diff --git a/docs/Apollo/Apollo简单入门.md b/docs/Apollo/Apollo简单入门.md
index 3e1d91a..b1063fe 100644
--- a/docs/Apollo/Apollo简单入门.md
+++ b/docs/Apollo/Apollo简单入门.md
@@ -8,7 +8,7 @@ categories:
- Apollo
keywords: Apollo,配置中心。
description: Apollo简单入门及和SpringBoot集成。
-cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@master/Apollo/logo.png'
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@v1.2.0/Apollo/logo.png'
abbrlink: 10d32fba
date: 2020-12-29 11:31:58
---
@@ -76,7 +76,7 @@ date: 2020-12-29 11:31:58
不过,解决一个问题的同时,往往会诞生出很多新的问题,所以微服务化的过程中伴随着很多的挑战,其中一个挑战就是有关服务(应用)配置的。当系统从一个单体应用,被拆分成分布式系统上一个个服务节点后,配置文件也必须跟着迁移(分割),这样配置就分散了,不仅如此,分散中还包含着冗余,如下图:
- +
+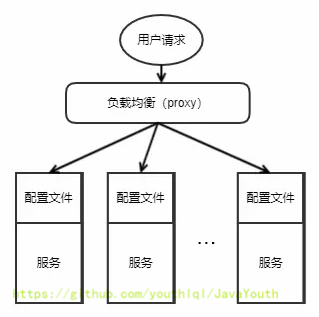 配置中心将配置从应用中剥离出来,统一管理,优雅的解决了配置的动态变更、持久化、运维成本等问题。
@@ -86,7 +86,7 @@ date: 2020-12-29 11:31:58
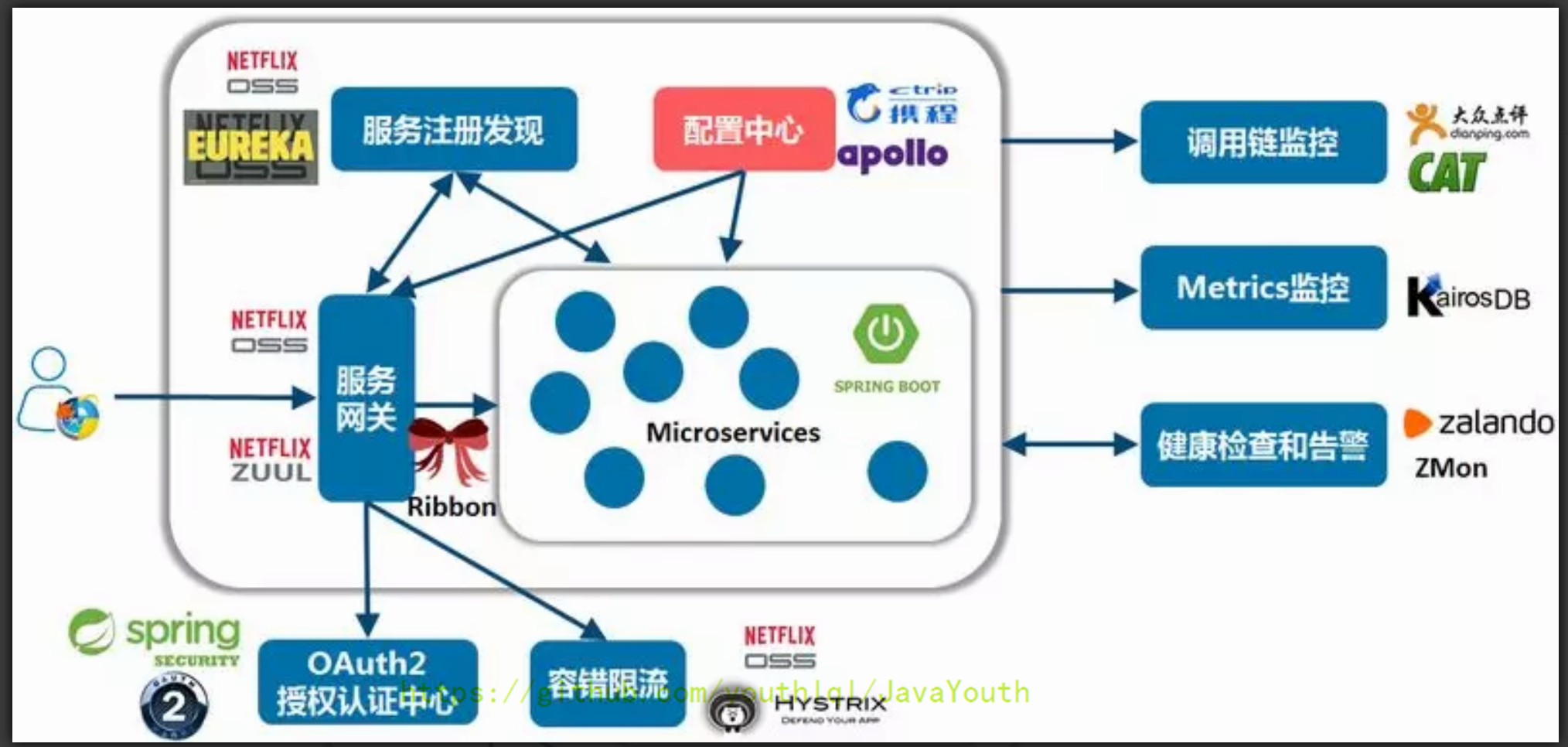
在系统架构中,配置中心是整个微服务基础架构体系中的一个组件,如下图,它的功能看上去并不起眼,无非就是配置的管理和存取,但它是整个微服务架构中不可或缺的一环。
-
配置中心将配置从应用中剥离出来,统一管理,优雅的解决了配置的动态变更、持久化、运维成本等问题。
@@ -86,7 +86,7 @@ date: 2020-12-29 11:31:58
在系统架构中,配置中心是整个微服务基础架构体系中的一个组件,如下图,它的功能看上去并不起眼,无非就是配置的管理和存取,但它是整个微服务架构中不可或缺的一环。
- +
+ @@ -171,7 +171,7 @@ Apollo简介
### Apollo简介
-
@@ -171,7 +171,7 @@ Apollo简介
### Apollo简介
- +
+ **Apollo - A reliable configuration management system**
@@ -221,7 +221,7 @@ Apollo快速入门
### 执行流程
-
**Apollo - A reliable configuration management system**
@@ -221,7 +221,7 @@ Apollo快速入门
### 执行流程
- +
+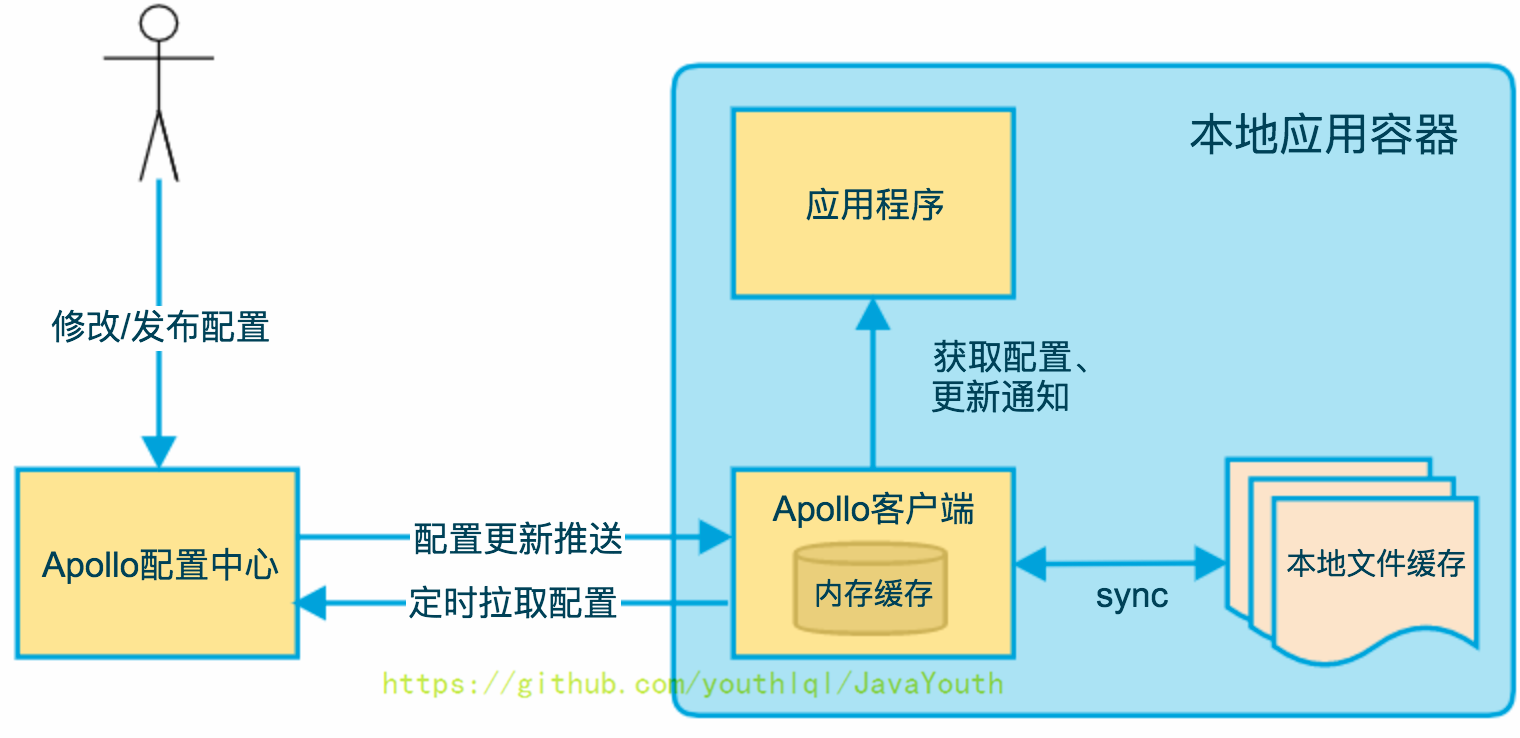 操作流程如下:
@@ -262,7 +262,7 @@ Apollo的表结构对`timestamp`使用了多个default声明,所以需要5.6.5
2. 打开1.3发布链接,下载必须的安装包:[https://github.com/ctripcorp/apollo/releases/tag/v1.3.0](https://github.com/ctripcorp/apollo/releases/tag/v1.3.0)。三个都要下
-
操作流程如下:
@@ -262,7 +262,7 @@ Apollo的表结构对`timestamp`使用了多个default声明,所以需要5.6.5
2. 打开1.3发布链接,下载必须的安装包:[https://github.com/ctripcorp/apollo/releases/tag/v1.3.0](https://github.com/ctripcorp/apollo/releases/tag/v1.3.0)。三个都要下
- +
+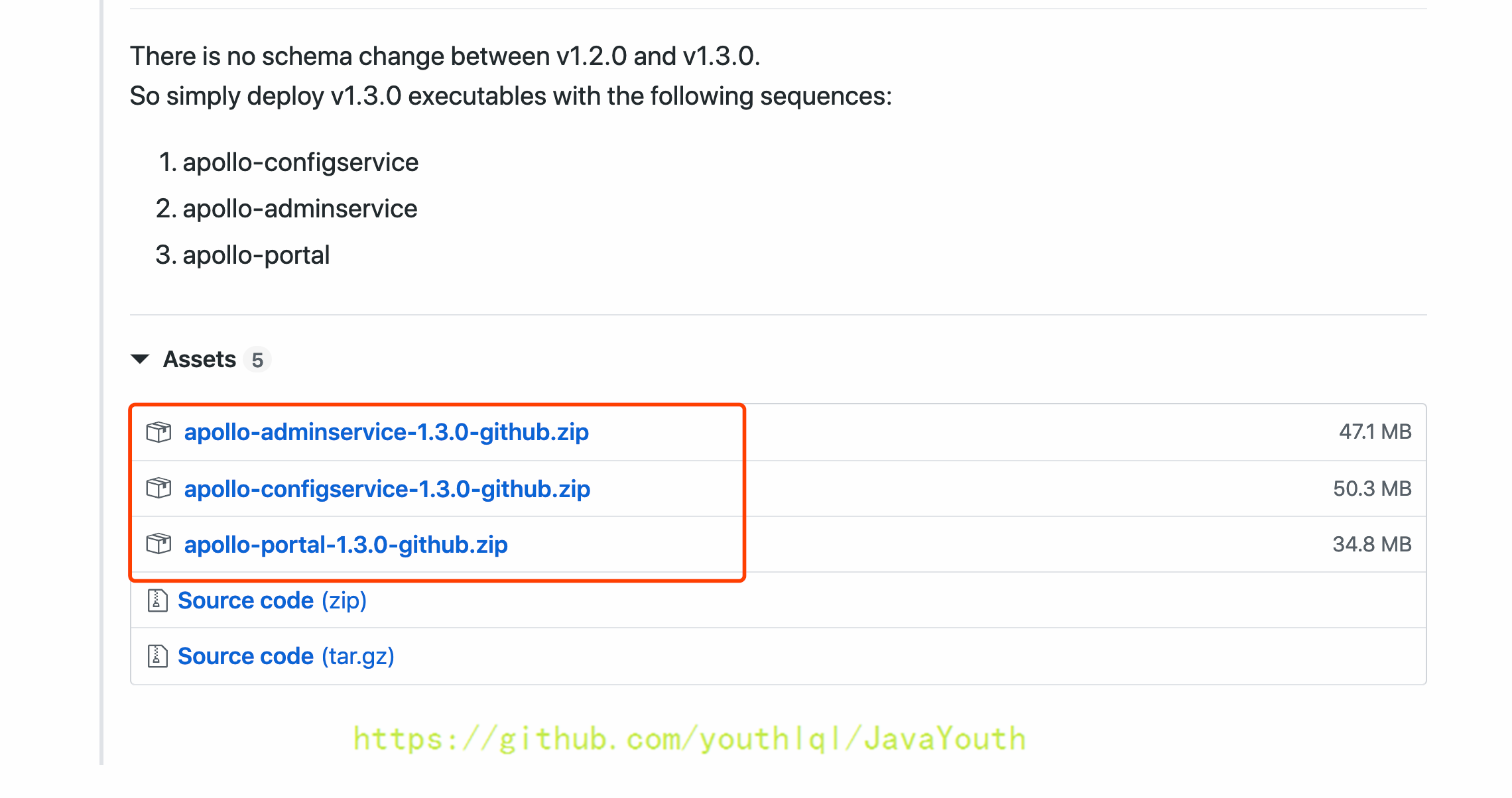 解压安装包后将apollo-configservice-1.3.0.jar, apollo-adminservice-1.3.0.jar, apollo-portal-1.3.0.jar放置于apollo目录下
@@ -349,11 +349,11 @@ Apollo服务端共需要两个数据库:`ApolloPortalDB`和`ApolloConfigDB`,
1. 也可以使用提供的runApollo.bat快速启动三个服务(修改数据库连接地址,数据库以及密码)
-
解压安装包后将apollo-configservice-1.3.0.jar, apollo-adminservice-1.3.0.jar, apollo-portal-1.3.0.jar放置于apollo目录下
@@ -349,11 +349,11 @@ Apollo服务端共需要两个数据库:`ApolloPortalDB`和`ApolloConfigDB`,
1. 也可以使用提供的runApollo.bat快速启动三个服务(修改数据库连接地址,数据库以及密码)
-  +
+  这里面是一个很简单的脚本
-
这里面是一个很简单的脚本
-  +
+  @@ -385,29 +385,29 @@ start "ApolloPortal" java -Xms256m -Xmx256m -Dapollo_profile=github,auth -Ddev_m
1. 打开[apollo](http://localhost:8070/) :新建项目apollo-quickstart
-
@@ -385,29 +385,29 @@ start "ApolloPortal" java -Xms256m -Xmx256m -Dapollo_profile=github,auth -Ddev_m
1. 打开[apollo](http://localhost:8070/) :新建项目apollo-quickstart
- +
+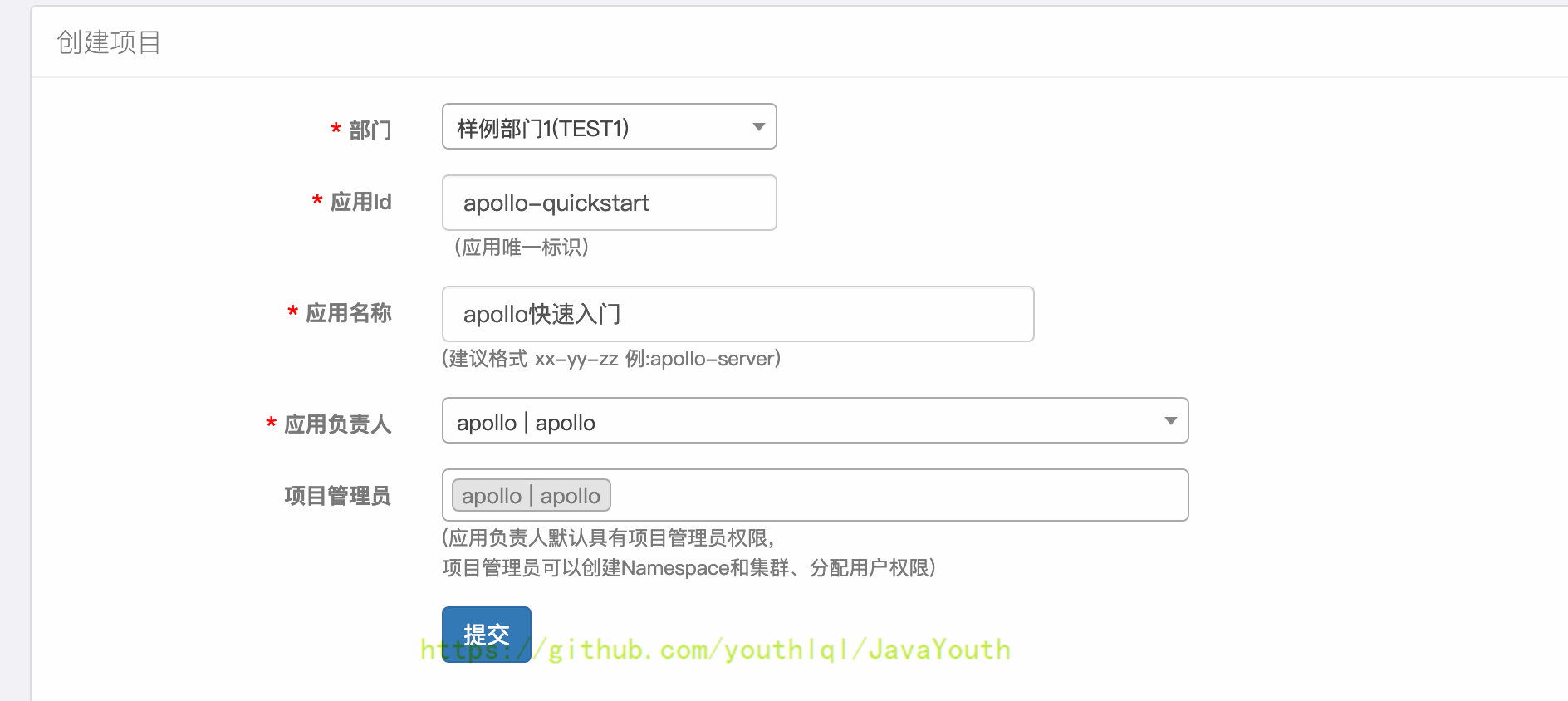 2. 新建配置项sms.enable
-
2. 新建配置项sms.enable
- +
+ -
- +
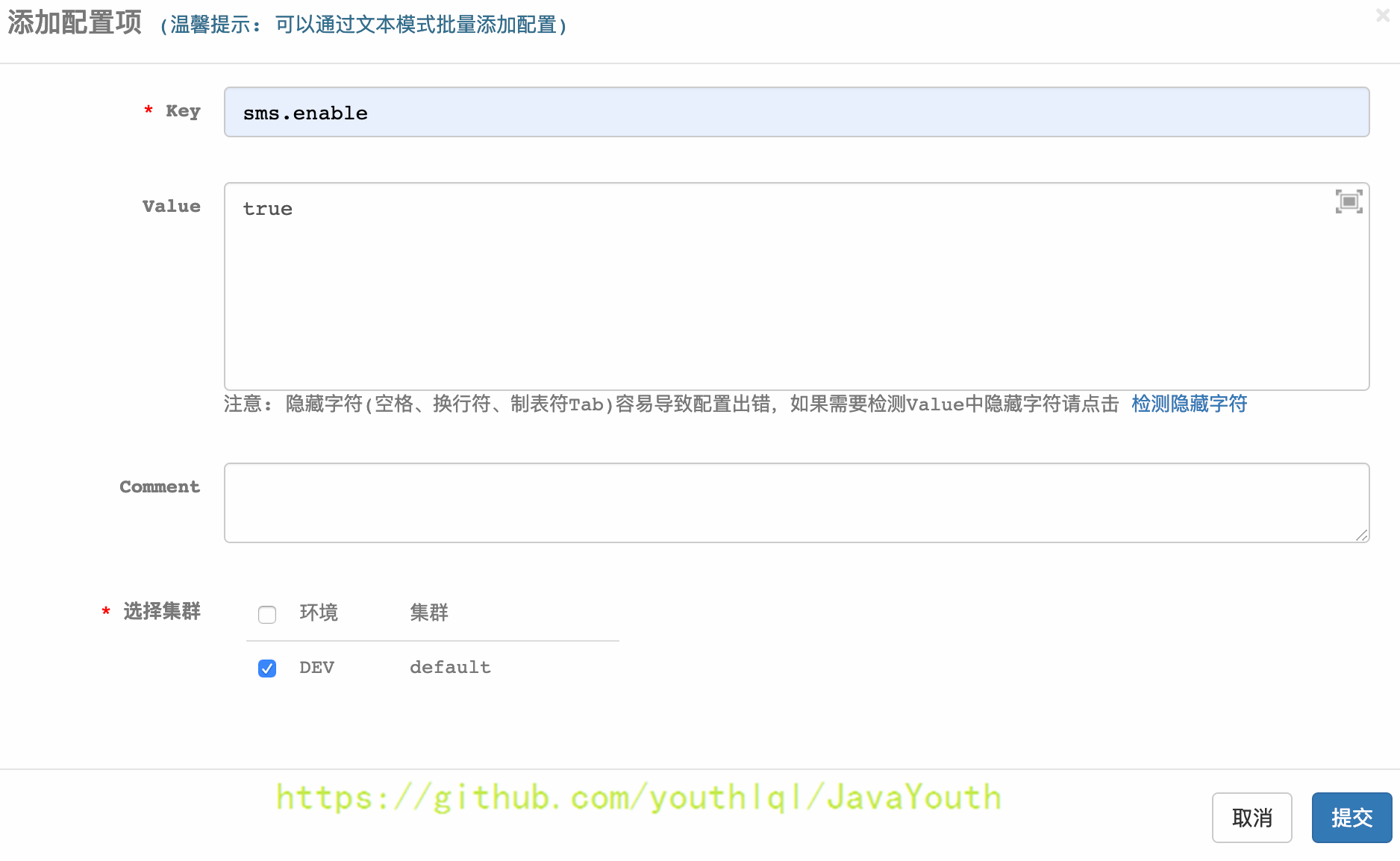
+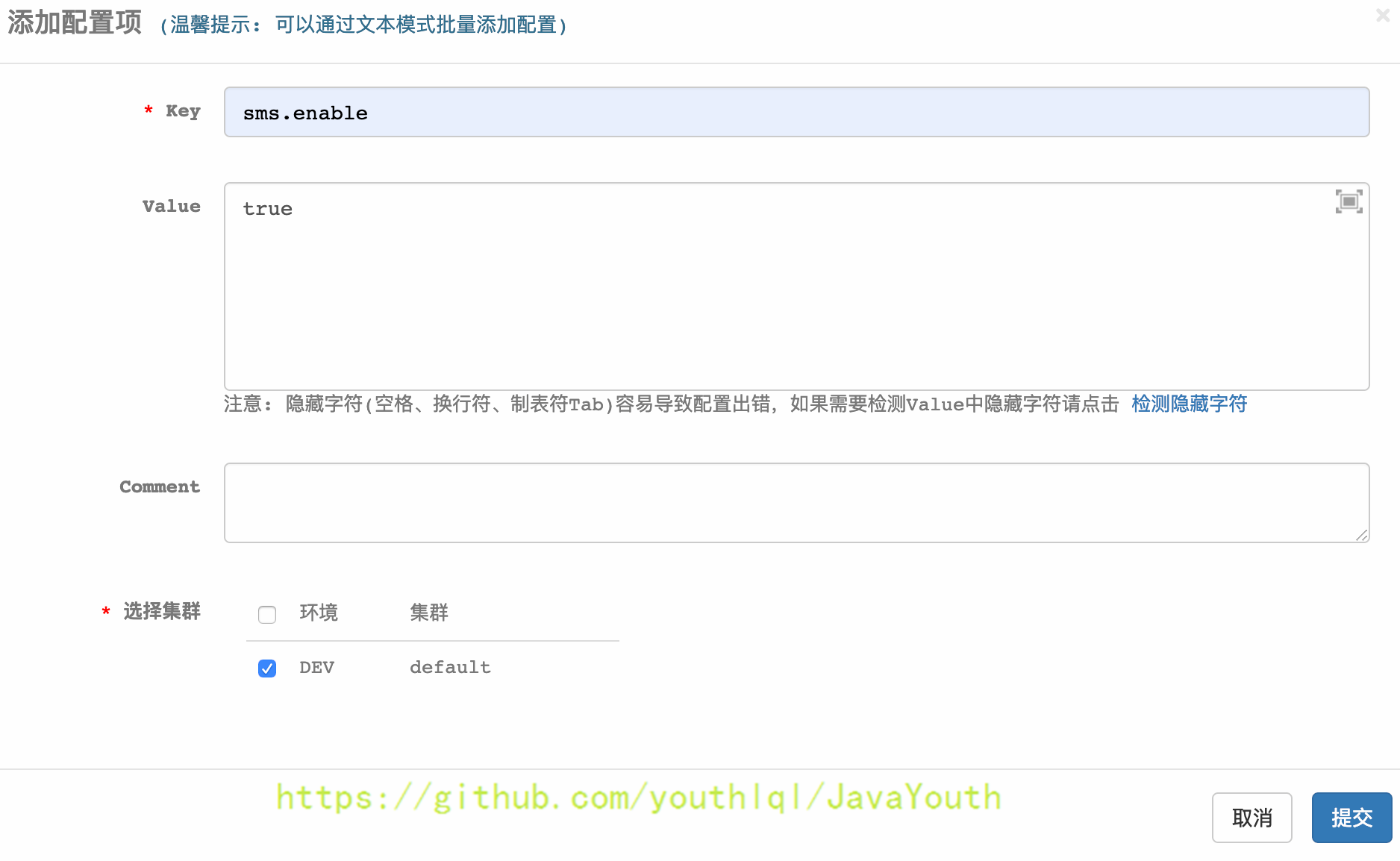 确认提交配置项
-
确认提交配置项
- +
+ -
+
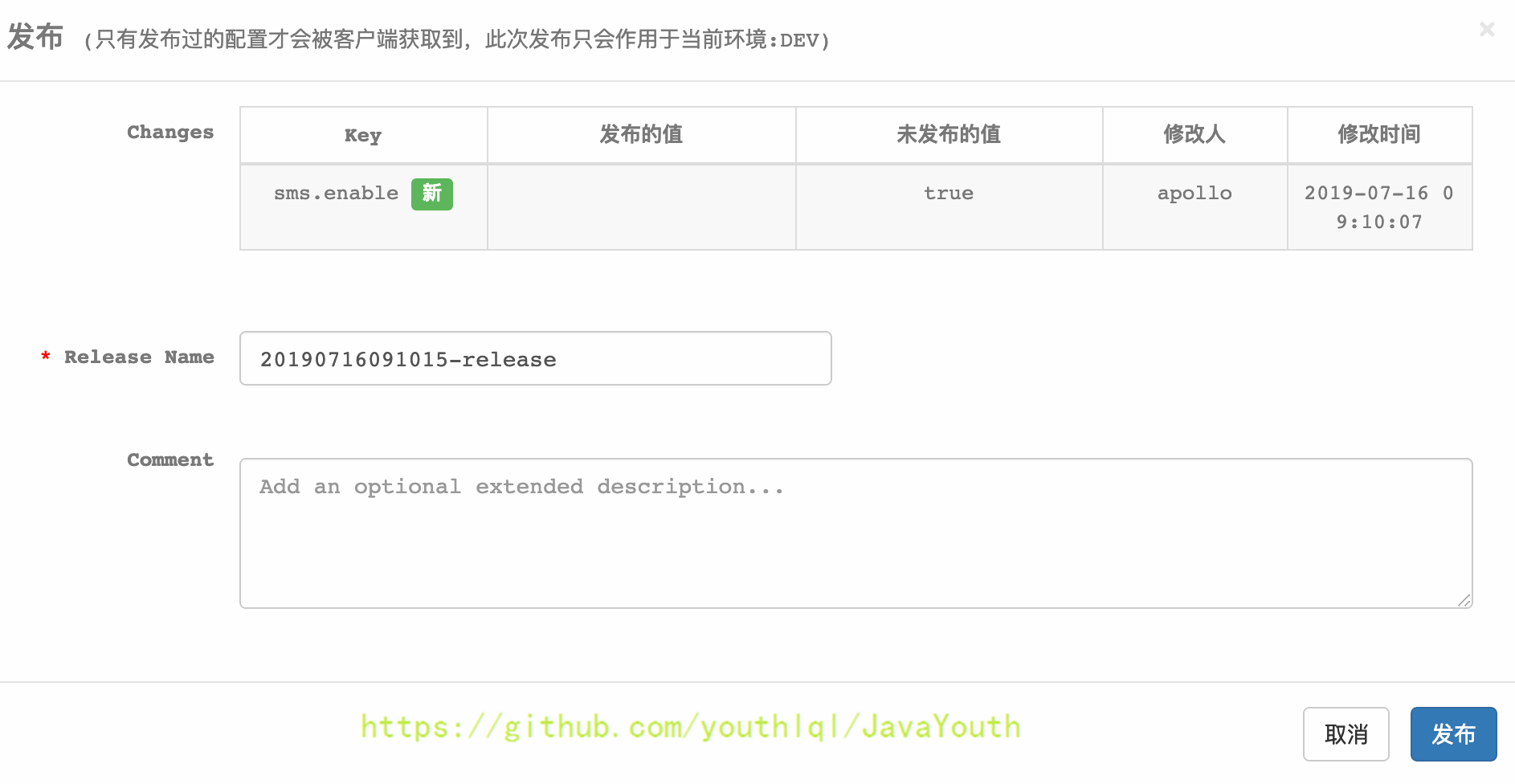
3. 发布配置项
-
-
+
3. 发布配置项
- +
+ #### 应用读取配置
@@ -485,7 +485,7 @@ public class GetConfigTest {
