From 12ea191d0b0a0fb8f99bf5aedafeb0ba4511c511 Mon Sep 17 00:00:00 2001
From: Dragon <1826692270@qq.com>
Date: Thu, 8 Apr 2021 15:49:28 +0800
Subject: [PATCH] =?UTF-8?q?=E6=9B=B4=E6=96=B0=E6=93=8D=E4=BD=9C=E7=B3=BB?=
=?UTF-8?q?=E7=BB=9F=E6=96=87=E7=AB=A0=E5=92=8Cnetty=E6=96=87=E7=AB=A0?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
README.md | 14 +-
docs/netty/introduction/Netty入门-第一话.md | 1381 +++++++++++++++++++
docs/os/操作系统-IO与零拷贝.md | 399 ++++++
3 files changed, 1793 insertions(+), 1 deletion(-)
create mode 100644 docs/netty/introduction/Netty入门-第一话.md
create mode 100644 docs/os/操作系统-IO与零拷贝.md
diff --git a/README.md b/README.md
index 105e784..5eaedf2 100644
--- a/README.md
+++ b/README.md
@@ -129,7 +129,7 @@ AQS剩余部分,以及阻塞队列源码暂时先搁置一下。
**总结篇**
-1、[计算机网络-总结-秋招篇](docs/Computer_NetWork/计算机网络-总结.md)
+[计算机网络-总结-秋招篇](docs/Computer_NetWork/计算机网络-总结.md)
@@ -137,6 +137,18 @@ AQS剩余部分,以及阻塞队列源码暂时先搁置一下。
+# 操作系统
+
+[操作系统-IO与零拷贝](docs/os/操作系统-IO与零拷贝.md)
+
+
+
+# Netty
+
+## 入门
+
+[Netty入门-第一话](docs/netty/introduction/Netty入门-第一话.md)
+
# Apollo
[Apollo简单入门](docs/Apollo/Apollo简单入门.md)
diff --git a/docs/netty/introduction/Netty入门-第一话.md b/docs/netty/introduction/Netty入门-第一话.md
new file mode 100644
index 0000000..b50025e
--- /dev/null
+++ b/docs/netty/introduction/Netty入门-第一话.md
@@ -0,0 +1,1381 @@
+---
+title: Netty入门-第一话
+tags:
+ - Netty
+categories:
+ - Netty
+ - 入门
+keywords: Netty
+description: Netty入门-第一话。
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@master/netty/netty_logo.jpg'
+abbrlink: 3f9283e7
+date: 2021-04-08 14:21:58
+---
+
+
+
+> - 因为学netty的过程中,发现计算机网络和操作系统蛮重要的,所以接下来会写几篇这方面的文章,希望读者不要觉得我东写一点,西写一点。
+> - 比如netty中有操作系统里的IO,零拷贝。有计算机网络里的通信(因为netty本身就是一个网络应用框架)。等等
+
+# Netty简介
+
+
+
+## Netty 的介绍
+
+1. `Netty` 是由 `JBOSS` 提供的一个 `Java` 开源框架,现为 `Github` 上的独立项目。
+2. `Netty` 是一个异步的、基于事件驱动的网络应用框架,用以快速开发高性能、高可靠性的网络 `IO` 程序。
+3. `Netty` 主要针对在 `TCP` 协议下,面向 `Client` 端的高并发应用,或者 `Peer-to-Peer` 场景下的大量数据持续传输的应用。
+4. `Netty` 本质是一个 `NIO` 框架,适用于服务器通讯相关的多种应用场景。
+5. 要透彻理解 `Netty`,需要先学习 `NIO`,这样我们才能阅读 `Netty` 的源码。
+
+
+
+相对简单的一个体系图
+
+ +
+## Netty 的应用场景
+
+### 互联网行业
+
+1. 互联网行业:在分布式系统中,各个节点之间需要远程服务调用,高性能的 `RPC` 框架必不可少,`Netty` 作为异步高性能的通信框架,往往作为基础通信组件被这些 `RPC` 框架使用。
+2. 典型的应用有:阿里分布式服务框架 `Dubbo` 的 `RPC` 框 架使用 `Dubbo` 协议进行节点间通信,`Dubbo` 协议默认使用 `Netty` 作为基础通信组件,用于实现各进程节点之间的内部通信。
+
+
+
+### 游戏行业
+
+1. 无论是手游服务端还是大型的网络游戏,`Java` 语言得到了越来越广泛的应用。
+2. `Netty` 作为高性能的基础通信组件,提供了 `TCP/UDP` 和 `HTTP` 协议栈,方便定制和开发私有协议栈,账号登录服务器。
+3. 地图服务器之间可以方便的通过 `Netty` 进行高性能的通信。
+
+
+
+### 大数据领域
+
+1. 经典的 `Hadoop` 的高性能通信和序列化组件 `Avro` 的 `RPC` 框架,默认采用 `Netty` 进行跨界点通信。
+2. 它的 `NettyService` 基于 `Netty` 框架二次封装实现。
+
+
+
+### 其它开源项目使用到 Netty
+
+网址:https://netty.io/wiki/related-projects.html
+
+
+
+## Netty 的学习资料参考
+
+
+
+## Netty 的应用场景
+
+### 互联网行业
+
+1. 互联网行业:在分布式系统中,各个节点之间需要远程服务调用,高性能的 `RPC` 框架必不可少,`Netty` 作为异步高性能的通信框架,往往作为基础通信组件被这些 `RPC` 框架使用。
+2. 典型的应用有:阿里分布式服务框架 `Dubbo` 的 `RPC` 框 架使用 `Dubbo` 协议进行节点间通信,`Dubbo` 协议默认使用 `Netty` 作为基础通信组件,用于实现各进程节点之间的内部通信。
+
+
+
+### 游戏行业
+
+1. 无论是手游服务端还是大型的网络游戏,`Java` 语言得到了越来越广泛的应用。
+2. `Netty` 作为高性能的基础通信组件,提供了 `TCP/UDP` 和 `HTTP` 协议栈,方便定制和开发私有协议栈,账号登录服务器。
+3. 地图服务器之间可以方便的通过 `Netty` 进行高性能的通信。
+
+
+
+### 大数据领域
+
+1. 经典的 `Hadoop` 的高性能通信和序列化组件 `Avro` 的 `RPC` 框架,默认采用 `Netty` 进行跨界点通信。
+2. 它的 `NettyService` 基于 `Netty` 框架二次封装实现。
+
+
+
+### 其它开源项目使用到 Netty
+
+网址:https://netty.io/wiki/related-projects.html
+
+
+
+## Netty 的学习资料参考
+
+ +
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+# Java BIO编程
+
+
+
+
+
+## I/O 模型
+
+
+
+1. `I/O` 模型简单的理解:就是用什么样的通道进行数据的发送和接收,很大程度上决定了程序通信的性能。
+2. `Java` 共支持 `3` 种网络编程模型 `I/O` 模式:`BIO`、`NIO`、`AIO`。
+3. `Java BIO`:同步并阻塞(传统阻塞型),服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销。【简单示意图】
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+# Java BIO编程
+
+
+
+
+
+## I/O 模型
+
+
+
+1. `I/O` 模型简单的理解:就是用什么样的通道进行数据的发送和接收,很大程度上决定了程序通信的性能。
+2. `Java` 共支持 `3` 种网络编程模型 `I/O` 模式:`BIO`、`NIO`、`AIO`。
+3. `Java BIO`:同步并阻塞(传统阻塞型),服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销。【简单示意图】
+
+ +
+4. `Java NIO`:同步非阻塞,服务器实现模式为一个线程处理多个请求(连接),即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有 `I/O` 请求就进行处理。【简单示意图】
+
+
+
+4. `Java NIO`:同步非阻塞,服务器实现模式为一个线程处理多个请求(连接),即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有 `I/O` 请求就进行处理。【简单示意图】
+
+ +
+5. `Java AIO(NIO.2)`:异步非阻塞,`AIO` 引入异步通道的概念,采用了 `Proactor` 模式,简化了程序编写,有效的请求才启动线程,它的特点是先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用。
+6. 我们依次展开讲解。
+
+## BIO、NIO、AIO 使用场景分析
+
+1. `BIO` 方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,`JDK1.4` 以前的唯一选择,但程序简单易理解。
+2. `NIO` 方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,弹幕系统,服务器间通讯等。编程比较复杂,`JDK1.4` 开始支持。
+3. `AIO` 方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用 `OS` 参与并发操作,编程比较复杂,`JDK7` 开始支持。
+
+## Java BIO 基本介绍
+
+1. `Java BIO` 就是传统的 `Java I/O` 编程,其相关的类和接口在 `java.io`。
+2. `BIO(BlockingI/O)`:同步阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,可以通过线程池机制改善(实现多个客户连接服务器)。【后有应用实例】
+3. `BIO` 方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,`JDK1.4` 以前的唯一选择,程序简单易理解。
+
+## Java BIO 工作机制
+
+
+
+5. `Java AIO(NIO.2)`:异步非阻塞,`AIO` 引入异步通道的概念,采用了 `Proactor` 模式,简化了程序编写,有效的请求才启动线程,它的特点是先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用。
+6. 我们依次展开讲解。
+
+## BIO、NIO、AIO 使用场景分析
+
+1. `BIO` 方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,`JDK1.4` 以前的唯一选择,但程序简单易理解。
+2. `NIO` 方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,弹幕系统,服务器间通讯等。编程比较复杂,`JDK1.4` 开始支持。
+3. `AIO` 方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用 `OS` 参与并发操作,编程比较复杂,`JDK7` 开始支持。
+
+## Java BIO 基本介绍
+
+1. `Java BIO` 就是传统的 `Java I/O` 编程,其相关的类和接口在 `java.io`。
+2. `BIO(BlockingI/O)`:同步阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,可以通过线程池机制改善(实现多个客户连接服务器)。【后有应用实例】
+3. `BIO` 方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,`JDK1.4` 以前的唯一选择,程序简单易理解。
+
+## Java BIO 工作机制
+
+ +
+对 `BIO` 编程流程的梳理
+
+1. 服务器端启动一个 `ServerSocket`。
+2. 客户端启动 `Socket` 对服务器进行通信,默认情况下服务器端需要对每个客户建立一个线程与之通讯。
+3. 客户端发出请求后,先咨询服务器是否有线程响应,如果没有则会等待,或者被拒绝。
+4. 如果有响应,客户端线程会等待请求结束后,再继续执行。
+
+## Java BIO 应用实例
+
+实例说明:
+
+1. 使用 `BIO` 模型编写一个服务器端,监听 `6666` 端口,当有客户端连接时,就启动一个线程与之通讯。
+2. 要求使用线程池机制改善,可以连接多个客户端。
+3. 服务器端可以接收客户端发送的数据(`telnet` 方式即可)。
+4. 代码演示:
+
+```java
+package com.atguigu.bio;
+
+import java.io.InputStream;
+import java.net.ServerSocket;
+import java.net.Socket;
+import java.util.concurrent.ExecutorService;
+import java.util.concurrent.Executors;
+
+public class BIOServer {
+
+ public static void main(String[] args) throws Exception {
+ //线程池机制
+ //思路
+ //1. 创建一个线程池
+ //2. 如果有客户端连接,就创建一个线程,与之通讯(单独写一个方法)
+ ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
+ //创建ServerSocket
+ ServerSocket serverSocket = new ServerSocket(6666);
+ System.out.println("服务器启动了");
+ while (true) {
+ System.out.println("线程信息id = " + Thread.currentThread().getId() + "名字 = " + Thread.currentThread().getName());
+ //监听,等待客户端连接
+ System.out.println("等待连接....");
+ //会阻塞在accept()
+ final Socket socket = serverSocket.accept();
+ System.out.println("连接到一个客户端");
+ //就创建一个线程,与之通讯(单独写一个方法)
+ newCachedThreadPool.execute(new Runnable() {
+ public void run() {//我们重写
+ //可以和客户端通讯
+ handler(socket);
+ }
+ });
+ }
+ }
+
+ //编写一个handler方法,和客户端通讯
+ public static void handler(Socket socket) {
+ try {
+ System.out.println("线程信息id = " + Thread.currentThread().getId() + "名字 = " + Thread.currentThread().getName());
+ byte[] bytes = new byte[1024];
+ //通过socket获取输入流
+ InputStream inputStream = socket.getInputStream();
+ //循环的读取客户端发送的数据
+ while (true) {
+ System.out.println("线程信息id = " + Thread.currentThread().getId() + "名字 = " + Thread.currentThread().getName());
+ System.out.println("read....");
+ int read = inputStream.read(bytes);
+ if (read != -1) {
+ System.out.println(new String(bytes, 0, read));//输出客户端发送的数据
+ } else {
+ break;
+ }
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ System.out.println("关闭和client的连接");
+ try {
+ socket.close();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+ }
+}
+```
+
+
+
+对 `BIO` 编程流程的梳理
+
+1. 服务器端启动一个 `ServerSocket`。
+2. 客户端启动 `Socket` 对服务器进行通信,默认情况下服务器端需要对每个客户建立一个线程与之通讯。
+3. 客户端发出请求后,先咨询服务器是否有线程响应,如果没有则会等待,或者被拒绝。
+4. 如果有响应,客户端线程会等待请求结束后,再继续执行。
+
+## Java BIO 应用实例
+
+实例说明:
+
+1. 使用 `BIO` 模型编写一个服务器端,监听 `6666` 端口,当有客户端连接时,就启动一个线程与之通讯。
+2. 要求使用线程池机制改善,可以连接多个客户端。
+3. 服务器端可以接收客户端发送的数据(`telnet` 方式即可)。
+4. 代码演示:
+
+```java
+package com.atguigu.bio;
+
+import java.io.InputStream;
+import java.net.ServerSocket;
+import java.net.Socket;
+import java.util.concurrent.ExecutorService;
+import java.util.concurrent.Executors;
+
+public class BIOServer {
+
+ public static void main(String[] args) throws Exception {
+ //线程池机制
+ //思路
+ //1. 创建一个线程池
+ //2. 如果有客户端连接,就创建一个线程,与之通讯(单独写一个方法)
+ ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
+ //创建ServerSocket
+ ServerSocket serverSocket = new ServerSocket(6666);
+ System.out.println("服务器启动了");
+ while (true) {
+ System.out.println("线程信息id = " + Thread.currentThread().getId() + "名字 = " + Thread.currentThread().getName());
+ //监听,等待客户端连接
+ System.out.println("等待连接....");
+ //会阻塞在accept()
+ final Socket socket = serverSocket.accept();
+ System.out.println("连接到一个客户端");
+ //就创建一个线程,与之通讯(单独写一个方法)
+ newCachedThreadPool.execute(new Runnable() {
+ public void run() {//我们重写
+ //可以和客户端通讯
+ handler(socket);
+ }
+ });
+ }
+ }
+
+ //编写一个handler方法,和客户端通讯
+ public static void handler(Socket socket) {
+ try {
+ System.out.println("线程信息id = " + Thread.currentThread().getId() + "名字 = " + Thread.currentThread().getName());
+ byte[] bytes = new byte[1024];
+ //通过socket获取输入流
+ InputStream inputStream = socket.getInputStream();
+ //循环的读取客户端发送的数据
+ while (true) {
+ System.out.println("线程信息id = " + Thread.currentThread().getId() + "名字 = " + Thread.currentThread().getName());
+ System.out.println("read....");
+ int read = inputStream.read(bytes);
+ if (read != -1) {
+ System.out.println(new String(bytes, 0, read));//输出客户端发送的数据
+ } else {
+ break;
+ }
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ System.out.println("关闭和client的连接");
+ try {
+ socket.close();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+ }
+}
+```
+
+ +
+
+
+## 问题分析
+
+1. 每个请求都需要创建独立的线程,与对应的客户端进行数据 `Read`,业务处理,数据 `Write`。
+2. 当并发数较大时,需要创建大量线程来处理连接,系统资源占用较大。
+3. 连接建立后,如果当前线程暂时没有数据可读,则线程就阻塞在 `Read` 操作上,造成线程资源浪费。
+
+
+
+
+
+# Java NIO编程
+
+
+
+## Java NIO 基本介绍
+
+1. `Java NIO` 全称 `Java non-blocking IO`,是指 `JDK` 提供的新 `API`。从 `JDK1.4` 开始,`Java` 提供了一系列改进的输入/输出的新特性,被统称为 `NIO`(即 `NewIO`),是同步非阻塞的。
+2. `NIO` 相关类都被放在 `java.nio` 包及子包下,并且对原 `java.io` 包中的很多类进行改写。【基本案例】
+3. `NIO` 有三大核心部分:**`Channel`(通道)、`Buffer`(缓冲区)、`Selector`(选择器)** 。
+4. `NIO` 是**面向缓冲区,或者面向块编程**的。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动,这就增加了处理过程中的灵活性,使用它可以提供非阻塞式的高伸缩性网络。
+5. `Java NIO` 的非阻塞模式,使一个线程从某通道发送请求或者读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。非阻塞写也是如此,一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。【后面有案例说明】
+6. 通俗理解:`NIO` 是可以做到用一个线程来处理多个操作的。假设有 `10000` 个请求过来,根据实际情况,可以分配 `50` 或者 `100` 个线程来处理。不像之前的阻塞 `IO` 那样,非得分配 `10000` 个。
+7. `HTTP 2.0` 使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比 `HTTP 1.1` 大了好几个数量级。
+8. 案例说明 `NIO` 的 `Buffer`
+
+```java
+package com.atguigu.nio;
+
+import java.nio.IntBuffer;
+
+public class BasicBuffer {
+
+ public static void main(String[] args) {
+
+ //举例说明 Buffer 的使用(简单说明)
+ //创建一个 Buffer,大小为 5,即可以存放 5 个 int
+ IntBuffer intBuffer = IntBuffer.allocate(5);
+
+ //向buffer存放数据
+ //intBuffer.put(10);
+ //intBuffer.put(11);
+ //intBuffer.put(12);
+ //intBuffer.put(13);
+ //intBuffer.put(14);
+ for (int i = 0; i < intBuffer.capacity(); i++) {
+ intBuffer.put(i * 2);
+ }
+ //如何从 buffer 读取数据
+ //将 buffer 转换,读写切换(!!!)
+ intBuffer.flip();
+ while (intBuffer.hasRemaining()) {
+ System.out.println(intBuffer.get());
+ }
+ }
+}
+```
+
+
+
+## NIO 和 BIO 的比较
+
+1. `BIO` 以流的方式处理数据,而 `NIO` 以块的方式处理数据,块 `I/O` 的效率比流 `I/O` 高很多。
+2. `BIO` 是阻塞的,`NIO` 则是非阻塞的。
+3. `BIO` 基于字节流和字符流进行操作,而 `NIO` 基于 `Channel`(通道)和 `Buffer`(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。`Selector`(选择器)用于监听多个通道的事件(比如:连接请求,数据到达等),因此使用单个线程就可以监听多个客户端通道。
+4. Buffer和Channel之间的数据流向是双向的
+
+
+
+
+
+## 问题分析
+
+1. 每个请求都需要创建独立的线程,与对应的客户端进行数据 `Read`,业务处理,数据 `Write`。
+2. 当并发数较大时,需要创建大量线程来处理连接,系统资源占用较大。
+3. 连接建立后,如果当前线程暂时没有数据可读,则线程就阻塞在 `Read` 操作上,造成线程资源浪费。
+
+
+
+
+
+# Java NIO编程
+
+
+
+## Java NIO 基本介绍
+
+1. `Java NIO` 全称 `Java non-blocking IO`,是指 `JDK` 提供的新 `API`。从 `JDK1.4` 开始,`Java` 提供了一系列改进的输入/输出的新特性,被统称为 `NIO`(即 `NewIO`),是同步非阻塞的。
+2. `NIO` 相关类都被放在 `java.nio` 包及子包下,并且对原 `java.io` 包中的很多类进行改写。【基本案例】
+3. `NIO` 有三大核心部分:**`Channel`(通道)、`Buffer`(缓冲区)、`Selector`(选择器)** 。
+4. `NIO` 是**面向缓冲区,或者面向块编程**的。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动,这就增加了处理过程中的灵活性,使用它可以提供非阻塞式的高伸缩性网络。
+5. `Java NIO` 的非阻塞模式,使一个线程从某通道发送请求或者读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。非阻塞写也是如此,一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。【后面有案例说明】
+6. 通俗理解:`NIO` 是可以做到用一个线程来处理多个操作的。假设有 `10000` 个请求过来,根据实际情况,可以分配 `50` 或者 `100` 个线程来处理。不像之前的阻塞 `IO` 那样,非得分配 `10000` 个。
+7. `HTTP 2.0` 使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比 `HTTP 1.1` 大了好几个数量级。
+8. 案例说明 `NIO` 的 `Buffer`
+
+```java
+package com.atguigu.nio;
+
+import java.nio.IntBuffer;
+
+public class BasicBuffer {
+
+ public static void main(String[] args) {
+
+ //举例说明 Buffer 的使用(简单说明)
+ //创建一个 Buffer,大小为 5,即可以存放 5 个 int
+ IntBuffer intBuffer = IntBuffer.allocate(5);
+
+ //向buffer存放数据
+ //intBuffer.put(10);
+ //intBuffer.put(11);
+ //intBuffer.put(12);
+ //intBuffer.put(13);
+ //intBuffer.put(14);
+ for (int i = 0; i < intBuffer.capacity(); i++) {
+ intBuffer.put(i * 2);
+ }
+ //如何从 buffer 读取数据
+ //将 buffer 转换,读写切换(!!!)
