diff --git a/docs/Apollo/Apollo简单入门.md b/docs/Apollo/Apollo简单入门.md
index d87cb6a..c7368ad 100644
--- a/docs/Apollo/Apollo简单入门.md
+++ b/docs/Apollo/Apollo简单入门.md
@@ -76,7 +76,7 @@ date: 2020-12-29 11:31:58
不过,解决一个问题的同时,往往会诞生出很多新的问题,所以微服务化的过程中伴随着很多的挑战,其中一个挑战就是有关服务(应用)配置的。当系统从一个单体应用,被拆分成分布式系统上一个个服务节点后,配置文件也必须跟着迁移(分割),这样配置就分散了,不仅如此,分散中还包含着冗余,如下图:
- +
+ 配置中心将配置从应用中剥离出来,统一管理,优雅的解决了配置的动态变更、持久化、运维成本等问题。
@@ -86,7 +86,7 @@ date: 2020-12-29 11:31:58
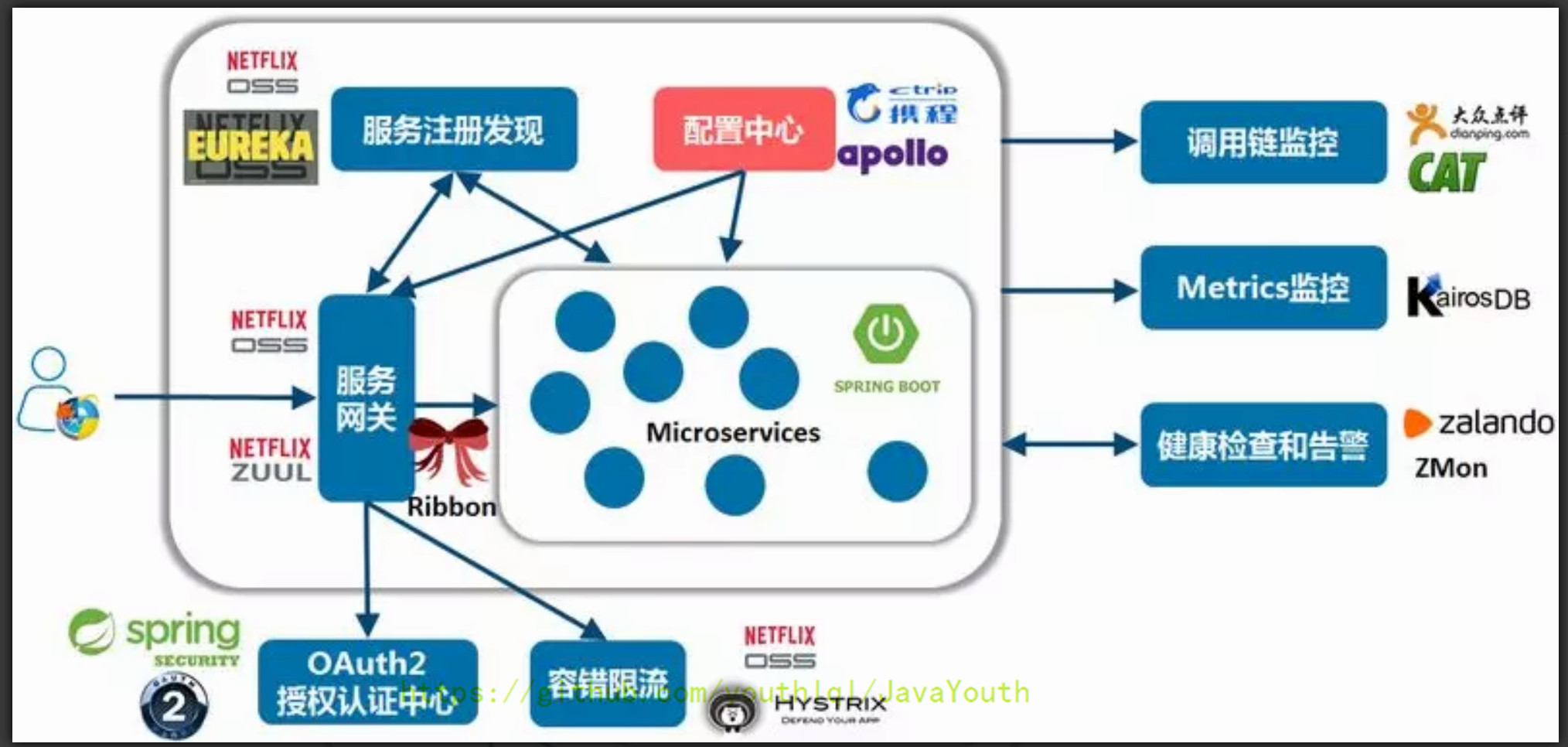
在系统架构中,配置中心是整个微服务基础架构体系中的一个组件,如下图,它的功能看上去并不起眼,无非就是配置的管理和存取,但它是整个微服务架构中不可或缺的一环。
-
配置中心将配置从应用中剥离出来,统一管理,优雅的解决了配置的动态变更、持久化、运维成本等问题。
@@ -86,7 +86,7 @@ date: 2020-12-29 11:31:58
在系统架构中,配置中心是整个微服务基础架构体系中的一个组件,如下图,它的功能看上去并不起眼,无非就是配置的管理和存取,但它是整个微服务架构中不可或缺的一环。
- +
+ @@ -171,7 +171,7 @@ Apollo简介
### Apollo简介
-
@@ -171,7 +171,7 @@ Apollo简介
### Apollo简介
- +
+ **Apollo - A reliable configuration management system**
@@ -221,7 +221,7 @@ Apollo快速入门
### 执行流程
-