-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:8080
-
#### 应用读取配置
@@ -485,7 +485,7 @@ public class GetConfigTest {
-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:8080
- +
+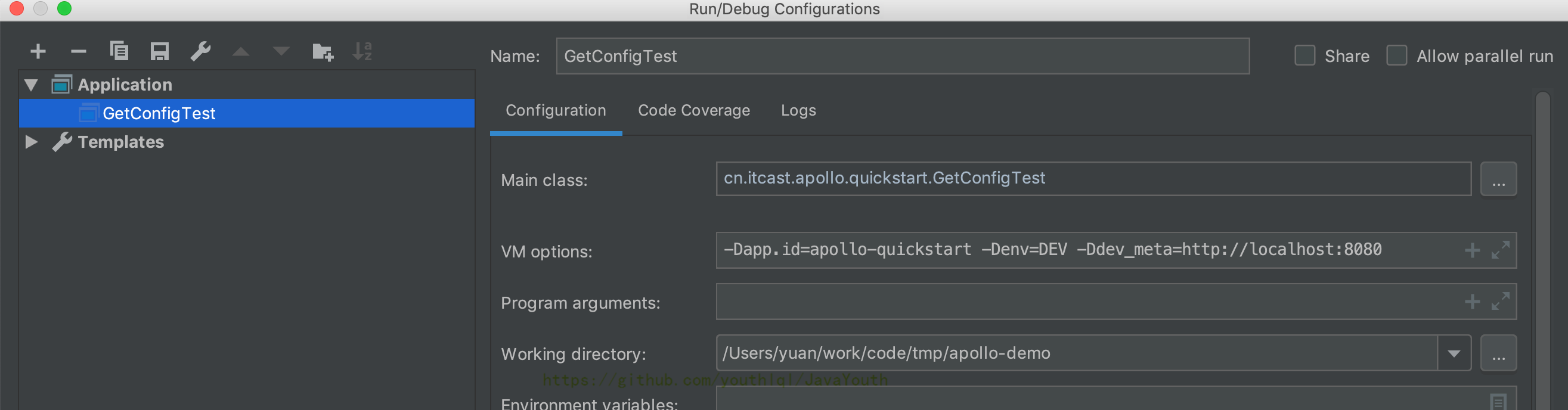 运行GetConfigTest,打开控制台,观察输出结果
@@ -523,19 +523,19 @@ sma.enable: true
2. 运行GetConfigTest观察输出结果
-
运行GetConfigTest,打开控制台,观察输出结果
@@ -523,19 +523,19 @@ sma.enable: true
2. 运行GetConfigTest观察输出结果
- +
+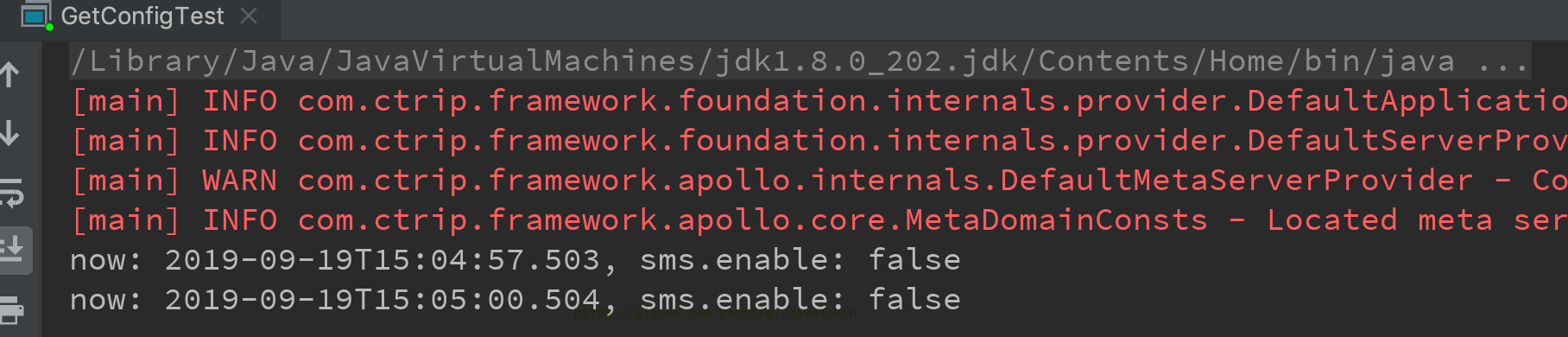 3. 在Apollo管理界面修改配置项
-
3. 在Apollo管理界面修改配置项
- +
+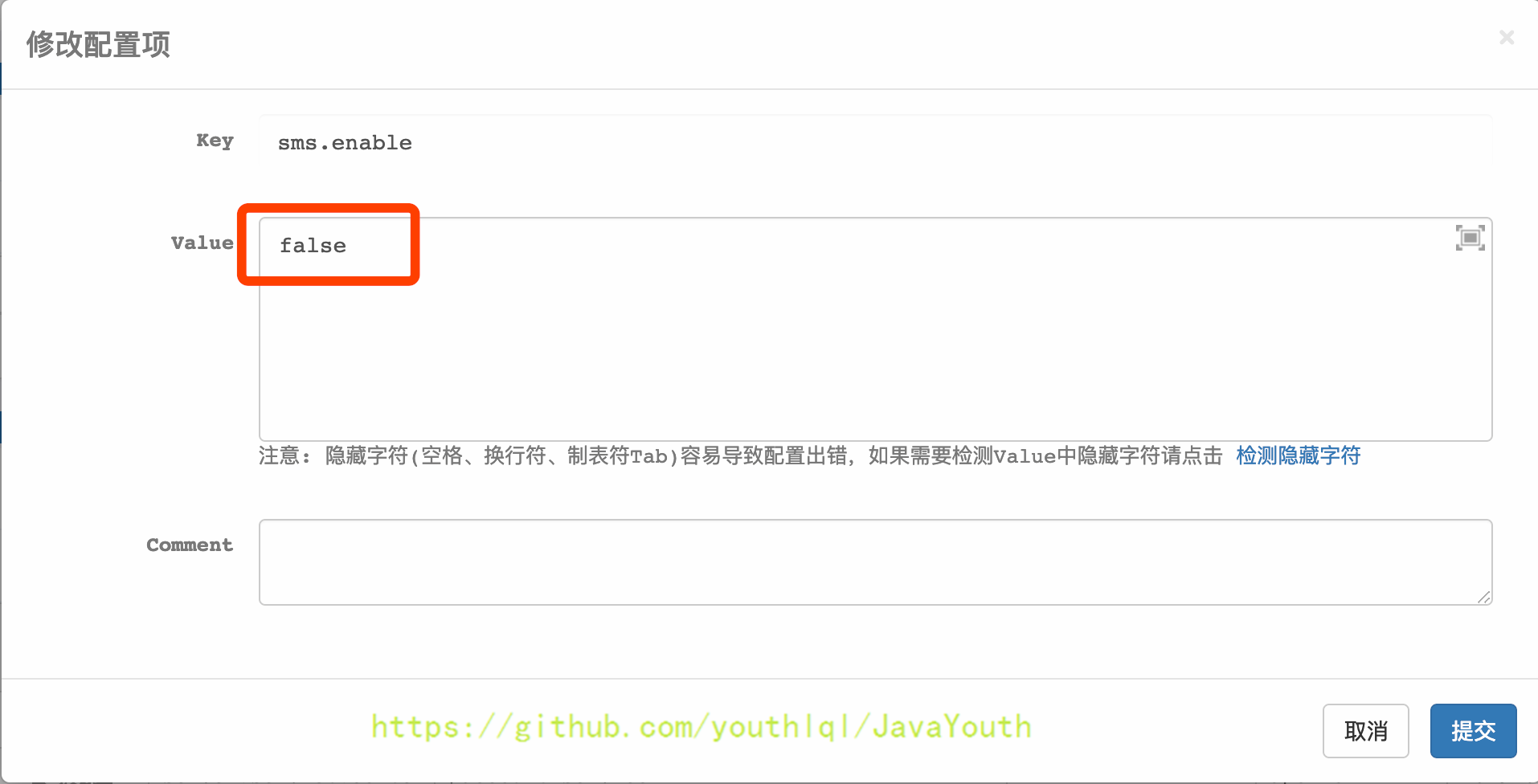 4. 发布配置
-
4. 发布配置
- +
+ 5. 在控制台查看详细情况:可以看到程序获取的sms.enable的值已由false变成了修改后的true
-
5. 在控制台查看详细情况:可以看到程序获取的sms.enable的值已由false变成了修改后的true
- +
+ @@ -546,7 +546,7 @@ Apollo应用
下图是Apollo架构模块的概览
-
@@ -546,7 +546,7 @@ Apollo应用
下图是Apollo架构模块的概览
- +
+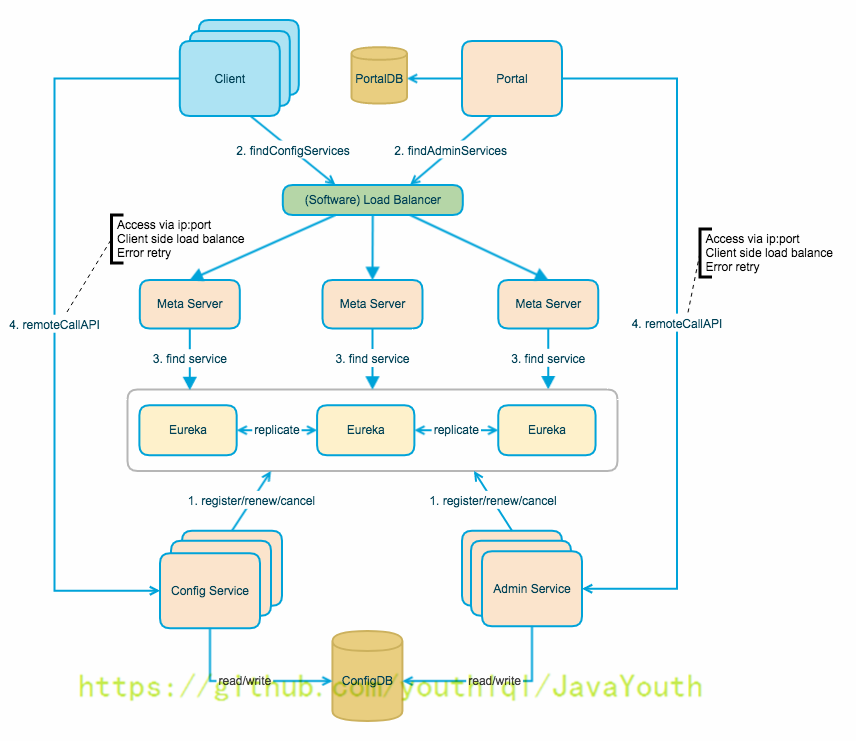 #### 各模块职责
@@ -601,7 +601,7 @@ Apollo应用
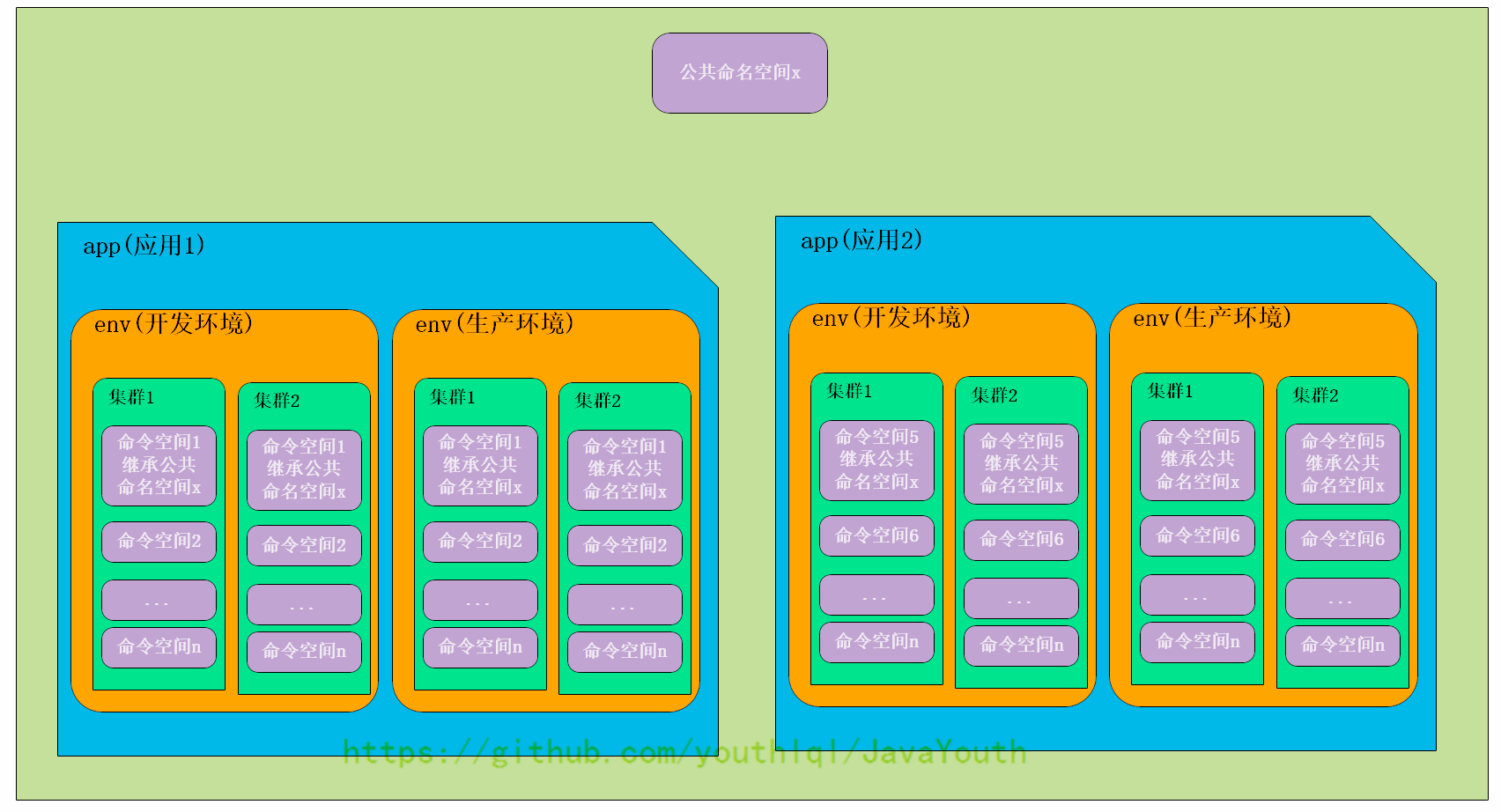
它们的关系如下图所示:
-
#### 各模块职责
@@ -601,7 +601,7 @@ Apollo应用
它们的关系如下图所示:
- +
+ @@ -615,15 +615,15 @@ apollo 默认部门有两个。要增加自己的部门,可在系统参数中
* 进入系统参数设置
-
@@ -615,15 +615,15 @@ apollo 默认部门有两个。要增加自己的部门,可在系统参数中
* 进入系统参数设置
- +
+ -
+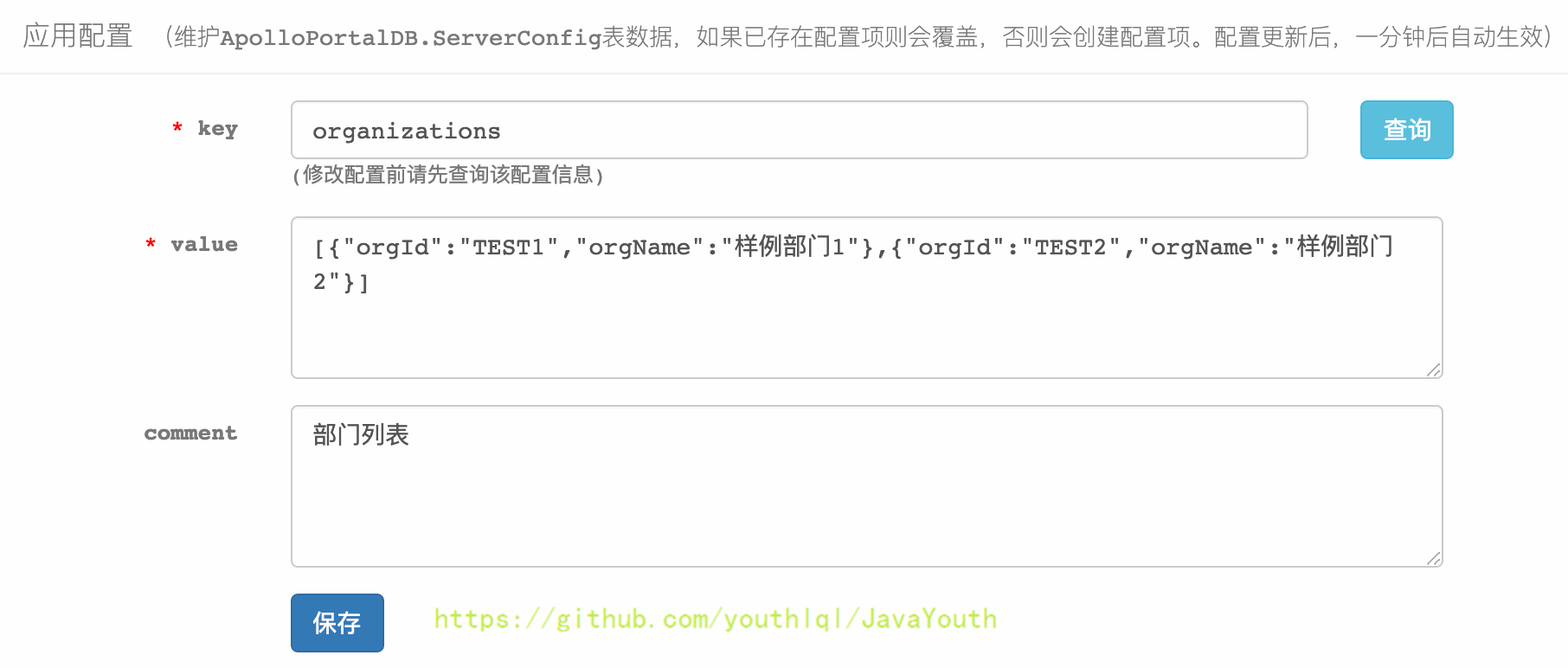
* 输入key查询已存在的部门设置:organizations
-
-
+
* 输入key查询已存在的部门设置:organizations
-  +
+ 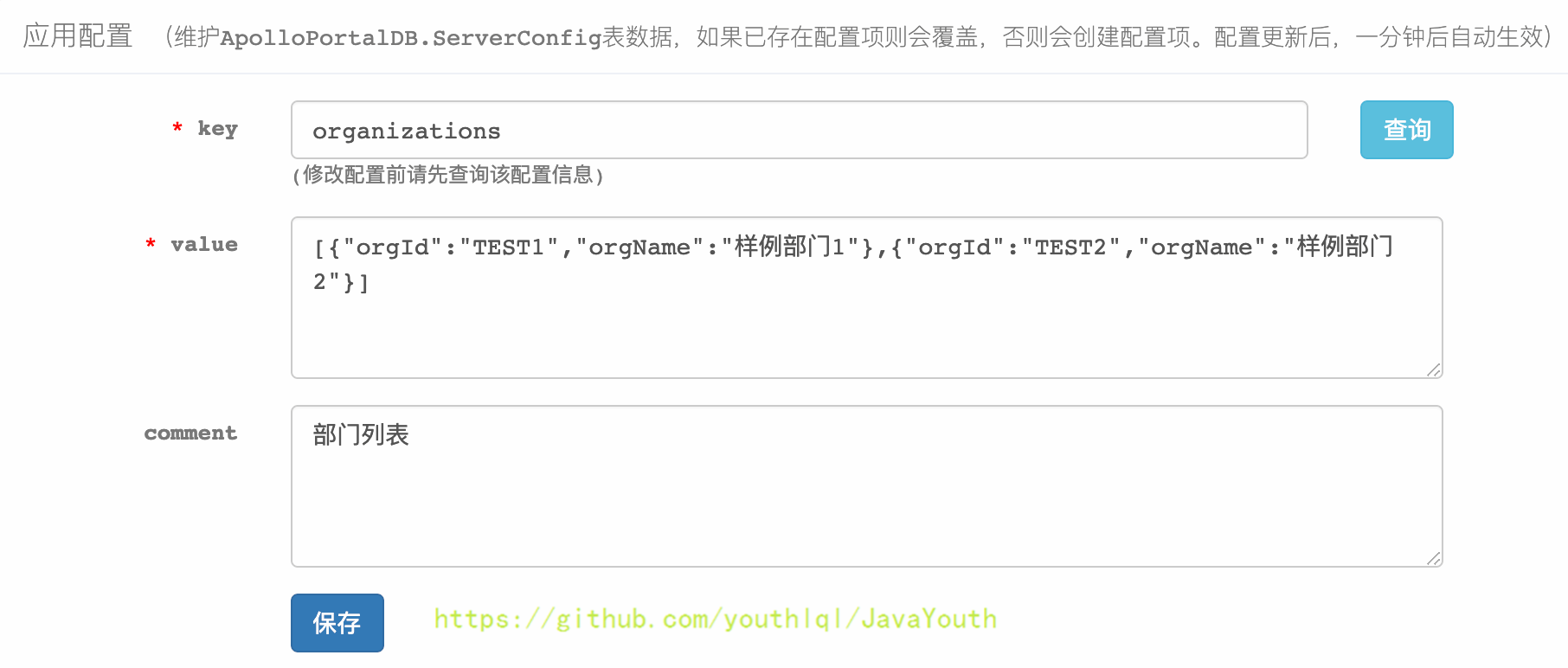 * 修改value值来添加新部门,下面添加一个微服务部门:
@@ -639,11 +639,11 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 新建用户张三
-
* 修改value值来添加新部门,下面添加一个微服务部门:
@@ -639,11 +639,11 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 新建用户张三
- +
+ -
- +
+ #### 创建项目
@@ -661,7 +661,7 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 应用名称:应用名,仅用于界面展示
* 应用负责人:选择的人默认会成为该项目的管理员,具备项目权限管理、集群创建、Namespace创建等权限
-
#### 创建项目
@@ -661,7 +661,7 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 应用名称:应用名,仅用于界面展示
* 应用负责人:选择的人默认会成为该项目的管理员,具备项目权限管理、集群创建、Namespace创建等权限
- +
+ 4. 点击提交,创建成功后,会自动跳转到项目首页
@@ -671,7 +671,7 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 使用管理员apollo将指定项目授权给用户张三
-
4. 点击提交,创建成功后,会自动跳转到项目首页
@@ -671,7 +671,7 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 使用管理员apollo将指定项目授权给用户张三
-  +
+ 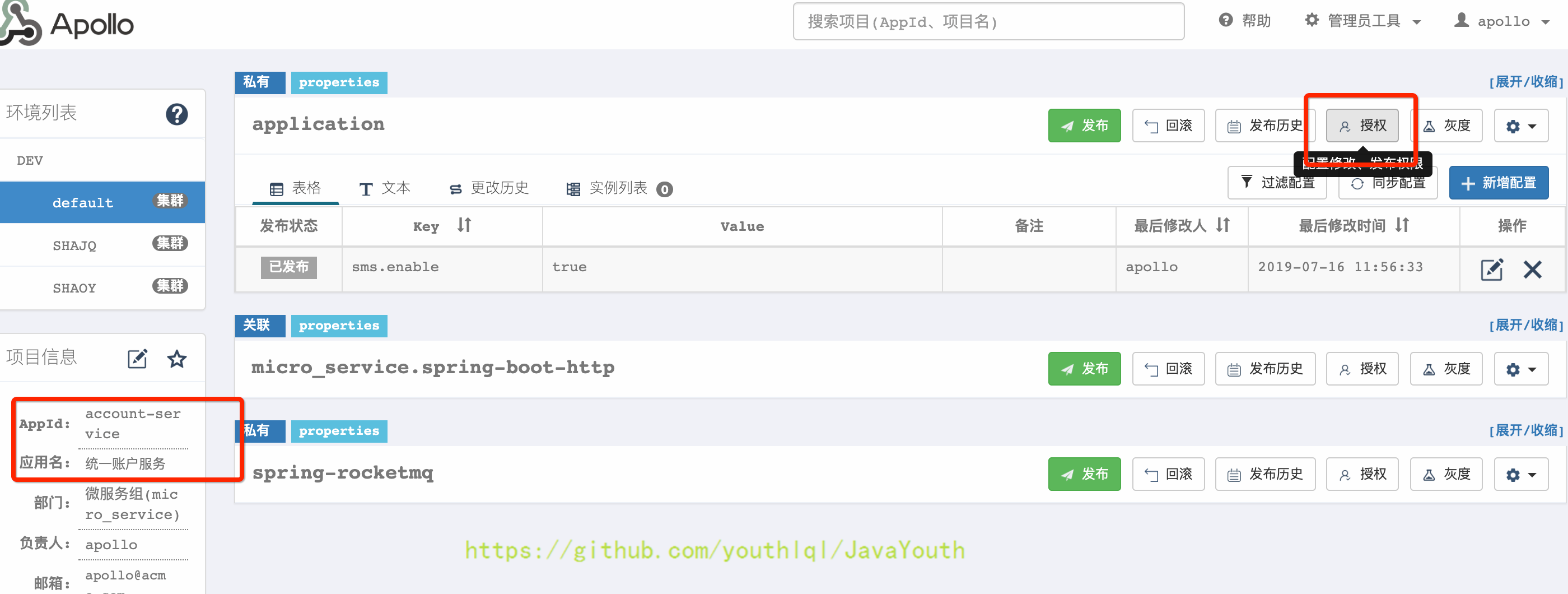 * 将修改和发布权限都授权给张三
@@ -731,7 +731,7 @@ Namespace作为配置的分类,可当成一个配置文件。
进入项目首页,点击左下脚的“添加Namespace”,共包括两项:关联公共Namespace和创建Namespace,这里选择“创建Namespace”
-
* 将修改和发布权限都授权给张三
@@ -731,7 +731,7 @@ Namespace作为配置的分类,可当成一个配置文件。
进入项目首页,点击左下脚的“添加Namespace”,共包括两项:关联公共Namespace和创建Namespace,这里选择“创建Namespace”
- +
+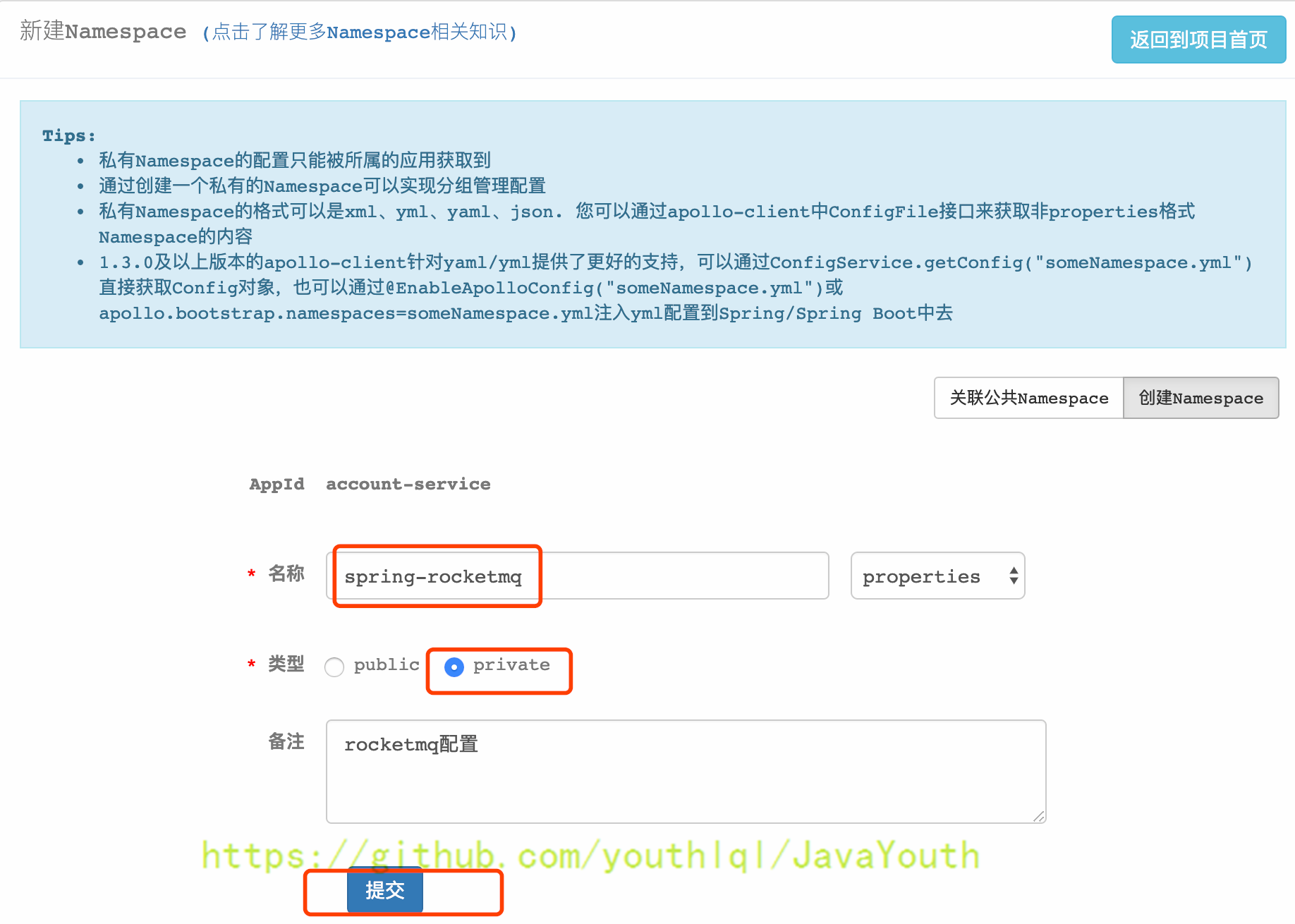 2. 添加配置项
@@ -758,11 +758,11 @@ Namespace作为配置的分类,可当成一个配置文件。
进入common-template项目管理页面:[http://localhost:8070/config.html?#/appid=common-template](http://localhost:8070/config.html?#/appid=common-template)
-
2. 添加配置项
@@ -758,11 +758,11 @@ Namespace作为配置的分类,可当成一个配置文件。
进入common-template项目管理页面:[http://localhost:8070/config.html?#/appid=common-template](http://localhost:8070/config.html?#/appid=common-template)
- +
+ -
- +
+ 1. 添加配置项并发布
@@ -786,11 +786,11 @@ Namespace作为配置的分类,可当成一个配置文件。
2. 点击左侧的添加Namespace
3. 添加Namespace
-
1. 添加配置项并发布
@@ -786,11 +786,11 @@ Namespace作为配置的分类,可当成一个配置文件。
2. 点击左侧的添加Namespace
3. 添加Namespace
- +