+ intBuffer.flip();
+ while (intBuffer.hasRemaining()) {
+ System.out.println(intBuffer.get());
+ }
+ }
+}
+```
+
+
+
+## NIO 和 BIO 的比较
+
+1. `BIO` 以流的方式处理数据,而 `NIO` 以块的方式处理数据,块 `I/O` 的效率比流 `I/O` 高很多。
+2. `BIO` 是阻塞的,`NIO` 则是非阻塞的。
+3. `BIO` 基于字节流和字符流进行操作,而 `NIO` 基于 `Channel`(通道)和 `Buffer`(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。`Selector`(选择器)用于监听多个通道的事件(比如:连接请求,数据到达等),因此使用单个线程就可以监听多个客户端通道。
+4. Buffer和Channel之间的数据流向是双向的
+
+ +
+## NIO 三大核心原理示意图
+
+一张图描述 `NIO` 的 `Selector`、`Channel` 和 `Buffer` 的关系。
+
+### Selector、Channel 和 Buffer 关系图(简单版)
+
+关系图的说明:
+
+
+
+## NIO 三大核心原理示意图
+
+一张图描述 `NIO` 的 `Selector`、`Channel` 和 `Buffer` 的关系。
+
+### Selector、Channel 和 Buffer 关系图(简单版)
+
+关系图的说明:
+
+ +
+1. 每个 `Channel` 都会对应一个 `Buffer`。
+2. `Selector` 对应一个线程,一个线程对应多个 `Channel`(连接)。
+3. 该图反应了有三个 `Channel` 注册到该 `Selector` //程序
+4. 程序切换到哪个 `Channel` 是由事件决定的,`Event` 就是一个重要的概念。
+5. `Selector` 会根据不同的事件,在各个通道上切换。
+6. `Buffer` 就是一个内存块,底层是有一个数组。
+7. 数据的读取写入是通过 `Buffer`,这个和 `BIO`是不同的,`BIO` 中要么是输入流,或者是输出流,不能双向,但是 `NIO` 的 `Buffer` 是可以读也可以写,需要 `flip` 方法切换 `Channel` 是双向的,可以返回底层操作系统的情况,比如 `Linux`,底层的操作系统通道就是双向的。
+
+## 缓冲区(Buffer)
+
+### 基本介绍
+
+缓冲区(`Buffer`):缓冲区本质上是一个**可以读写数据的内存块**,可以理解成是一个**容器对象(含数组)**,该对象提供了一组方法,可以更轻松地使用内存块,,缓冲区对象内置了一些机制,能够跟踪和记录缓冲区的状态变化情况。`Channel` 提供从文件、网络读取数据的渠道,但是读取或写入的数据都必须经由 `Buffer`,如图:【后面举例说明】
+
+
+
+1. 每个 `Channel` 都会对应一个 `Buffer`。
+2. `Selector` 对应一个线程,一个线程对应多个 `Channel`(连接)。
+3. 该图反应了有三个 `Channel` 注册到该 `Selector` //程序
+4. 程序切换到哪个 `Channel` 是由事件决定的,`Event` 就是一个重要的概念。
+5. `Selector` 会根据不同的事件,在各个通道上切换。
+6. `Buffer` 就是一个内存块,底层是有一个数组。
+7. 数据的读取写入是通过 `Buffer`,这个和 `BIO`是不同的,`BIO` 中要么是输入流,或者是输出流,不能双向,但是 `NIO` 的 `Buffer` 是可以读也可以写,需要 `flip` 方法切换 `Channel` 是双向的,可以返回底层操作系统的情况,比如 `Linux`,底层的操作系统通道就是双向的。
+
+## 缓冲区(Buffer)
+
+### 基本介绍
+
+缓冲区(`Buffer`):缓冲区本质上是一个**可以读写数据的内存块**,可以理解成是一个**容器对象(含数组)**,该对象提供了一组方法,可以更轻松地使用内存块,,缓冲区对象内置了一些机制,能够跟踪和记录缓冲区的状态变化情况。`Channel` 提供从文件、网络读取数据的渠道,但是读取或写入的数据都必须经由 `Buffer`,如图:【后面举例说明】
+
+ +
+### Buffer 类及其子类
+
+1. 在 `NIO` 中,`Buffer` 是一个顶层父类,它是一个抽象类,类的层级关系图:
+
+
+
+### Buffer 类及其子类
+
+1. 在 `NIO` 中,`Buffer` 是一个顶层父类,它是一个抽象类,类的层级关系图:
+
+ +
+2. `Buffer` 类定义了所有的缓冲区都具有的四个属性来提供关于其所包含的数据元素的信息:
+
+
+
+2. `Buffer` 类定义了所有的缓冲区都具有的四个属性来提供关于其所包含的数据元素的信息:
+
+ +
+
+
+
+
+3. `Buffer` 类相关方法一览
+
+
+
+
+
+
+
+3. `Buffer` 类相关方法一览
+
+ +
+### ByteBuffer
+
+从前面可以看出对于 `Java` 中的基本数据类型(`boolean` 除外),都有一个 `Buffer` 类型与之相对应,最常用的自然是 `ByteBuffer` 类(二进制数据),该类的主要方法如下:
+
+
+
+### ByteBuffer
+
+从前面可以看出对于 `Java` 中的基本数据类型(`boolean` 除外),都有一个 `Buffer` 类型与之相对应,最常用的自然是 `ByteBuffer` 类(二进制数据),该类的主要方法如下:
+
+ +
+## 通道(Channel)
+
+### 基本介绍
+
+1. `NIO` 的通道类似于流,但有些区别如下:
+ - 通道可以同时进行读写,而流只能读或者只能写
+ - 通道可以实现异步读写数据
+ - 通道可以从缓冲读数据,也可以写数据到缓冲:
+2. `BIO` 中的 `Stream` 是单向的,例如 `FileInputStream` 对象只能进行读取数据的操作,而 `NIO` 中的通道(`Channel`)是双向的,可以读操作,也可以写操作。
+3. `Channel` 在 `NIO` 中是一个接口 `public interface Channel extends Closeable{}`
+4. 常用的 `Channel` 类有:**`FileChannel`、`DatagramChannel`、`ServerSocketChannel` 和 `SocketChannel`**。【`ServerSocketChanne` 类似 `ServerSocket`、`SocketChannel` 类似 `Socket`】
+5. `FileChannel` 用于文件的数据读写,`DatagramChannel` 用于 `UDP` 的数据读写,`ServerSocketChannel` 和 `SocketChannel` 用于 `TCP` 的数据读写。
+6. 图示
+
+
+
+## 通道(Channel)
+
+### 基本介绍
+
+1. `NIO` 的通道类似于流,但有些区别如下:
+ - 通道可以同时进行读写,而流只能读或者只能写
+ - 通道可以实现异步读写数据
+ - 通道可以从缓冲读数据,也可以写数据到缓冲:
+2. `BIO` 中的 `Stream` 是单向的,例如 `FileInputStream` 对象只能进行读取数据的操作,而 `NIO` 中的通道(`Channel`)是双向的,可以读操作,也可以写操作。
+3. `Channel` 在 `NIO` 中是一个接口 `public interface Channel extends Closeable{}`
+4. 常用的 `Channel` 类有:**`FileChannel`、`DatagramChannel`、`ServerSocketChannel` 和 `SocketChannel`**。【`ServerSocketChanne` 类似 `ServerSocket`、`SocketChannel` 类似 `Socket`】
+5. `FileChannel` 用于文件的数据读写,`DatagramChannel` 用于 `UDP` 的数据读写,`ServerSocketChannel` 和 `SocketChannel` 用于 `TCP` 的数据读写。
+6. 图示
+
+ +
+### FileChannel 类
+
+`FileChannel` 主要用来对本地文件进行 `IO` 操作,常见的方法有
+
+- `public int read(ByteBuffer dst)`,从通道读取数据并放到缓冲区中
+- `public int write(ByteBuffer src)`,把缓冲区的数据写到通道中
+- `public long transferFrom(ReadableByteChannel src, long position, long count)`,从目标通道中复制数据到当前通道
+- `public long transferTo(long position, long count, WritableByteChannel target)`,把数据从当前通道复制给目标通道
+
+### 应用实例1 - 本地文件写数据
+
+实例要求:
+
+1. 使用前面学习后的 `ByteBuffer`(缓冲)和 `FileChannel`(通道),将 "hello,尚硅谷" 写入到 `file01.txt` 中
+2. 文件不存在就创建
+3. 代码演示
+
+```java
+package com.atguigu.nio;
+
+import java.io.FileOutputStream;
+import java.nio.ByteBuffer;
+import java.nio.channels.FileChannel;
+
+public class NIOFileChannel01 {
+
+ public static void main(String[] args) throws Exception {
+ String str = "hello,尚硅谷";
+ //创建一个输出流 -> channel
+ FileOutputStream fileOutputStream = new FileOutputStream("d:\\file01.txt");
+
+ //通过 fileOutputStream 获取对应的 FileChannel
+ //这个 fileChannel 真实类型是 FileChannelImpl
+ FileChannel fileChannel = fileOutputStream.getChannel();
+
+ //创建一个缓冲区 ByteBuffer
+ ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
+
+ //将 str 放入 byteBuffer
+ byteBuffer.put(str.getBytes());
+
+ //对 byteBuffer 进行 flip
+ byteBuffer.flip();
+
+ //将 byteBuffer 数据写入到 fileChannel
+ fileChannel.write(byteBuffer);
+ fileOutputStream.close();
+ }
+}
+```
+
+### 应用实例2 - 本地文件读数据
+
+实例要求:
+
+1. 使用前面学习后的 `ByteBuffer`(缓冲)和 `FileChannel`(通道),将 `file01.txt` 中的数据读入到程序,并显示在控制台屏幕
+2. 假定文件已经存在
+3. 代码演示
+
+```java
+package com.atguigu.nio;
+
+import java.io.File;
+import java.io.FileInputStream;
+import java.nio.ByteBuffer;
+import java.nio.channels.FileChannel;
+
+public class NIOFileChannel02 {
+
+ public static void main(String[] args) throws Exception {
+
+ //创建文件的输入流
+ File file = new File("d:\\file01.txt");
+ FileInputStream fileInputStream = new FileInputStream(file);
+
+ //通过 fileInputStream 获取对应的 FileChannel -> 实际类型 FileChannelImpl
+ FileChannel fileChannel = fileInputStream.getChannel();
+
+ //创建缓冲区
+ ByteBuffer byteBuffer = ByteBuffer.allocate((int)file.length());
+
+ //将通道的数据读入到 Buffer
+ fileChannel.read(byteBuffer);
+
+ //将 byteBuffer 的字节数据转成 String
+ System.out.println(new String(byteBuffer.array()));
+ fileInputStream.close();
+ }
+}
+```
+
+### 应用实例3 - 使用一个 Buffer 完成文件读取、写入
+
+实例要求:
+
+1. 使用 `FileChannel`(通道)和方法 `read、write`,完成文件的拷贝
+2. 拷贝一个文本文件 `1.txt`,放在项目下即可
+3. 代码演示
+
+
+
+### FileChannel 类
+
+`FileChannel` 主要用来对本地文件进行 `IO` 操作,常见的方法有
+
+- `public int read(ByteBuffer dst)`,从通道读取数据并放到缓冲区中
+- `public int write(ByteBuffer src)`,把缓冲区的数据写到通道中
+- `public long transferFrom(ReadableByteChannel src, long position, long count)`,从目标通道中复制数据到当前通道
+- `public long transferTo(long position, long count, WritableByteChannel target)`,把数据从当前通道复制给目标通道
+
+### 应用实例1 - 本地文件写数据
+
+实例要求:
+
+1. 使用前面学习后的 `ByteBuffer`(缓冲)和 `FileChannel`(通道),将 "hello,尚硅谷" 写入到 `file01.txt` 中
+2. 文件不存在就创建
+3. 代码演示
+
+```java
+package com.atguigu.nio;
+
+import java.io.FileOutputStream;
+import java.nio.ByteBuffer;
+import java.nio.channels.FileChannel;
+
+public class NIOFileChannel01 {
+
+ public static void main(String[] args) throws Exception {
+ String str = "hello,尚硅谷";
+ //创建一个输出流 -> channel
+ FileOutputStream fileOutputStream = new FileOutputStream("d:\\file01.txt");
+
+ //通过 fileOutputStream 获取对应的 FileChannel
+ //这个 fileChannel 真实类型是 FileChannelImpl
+ FileChannel fileChannel = fileOutputStream.getChannel();
+
+ //创建一个缓冲区 ByteBuffer
+ ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
+
+ //将 str 放入 byteBuffer
+ byteBuffer.put(str.getBytes());
+
+ //对 byteBuffer 进行 flip
+ byteBuffer.flip();
+
+ //将 byteBuffer 数据写入到 fileChannel
+ fileChannel.write(byteBuffer);
+ fileOutputStream.close();
+ }
+}
+```
+
+### 应用实例2 - 本地文件读数据
+
+实例要求:
+
+1. 使用前面学习后的 `ByteBuffer`(缓冲)和 `FileChannel`(通道),将 `file01.txt` 中的数据读入到程序,并显示在控制台屏幕
+2. 假定文件已经存在
+3. 代码演示
+
+```java
+package com.atguigu.nio;
+
+import java.io.File;
+import java.io.FileInputStream;
+import java.nio.ByteBuffer;
+import java.nio.channels.FileChannel;
+
+public class NIOFileChannel02 {
+
+ public static void main(String[] args) throws Exception {
+
+ //创建文件的输入流
+ File file = new File("d:\\file01.txt");
+ FileInputStream fileInputStream = new FileInputStream(file);
+
+ //通过 fileInputStream 获取对应的 FileChannel -> 实际类型 FileChannelImpl
+ FileChannel fileChannel = fileInputStream.getChannel();
+
+ //创建缓冲区
+ ByteBuffer byteBuffer = ByteBuffer.allocate((int)file.length());
+
+ //将通道的数据读入到 Buffer
+ fileChannel.read(byteBuffer);
+
+ //将 byteBuffer 的字节数据转成 String
+ System.out.println(new String(byteBuffer.array()));
+ fileInputStream.close();
+ }
+}
+```
+
+### 应用实例3 - 使用一个 Buffer 完成文件读取、写入
+
+实例要求:
+
+1. 使用 `FileChannel`(通道)和方法 `read、write`,完成文件的拷贝
+2. 拷贝一个文本文件 `1.txt`,放在项目下即可
+3. 代码演示
+
+ +
+```java
+package com.atguigu.nio;
+
+import java.io.FileInputStream;
+import java.io.FileOutputStream;
+import java.nio.ByteBuffer;
+import java.nio.channels.FileChannel;
+
+public class NIOFileChannel03 {
+
+ public static void main(String[] args) throws Exception {
+
+ FileInputStream fileInputStream = new FileInputStream("1.txt");
+ FileChannel fileChannel01 = fileInputStream.getChannel();
+ FileOutputStream fileOutputStream = new FileOutputStream("2.txt");
+ FileChannel fileChannel02 = fileOutputStream.getChannel();
+
+ ByteBuffer byteBuffer = ByteBuffer.allocate(512);
+
+ while (true) { //循环读取
+
+ //这里有一个重要的操作,一定不要忘了
+ /*
+ public final Buffer clear() {
+ position = 0;
+ limit = capacity;
+ mark = -1;
+ return this;
+ }
+ */
+ byteBuffer.clear(); //清空 buffer
+ int read = fileChannel01.read(byteBuffer);
+ System.out.println("read = " + read);
+ if (read == -1) { //表示读完
+ break;
+ }
+
+ //将 buffer 中的数据写入到 fileChannel02--2.txt
+ byteBuffer.flip();
+ fileChannel02.write(byteBuffer);
+ }
+
+ //关闭相关的流
+ fileInputStream.close();
+ fileOutputStream.close();
+ }
+}
+```
+
+### 应用实例4 - 拷贝文件 transferFrom 方法
+
+1. 实例要求:
+2. 使用 `FileChannel`(通道)和方法 `transferFrom`,完成文件的拷贝
+3. 拷贝一张图片
+4. 代码演示
+
+```java
+package com.atguigu.nio;
+
+import java.io.FileInputStream;
+import java.io.FileOutputStream;
+import java.nio.channels.FileChannel;
+
+public class NIOFileChannel04 {
+
+ public static void main(String[] args) throws Exception {
+
+ //创建相关流
+ FileInputStream fileInputStream = new FileInputStream("d:\\a.jpg");
+ FileOutputStream fileOutputStream = new FileOutputStream("d:\\a2.jpg");
+
+ //获取各个流对应的 FileChannel
+ FileChannel sourceCh = fileInputStream.getChannel();
+ FileChannel destCh = fileOutputStream.getChannel();
+
+ //使用 transferForm 完成拷贝
+ destCh.transferFrom(sourceCh, 0, sourceCh.size());
+
+ //关闭相关通道和流
+ sourceCh.close();
+ destCh.close();
+ fileInputStream.close();
+ fileOutputStream.close();
+ }
+}
+```
+
+### 关于 Buffer 和 Channel 的注意事项和细节
+
+1. `ByteBuffer` 支持类型化的 `put` 和 `get`,`put` 放入的是什么数据类型,`get` 就应该使用相应的数据类型来取出,否则可能有 `BufferUnderflowException` 异常。【举例说明】
+
+```java
+package com.atguigu.nio;
+
+import java.nio.ByteBuffer;
+
+public class NIOByteBufferPutGet {
+
+ public static void main(String[] args) {
+
+ //创建一个 Buffer
+ ByteBuffer buffer = ByteBuffer.allocate(64);
+
+ //类型化方式放入数据
+ buffer.putInt(100);
+ buffer.putLong(9);
+ buffer.putChar('尚');
+ buffer.putShort((short) 4);
+
+ //取出
+ buffer.flip();
+
+ System.out.println();
+
+ System.out.println(buffer.getInt());
+ System.out.println(buffer.getLong());
+ System.out.println(buffer.getChar());
+ System.out.println(buffer.getShort());
+ }
+}
+```
+
+2. 可以将一个普通 `Buffer` 转成只读 `Buffer`【举例说明】
+
+```java
+package com.atguigu.nio;
+
+import java.nio.ByteBuffer;
+
+public class ReadOnlyBuffer {
+
+ public static void main(String[] args) {
+
+ //创建一个 buffer
+ ByteBuffer buffer = ByteBuffer.allocate(64);
+
+ for (int i = 0; i < 64; i++) {
+ buffer.put((byte) i);
+ }
+
+ //读取
+ buffer.flip();
+
+ //得到一个只读的 Buffer
+ ByteBuffer readOnlyBuffer = buffer.asReadOnlyBuffer();
+ System.out.println(readOnlyBuffer.getClass());
+
+ //读取
+ while (readOnlyBuffer.hasRemaining()) {
+ System.out.println(readOnlyBuffer.get());
+ }
+
+ readOnlyBuffer.put((byte) 100); //ReadOnlyBufferException
+ }
+}
+```
+
+3. `NIO` 还提供了 `MappedByteBuffer`,可以让文件直接在内存(堆外的内存)中进行修改,而如何同步到文件由 `NIO` 来完成。【举例说明】
+
+```java
+package com.atguigu.nio;
+
+import java.io.RandomAccessFile;
+import java.nio.MappedByteBuffer;
+import java.nio.channels.FileChannel;
+
+/**
+ * 说明 1.MappedByteBuffer 可让文件直接在内存(堆外内存)修改,操作系统不需要拷贝一次
+ */
+public class MappedByteBufferTest {
+
+ public static void main(String[] args) throws Exception {
+
+ RandomAccessFile randomAccessFile = new RandomAccessFile("1.txt", "rw");
+ //获取对应的通道
+ FileChannel channel = randomAccessFile.getChannel();
+
+ /**
+ * 参数 1:FileChannel.MapMode.READ_WRITE 使用的读写模式
+ * 参数 2:0:可以直接修改的起始位置
+ * 参数 3:5: 是映射到内存的大小(不是索引位置),即将 1.txt 的多少个字节映射到内存
+ * 可以直接修改的范围就是 0-5
+ * 实际类型 DirectByteBuffer
+ */
+ MappedByteBuffer mappedByteBuffer = channel.map(FileChannel.MapMode.READ_WRITE, 0, 5);
+
+ mappedByteBuffer.put(0, (byte) 'H');
+ mappedByteBuffer.put(3, (byte) '9');
+ mappedByteBuffer.put(5, (byte) 'Y');//IndexOutOfBoundsException
+
+ randomAccessFile.close();
+ System.out.println("修改成功~~");
+ }
+}
+```
+
+4. 前面我们讲的读写操作,都是通过一个 `Buffer` 完成的,`NIO` 还支持通过多个 `Buffer`(即 `Buffer`数组)完成读写操作,即 `Scattering` 和 `Gathering`【举例说明】
+
+```java
+package com.atguigu.nio;
+
