From 785faca8b458abfe0803d2a9a51143c6a8da2a0e Mon Sep 17 00:00:00 2001
From: Dragon <1826692270@qq.com>
Date: Thu, 8 Apr 2021 00:56:56 +0800
Subject: [PATCH] .
---
docs/Computer_NetWork/计算机网络-总结.md | 102 -----------------------
1 file changed, 102 deletions(-)
diff --git a/docs/Computer_NetWork/计算机网络-总结.md b/docs/Computer_NetWork/计算机网络-总结.md
index 0c46666..38576bf 100644
--- a/docs/Computer_NetWork/计算机网络-总结.md
+++ b/docs/Computer_NetWork/计算机网络-总结.md
@@ -807,100 +807,6 @@ proactor: 这有十个字节数据,收好了跟我说一声。
> 想要理解这两设计模式,还是要真正的学习设计模式。
-
-
-# 五种IO模型的区别
-
-> 从下面这两个文章总结的:
->
-> * https://blog.csdn.net/sehanlingfeng/article/details/78920423
-> * http://www.tianshouzhi.com/api/tutorials/netty/221
->
-> 下面总结的地方如果有不懂的,看上面的文章内容
->
-> 下面这两篇文章看起来不错,不过还没认真看:
->
-> * https://blog.csdn.net/ocean_fan/article/details/79622956
-> * https://blog.csdn.net/ZWE7616175/article/details/80591587
-
-在这里,我们以一个网络IO来的read来举例,它会涉及到两个东西:一个是产生这个IO的进程,另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
-
-**阶段1:**等待数据准备
-
-**阶段2:**将数据从内核拷贝到进程中
-
-## 阻塞IO
-
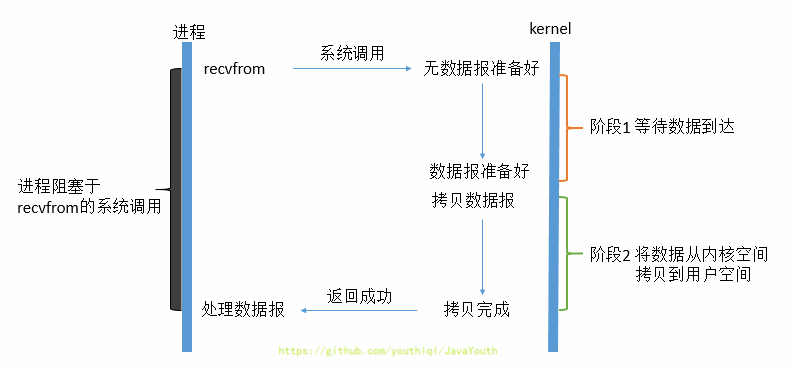
- 当用户进程进行recvfrom这个系统调用,内核就开始了IO的第一个阶段:等待数据准备。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候**内核**就要等待足够的数据到来。而在用户进程这边,整 个进程会被阻塞。当**内核**一直等到数据准备好了,它就会将数据从**内核**中拷贝到用户内存,然后**内核**返回果,用户进程才解除 block的状态,重新运行起来。**所以,blocking IO的特点就是在IO执行的两个阶段都被block了。**
-
- -
-
-
- -
-## 非阻塞IO
-
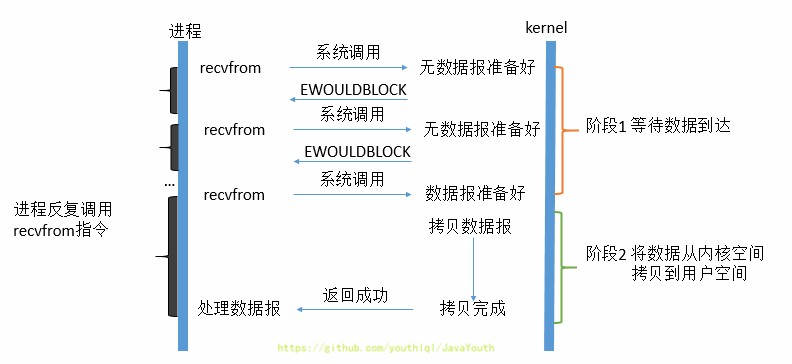
-1. 当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。
-2. 从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好。用户线程需要不断地发起IO请求,直到数据到达后,才真正读取到数据,继续执行。
-3. 虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
-4. **所以,用户进程第一个阶段不是阻塞的,需要不断的主动询问内核数据好了没有;第二个阶段依然总是阻塞的。**
-
-
-
-## 非阻塞IO
-
-1. 当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。
-2. 从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好。用户线程需要不断地发起IO请求,直到数据到达后,才真正读取到数据,继续执行。
-3. 虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
-4. **所以,用户进程第一个阶段不是阻塞的,需要不断的主动询问内核数据好了没有;第二个阶段依然总是阻塞的。**
-
- -
-
-
- -
-
-
-## 多路复用IO
-