**Apollo - A reliable configuration management system**
@@ -221,7 +221,7 @@ Apollo快速入门
### 执行流程
- +
+ 操作流程如下:
@@ -262,7 +262,7 @@ Apollo的表结构对`timestamp`使用了多个default声明,所以需要5.6.5
2. 打开1.3发布链接,下载必须的安装包:[https://github.com/ctripcorp/apollo/releases/tag/v1.3.0](https://github.com/ctripcorp/apollo/releases/tag/v1.3.0)。三个都要下
-
操作流程如下:
@@ -262,7 +262,7 @@ Apollo的表结构对`timestamp`使用了多个default声明,所以需要5.6.5
2. 打开1.3发布链接,下载必须的安装包:[https://github.com/ctripcorp/apollo/releases/tag/v1.3.0](https://github.com/ctripcorp/apollo/releases/tag/v1.3.0)。三个都要下
- +
+ 解压安装包后将apollo-configservice-1.3.0.jar, apollo-adminservice-1.3.0.jar, apollo-portal-1.3.0.jar放置于apollo目录下
@@ -349,11 +349,11 @@ Apollo服务端共需要两个数据库:`ApolloPortalDB`和`ApolloConfigDB`,
1. 也可以使用提供的runApollo.bat快速启动三个服务(修改数据库连接地址,数据库以及密码)
-
解压安装包后将apollo-configservice-1.3.0.jar, apollo-adminservice-1.3.0.jar, apollo-portal-1.3.0.jar放置于apollo目录下
@@ -349,11 +349,11 @@ Apollo服务端共需要两个数据库:`ApolloPortalDB`和`ApolloConfigDB`,