+import java.net.InetSocketAddress;
+import java.nio.ByteBuffer;
+import java.nio.channels.ServerSocketChannel;
+import java.nio.channels.SocketChannel;
+import java.util.Arrays;
+
+/**
+ * Scattering:将数据写入到 buffer 时,可以采用 buffer 数组,依次写入 [分散]
+ * Gathering:从 buffer 读取数据时,可以采用 buffer 数组,依次读
+ */
+public class ScatteringAndGatheringTest {
+
+ public static void main(String[] args) throws Exception {
+
+ //使用 ServerSocketChannel 和 SocketChannel 网络
+ ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
+ InetSocketAddress inetSocketAddress = new InetSocketAddress(7000);
+
+ //绑定端口到 socket,并启动
+ serverSocketChannel.socket().bind(inetSocketAddress);
+
+ //创建 buffer 数组
+ ByteBuffer[] byteBuffers = new ByteBuffer[2];
+ byteBuffers[0] = ByteBuffer.allocate(5);
+ byteBuffers[1] = ByteBuffer.allocate(3);
+
+ //等客户端连接 (telnet)
+ SocketChannel socketChannel = serverSocketChannel.accept();
+
+ int messageLength = 8; //假定从客户端接收 8 个字节
+
+ //循环的读取
+ while (true) {
+ int byteRead = 0;
+
+ while (byteRead < messageLength) {
+ long l = socketChannel.read(byteBuffers);
+ byteRead += l; //累计读取的字节数
+ System.out.println("byteRead = " + byteRead);
+ //使用流打印,看看当前的这个 buffer 的 position 和 limit
+ Arrays.asList(byteBuffers).stream().map(buffer -> "position = " + buffer.position() + ", limit = " + buffer.limit()).forEach(System.out::println);
+ }
+
+ //将所有的 buffer 进行 flip
+ Arrays.asList(byteBuffers).forEach(buffer -> buffer.flip());
+ //将数据读出显示到客户端
+ long byteWirte = 0;
+ while (byteWirte < messageLength) {
+ long l = socketChannel.write(byteBuffers);//
+ byteWirte += l;
+ }
+
+ //将所有的buffer进行clear
+ Arrays.asList(byteBuffers).forEach(buffer -> {
+ buffer.clear();
+ });
+
+ System.out.println("byteRead = " + byteRead + ", byteWrite = " + byteWirte + ", messagelength = " + messageLength);
+ }
+ }
+}
+```
+
+## Selector(选择器)
+
+### 基本介绍
+
+1. `Java` 的 `NIO`,用非阻塞的 `IO` 方式。可以用一个线程,处理多个的客户端连接,就会使用到 `Selector`(选择器)。
+2. `Selector` 能够检测多个注册的通道上是否有事件发生(注意:多个 `Channel` 以事件的方式可以注册到同一个 `Selector`),如果有事件发生,便获取事件然后针对每个事件进行相应的处理。这样就可以只用一个单线程去管理多个通道,也就是管理多个连接和请求。
+3. 只有在连接/通道真正有读写事件发生时,才会进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程。
+4. 避免了多线程之间的上下文切换导致的开销。
+
+### Selector 示意图和特点说明
+
+
+
+```java
+package com.atguigu.nio;
+
+import java.io.FileInputStream;
+import java.io.FileOutputStream;
+import java.nio.ByteBuffer;
+import java.nio.channels.FileChannel;
+
+public class NIOFileChannel03 {
+
+ public static void main(String[] args) throws Exception {
+
+ FileInputStream fileInputStream = new FileInputStream("1.txt");
+ FileChannel fileChannel01 = fileInputStream.getChannel();
+ FileOutputStream fileOutputStream = new FileOutputStream("2.txt");
+ FileChannel fileChannel02 = fileOutputStream.getChannel();
+
+ ByteBuffer byteBuffer = ByteBuffer.allocate(512);
+
+ while (true) { //循环读取
+
+ //这里有一个重要的操作,一定不要忘了
+ /*
+ public final Buffer clear() {
+ position = 0;
+ limit = capacity;
+ mark = -1;
+ return this;
+ }
+ */
+ byteBuffer.clear(); //清空 buffer
+ int read = fileChannel01.read(byteBuffer);
+ System.out.println("read = " + read);
+ if (read == -1) { //表示读完
+ break;
+ }
+
+ //将 buffer 中的数据写入到 fileChannel02--2.txt
+ byteBuffer.flip();
+ fileChannel02.write(byteBuffer);
+ }
+
+ //关闭相关的流
+ fileInputStream.close();
+ fileOutputStream.close();
+ }
+}
+```
+
+### 应用实例4 - 拷贝文件 transferFrom 方法
+
+1. 实例要求:
+2. 使用 `FileChannel`(通道)和方法 `transferFrom`,完成文件的拷贝
+3. 拷贝一张图片
+4. 代码演示
+
+```java
+package com.atguigu.nio;
+
+import java.io.FileInputStream;
+import java.io.FileOutputStream;
+import java.nio.channels.FileChannel;
+
+public class NIOFileChannel04 {
+
+ public static void main(String[] args) throws Exception {
+
+ //创建相关流
+ FileInputStream fileInputStream = new FileInputStream("d:\\a.jpg");
+ FileOutputStream fileOutputStream = new FileOutputStream("d:\\a2.jpg");
+
+ //获取各个流对应的 FileChannel
+ FileChannel sourceCh = fileInputStream.getChannel();
+ FileChannel destCh = fileOutputStream.getChannel();
+
+ //使用 transferForm 完成拷贝
+ destCh.transferFrom(sourceCh, 0, sourceCh.size());
+
+ //关闭相关通道和流
+ sourceCh.close();
+ destCh.close();
+ fileInputStream.close();
+ fileOutputStream.close();
+ }
+}
+```
+
+### 关于 Buffer 和 Channel 的注意事项和细节
+
+1. `ByteBuffer` 支持类型化的 `put` 和 `get`,`put` 放入的是什么数据类型,`get` 就应该使用相应的数据类型来取出,否则可能有 `BufferUnderflowException` 异常。【举例说明】
+
+```java
+package com.atguigu.nio;
+
+import java.nio.ByteBuffer;
+
+public class NIOByteBufferPutGet {
+
+ public static void main(String[] args) {
+
+ //创建一个 Buffer
+ ByteBuffer buffer = ByteBuffer.allocate(64);
+
+ //类型化方式放入数据
+ buffer.putInt(100);
+ buffer.putLong(9);
+ buffer.putChar('尚');
+ buffer.putShort((short) 4);
+
+ //取出
+ buffer.flip();
+
+ System.out.println();
+
+ System.out.println(buffer.getInt());
+ System.out.println(buffer.getLong());
+ System.out.println(buffer.getChar());
+ System.out.println(buffer.getShort());
+ }
+}
+```
+
+2. 可以将一个普通 `Buffer` 转成只读 `Buffer`【举例说明】
+
+```java
+package com.atguigu.nio;
+
+import java.nio.ByteBuffer;
+
+public class ReadOnlyBuffer {
+
+ public static void main(String[] args) {
+
+ //创建一个 buffer
+ ByteBuffer buffer = ByteBuffer.allocate(64);
+
+ for (int i = 0; i < 64; i++) {
+ buffer.put((byte) i);
+ }
+
+ //读取
+ buffer.flip();
+
+ //得到一个只读的 Buffer
+ ByteBuffer readOnlyBuffer = buffer.asReadOnlyBuffer();
+ System.out.println(readOnlyBuffer.getClass());
+
+ //读取
+ while (readOnlyBuffer.hasRemaining()) {
+ System.out.println(readOnlyBuffer.get());
+ }
+
+ readOnlyBuffer.put((byte) 100); //ReadOnlyBufferException
+ }
+}
+```
+
+3. `NIO` 还提供了 `MappedByteBuffer`,可以让文件直接在内存(堆外的内存)中进行修改,而如何同步到文件由 `NIO` 来完成。【举例说明】
+
+```java
+package com.atguigu.nio;
+
+import java.io.RandomAccessFile;
+import java.nio.MappedByteBuffer;
+import java.nio.channels.FileChannel;
+
+/**
+ * 说明 1.MappedByteBuffer 可让文件直接在内存(堆外内存)修改,操作系统不需要拷贝一次
+ */
+public class MappedByteBufferTest {
+
+ public static void main(String[] args) throws Exception {
+
+ RandomAccessFile randomAccessFile = new RandomAccessFile("1.txt", "rw");
+ //获取对应的通道
+ FileChannel channel = randomAccessFile.getChannel();
+
+ /**
+ * 参数 1:FileChannel.MapMode.READ_WRITE 使用的读写模式
+ * 参数 2:0:可以直接修改的起始位置
+ * 参数 3:5: 是映射到内存的大小(不是索引位置),即将 1.txt 的多少个字节映射到内存
+ * 可以直接修改的范围就是 0-5
+ * 实际类型 DirectByteBuffer
+ */
+ MappedByteBuffer mappedByteBuffer = channel.map(FileChannel.MapMode.READ_WRITE, 0, 5);
+
+ mappedByteBuffer.put(0, (byte) 'H');
+ mappedByteBuffer.put(3, (byte) '9');
+ mappedByteBuffer.put(5, (byte) 'Y');//IndexOutOfBoundsException
+
+ randomAccessFile.close();
+ System.out.println("修改成功~~");
+ }
+}
+```
+
+4. 前面我们讲的读写操作,都是通过一个 `Buffer` 完成的,`NIO` 还支持通过多个 `Buffer`(即 `Buffer`数组)完成读写操作,即 `Scattering` 和 `Gathering`【举例说明】
+
+```java
+package com.atguigu.nio;
+
+import java.net.InetSocketAddress;
+import java.nio.ByteBuffer;
+import java.nio.channels.ServerSocketChannel;
+import java.nio.channels.SocketChannel;
+import java.util.Arrays;
+
+/**
+ * Scattering:将数据写入到 buffer 时,可以采用 buffer 数组,依次写入 [分散]
+ * Gathering:从 buffer 读取数据时,可以采用 buffer 数组,依次读
+ */
+public class ScatteringAndGatheringTest {
+
+ public static void main(String[] args) throws Exception {
+
+ //使用 ServerSocketChannel 和 SocketChannel 网络
+ ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
+ InetSocketAddress inetSocketAddress = new InetSocketAddress(7000);
+
+ //绑定端口到 socket,并启动
+ serverSocketChannel.socket().bind(inetSocketAddress);
+
+ //创建 buffer 数组
+ ByteBuffer[] byteBuffers = new ByteBuffer[2];
+ byteBuffers[0] = ByteBuffer.allocate(5);
+ byteBuffers[1] = ByteBuffer.allocate(3);
+
+ //等客户端连接 (telnet)
+ SocketChannel socketChannel = serverSocketChannel.accept();
+
+ int messageLength = 8; //假定从客户端接收 8 个字节
+
+ //循环的读取
+ while (true) {
+ int byteRead = 0;
+
+ while (byteRead < messageLength) {
+ long l = socketChannel.read(byteBuffers);
+ byteRead += l; //累计读取的字节数
+ System.out.println("byteRead = " + byteRead);
+ //使用流打印,看看当前的这个 buffer 的 position 和 limit
+ Arrays.asList(byteBuffers).stream().map(buffer -> "position = " + buffer.position() + ", limit = " + buffer.limit()).forEach(System.out::println);
+ }
+
+ //将所有的 buffer 进行 flip
+ Arrays.asList(byteBuffers).forEach(buffer -> buffer.flip());
+ //将数据读出显示到客户端
+ long byteWirte = 0;
+ while (byteWirte < messageLength) {
+ long l = socketChannel.write(byteBuffers);//
+ byteWirte += l;
+ }
+
+ //将所有的buffer进行clear
+ Arrays.asList(byteBuffers).forEach(buffer -> {
+ buffer.clear();
+ });
+
+ System.out.println("byteRead = " + byteRead + ", byteWrite = " + byteWirte + ", messagelength = " + messageLength);
+ }
+ }
+}
+```
+
+## Selector(选择器)
+
+### 基本介绍
+
+1. `Java` 的 `NIO`,用非阻塞的 `IO` 方式。可以用一个线程,处理多个的客户端连接,就会使用到 `Selector`(选择器)。
+2. `Selector` 能够检测多个注册的通道上是否有事件发生(注意:多个 `Channel` 以事件的方式可以注册到同一个 `Selector`),如果有事件发生,便获取事件然后针对每个事件进行相应的处理。这样就可以只用一个单线程去管理多个通道,也就是管理多个连接和请求。
+3. 只有在连接/通道真正有读写事件发生时,才会进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程。
+4. 避免了多线程之间的上下文切换导致的开销。
+
+### Selector 示意图和特点说明
+
+ +
+说明如下:
+
+1. `Netty` 的 `IO` 线程 `NioEventLoop` 聚合了 `Selector`(选择器,也叫多路复用器),可以同时并发处理成百上千个客户端连接。
+2. 当线程从某客户端 `Socket` 通道进行读写数据时,若没有数据可用时,该线程可以进行其他任务。
+3. 线程通常将非阻塞 `IO` 的空闲时间用于在其他通道上执行 `IO` 操作,所以单独的线程可以管理多个输入和输出通道。
+4. 由于读写操作都是非阻塞的,这就可以充分提升 `IO` 线程的运行效率,避免由于频繁 `I/O` 阻塞导致的线程挂起。
+5. 一个 `I/O` 线程可以并发处理 `N` 个客户端连接和读写操作,这从根本上解决了传统同步阻塞 `I/O` 一连接一线程模型,架构的性能、弹性伸缩能力和可靠性都得到了极大的提升。
+
+### Selector 类相关方法
+
+
+
+说明如下:
+
+1. `Netty` 的 `IO` 线程 `NioEventLoop` 聚合了 `Selector`(选择器,也叫多路复用器),可以同时并发处理成百上千个客户端连接。
+2. 当线程从某客户端 `Socket` 通道进行读写数据时,若没有数据可用时,该线程可以进行其他任务。
+3. 线程通常将非阻塞 `IO` 的空闲时间用于在其他通道上执行 `IO` 操作,所以单独的线程可以管理多个输入和输出通道。
+4. 由于读写操作都是非阻塞的,这就可以充分提升 `IO` 线程的运行效率,避免由于频繁 `I/O` 阻塞导致的线程挂起。
+5. 一个 `I/O` 线程可以并发处理 `N` 个客户端连接和读写操作,这从根本上解决了传统同步阻塞 `I/O` 一连接一线程模型,架构的性能、弹性伸缩能力和可靠性都得到了极大的提升。
+
+### Selector 类相关方法
+
+ +
+### 注意事项
+
+1. `NIO` 中的 `ServerSocketChannel` 功能类似 `ServerSocket`、`SocketChannel` 功能类似 `Socket`。
+2. `Selector` 相关方法说明
+ - `selector.select();` //阻塞
+ - `selector.select(1000);` //阻塞 1000 毫秒,在 1000 毫秒后返回
+ - `selector.wakeup();` //唤醒 selector
+ - `selector.selectNow();` //不阻塞,立马返还
+
+## NIO 非阻塞网络编程原理分析图
+
+`NIO` 非阻塞网络编程相关的(`Selector`、`SelectionKey`、`ServerScoketChannel` 和 `SocketChannel`)关系梳理图
+
+
+
+### 注意事项
+
+1. `NIO` 中的 `ServerSocketChannel` 功能类似 `ServerSocket`、`SocketChannel` 功能类似 `Socket`。
+2. `Selector` 相关方法说明
+ - `selector.select();` //阻塞
+ - `selector.select(1000);` //阻塞 1000 毫秒,在 1000 毫秒后返回
+ - `selector.wakeup();` //唤醒 selector
+ - `selector.selectNow();` //不阻塞,立马返还
+
+## NIO 非阻塞网络编程原理分析图
+
+`NIO` 非阻塞网络编程相关的(`Selector`、`SelectionKey`、`ServerScoketChannel` 和 `SocketChannel`)关系梳理图
+
+ +
+对上图的说明:
+
+1. 当客户端连接时,会通过 `ServerSocketChannel` 得到 `SocketChannel`。
+2. `Selector` 进行监听 `select` 方法,返回有事件发生的通道的个数。
+3. 将 `socketChannel` 注册到 `Selector` 上,`register(Selector sel, int ops)`,一个 `Selector` 上可以注册多个 `SocketChannel`。
+4. 注册后返回一个 `SelectionKey`,会和该 `Selector` 关联(集合)。
+5. 进一步得到各个 `SelectionKey`(有事件发生)。
+6. 在通过 `SelectionKey` 反向获取 `SocketChannel`,方法 `channel()`。
+7. 可以通过得到的 `channel`,完成业务处理。
+8. 直接看后面代码吧
+
+## NIO 非阻塞网络编程快速入门
+
+案例:
+
+1. 编写一个 `NIO` 入门案例,实现服务器端和客户端之间的数据简单通讯(非阻塞)
+2. 目的:理解 `NIO` 非阻塞网络编程机制
+
+
+
+```java
+package com.atguigu.nio;
+
+import java.net.InetSocketAddress;
+import java.nio.ByteBuffer;
+import java.nio.channels.*;
+import java.util.Iterator;
+import java.util.Set;
+
+public class NIOServer {
+ public static void main(String[] args) throws Exception{
+
+ //创建ServerSocketChannel -> ServerSocket
+
+ ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
+
+ //得到一个Selecor对象
+ Selector selector = Selector.open();
+
+ //绑定一个端口6666, 在服务器端监听
+ serverSocketChannel.socket().bind(new InetSocketAddress(6666));
+ //设置为非阻塞
+ serverSocketChannel.configureBlocking(false);
+
+ //把 serverSocketChannel 注册到 selector 关心 事件为 OP_ACCEPT pos_1
+ serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
+
+ System.out.println("注册后的selectionkey 数量=" + selector.keys().size()); // 1
+
+
+
+ //循环等待客户端连接
+ while (true) {
+
+ //这里我们等待1秒,如果没有事件发生, 返回
+ if(selector.select(1000) == 0) { //没有事件发生
+ System.out.println("服务器等待了1秒,无连接");
+ continue;
+ }
+
+ //如果返回的>0, 就获取到相关的 selectionKey集合
+ //1.如果返回的>0, 表示已经获取到关注的事件
+ //2. selector.selectedKeys() 返回关注事件的集合
+ // 通过 selectionKeys 反向获取通道
+ Set selectionKeys = selector.selectedKeys();
+ System.out.println("selectionKeys 数量 = " + selectionKeys.size());
+
+ //遍历 Set, 使用迭代器遍历
+ Iterator keyIterator = selectionKeys.iterator();
+
+ while (keyIterator.hasNext()) {
+ //获取到SelectionKey
+ SelectionKey key = keyIterator.next();
+ //根据key 对应的通道发生的事件做相应处理
+ if(key.isAcceptable()) { //如果是 OP_ACCEPT, 有新的客户端连接
+ //该该客户端生成一个 SocketChannel
+ SocketChannel socketChannel = serverSocketChannel.accept();
+ System.out.println("客户端连接成功 生成了一个 socketChannel " + socketChannel.hashCode());
+ //将 SocketChannel 设置为非阻塞
+ socketChannel.configureBlocking(false);
+ //将socketChannel 注册到selector, 关注事件为 OP_READ, 同时给socketChannel
+ //关联一个Buffer
+ socketChannel.register(selector, SelectionKey.OP_READ, ByteBuffer.allocate(1024));
+
+ System.out.println("客户端连接后 ,注册的selectionkey 数量=" + selector.keys().size()); //2,3,4..