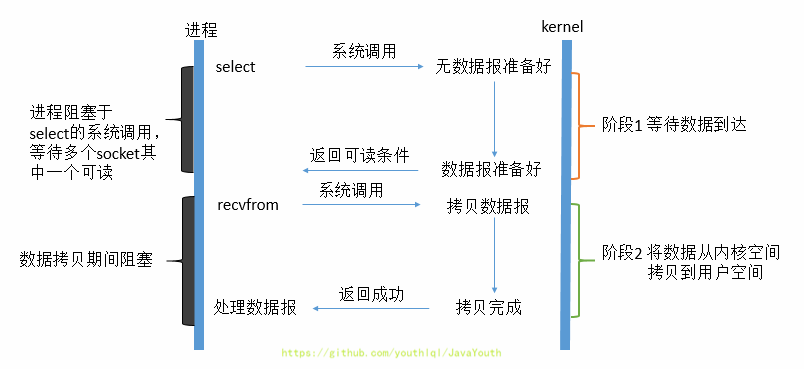
-1. IO多路复用模型是建立在内核提供的多路分离函数select基础之上的,使用select函数可以避免同步非阻塞IO模型中轮询等待的问题。利用了新的select系统调用,由内核来负责本来是请求进程该做的轮询操作
-2. 它的基本原理就是select /epoll这个函数会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程,正式发起read请求。
-3. 从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket(也就是数据准备好了的socket),即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
-
-
-
-
-
-## 多路复用IO
-
-1. IO多路复用模型是建立在内核提供的多路分离函数select基础之上的,使用select函数可以避免同步非阻塞IO模型中轮询等待的问题。利用了新的select系统调用,由内核来负责本来是请求进程该做的轮询操作
-2. 它的基本原理就是select /epoll这个函数会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程,正式发起read请求。
-3. 从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket(也就是数据准备好了的socket),即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
-
- -
-
-
-### select函数的其它好处
-
-> handle_events:实现事件循环
->
-> handle_event:进行读/写等操作
-
-1. 使用select函数的优点并不仅限于此。虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。
-2. 如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率。
-3. IO多路复用模型使用了Reactor设计模式实现了这一机制。
-4. 通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时(就是数据准备好的时候),则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。
-5. 由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。(一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。)
-
-
-
-
-
-### select函数的其它好处
-
-> handle_events:实现事件循环
->
-> handle_event:进行读/写等操作
-
-1. 使用select函数的优点并不仅限于此。虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。
-2. 如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率。
-3. IO多路复用模型使用了Reactor设计模式实现了这一机制。
-4. 通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时(就是数据准备好的时候),则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。
-5. 由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。(一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。)
-
- -
-
-
-## 信号驱动IO
-
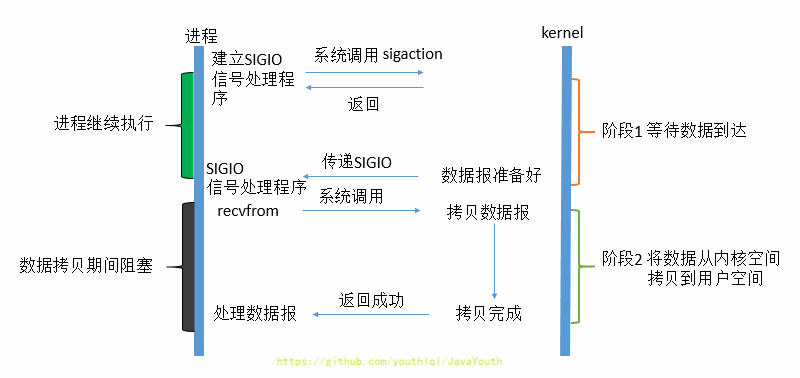
-1. 在信号驱动IO模型中,当用户线程发起一个IO请求操作,会给对应的socket注册一个信号函数,然后用户线程会继续执行,当内核数据就绪时会发送一个信号给用户线程,用户线程接收到信号之后,便在信号函数中调用IO读写操作来进行实际的IO请求操作。
-2. 这个一般用于UDP中,对TCP套接口几乎是没用的,原因是该信号产生得过于频繁,并且该信号的出现并没有告诉我们发生了什么事情