1. 也可以使用提供的runApollo.bat快速启动三个服务(修改数据库连接地址,数据库以及密码)
-  +
+  这里面是一个很简单的脚本
-
这里面是一个很简单的脚本
-  +
+  @@ -385,29 +385,29 @@ start "ApolloPortal" java -Xms256m -Xmx256m -Dapollo_profile=github,auth -Ddev_m
1. 打开[apollo](http://localhost:8070/) :新建项目apollo-quickstart
-
@@ -385,29 +385,29 @@ start "ApolloPortal" java -Xms256m -Xmx256m -Dapollo_profile=github,auth -Ddev_m
1. 打开[apollo](http://localhost:8070/) :新建项目apollo-quickstart
- +
+ 2. 新建配置项sms.enable
-
2. 新建配置项sms.enable
- +
+ -
- +
+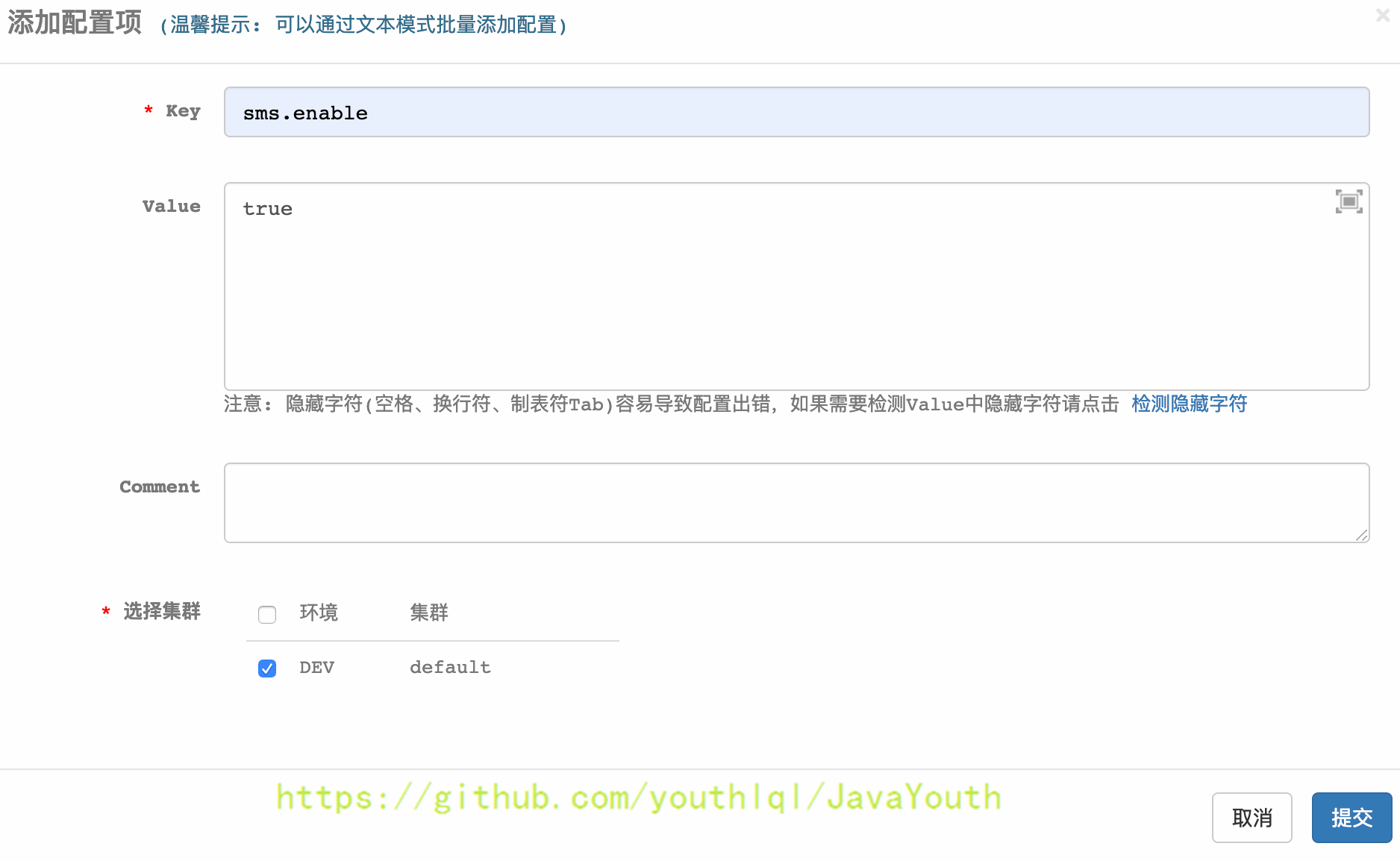 确认提交配置项
-
确认提交配置项
- +
+ -
+
3. 发布配置项
-
-
+
3. 发布配置项
- +
+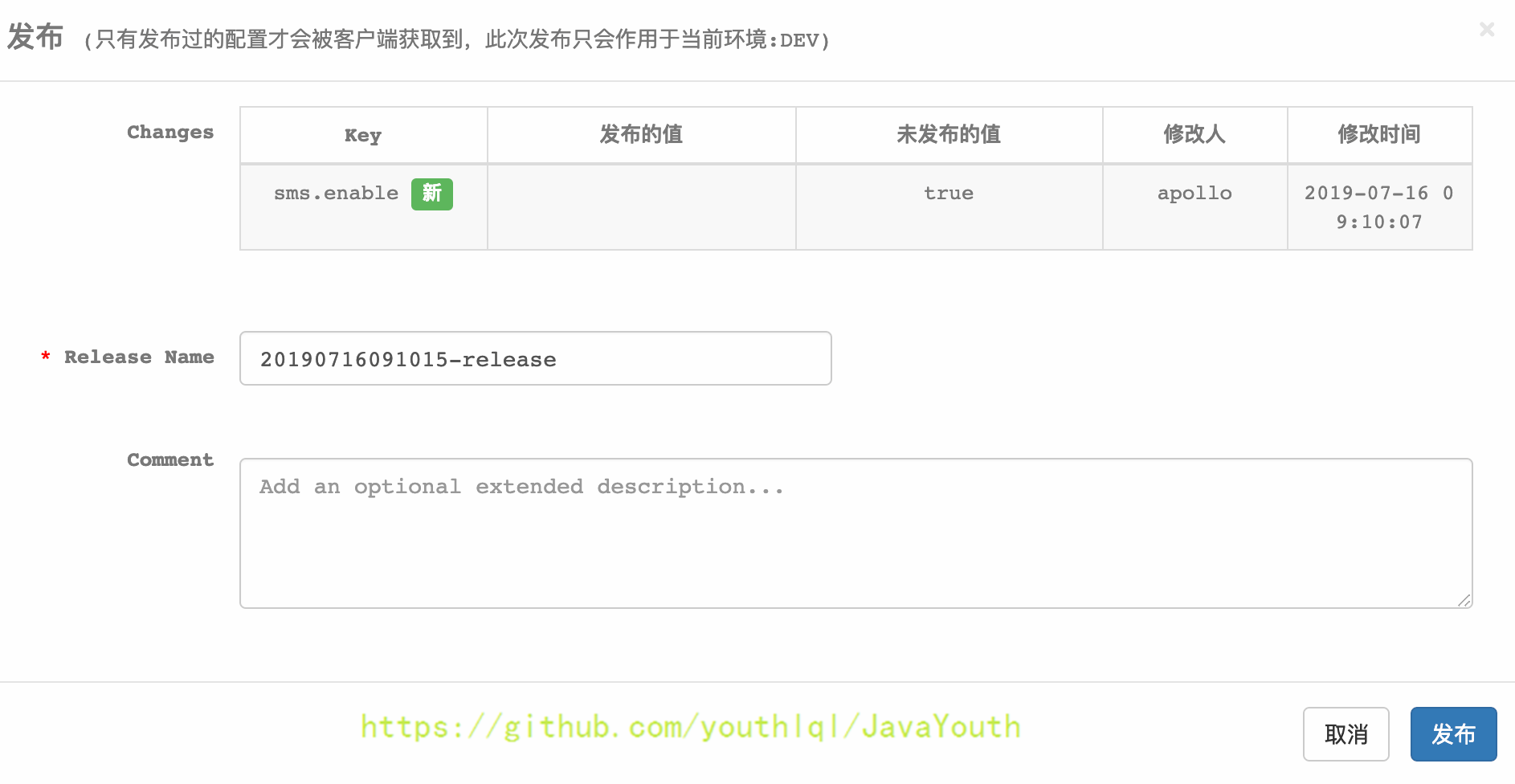 #### 应用读取配置
@@ -485,7 +485,7 @@ public class GetConfigTest {
-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:8080
-
#### 应用读取配置
@@ -485,7 +485,7 @@ public class GetConfigTest {
-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:8080
- +
+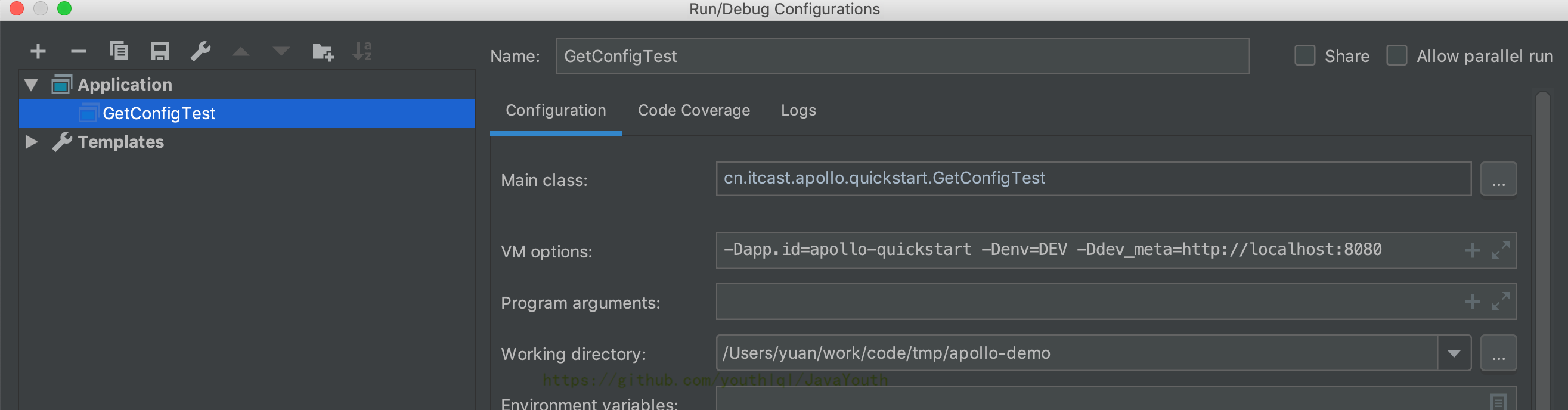 运行GetConfigTest,打开控制台,观察输出结果
