollo-configservice-1.3.0.jar, apollo-adminservice-1.3.0.jar, apollo-portal-1.3.0.jar放置于apollo目录下
@@ -350,11 +349,11 @@ Apollo服务端共需要两个数据库:`ApolloPortalDB`和`ApolloConfigDB`,
1. 也可以使用提供的runApollo.bat快速启动三个服务(修改数据库连接地址,数据库以及密码)
-  +
+  这里面是一个很简单的脚本
-
这里面是一个很简单的脚本
-  +
+  @@ -386,29 +385,29 @@ start "ApolloPortal" java -Xms256m -Xmx256m -Dapollo_profile=github,auth -Ddev_m
1. 打开[apollo](http://localhost:8070/) :新建项目apollo-quickstart
-
@@ -386,29 +385,29 @@ start "ApolloPortal" java -Xms256m -Xmx256m -Dapollo_profile=github,auth -Ddev_m
1. 打开[apollo](http://localhost:8070/) :新建项目apollo-quickstart
- +
+ 2. 新建配置项sms.enable
-
2. 新建配置项sms.enable
- +
+ -
- +
+ 确认提交配置项
-
确认提交配置项
- +
+ -
+
3. 发布配置项
-
-
+
3. 发布配置项
- +
+ #### 应用读取配置
@@ -486,7 +485,7 @@ public class GetConfigTest {
-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:8080
-
#### 应用读取配置
@@ -486,7 +485,7 @@ public class GetConfigTest {
-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:8080
- +
+ 运行GetConfigTest,打开控制台,观察输出结果
@@ -524,19 +523,19 @@ sma.enable: true
2. 运行GetConfigTest观察输出结果
-
运行GetConfigTest,打开控制台,观察输出结果
@@ -524,19 +523,19 @@ sma.enable: true
2. 运行GetConfigTest观察输出结果
- +
+ 3. 在Apollo管理界面修改配置项
-
3. 在Apollo管理界面修改配置项
- +
+ 4. 发布配置
-
4. 发布配置
- +
+ 5. 在控制台查看详细情况:可以看到程序获取的sms.enable的值已由false变成了修改后的true
-
5. 在控制台查看详细情况:可以看到程序获取的sms.enable的值已由false变成了修改后的true
- +
+ @@ -547,7 +546,7 @@ Apollo应用
下图是Apollo架构模块的概览
-
@@ -547,7 +546,7 @@ Apollo应用
下图是Apollo架构模块的概览
- +
+ #### 各模块职责
@@ -602,7 +601,7 @@ Apollo应用
它们的关系如下图所示:
-
#### 各模块职责
@@ -602,7 +601,7 @@ Apollo应用
它们的关系如下图所示:
- +
+ @@ -616,15 +615,15 @@ apollo 默认部门有两个。要增加自己的部门,可在系统参数中
* 进入系统参数设置
-
@@ -616,15 +615,15 @@ apollo 默认部门有两个。要增加自己的部门,可在系统参数中
* 进入系统参数设置
- +
+ -
+
* 输入key查询已存在的部门设置:organizations
-
-
+
* 输入key查询已存在的部门设置:organizations
-  +
+  * 修改value值来添加新部门,下面添加一个微服务部门:
@@ -640,11 +639,11 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 新建用户张三
-
* 修改value值来添加新部门,下面添加一个微服务部门:
@@ -640,11 +639,11 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 新建用户张三
- +
+ -
- +
+ #### 创建项目
@@ -662,7 +661,7 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 应用名称:应用名,仅用于界面展示
* 应用负责人:选择的人默认会成为该项目的管理员,具备项目权限管理、集群创建、Namespace创建等权限
-
#### 创建项目
@@ -662,7 +661,7 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 应用名称:应用名,仅用于界面展示
* 应用负责人:选择的人默认会成为该项目的管理员,具备项目权限管理、集群创建、Namespace创建等权限
- +
+ 4. 点击提交,创建成功后,会自动跳转到项目首页
@@ -672,7 +671,7 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 使用管理员apollo将指定项目授权给用户张三
-
4. 点击提交,创建成功后,会自动跳转到项目首页
@@ -672,7 +671,7 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 使用管理员apollo将指定项目授权给用户张三
-  +
+  * 将修改和发布权限都授权给张三
@@ -732,7 +731,7 @@ Namespace作为配置的分类,可当成一个配置文件。
进入项目首页,点击左下脚的“添加Namespace”,共包括两项:关联公共Namespace和创建Namespace,这里选择“创建Namespace”
-
* 将修改和发布权限都授权给张三
@@ -732,7 +731,7 @@ Namespace作为配置的分类,可当成一个配置文件。
进入项目首页,点击左下脚的“添加Namespace”,共包括两项:关联公共Namespace和创建Namespace,这里选择“创建Namespace”
- +
+ 2. 添加配置项
@@ -759,11 +758,11 @@ Namespace作为配置的分类,可当成一个配置文件。
进入common-template项目管理页面:[http://localhost:8070/config.html?#/appid=common-template](http://localhost:8070/config.html?#/appid=common-template)
-
2. 添加配置项
@@ -759,11 +758,11 @@ Namespace作为配置的分类,可当成一个配置文件。
进入common-template项目管理页面:[http://localhost:8070/config.html?#/appid=common-template](http://localhost:8070/config.html?#/appid=common-template)
- +
+ -
- +
+ 1. 添加配置项并发布