+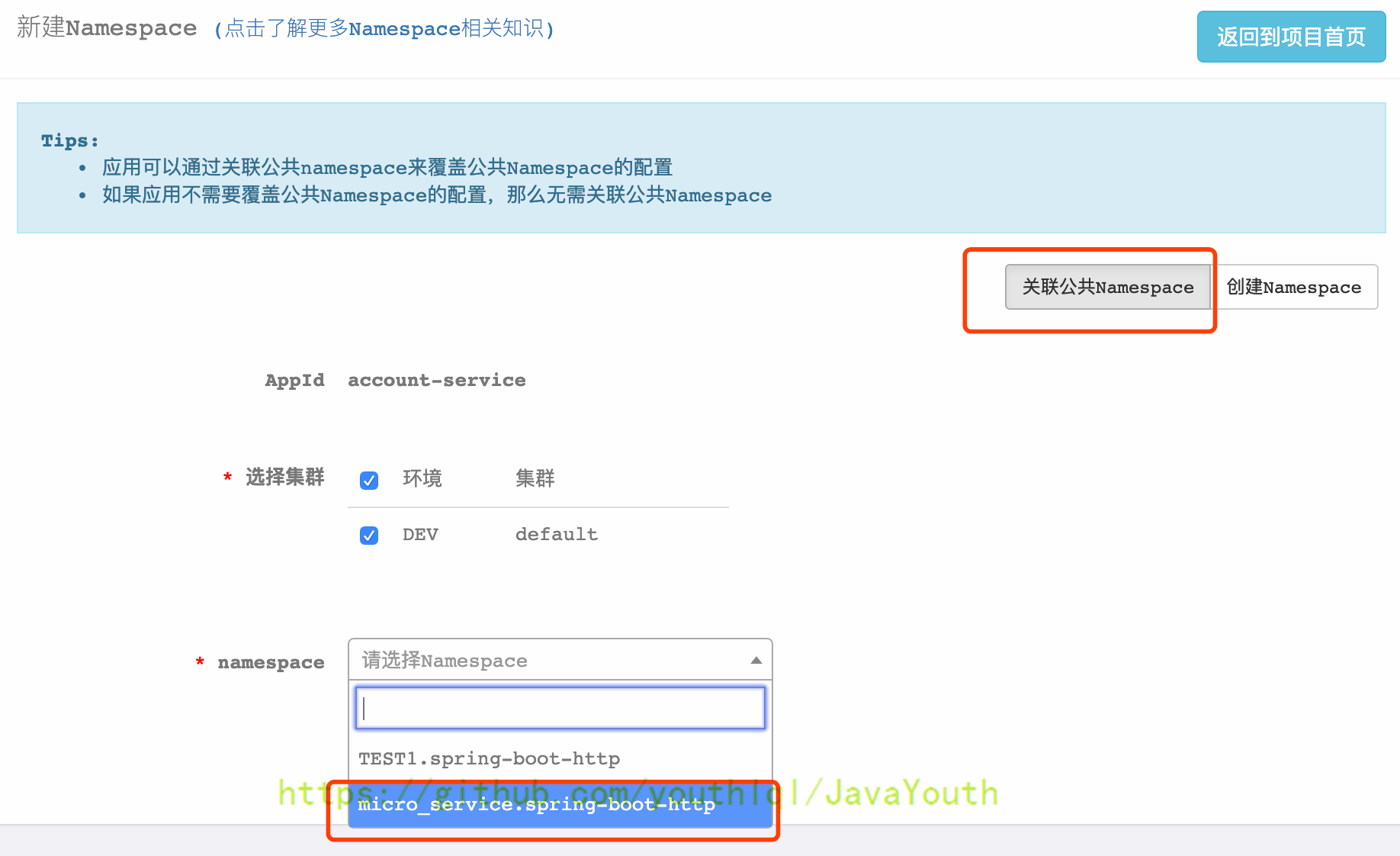 4. 根据需求可以覆盖引入公共Namespace中的配置,下面以覆盖server.servlet.context-path为例
-
4. 根据需求可以覆盖引入公共Namespace中的配置,下面以覆盖server.servlet.context-path为例
- +
+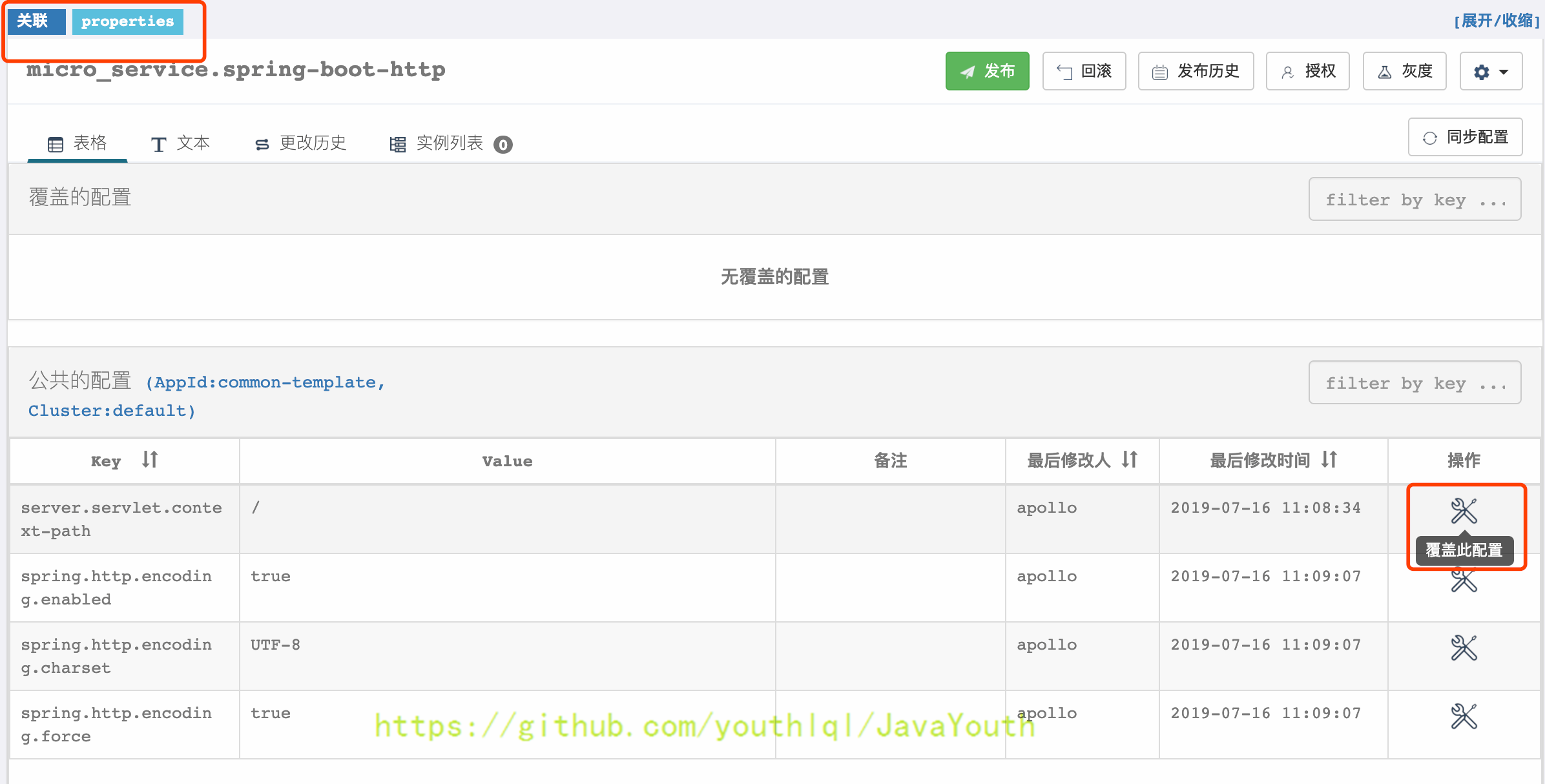 5. 修改server.servlet.context-path为:/account-service
6. 发布修改的配置项
@@ -806,15 +806,15 @@ Namespace作为配置的分类,可当成一个配置文件。
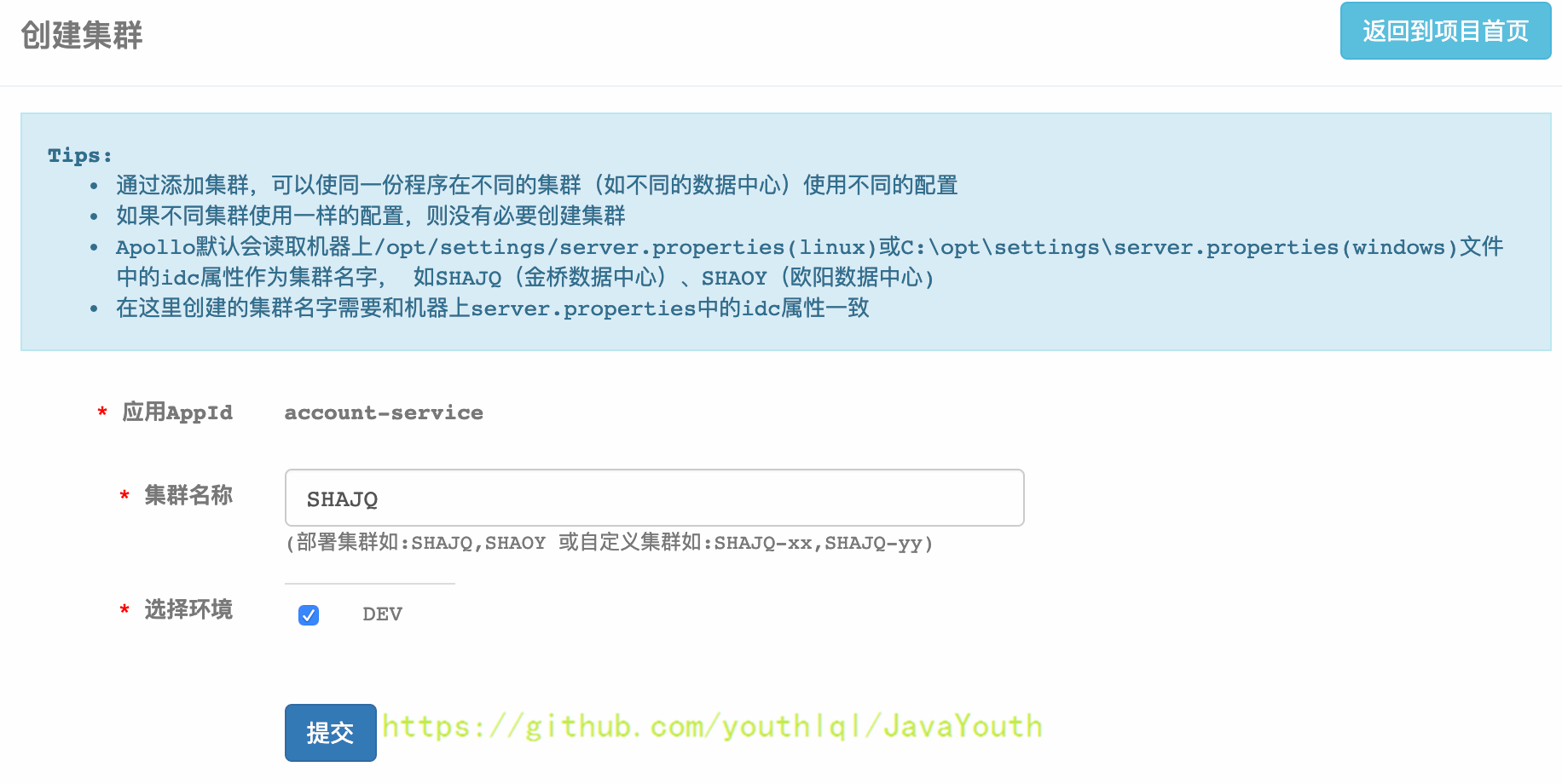
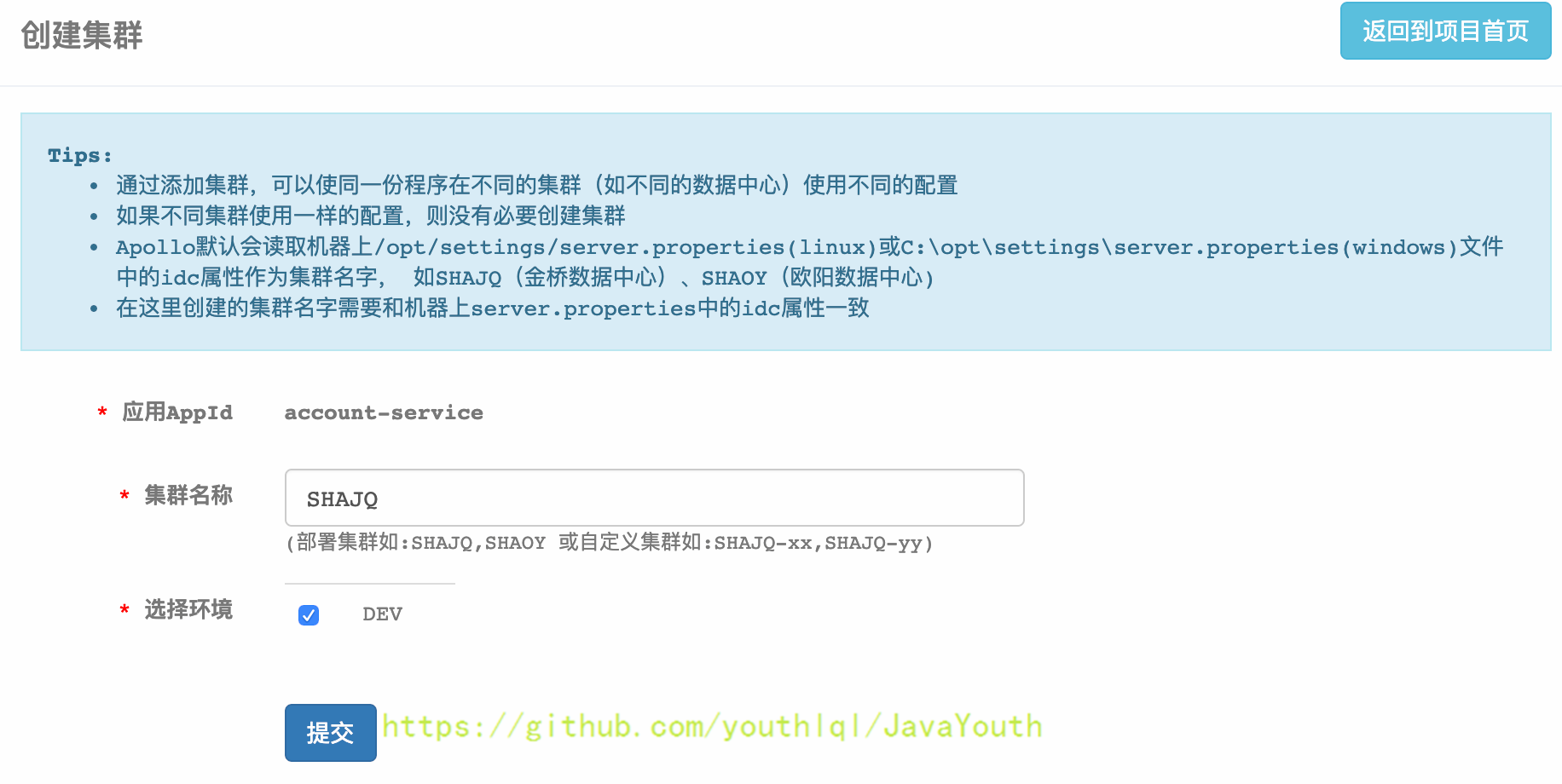
1. 点击页面左侧的“添加集群”按钮
2. 输入集群名称SHAJQ,选择环境并提交:添加上海金桥数据中心为例
-
5. 修改server.servlet.context-path为:/account-service
6. 发布修改的配置项
@@ -806,15 +806,15 @@ Namespace作为配置的分类,可当成一个配置文件。
1. 点击页面左侧的“添加集群”按钮
2. 输入集群名称SHAJQ,选择环境并提交:添加上海金桥数据中心为例
- +
+ -
+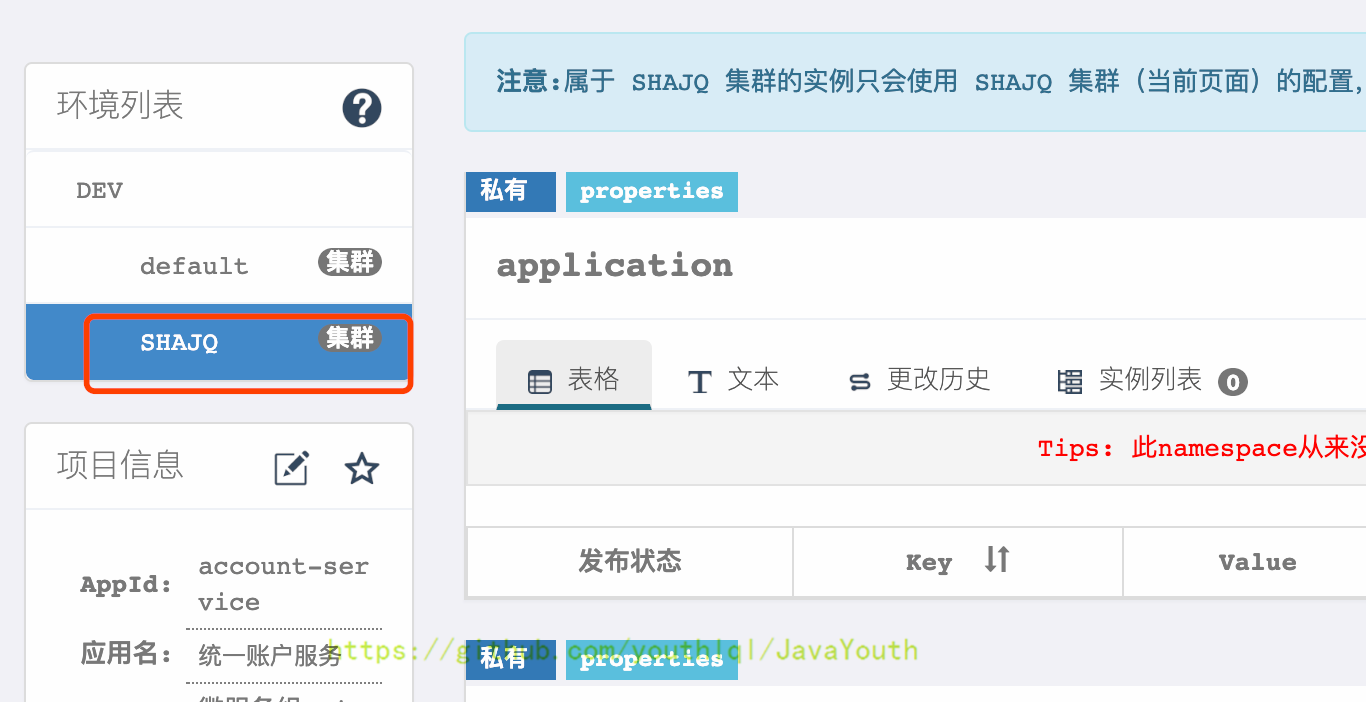
3. 切换到对应的集群,修改配置并发布即可
-
-
+
3. 切换到对应的集群,修改配置并发布即可
- +
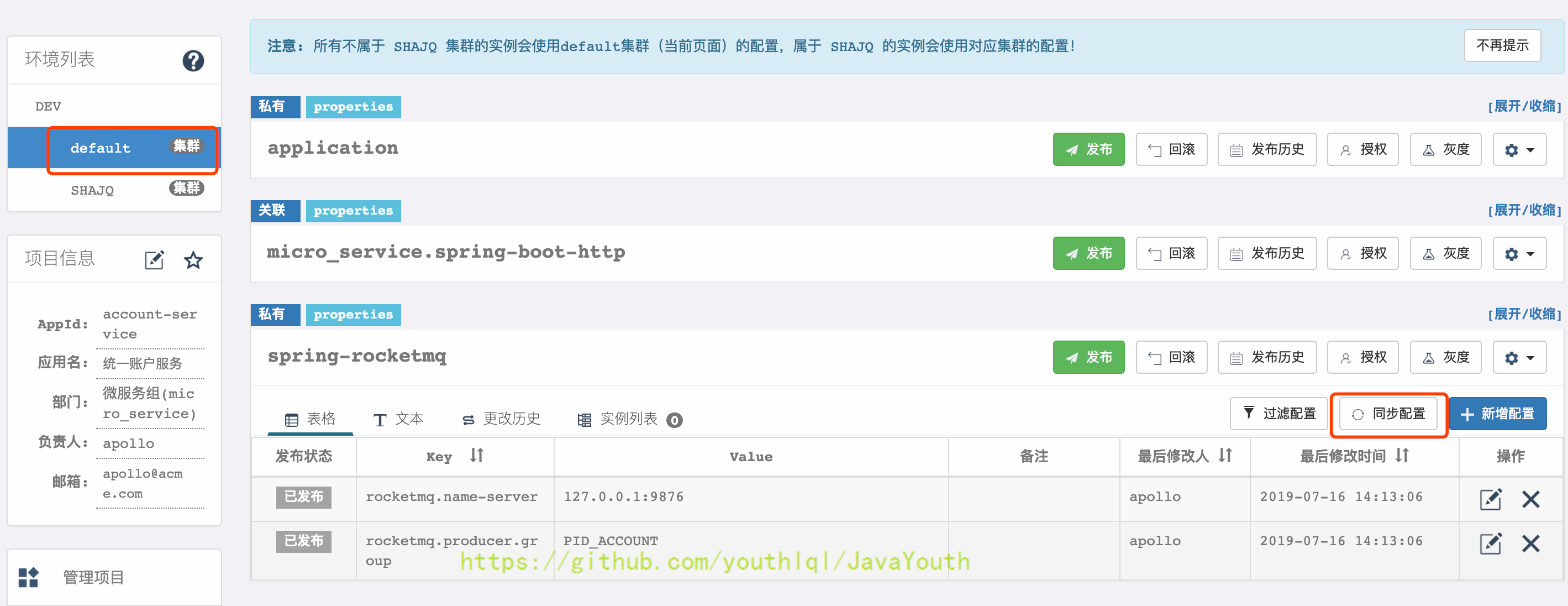
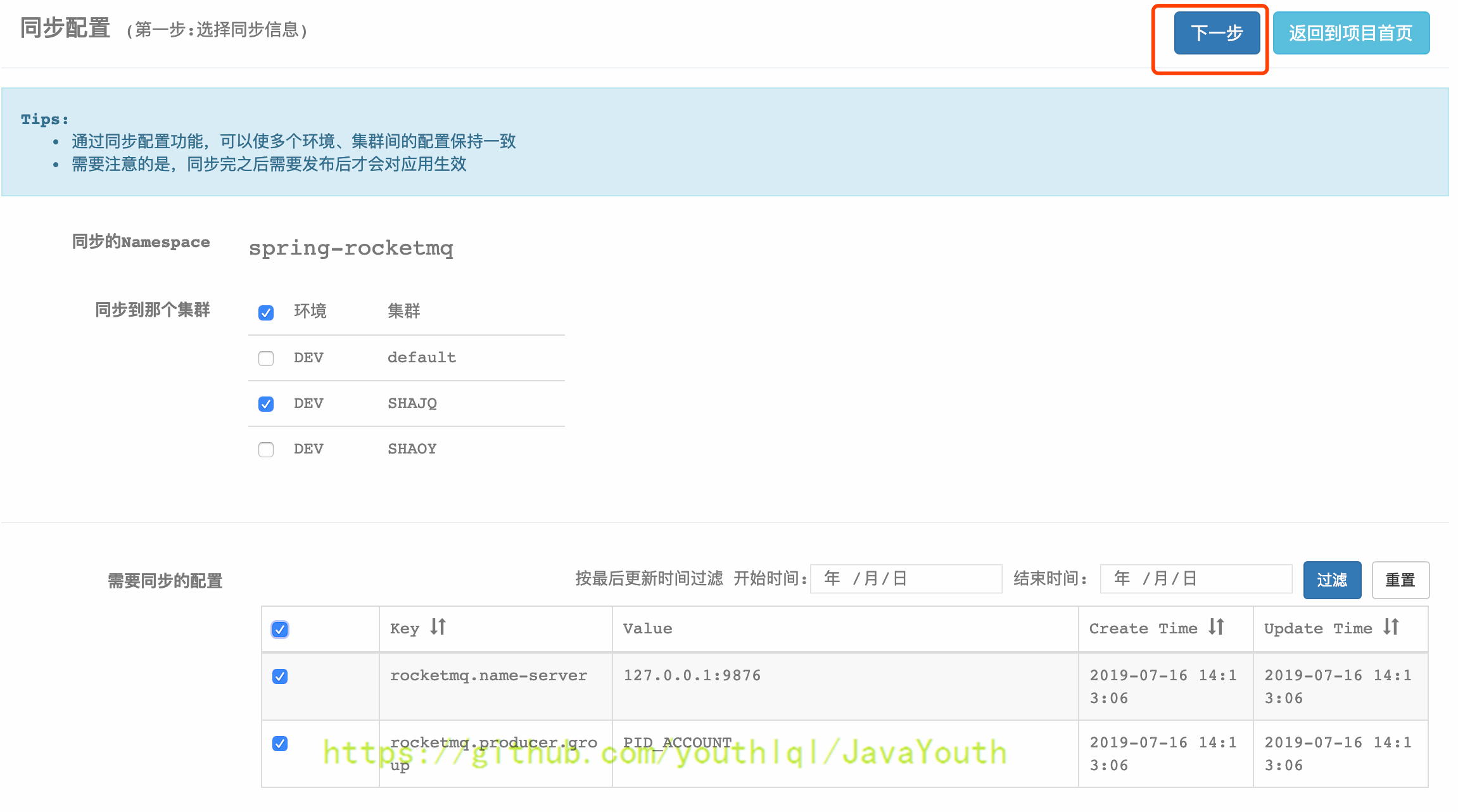
+ #### 同步集群配置
@@ -827,19 +827,19 @@ Namespace作为配置的分类,可当成一个配置文件。
* 展开要同步的Namespace,点击同步配置
-
#### 同步集群配置
@@ -827,19 +827,19 @@ Namespace作为配置的分类,可当成一个配置文件。
* 展开要同步的Namespace,点击同步配置
-  +
+  - 
+ 
* 选择同步到的新集群,再选择要同步的配置
-
- 
+ 
* 选择同步到的新集群,再选择要同步的配置
-  +
+ 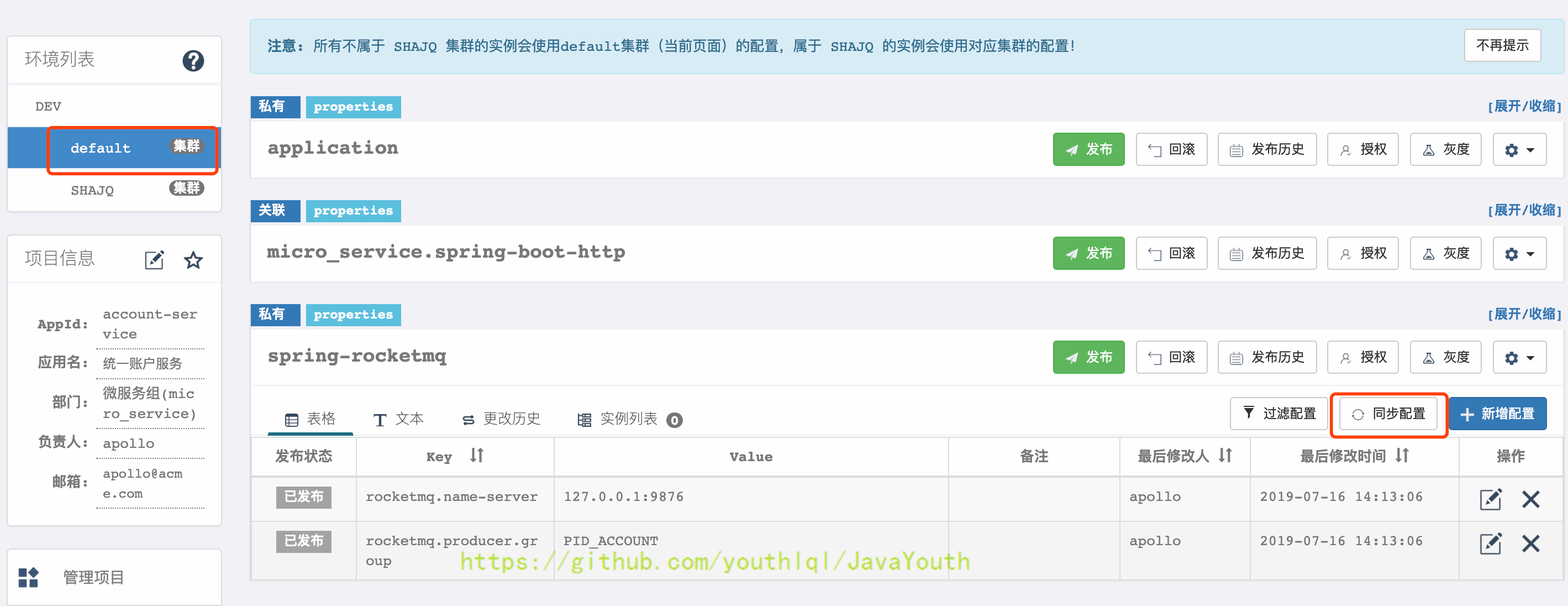 * 同步完成后,切换到SHAJQ集群,发布配置
-
* 同步完成后,切换到SHAJQ集群,发布配置
-  +
+ 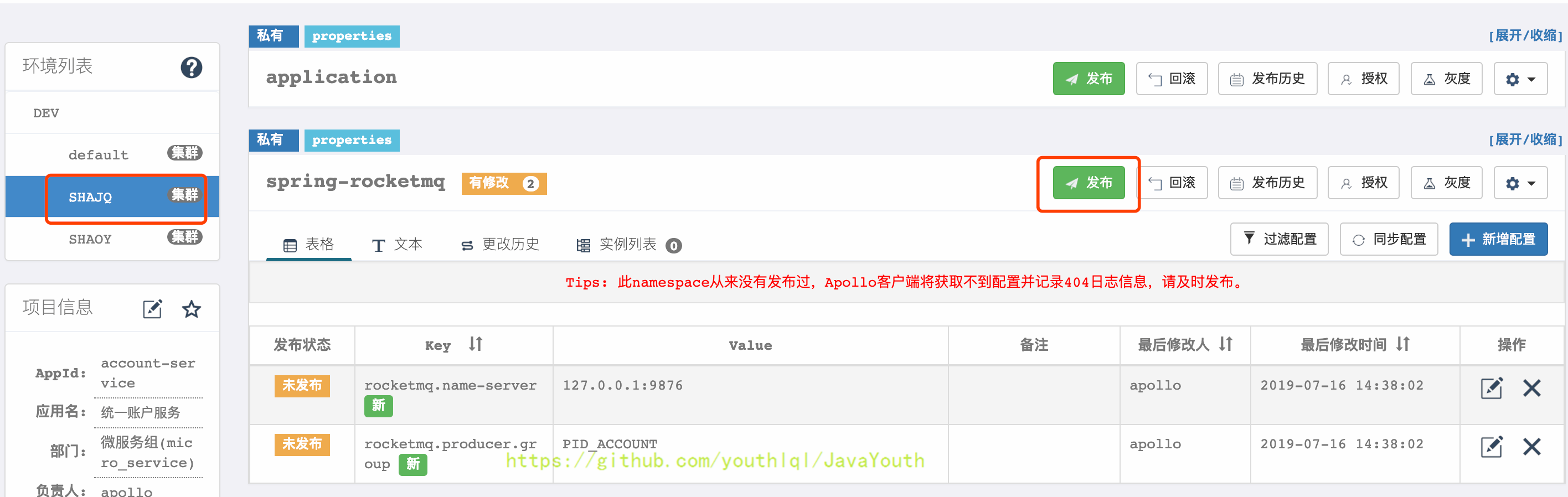 #### 读取配置
@@ -863,7 +863,7 @@ Namespace作为配置的分类,可当成一个配置文件。
在配置中心中,一个重要的功能就是配置发布后实时推送到客户端。下面我们简要看一下这块是怎么设计实现的。
-
#### 读取配置
@@ -863,7 +863,7 @@ Namespace作为配置的分类,可当成一个配置文件。
在配置中心中,一个重要的功能就是配置发布后实时推送到客户端。下面我们简要看一下这块是怎么设计实现的。
- +
+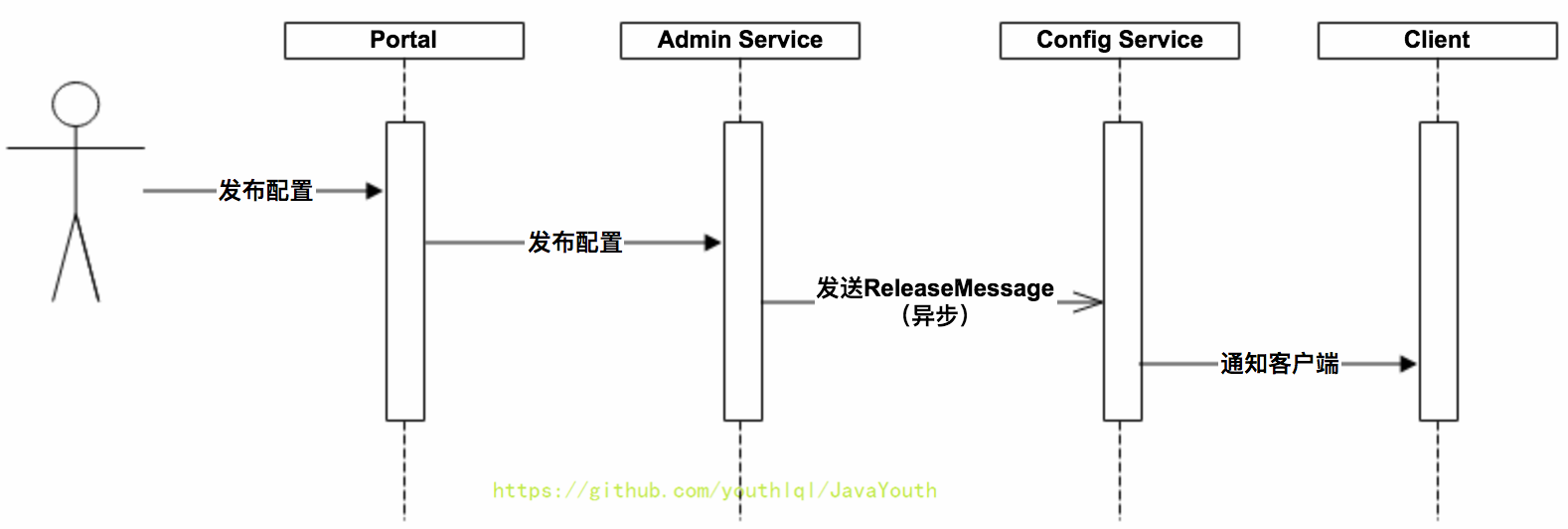 上图简要描述了配置发布的主要过程:
@@ -890,7 +890,7 @@ Admin Service在配置发布后,需要通知所有的Config Service有配置
SELECT * FROM ApolloConfigDB.ReleaseMessage
```
-
上图简要描述了配置发布的主要过程:
@@ -890,7 +890,7 @@ Admin Service在配置发布后,需要通知所有的Config Service有配置
SELECT * FROM ApolloConfigDB.ReleaseMessage
```
- +
+ @@ -1012,7 +1012,7 @@ Admin Service在配置发布后,需要通知所有的Config Service有配置
4. NotificationControllerV2得到配置发布的AppId+Cluster+Namespace后,会通知对应的客户端
-
@@ -1012,7 +1012,7 @@ Admin Service在配置发布后,需要通知所有的Config Service有配置
4. NotificationControllerV2得到配置发布的AppId+Cluster+Namespace后,会通知对应的客户端
- +
+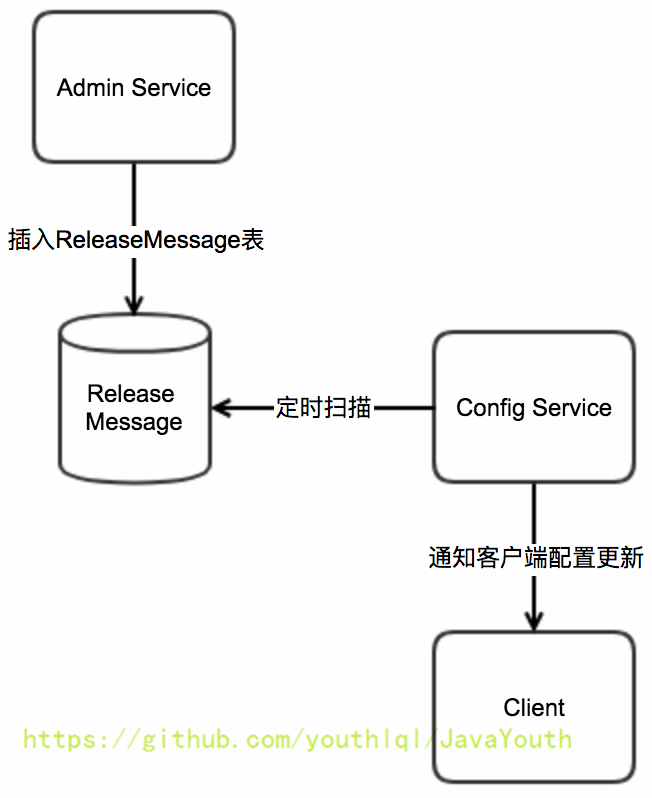 #### Config Service通知客户端
@@ -1268,7 +1268,7 @@ Apollo客户端会把从服务端获取到的配置在本地文件系统缓存
-Denv=DEV -Dapollo.cacheDir=/opt/data/apollo-config -Dapollo.cluster=DEFAULTbash
```
-
#### Config Service通知客户端
@@ -1268,7 +1268,7 @@ Apollo客户端会把从服务端获取到的配置在本地文件系统缓存
-Denv=DEV -Dapollo.cacheDir=/opt/data/apollo-config -Dapollo.cluster=DEFAULTbash
```
- +
+ @@ -1366,11 +1366,11 @@ public class AccountApplication {
2. spring-http命名空间在之前已通过关联公共命名空间添加好了,现在来添加spring-boot-druid命名空间
-
@@ -1366,11 +1366,11 @@ public class AccountApplication {
2. spring-http命名空间在之前已通过关联公共命名空间添加好了,现在来添加spring-boot-druid命名空间
- +
+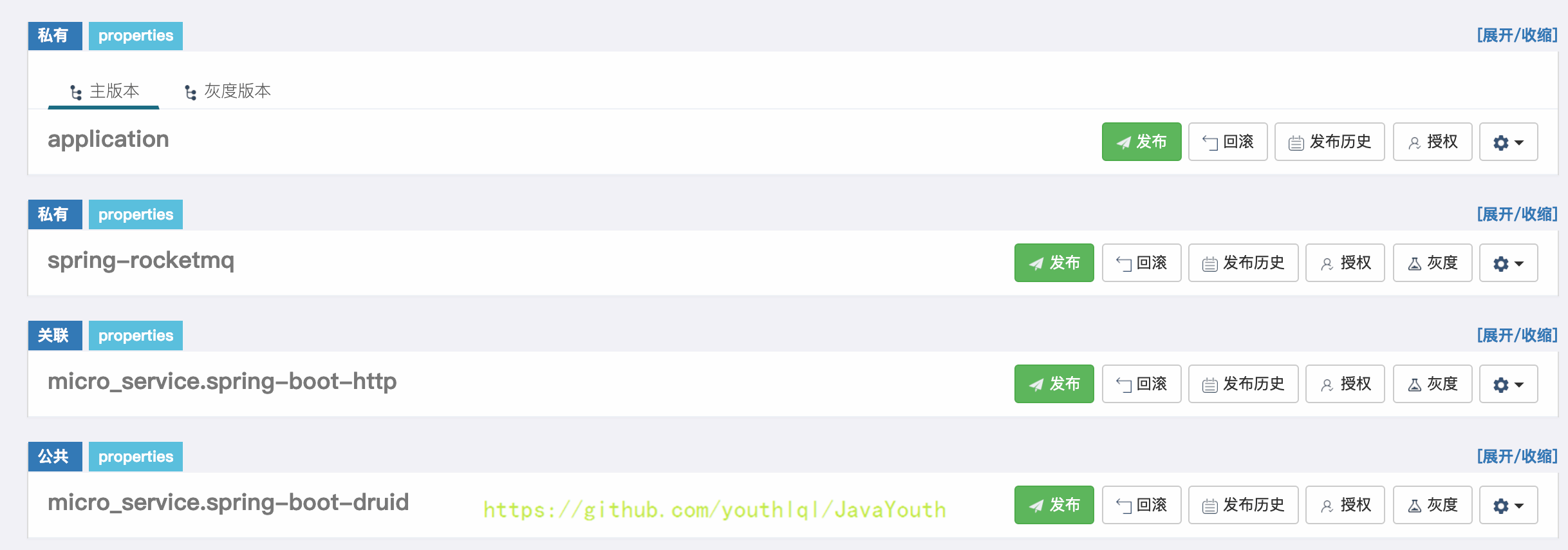 3. 添加本地文件中的配置到对应的命名空间,然后发布配置
-
3. 添加本地文件中的配置到对应的命名空间,然后发布配置
- +
+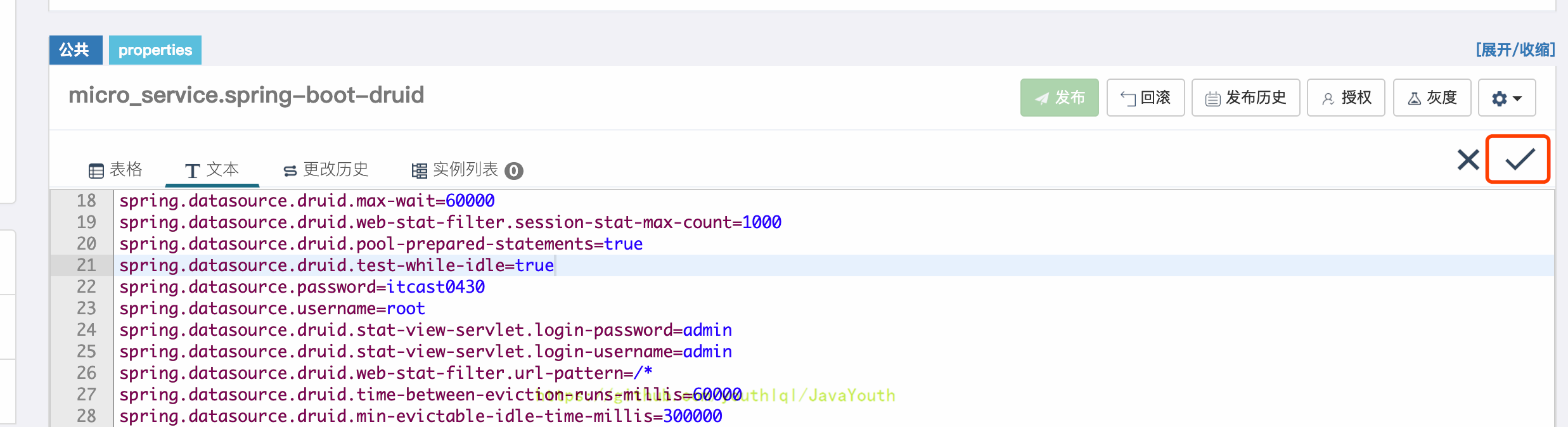 4. 在account-service/src/main/resources/application.properties中配置apollo.bootstrap.namespaces需要引入的命名空间(上面写过)
@@ -1458,7 +1458,7 @@ public class AccountController {
* 访问[http://127.0.0.1:63000/account-service/db-url](http://127.0.0.1:63000/account-service/db-url),显示结果
-
4. 在account-service/src/main/resources/application.properties中配置apollo.bootstrap.namespaces需要引入的命名空间(上面写过)