@@ -523,19 +523,19 @@ sma.enable: true
2. 运行GetConfigTest观察输出结果
-
运行GetConfigTest,打开控制台,观察输出结果
@@ -523,19 +523,19 @@ sma.enable: true
2. 运行GetConfigTest观察输出结果
- +
+ 3. 在Apollo管理界面修改配置项
-
3. 在Apollo管理界面修改配置项
- +
+ 4. 发布配置
-
4. 发布配置
- +
+ 5. 在控制台查看详细情况:可以看到程序获取的sms.enable的值已由false变成了修改后的true
-
5. 在控制台查看详细情况:可以看到程序获取的sms.enable的值已由false变成了修改后的true
- +
+ @@ -546,7 +546,7 @@ Apollo应用
下图是Apollo架构模块的概览
-
@@ -546,7 +546,7 @@ Apollo应用
下图是Apollo架构模块的概览
- +
+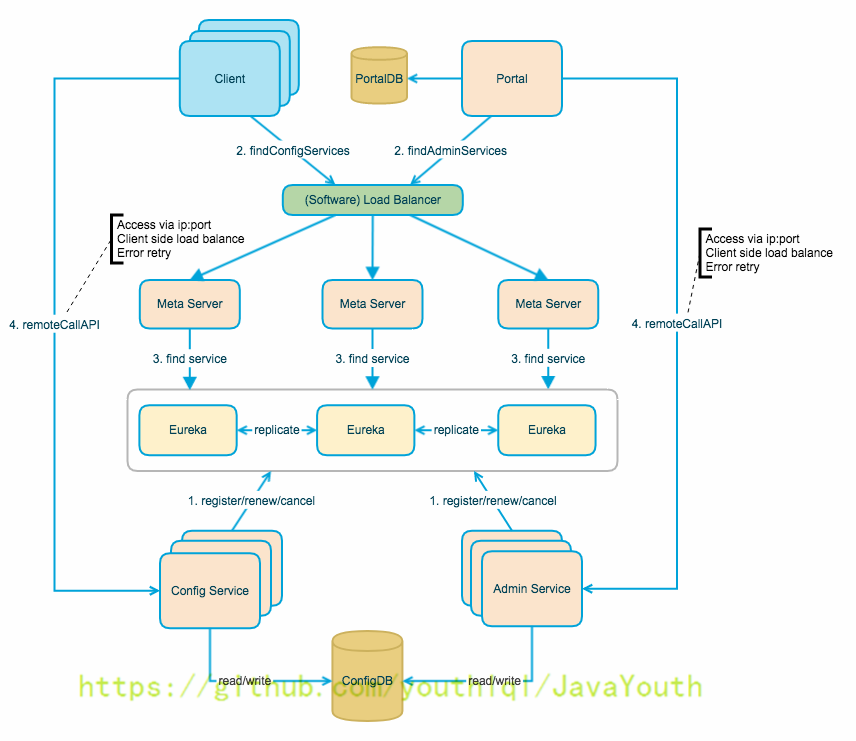 #### 各模块职责
@@ -601,7 +601,7 @@ Apollo应用
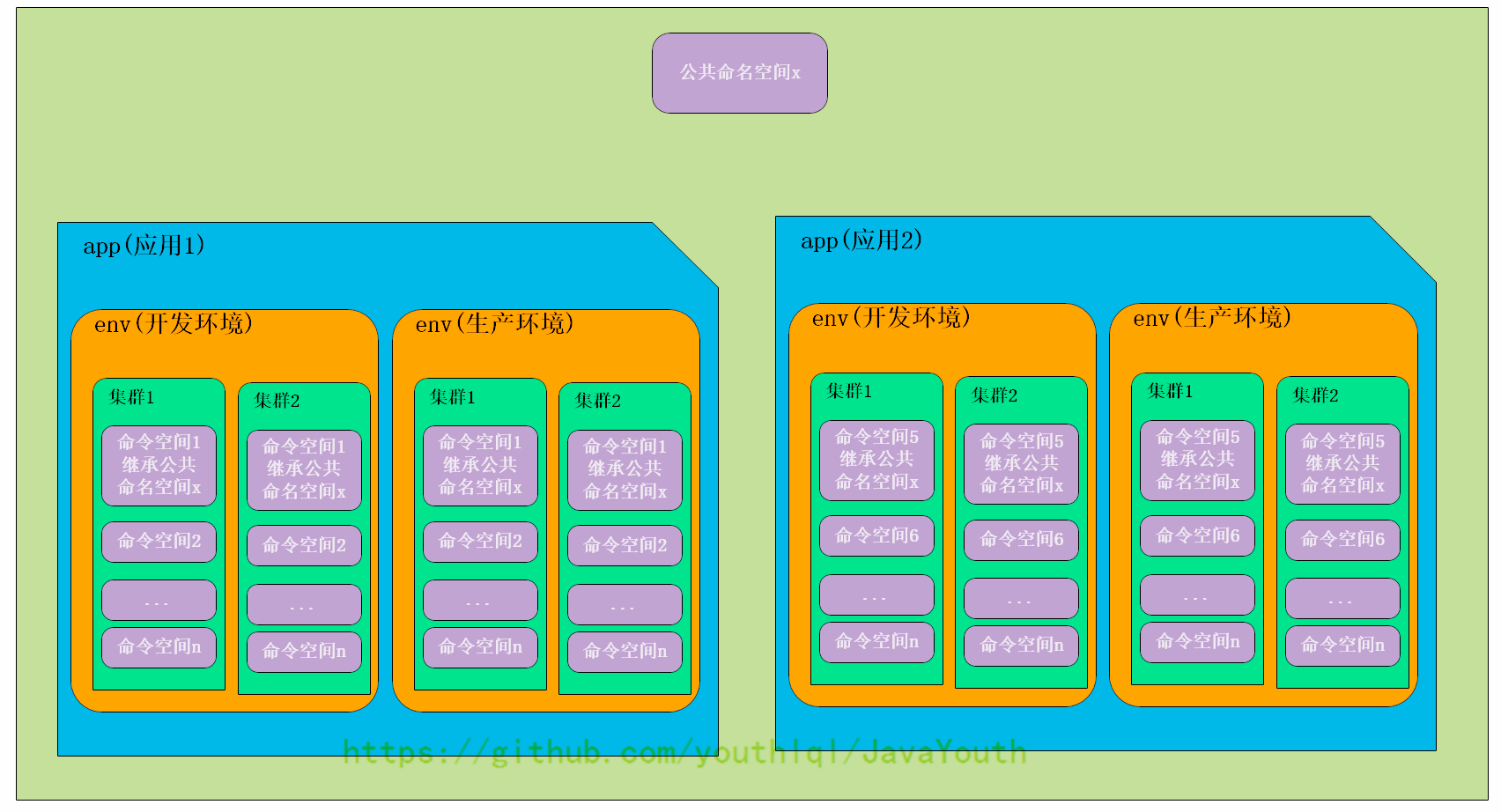
它们的关系如下图所示:
-
#### 各模块职责
@@ -601,7 +601,7 @@ Apollo应用
它们的关系如下图所示:
- +
+ @@ -615,15 +615,15 @@ apollo 默认部门有两个。要增加自己的部门,可在系统参数中
* 进入系统参数设置
-
@@ -615,15 +615,15 @@ apollo 默认部门有两个。要增加自己的部门,可在系统参数中
* 进入系统参数设置
- +
+ -
+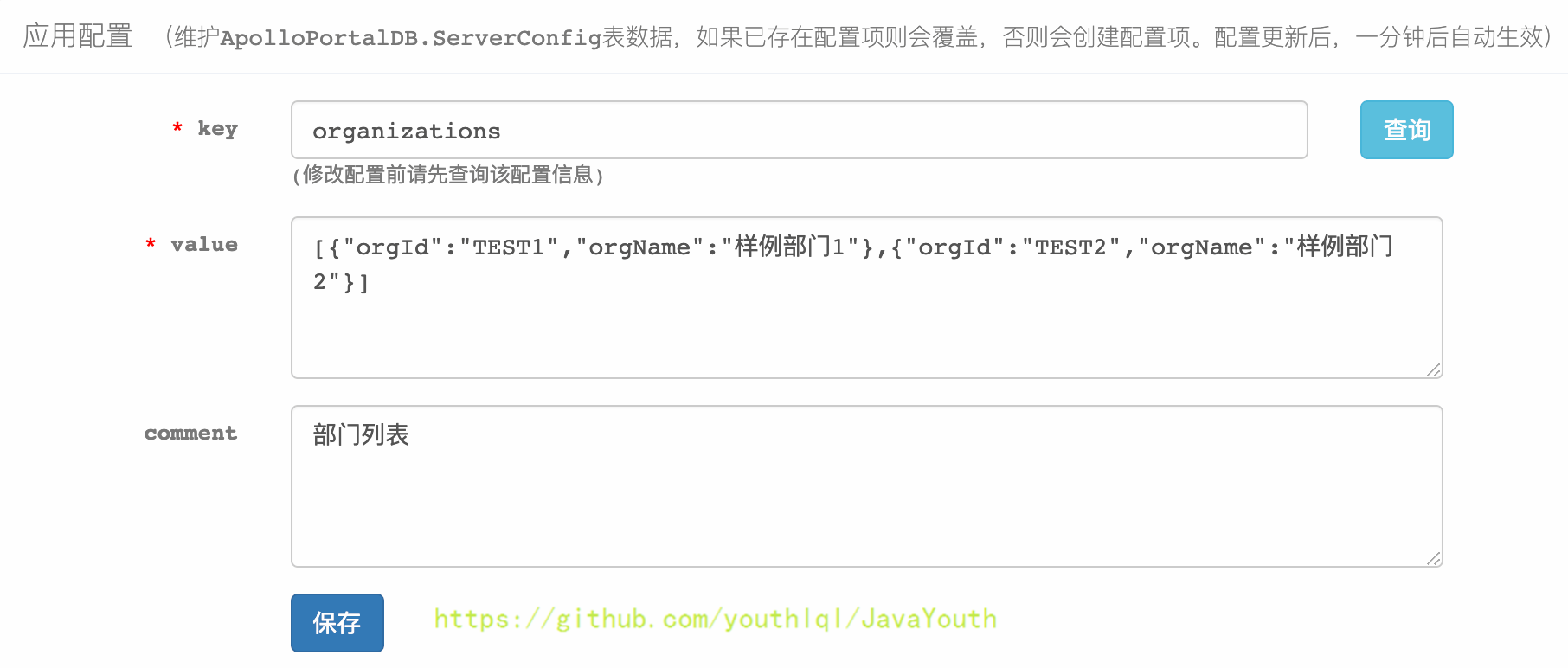
* 输入key查询已存在的部门设置:organizations
-
-
+
* 输入key查询已存在的部门设置:organizations
-  +