@@ -787,11 +786,11 @@ Namespace作为配置的分类,可当成一个配置文件。
2. 点击左侧的添加Namespace
3. 添加Namespace
-
1. 添加配置项并发布
@@ -787,11 +786,11 @@ Namespace作为配置的分类,可当成一个配置文件。
2. 点击左侧的添加Namespace
3. 添加Namespace
- +
+ 4. 根据需求可以覆盖引入公共Namespace中的配置,下面以覆盖server.servlet.context-path为例
-
4. 根据需求可以覆盖引入公共Namespace中的配置,下面以覆盖server.servlet.context-path为例
- +
+ 5. 修改server.servlet.context-path为:/account-service
6. 发布修改的配置项
@@ -807,15 +806,15 @@ Namespace作为配置的分类,可当成一个配置文件。
1. 点击页面左侧的“添加集群”按钮
2. 输入集群名称SHAJQ,选择环境并提交:添加上海金桥数据中心为例
-
5. 修改server.servlet.context-path为:/account-service
6. 发布修改的配置项
@@ -807,15 +806,15 @@ Namespace作为配置的分类,可当成一个配置文件。
1. 点击页面左侧的“添加集群”按钮
2. 输入集群名称SHAJQ,选择环境并提交:添加上海金桥数据中心为例
- +
+ -
+
3. 切换到对应的集群,修改配置并发布即可
-
-
+
3. 切换到对应的集群,修改配置并发布即可
- +
+ #### 同步集群配置
@@ -828,19 +827,19 @@ Namespace作为配置的分类,可当成一个配置文件。
* 展开要同步的Namespace,点击同步配置
-
#### 同步集群配置
@@ -828,19 +827,19 @@ Namespace作为配置的分类,可当成一个配置文件。
* 展开要同步的Namespace,点击同步配置
-  +
+  - 
+ 
* 选择同步到的新集群,再选择要同步的配置
-
- 
+ 
* 选择同步到的新集群,再选择要同步的配置
-  +
+  * 同步完成后,切换到SHAJQ集群,发布配置
-
* 同步完成后,切换到SHAJQ集群,发布配置
-  +
+  #### 读取配置
@@ -864,7 +863,7 @@ Namespace作为配置的分类,可当成一个配置文件。
在配置中心中,一个重要的功能就是配置发布后实时推送到客户端。下面我们简要看一下这块是怎么设计实现的。
-
#### 读取配置
@@ -864,7 +863,7 @@ Namespace作为配置的分类,可当成一个配置文件。
在配置中心中,一个重要的功能就是配置发布后实时推送到客户端。下面我们简要看一下这块是怎么设计实现的。
- +
+ 上图简要描述了配置发布的主要过程:
@@ -891,7 +890,7 @@ Admin Service在配置发布后,需要通知所有的Config Service有配置
SELECT * FROM ApolloConfigDB.ReleaseMessage
```
-
上图简要描述了配置发布的主要过程:
@@ -891,7 +890,7 @@ Admin Service在配置发布后,需要通知所有的Config Service有配置
SELECT * FROM ApolloConfigDB.ReleaseMessage
```
- +
+ @@ -1013,7 +1012,7 @@ Admin Service在配置发布后,需要通知所有的Config Service有配置
4. NotificationControllerV2得到配置发布的AppId+Cluster+Namespace后,会通知对应的客户端
-
@@ -1013,7 +1012,7 @@ Admin Service在配置发布后,需要通知所有的Config Service有配置
4. NotificationControllerV2得到配置发布的AppId+Cluster+Namespace后,会通知对应的客户端
- +
+ #### Config Service通知客户端
@@ -1269,7 +1268,7 @@ Apollo客户端会把从服务端获取到的配置在本地文件系统缓存
-Denv=DEV -Dapollo.cacheDir=/opt/data/apollo-config -Dapollo.cluster=DEFAULTbash
```
-
#### Config Service通知客户端
@@ -1269,7 +1268,7 @@ Apollo客户端会把从服务端获取到的配置在本地文件系统缓存
-Denv=DEV -Dapollo.cacheDir=/opt/data/apollo-config -Dapollo.cluster=DEFAULTbash
```
- +
+ @@ -1367,11 +1366,11 @@ public class AccountApplication {
2. spring-http命名空间在之前已通过关联公共命名空间添加好了,现在来添加spring-boot-druid命名空间
-
@@ -1367,11 +1366,11 @@ public class AccountApplication {
2. spring-http命名空间在之前已通过关联公共命名空间添加好了,现在来添加spring-boot-druid命名空间
- +
+ 3. 添加本地文件中的配置到对应的命名空间,然后发布配置
-
3. 添加本地文件中的配置到对应的命名空间,然后发布配置
- +
+ 4. 在account-service/src/main/resources/application.properties中配置apollo.bootstrap.namespaces需要引入的命名空间(上面写过)
@@ -1459,7 +1458,7 @@ public class AccountController {
* 访问[http://127.0.0.1:63000/account-service/db-url](http://127.0.0.1:63000/account-service/db-url),显示结果
-
4. 在account-service/src/main/resources/application.properties中配置apollo.bootstrap.namespaces需要引入的命名空间(上面写过)
@@ -1459,7 +1458,7 @@ public class AccountController {
* 访问[http://127.0.0.1:63000/account-service/db-url](http://127.0.0.1:63000/account-service/db-url),显示结果
- +
+ #### 创建其它项目
@@ -1475,7 +1474,7 @@ public class AccountController {
具体如下图所示:
-
#### 创建其它项目
@@ -1475,7 +1474,7 @@ public class AccountController {
具体如下图所示:
- +
+ 下面以添加生产环境部署为例
@@ -1524,7 +1523,7 @@ UPDATE ServerConfig SET `Value` = "http://localhost:8081/eureka/" WHERE `key` =