+
+
+ }
+ if(key.isReadable()) { //发生 OP_READ
+
+ //通过key 反向获取到对应channel
+ SocketChannel channel = (SocketChannel)key.channel();
+
+ //获取到该channel关联的buffer
+ ByteBuffer buffer = (ByteBuffer)key.attachment();
+ channel.read(buffer);
+ System.out.println("form 客户端 " + new String(buffer.array()));
+
+ }
+
+ //手动从集合中移动当前的selectionKey, 防止重复操作
+ keyIterator.remove();
+
+ }
+
+ }
+
+ }
+}
+
+```
+
+
+
+
+> pos1:
+>
+> 1、对操作系统有一定了解的同学,就会大概知道这里监听的是一个Accept通道。这个通道的
+> 作用就是监听,实际建立连接了还会有一个通道。
+> 2、简单说一下为什么。因为客户端发请求的时候,服务器这边是肯定要先有一个监听通道,
+> 监听某个端口是否有客户端要建立链接,如果有客户端想要建立链接,那么会再创建一个和
+> 客户端真正通信的通道。
+> 3、如果有其它客户端还想要建立链接,这个Accept监听端口监听到了,就会再创建几个真正
+> 的通信通道。
+> 4、也就是Server的一个端口可以建立多个TCP连接,因为IP层协议通过
+> 目标地址+端口+源地址+源端口四个信息识别一个上下文
+>
+> **顺便插一句嘴:因为学netty的过程中,发现计算机网络和操作系统蛮重要的,所以接下来会写几篇这方面的文章**
+
+
+
+```java
+package com.atguigu.nio;
+
+import java.net.InetSocketAddress;
+import java.nio.ByteBuffer;
+import java.nio.channels.SocketChannel;
+
+public class NIOClient {
+ public static void main(String[] args) throws Exception{
+
+ //得到一个网络通道
+ SocketChannel socketChannel = SocketChannel.open();
+ //设置非阻塞
+ socketChannel.configureBlocking(false);
+ //提供服务器端的ip 和 端口
+ InetSocketAddress inetSocketAddress = new InetSocketAddress("127.0.0.1", 6666);
+ //连接服务器
+ if (!socketChannel.connect(inetSocketAddress)) {
+
+ while (!socketChannel.finishConnect()) {
+ System.out.println("因为连接需要时间,客户端不会阻塞,可以做其它工作..");
+ }
+ }
+
+ //...如果连接成功,就发送数据
+ String str = "hello, 尚硅谷~";
+ //Wraps a byte array into a buffer
+ ByteBuffer buffer = ByteBuffer.wrap(str.getBytes());
+ //发送数据,将 buffer 数据写入 channel
+ socketChannel.write(buffer);
+ System.in.read();
+
+ }
+}
+```
+
+实际执行效果可以复制代码去试下
+
+### SelectionKey
+
+1. `SelectionKey`,表示 `Selector` 和网络通道的注册关系,共四种:
+ - `int OP_ACCEPT`:有新的网络连接可以 `accept`,值为 `16`
+ - `int OP_CONNECT`:代表连接已经建立,值为 `8`
+ - `int OP_READ`:代表读操作,值为 `1`
+ - `int OP_WRITE`:代表写操作,值为 `4`
+
+源码中:
+
+```java
+public static final int OP_READ = 1 << 0;
+public static final int OP_WRITE = 1 << 2;
+public static final int OP_CONNECT = 1 << 3;
+public static final int OP_ACCEPT = 1 << 4;
+```
+
+2. `SelectionKey` 相关方法
+
+
+
+对上图的说明:
+
+1. 当客户端连接时,会通过 `ServerSocketChannel` 得到 `SocketChannel`。
+2. `Selector` 进行监听 `select` 方法,返回有事件发生的通道的个数。
+3. 将 `socketChannel` 注册到 `Selector` 上,`register(Selector sel, int ops)`,一个 `Selector` 上可以注册多个 `SocketChannel`。
+4. 注册后返回一个 `SelectionKey`,会和该 `Selector` 关联(集合)。
+5. 进一步得到各个 `SelectionKey`(有事件发生)。
+6. 在通过 `SelectionKey` 反向获取 `SocketChannel`,方法 `channel()`。
+7. 可以通过得到的 `channel`,完成业务处理。
+8. 直接看后面代码吧
+
+## NIO 非阻塞网络编程快速入门
+
+案例:
+
+1. 编写一个 `NIO` 入门案例,实现服务器端和客户端之间的数据简单通讯(非阻塞)
+2. 目的:理解 `NIO` 非阻塞网络编程机制
+
+
+
+```java
+package com.atguigu.nio;
+
+import java.net.InetSocketAddress;
+import java.nio.ByteBuffer;
+import java.nio.channels.*;
+import java.util.Iterator;
+import java.util.Set;
+
+public class NIOServer {
+ public static void main(String[] args) throws Exception{
+
+ //创建ServerSocketChannel -> ServerSocket
+
+ ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
+
+ //得到一个Selecor对象
+ Selector selector = Selector.open();
+
+ //绑定一个端口6666, 在服务器端监听
+ serverSocketChannel.socket().bind(new InetSocketAddress(6666));
+ //设置为非阻塞
+ serverSocketChannel.configureBlocking(false);
+
+ //把 serverSocketChannel 注册到 selector 关心 事件为 OP_ACCEPT pos_1
+ serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
+
+ System.out.println("注册后的selectionkey 数量=" + selector.keys().size()); // 1
+
+
+
+ //循环等待客户端连接
+ while (true) {
+
+ //这里我们等待1秒,如果没有事件发生, 返回
+ if(selector.select(1000) == 0) { //没有事件发生
+ System.out.println("服务器等待了1秒,无连接");
+ continue;
+ }
+
+ //如果返回的>0, 就获取到相关的 selectionKey集合
+ //1.如果返回的>0, 表示已经获取到关注的事件
+ //2. selector.selectedKeys() 返回关注事件的集合
+ // 通过 selectionKeys 反向获取通道
+ Set selectionKeys = selector.selectedKeys();
+ System.out.println("selectionKeys 数量 = " + selectionKeys.size());
+
+ //遍历 Set, 使用迭代器遍历
+ Iterator keyIterator = selectionKeys.iterator();
+
+ while (keyIterator.hasNext()) {
+ //获取到SelectionKey
+ SelectionKey key = keyIterator.next();
+ //根据key 对应的通道发生的事件做相应处理
+ if(key.isAcceptable()) { //如果是 OP_ACCEPT, 有新的客户端连接
+ //该该客户端生成一个 SocketChannel
+ SocketChannel socketChannel = serverSocketChannel.accept();
+ System.out.println("客户端连接成功 生成了一个 socketChannel " + socketChannel.hashCode());
+ //将 SocketChannel 设置为非阻塞
+ socketChannel.configureBlocking(false);
+ //将socketChannel 注册到selector, 关注事件为 OP_READ, 同时给socketChannel
+ //关联一个Buffer
+ socketChannel.register(selector, SelectionKey.OP_READ, ByteBuffer.allocate(1024));
+
+ System.out.println("客户端连接后 ,注册的selectionkey 数量=" + selector.keys().size()); //2,3,4..
+
+
+ }
+ if(key.isReadable()) { //发生 OP_READ
+
+ //通过key 反向获取到对应channel
+ SocketChannel channel = (SocketChannel)key.channel();
+
+ //获取到该channel关联的buffer
+ ByteBuffer buffer = (ByteBuffer)key.attachment();
+ channel.read(buffer);
+ System.out.println("form 客户端 " + new String(buffer.array()));
+
+ }
+
+ //手动从集合中移动当前的selectionKey, 防止重复操作
+ keyIterator.remove();
+
+ }
+
+ }
+
+ }
+}
+
+```
+
+
+
+
+> pos1:
+>
+> 1、对操作系统有一定了解的同学,就会大概知道这里监听的是一个Accept通道。这个通道的
+> 作用就是监听,实际建立连接了还会有一个通道。
+> 2、简单说一下为什么。因为客户端发请求的时候,服务器这边是肯定要先有一个监听通道,
+> 监听某个端口是否有客户端要建立链接,如果有客户端想要建立链接,那么会再创建一个和
+> 客户端真正通信的通道。
+> 3、如果有其它客户端还想要建立链接,这个Accept监听端口监听到了,就会再创建几个真正
+> 的通信通道。
+> 4、也就是Server的一个端口可以建立多个TCP连接,因为IP层协议通过
+> 目标地址+端口+源地址+源端口四个信息识别一个上下文
+>
+> **顺便插一句嘴:因为学netty的过程中,发现计算机网络和操作系统蛮重要的,所以接下来会写几篇这方面的文章**
+
+
+
+```java
+package com.atguigu.nio;
+
+import java.net.InetSocketAddress;
+import java.nio.ByteBuffer;
+import java.nio.channels.SocketChannel;
+
+public class NIOClient {
+ public static void main(String[] args) throws Exception{
+
+ //得到一个网络通道
+ SocketChannel socketChannel = SocketChannel.open();
+ //设置非阻塞
+ socketChannel.configureBlocking(false);
+ //提供服务器端的ip 和 端口
+ InetSocketAddress inetSocketAddress = new InetSocketAddress("127.0.0.1", 6666);
+ //连接服务器
+ if (!socketChannel.connect(inetSocketAddress)) {
+
+ while (!socketChannel.finishConnect()) {
+ System.out.println("因为连接需要时间,客户端不会阻塞,可以做其它工作..");
+ }
+ }
+
+ //...如果连接成功,就发送数据
+ String str = "hello, 尚硅谷~";
+ //Wraps a byte array into a buffer
+ ByteBuffer buffer = ByteBuffer.wrap(str.getBytes());
+ //发送数据,将 buffer 数据写入 channel
+ socketChannel.write(buffer);
+ System.in.read();
+
+ }
+}
+```
+
+实际执行效果可以复制代码去试下
+
+### SelectionKey
+
+1. `SelectionKey`,表示 `Selector` 和网络通道的注册关系,共四种:
+ - `int OP_ACCEPT`:有新的网络连接可以 `accept`,值为 `16`
+ - `int OP_CONNECT`:代表连接已经建立,值为 `8`
+ - `int OP_READ`:代表读操作,值为 `1`
+ - `int OP_WRITE`:代表写操作,值为 `4`
+
+源码中:
+
+```java
+public static final int OP_READ = 1 << 0;
+public static final int OP_WRITE = 1 << 2;
+public static final int OP_CONNECT = 1 << 3;
+public static final int OP_ACCEPT = 1 << 4;
+```
+
+2. `SelectionKey` 相关方法
+
+ +
+### ServerSocketChannel
+
+1. `ServerSocketChannel` 在服务器端监听新的客户端 `Socket` 连接,负责监听,不负责实际的读写操作
+2. 相关方法如下
+
+
+
+### ServerSocketChannel
+
+1. `ServerSocketChannel` 在服务器端监听新的客户端 `Socket` 连接,负责监听,不负责实际的读写操作
+2. 相关方法如下
+
+ +
+### SocketChannel
+
+1. `SocketChannel`,网络 `IO` 通道,**具体负责进行读写操作**。`NIO` 把缓冲区的数据写入通道,或者把通道里的数据读到缓冲区。
+2. 相关方法如下
+
+
+
+### SocketChannel
+
+1. `SocketChannel`,网络 `IO` 通道,**具体负责进行读写操作**。`NIO` 把缓冲区的数据写入通道,或者把通道里的数据读到缓冲区。
+2. 相关方法如下
+
+ +
+## NIO网络编程应用实例 - 群聊系统
+
+实例要求:
+
+1. 编写一个 `NIO` 群聊系统,实现服务器端和客户端之间的数据简单通讯(非阻塞)
+2. 实现多人群聊
+3. 服务器端:可以监测用户上线,离线,并实现消息转发功能
+4. 客户端:通过 `Channel` 可以无阻塞发送消息给其它所有用户,同时可以接受其它用户发送的消息(有服务器转发得到)
+5. 目的:进一步理解 `NIO` 非阻塞网络编程机制
+6. 示意图分析和代码
+
+
+
+## NIO网络编程应用实例 - 群聊系统
+
+实例要求:
+
+1. 编写一个 `NIO` 群聊系统,实现服务器端和客户端之间的数据简单通讯(非阻塞)
+2. 实现多人群聊
+3. 服务器端:可以监测用户上线,离线,并实现消息转发功能
+4. 客户端:通过 `Channel` 可以无阻塞发送消息给其它所有用户,同时可以接受其它用户发送的消息(有服务器转发得到)
+5. 目的:进一步理解 `NIO` 非阻塞网络编程机制
+6. 示意图分析和代码
+
+ +
+代码:
+
+```java
+
+// 服务端:
+
+package com.atguigu.nio.groupchat;
+
+import java.io.IOException;
+import java.net.InetSocketAddress;
+import java.nio.ByteBuffer;
+import java.nio.channels.Channel;
+import java.nio.channels.SelectionKey;
+import java.nio.channels.Selector;
+import java.nio.channels.ServerSocketChannel;
+import java.nio.channels.SocketChannel;
+import java.util.Iterator;
+
+public class GroupChatServer {
+
+ //定义属性
+ private Selector selector;
+ private ServerSocketChannel listenChannel;
+
+ private static final int PORT = 6667;
+
+ //构造器
+ //初始化工作
+ public GroupChatServer() {
+ try {
+ //得到选择器
+ selector = Selector.open();
+ //ServerSocketChannel
+ listenChannel = ServerSocketChannel.open();
+ //绑定端口
+ listenChannel.socket().bind(new InetSocketAddress(PORT));
+ //设置非阻塞模式
+ listenChannel.configureBlocking(false);
+ //将该 listenChannel 注册到 selector
+ listenChannel.register(selector, SelectionKey.OP_ACCEPT);
+ } catch (IOException e) {
+ e.printStackTrace();
+ }
+ }
+
+ public void listen() {
+ try {
+ //循环处理
+ while (true) {
+ int count = selector.select();
+ if (count > 0) { //有事件处理
+ // 遍历得到 selectionKey 集合
+ Iterator iterator = selector.selectedKeys().iterator();
+ while (iterator.hasNext()) {
+ //取出 selectionkey
+ SelectionKey key = iterator.next();
+ //监听到 accept
+ if (key.isAcceptable()) {
+ SocketChannel sc = listenChannel.accept();
+ sc.configureBlocking(false);
+ //将该 sc 注册到 seletor
+ sc.register(selector, SelectionKey.OP_READ);
+ //提示
+ System.out.println(sc.getRemoteAddress() + " 上线 ");
+ }
+ if (key.isReadable()) {//通道发送read事件,即通道是可读的状态
+ // 处理读(专门写方法..)
+ readData(key);
+ }
+ //当前的 key 删除,防止重复处理
+ iterator.remove();
+ }
+ } else {
+ System.out.println("等待....");
+ }
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ //发生异常处理....