+  * 修改value值来添加新部门,下面添加一个微服务部门:
@@ -639,11 +639,11 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 新建用户张三
-
* 修改value值来添加新部门,下面添加一个微服务部门:
@@ -639,11 +639,11 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 新建用户张三
- +
+ -
- +
+ #### 创建项目
@@ -661,7 +661,7 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 应用名称:应用名,仅用于界面展示
* 应用负责人:选择的人默认会成为该项目的管理员,具备项目权限管理、集群创建、Namespace创建等权限
-
#### 创建项目
@@ -661,7 +661,7 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 应用名称:应用名,仅用于界面展示
* 应用负责人:选择的人默认会成为该项目的管理员,具备项目权限管理、集群创建、Namespace创建等权限
- +
+ 4. 点击提交,创建成功后,会自动跳转到项目首页
@@ -671,7 +671,7 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 使用管理员apollo将指定项目授权给用户张三
-
4. 点击提交,创建成功后,会自动跳转到项目首页
@@ -671,7 +671,7 @@ apollo默认提供一个超级管理员: apollo,可以自行添加用户
* 使用管理员apollo将指定项目授权给用户张三
-  +
+ 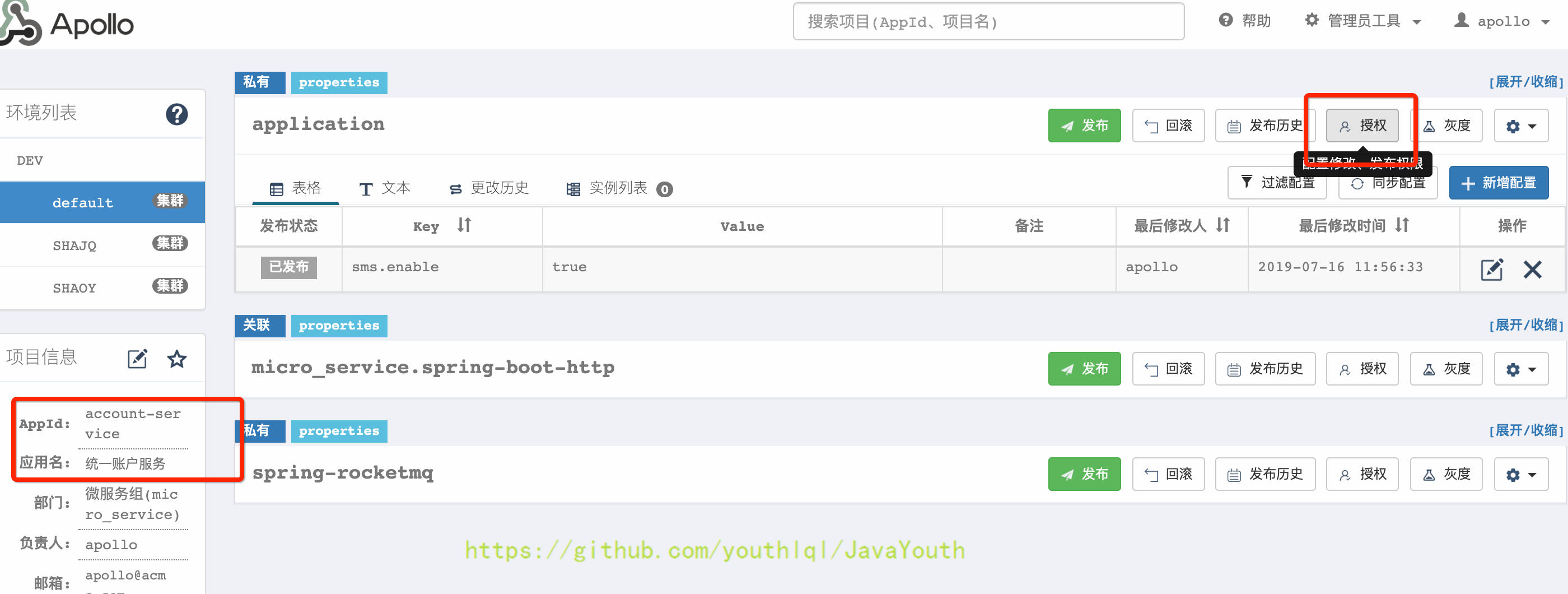 * 将修改和发布权限都授权给张三
@@ -731,7 +731,7 @@ Namespace作为配置的分类,可当成一个配置文件。
进入项目首页,点击左下脚的“添加Namespace”,共包括两项:关联公共Namespace和创建Namespace,这里选择“创建Namespace”