服务配置项统一存储在ApolloPortalDB.ServerConfig表中,可以通过`管理员工具 - 系统参数`页面进行配置:apollo.portal.envs - 可支持的环境列表
-
下面以添加生产环境部署为例
@@ -1524,7 +1523,7 @@ UPDATE ServerConfig SET `Value` = "http://localhost:8081/eureka/" WHERE `key` =
服务配置项统一存储在ApolloPortalDB.ServerConfig表中,可以通过`管理员工具 - 系统参数`页面进行配置:apollo.portal.envs - 可支持的环境列表
- +
+ 默认值是dev,如果portal需要管理多个环境的话,以逗号分隔即可(大小写不敏感),如:
@@ -1557,7 +1556,7 @@ Apollo Portal需要在不同的环境访问不同的meta service(apollo-configse
1. 启动之后,点击account-service服务配置后会提示环境缺失,此时需要补全上边新增生产环境的配置
-
默认值是dev,如果portal需要管理多个环境的话,以逗号分隔即可(大小写不敏感),如:
@@ -1557,7 +1556,7 @@ Apollo Portal需要在不同的环境访问不同的meta service(apollo-configse
1. 启动之后,点击account-service服务配置后会提示环境缺失,此时需要补全上边新增生产环境的配置
- +
+ 3. 点击左下方的补缺环境
@@ -1565,7 +1564,7 @@ Apollo Portal需要在不同的环境访问不同的meta service(apollo-configse
4. 补缺过生产环境后,切换到PRO环境后会提示有Namespace缺失,点击补缺
-
3. 点击左下方的补缺环境
@@ -1565,7 +1564,7 @@ Apollo Portal需要在不同的环境访问不同的meta service(apollo-configse
4. 补缺过生产环境后,切换到PRO环境后会提示有Namespace缺失,点击补缺
- +
+ 5. 从dev环境同步配置到pro
@@ -1611,7 +1610,7 @@ apollo-quickstart项目有两个客户端:
1. 172.16.0.160
2. 172.16.0.170
-
5. 从dev环境同步配置到pro
@@ -1611,7 +1610,7 @@ apollo-quickstart项目有两个客户端:
1. 172.16.0.160
2. 172.16.0.170
- +
+ **灰度目标**
@@ -1627,7 +1626,7 @@ apollo-quickstart项目有两个客户端:
2. 点击确定后,灰度版本就创建成功了,页面会自动切换到`灰度版本`Tab
-
**灰度目标**
@@ -1627,7 +1626,7 @@ apollo-quickstart项目有两个客户端:
2. 点击确定后,灰度版本就创建成功了,页面会自动切换到`灰度版本`Tab
- +
+ #### 灰度配置
@@ -1635,17 +1634,17 @@ apollo-quickstart项目有两个客户端:
2. 在弹出框中填入要灰度的值:3000,点击提交
-
#### 灰度配置
@@ -1635,17 +1634,17 @@ apollo-quickstart项目有两个客户端:
2. 在弹出框中填入要灰度的值:3000,点击提交
- +
+ #### 配置灰度规则
1. 切换到`灰度规则`Tab,点击`新增规则`按钮
-
#### 配置灰度规则
1. 切换到`灰度规则`Tab,点击`新增规则`按钮
- +
+ 2. 在弹出框中`灰度的IP`下拉框会默认展示当前使用配置的机器列表,选择我们要灰度的IP,点击完成
-
2. 在弹出框中`灰度的IP`下拉框会默认展示当前使用配置的机器列表,选择我们要灰度的IP,点击完成
- +
+ 如果下拉框中没找到需要的IP,说明机器还没从Apollo取过配置,可以点击手动输入IP来输入,输入完后点击添加按钮
@@ -1675,11 +1674,11 @@ vm options: `-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:80
}
```
-
如果下拉框中没找到需要的IP,说明机器还没从Apollo取过配置,可以点击手动输入IP来输入,输入完后点击添加按钮
@@ -1675,11 +1674,11 @@ vm options: `-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:80
}
```
- +
+ 2. 切换到`配置`Tab,再次检查灰度的配置部分,如果没有问题,点击`灰度发布`
-
2. 切换到`配置`Tab,再次检查灰度的配置部分,如果没有问题,点击`灰度发布`
- +
+ 3. 在弹出框中可以看到主版本的值是2000,灰度版本即将发布的值是3000。填入其它信息后,点击发布
@@ -1687,9 +1686,9 @@ vm options: `-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:80
4. 发布后,切换到`灰度实例列表`Tab,就能看到172.16.0.160已经使用了灰度发布的值
-
3. 在弹出框中可以看到主版本的值是2000,灰度版本即将发布的值是3000。填入其它信息后,点击发布
@@ -1687,9 +1686,9 @@ vm options: `-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:80
4. 发布后,切换到`灰度实例列表`Tab,就能看到172.16.0.160已经使用了灰度发布的值
- +
+ -
- +
+ diff --git a/docs/Computer_NetWork/计算机网络-总结.md b/docs/Computer_NetWork/计算机网络-总结.md
index aba837b..0c46666 100644
--- a/docs/Computer_NetWork/计算机网络-总结.md
+++ b/docs/Computer_NetWork/计算机网络-总结.md
@@ -1,3 +1,17 @@
+---
+title: 计算机网络-总结篇
+tags:
+ - 计算机网络
+ - 面试
+categories:
+ - 计算机网络
+keywords: 计算机网络,计网,面试
+description: 计算机网络-总结篇,可以用来期末复习,校招面试等。
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@v1.0.0/computer_network/logo.jpg'
+abbrlink: 3905e6f8
+date: 2020-04-16 17:21:58
+---
+
# 备注
@@ -177,7 +191,7 @@ https://www.cnblogs.com/felixzh/p/10345929.html
## 区别+应用场景
-
diff --git a/docs/Computer_NetWork/计算机网络-总结.md b/docs/Computer_NetWork/计算机网络-总结.md
index aba837b..0c46666 100644
--- a/docs/Computer_NetWork/计算机网络-总结.md
+++ b/docs/Computer_NetWork/计算机网络-总结.md
@@ -1,3 +1,17 @@