-3. 信号驱动IO放佛很像异步IO,它的第一阶段不是阻塞的。但是很遗憾,它的数据拷贝阶段(第二阶段),任然是阻塞的。
-
-
-
-
-
-## 信号驱动IO
-
-1. 在信号驱动IO模型中,当用户线程发起一个IO请求操作,会给对应的socket注册一个信号函数,然后用户线程会继续执行,当内核数据就绪时会发送一个信号给用户线程,用户线程接收到信号之后,便在信号函数中调用IO读写操作来进行实际的IO请求操作。
-2. 这个一般用于UDP中,对TCP套接口几乎是没用的,原因是该信号产生得过于频繁,并且该信号的出现并没有告诉我们发生了什么事情
-3. 信号驱动IO放佛很像异步IO,它的第一阶段不是阻塞的。但是很遗憾,它的数据拷贝阶段(第二阶段),任然是阻塞的。
-
- -
-
-
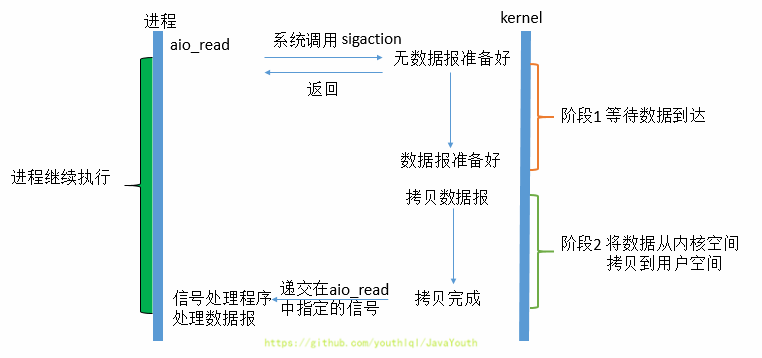
-## 异步IO
-
-1. 真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,由用户线程自行读取数据、处理数据。
-2. 而在异步IO模型中,用户进程发起read操作之后,立刻就可以开始去做其它的事。
-3. 而另一方面,从**内核**的角度,当它受到一个异步读之后,首先它会立刻返回,所以不会对用户进程产生任何阻塞。然后,内核会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都 完成之后,**内核**会给用户进程发送一个信号,告诉它read操作完成了,用户线程直接使用即可。 在这整个过程中,进程完全没有被阻塞。
-4. 异步IO模型使用了Proactor设计模式实现了这一机制。**(具体怎么搞得,看上面的文章链接)**
-
-
-
-
-
-## 异步IO
-
-1. 真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,由用户线程自行读取数据、处理数据。
-2. 而在异步IO模型中,用户进程发起read操作之后,立刻就可以开始去做其它的事。
-3. 而另一方面,从**内核**的角度,当它受到一个异步读之后,首先它会立刻返回,所以不会对用户进程产生任何阻塞。然后,内核会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都 完成之后,**内核**会给用户进程发送一个信号,告诉它read操作完成了,用户线程直接使用即可。 在这整个过程中,进程完全没有被阻塞。
-4. 异步IO模型使用了Proactor设计模式实现了这一机制。**(具体怎么搞得,看上面的文章链接)**
-
- -
-
-
-
-
-
-
- -
-
-
# select、poll、epoll的区别?
> select, poll, epoll 都是I/O多路复用的具体的实现,之所以有这三个存在,其实是他们出现是有先后顺序的。
@@ -927,11 +833,3 @@ poll本质上和select没有区别,采用**链表**的方式替换原有fd_set
-# IO疑难点
-
-https://blog.csdn.net/m0_38109046/article/details/89449305
-
-https://www.zhihu.com/question/19732473
-
-[漫画讲IO](https://mp.weixin.qq.com/s?__biz=Mzg3MjA4MTExMw==&mid=2247484746&idx=1&sn=c0a7f9129d780786cabfcac0a8aa6bb7&source=41&scene=21#wechat_redirect)
-
-
-
-
# select、poll、epoll的区别?
> select, poll, epoll 都是I/O多路复用的具体的实现,之所以有这三个存在,其实是他们出现是有先后顺序的。
@@ -927,11 +833,3 @@ poll本质上和select没有区别,采用**链表**的方式替换原有fd_set
-# IO疑难点
-
-https://blog.csdn.net/m0_38109046/article/details/89449305
-
-https://www.zhihu.com/question/19732473
-
-[漫画讲IO](https://mp.weixin.qq.com/s?__biz=Mzg3MjA4MTExMw==&mid=2247484746&idx=1&sn=c0a7f9129d780786cabfcac0a8aa6bb7&source=41&scene=21#wechat_redirect)
-