@@ -1458,7 +1458,7 @@ public class AccountController {
* 访问[http://127.0.0.1:63000/account-service/db-url](http://127.0.0.1:63000/account-service/db-url),显示结果
- +
+ #### 创建其它项目
@@ -1474,7 +1474,7 @@ public class AccountController {
具体如下图所示:
-
#### 创建其它项目
@@ -1474,7 +1474,7 @@ public class AccountController {
具体如下图所示:
- +
+ 下面以添加生产环境部署为例
@@ -1523,7 +1523,7 @@ UPDATE ServerConfig SET `Value` = "http://localhost:8081/eureka/" WHERE `key` =
服务配置项统一存储在ApolloPortalDB.ServerConfig表中,可以通过`管理员工具 - 系统参数`页面进行配置:apollo.portal.envs - 可支持的环境列表
-
下面以添加生产环境部署为例
@@ -1523,7 +1523,7 @@ UPDATE ServerConfig SET `Value` = "http://localhost:8081/eureka/" WHERE `key` =
服务配置项统一存储在ApolloPortalDB.ServerConfig表中,可以通过`管理员工具 - 系统参数`页面进行配置:apollo.portal.envs - 可支持的环境列表
- +
+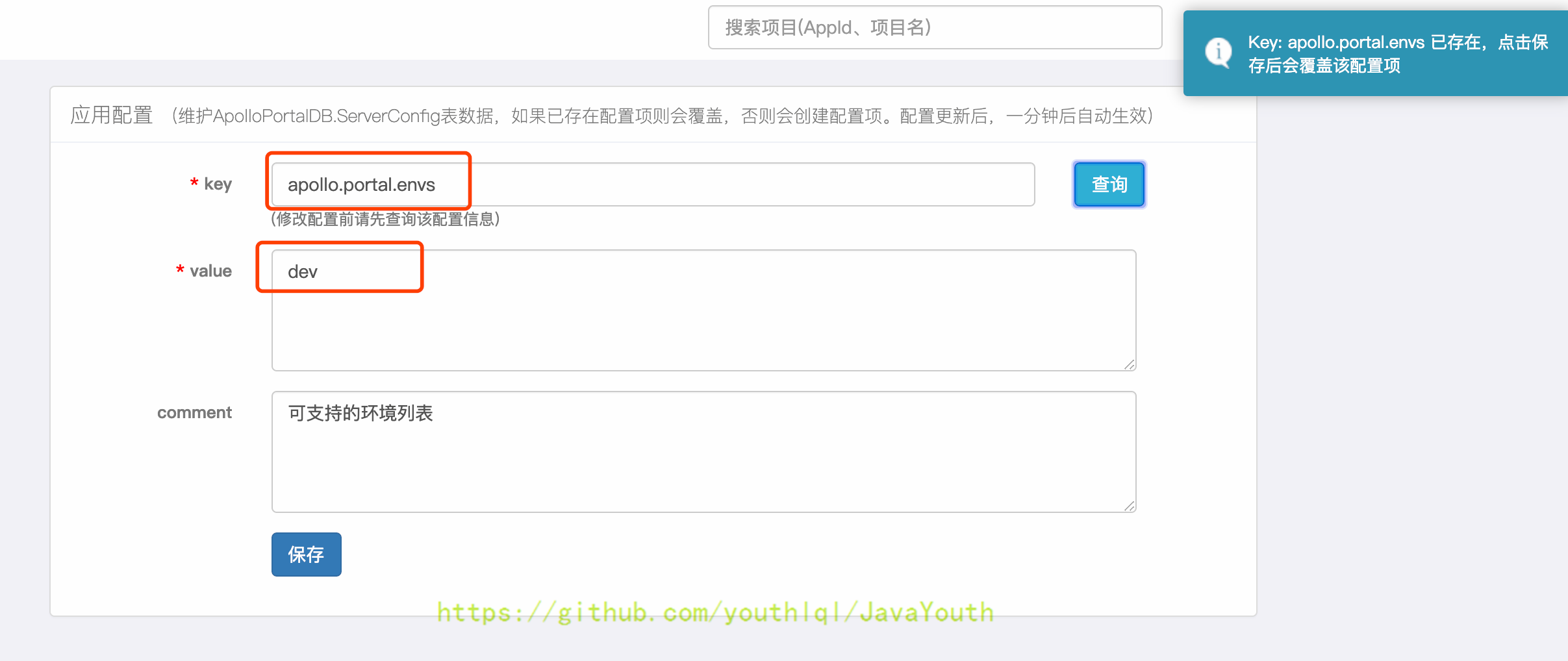 默认值是dev,如果portal需要管理多个环境的话,以逗号分隔即可(大小写不敏感),如:
@@ -1556,7 +1556,7 @@ Apollo Portal需要在不同的环境访问不同的meta service(apollo-configse
1. 启动之后,点击account-service服务配置后会提示环境缺失,此时需要补全上边新增生产环境的配置
-
默认值是dev,如果portal需要管理多个环境的话,以逗号分隔即可(大小写不敏感),如:
@@ -1556,7 +1556,7 @@ Apollo Portal需要在不同的环境访问不同的meta service(apollo-configse
1. 启动之后,点击account-service服务配置后会提示环境缺失,此时需要补全上边新增生产环境的配置
- +
+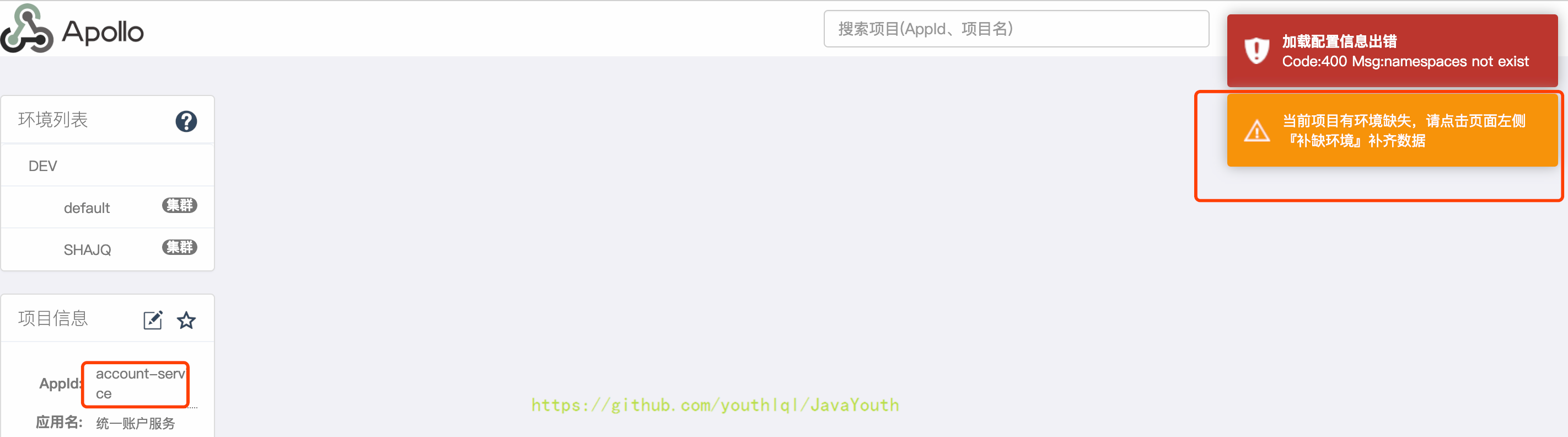 3. 点击左下方的补缺环境
@@ -1564,7 +1564,7 @@ Apollo Portal需要在不同的环境访问不同的meta service(apollo-configse
4. 补缺过生产环境后,切换到PRO环境后会提示有Namespace缺失,点击补缺
-
3. 点击左下方的补缺环境
@@ -1564,7 +1564,7 @@ Apollo Portal需要在不同的环境访问不同的meta service(apollo-configse
4. 补缺过生产环境后,切换到PRO环境后会提示有Namespace缺失,点击补缺
- +
+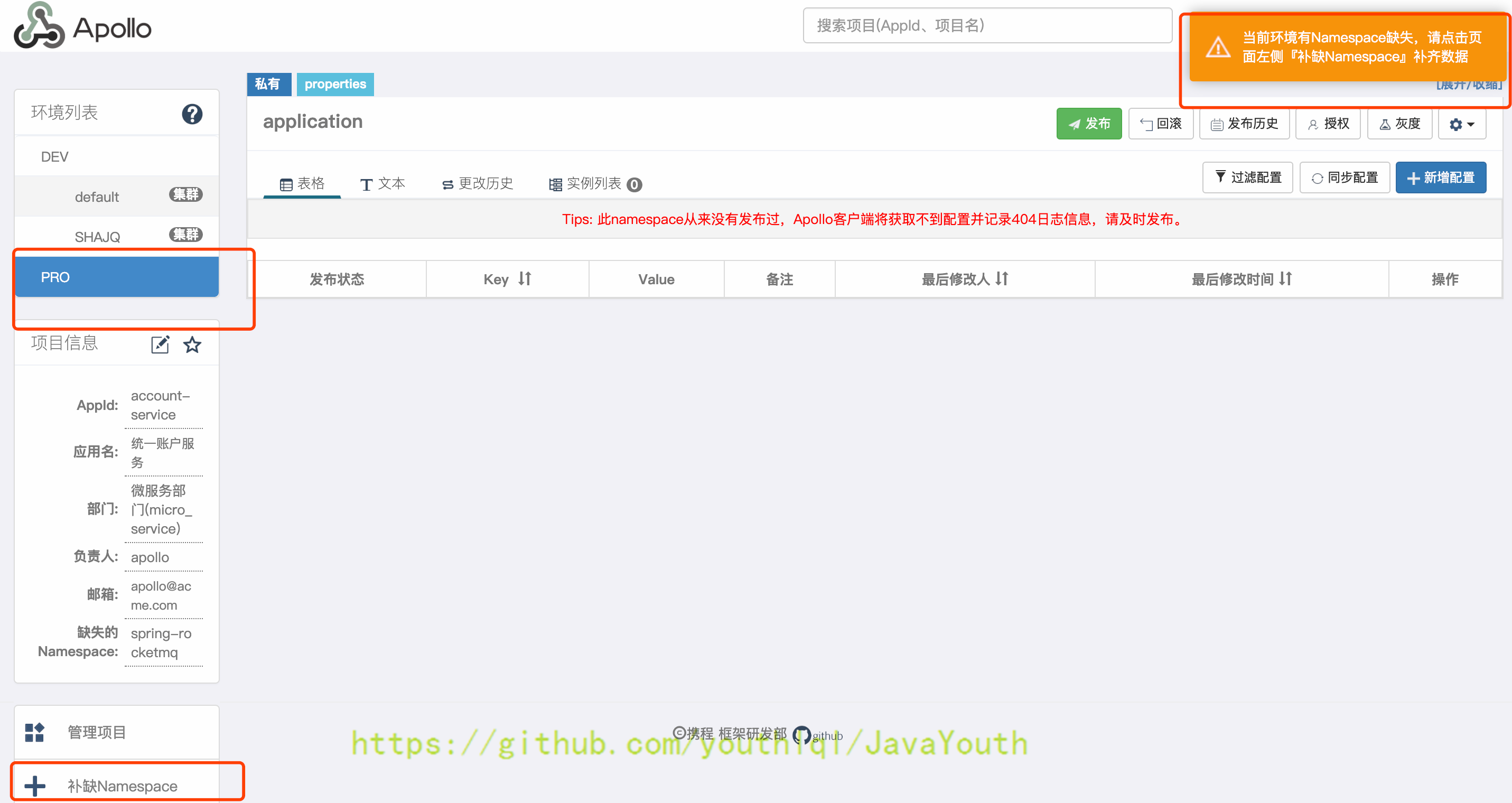 5. 从dev环境同步配置到pro
@@ -1610,7 +1610,7 @@ apollo-quickstart项目有两个客户端:
1. 172.16.0.160
2. 172.16.0.170
-
5. 从dev环境同步配置到pro
@@ -1610,7 +1610,7 @@ apollo-quickstart项目有两个客户端:
1. 172.16.0.160
2. 172.16.0.170
- +
+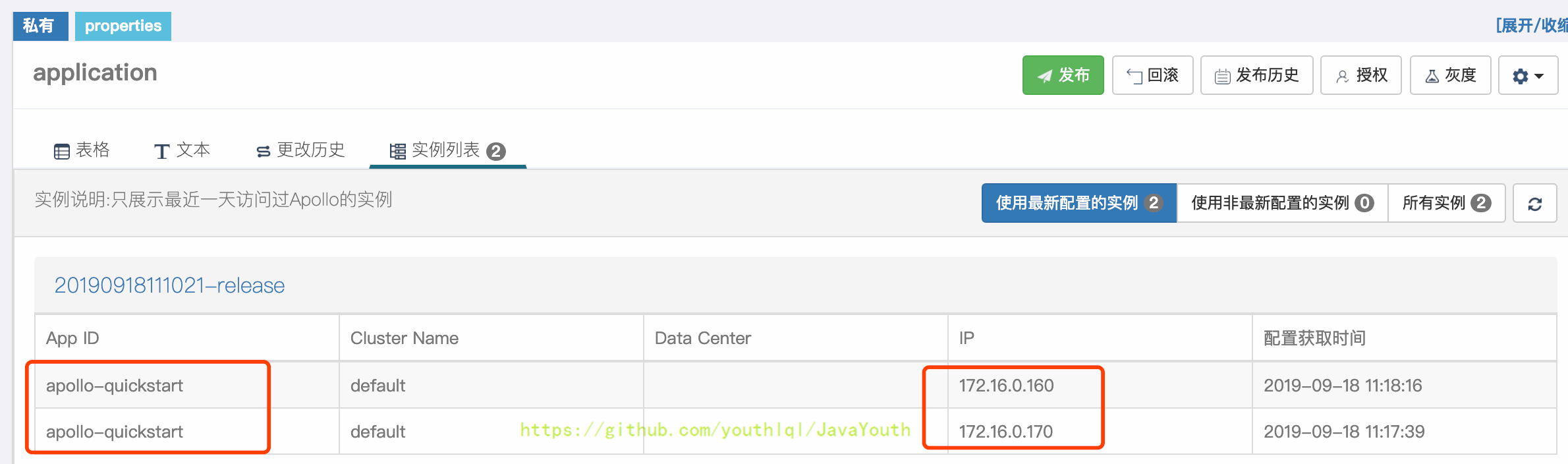 **灰度目标**
@@ -1626,7 +1626,7 @@ apollo-quickstart项目有两个客户端:
2. 点击确定后,灰度版本就创建成功了,页面会自动切换到`灰度版本`Tab
-
**灰度目标**
@@ -1626,7 +1626,7 @@ apollo-quickstart项目有两个客户端:
2. 点击确定后,灰度版本就创建成功了,页面会自动切换到`灰度版本`Tab
- +
+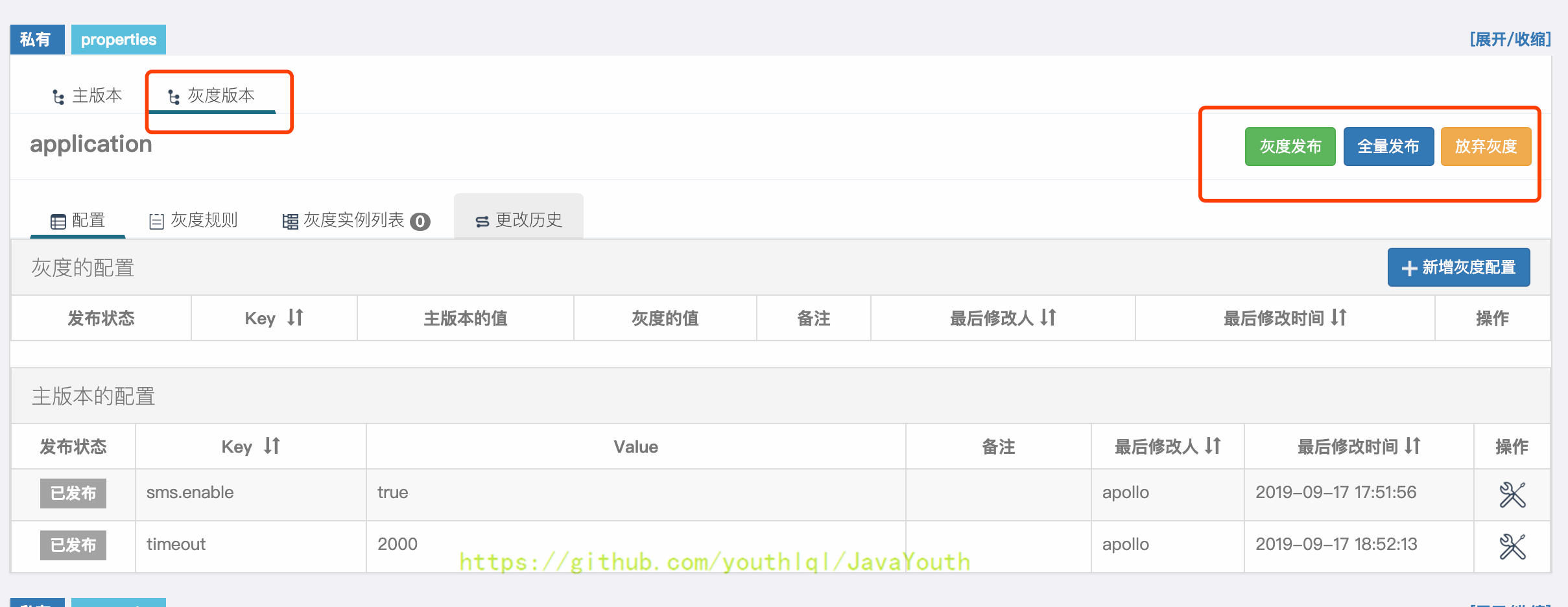 #### 灰度配置
@@ -1634,17 +1634,17 @@ apollo-quickstart项目有两个客户端:
2. 在弹出框中填入要灰度的值:3000,点击提交
-
#### 灰度配置
@@ -1634,17 +1634,17 @@ apollo-quickstart项目有两个客户端:
2. 在弹出框中填入要灰度的值:3000,点击提交
- +
+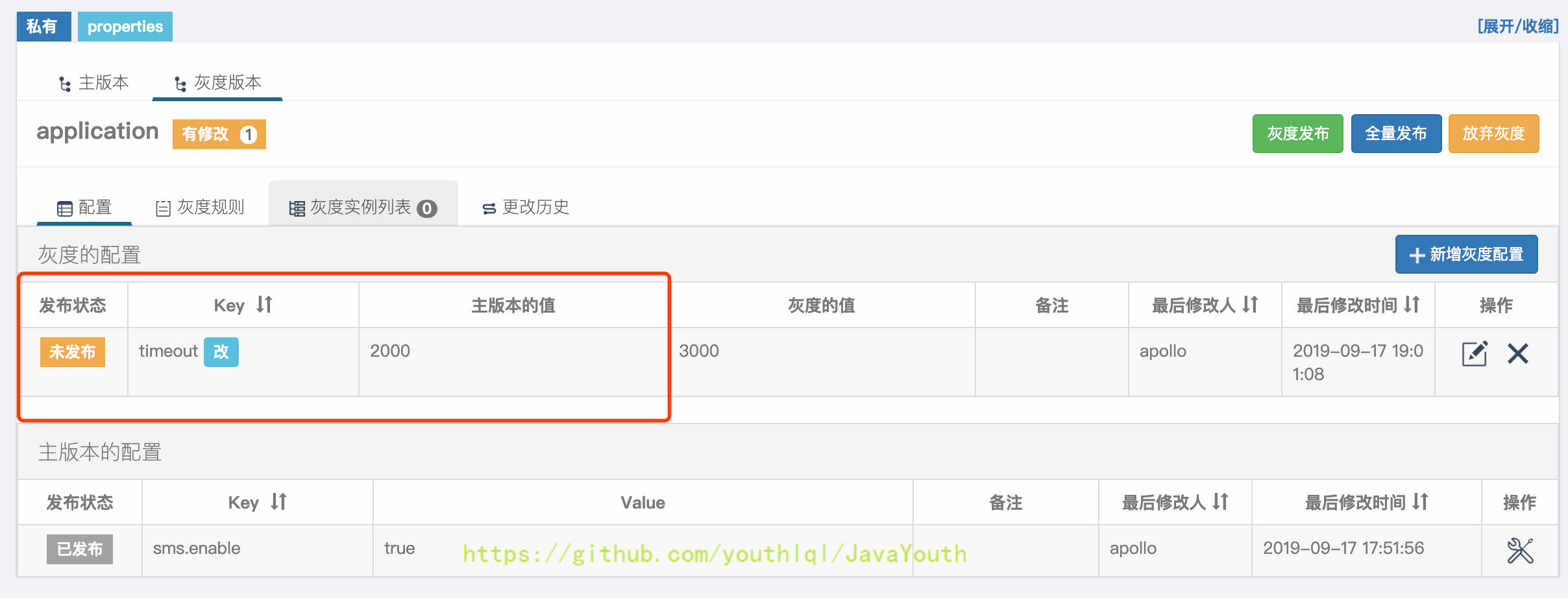 #### 配置灰度规则
1. 切换到`灰度规则`Tab,点击`新增规则`按钮
-
#### 配置灰度规则
1. 切换到`灰度规则`Tab,点击`新增规则`按钮
- +
+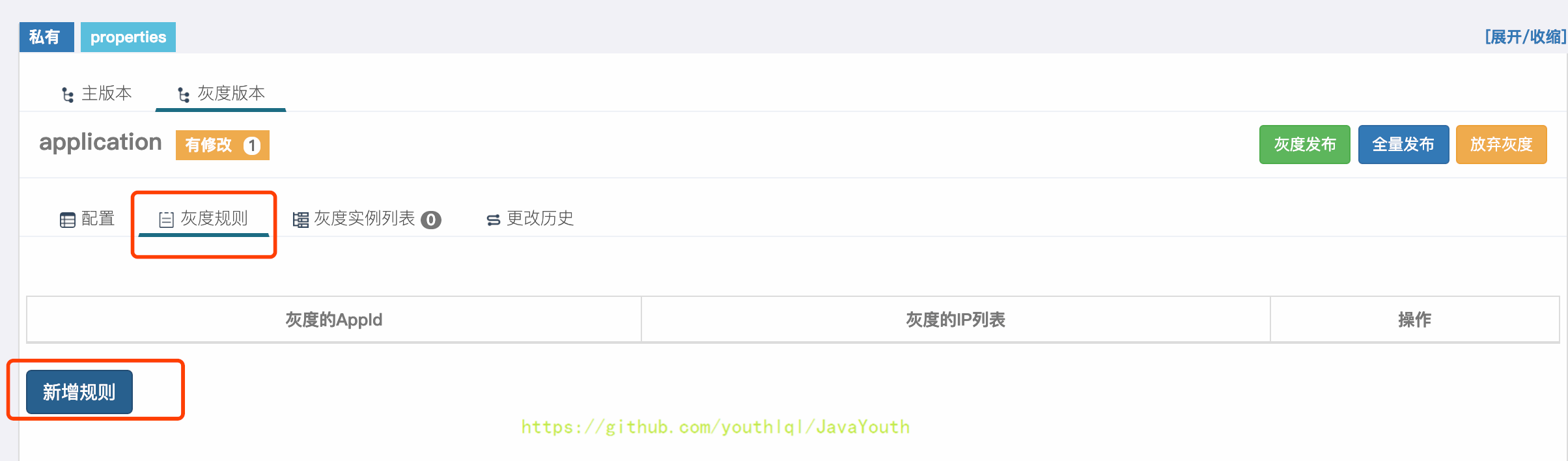 2. 在弹出框中`灰度的IP`下拉框会默认展示当前使用配置的机器列表,选择我们要灰度的IP,点击完成
-
2. 在弹出框中`灰度的IP`下拉框会默认展示当前使用配置的机器列表,选择我们要灰度的IP,点击完成
- +
+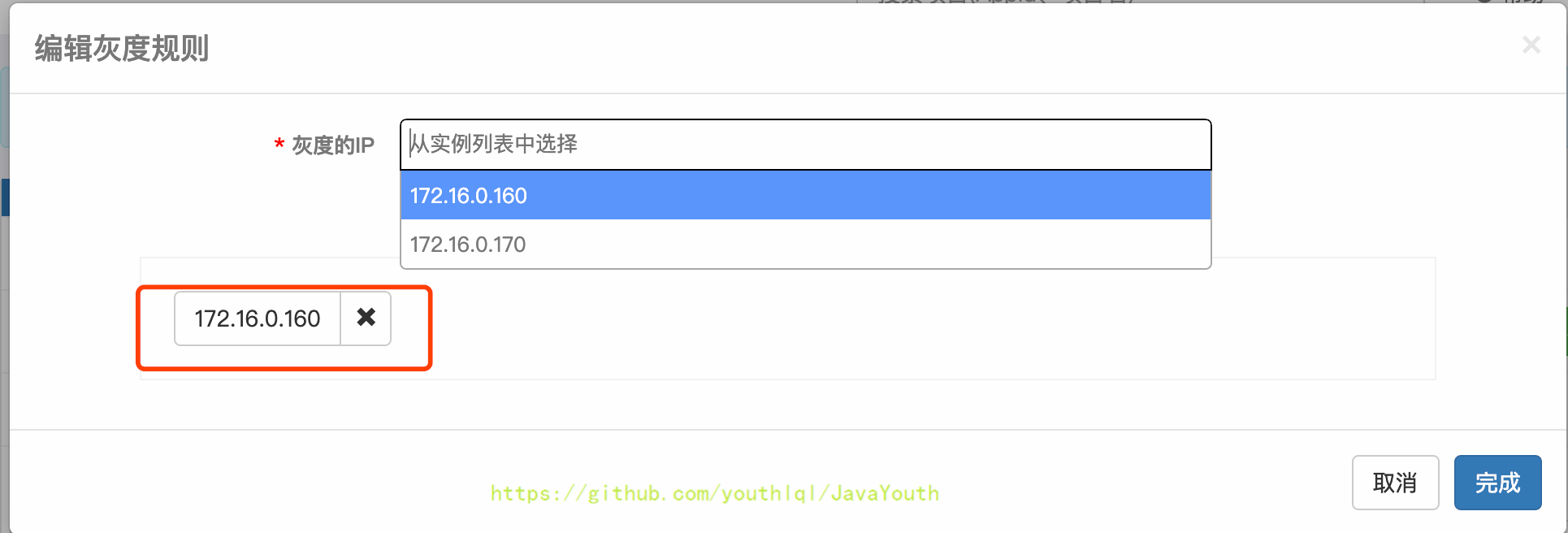 如果下拉框中没找到需要的IP,说明机器还没从Apollo取过配置,可以点击手动输入IP来输入,输入完后点击添加按钮
@@ -1674,11 +1674,11 @@ vm options: `-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:80
}
```
-
如果下拉框中没找到需要的IP,说明机器还没从Apollo取过配置,可以点击手动输入IP来输入,输入完后点击添加按钮
@@ -1674,11 +1674,11 @@ vm options: `-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:80
}
```
- +
+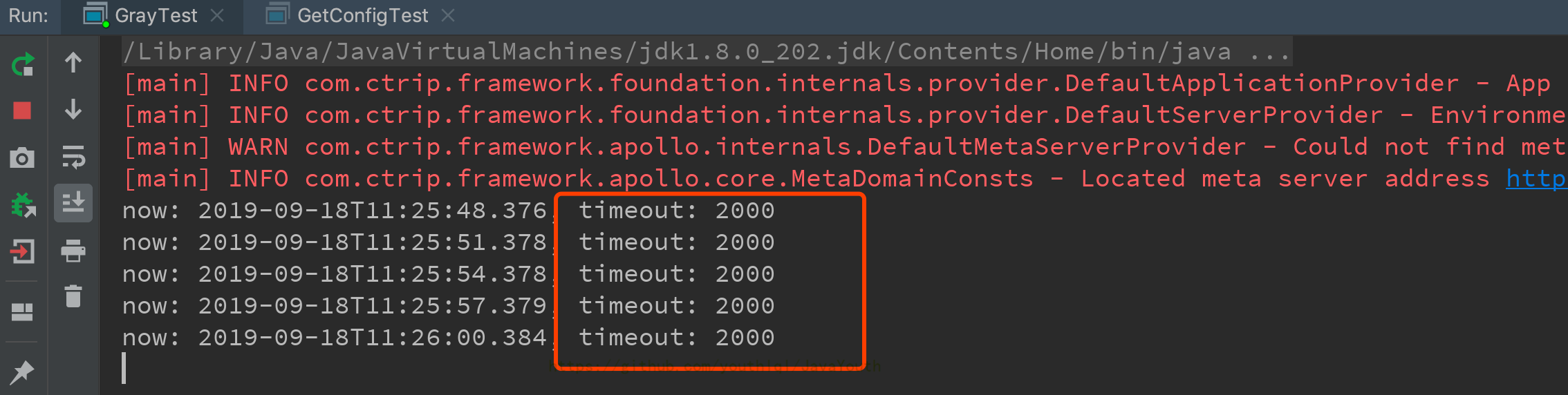 2. 切换到`配置`Tab,再次检查灰度的配置部分,如果没有问题,点击`灰度发布`
-
2. 切换到`配置`Tab,再次检查灰度的配置部分,如果没有问题,点击`灰度发布`
- +
+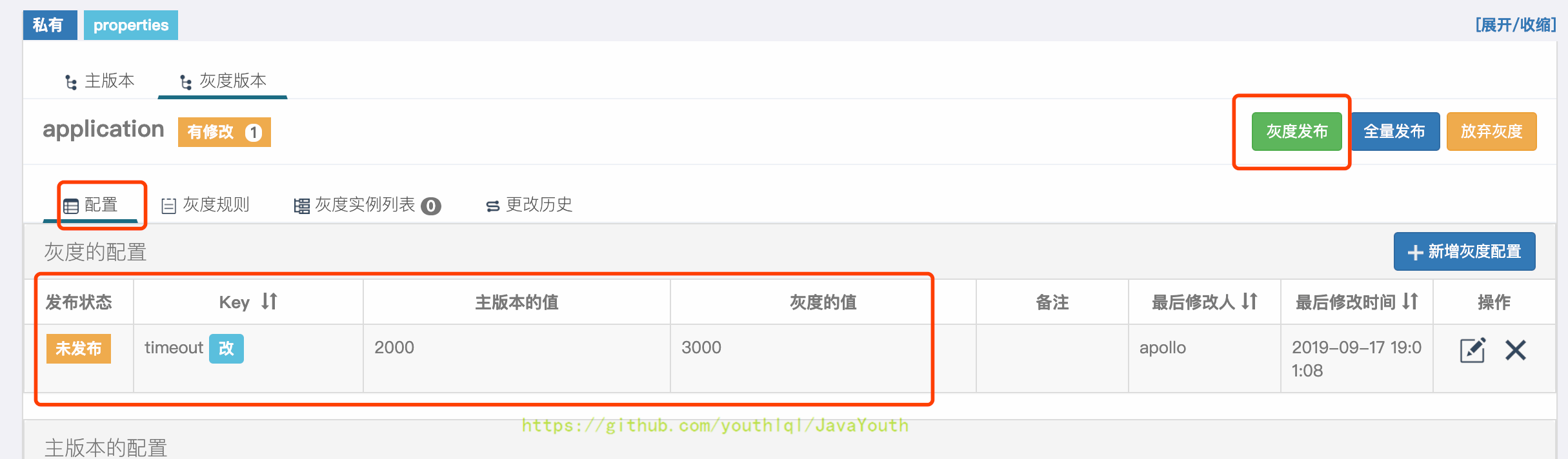 3. 在弹出框中可以看到主版本的值是2000,灰度版本即将发布的值是3000。填入其它信息后,点击发布