+---
+title: 计算机网络-总结篇
+tags:
+ - 计算机网络
+ - 面试
+categories:
+ - 计算机网络
+keywords: 计算机网络,计网,面试
+description: 计算机网络-总结篇,可以用来期末复习,校招面试等。
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@v1.0.0/computer_network/logo.jpg'
+abbrlink: 3905e6f8
+date: 2020-04-16 17:21:58
+---
+
# 备注
@@ -177,7 +191,7 @@ https://www.cnblogs.com/felixzh/p/10345929.html
## 区别+应用场景
- +
+ **总结:**
@@ -292,7 +306,7 @@ TCP通过三次握手建立可靠连接
在采用快恢复算法时,慢开始算法只是在TCP连接建立时和网络出现超时时才使用。
-
**总结:**
@@ -292,7 +306,7 @@ TCP通过三次握手建立可靠连接
在采用快恢复算法时,慢开始算法只是在TCP连接建立时和网络出现超时时才使用。
- +
+ @@ -819,7 +833,7 @@ proactor: 这有十个字节数据,收好了跟我说一声。
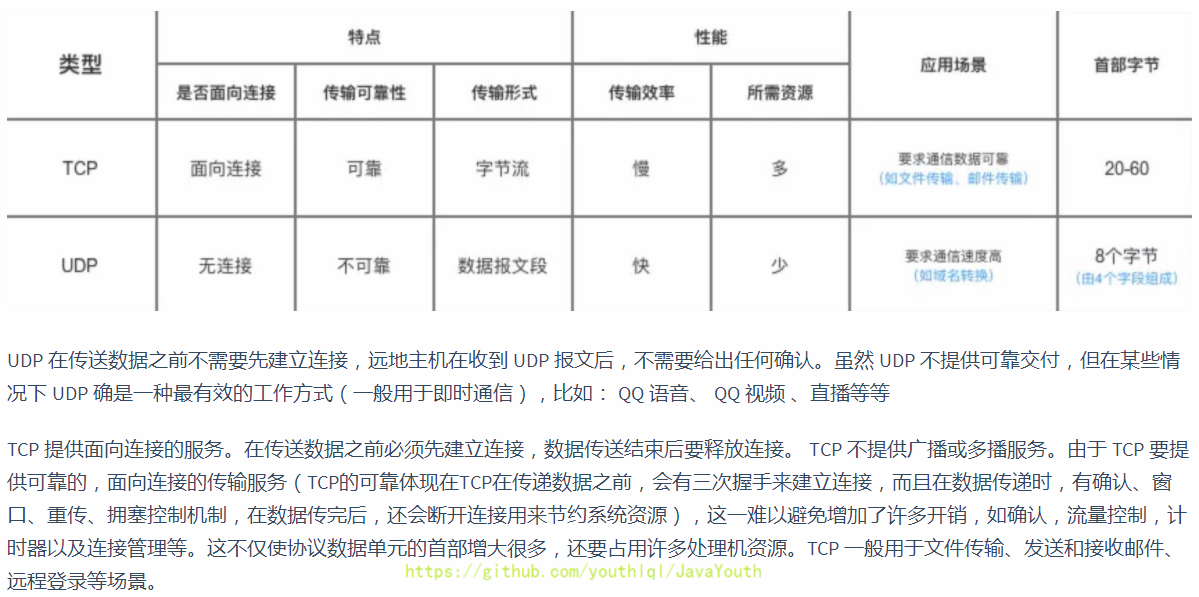
当用户进程进行recvfrom这个系统调用,内核就开始了IO的第一个阶段:等待数据准备。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候**内核**就要等待足够的数据到来。而在用户进程这边,整 个进程会被阻塞。当**内核**一直等到数据准备好了,它就会将数据从**内核**中拷贝到用户内存,然后**内核**返回果,用户进程才解除 block的状态,重新运行起来。**所以,blocking IO的特点就是在IO执行的两个阶段都被block了。**
-
@@ -819,7 +833,7 @@ proactor: 这有十个字节数据,收好了跟我说一声。
当用户进程进行recvfrom这个系统调用,内核就开始了IO的第一个阶段:等待数据准备。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候**内核**就要等待足够的数据到来。而在用户进程这边,整 个进程会被阻塞。当**内核**一直等到数据准备好了,它就会将数据从**内核**中拷贝到用户内存,然后**内核**返回果,用户进程才解除 block的状态,重新运行起来。**所以,blocking IO的特点就是在IO执行的两个阶段都被block了。**
- +
+
 @@ -830,7 +844,7 @@ proactor: 这有十个字节数据,收好了跟我说一声。
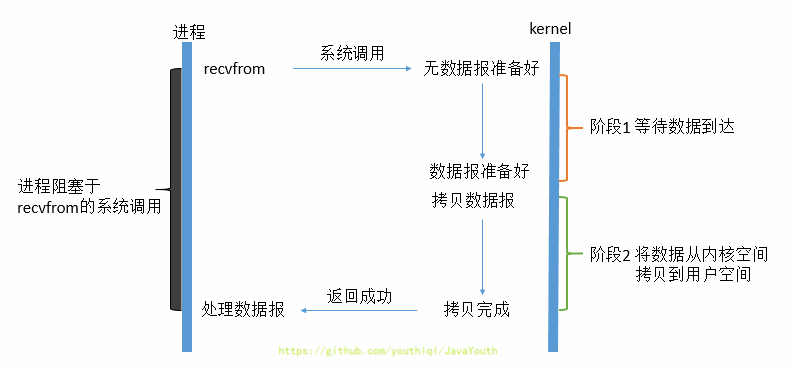
3. 虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
4. **所以,用户进程第一个阶段不是阻塞的,需要不断的主动询问内核数据好了没有;第二个阶段依然总是阻塞的。**
-
@@ -830,7 +844,7 @@ proactor: 这有十个字节数据,收好了跟我说一声。
3. 虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
4. **所以,用户进程第一个阶段不是阻塞的,需要不断的主动询问内核数据好了没有;第二个阶段依然总是阻塞的。**
- +
+
 @@ -842,7 +856,7 @@ proactor: 这有十个字节数据,收好了跟我说一声。
2. 它的基本原理就是select /epoll这个函数会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程,正式发起read请求。
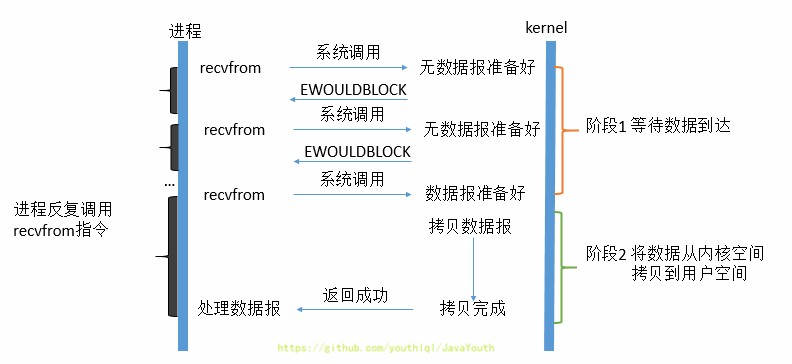
3. 从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket(也就是数据准备好了的socket),即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
-
@@ -842,7 +856,7 @@ proactor: 这有十个字节数据,收好了跟我说一声。
2. 它的基本原理就是select /epoll这个函数会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程,正式发起read请求。
3. 从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket(也就是数据准备好了的socket),即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
- +
+ @@ -868,7 +882,7 @@ proactor: 这有十个字节数据,收好了跟我说一声。
2. 这个一般用于UDP中,对TCP套接口几乎是没用的,原因是该信号产生得过于频繁,并且该信号的出现并没有告诉我们发生了什么事情
3. 信号驱动IO放佛很像异步IO,它的第一阶段不是阻塞的。但是很遗憾,它的数据拷贝阶段(第二阶段),任然是阻塞的。
-
@@ -868,7 +882,7 @@ proactor: 这有十个字节数据,收好了跟我说一声。
2. 这个一般用于UDP中,对TCP套接口几乎是没用的,原因是该信号产生得过于频繁,并且该信号的出现并没有告诉我们发生了什么事情
3. 信号驱动IO放佛很像异步IO,它的第一阶段不是阻塞的。但是很遗憾,它的数据拷贝阶段(第二阶段),任然是阻塞的。
- +
+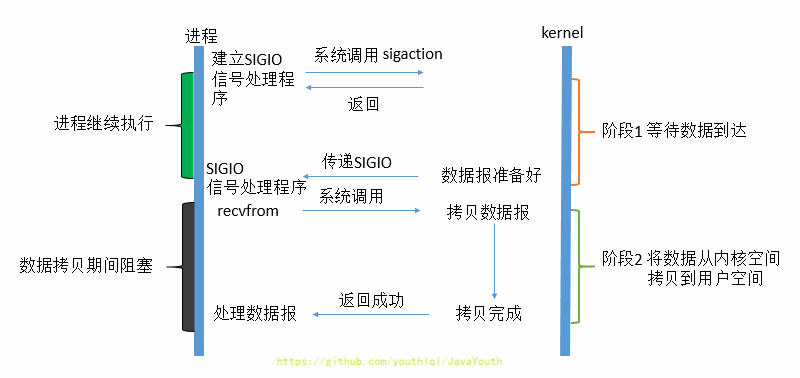 @@ -879,7 +893,7 @@ proactor: 这有十个字节数据,收好了跟我说一声。
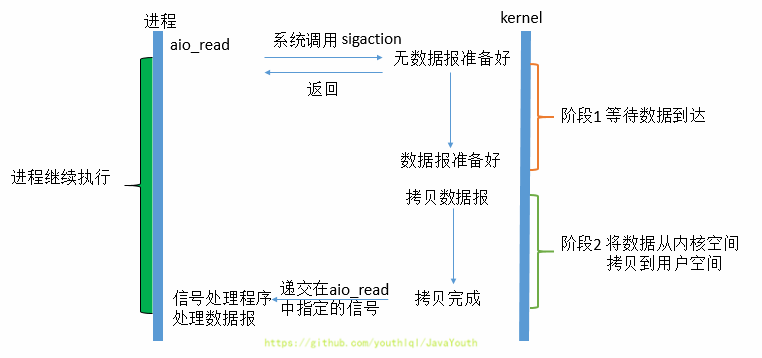
3. 而另一方面,从**内核**的角度,当它受到一个异步读之后,首先它会立刻返回,所以不会对用户进程产生任何阻塞。然后,内核会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都 完成之后,**内核**会给用户进程发送一个信号,告诉它read操作完成了,用户线程直接使用即可。 在这整个过程中,进程完全没有被阻塞。
4. 异步IO模型使用了Proactor设计模式实现了这一机制。**(具体怎么搞得,看上面的文章链接)**
-
@@ -879,7 +893,7 @@ proactor: 这有十个字节数据,收好了跟我说一声。
3. 而另一方面,从**内核**的角度,当它受到一个异步读之后,首先它会立刻返回,所以不会对用户进程产生任何阻塞。然后,内核会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都 完成之后,**内核**会给用户进程发送一个信号,告诉它read操作完成了,用户线程直接使用即可。 在这整个过程中,进程完全没有被阻塞。
4. 异步IO模型使用了Proactor设计模式实现了这一机制。**(具体怎么搞得,看上面的文章链接)**
- +
+ diff --git a/docs/ElasticSearch/usage/ElasticSearch-入门.md b/docs/ElasticSearch/usage/ElasticSearch-入门.md