+ }
+ }
+
+ //读取客户端消息
+ public void readData(SelectionKey key) {
+ SocketChannel channel = null;
+ try {
+ //得到 channel
+ channel = (SocketChannel) key.channel();
+ //创建 buffer
+ ByteBuffer buffer = ByteBuffer.allocate(1024);
+ int count = channel.read(buffer);
+ //根据 count 的值做处理
+ if (count > 0) {
+ //把缓存区的数据转成字符串
+ String msg = new String(buffer.array());
+ //输出该消息
+ System.out.println("form客户端:" + msg);
+ //向其它的客户端转发消息(去掉自己),专门写一个方法来处理
+ sendInfoToOtherClients(msg, channel);
+ }
+ } catch (IOException e) {
+ try {
+ System.out.println(channel.getRemoteAddress() + "离线了..");
+ //取消注册
+ key.cancel();
+ //关闭通道
+ channel.close();
+ } catch (IOException e2) {
+ e2.printStackTrace();
+ }
+ }
+ }
+
+ //转发消息给其它客户(通道)
+ private void sendInfoToOtherClients(String msg, SocketChannel self) throws IOException {
+
+ System.out.println("服务器转发消息中...");
+ //遍历所有注册到 selector 上的 SocketChannel,并排除 self
+ for (SelectionKey key : selector.keys()) {
+ //通过 key 取出对应的 SocketChannel
+ Channel targetChannel = key.channel();
+ //排除自己
+ if (targetChannel instanceof SocketChannel && targetChannel != self) {
+ //转型
+ SocketChannel dest = (SocketChannel) targetChannel;
+ //将 msg 存储到 buffer
+ ByteBuffer buffer = ByteBuffer.wrap(msg.getBytes());
+ //将 buffer 的数据写入通道
+ dest.write(buffer);
+ }
+ }
+ }
+
+ public static void main(String[] args) {
+ //创建服务器对象
+ GroupChatServer groupChatServer = new GroupChatServer();
+ groupChatServer.listen();
+ }
+}
+
+// 客户端:
+
+package com.atguigu.nio.groupchat;
+
+import java.io.IOException;
+import java.net.InetSocketAddress;
+import java.nio.ByteBuffer;
+import java.nio.channels.SelectionKey;
+import java.nio.channels.Selector;
+import java.nio.channels.SocketChannel;
+import java.util.Iterator;
+import java.util.Scanner;
+
+public class GroupChatClient {
+
+ //定义相关的属性
+ private final String HOST = "127.0.0.1";//服务器的ip
+ private final int PORT = 6667;//服务器端口
+ private Selector selector;
+ private SocketChannel socketChannel;
+ private String username;
+
+ //构造器,完成初始化工作
+ public GroupChatClient() throws IOException {
+
+ selector = Selector.open();
+ //连接服务器
+ socketChannel = SocketChannel.open(new InetSocketAddress(HOST, PORT));
+ //设置非阻塞
+ socketChannel.configureBlocking(false);
+ //将 channel 注册到selector
+ socketChannel.register(selector, SelectionKey.OP_READ);
+ //得到 username
+ username = socketChannel.getLocalAddress().toString().substring(1);
+ System.out.println(username + " is ok...");
+ }
+
+ //向服务器发送消息
+ public void sendInfo(String info) {
+ info = username + " 说:" + info;
+ try {
+ socketChannel.write(ByteBuffer.wrap(info.getBytes()));
+ } catch (IOException e) {
+ e.printStackTrace();
+ }
+ }
+
+ //读取从服务器端回复的消息
+ public void readInfo() {
+ try {
+ int readChannels = selector.select();
+ if (readChannels > 0) {//有可以用的通道
+ Iterator iterator = selector.selectedKeys().iterator();
+ while (iterator.hasNext()) {
+ SelectionKey key = iterator.next();
+ if (key.isReadable()) {
+ //得到相关的通道
+ SocketChannel sc = (SocketChannel) key.channel();
+ //得到一个 Buffer
+ ByteBuffer buffer = ByteBuffer.allocate(1024);
+ //读取
+ sc.read(buffer);
+ //把读到的缓冲区的数据转成字符串
+ String msg = new String(buffer.array());
+ System.out.println(msg.trim());
+ }
+ }
+ iterator.remove(); //删除当前的 selectionKey,防止重复操作
+ } else {
+ //System.out.println("没有可以用的通道...");
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+
+ public static void main(String[] args) throws Exception {
+
+ //启动我们客户端
+ GroupChatClient chatClient = new GroupChatClient();
+ //启动一个线程,每个 3 秒,读取从服务器发送数据
+ new Thread() {
+ public void run() {
+ while (true) {
+ chatClient.readInfo();
+ try {
+ Thread.currentThread().sleep(3000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+ }.start();
+
+ //发送数据给服务器端
+ Scanner scanner = new Scanner(System.in);
+ while (scanner.hasNextLine()) {
+ String s = scanner.nextLine();
+ chatClient.sendInfo(s);
+ }
+ }
+}
+```
+
+## NIO与零拷贝
+
+> 1、尚硅谷这里的零拷贝感觉讲的感觉有点问题,但是为了笔记的完整性,任然保留了这里的笔记。不过笔者考虑再写一篇零拷贝。
+>
+> 2、而且这里课件的图也看不太清
+>
+> 3、读者可以将我写的零拷贝和尚硅谷这里讲的零拷贝对照着看,取长补短
+
+### 零拷贝基本介绍
+
+1. 零拷贝是网络编程的关键,很多性能优化都离不开。
+2. 在 `Java` 程序中,常用的零拷贝有 `mmap`(内存映射)和 `sendFile`。那么,他们在 `OS` 里,到底是怎么样的一个的设计?我们分析 `mmap` 和 `sendFile` 这两个零拷贝
+3. 另外我们看下 `NIO` 中如何使用零拷贝
+
+### 传统 IO 数据读写
+
+`Java` 传统 `IO` 和网络编程的一段代码
+
+```java
+File file = new File("test.txt");
+RandomAccessFile raf = new RandomAccessFile(file, "rw");
+
+byte[] arr = new byte[(int) file.length()];
+raf.read(arr);
+
+Socket socket = new ServerSocket(8080).accept();
+socket.getOutputStream().write(arr);
+```
+
+### 传统 IO 模型
+
+
+
+代码:
+
+```java
+
+// 服务端:
+
+package com.atguigu.nio.groupchat;
+
+import java.io.IOException;
+import java.net.InetSocketAddress;
+import java.nio.ByteBuffer;
+import java.nio.channels.Channel;
+import java.nio.channels.SelectionKey;
+import java.nio.channels.Selector;
+import java.nio.channels.ServerSocketChannel;
+import java.nio.channels.SocketChannel;
+import java.util.Iterator;
+
+public class GroupChatServer {
+
+ //定义属性
+ private Selector selector;
+ private ServerSocketChannel listenChannel;
+
+ private static final int PORT = 6667;
+
+ //构造器
+ //初始化工作
+ public GroupChatServer() {
+ try {
+ //得到选择器
+ selector = Selector.open();
+ //ServerSocketChannel
+ listenChannel = ServerSocketChannel.open();
+ //绑定端口
+ listenChannel.socket().bind(new InetSocketAddress(PORT));
+ //设置非阻塞模式
+ listenChannel.configureBlocking(false);
+ //将该 listenChannel 注册到 selector
+ listenChannel.register(selector, SelectionKey.OP_ACCEPT);
+ } catch (IOException e) {
+ e.printStackTrace();
+ }
+ }
+
+ public void listen() {
+ try {
+ //循环处理
+ while (true) {
+ int count = selector.select();
+ if (count > 0) { //有事件处理
+ // 遍历得到 selectionKey 集合
+ Iterator iterator = selector.selectedKeys().iterator();
+ while (iterator.hasNext()) {
+ //取出 selectionkey
+ SelectionKey key = iterator.next();
+ //监听到 accept
+ if (key.isAcceptable()) {
+ SocketChannel sc = listenChannel.accept();
+ sc.configureBlocking(false);
+ //将该 sc 注册到 seletor
+ sc.register(selector, SelectionKey.OP_READ);
+ //提示
+ System.out.println(sc.getRemoteAddress() + " 上线 ");
+ }
+ if (key.isReadable()) {//通道发送read事件,即通道是可读的状态
+ // 处理读(专门写方法..)
+ readData(key);
+ }
+ //当前的 key 删除,防止重复处理
+ iterator.remove();
+ }
+ } else {
+ System.out.println("等待....");
+ }
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ //发生异常处理....
+ }
+ }
+
+ //读取客户端消息
+ public void readData(SelectionKey key) {
+ SocketChannel channel = null;
+ try {
+ //得到 channel
+ channel = (SocketChannel) key.channel();
+ //创建 buffer
+ ByteBuffer buffer = ByteBuffer.allocate(1024);
+ int count = channel.read(buffer);
+ //根据 count 的值做处理
+ if (count > 0) {
+ //把缓存区的数据转成字符串
+ String msg = new String(buffer.array());
+ //输出该消息
+ System.out.println("form客户端:" + msg);
+ //向其它的客户端转发消息(去掉自己),专门写一个方法来处理
+ sendInfoToOtherClients(msg, channel);
+ }
+ } catch (IOException e) {
+ try {
+ System.out.println(channel.getRemoteAddress() + "离线了..");
+ //取消注册
+ key.cancel();
+ //关闭通道
+ channel.close();
+ } catch (IOException e2) {
+ e2.printStackTrace();
+ }
+ }
+ }
+
+ //转发消息给其它客户(通道)
+ private void sendInfoToOtherClients(String msg, SocketChannel self) throws IOException {
+
+ System.out.println("服务器转发消息中...");
+ //遍历所有注册到 selector 上的 SocketChannel,并排除 self
+ for (SelectionKey key : selector.keys()) {
+ //通过 key 取出对应的 SocketChannel
+ Channel targetChannel = key.channel();
+ //排除自己
+ if (targetChannel instanceof SocketChannel && targetChannel != self) {
+ //转型
+ SocketChannel dest = (SocketChannel) targetChannel;
+ //将 msg 存储到 buffer
+ ByteBuffer buffer = ByteBuffer.wrap(msg.getBytes());
+ //将 buffer 的数据写入通道
+ dest.write(buffer);
+ }
+ }
+ }
+
+ public static void main(String[] args) {
+ //创建服务器对象
+ GroupChatServer groupChatServer = new GroupChatServer();
+ groupChatServer.listen();
+ }
+}
+
+// 客户端:
+
+package com.atguigu.nio.groupchat;
+
+import java.io.IOException;
+import java.net.InetSocketAddress;
+import java.nio.ByteBuffer;
+import java.nio.channels.SelectionKey;
+import java.nio.channels.Selector;
+import java.nio.channels.SocketChannel;
+import java.util.Iterator;
+import java.util.Scanner;
+
+public class GroupChatClient {
+
+ //定义相关的属性
+ private final String HOST = "127.0.0.1";//服务器的ip
+ private final int PORT = 6667;//服务器端口
+ private Selector selector;
+ private SocketChannel socketChannel;
+ private String username;
+
+ //构造器,完成初始化工作
+ public GroupChatClient() throws IOException {
+
+ selector = Selector.open();
+ //连接服务器
+ socketChannel = SocketChannel.open(new InetSocketAddress(HOST, PORT));
+ //设置非阻塞
+ socketChannel.configureBlocking(false);
+ //将 channel 注册到selector
+ socketChannel.register(selector, SelectionKey.OP_READ);
+ //得到 username
+ username = socketChannel.getLocalAddress().toString().substring(1);
+ System.out.println(username + " is ok...");
+ }
+
+ //向服务器发送消息
+ public void sendInfo(String info) {
+ info = username + " 说:" + info;
+ try {
+ socketChannel.write(ByteBuffer.wrap(info.getBytes()));
+ } catch (IOException e) {
+ e.printStackTrace();
+ }
+ }
+
+ //读取从服务器端回复的消息
+ public void readInfo() {
+ try {
+ int readChannels = selector.select();
+ if (readChannels > 0) {//有可以用的通道
+ Iterator iterator = selector.selectedKeys().iterator();
+ while (iterator.hasNext()) {
+ SelectionKey key = iterator.next();
+ if (key.isReadable()) {
+ //得到相关的通道
+ SocketChannel sc = (SocketChannel) key.channel();
+ //得到一个 Buffer
+ ByteBuffer buffer = ByteBuffer.allocate(1024);
+ //读取
+ sc.read(buffer);
+ //把读到的缓冲区的数据转成字符串
+ String msg = new String(buffer.array());
+ System.out.println(msg.trim());
+ }
+ }
+ iterator.remove(); //删除当前的 selectionKey,防止重复操作
+ } else {
+ //System.out.println("没有可以用的通道...");
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+
+ public static void main(String[] args) throws Exception {
+
+ //启动我们客户端
+ GroupChatClient chatClient = new GroupChatClient();
+ //启动一个线程,每个 3 秒,读取从服务器发送数据
+ new Thread() {
+ public void run() {
+ while (true) {
+ chatClient.readInfo();
+ try {
+ Thread.currentThread().sleep(3000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+ }.start();
+
+ //发送数据给服务器端
+ Scanner scanner = new Scanner(System.in);
+ while (scanner.hasNextLine()) {
+ String s = scanner.nextLine();
+ chatClient.sendInfo(s);
+ }
+ }
+}
+```
+
+## NIO与零拷贝
+
+> 1、尚硅谷这里的零拷贝感觉讲的感觉有点问题,但是为了笔记的完整性,任然保留了这里的笔记。不过笔者考虑再写一篇零拷贝。
+>
+> 2、而且这里课件的图也看不太清
+>
+> 3、读者可以将我写的零拷贝和尚硅谷这里讲的零拷贝对照着看,取长补短
+
+### 零拷贝基本介绍
+
+1. 零拷贝是网络编程的关键,很多性能优化都离不开。
+2. 在 `Java` 程序中,常用的零拷贝有 `mmap`(内存映射)和 `sendFile`。那么,他们在 `OS` 里,到底是怎么样的一个的设计?我们分析 `mmap` 和 `sendFile` 这两个零拷贝
+3. 另外我们看下 `NIO` 中如何使用零拷贝
+
+### 传统 IO 数据读写
+
+`Java` 传统 `IO` 和网络编程的一段代码
+
+```java
+File file = new File("test.txt");
+RandomAccessFile raf = new RandomAccessFile(file, "rw");
+
+byte[] arr = new byte[(int) file.length()];
+raf.read(arr);
+
+Socket socket = new ServerSocket(8080).accept();
+socket.getOutputStream().write(arr);
+```
+
+### 传统 IO 模型
+
+ +
+**DMA**:`direct memory access` 直接内存拷贝(不使用 `CPU`)
+
+### mmap 优化
+
+1. `mmap` 通过内存映射,将文件映射到内核缓冲区,同时,用户空间可以共享内核空间的数据。这样,在进行网络传输时,就可以减少内核空间到用户空间的拷贝次数。如下图
+2. `mmap` 示意图
+
+
+
+**DMA**:`direct memory access` 直接内存拷贝(不使用 `CPU`)
+
+### mmap 优化
+
+1. `mmap` 通过内存映射,将文件映射到内核缓冲区,同时,用户空间可以共享内核空间的数据。这样,在进行网络传输时,就可以减少内核空间到用户空间的拷贝次数。如下图
+2. `mmap` 示意图
+
+ +
+### sendFile 优化
+
+1. `Linux2.1` 版本提供了 `sendFile` 函数,其基本原理如下:数据根本不经过用户态,直接从内核缓冲区进入到 `SocketBuffer`,同时,由于和用户态完全无关,就减少了一次上下文切换
+2. 示意图和小结
+
+
+
+### sendFile 优化
+
+1. `Linux2.1` 版本提供了 `sendFile` 函数,其基本原理如下:数据根本不经过用户态,直接从内核缓冲区进入到 `SocketBuffer`,同时,由于和用户态完全无关,就减少了一次上下文切换
+2. 示意图和小结
+
+ +
+3. 提示:零拷贝从操作系统角度,是没有 `cpu` 拷贝
+4. `Linux在2.4` 版本中,做了一些修改,避免了从内核缓冲区拷贝到 `Socketbuffer` 的操作,直接拷贝到协议栈,从而再一次减少了数据拷贝。具体如下图和小结:
+
+
+
+3. 提示:零拷贝从操作系统角度,是没有 `cpu` 拷贝
+4. `Linux在2.4` 版本中,做了一些修改,避免了从内核缓冲区拷贝到 `Socketbuffer` 的操作,直接拷贝到协议栈,从而再一次减少了数据拷贝。具体如下图和小结:
+
+ +
+5. 这里其实有一次 `cpu` 拷贝 `kernel buffer` -> `socket buffer` 但是,拷贝的信息很少,比如 `lenght`、`offset` 消耗低,可以忽略
+
+### 零拷贝的再次理解
+
+1. 我们说零拷贝,是从操作系统的角度来说的。因为内核缓冲区之间,没有数据是重复的(只有 `kernel buffer` 有一份数据)。
+2. 零拷贝不仅仅带来更少的数据复制,还能带来其他的性能优势,例如更少的上下文切换,更少的 `CPU` 缓存伪共享以及无 `CPU` 校验和计算。
+
+### mmap 和 sendFile 的区别
+
+1. `mmap` 适合小数据量读写,`sendFile` 适合大文件传输。
+2. `mmap` 需要 `4` 次上下文切换,`3` 次数据拷贝;`sendFile` 需要 `3` 次上下文切换,最少 `2` 次数据拷贝。
+3. `sendFile` 可以利用 `DMA` 方式,减少 `CPU` 拷贝,`mmap` 则不能(必须从内核拷贝到 `Socket`缓冲区)。
+
+### NIO 零拷贝案例
+
+案例要求:
+
+1. 使用传统的 `IO` 方法传递一个大文件
+2. 使用 `NIO` 零拷贝方式传递(`transferTo`)一个大文件
+3. 看看两种传递方式耗时时间分别是多少
+
+```java
+NewIOServer.java
+
+package com.atguigu.nio.zerocopy;
+
+import java.net.InetSocketAddress;
+import java.net.ServerSocket;
+import java.nio.ByteBuffer;
+import java.nio.channels.ServerSocketChannel;
+import java.nio.channels.SocketChannel;
+
+//服务器
+public class NewIOServer {
+
+ public static void main(String[] args) throws Exception {
+ InetSocketAddress address = new InetSocketAddress(7001);
+ ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
+ ServerSocket serverSocket = serverSocketChannel.socket();
+ serverSocket.bind(address);
+
+ //创建buffer
+ ByteBuffer byteBuffer = ByteBuffer.allocate(4096);
+
+ while (true) {
+ SocketChannel socketChannel = serverSocketChannel.accept();
+ int readcount = 0;
+ while (-1 != readcount) {
+ try {
+ readcount = socketChannel.read(byteBuffer);
+ } catch (Exception ex) {
+ // ex.printStackTrace();
+ break;
+ }
+ //
+ byteBuffer.rewind(); //倒带 position = 0 mark 作废
+ }
+ }
+ }
+}
+
+NewIOClient.java
+
+package com.atguigu.nio.zerocopy;
+
+import java.io.FileInputStream;
+import java.net.InetSocketAddress;
+import java.nio.channels.FileChannel;
+import java.nio.channels.SocketChannel;
+
+public class NewIOClient {
+
+ public static void main(String[] args) throws Exception {
+ SocketChannel socketChannel = SocketChannel.open();
+ socketChannel.connect(new InetSocketAddress("localhost", 7001));
+ String filename = "protoc-3.6.1-win32.zip";
+ //得到一个文件channel
+ FileChannel fileChannel = new FileInputStream(filename).getChannel();
+ //准备发送
+ long startTime = System.currentTimeMillis();
+ //在 linux 下一个 transferTo 方法就可以完成传输
+ //在 windows 下一次调用 transferTo 只能发送 8m, 就需要分段传输文件,而且要主要
+ //传输时的位置=》课后思考...
+ //transferTo 底层使用到零拷贝
+ long transferCount = fileChannel.transferTo(0, fileChannel.size(), socketChannel);
+ System.out.println("发送的总的字节数 = " + transferCount + " 耗时: " + (System.currentTimeMillis() - startTime));
+
+ //关闭
+ fileChannel.close();
+ }
+}
+```
+
+## Java AIO 基本介绍
+
+1. `JDK7` 引入了 `AsynchronousI/O`,即 `AIO`。在进行 `I/O` 编程中,常用到两种模式:`Reactor` 和 `Proactor`。`Java` 的 `NIO` 就是 `Reactor`,当有事件触发时,服务器端得到通知,进行相应的处理
+2. `AIO` 即 `NIO2.0`,叫做异步不阻塞的 `IO`。`AIO` 引入异步通道的概念,采用了 `Proactor` 模式,简化了程序编写,有效的请求才启动线程,它的特点是先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用
+3. 目前 `AIO` 还没有广泛应用,`Netty` 也是基于 `NIO`,而不是 `AIO`,因此我们就不详解 `AIO` 了,有兴趣的同学可以参考[《Java新一代网络编程模型AIO原理及Linux系统AIO介绍》](http://www.52im.net/thread-306-1-1.html)
+
+## BIO、NIO、AIO 对比表
+
+| | BIO | NIO | AIO |
+| :------: | :------: | :--------------------: | :--------: |
+| IO模型 | 同步阻塞 | 同步非阻塞(多路复用) | 异步非阻塞 |
+| 编程难度 | 简单 | 复杂 | 复杂 |
+| 可靠性 | 差 | 好 | 好 |
+| 吞吐量 | 低 | 高 | 高 |
+
+**举例说明**
+
+1. 同步阻塞:到理发店理发,就一直等理发师,直到轮到自己理发。
+2. 同步非阻塞:到理发店理发,发现前面有其它人理发,给理发师说下,先干其他事情,一会过来看是否轮到自己.