@@ -1686,9 +1686,9 @@ vm options: `-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:80
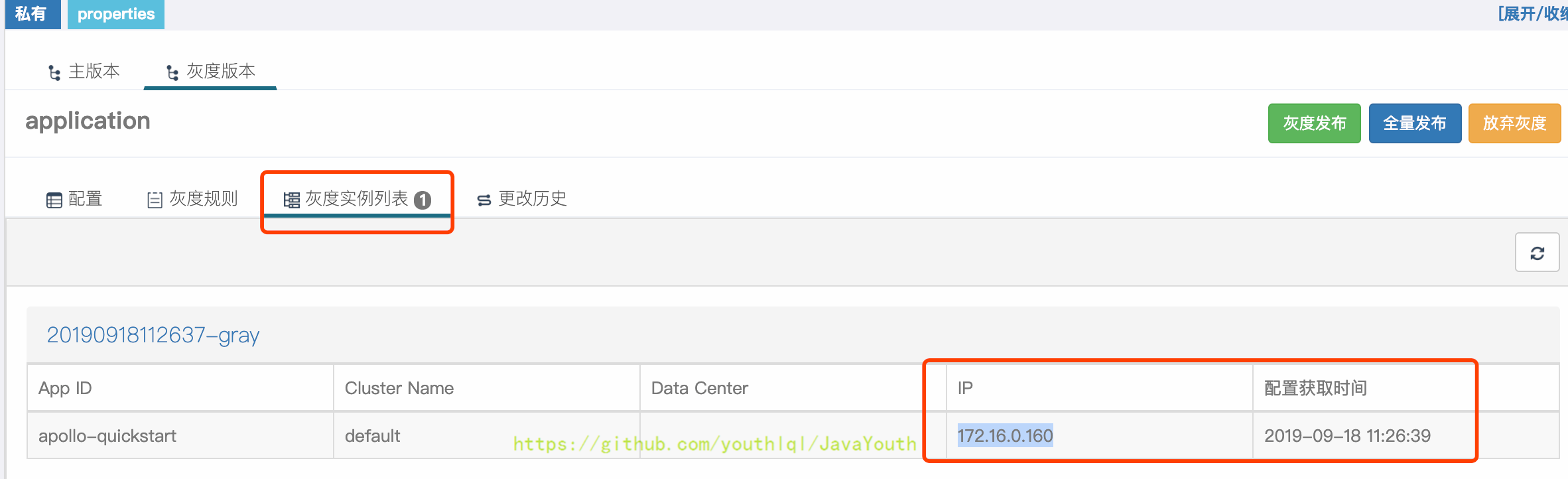
4. 发布后,切换到`灰度实例列表`Tab,就能看到172.16.0.160已经使用了灰度发布的值
-
3. 在弹出框中可以看到主版本的值是2000,灰度版本即将发布的值是3000。填入其它信息后,点击发布
@@ -1686,9 +1686,9 @@ vm options: `-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:80
4. 发布后,切换到`灰度实例列表`Tab,就能看到172.16.0.160已经使用了灰度发布的值
- +
+ -
- +
+ diff --git a/docs/Java/JVM/JVM系列-第12章-垃圾回收器.md b/docs/Java/JVM/JVM系列-第12章-垃圾回收器.md
index 6a8b74c..bedb653 100644
--- a/docs/Java/JVM/JVM系列-第12章-垃圾回收器.md
+++ b/docs/Java/JVM/JVM系列-第12章-垃圾回收器.md
@@ -44,7 +44,7 @@ GC 分类与性能指标
**按线程数分(垃圾回收线程数),可以分为串行垃圾回收器和并行垃圾回收器。**
-
diff --git a/docs/Java/JVM/JVM系列-第12章-垃圾回收器.md b/docs/Java/JVM/JVM系列-第12章-垃圾回收器.md
index 6a8b74c..bedb653 100644
--- a/docs/Java/JVM/JVM系列-第12章-垃圾回收器.md
+++ b/docs/Java/JVM/JVM系列-第12章-垃圾回收器.md
@@ -44,7 +44,7 @@ GC 分类与性能指标
**按线程数分(垃圾回收线程数),可以分为串行垃圾回收器和并行垃圾回收器。**
- +
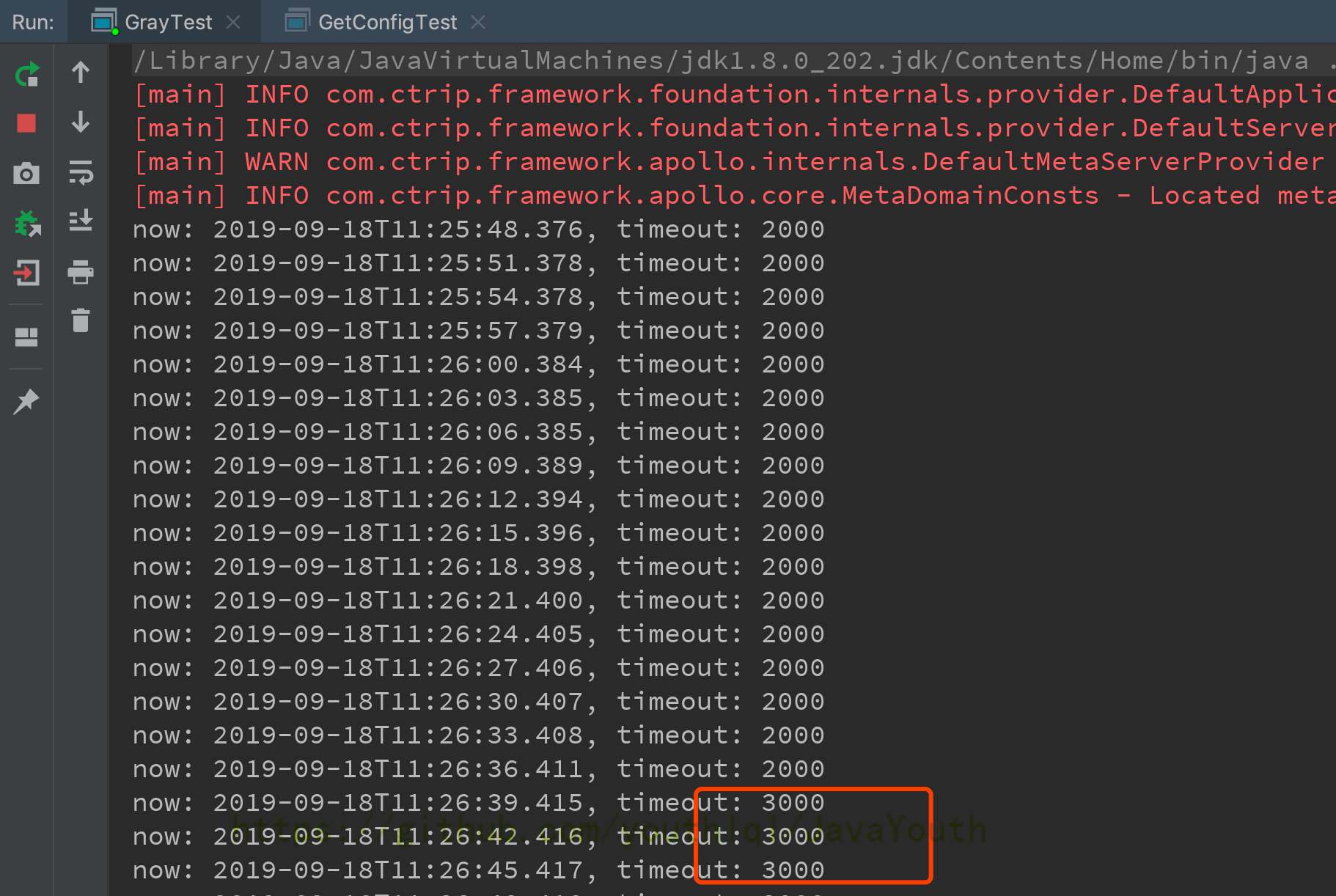
+ 1. 串行回收指的是在同一时间段内只允许有一个CPU用于执行垃圾回收操作,此时工作线程被暂停,直至垃圾收集工作结束。
1. 在诸如单CPU处理器或者较小的应用内存等硬件平台不是特别优越的场合,串行回收器的性能表现可以超过并行回收器和并发回收器。所以,串行回收默认被应用在客户端的Client模式下的JVM中
@@ -60,7 +60,7 @@ GC 分类与性能指标
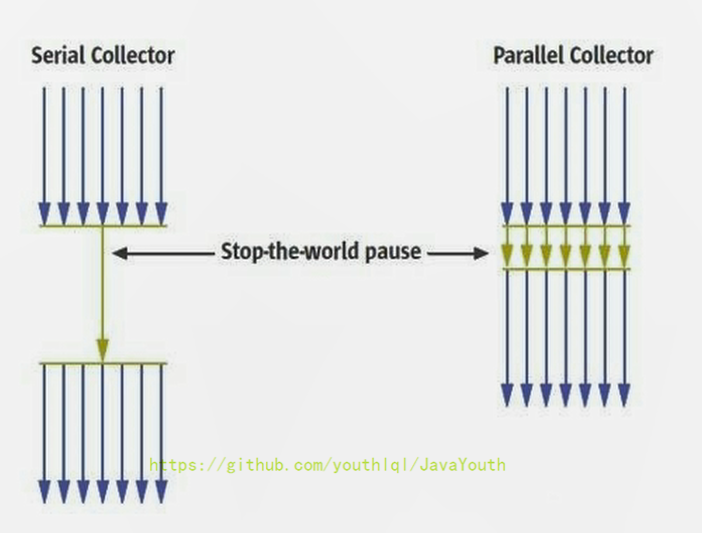
1. 并发式垃圾回收器与应用程序线程交替工作,以尽可能减少应用程序的停顿时间。
2. 独占式垃圾回收器(Stop the World)一旦运行,就停止应用程序中的所有用户线程,直到垃圾回收过程完全结束。
-
1. 串行回收指的是在同一时间段内只允许有一个CPU用于执行垃圾回收操作,此时工作线程被暂停,直至垃圾收集工作结束。
1. 在诸如单CPU处理器或者较小的应用内存等硬件平台不是特别优越的场合,串行回收器的性能表现可以超过并行回收器和并发回收器。所以,串行回收默认被应用在客户端的Client模式下的JVM中
@@ -60,7 +60,7 @@ GC 分类与性能指标
1. 并发式垃圾回收器与应用程序线程交替工作,以尽可能减少应用程序的停顿时间。
2. 独占式垃圾回收器(Stop the World)一旦运行,就停止应用程序中的所有用户线程,直到垃圾回收过程完全结束。
- +
+ @@ -105,7 +105,7 @@ GC 分类与性能指标
2. 这种情况下,应用程序能容忍较高的暂停时间,因此,高吞吐量的应用程序有更长的时间基准,快速响应是不必考虑的
3. 吞吐量优先,意味着在单位时间内,STW的时间最短:0.2+0.2=0.4
-
@@ -105,7 +105,7 @@ GC 分类与性能指标
2. 这种情况下,应用程序能容忍较高的暂停时间,因此,高吞吐量的应用程序有更长的时间基准,快速响应是不必考虑的
3. 吞吐量优先,意味着在单位时间内,STW的时间最短:0.2+0.2=0.4
- +
+ @@ -115,7 +115,7 @@ GC 分类与性能指标
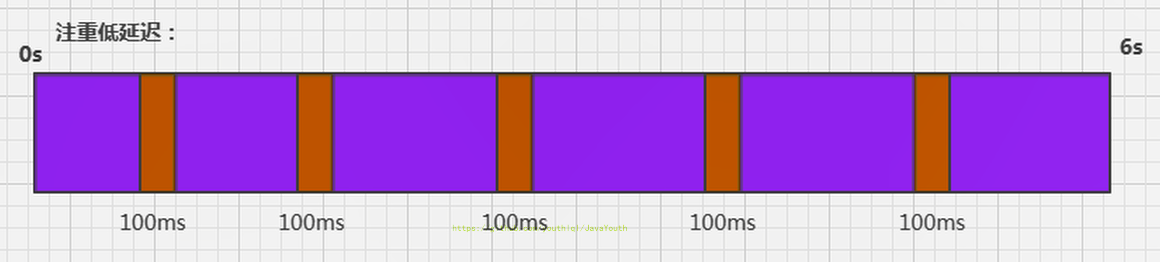
- 例如,GC期间100毫秒的暂停时间意味着在这100毫秒期间内没有应用程序线程是活动的
2. 暂停时间优先,意味着尽可能让单次STW的时间最短:0.1+0.1 + 0.1+ 0.1+ 0.1=0.5,但是总的GC时间可能会长
-
@@ -115,7 +115,7 @@ GC 分类与性能指标
- 例如,GC期间100毫秒的暂停时间意味着在这100毫秒期间内没有应用程序线程是活动的
2. 暂停时间优先,意味着尽可能让单次STW的时间最短:0.1+0.1 + 0.1+ 0.1+ 0.1=0.5,但是总的GC时间可能会长
- +
+ @@ -169,17 +169,17 @@ GC 分类与性能指标
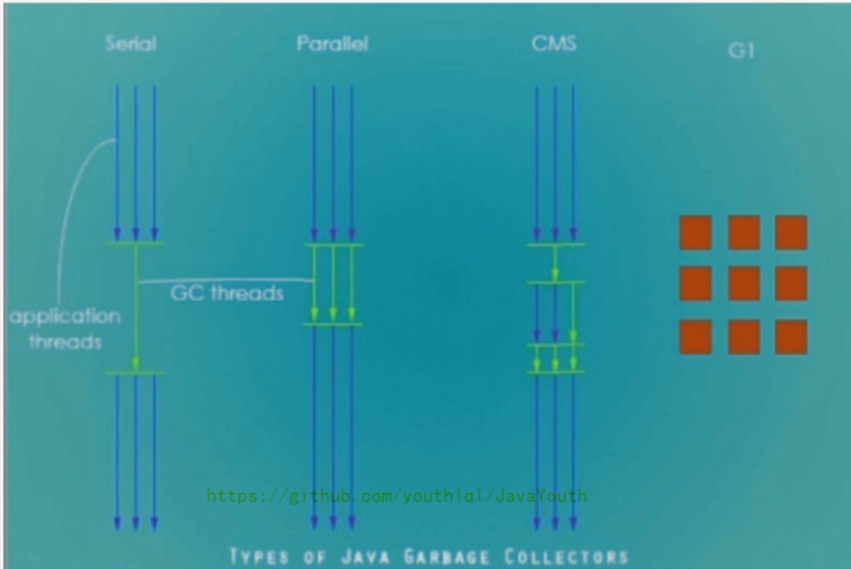
2. 并行回收器:ParNew、Parallel Scavenge、Parallel old
3. 并发回收器:CMS、G1
-
@@ -169,17 +169,17 @@ GC 分类与性能指标
2. 并行回收器:ParNew、Parallel Scavenge、Parallel old
3. 并发回收器:CMS、G1
- +
+ **官方文档**
-
**官方文档**
- +
+ **7款经典回收器与垃圾分代之间的关系**
-
**7款经典回收器与垃圾分代之间的关系**
- +
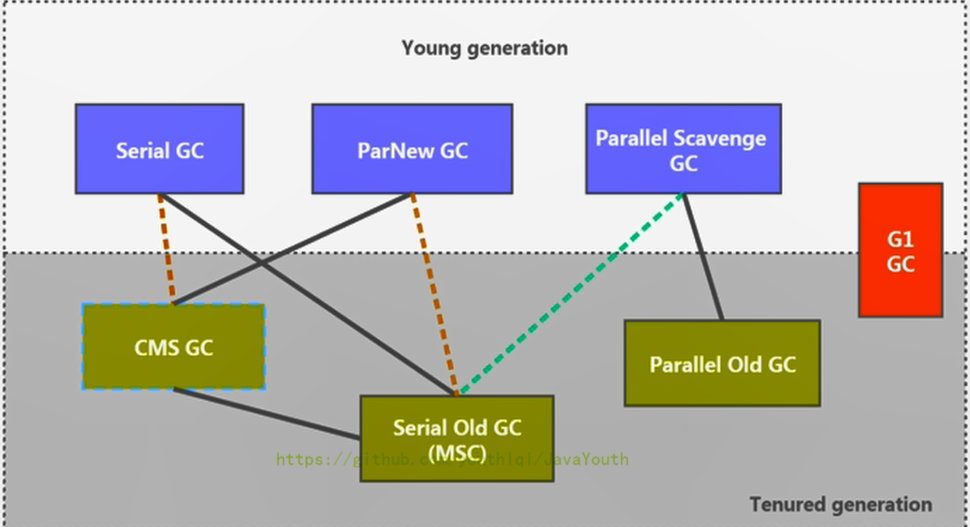
+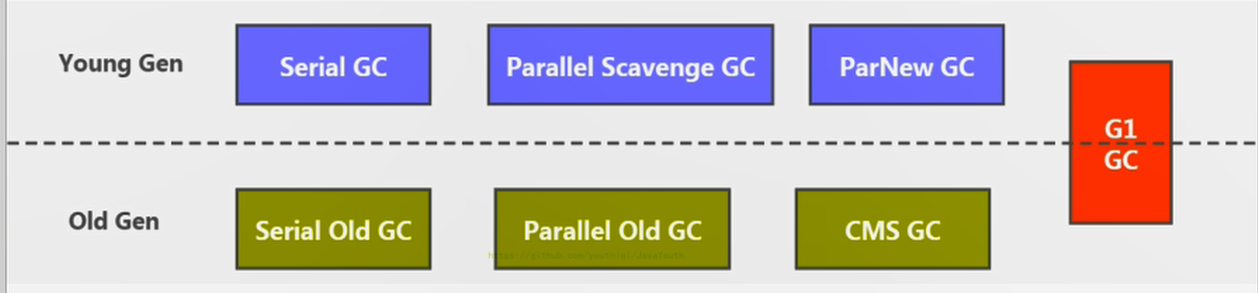 1. 新生代收集器:Serial、ParNew、Parallel Scavenge;
@@ -192,7 +192,7 @@ GC 分类与性能指标
### 垃圾收集器的组合关系
-
1. 新生代收集器:Serial、ParNew、Parallel Scavenge;
@@ -192,7 +192,7 @@ GC 分类与性能指标
### 垃圾收集器的组合关系
- +
+ @@ -251,11 +251,11 @@ jinfo -flag UseParallelOldGC 进程id
JDK 8 中默认使用 ParallelGC 和 ParallelOldGC 的组合
-
@@ -251,11 +251,11 @@ jinfo -flag UseParallelOldGC 进程id
JDK 8 中默认使用 ParallelGC 和 ParallelOldGC 的组合
- +
+ #### JDK9
-
#### JDK9
- +
+ @@ -281,7 +281,7 @@ Serial 回收器:串行回收
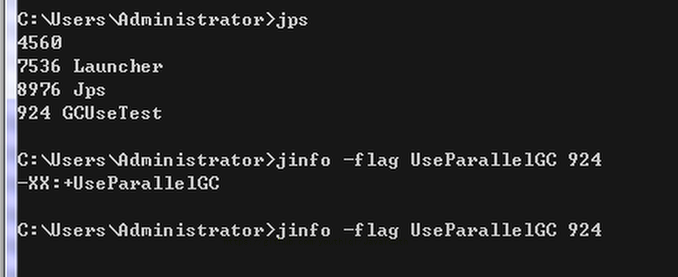