index eca1fb7..dd008f6 100644
--- a/docs/ElasticSearch/usage/ElasticSearch-入门.md
+++ b/docs/ElasticSearch/usage/ElasticSearch-入门.md
@@ -9,8 +9,7 @@ categories:
- 用法
keywords: ElasticSearch,全文检索
description: ElasticSearch-入门篇,适合做入门,或者知识回顾。
-cover: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/ElasticSearch/logo.jpg'
-top_img: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/blog/top_img.jpg'
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@v1.0.0/ElasticSearch/logo.jpg'
abbrlink: 7f60dde9
date: 2020-02-03 13:11:45
---
@@ -47,7 +46,7 @@ date: 2020-02-03 13:11:45
下图是ElasticSearch的索引结构,下边黑色部分是物理结构,上边黄色部分是逻辑结构,逻辑结构也是为了更好的 去描述ElasticSearch的工作原理及去使用物理结构中的索引文件。
-
diff --git a/docs/ElasticSearch/usage/ElasticSearch-入门.md b/docs/ElasticSearch/usage/ElasticSearch-入门.md
index eca1fb7..dd008f6 100644
--- a/docs/ElasticSearch/usage/ElasticSearch-入门.md
+++ b/docs/ElasticSearch/usage/ElasticSearch-入门.md
@@ -9,8 +9,7 @@ categories:
- 用法
keywords: ElasticSearch,全文检索
description: ElasticSearch-入门篇,适合做入门,或者知识回顾。
-cover: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/ElasticSearch/logo.jpg'
-top_img: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/blog/top_img.jpg'
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@v1.0.0/ElasticSearch/logo.jpg'
abbrlink: 7f60dde9
date: 2020-02-03 13:11:45
---
@@ -47,7 +46,7 @@ date: 2020-02-03 13:11:45
下图是ElasticSearch的索引结构,下边黑色部分是物理结构,上边黄色部分是逻辑结构,逻辑结构也是为了更好的 去描述ElasticSearch的工作原理及去使用物理结构中的索引文件。
- +
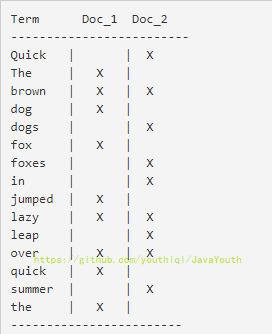
+ 逻辑结构部分是一个倒排索引表:
@@ -59,11 +58,11 @@ date: 2020-02-03 13:11:45
如下:
-
逻辑结构部分是一个倒排索引表:
@@ -59,11 +58,11 @@ date: 2020-02-03 13:11:45
如下:
- +
+ 现在,如果我们想搜到`quick brown`我们只需要查找包含每个词条的文档:
-
现在,如果我们想搜到`quick brown`我们只需要查找包含每个词条的文档:
- +
+ 两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 , 那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳
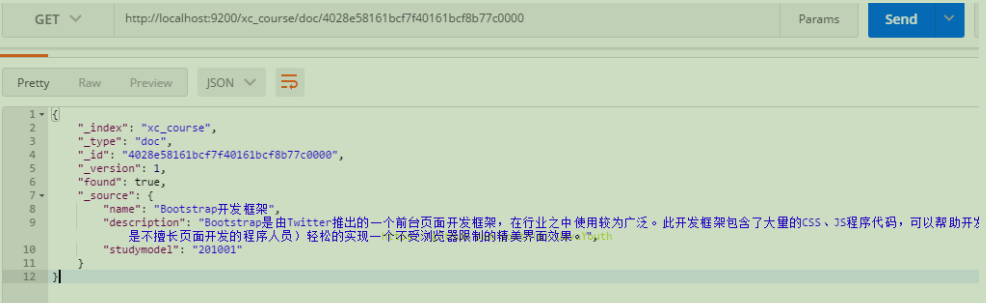
@@ -237,7 +236,7 @@ http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000
使用postman测试:
-
两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 , 那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳
@@ -237,7 +236,7 @@ http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000
使用postman测试:
- +
+ diff --git a/docs/ElasticSearch/usage/ElasticSearch-进阶.md b/docs/ElasticSearch/usage/ElasticSearch-进阶.md
index ab20eb2..d3e1fde 100644
--- a/docs/ElasticSearch/usage/ElasticSearch-进阶.md
+++ b/docs/ElasticSearch/usage/ElasticSearch-进阶.md
@@ -9,8 +9,7 @@ categories:
- 用法
keywords: ElasticSearch,全文检索
description: ElasticSearch-进阶篇,ElasticSearch的一些实战用法,集成SpringBoot。
-cover: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/ElasticSearch/logo.jpg'
-top_img: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/blog/top_img.jpg'
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@v1.0.0/ElasticSearch/logo.jpg'
abbrlink: 50e81c79
date: 2020-02-08 18:06:23
---
@@ -431,7 +430,7 @@ Post:http://localhost:9200/xc_test/doc/3
```json
{
"name": "spring cloud实战",
- "description": "本课程主要从四个章节进行讲解: 1.微服务架构入门 2.spring cloud 基础入门 3.实战Spring Boot 4.注册中心eureka。",
+ "description": "本课程主要从四个章节进行讲解: 1.微服务架构入门 2.spring cloud 基础入门 3.实战SpringBoot 4.注册中心eureka。",
"studymodel": "201001",
"price": 5.6
}
@@ -1729,4 +1728,5 @@ Post: http://127.0.0.1:9200/xc_course/doc/_search
}
}
-```
\ No newline at end of file