-
* 将修改和发布权限都授权给张三
@@ -731,7 +731,7 @@ Namespace作为配置的分类,可当成一个配置文件。
进入项目首页,点击左下脚的“添加Namespace”,共包括两项:关联公共Namespace和创建Namespace,这里选择“创建Namespace”
- +
+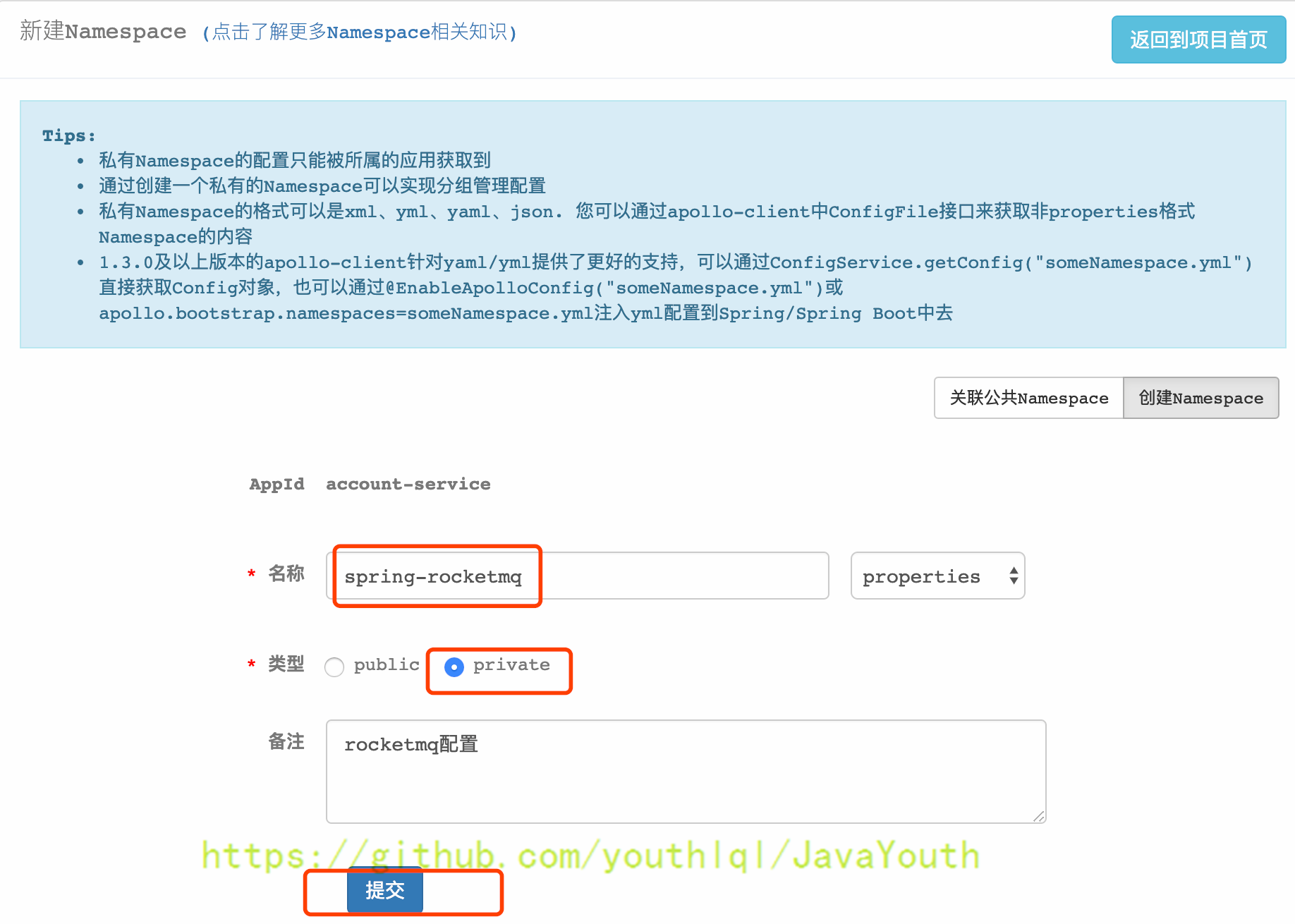 2. 添加配置项
@@ -758,11 +758,11 @@ Namespace作为配置的分类,可当成一个配置文件。
进入common-template项目管理页面:[http://localhost:8070/config.html?#/appid=common-template](http://localhost:8070/config.html?#/appid=common-template)
-
2. 添加配置项
@@ -758,11 +758,11 @@ Namespace作为配置的分类,可当成一个配置文件。
进入common-template项目管理页面:[http://localhost:8070/config.html?#/appid=common-template](http://localhost:8070/config.html?#/appid=common-template)
- +
+ -
- +
+ 1. 添加配置项并发布
@@ -786,11 +786,11 @@ Namespace作为配置的分类,可当成一个配置文件。
2. 点击左侧的添加Namespace
3. 添加Namespace
-
1. 添加配置项并发布
@@ -786,11 +786,11 @@ Namespace作为配置的分类,可当成一个配置文件。
2. 点击左侧的添加Namespace
3. 添加Namespace
- +
+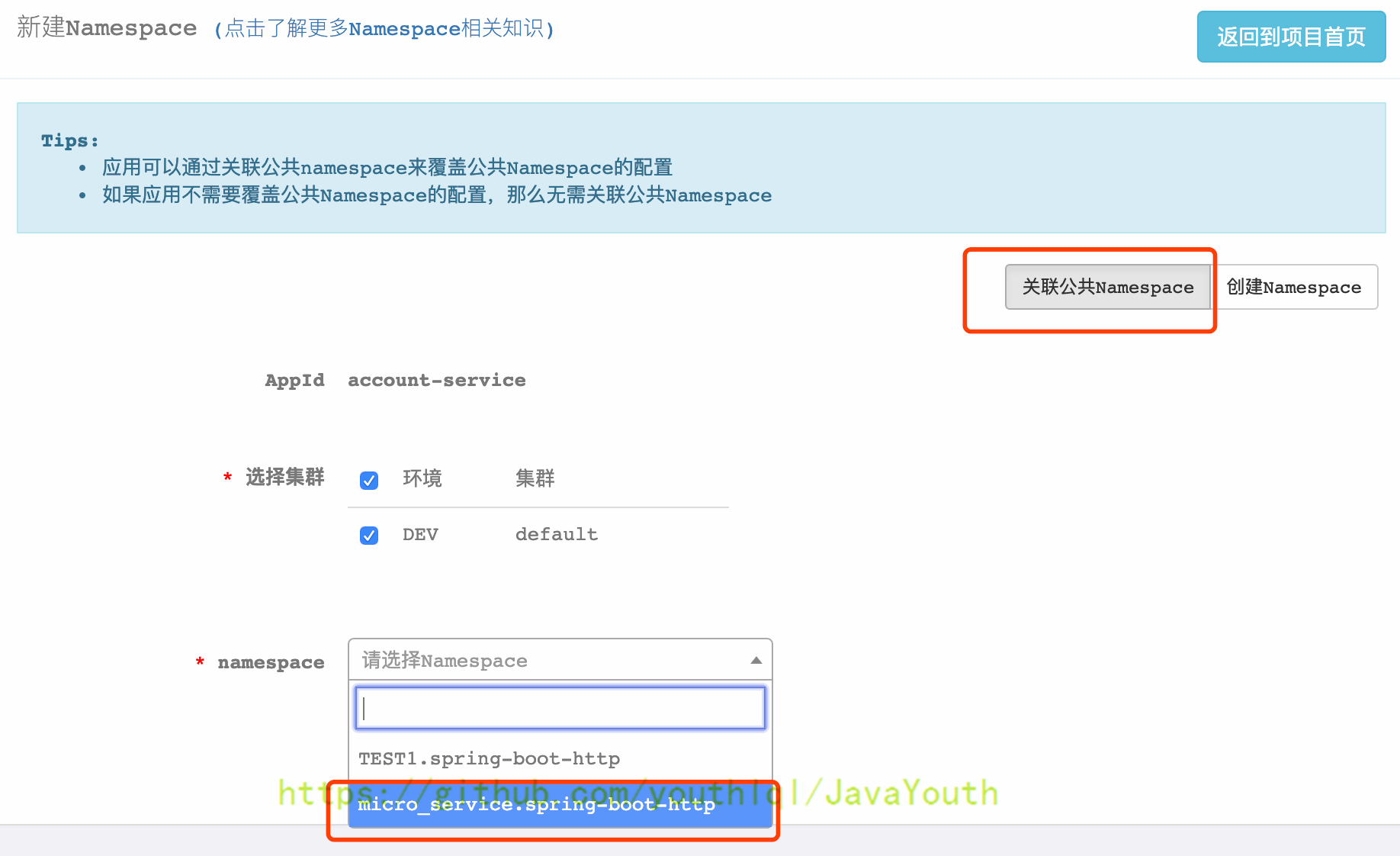 4. 根据需求可以覆盖引入公共Namespace中的配置,下面以覆盖server.servlet.context-path为例
-