这个收集器是一个单线程的收集器,“单线程”的意义:它只会使用一个CPU(串行)或一条收集线程去完成垃圾收集工作。更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束(Stop The World)
-
@@ -281,7 +281,7 @@ Serial 回收器:串行回收
这个收集器是一个单线程的收集器,“单线程”的意义:它只会使用一个CPU(串行)或一条收集线程去完成垃圾收集工作。更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束(Stop The World)
- +
+ @@ -313,7 +313,7 @@ ParNew 回收器:并行回收
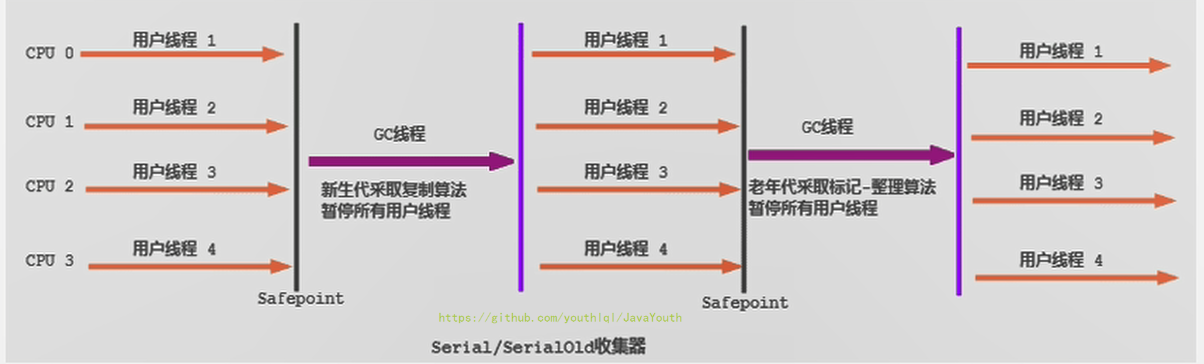
2. ParNew 收集器除了采用**并行回收**的方式执行内存回收外,两款垃圾收集器之间几乎没有任何区别。ParNew收集器在年轻代中同样也是采用复制算法、"Stop-the-World"机制。
3. ParNew 是很多JVM运行在Server模式下新生代的默认垃圾收集器。
-
@@ -313,7 +313,7 @@ ParNew 回收器:并行回收
2. ParNew 收集器除了采用**并行回收**的方式执行内存回收外,两款垃圾收集器之间几乎没有任何区别。ParNew收集器在年轻代中同样也是采用复制算法、"Stop-the-World"机制。
3. ParNew 是很多JVM运行在Server模式下新生代的默认垃圾收集器。
- +
+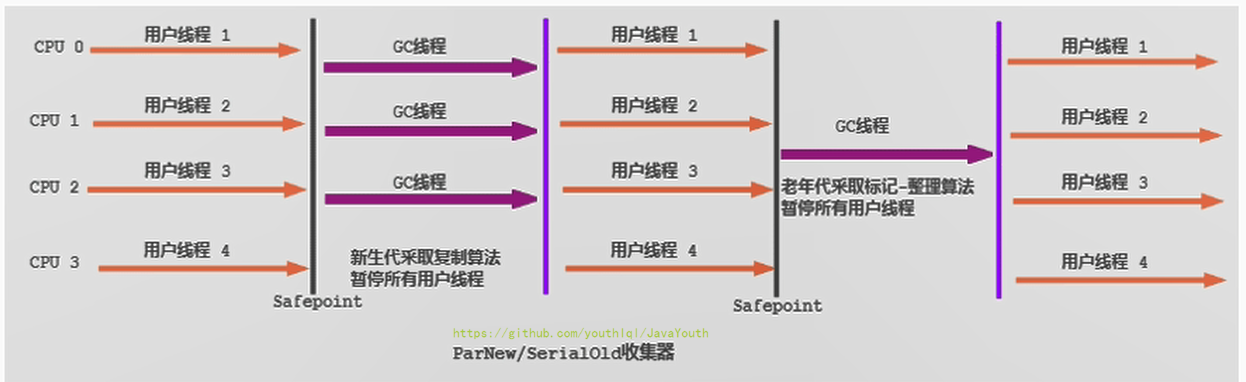 1. 对于新生代,回收次数频繁,使用并行方式高效。
2. 对于老年代,回收次数少,使用串行方式节省资源。(CPU并行需要切换线程,串行可以省去切换线程的资源)
@@ -361,7 +361,7 @@ Parallel 回收器:吞吐量优先
5. Parallel Old收集器采用了标记-压缩算法,但同样也是基于并行回收和"Stop-the-World"机制。
-
1. 对于新生代,回收次数频繁,使用并行方式高效。
2. 对于老年代,回收次数少,使用串行方式节省资源。(CPU并行需要切换线程,串行可以省去切换线程的资源)
@@ -361,7 +361,7 @@ Parallel 回收器:吞吐量优先
5. Parallel Old收集器采用了标记-压缩算法,但同样也是基于并行回收和"Stop-the-World"机制。
- +
+ 1. 在程序吞吐量优先的应用场景中,Parallel收集器和Parallel Old收集器的组合,在server模式下的内存回收性能很不错。
2. **在Java8中,默认是此垃圾收集器。**
@@ -418,7 +418,7 @@ CMS 回收器:低延迟
### CMS 工作原理(过程)
-
1. 在程序吞吐量优先的应用场景中,Parallel收集器和Parallel Old收集器的组合,在server模式下的内存回收性能很不错。
2. **在Java8中,默认是此垃圾收集器。**
@@ -418,7 +418,7 @@ CMS 回收器:低延迟
### CMS 工作原理(过程)
- +
+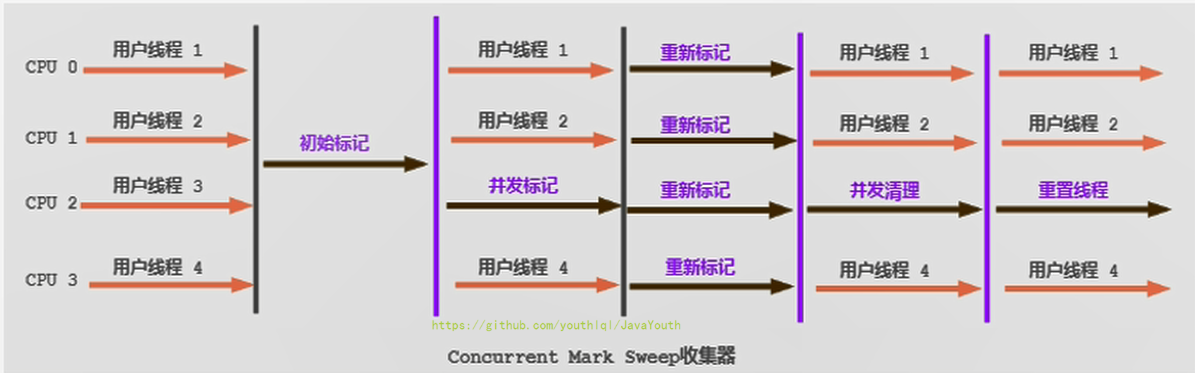 CMS整个过程比之前的收集器要复杂,整个过程分为4个主要阶段,即初始标记阶段、并发标记阶段、重新标记阶段和并发清除阶段。(涉及STW的阶段主要是:初始标记 和 重新标记)
@@ -438,7 +438,7 @@ CMS整个过程比之前的收集器要复杂,整个过程分为4个主要阶
3. 另外,由于在垃圾收集阶段用户线程没有中断,所以在CMS回收过程中,还应该确保应用程序用户线程有足够的内存可用。因此,CMS收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,**而是当堆内存使用率达到某一阈值时,便开始进行回收**,以确保应用程序在CMS工作过程中依然有足够的空间支持应用程序运行。要是CMS运行期间预留的内存无法满足程序需要,就会出现一次**“Concurrent Mode Failure”** 失败,这时虚拟机将启动后备预案:临时启用Serial old收集器来重新进行老年代的垃圾收集,这样停顿时间就很长了。
4. CMS收集器的垃圾收集算法采用的是**标记清除算法**,这意味着每次执行完内存回收后,由于被执行内存回收的无用对象所占用的内存空间极有可能是不连续的一些内存块,**不可避免地将会产生一些内存碎片**。那么CMS在为新对象分配内存空间时,将无法使用指针碰撞(Bump the Pointer)技术,而只能够选择空闲列表(Free List)执行内存分配。
-
CMS整个过程比之前的收集器要复杂,整个过程分为4个主要阶段,即初始标记阶段、并发标记阶段、重新标记阶段和并发清除阶段。(涉及STW的阶段主要是:初始标记 和 重新标记)
@@ -438,7 +438,7 @@ CMS整个过程比之前的收集器要复杂,整个过程分为4个主要阶
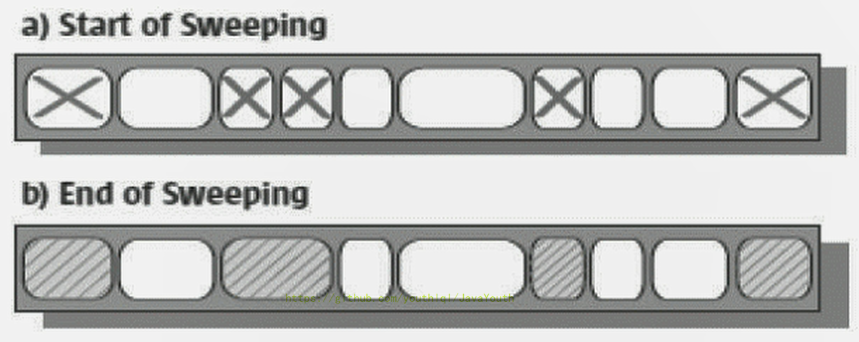
3. 另外,由于在垃圾收集阶段用户线程没有中断,所以在CMS回收过程中,还应该确保应用程序用户线程有足够的内存可用。因此,CMS收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,**而是当堆内存使用率达到某一阈值时,便开始进行回收**,以确保应用程序在CMS工作过程中依然有足够的空间支持应用程序运行。要是CMS运行期间预留的内存无法满足程序需要,就会出现一次**“Concurrent Mode Failure”** 失败,这时虚拟机将启动后备预案:临时启用Serial old收集器来重新进行老年代的垃圾收集,这样停顿时间就很长了。
4. CMS收集器的垃圾收集算法采用的是**标记清除算法**,这意味着每次执行完内存回收后,由于被执行内存回收的无用对象所占用的内存空间极有可能是不连续的一些内存块,**不可避免地将会产生一些内存碎片**。那么CMS在为新对象分配内存空间时,将无法使用指针碰撞(Bump the Pointer)技术,而只能够选择空闲列表(Free List)执行内存分配。
- +
+ @@ -558,11 +558,11 @@ G1 回收器:区域化分代式
G1的分代,已经不是下面这样的了
-
@@ -558,11 +558,11 @@ G1 回收器:区域化分代式
G1的分代,已经不是下面这样的了
- +
+ G1的分区是这样的一个区域
-
G1的分区是这样的一个区域
- +
+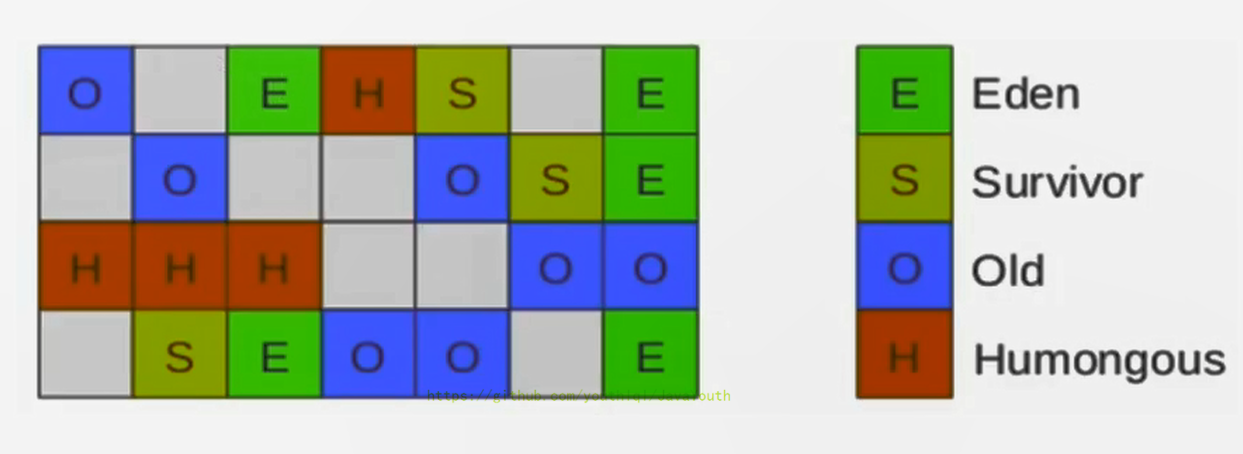 **空间整合**
@@ -655,7 +655,7 @@ G1中提供了三种垃圾回收模式:YoungGC、Mixed GC和Full GC,在不
>
> 如图所示,可以将区域分配到Eden,幸存者和旧时代区域。 此外,还有第四种类型的物体被称为巨大区域。 这些区域旨在容纳标准区域大小的50%或更大的对象。 它们存储为一组连续区域。 最后,最后一种区域类型是堆的未使用区域。
-