+```
+
diff --git a/docs/Java/Basis/Java8_New_Features/Java8新特性.md b/docs/Java/Basis/Java8_New_Features/Java8新特性.md
index 595881c..967f898 100644
--- a/docs/Java/Basis/Java8_New_Features/Java8新特性.md
+++ b/docs/Java/Basis/Java8_New_Features/Java8新特性.md
@@ -5,12 +5,11 @@ tags:
- JDK8
- 新特性
categories:
- - Java
+ - Java基础
- 新特性
keywords: Java8,新特性,JDK8
description: 详解JDK8出现的新特性。
-cover: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/Java_Basis/logo.png'
-top_img: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/blog/top_img.jpg'
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@v1.0.0/Java_Basis/logo.png'
abbrlink: de3879ae
date: 2020-10-19 22:15:58
---
@@ -21,7 +20,7 @@ date: 2020-10-19 22:15:58
> 本篇文章只讲解比较重要的
-
diff --git a/docs/ElasticSearch/usage/ElasticSearch-进阶.md b/docs/ElasticSearch/usage/ElasticSearch-进阶.md
index ab20eb2..d3e1fde 100644
--- a/docs/ElasticSearch/usage/ElasticSearch-进阶.md
+++ b/docs/ElasticSearch/usage/ElasticSearch-进阶.md
@@ -9,8 +9,7 @@ categories:
- 用法
keywords: ElasticSearch,全文检索
description: ElasticSearch-进阶篇,ElasticSearch的一些实战用法,集成SpringBoot。
-cover: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/ElasticSearch/logo.jpg'
-top_img: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/blog/top_img.jpg'
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@v1.0.0/ElasticSearch/logo.jpg'
abbrlink: 50e81c79
date: 2020-02-08 18:06:23
---
@@ -431,7 +430,7 @@ Post:http://localhost:9200/xc_test/doc/3
```json
{
"name": "spring cloud实战",
- "description": "本课程主要从四个章节进行讲解: 1.微服务架构入门 2.spring cloud 基础入门 3.实战Spring Boot 4.注册中心eureka。",
+ "description": "本课程主要从四个章节进行讲解: 1.微服务架构入门 2.spring cloud 基础入门 3.实战SpringBoot 4.注册中心eureka。",
"studymodel": "201001",
"price": 5.6
}
@@ -1729,4 +1728,5 @@ Post: http://127.0.0.1:9200/xc_course/doc/_search
}
}
-```
\ No newline at end of file
+```
+
diff --git a/docs/Java/Basis/Java8_New_Features/Java8新特性.md b/docs/Java/Basis/Java8_New_Features/Java8新特性.md
index 595881c..967f898 100644
--- a/docs/Java/Basis/Java8_New_Features/Java8新特性.md
+++ b/docs/Java/Basis/Java8_New_Features/Java8新特性.md
@@ -5,12 +5,11 @@ tags:
- JDK8
- 新特性
categories:
- - Java
+ - Java基础
- 新特性
keywords: Java8,新特性,JDK8
description: 详解JDK8出现的新特性。
-cover: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/Java_Basis/logo.png'
-top_img: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/blog/top_img.jpg'
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@v1.0.0/Java_Basis/logo.png'
abbrlink: de3879ae
date: 2020-10-19 22:15:58
---
@@ -21,7 +20,7 @@ date: 2020-10-19 22:15:58
> 本篇文章只讲解比较重要的
- +
+ @@ -112,12 +111,15 @@ import java.util.function.Consumer;
* 3. Lambda表达式的使用:(分为6种情况介绍)
*
@@ -112,12 +111,15 @@ import java.util.function.Consumer;
* 3. Lambda表达式的使用:(分为6种情况介绍)
*
* 总结:
- * ->左边:lambda形参列表的参数类型可以省略(类型推断);如果lambda形参列表只有一个参数,其一对()也可以省略
- * ->右边:lambda体应该使用一对{}包裹;如果lambda体只有一条执行语句(可能是return语句),省略这一对{}和return关键字
+ * ->左边:lambda形参列表的参数类型可以省略(类型推断);如果lambda形参列表只有一个参数,其一对()也
+ * 可以省略
+ * ->右边:lambda体应该使用一对{}包裹;如果lambda体只有一条执行语句(可能是return语句),省略这一
+ 对{}和return关键字
*
* 4.Lambda表达式的本质:作为函数式接口的实例
*
- * 5. 如果一个接口中,只声明了一个抽象方法,则此接口就称为函数式接口。我们可以在一个接口上使用 @FunctionalInterface 注解,
+ * 5. 如果一个接口中,只声明了一个抽象方法,则此接口就称为函数式接口。我们可以在一个接口上
+ 使用 @FunctionalInterface 注解,
* 这样做可以检查它是否是一个函数式接口。
*
* 6. 所以以前用匿名实现类表示的现在都可以用Lambda表达式来写。