+3. 异步非阻塞:给理发师打电话,让理发师上门服务,自己干其它事情,理发师自己来家给你理发
\ No newline at end of file
diff --git a/docs/os/操作系统-IO与零拷贝.md b/docs/os/操作系统-IO与零拷贝.md
new file mode 100644
index 0000000..2279387
--- /dev/null
+++ b/docs/os/操作系统-IO与零拷贝.md
@@ -0,0 +1,399 @@
+---
+title: 操作系统-IO与零拷贝
+tags:
+ - 操作系统
+ - os
+ - IO
+ - 零拷贝
+categories:
+ - 操作系统
+keywords: 操作系统,IO,零拷贝
+description: 基本面试会问到的IO进行了详解,同时本篇文章也对面试以及平时工作中会看到的零拷贝进行了充分的解析。万字长文系列,读到就是赚到。
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@master/os/os_logo.jpg'
+abbrlink: e959db2e
+date: 2021-04-08 15:21:58
+---
+
+
+
+
+
+
+
+>
+> 1. 本篇文章对于IO相关内容并没有完全讲完,不过也讲的差不多了,基本面试会问到的都讲了,如果想看的更细的,推荐**《操作系统导论》**这本书。
+> 2. 同时本篇文章也讲了面试以及平时工作中会看到的零拷贝,因为和IO有比较大的关系,就在这篇文章写一下。
+> 3. 零拷贝很多开源项目都用到了,netty,kafka,rocketmq等等。所以还是比较重要的,也是面试常问
+> 4. 流程图为processOn手工画的
+
+# IO
+
+## 阻塞与非阻塞 I/O 和 同步与异步 I/O
+
+> 这应该是大家看到很多文章对IO的一种分类,这只是IO最常见的一种分类。是从是否阻塞,以及是否异步的角度来分类的
+
+在这里,我们以一个网络IO来的read来举例,它会涉及到两个东西:一个是产生这个IO的进程,另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
+
+**阶段1:**等待数据准备
+
+**阶段2:**数据从内核空间拷贝到用户进程缓冲区的过程
+
+
+
+### 阻塞IO
+
+1. 当用户进程进行recvfrom这个系统调用,内核就开始了IO的第一个阶段:等待数据准备。
+2. 于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的TCP包),这个时候**内核**就要等待足够的数据到来。
+3. 而在用户进程这边,整 个进程会被阻塞。当**内核**一直等到数据准备好了,它就会将数据从**内核**中拷贝到用户内存,然后**内核**返回果,用户进程才解除 block的状态,重新运行起来。
+4. **所以,blocking IO的特点就是在IO执行的两个阶段都被block了。**
+
+
+
+5. 这里其实有一次 `cpu` 拷贝 `kernel buffer` -> `socket buffer` 但是,拷贝的信息很少,比如 `lenght`、`offset` 消耗低,可以忽略
+
+### 零拷贝的再次理解
+
+1. 我们说零拷贝,是从操作系统的角度来说的。因为内核缓冲区之间,没有数据是重复的(只有 `kernel buffer` 有一份数据)。
+2. 零拷贝不仅仅带来更少的数据复制,还能带来其他的性能优势,例如更少的上下文切换,更少的 `CPU` 缓存伪共享以及无 `CPU` 校验和计算。
+
+### mmap 和 sendFile 的区别
+
+1. `mmap` 适合小数据量读写,`sendFile` 适合大文件传输。
+2. `mmap` 需要 `4` 次上下文切换,`3` 次数据拷贝;`sendFile` 需要 `3` 次上下文切换,最少 `2` 次数据拷贝。
+3. `sendFile` 可以利用 `DMA` 方式,减少 `CPU` 拷贝,`mmap` 则不能(必须从内核拷贝到 `Socket`缓冲区)。
+
+### NIO 零拷贝案例
+
+案例要求:
+
+1. 使用传统的 `IO` 方法传递一个大文件
+2. 使用 `NIO` 零拷贝方式传递(`transferTo`)一个大文件
+3. 看看两种传递方式耗时时间分别是多少
+
+```java
+NewIOServer.java
+
+package com.atguigu.nio.zerocopy;
+
+import java.net.InetSocketAddress;
+import java.net.ServerSocket;
+import java.nio.ByteBuffer;
+import java.nio.channels.ServerSocketChannel;
+import java.nio.channels.SocketChannel;
+
+//服务器
+public class NewIOServer {
+
+ public static void main(String[] args) throws Exception {
+ InetSocketAddress address = new InetSocketAddress(7001);
+ ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
+ ServerSocket serverSocket = serverSocketChannel.socket();
+ serverSocket.bind(address);
+
+ //创建buffer
+ ByteBuffer byteBuffer = ByteBuffer.allocate(4096);
+
+ while (true) {
+ SocketChannel socketChannel = serverSocketChannel.accept();
+ int readcount = 0;
+ while (-1 != readcount) {
+ try {
+ readcount = socketChannel.read(byteBuffer);
+ } catch (Exception ex) {
+ // ex.printStackTrace();
+ break;
+ }
+ //
+ byteBuffer.rewind(); //倒带 position = 0 mark 作废
+ }
+ }
+ }
+}
+
+NewIOClient.java
+
+package com.atguigu.nio.zerocopy;
+
+import java.io.FileInputStream;
+import java.net.InetSocketAddress;
+import java.nio.channels.FileChannel;
+import java.nio.channels.SocketChannel;
+
+public class NewIOClient {
+
+ public static void main(String[] args) throws Exception {
+ SocketChannel socketChannel = SocketChannel.open();
+ socketChannel.connect(new InetSocketAddress("localhost", 7001));
+ String filename = "protoc-3.6.1-win32.zip";
+ //得到一个文件channel
+ FileChannel fileChannel = new FileInputStream(filename).getChannel();
+ //准备发送
+ long startTime = System.currentTimeMillis();
+ //在 linux 下一个 transferTo 方法就可以完成传输
+ //在 windows 下一次调用 transferTo 只能发送 8m, 就需要分段传输文件,而且要主要
+ //传输时的位置=》课后思考...
+ //transferTo 底层使用到零拷贝
+ long transferCount = fileChannel.transferTo(0, fileChannel.size(), socketChannel);
+ System.out.println("发送的总的字节数 = " + transferCount + " 耗时: " + (System.currentTimeMillis() - startTime));
+
+ //关闭
+ fileChannel.close();
+ }
+}
+```
+
+## Java AIO 基本介绍
+
+1. `JDK7` 引入了 `AsynchronousI/O`,即 `AIO`。在进行 `I/O` 编程中,常用到两种模式:`Reactor` 和 `Proactor`。`Java` 的 `NIO` 就是 `Reactor`,当有事件触发时,服务器端得到通知,进行相应的处理
+2. `AIO` 即 `NIO2.0`,叫做异步不阻塞的 `IO`。`AIO` 引入异步通道的概念,采用了 `Proactor` 模式,简化了程序编写,有效的请求才启动线程,它的特点是先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用
+3. 目前 `AIO` 还没有广泛应用,`Netty` 也是基于 `NIO`,而不是 `AIO`,因此我们就不详解 `AIO` 了,有兴趣的同学可以参考[《Java新一代网络编程模型AIO原理及Linux系统AIO介绍》](http://www.52im.net/thread-306-1-1.html)
+
+## BIO、NIO、AIO 对比表
+
+| | BIO | NIO | AIO |
+| :------: | :------: | :--------------------: | :--------: |
+| IO模型 | 同步阻塞 | 同步非阻塞(多路复用) | 异步非阻塞 |
+| 编程难度 | 简单 | 复杂 | 复杂 |
+| 可靠性 | 差 | 好 | 好 |
+| 吞吐量 | 低 | 高 | 高 |
+
+**举例说明**
+
+1. 同步阻塞:到理发店理发,就一直等理发师,直到轮到自己理发。
+2. 同步非阻塞:到理发店理发,发现前面有其它人理发,给理发师说下,先干其他事情,一会过来看是否轮到自己.
+3. 异步非阻塞:给理发师打电话,让理发师上门服务,自己干其它事情,理发师自己来家给你理发
\ No newline at end of file
diff --git a/docs/os/操作系统-IO与零拷贝.md b/docs/os/操作系统-IO与零拷贝.md
new file mode 100644
index 0000000..2279387
--- /dev/null
+++ b/docs/os/操作系统-IO与零拷贝.md
@@ -0,0 +1,399 @@
+---
+title: 操作系统-IO与零拷贝
+tags:
+ - 操作系统
+ - os
+ - IO
+ - 零拷贝
+categories:
+ - 操作系统
+keywords: 操作系统,IO,零拷贝
+description: 基本面试会问到的IO进行了详解,同时本篇文章也对面试以及平时工作中会看到的零拷贝进行了充分的解析。万字长文系列,读到就是赚到。
+cover: 'https://cdn.jsdelivr.net/gh/youthlql/lqlp@master/os/os_logo.jpg'
+abbrlink: e959db2e
+date: 2021-04-08 15:21:58
+---
+
+
+
+
+
+
+
+>
+> 1. 本篇文章对于IO相关内容并没有完全讲完,不过也讲的差不多了,基本面试会问到的都讲了,如果想看的更细的,推荐**《操作系统导论》**这本书。
+> 2. 同时本篇文章也讲了面试以及平时工作中会看到的零拷贝,因为和IO有比较大的关系,就在这篇文章写一下。
+> 3. 零拷贝很多开源项目都用到了,netty,kafka,rocketmq等等。所以还是比较重要的,也是面试常问
+> 4. 流程图为processOn手工画的
+
+# IO
+
+## 阻塞与非阻塞 I/O 和 同步与异步 I/O
+
+> 这应该是大家看到很多文章对IO的一种分类,这只是IO最常见的一种分类。是从是否阻塞,以及是否异步的角度来分类的
+
+在这里,我们以一个网络IO来的read来举例,它会涉及到两个东西:一个是产生这个IO的进程,另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
+
+**阶段1:**等待数据准备
+
+**阶段2:**数据从内核空间拷贝到用户进程缓冲区的过程
+
+
+
+### 阻塞IO
+
+1. 当用户进程进行recvfrom这个系统调用,内核就开始了IO的第一个阶段:等待数据准备。
+2. 于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的TCP包),这个时候**内核**就要等待足够的数据到来。
+3. 而在用户进程这边,整 个进程会被阻塞。当**内核**一直等到数据准备好了,它就会将数据从**内核**中拷贝到用户内存,然后**内核**返回果,用户进程才解除 block的状态,重新运行起来。
+4. **所以,blocking IO的特点就是在IO执行的两个阶段都被block了。**
+
+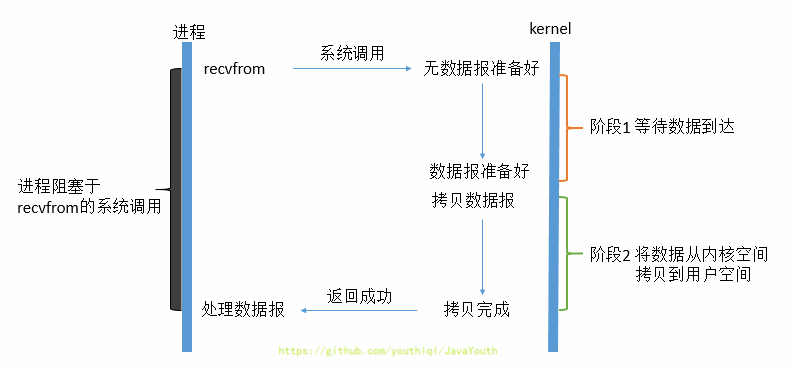 +
+
+
+### 非阻塞IO
+
+1. 当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。
+2. 从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好。用户线程需要不断地发起IO请求,直到数据到达后,才真正读取到数据,继续执行。
+3. 虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
+4. **所以,用户进程第一个阶段不是阻塞的,需要不断的主动询问内核数据好了没有;第二个阶段依然总是阻塞的。**
+
+
+
+
+
+### 非阻塞IO
+
+1. 当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。
+2. 从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好。用户线程需要不断地发起IO请求,直到数据到达后,才真正读取到数据,继续执行。
+3. 虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
+4. **所以,用户进程第一个阶段不是阻塞的,需要不断的主动询问内核数据好了没有;第二个阶段依然总是阻塞的。**
+
+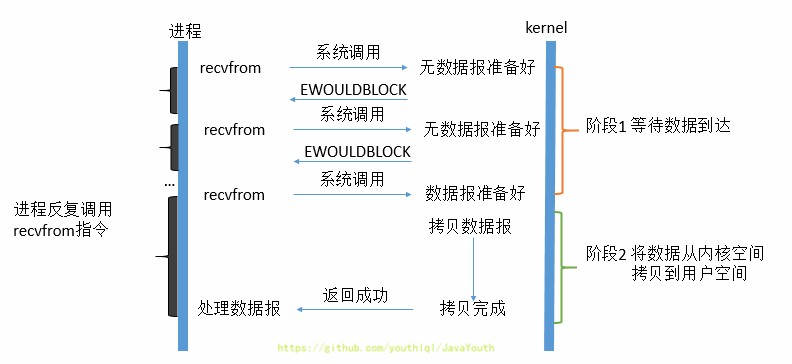 +
+
+
+### IO多路复用
+
+> 1. 应用程序每次轮询内核的 I/O 是否准备好,感觉有点傻乎乎,因为轮询的过程中,应用程序啥也做不了,只是在循环。
+>
+> 2. 为了解决这种傻乎乎轮询方式,于是 **I/O 多路复用**技术就出来了,如 select、poll,它是通过 I/O 事件分发,当内核数据准备好时,再以事件通知应用程序进行操作。
+>
+> 3. 这个做法大大改善了应用进程对 CPU 的利用率,在没有被通知的情况下,应用进程可以使用 CPU 做其他的事情。
+>
+> 下面是大概的过程
+
+1. IO多路复用模型是建立在内核提供的多路分离函数select基础之上的,使用select函数可以避免同步非阻塞IO模型中轮询等待的问题。利用了新的select系统调用,由内核来负责本来是请求进程该做的轮询操作
+2. 它的基本原理就是select /epoll这个函数会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程,正式发起read请求。
+3. 从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket(也就是数据准备好了的socket),即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
+
+
+
+
+
+### IO多路复用
+
+> 1. 应用程序每次轮询内核的 I/O 是否准备好,感觉有点傻乎乎,因为轮询的过程中,应用程序啥也做不了,只是在循环。
+>
+> 2. 为了解决这种傻乎乎轮询方式,于是 **I/O 多路复用**技术就出来了,如 select、poll,它是通过 I/O 事件分发,当内核数据准备好时,再以事件通知应用程序进行操作。
+>
+> 3. 这个做法大大改善了应用进程对 CPU 的利用率,在没有被通知的情况下,应用进程可以使用 CPU 做其他的事情。
+>
+> 下面是大概的过程
+
+1. IO多路复用模型是建立在内核提供的多路分离函数select基础之上的,使用select函数可以避免同步非阻塞IO模型中轮询等待的问题。利用了新的select系统调用,由内核来负责本来是请求进程该做的轮询操作
+2. 它的基本原理就是select /epoll这个函数会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程,正式发起read请求。
+3. 从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket(也就是数据准备好了的socket),即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
+
+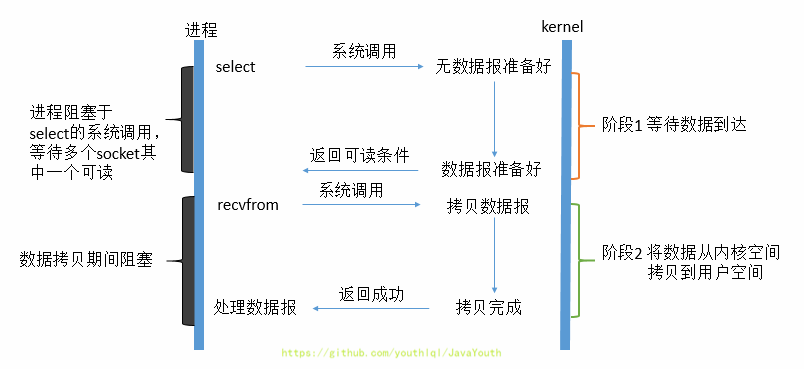 +
+**select函数**
+
+> handle_events:实现事件循环
+>
+> handle_event:进行读/写等操作
+
+1. 使用select函数的优点并不仅限于此。虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。
+2. 如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率。
+3. IO多路复用模型使用了Reactor设计模式实现了这一机制。
+4. 通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时(就是数据准备好的时候),则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。
+5. 由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。(一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。)
+
+
+
+**select函数**
+
+> handle_events:实现事件循环
+>
+> handle_event:进行读/写等操作
+
+1. 使用select函数的优点并不仅限于此。虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。
+2. 如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率。
+3. IO多路复用模型使用了Reactor设计模式实现了这一机制。
+4. 通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时(就是数据准备好的时候),则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。
+5. 由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。(一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。)
+
+ +
+
+
+### 异步IO
+
+- 实际上,无论是阻塞 I/O、非阻塞 I/O,还是基于非阻塞 I/O 的多路复用**都是同步调用。因为它们在 read 调用时,内核将数据从内核空间拷贝到应用进程空间,这个阶段都是需要等待的。**
+- 而真正的**异步 I/O** 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待
+
+
+
+1. 真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,由用户线程自行读取数据、处理数据。
+2. 而在异步IO模型中,用户进程发起read操作之后,立刻就可以开始去做其它的事。
+3. 而另一方面,从**内核**的角度,当它受到一个异步读之后,首先它会立刻返回,所以不会对用户进程产生任何阻塞。然后,内核会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都 完成之后,**内核**会给用户进程发送一个信号,告诉它read操作完成了,用户线程直接使用即可。 在这整个过程中,进程完全没有被阻塞。
+4. 异步IO模型使用了Proactor设计模式实现了这一机制。**(具体怎么搞得,看上面的文章链接)**
+
+
+
+
+
+### 异步IO
+
+- 实际上,无论是阻塞 I/O、非阻塞 I/O,还是基于非阻塞 I/O 的多路复用**都是同步调用。因为它们在 read 调用时,内核将数据从内核空间拷贝到应用进程空间,这个阶段都是需要等待的。**
+- 而真正的**异步 I/O** 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待
+
+
+
+1. 真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,由用户线程自行读取数据、处理数据。