**空间整合**
@@ -655,7 +655,7 @@ G1中提供了三种垃圾回收模式:YoungGC、Mixed GC和Full GC,在不
>
> 如图所示,可以将区域分配到Eden,幸存者和旧时代区域。 此外,还有第四种类型的物体被称为巨大区域。 这些区域旨在容纳标准区域大小的50%或更大的对象。 它们存储为一组连续区域。 最后,最后一种区域类型是堆的未使用区域。
- +
+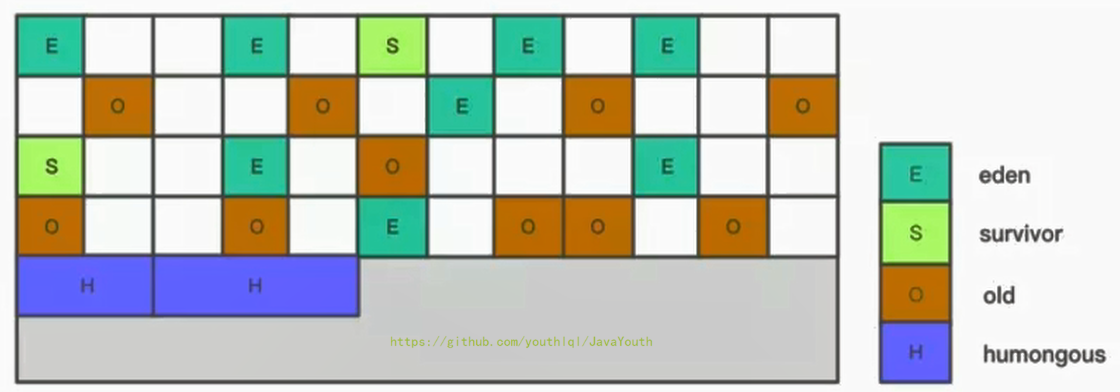 @@ -667,7 +667,7 @@ G1中提供了三种垃圾回收模式:YoungGC、Mixed GC和Full GC,在不
**Regio的细节**
-
@@ -667,7 +667,7 @@ G1中提供了三种垃圾回收模式:YoungGC、Mixed GC和Full GC,在不
**Regio的细节**
- +
+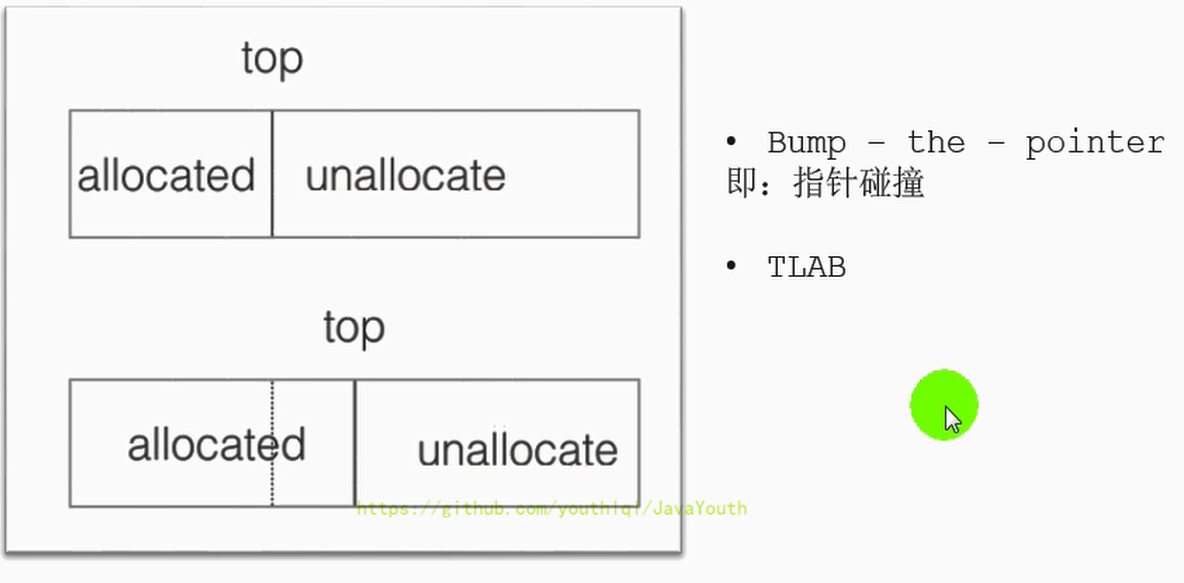 1. 每个Region都是通过指针碰撞来分配空间
2. G1为每一个Region设 计了两个名为TAMS(Top at Mark Start)的指针,把Region中的一部分空间划分出来用于并发回收过程中的新对象分配,并发回收时新分配的对象地址都必须要在这两个指针位置以上。
@@ -686,7 +686,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
* 混合回收(Mixed GC)
* (如果需要,单线程、独占式、高强度的Full GC还是继续存在的。它针对GC的评估失败提供了一种失败保护机制,即强力回收。)
-
1. 每个Region都是通过指针碰撞来分配空间
2. G1为每一个Region设 计了两个名为TAMS(Top at Mark Start)的指针,把Region中的一部分空间划分出来用于并发回收过程中的新对象分配,并发回收时新分配的对象地址都必须要在这两个指针位置以上。
@@ -686,7 +686,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
* 混合回收(Mixed GC)
* (如果需要,单线程、独占式、高强度的Full GC还是继续存在的。它针对GC的评估失败提供了一种失败保护机制,即强力回收。)
- +
+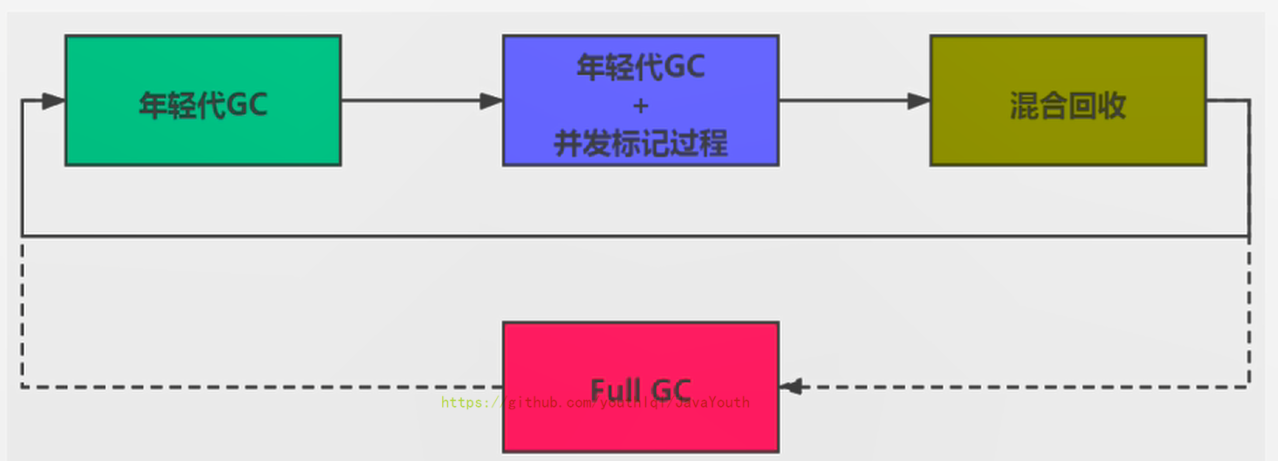 顺时针,Young GC --> Young GC+Concurrent Marking --> Mixed GC顺序,进行垃圾回收
@@ -731,7 +731,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
-
顺时针,Young GC --> Young GC+Concurrent Marking --> Mixed GC顺序,进行垃圾回收
@@ -731,7 +731,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
- +
+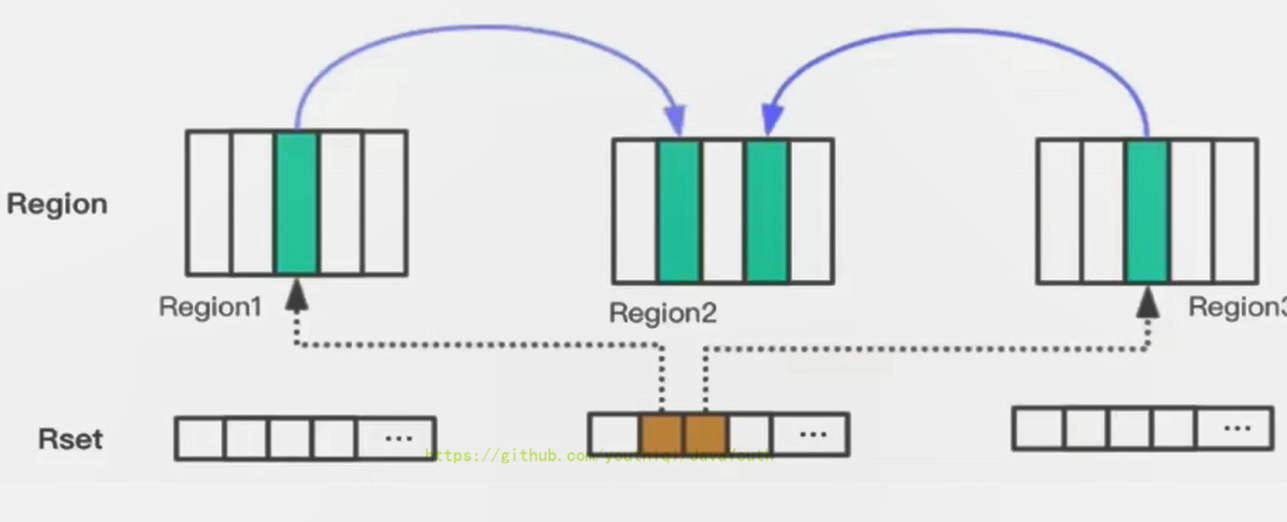 1. 在回收 Region 时,为了不进行全堆的扫描,引入了 Remembered Set
2. Remembered Set 记录了当前 Region 中的对象被哪个对象引用了
@@ -748,7 +748,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
2. 年轻代回收只回收Eden区和Survivor区
3. YGC时,首先G1停止应用程序的执行(Stop-The-World),G1创建回收集(Collection Set),回收集是指需要被回收的内存分段的集合,年轻代回收过程的回收集包含年轻代Eden区和Survivor区所有的内存分段。
-
1. 在回收 Region 时,为了不进行全堆的扫描,引入了 Remembered Set
2. Remembered Set 记录了当前 Region 中的对象被哪个对象引用了
@@ -748,7 +748,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
2. 年轻代回收只回收Eden区和Survivor区
3. YGC时,首先G1停止应用程序的执行(Stop-The-World),G1创建回收集(Collection Set),回收集是指需要被回收的内存分段的集合,年轻代回收过程的回收集包含年轻代Eden区和Survivor区所有的内存分段。
- +
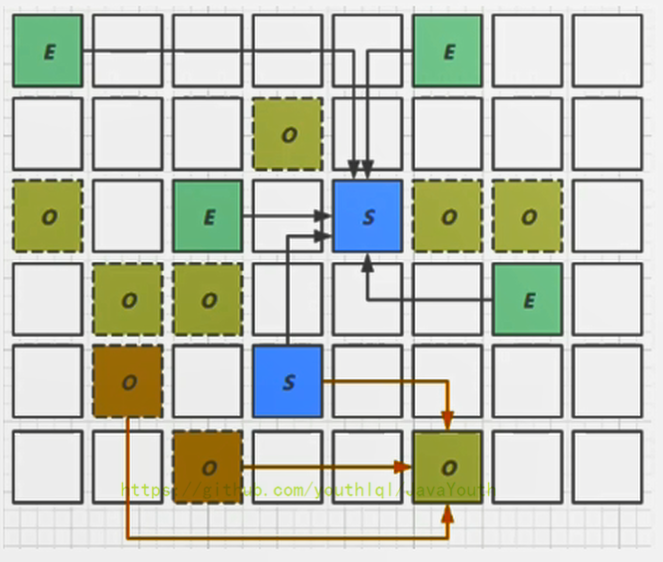
+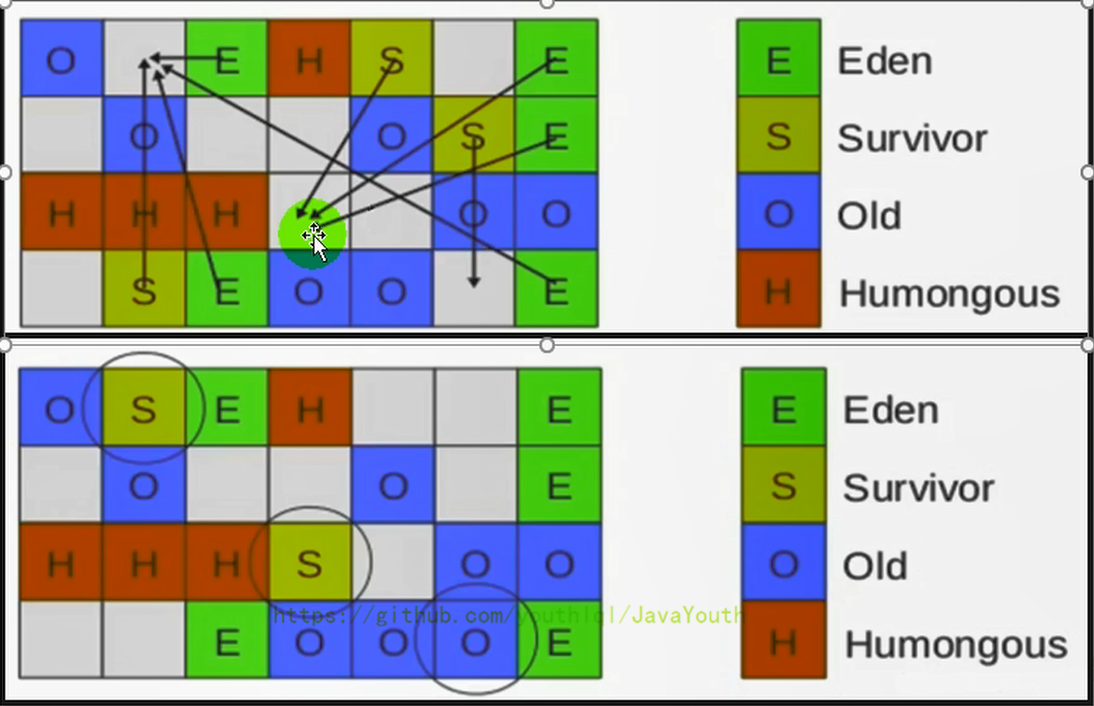 图的大致意思就是:
@@ -804,7 +804,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
当越来越多的对象晋升到老年代Old Region时,为了避免堆内存被耗尽,虚拟机会触发一个混合的垃圾收集器,即Mixed GC,该算法并不是一个Old GC,除了回收整个Young Region,还会回收一部分的Old Region。这里需要注意:是一部分老年代,而不是全部老年代。可以选择哪些Old Region进行收集,从而可以对垃圾回收的耗时时间进行控制。也要注意的是Mixed GC并不是Full GC。
-
图的大致意思就是:
@@ -804,7 +804,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
当越来越多的对象晋升到老年代Old Region时,为了避免堆内存被耗尽,虚拟机会触发一个混合的垃圾收集器,即Mixed GC,该算法并不是一个Old GC,除了回收整个Young Region,还会回收一部分的Old Region。这里需要注意:是一部分老年代,而不是全部老年代。可以选择哪些Old Region进行收集,从而可以对垃圾回收的耗时时间进行控制。也要注意的是Mixed GC并不是Full GC。
- +
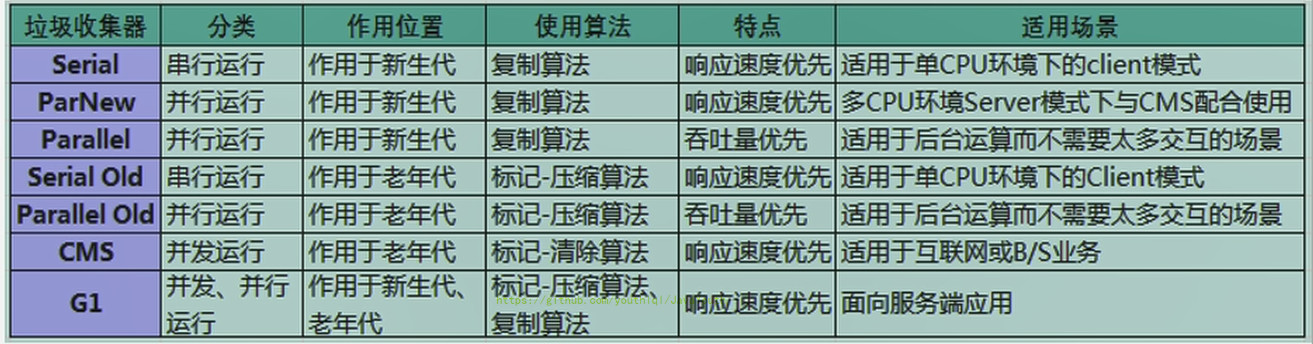
+ @@ -854,11 +854,11 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
截止JDK1.8,一共有7款不同的垃圾收集器。每一款的垃圾收集器都有不同的特点,在具体使用的时候,需要根据具体的情况选用不同的垃圾收集器。
-
@@ -854,11 +854,11 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
截止JDK1.8,一共有7款不同的垃圾收集器。每一款的垃圾收集器都有不同的特点,在具体使用的时候,需要根据具体的情况选用不同的垃圾收集器。
- +
+ -
- +
+ @@ -922,11 +922,11 @@ GC 日志分析
2、这个只会显示总的GC堆的变化,如下:
-
@@ -922,11 +922,11 @@ GC 日志分析
2、这个只会显示总的GC堆的变化,如下:
- +