4. 根据需求可以覆盖引入公共Namespace中的配置,下面以覆盖server.servlet.context-path为例
- +
+ 5. 修改server.servlet.context-path为:/account-service
6. 发布修改的配置项
@@ -806,15 +806,15 @@ Namespace作为配置的分类,可当成一个配置文件。
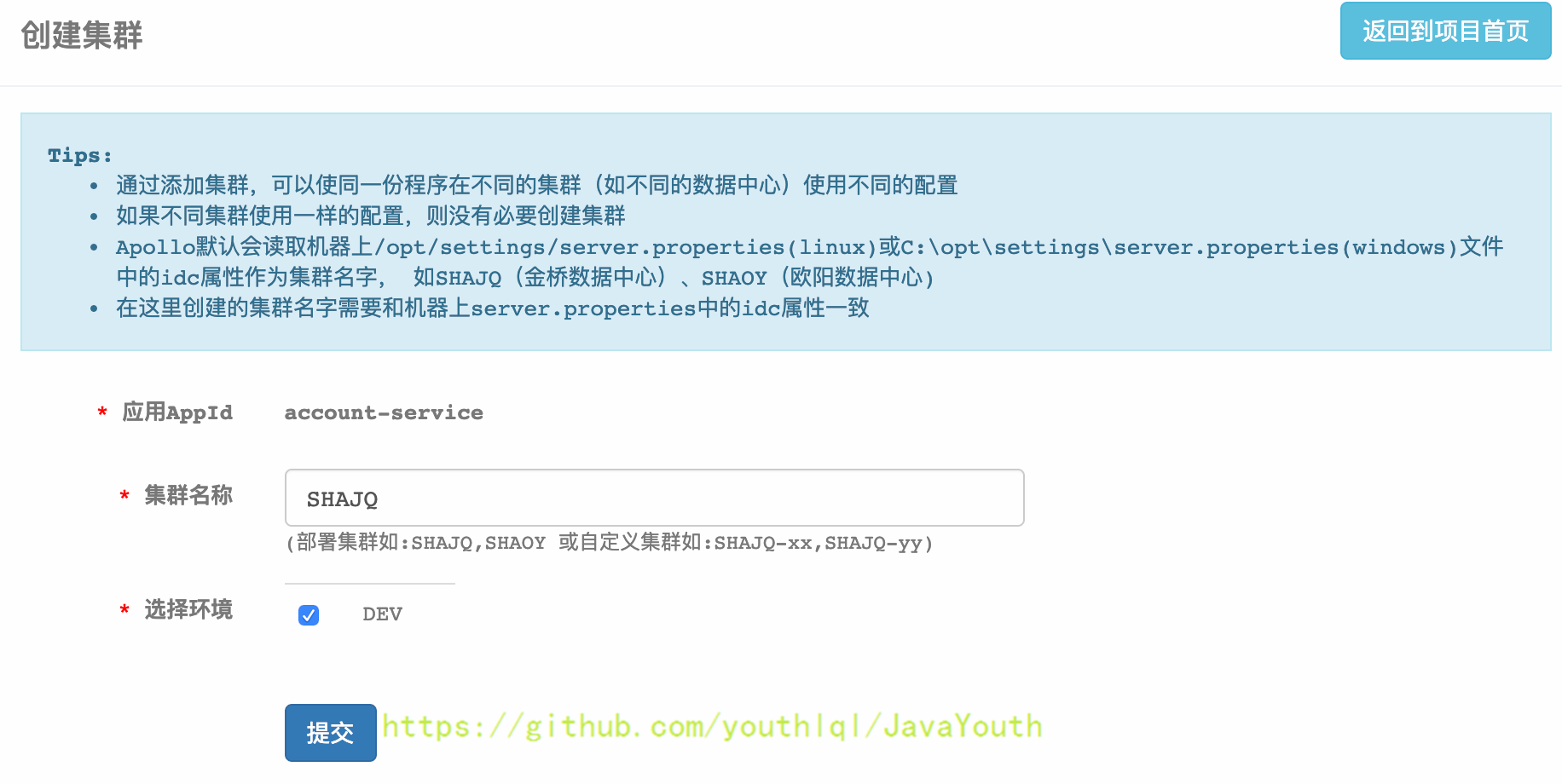
1. 点击页面左侧的“添加集群”按钮
2. 输入集群名称SHAJQ,选择环境并提交:添加上海金桥数据中心为例
-
5. 修改server.servlet.context-path为:/account-service
6. 发布修改的配置项
@@ -806,15 +806,15 @@ Namespace作为配置的分类,可当成一个配置文件。
1. 点击页面左侧的“添加集群”按钮
2. 输入集群名称SHAJQ,选择环境并提交:添加上海金桥数据中心为例
- +
+ -
+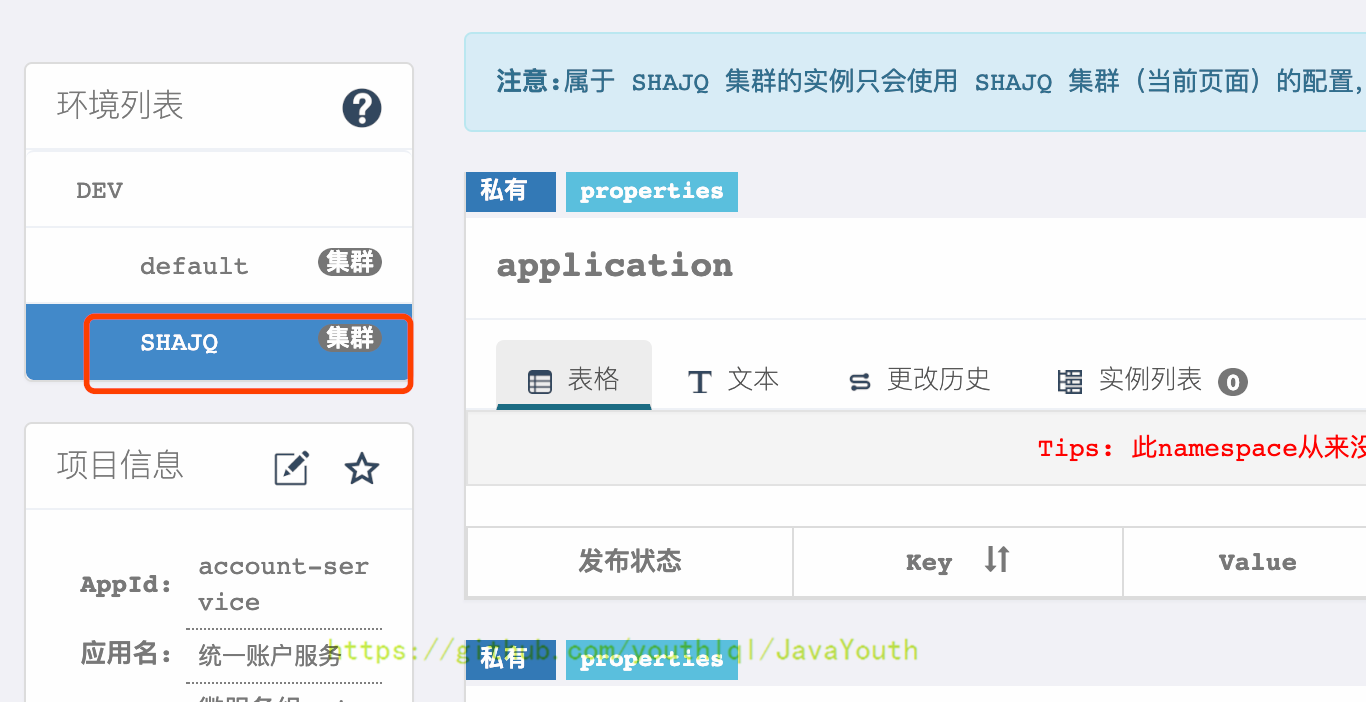
3. 切换到对应的集群,修改配置并发布即可
-
-
+
3. 切换到对应的集群,修改配置并发布即可
- +
+ #### 同步集群配置
@@ -827,19 +827,19 @@ Namespace作为配置的分类,可当成一个配置文件。
* 展开要同步的Namespace,点击同步配置
-
#### 同步集群配置
@@ -827,19 +827,19 @@ Namespace作为配置的分类,可当成一个配置文件。
* 展开要同步的Namespace,点击同步配置
-  +
+ 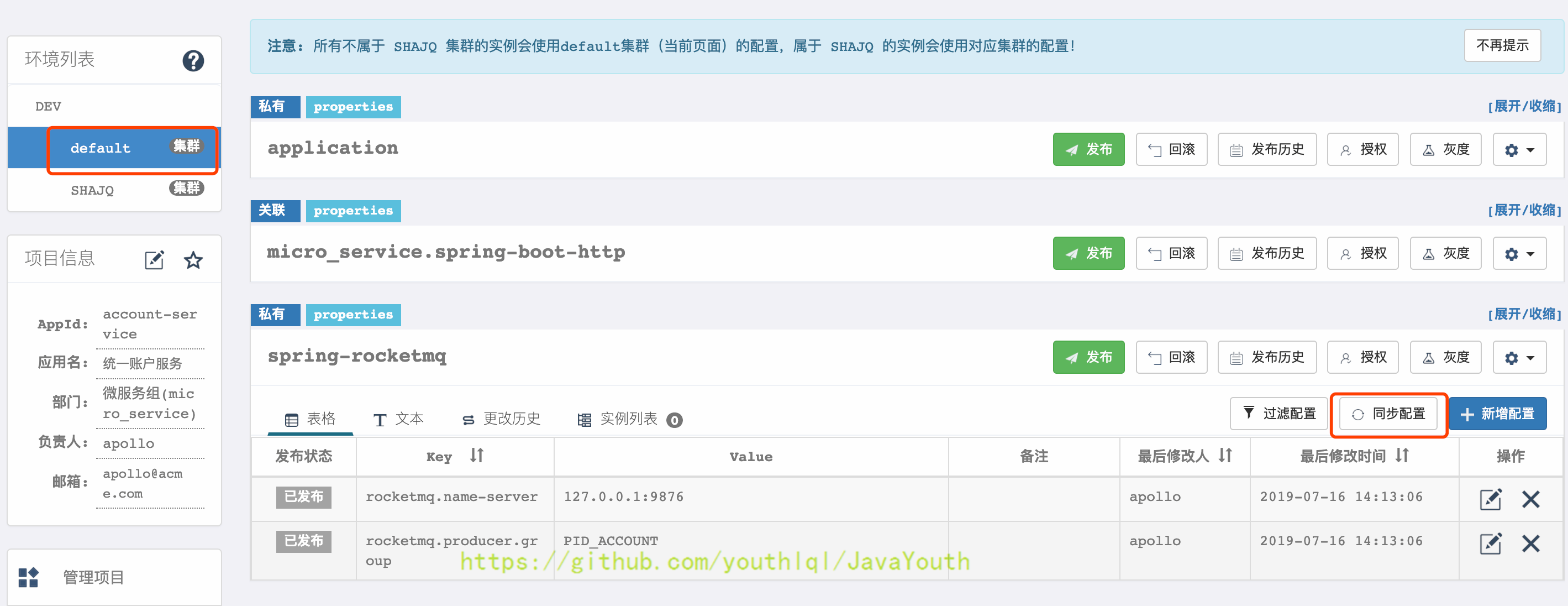 - 
+ 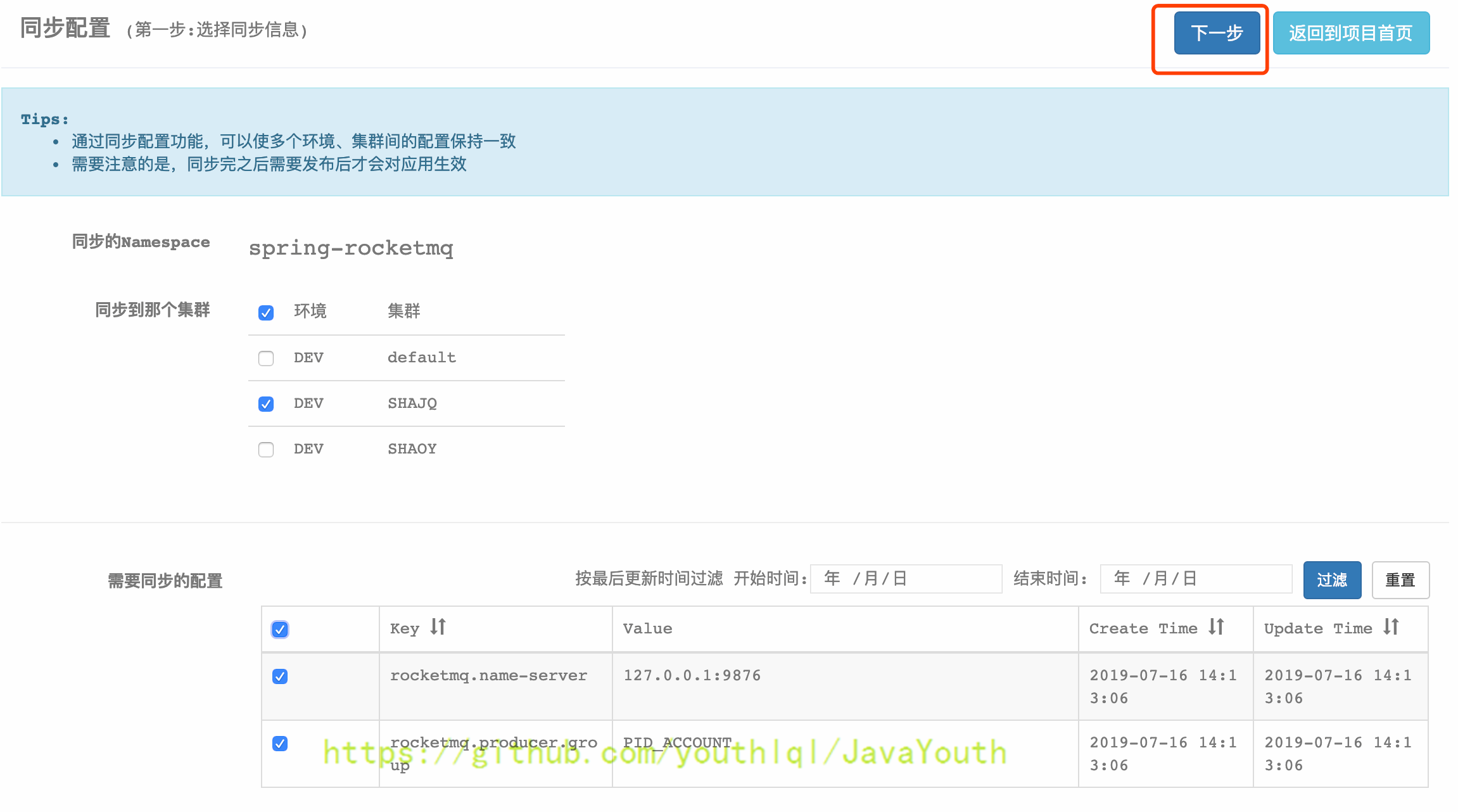
* 选择同步到的新集群,再选择要同步的配置
-
- 
+ 
* 选择同步到的新集群,再选择要同步的配置
-  +
+  * 同步完成后,切换到SHAJQ集群,发布配置
-
* 同步完成后,切换到SHAJQ集群,发布配置
-  +