@@ -306,13 +308,13 @@ public class LambdaTest1 {
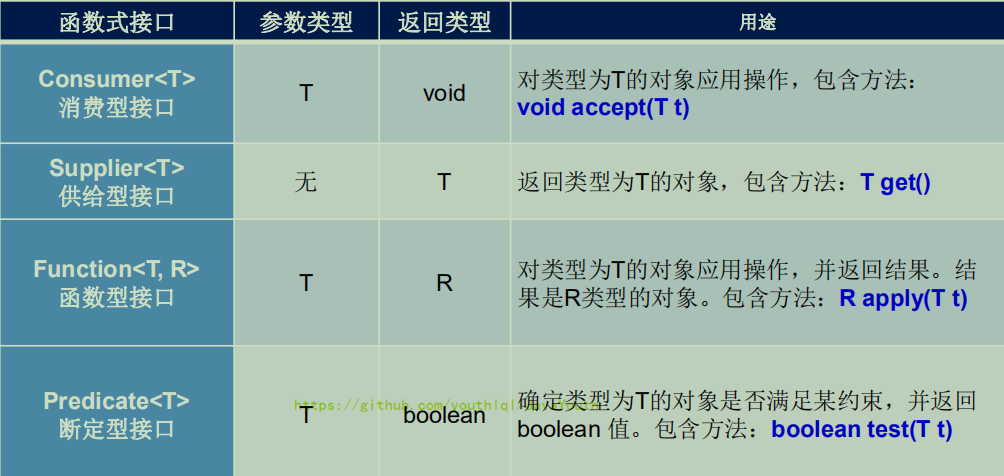
**核心函数式接口**
- +
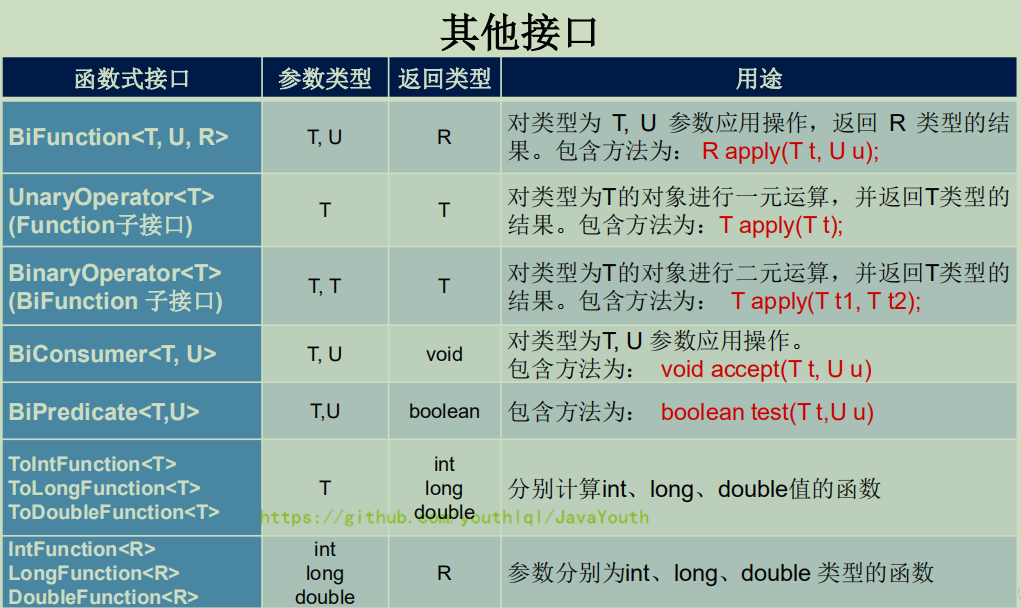
+ **其它函数式接口**
-
**其它函数式接口**
- +
+ @@ -900,7 +902,7 @@ Stream到底是什么呢?
-
@@ -900,7 +902,7 @@ Stream到底是什么呢?
- +
+ @@ -999,7 +1001,10 @@ public class StreamAPITest1 {
list.stream().limit(3).forEach(System.out::println);
System.out.println();
-// skip(n) —— 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补
+ /*
+ skip(n) —— 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,
+ 则返回一个空流。与 limit(n) 互补
+ */
list.stream().skip(3).forEach(System.out::println);
System.out.println();
@@ -1019,7 +1024,10 @@ public class StreamAPITest1 {
//映射
@Test
public void test2(){
-// map(Function f)——接收一个函数作为参数,将元素转换成其他形式或提取信息,该函数会被应用到每个元素上,并将其映射成一个新的元素。
+ /*
+ map(Function f)——接收一个函数作为参数,将元素转换成其他形式或提取信息,该函数会被应
+ 用到每个元素上,并将其映射成一个新的元素。
+ */
List list = Arrays.asList("aa", "bb", "cc", "dd");
list.stream().map(str -> str.toUpperCase()).forEach(System.out::println);
@@ -1035,8 +1043,10 @@ public class StreamAPITest1 {
s.forEach(System.out::println);
});
System.out.println();
-// flatMap(Function f)——接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
- //flatMap一层遍历即可拿到想要的结果
+ /*
+ flatMap(Function f)——接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连
+ 接成一个流。flatMap一层遍历即可拿到想要的结果
+ */
Stream characterStream = list.stream().flatMap(StreamAPITest1::fromStringToStream);
characterStream.forEach(System.out::println);
@@ -1171,7 +1181,7 @@ public class StreamAPITest2 {
//3-收集
@Test
public void test4(){
-// collect(Collector c)——将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法
+// collect(Collector c)——将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法
// 练习1:查找工资大于6000的员工,结果返回为一个List或Set
List employees = EmployeeData.getEmployees();
@@ -1209,7 +1219,7 @@ public class StreamAPITest2 {
## 常用API
-
@@ -999,7 +1001,10 @@ public class StreamAPITest1 {
list.stream().limit(3).forEach(System.out::println);
System.out.println();
-// skip(n) —— 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补
+ /*
+ skip(n) —— 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,
+ 则返回一个空流。与 limit(n) 互补
+ */
list.stream().skip(3).forEach(System.out::println);
System.out.println();
@@ -1019,7 +1024,10 @@ public class StreamAPITest1 {
//映射
@Test
public void test2(){
-// map(Function f)——接收一个函数作为参数,将元素转换成其他形式或提取信息,该函数会被应用到每个元素上,并将其映射成一个新的元素。
+ /*
+ map(Function f)——接收一个函数作为参数,将元素转换成其他形式或提取信息,该函数会被应
+ 用到每个元素上,并将其映射成一个新的元素。
+ */
List list = Arrays.asList("aa", "bb", "cc", "dd");
list.stream().map(str -> str.toUpperCase()).forEach(System.out::println);
@@ -1035,8 +1043,10 @@ public class StreamAPITest1 {
s.forEach(System.out::println);
});
System.out.println();
-// flatMap(Function f)——接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
- //flatMap一层遍历即可拿到想要的结果
+ /*
+ flatMap(Function f)——接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连
+ 接成一个流。flatMap一层遍历即可拿到想要的结果
+ */
Stream characterStream = list.stream().flatMap(StreamAPITest1::fromStringToStream);
characterStream.forEach(System.out::println);
@@ -1171,7 +1181,7 @@ public class StreamAPITest2 {
//3-收集
@Test
public void test4(){
-// collect(Collector c)——将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法
+// collect(Collector c)——将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法