+ 3、参数解析
-
3、参数解析
- +
+ @@ -938,11 +938,11 @@ GC 日志分析
2、输入信息如下
-
@@ -938,11 +938,11 @@ GC 日志分析
2、输入信息如下
- +
+ 3、参数解析
-
3、参数解析
- +
+ @@ -954,7 +954,7 @@ GC 日志分析
2、输出信息如下
-
@@ -954,7 +954,7 @@ GC 日志分析
2、输出信息如下
- +
+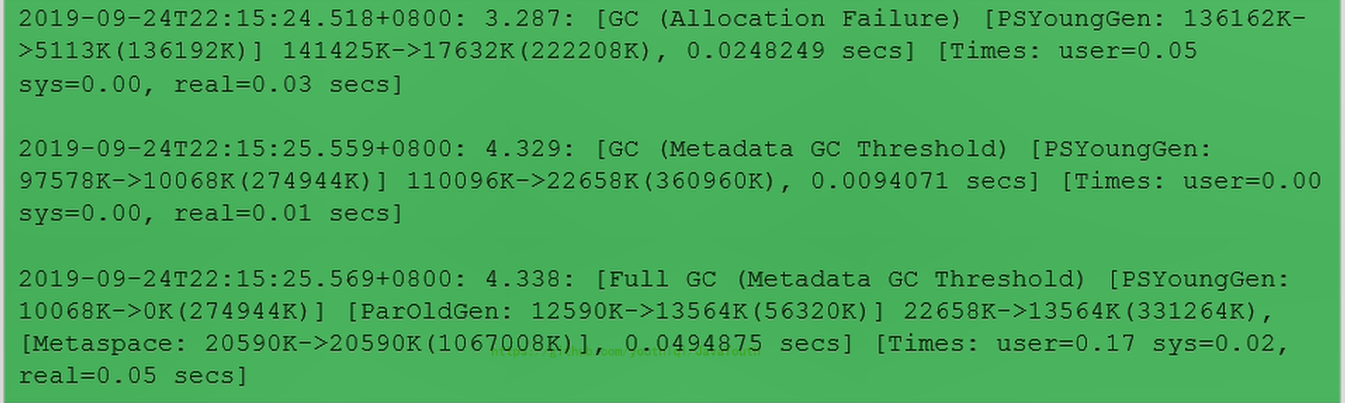 3、说明:日志带上了日期和时间
@@ -989,13 +989,13 @@ GC 日志分析
#### Young GC
-
3、说明:日志带上了日期和时间
@@ -989,13 +989,13 @@ GC 日志分析
#### Young GC
- +
+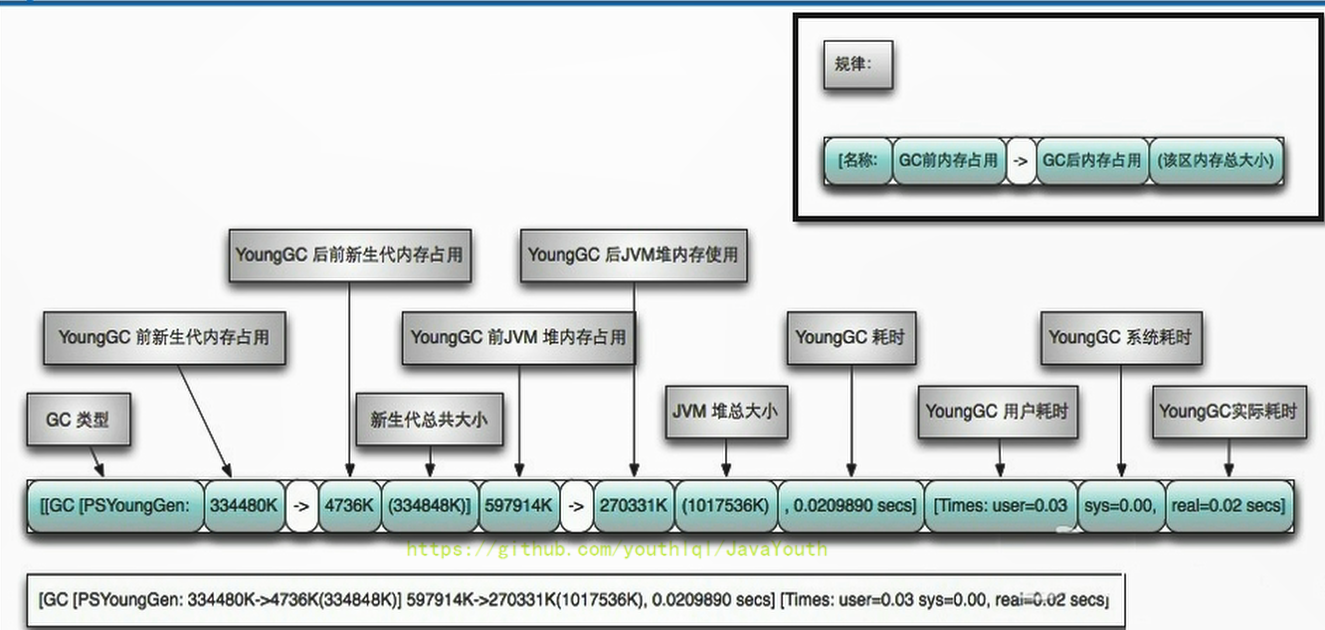 #### Full GC
-
#### Full GC
- +
+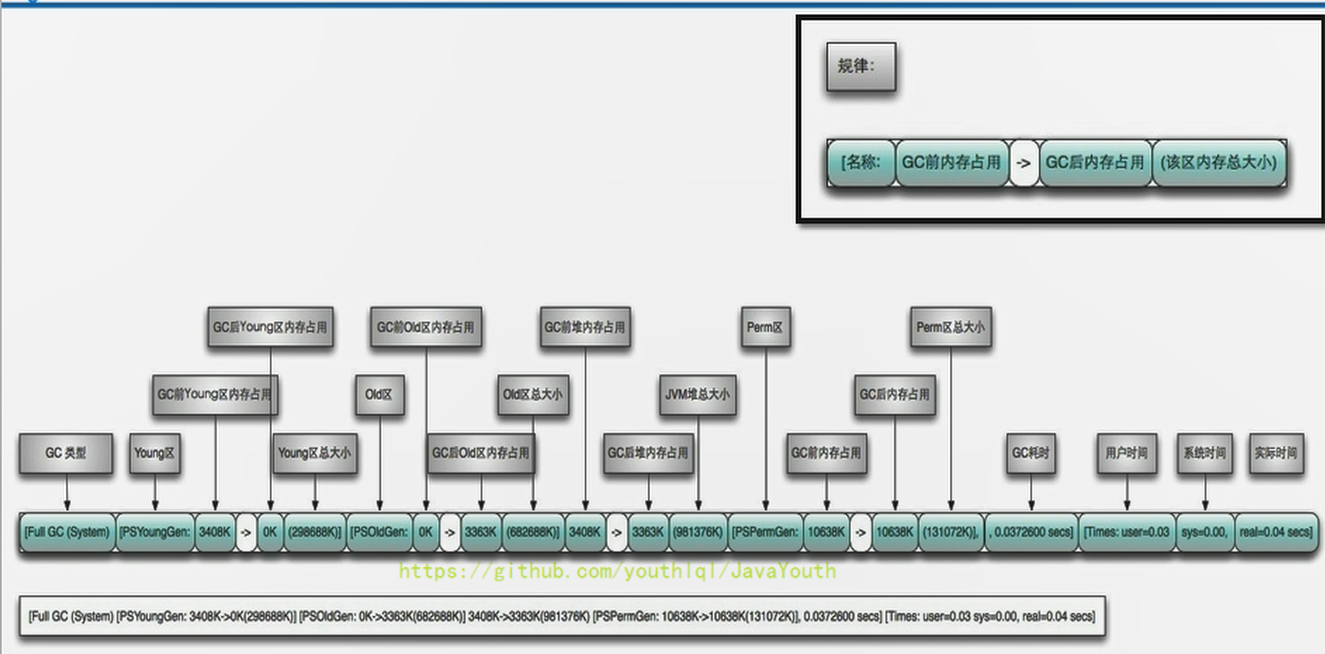 @@ -1029,11 +1029,11 @@ public class GCLogTest1 {
1、首先我们会将3个2M的数组存放到Eden区,然后后面4M的数组来了后,将无法存储,因为Eden区只剩下2M的剩余空间了,那么将会进行一次Young GC操作,将原来Eden区的内容,存放到Survivor区,但是Survivor区也存放不下,那么就会直接晋级存入Old 区
-
@@ -1029,11 +1029,11 @@ public class GCLogTest1 {
1、首先我们会将3个2M的数组存放到Eden区,然后后面4M的数组来了后,将无法存储,因为Eden区只剩下2M的剩余空间了,那么将会进行一次Young GC操作,将原来Eden区的内容,存放到Survivor区,但是Survivor区也存放不下,那么就会直接晋级存入Old 区
- +
+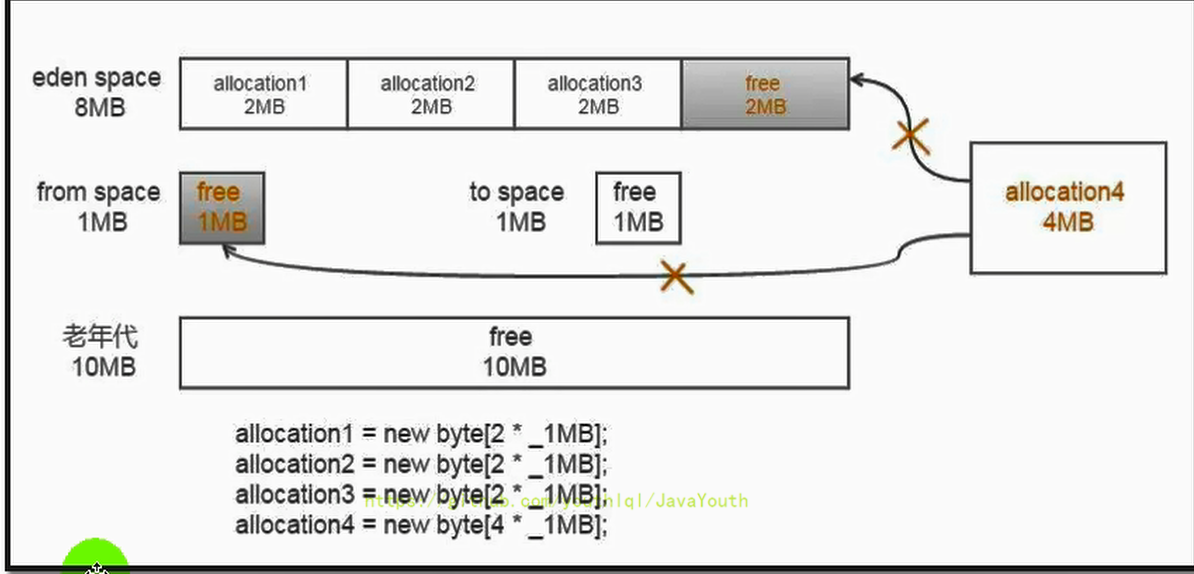 2、然后我们将4M对象存入到Eden区中
-
2、然后我们将4M对象存入到Eden区中
- +
+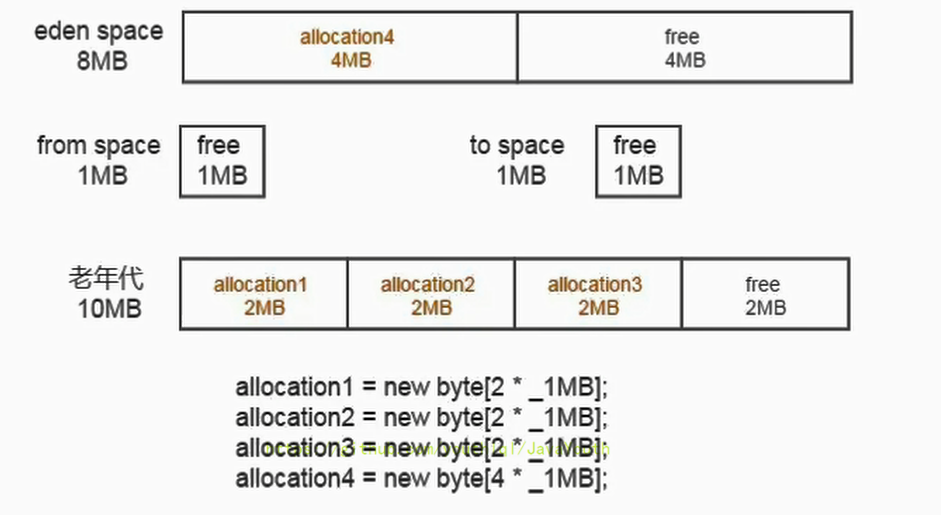 老年代图画的有问题,free应该是4M
@@ -1056,7 +1056,7 @@ Process finished with exit code 0
```
-
老年代图画的有问题,free应该是4M
@@ -1056,7 +1056,7 @@ Process finished with exit code 0
```
- +
+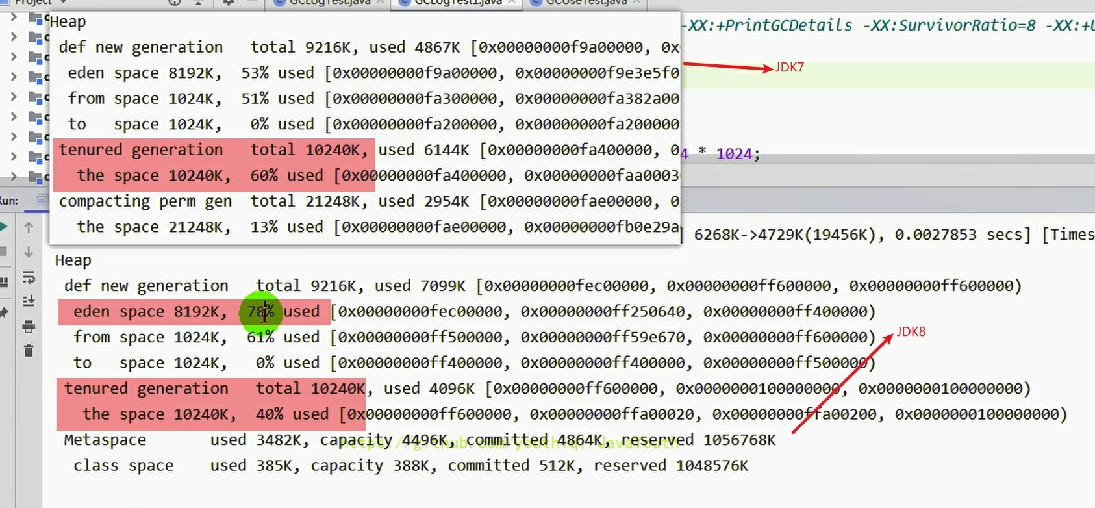 与 JDK7 不同的是,JDK8 直接判定 4M 的数组为大对象,直接怼到老年区去了
@@ -1082,15 +1082,15 @@ GCViewer、GCEasy、GCHisto、GCLogViewer、Hpjmeter、garbagecat等
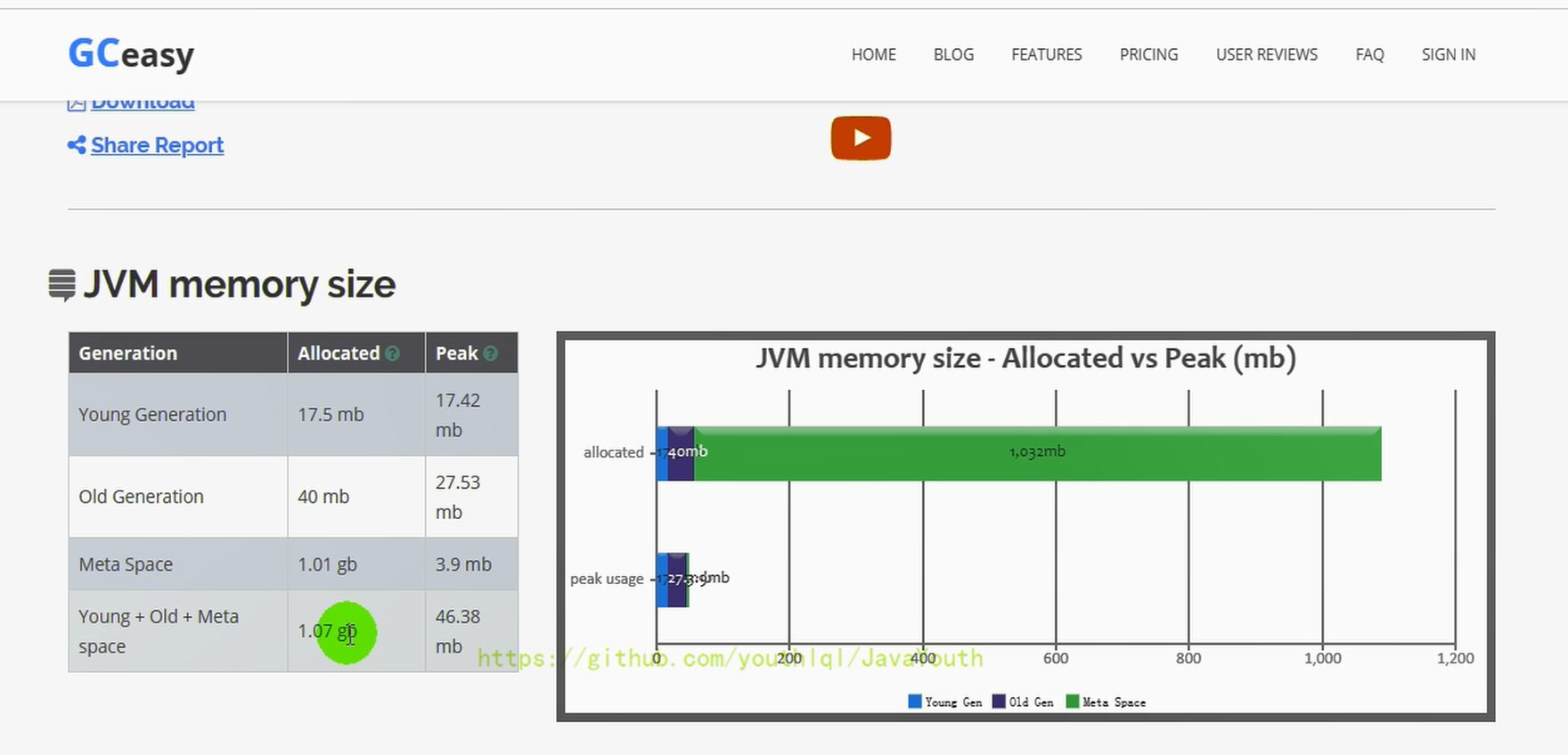
在线分析网址:gceasy.io
-
与 JDK7 不同的是,JDK8 直接判定 4M 的数组为大对象,直接怼到老年区去了
@@ -1082,15 +1082,15 @@ GCViewer、GCEasy、GCHisto、GCLogViewer、Hpjmeter、garbagecat等
在线分析网址:gceasy.io
- +
+ -
- +
+ -
- +
+ @@ -1126,7 +1126,7 @@ GCViewer、GCEasy、GCHisto、GCLogViewer、Hpjmeter、garbagecat等
1. 停顿时间比其他几款收集器确实有了质的飞跃,但也未实现最大停顿时间控制在十毫秒以内的目标。
2. 而吞吐量方面出现了明显的下降,总运行时间是所有测试收集器里最长的。
-
@@ -1126,7 +1126,7 @@ GCViewer、GCEasy、GCHisto、GCLogViewer、Hpjmeter、garbagecat等
1. 停顿时间比其他几款收集器确实有了质的飞跃,但也未实现最大停顿时间控制在十毫秒以内的目标。
2. 而吞吐量方面出现了明显的下降,总运行时间是所有测试收集器里最长的。
- +
+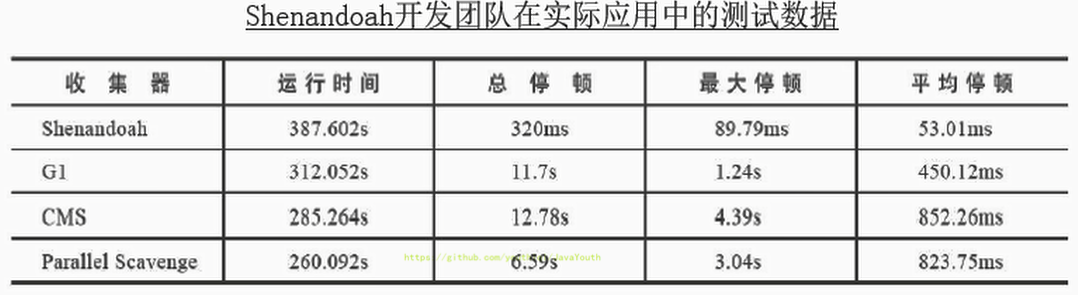 @@ -1156,7 +1156,7 @@ GCViewer、GCEasy、GCHisto、GCLogViewer、Hpjmeter、garbagecat等
**吞吐量**
-
@@ -1156,7 +1156,7 @@ GCViewer、GCEasy、GCHisto、GCLogViewer、Hpjmeter、garbagecat等
**吞吐量**
- +
+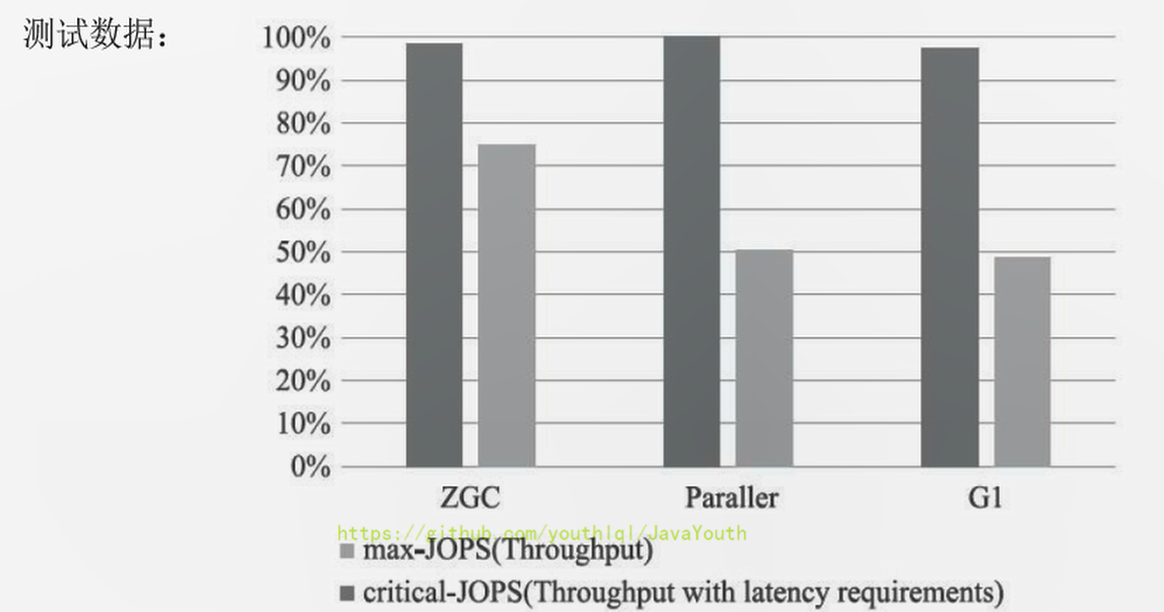 max-JOPS:以低延迟为首要前提下的数据
@@ -1166,13 +1166,13 @@ critical-JOPS:不考虑低延迟下的数据
**低延迟**
-
max-JOPS:以低延迟为首要前提下的数据
@@ -1166,13 +1166,13 @@ critical-JOPS:不考虑低延迟下的数据
**低延迟**
- +
+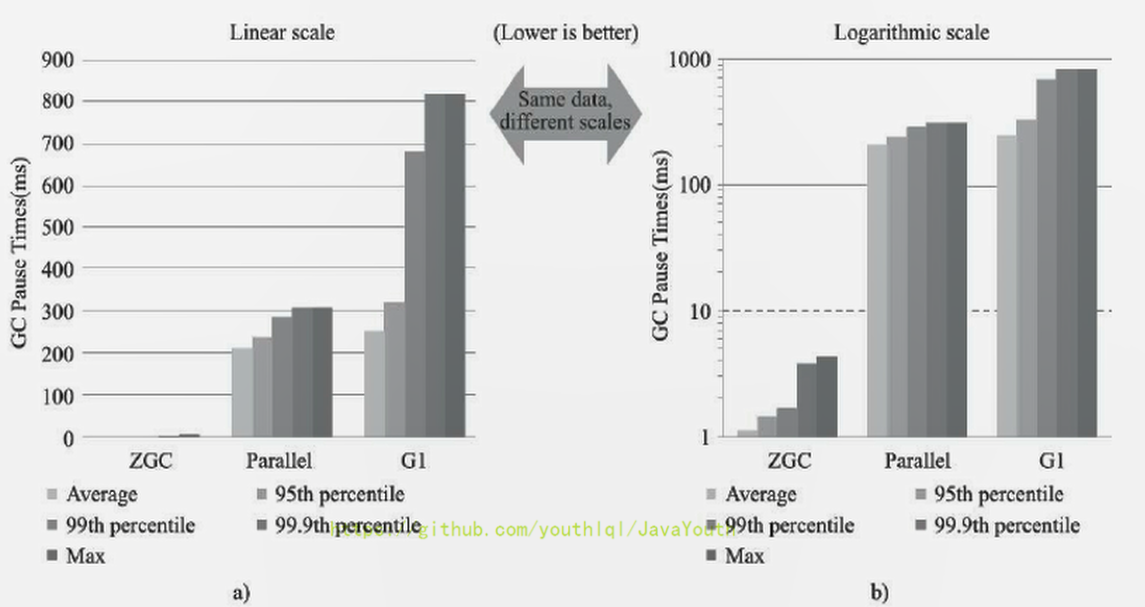 在ZGC的强项停顿时间测试上,它毫不留情的将Parallel、G1拉开了两个数量级的差距。无论平均停顿、95%停顿、998停顿、99. 98停顿,还是最大停顿时间,ZGC都能毫不费劲控制在10毫秒以内。
虽然ZGC还在试验状态,没有完成所有特性,但此时性能已经相当亮眼,用“令人震惊、革命性”来形容,不为过。未来将在服务端、大内存、低延迟应用的首选垃圾收集器。
-
在ZGC的强项停顿时间测试上,它毫不留情的将Parallel、G1拉开了两个数量级的差距。无论平均停顿、95%停顿、998停顿、99. 98停顿,还是最大停顿时间,ZGC都能毫不费劲控制在10毫秒以内。
虽然ZGC还在试验状态,没有完成所有特性,但此时性能已经相当亮眼,用“令人震惊、革命性”来形容,不为过。未来将在服务端、大内存、低延迟应用的首选垃圾收集器。
- +
+ @@ -1192,4 +1192,4 @@ critical-JOPS:不考虑低延迟下的数据
AliGC是阿里巴巴JVM团队基于G1算法,面向大堆(LargeHeap)应用场景。指定场景下的对比:
-
@@ -1192,4 +1192,4 @@ critical-JOPS:不考虑低延迟下的数据
AliGC是阿里巴巴JVM团队基于G1算法,面向大堆(LargeHeap)应用场景。指定场景下的对比:
- \ No newline at end of file
+
\ No newline at end of file
+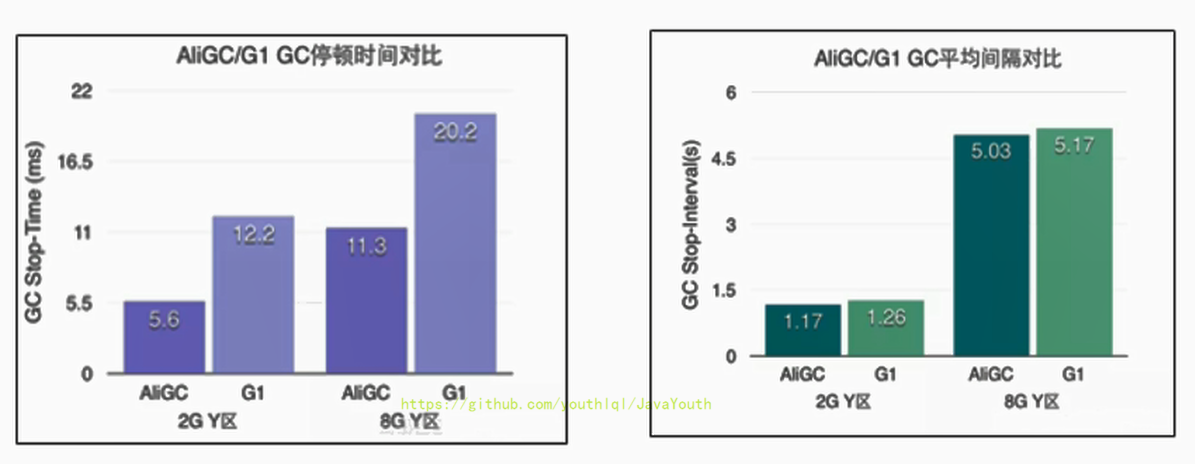 \ No newline at end of file
\ No newline at end of file