+2. 而在异步IO模型中,用户进程发起read操作之后,立刻就可以开始去做其它的事。
+3. 而另一方面,从**内核**的角度,当它受到一个异步读之后,首先它会立刻返回,所以不会对用户进程产生任何阻塞。然后,内核会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都 完成之后,**内核**会给用户进程发送一个信号,告诉它read操作完成了,用户线程直接使用即可。 在这整个过程中,进程完全没有被阻塞。
+4. 异步IO模型使用了Proactor设计模式实现了这一机制。**(具体怎么搞得,看上面的文章链接)**
+
+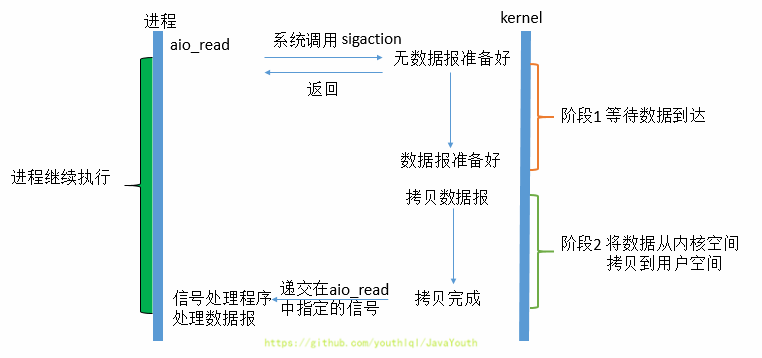 +
+
+
+> 有一篇文章以实际例子讲解的比较形象
+>
+> [漫画讲IO](https://mp.weixin.qq.com/s?__biz=Mzg3MjA4MTExMw==&mid=2247484746&idx=1&sn=c0a7f9129d780786cabfcac0a8aa6bb7&source=41&scene=21#wechat_redirect)
+
+## 直接与非直接I/O
+
+1. 磁盘 I/O 是非常慢的,所以 Linux 内核通过减少磁盘 I/O 次数来减少I/O时间,在系统调用后,会把用户数据拷贝到内核中缓存起来,这个内核缓存空间也就是【页缓存:PageCache】,只有当缓存满足某些条件的时候,才发起磁盘 I/O 的请求。
+
+2. **根据是「否利用操作系统的页缓存」,可以把文件 I/O 分为直接 I/O 与非直接 I/O**:
+
+* 直接 I/O,不会发生内核缓存和用户程序之间数据复制,跳过操作系统的页缓存,直接经过文件系统访问磁盘。
+* 非直接 I/O,正相反,读操作时,数据从内核缓存中拷贝给用户程序,写操作时,数据从用户程序拷贝给内核缓存,再由内核决定什么时候写入数据到磁盘。
+
+3. 想要实现直接I/O,需要你在系统调用中,指定 O_DIRECT 标志。如果没有设置过,默认的是非直接I/O。
+
+
+
+在进行写操作的时候以下几种场景会触发内核缓存的数据写入磁盘:
+
+> 以下摘自---**《深入linux内核架构》**
+>
+> **1、**
+>
+> 可能因不同原因、在不同的时机触发不同的刷出数据的机制。
+>
+> - 周期性的内核线程,将扫描脏页的链表,并根据页变脏的时间,来选择一些页写回。如果系统不是太忙于写操作,那么在脏页的数目,以及刷出页所需的硬盘访问操作对系统造成的负荷之间,有一个可接受的比例。
+>
+> - 如果系统中的脏页过多(例如,一个大型的写操作可能造成这种情况),内核将触发进一步的机制对脏页与后备存储器进行同步,直至脏页的数目降低到一个可接受的程度。而“脏页过多”和“可接受的程度”到底意味着什么,此时尚是一个不确定的问题,将在下文讨论。
+>
+> - 内核的各个组件可能要求数据必须在特定事件发生时同步,例如在重新装载文件系统时。
+>
+> 前两种机制由内核线程pdflush实现,该线程执行同步代码,而第三种机制可能由内核中的多处代码触发。
+>
+>
+>
+> **2、**
+>
+> 可以从用户空间通过各种系统调用来启用内核同步机制,以确保内存和块设备之间(完全或部分)的数据完整性。有如下3个基本选项可用。
+>
+> 1. 使用sync系统调用刷出整个缓存内容。在某些情况下,这可能非常耗时。
+>
+> 2. 各个文件的内容(以及相关inode的元数据)可以被传输到底层的块设备。内核为此提供了fsync和fdatasync系统调用。尽管sync通常与上文提到的系统工具sync联合使用,但fsync和fdatasync则专用于特定的应用程序,因为刷出的文件是通过特定于进程的文件描述符(在第8章介绍)来选择的。因而,没有一个通用的用户空间工具可以回写特定的文件。
+> 3. msync用于同步内存映射
+
+1、我们先来说脏页
+
+脏页-linux内核中的概念,因为硬盘的读写速度远赶不上内存的速度,系统就把读写比较频繁的数据事先放到内存中,以提高读写速度,这就叫高速缓存,linux是以页作为高速缓存的单位,当进程修改了高速缓存里的数据时,该页就被内核标记为脏页,内核将会在合适的时间把脏页的数据写到磁盘中去,以保持高速缓存中的数据和磁盘中的数据是一致的。
+
+2、通过对上面的解读,我们用通俗的语言翻译以下
+
+- 周期性的扫描脏页,如果发现脏页存在的时间过了某一时间时,也会把该脏页的数据刷到磁盘上
+
+* 当发现脏页太多的时候,内核会把一定数量的脏页数据写到磁盘上;
+* 用户主动调用 `sync`,`fsync`,`fdatasync`,内核缓存会刷到磁盘上;
+
+## 缓冲与非缓冲I/O
+
+1. 文件操作的标准库是可以实现数据的缓存,那么**根据「是否利用标准库缓冲」,可以把文件 I/O 分为缓冲 I/O 和非缓冲 I/O**:
+
+* 缓冲 I/O,利用的是标准库的缓存实现文件的加速访问,而标准库再通过系统调用访问文件。
+* 非缓冲 I/O,直接通过系统调用访问文件,不经过标准库缓存。
+
+2. 这里所说的「缓冲」特指标准库内部实现的缓冲。比方说,很多程序遇到换行时才真正输出,而换行前的内容,其实就是被标准库暂时缓存了起来,这样做的目的是,减少系统调用的次数。
+3. 非缓冲io,因为没有标准库提供的缓冲,只能用操作系统的缓存区,会造成很多次的系统调用,降低效率
+4. 带缓存IO也叫标准IO,符合ANSI C 的标准IO处理,不依赖系统内核,所以移植性强,我们使用标准IO操作很多时候是为了减少对read()和write()的系统调用次数,带缓存IO其实就是在用户层再建立一个缓存区,这个缓存区的分配和优化长度等细节都是标准IO库代你处理好了,不用去操心。
+
+
+
+> 标准 I/O 库提供缓冲的目的是尽可能减少使用 read 和 write 调用的次数(见图 3-6,其中显示了在不同缓冲区长度情况下,执行 I/O 所需的 CPU 时间量)。它也对每个 I/O流自动地进行缓冲管理,从而避免了应用程序需要考虑这一点所带来的麻烦。遗憾的是,标准 I/O 库最令人迷惑的也是它的缓冲。
+>
+> 标准 I/O提供了以下3 种类型的缓冲。
+>
+> 1. 全缓冲。在这种情况下,在填满标准 I/O 缓冲区后才进行实际 I/O 操作。对于驻留在磁盘上的文件通常是由标准 IO库实施全缓冲的。在一个流上执行第一次 I/O 操作时,相关标准 I/O函数通常调用 malloc (见7.8 节)获得需使用的缓冲区。
术语冲洗(fush)说明标准 UO 缓冲区的写操作。缓冲区可由标准 I/O 例程自动地冲洗(例如,当填满一个缓冲区时),或者可以调用函数 fflush 冲洗一个流。值得注意的是,在 UNTX环境中,fush有两种意思。在标准 I/O库方面,flush(冲洗)意味着将缓冲区中的内容写到磁盘上(该缓冲区可能只是部分填满的)。在终端驱动程序方面(例如,在第 18章中所述的tcflush函数),flush(刷清)表示丢弃已存储在缓冲区中的数据。
+>2. 行缓冲。在这种情况下,当在输入和输出中遇到换行符时,标准 I/O 库执行 I/O 操作。这允许我们一次输出一个字符(用标准 I/O 函数fputc),但只有在写了一行之后才进行实际 I/O操作。当流涉及一个终端时(如标准输入和标准输出),通常使用行缓冲。
对于行缓冲有两个限制。第一,因为标准 I/O 库用来收集每一行的缓冲区的长度是固定的。所以只要填满了缓冲区,那么即使还没有写一个换行符,也进行 I/O 操作。第二,任何时候只要通过标准 I/O 库要求从(a)一个不带缓冲的流,或者(b)一个行缓冲的流(它从内核请求需要 数据)得到输入数据,那么就会冲洗所有行缓冲输出流。在(b)中带了一个在括号中的说明,其理由是,所需的数据可能已在该缓冲区中,它并不要求一定从内核读数据。很明显,从一个不带缓冲的流中输入(即(a)项)需要从内核获得数据。
+> 3. 不带缓冲。标准 I/O 库不对字符进行缓冲存储,例如,若用标准 I/O 函数 fputs 写 15个字符到不带缓冲的流中,我们就期望这 15 个字符能立即输出,很可能使用 3.8 节的write 函数将这些字符写到相关联的打开文件中。
+
+
+
+# 零拷贝
+
+> 讲零拷贝前,讲一下前置知识
+
+## 标准设备
+
+1. 来看一个标准设备(不是真实存在的,相当于一个逻辑上抽象的东西),通过它来帮助我们更好地理解设备交互的机制。可以看到一个包含两部分重要组件的设备。第一部分是向系统其他部分展现的硬件接口(interface)。同软件一样,硬件也需要一些接口,让系统软件来控制它的操作。因此,所有设备都有自己的特定接口以及典型交互的协议。
+
+
+
+
+
+> 有一篇文章以实际例子讲解的比较形象
+>
+> [漫画讲IO](https://mp.weixin.qq.com/s?__biz=Mzg3MjA4MTExMw==&mid=2247484746&idx=1&sn=c0a7f9129d780786cabfcac0a8aa6bb7&source=41&scene=21#wechat_redirect)
+
+## 直接与非直接I/O
+
+1. 磁盘 I/O 是非常慢的,所以 Linux 内核通过减少磁盘 I/O 次数来减少I/O时间,在系统调用后,会把用户数据拷贝到内核中缓存起来,这个内核缓存空间也就是【页缓存:PageCache】,只有当缓存满足某些条件的时候,才发起磁盘 I/O 的请求。
+
+2. **根据是「否利用操作系统的页缓存」,可以把文件 I/O 分为直接 I/O 与非直接 I/O**:
+
+* 直接 I/O,不会发生内核缓存和用户程序之间数据复制,跳过操作系统的页缓存,直接经过文件系统访问磁盘。
+* 非直接 I/O,正相反,读操作时,数据从内核缓存中拷贝给用户程序,写操作时,数据从用户程序拷贝给内核缓存,再由内核决定什么时候写入数据到磁盘。
+
+3. 想要实现直接I/O,需要你在系统调用中,指定 O_DIRECT 标志。如果没有设置过,默认的是非直接I/O。
+
+
+
+在进行写操作的时候以下几种场景会触发内核缓存的数据写入磁盘:
+
+> 以下摘自---**《深入linux内核架构》**
+>
+> **1、**
+>
+> 可能因不同原因、在不同的时机触发不同的刷出数据的机制。
+>
+> - 周期性的内核线程,将扫描脏页的链表,并根据页变脏的时间,来选择一些页写回。如果系统不是太忙于写操作,那么在脏页的数目,以及刷出页所需的硬盘访问操作对系统造成的负荷之间,有一个可接受的比例。
+>
+> - 如果系统中的脏页过多(例如,一个大型的写操作可能造成这种情况),内核将触发进一步的机制对脏页与后备存储器进行同步,直至脏页的数目降低到一个可接受的程度。而“脏页过多”和“可接受的程度”到底意味着什么,此时尚是一个不确定的问题,将在下文讨论。
+>
+> - 内核的各个组件可能要求数据必须在特定事件发生时同步,例如在重新装载文件系统时。
+>
+> 前两种机制由内核线程pdflush实现,该线程执行同步代码,而第三种机制可能由内核中的多处代码触发。
+>
+>
+>
+> **2、**
+>
+> 可以从用户空间通过各种系统调用来启用内核同步机制,以确保内存和块设备之间(完全或部分)的数据完整性。有如下3个基本选项可用。
+>
+> 1. 使用sync系统调用刷出整个缓存内容。在某些情况下,这可能非常耗时。
+>
+> 2. 各个文件的内容(以及相关inode的元数据)可以被传输到底层的块设备。内核为此提供了fsync和fdatasync系统调用。尽管sync通常与上文提到的系统工具sync联合使用,但fsync和fdatasync则专用于特定的应用程序,因为刷出的文件是通过特定于进程的文件描述符(在第8章介绍)来选择的。因而,没有一个通用的用户空间工具可以回写特定的文件。
+> 3. msync用于同步内存映射
+
+1、我们先来说脏页
+
+脏页-linux内核中的概念,因为硬盘的读写速度远赶不上内存的速度,系统就把读写比较频繁的数据事先放到内存中,以提高读写速度,这就叫高速缓存,linux是以页作为高速缓存的单位,当进程修改了高速缓存里的数据时,该页就被内核标记为脏页,内核将会在合适的时间把脏页的数据写到磁盘中去,以保持高速缓存中的数据和磁盘中的数据是一致的。
+
+2、通过对上面的解读,我们用通俗的语言翻译以下
+
+- 周期性的扫描脏页,如果发现脏页存在的时间过了某一时间时,也会把该脏页的数据刷到磁盘上
+
+* 当发现脏页太多的时候,内核会把一定数量的脏页数据写到磁盘上;
+* 用户主动调用 `sync`,`fsync`,`fdatasync`,内核缓存会刷到磁盘上;
+
+## 缓冲与非缓冲I/O
+
+1. 文件操作的标准库是可以实现数据的缓存,那么**根据「是否利用标准库缓冲」,可以把文件 I/O 分为缓冲 I/O 和非缓冲 I/O**:
+
+* 缓冲 I/O,利用的是标准库的缓存实现文件的加速访问,而标准库再通过系统调用访问文件。
+* 非缓冲 I/O,直接通过系统调用访问文件,不经过标准库缓存。
+
+2. 这里所说的「缓冲」特指标准库内部实现的缓冲。比方说,很多程序遇到换行时才真正输出,而换行前的内容,其实就是被标准库暂时缓存了起来,这样做的目的是,减少系统调用的次数。
+3. 非缓冲io,因为没有标准库提供的缓冲,只能用操作系统的缓存区,会造成很多次的系统调用,降低效率
+4. 带缓存IO也叫标准IO,符合ANSI C 的标准IO处理,不依赖系统内核,所以移植性强,我们使用标准IO操作很多时候是为了减少对read()和write()的系统调用次数,带缓存IO其实就是在用户层再建立一个缓存区,这个缓存区的分配和优化长度等细节都是标准IO库代你处理好了,不用去操心。
+
+
+
+> 标准 I/O 库提供缓冲的目的是尽可能减少使用 read 和 write 调用的次数(见图 3-6,其中显示了在不同缓冲区长度情况下,执行 I/O 所需的 CPU 时间量)。它也对每个 I/O流自动地进行缓冲管理,从而避免了应用程序需要考虑这一点所带来的麻烦。遗憾的是,标准 I/O 库最令人迷惑的也是它的缓冲。
+>
+> 标准 I/O提供了以下3 种类型的缓冲。
+>
+> 1. 全缓冲。在这种情况下,在填满标准 I/O 缓冲区后才进行实际 I/O 操作。对于驻留在磁盘上的文件通常是由标准 IO库实施全缓冲的。在一个流上执行第一次 I/O 操作时,相关标准 I/O函数通常调用 malloc (见7.8 节)获得需使用的缓冲区。
术语冲洗(fush)说明标准 UO 缓冲区的写操作。缓冲区可由标准 I/O 例程自动地冲洗(例如,当填满一个缓冲区时),或者可以调用函数 fflush 冲洗一个流。值得注意的是,在 UNTX环境中,fush有两种意思。在标准 I/O库方面,flush(冲洗)意味着将缓冲区中的内容写到磁盘上(该缓冲区可能只是部分填满的)。在终端驱动程序方面(例如,在第 18章中所述的tcflush函数),flush(刷清)表示丢弃已存储在缓冲区中的数据。
+>2. 行缓冲。在这种情况下,当在输入和输出中遇到换行符时,标准 I/O 库执行 I/O 操作。这允许我们一次输出一个字符(用标准 I/O 函数fputc),但只有在写了一行之后才进行实际 I/O操作。当流涉及一个终端时(如标准输入和标准输出),通常使用行缓冲。
对于行缓冲有两个限制。第一,因为标准 I/O 库用来收集每一行的缓冲区的长度是固定的。所以只要填满了缓冲区,那么即使还没有写一个换行符,也进行 I/O 操作。第二,任何时候只要通过标准 I/O 库要求从(a)一个不带缓冲的流,或者(b)一个行缓冲的流(它从内核请求需要 数据)得到输入数据,那么就会冲洗所有行缓冲输出流。在(b)中带了一个在括号中的说明,其理由是,所需的数据可能已在该缓冲区中,它并不要求一定从内核读数据。很明显,从一个不带缓冲的流中输入(即(a)项)需要从内核获得数据。
+> 3. 不带缓冲。标准 I/O 库不对字符进行缓冲存储,例如,若用标准 I/O 函数 fputs 写 15个字符到不带缓冲的流中,我们就期望这 15 个字符能立即输出,很可能使用 3.8 节的write 函数将这些字符写到相关联的打开文件中。
+
+
+
+# 零拷贝
+
+> 讲零拷贝前,讲一下前置知识
+
+## 标准设备
+
+1. 来看一个标准设备(不是真实存在的,相当于一个逻辑上抽象的东西),通过它来帮助我们更好地理解设备交互的机制。可以看到一个包含两部分重要组件的设备。第一部分是向系统其他部分展现的硬件接口(interface)。同软件一样,硬件也需要一些接口,让系统软件来控制它的操作。因此,所有设备都有自己的特定接口以及典型交互的协议。
+
+ +
+2. 第2部分是它的内部结构(internal structure)。这部分包含设备相关的特定实现,负责具体实现设备展示给系统的抽象接口。
+
+## 标准协议
+
+1. 在上图中,一个(简化的)设备接口包含3个寄存器:一个状态(status)寄存器,可以读取并查看设备的当前状态;一个命令(command)寄存器,用于通知设备执行某个具体任务;一个数据(data)寄存器,将数据传给设备或从设备接收数据。通过读写这些寄存器,操作系统可以控制设备的行为
+2. 我们现在来描述操作系统与该设备的典型交互,以便让设备为它做某事。协议如下:
+
+```c++
+While (STATUS == BUSY);//wait until device is not busy
+
+Write data to DATA register
+Write command to COMMAND register
+ (Doing so starts the device and executes the command)
+
+While (STATUS == BUSY);//wait until device is done with your request
+```
+
+3. 该协议包含4步。
+ - 第1步,操作系统通过反复读取状态寄存器,等待设备进入可以接收命令的就绪状态。我们称之为轮询(polling)设备(基本上,就是问它正在做什么)。
+ - 第2步,操作系统下发数据到数据寄存器。例如,你可以想象如果这是一个磁盘,需要多次写入操作,将一个磁盘块(比如4KB)传递给设备。如果主CPU参与数据移动(就像这个示例协议一样),我们就称之为编程的I/O(programmedI/O,PIO)。
+ - 第3步,操作系统将命令写入命令寄存器;这样设备就知道数据已经准备好了,它应该开始执行命令。最后一步,操作系统再次通过不断轮询设备,等待并判断设备是否执行完成命令(有可能得到一个指示成功或失败的错误码)。
+4. 这个简单的协议好处是足够简单并且有效。但是难免会有一些低效和不方便。我们注意到这个协议存在的第一个问题就是轮询过程比较低效,在等待设备执行完成命令时浪费大量CPU时间,如果此时操作系统可以切换执行下一个就绪进程,就可以大大提高CPU的利用率。
+
+> 关键问题:如何减少轮询开销操作系统检查设备状态时如何避免频繁轮询,从而降低管理设备的CPU开销?
+
+## 利用中断减少CPU开销
+
+**概念:**有了中断后,CPU 不再需要不断轮询设备,而是向设备发出一个请求,然后就可以让对应进程睡眠,切换执行其他任务。当设备完成了自身操作,会抛出一个硬件中断,引发CPU跳转执行操作系统预先定义好的中断服务例程(InterruptService Routine,ISR),或更为简单的中断处理程序(interrupt handler)。中断处理程序是一小段操作系统代码,它会结束之前的请求(比如从设备读取到了数据或者错误码)并且唤醒等待I/O的进程继续执行。
+
+**例子:**
+
+1. 没有中断时:进程1在CPU上运行一段时间(对应CPU那一行上重复的1),然后发出一个读取数据的I/O请求给磁盘。如果没有中断,那么操作系统就会简单自旋,不断轮询设备状态,直到设备完成I/O操作(对应其中的p)。当设备完成请求的操作后,进程1又可以继续运行。
+
+
+
+2. 第2部分是它的内部结构(internal structure)。这部分包含设备相关的特定实现,负责具体实现设备展示给系统的抽象接口。
+
+## 标准协议
+
+1. 在上图中,一个(简化的)设备接口包含3个寄存器:一个状态(status)寄存器,可以读取并查看设备的当前状态;一个命令(command)寄存器,用于通知设备执行某个具体任务;一个数据(data)寄存器,将数据传给设备或从设备接收数据。通过读写这些寄存器,操作系统可以控制设备的行为
+2. 我们现在来描述操作系统与该设备的典型交互,以便让设备为它做某事。协议如下:
+
+```c++
+While (STATUS == BUSY);//wait until device is not busy
+
+Write data to DATA register
+Write command to COMMAND register
+ (Doing so starts the device and executes the command)
+
+While (STATUS == BUSY);//wait until device is done with your request
+```
+
+3. 该协议包含4步。
+ - 第1步,操作系统通过反复读取状态寄存器,等待设备进入可以接收命令的就绪状态。我们称之为轮询(polling)设备(基本上,就是问它正在做什么)。
+ - 第2步,操作系统下发数据到数据寄存器。例如,你可以想象如果这是一个磁盘,需要多次写入操作,将一个磁盘块(比如4KB)传递给设备。如果主CPU参与数据移动(就像这个示例协议一样),我们就称之为编程的I/O(programmedI/O,PIO)。
+ - 第3步,操作系统将命令写入命令寄存器;这样设备就知道数据已经准备好了,它应该开始执行命令。最后一步,操作系统再次通过不断轮询设备,等待并判断设备是否执行完成命令(有可能得到一个指示成功或失败的错误码)。
+4. 这个简单的协议好处是足够简单并且有效。但是难免会有一些低效和不方便。我们注意到这个协议存在的第一个问题就是轮询过程比较低效,在等待设备执行完成命令时浪费大量CPU时间,如果此时操作系统可以切换执行下一个就绪进程,就可以大大提高CPU的利用率。
+
+> 关键问题:如何减少轮询开销操作系统检查设备状态时如何避免频繁轮询,从而降低管理设备的CPU开销?