// 练习1:查找工资大于6000的员工,结果返回为一个List或Set
List employees = EmployeeData.getEmployees();
@@ -1209,7 +1219,7 @@ public class StreamAPITest2 {
## 常用API
- +
+ diff --git a/docs/Java/Basis/keyAndDifficultPoints/Generic/泛型.md b/docs/Java/Basis/keyAndDifficultPoints/Generic/泛型.md
index 5de3736..051814e 100644
--- a/docs/Java/Basis/keyAndDifficultPoints/Generic/泛型.md
+++ b/docs/Java/Basis/keyAndDifficultPoints/Generic/泛型.md
@@ -9,9 +9,8 @@ categories:
- 重难点
keywords: Java基础,泛型
description: 万字长文详解Java泛型。
-cover: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/Java_Basis/logo.png'
-top_img: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/blog/top_img.jpg'
-abbrlink: 1c342bc4
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@v1.0.0/Java_Basis/logo.png'
+abbrlink: adb2faf0
date: 2020-10-19 22:21:58
---
@@ -592,7 +591,8 @@ class GenerateTest {
/**
* 1、在泛型类中声明了一个泛型方法,使用泛型E,这种泛型E可以为任意类型。可以类型与T相同,也可以不同。
- * 2、由于泛型方法在声明的时候会声明泛型,因此即使在泛型类中并未声明泛型,编译器也能够正确识别泛型方法中识别的泛型。
+ * 2、由于泛型方法在声明的时候会声明泛型,因此即使在泛型类中并未声明泛型,编译器也能够正确识别
+ 泛型方法中识别的泛型。
*/
public void show_3(E t) {
System.out.println(t.toString());
@@ -777,7 +777,8 @@ class Order {
/**
* 2、泛型方法:在方法中出现了泛型的结构,泛型参数与类的泛型参数没有任何关系。换句话说,
* 泛型方法所属的类是不是泛型类都没有关系。
- * 3、泛型方法,可以声明为静态的。原因:泛型参数是在调用方法时确定的。并非在初始化类时确定,所以无所谓
+ * 3、泛型方法,可以声明为静态的。原因:泛型参数是在调用方法时确定的。并非在初始化类时确定,
+ * 所以无所谓
*/
public static List copyFromArrayToList(E[] arr){
@@ -1037,7 +1038,7 @@ class Dog extends Animal {
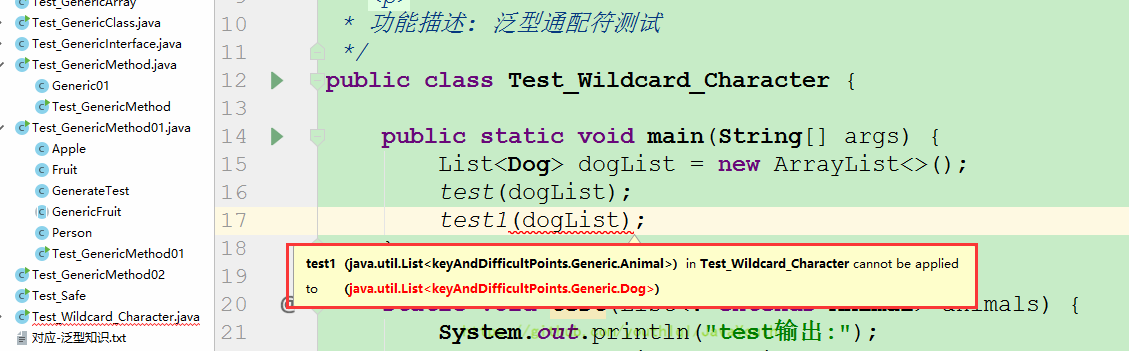
`test1()`在编译时就会飘红
-
diff --git a/docs/Java/Basis/keyAndDifficultPoints/Generic/泛型.md b/docs/Java/Basis/keyAndDifficultPoints/Generic/泛型.md
index 5de3736..051814e 100644
--- a/docs/Java/Basis/keyAndDifficultPoints/Generic/泛型.md
+++ b/docs/Java/Basis/keyAndDifficultPoints/Generic/泛型.md
@@ -9,9 +9,8 @@ categories:
- 重难点
keywords: Java基础,泛型
description: 万字长文详解Java泛型。
-cover: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/Java_Basis/logo.png'
-top_img: 'https://cdn.jsdelivr.net/gh/youthlql/lql_img/blog/top_img.jpg'
-abbrlink: 1c342bc4
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@v1.0.0/Java_Basis/logo.png'
+abbrlink: adb2faf0
date: 2020-10-19 22:21:58
---
@@ -592,7 +591,8 @@ class GenerateTest {
/**
* 1、在泛型类中声明了一个泛型方法,使用泛型E,这种泛型E可以为任意类型。可以类型与T相同,也可以不同。
- * 2、由于泛型方法在声明的时候会声明泛型,因此即使在泛型类中并未声明泛型,编译器也能够正确识别泛型方法中识别的泛型。
+ * 2、由于泛型方法在声明的时候会声明泛型,因此即使在泛型类中并未声明泛型,编译器也能够正确识别
+ 泛型方法中识别的泛型。
*/
public void show_3(E t) {
System.out.println(t.toString());
@@ -777,7 +777,8 @@ class Order {
/**
* 2、泛型方法:在方法中出现了泛型的结构,泛型参数与类的泛型参数没有任何关系。换句话说,
* 泛型方法所属的类是不是泛型类都没有关系。
- * 3、泛型方法,可以声明为静态的。原因:泛型参数是在调用方法时确定的。并非在初始化类时确定,所以无所谓
+ * 3、泛型方法,可以声明为静态的。原因:泛型参数是在调用方法时确定的。并非在初始化类时确定,
+ * 所以无所谓
*/
public static List copyFromArrayToList(E[] arr){
@@ -1037,7 +1038,7 @@ class Dog extends Animal {
`test1()`在编译时就会飘红
- +
+ @@ -1289,7 +1290,7 @@ public class Test_difference {
}
```
-
@@ -1289,7 +1290,7 @@ public class Test_difference {
}
```
- +
+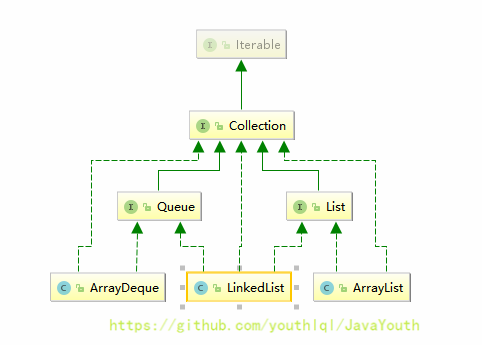 ### 区别3:?通配符可以使用超类限定而T不行
@@ -1382,7 +1383,7 @@ class D {
Java中的泛型基本上都是在编译器这个层次来实现的,在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,编译器在编译的时候去掉,这个过程就称为类型擦除。
- 如在代码中定义的List
### 区别3:?通配符可以使用超类限定而T不行
@@ -1382,7 +1383,7 @@ class D {
Java中的泛型基本上都是在编译器这个层次来实现的,在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,编译器在编译的时候去掉,这个过程就称为类型擦除。
- 如在代码中定义的List