+
+## 利用中断减少CPU开销
+
+**概念:**有了中断后,CPU 不再需要不断轮询设备,而是向设备发出一个请求,然后就可以让对应进程睡眠,切换执行其他任务。当设备完成了自身操作,会抛出一个硬件中断,引发CPU跳转执行操作系统预先定义好的中断服务例程(InterruptService Routine,ISR),或更为简单的中断处理程序(interrupt handler)。中断处理程序是一小段操作系统代码,它会结束之前的请求(比如从设备读取到了数据或者错误码)并且唤醒等待I/O的进程继续执行。
+
+**例子:**
+
+1. 没有中断时:进程1在CPU上运行一段时间(对应CPU那一行上重复的1),然后发出一个读取数据的I/O请求给磁盘。如果没有中断,那么操作系统就会简单自旋,不断轮询设备状态,直到设备完成I/O操作(对应其中的p)。当设备完成请求的操作后,进程1又可以继续运行。
+
+ +
+2. 有了中断后:中断允许计算与I/O重叠(overlap),这是提高CPU利用率的关键。我们利用中断并允许重叠,操作系统就可以在等待磁盘操作时做其他事情。
+
+
+
+2. 有了中断后:中断允许计算与I/O重叠(overlap),这是提高CPU利用率的关键。我们利用中断并允许重叠,操作系统就可以在等待磁盘操作时做其他事情。
+
+  +
+ - 在这个例子中,在磁盘处理进程1的请求时,操作系统在CPU上运行进程2。磁盘处理完成后,触发一个中断,然后操作系统唤醒进程1继续运行。这样,在这段时间,无论CPU还是磁盘都可以有效地利用。
+
+> 注意,使用中断并非总是最佳方案。假如有一个非常高性能的设备,它处理请求很快:通常在CPU第一次轮询时就可以返回结果。此时如果使用中断,反而会使系统变慢:切换到其他进程,处理中断,再切换回之前的进程代价不小。因此,如果设备非常快,那么最好的办法反而是轮询。如果设备比较慢,那么采用允许发生重叠的中断更好。如果设备的速度未知,或者时快时慢,可以考虑使用混合(hybrid)策略,先尝试轮询一小段时间,如果设备没有完成操作,此时再使用中断。这种两阶段(two-phased)的办法可以实现两种方法的好处。
+
+中断仍旧存在的缺点:
+
+
+
+ - 在这个例子中,在磁盘处理进程1的请求时,操作系统在CPU上运行进程2。磁盘处理完成后,触发一个中断,然后操作系统唤醒进程1继续运行。这样,在这段时间,无论CPU还是磁盘都可以有效地利用。
+
+> 注意,使用中断并非总是最佳方案。假如有一个非常高性能的设备,它处理请求很快:通常在CPU第一次轮询时就可以返回结果。此时如果使用中断,反而会使系统变慢:切换到其他进程,处理中断,再切换回之前的进程代价不小。因此,如果设备非常快,那么最好的办法反而是轮询。如果设备比较慢,那么采用允许发生重叠的中断更好。如果设备的速度未知,或者时快时慢,可以考虑使用混合(hybrid)策略,先尝试轮询一小段时间,如果设备没有完成操作,此时再使用中断。这种两阶段(two-phased)的办法可以实现两种方法的好处。
+
+中断仍旧存在的缺点:
+
+ +
+IO过程简述:
+
+1. 用户进程调用 read 方法,向cpu发出 I/O 请求
+2. cpu向磁盘发起IO请求给磁盘控制器,**之后立马返回**。返回之后cpu可以切换到其它进程执行其他任务
+3. 磁盘控制器收到指令后,于是就开始进行磁盘IO,磁盘IO完成后会把数据放入到磁盘控制器的内部缓冲区中,然后产生一个**中断**
+4. CPU 收到中断信号后,停下手头的工作,接着把磁盘控制器的缓冲区的数据读进内核的页缓存【这个过程是可以用DMA进行优化的】。
+5. 接着将数据从内核页缓存拷贝到用户进程空间【这个过程想要优化,只能用到我们上面说的异步IO】
+6. 最后read()调用返回。
+
+> 注意:
+>
+> 1. 这里很多博客画的图是错的,讲的也是错的。使用中断减少CPU开销时,在进行磁盘IO期间,CPU可以执行其他的进程不必等待磁盘IO。【因为这是《操作系统导论》里的原话】
+
+
+
+## 利用DMA进行更高效的数据传送
+
+> 这里为什么要特别强调原文呢?因为可以让读者读的安心,这本经典书籍总不会出错吧
+
+> 《操作系统导论》原文:
+>
+> 标准协议还有一点需要我们注意。具体来说,如果使用编程的I/O将一大块数据传给设备,CPU又会因为琐碎的任务而变得负载很重,浪费了时间和算力,本来更好是用于运行其他进程。下面的时间线展示了这个问题:
+>
+>
+
+IO过程简述:
+
+1. 用户进程调用 read 方法,向cpu发出 I/O 请求
+2. cpu向磁盘发起IO请求给磁盘控制器,**之后立马返回**。返回之后cpu可以切换到其它进程执行其他任务
+3. 磁盘控制器收到指令后,于是就开始进行磁盘IO,磁盘IO完成后会把数据放入到磁盘控制器的内部缓冲区中,然后产生一个**中断**
+4. CPU 收到中断信号后,停下手头的工作,接着把磁盘控制器的缓冲区的数据读进内核的页缓存【这个过程是可以用DMA进行优化的】。
+5. 接着将数据从内核页缓存拷贝到用户进程空间【这个过程想要优化,只能用到我们上面说的异步IO】
+6. 最后read()调用返回。
+
+> 注意:
+>
+> 1. 这里很多博客画的图是错的,讲的也是错的。使用中断减少CPU开销时,在进行磁盘IO期间,CPU可以执行其他的进程不必等待磁盘IO。【因为这是《操作系统导论》里的原话】
+
+
+
+## 利用DMA进行更高效的数据传送
+
+> 这里为什么要特别强调原文呢?因为可以让读者读的安心,这本经典书籍总不会出错吧
+
+> 《操作系统导论》原文:
+>
+> 标准协议还有一点需要我们注意。具体来说,如果使用编程的I/O将一大块数据传给设备,CPU又会因为琐碎的任务而变得负载很重,浪费了时间和算力,本来更好是用于运行其他进程。下面的时间线展示了这个问题:
+>
+>  +>
+> 进程1在运行过程中需要向磁盘写一些数据,所以它开始进行I/O操作,将数据从内存拷贝到磁盘(其中标示c的过程)。**拷贝结束后,磁盘上的I/O操作开始执行,此时CPU才可以处理其他请求。**
+
+也就是说在从**内存拷贝到磁盘或者从磁盘拷贝到内存**这个过程是可以使用DMA(Direct Memory Access)优化的,怎么优化呢?
+
+> 原文:
+>
+> DMA工作过程如下。为了能够将数据传送给设备,操作系统会通过编程告诉DMA引擎数据在内存的位置,要拷贝的大小以及要拷贝到哪个设备。在此之后,操作系统就可以处理其他请求了。当DMA的任务完成后,DMA控制器会抛出一个中断来告诉操作系统自己已经完成数据传输。修改后的时间线如下:
+>
+>
+>
+> 进程1在运行过程中需要向磁盘写一些数据,所以它开始进行I/O操作,将数据从内存拷贝到磁盘(其中标示c的过程)。**拷贝结束后,磁盘上的I/O操作开始执行,此时CPU才可以处理其他请求。**
+
+也就是说在从**内存拷贝到磁盘或者从磁盘拷贝到内存**这个过程是可以使用DMA(Direct Memory Access)优化的,怎么优化呢?
+
+> 原文:
+>
+> DMA工作过程如下。为了能够将数据传送给设备,操作系统会通过编程告诉DMA引擎数据在内存的位置,要拷贝的大小以及要拷贝到哪个设备。在此之后,操作系统就可以处理其他请求了。当DMA的任务完成后,DMA控制器会抛出一个中断来告诉操作系统自己已经完成数据传输。修改后的时间线如下:
+>
+>  +>
+> 从时间线中可以看到,数据的拷贝工作都是由DMA控制器来完成的。因为CPU在此时是空闲的,所以操作系统可以让它做一些其他事情,比如此处调度进程2到CPU来运行。因此进程2在进程1再次运行之前可以使用更多的CPU。
+
+为了更好理解,看图:
+
+
+>
+> 从时间线中可以看到,数据的拷贝工作都是由DMA控制器来完成的。因为CPU在此时是空闲的,所以操作系统可以让它做一些其他事情,比如此处调度进程2到CPU来运行。因此进程2在进程1再次运行之前可以使用更多的CPU。
+
+为了更好理解,看图:
+
+ +
+过程:
+
+1. 用户进程调用 read 方法,向cpu发出 I/O 请求
+2. cpu将IO请求交给DMA控制器,**之后自己立马返回去执行其他进程的任务**
+3. DMA向磁盘发起IO请求
+4. 磁盘控制器收到指令后,于是就开始进行磁盘IO,磁盘IO完成后会把数据放入到磁盘控制器的内部缓冲区中,然后产生一个**中断**。
+5. DMA收到中断后,把磁盘控制器的缓冲区的数据读进内核的页缓存,接着抛出一个中断
+6. 操作系统收到中断后,调度cpu回来执行之前的进程:将数据从内核页缓存拷贝到用户进程空间【这一步还是只能用异步IO来优化】
+7. 最后read()调用返回。
+
+
+
+## 零拷贝 - 传统文件IO
+
+场景:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。
+
+
+
+过程:
+
+1. 用户进程调用 read 方法,向cpu发出 I/O 请求
+2. cpu将IO请求交给DMA控制器,**之后自己立马返回去执行其他进程的任务**
+3. DMA向磁盘发起IO请求
+4. 磁盘控制器收到指令后,于是就开始进行磁盘IO,磁盘IO完成后会把数据放入到磁盘控制器的内部缓冲区中,然后产生一个**中断**。
+5. DMA收到中断后,把磁盘控制器的缓冲区的数据读进内核的页缓存,接着抛出一个中断
+6. 操作系统收到中断后,调度cpu回来执行之前的进程:将数据从内核页缓存拷贝到用户进程空间【这一步还是只能用异步IO来优化】
+7. 最后read()调用返回。
+
+
+
+## 零拷贝 - 传统文件IO
+
+场景:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。
+
+ +
+1. 很明显发生了4次拷贝
+
+ * 第一次拷贝,把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝是通过 DMA 的。
+ * 第二次拷贝,把内核缓冲区的数据拷贝到用户的缓冲区里,于是应用程序就可以使用这部分数据了,这个拷贝是由 CPU 完成的。
+ * 第三次拷贝,把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程依然由 CPU 完成的。
+ * *第四次拷贝*,把内核的 socket 缓冲区里的数据,拷贝到协议栈里,这个过程又是由 DMA 完成的。
+
+2. 发生了4次用户上下文切换,因为发生了两个系统调用read和write。一个系统调用对应两次上下文切换,所以上下文切换次数在一般情况下只可能是偶数。
+
+> 想要优化文件传输的性能就两个方向
+>
+> 1. 减少上下文切换次数
+> 2. 减少数据拷贝次数
+>
+> 因为这两个是最耗时的
+
+
+
+## 零拷贝之mmap
+
+`read()` 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,为了减少这一步开销,我们可以用 `mmap()` 替换 `read()` 系统调用函数。`mmap()` 系统调用函数会直接把内核缓冲区里的数据映射到用户空间,这样,操作系统内核与用户空间共享缓冲区,就不需要再进行任何的数据拷贝操作。
+
+
+
+1. 很明显发生了4次拷贝
+
+ * 第一次拷贝,把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝是通过 DMA 的。
+ * 第二次拷贝,把内核缓冲区的数据拷贝到用户的缓冲区里,于是应用程序就可以使用这部分数据了,这个拷贝是由 CPU 完成的。
+ * 第三次拷贝,把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程依然由 CPU 完成的。
+ * *第四次拷贝*,把内核的 socket 缓冲区里的数据,拷贝到协议栈里,这个过程又是由 DMA 完成的。
+
+2. 发生了4次用户上下文切换,因为发生了两个系统调用read和write。一个系统调用对应两次上下文切换,所以上下文切换次数在一般情况下只可能是偶数。
+
+> 想要优化文件传输的性能就两个方向
+>
+> 1. 减少上下文切换次数
+> 2. 减少数据拷贝次数
+>
+> 因为这两个是最耗时的
+
+
+
+## 零拷贝之mmap
+
+`read()` 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,为了减少这一步开销,我们可以用 `mmap()` 替换 `read()` 系统调用函数。`mmap()` 系统调用函数会直接把内核缓冲区里的数据映射到用户空间,这样,操作系统内核与用户空间共享缓冲区,就不需要再进行任何的数据拷贝操作。
+
+ +
+总的来说mmap减少了一次数据拷贝,总共4次上下文切换,3次数据拷贝
+
+
+
+## 零拷贝之sendfile
+
+`Linux2.1` 版本提供了 `sendFile` 函数,其基本原理如下:数据根本不经过用户态,直接从内核缓冲区进入到 `SocketBuffer`
+
+
+
+总的来说mmap减少了一次数据拷贝,总共4次上下文切换,3次数据拷贝
+
+
+
+## 零拷贝之sendfile
+
+`Linux2.1` 版本提供了 `sendFile` 函数,其基本原理如下:数据根本不经过用户态,直接从内核缓冲区进入到 `SocketBuffer`
+
+ +
+总的来说有2次上下文切换,3次数据拷贝。
+
+## sendfile再优化
+
+`Linux在2.4` 版本中,做了一些修改,避免了从内核缓冲区拷贝到 `Socketbuffer` 的操作,直接拷贝到协议栈,从而再一次减少了数据拷贝
+
+
+
+总的来说有2次上下文切换,3次数据拷贝。
+
+## sendfile再优化
+
+`Linux在2.4` 版本中,做了一些修改,避免了从内核缓冲区拷贝到 `Socketbuffer` 的操作,直接拷贝到协议栈,从而再一次减少了数据拷贝
+
+ +
+
+
+# 文件传输总结
+
+## 小文件传输
+
+前文一直提到了内核里的页缓存(PageCache),这个页缓存的作用就是用来提升小文件传输的效率
+
+原因:
+
+1. 读写磁盘相比读写内存的速度慢太多了,这个有点基础的人应该都知道,所以我们应该想办法把读写磁盘换成读写内存。于是,我们通过 DMA 把磁盘里的数据拷贝到内存里,这样就可以用读内存替换读磁盘。读磁盘数据的时候,优先在 PageCache 找,如果数据存在则可以直接返回;如果没有,则从磁盘中读取,然后缓存 PageCache 中。这点不是很类似redis和mysql的关系吗,所以说操作系统里的一些设计理念和平时工作应用息息相关,毕竟操作系统可是无数大牛的结晶
+2. 程序运行的时候,具有局部性原理,也就是说刚被访问的数据在短时间内再次被访问的概率很高,通常称为热点数据,于是我们用 PageCache 来缓存这些热点数据,当空间不足时有对应的缓存淘汰策略。
+
+## 大文件传输
+
+Q:PageCache可以用来大文件传输吗?
+
+A:不能
+
+Q:为什么呢?
+
+A:
+
+1. 假设你要几G的数据要传输,用户访问这些大文件的时候,内核会把它们载入 PageCache 中, PageCache 空间很快被这些大文件占满。
+2. PageCache 由于长时间被大文件占据,其他热点小文件可能就无法使用到 PageCache,就频繁读写磁盘,效率低下
+3. 而PageCache 中的大文件数据,没有享受到缓存带来的好处,反而却耗费 DMA 多拷贝到 PageCache 一次
+4. 这前前后后加起来,效率低了很多,所以PageCache不适合小文件传输
+
+而想不用到内核缓冲区,我们就想到了**直接IO**这个东西,直接IO不经过内核缓存,同时经过上面的讲述,我们也可以知道异步IO效率是最高的。所以大文件传输最好的解决办法应该是:**异步IO+直接IO**
+
+
+
+> 读到这里你就会发现,我为何这样安排目录顺序了,前面讲到的,后面都会用到。
+
+
+
+# 相关文章
+
+- 《操作系统导论》 强推
+
+- [漫画讲IO](https://mp.weixin.qq.com/s?__biz=Mzg3MjA4MTExMw==&mid=2247484746&idx=1&sn=c0a7f9129d780786cabfcac0a8aa6bb7&source=41&scene=21#wechat_redirect)
+
+* https://blog.csdn.net/sehanlingfeng/article/details/78920423
+
+* https://blog.csdn.net/m0_38109046/article/details/89449305
+
+* https://www.zhihu.com/question/19732473
+
+* [linux 同步IO: sync、fsync与fdatasync](https://blog.csdn.net/younger_china/article/details/51127127)
+
+
\ No newline at end of file
+
+
+
+# 文件传输总结
+
+## 小文件传输
+
+前文一直提到了内核里的页缓存(PageCache),这个页缓存的作用就是用来提升小文件传输的效率
+
+原因:
+
+1. 读写磁盘相比读写内存的速度慢太多了,这个有点基础的人应该都知道,所以我们应该想办法把读写磁盘换成读写内存。于是,我们通过 DMA 把磁盘里的数据拷贝到内存里,这样就可以用读内存替换读磁盘。读磁盘数据的时候,优先在 PageCache 找,如果数据存在则可以直接返回;如果没有,则从磁盘中读取,然后缓存 PageCache 中。这点不是很类似redis和mysql的关系吗,所以说操作系统里的一些设计理念和平时工作应用息息相关,毕竟操作系统可是无数大牛的结晶
+2. 程序运行的时候,具有局部性原理,也就是说刚被访问的数据在短时间内再次被访问的概率很高,通常称为热点数据,于是我们用 PageCache 来缓存这些热点数据,当空间不足时有对应的缓存淘汰策略。
+
+## 大文件传输
+
+Q:PageCache可以用来大文件传输吗?
+
+A:不能
+
+Q:为什么呢?
+
+A:
+
+1. 假设你要几G的数据要传输,用户访问这些大文件的时候,内核会把它们载入 PageCache 中, PageCache 空间很快被这些大文件占满。
+2. PageCache 由于长时间被大文件占据,其他热点小文件可能就无法使用到 PageCache,就频繁读写磁盘,效率低下
+3. 而PageCache 中的大文件数据,没有享受到缓存带来的好处,反而却耗费 DMA 多拷贝到 PageCache 一次
+4. 这前前后后加起来,效率低了很多,所以PageCache不适合小文件传输
+
+而想不用到内核缓冲区,我们就想到了**直接IO**这个东西,直接IO不经过内核缓存,同时经过上面的讲述,我们也可以知道异步IO效率是最高的。所以大文件传输最好的解决办法应该是:**异步IO+直接IO**
+
+
+
+> 读到这里你就会发现,我为何这样安排目录顺序了,前面讲到的,后面都会用到。
+
+
+
+# 相关文章
+
+- 《操作系统导论》 强推
+
+- [漫画讲IO](https://mp.weixin.qq.com/s?__biz=Mzg3MjA4MTExMw==&mid=2247484746&idx=1&sn=c0a7f9129d780786cabfcac0a8aa6bb7&source=41&scene=21#wechat_redirect)
+
+* https://blog.csdn.net/sehanlingfeng/article/details/78920423
+
+* https://blog.csdn.net/m0_38109046/article/details/89449305
+
+* https://www.zhihu.com/question/19732473
+
+* [linux 同步IO: sync、fsync与fdatasync](https://blog.csdn.net/younger_china/article/details/51127127)
+
+
\ No newline at end of file