+ 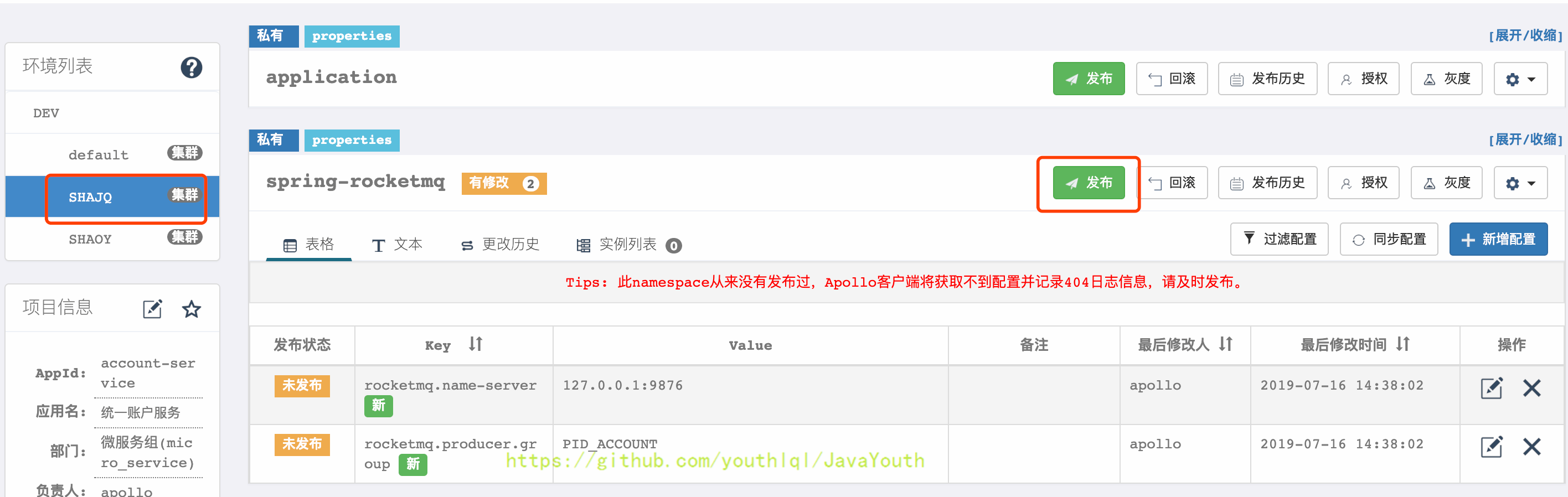 #### 读取配置
@@ -863,7 +863,7 @@ Namespace作为配置的分类,可当成一个配置文件。
在配置中心中,一个重要的功能就是配置发布后实时推送到客户端。下面我们简要看一下这块是怎么设计实现的。
-
#### 读取配置
@@ -863,7 +863,7 @@ Namespace作为配置的分类,可当成一个配置文件。
在配置中心中,一个重要的功能就是配置发布后实时推送到客户端。下面我们简要看一下这块是怎么设计实现的。
- +
+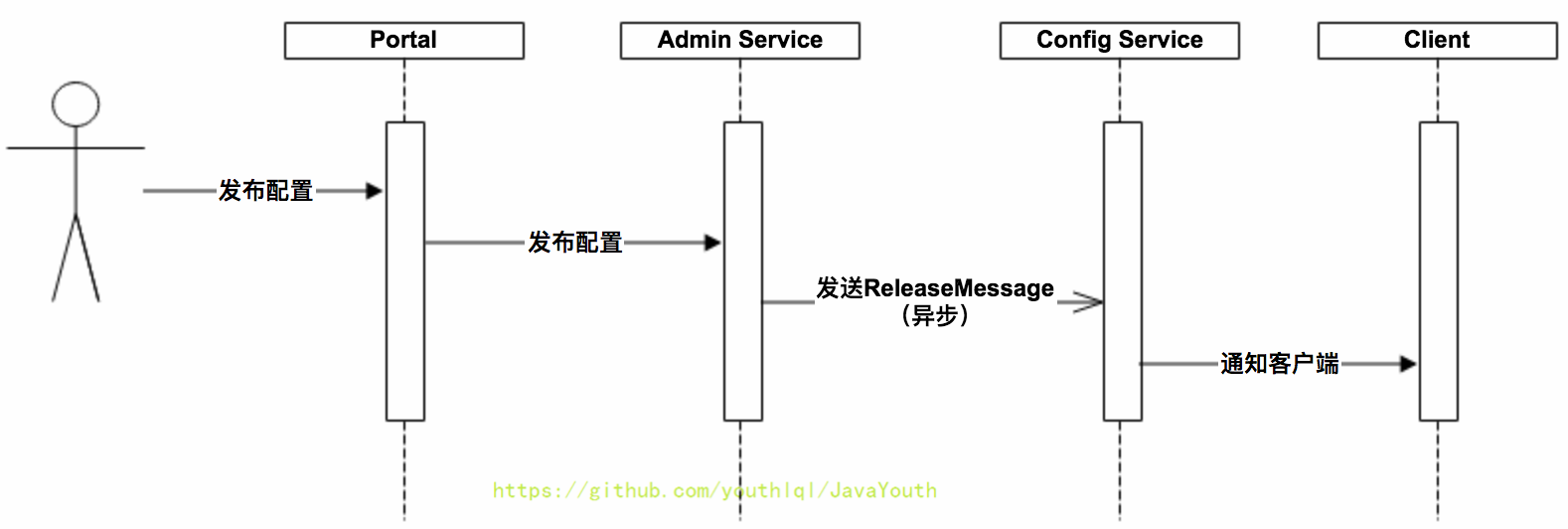 上图简要描述了配置发布的主要过程:
@@ -890,7 +890,7 @@ Admin Service在配置发布后,需要通知所有的Config Service有配置
SELECT * FROM ApolloConfigDB.ReleaseMessage
```
-
上图简要描述了配置发布的主要过程:
@@ -890,7 +890,7 @@ Admin Service在配置发布后,需要通知所有的Config Service有配置
SELECT * FROM ApolloConfigDB.ReleaseMessage
```
- +
+ @@ -1012,7 +1012,7 @@ Admin Service在配置发布后,需要通知所有的Config Service有配置
4. NotificationControllerV2得到配置发布的AppId+Cluster+Namespace后,会通知对应的客户端
-
@@ -1012,7 +1012,7 @@ Admin Service在配置发布后,需要通知所有的Config Service有配置
4. NotificationControllerV2得到配置发布的AppId+Cluster+Namespace后,会通知对应的客户端
- +
+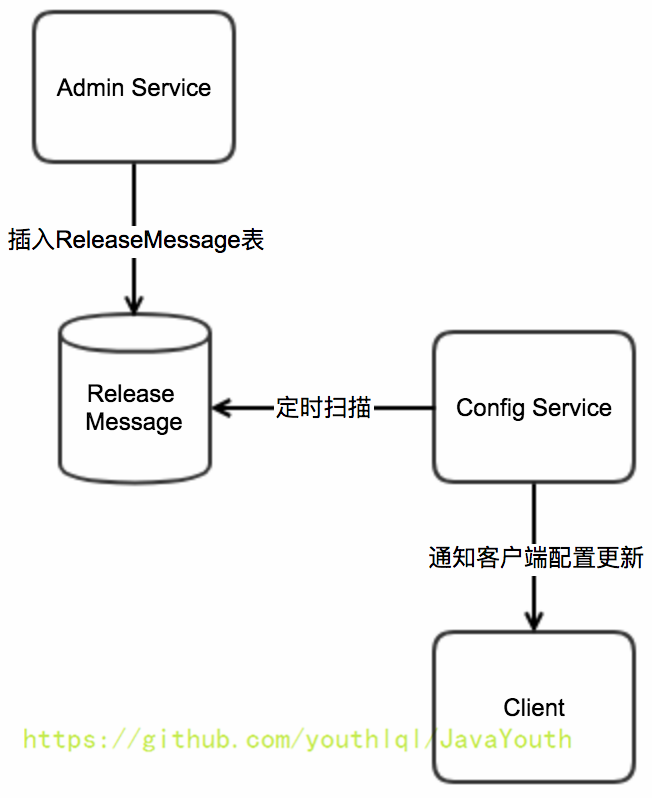 #### Config Service通知客户端
@@ -1268,7 +1268,7 @@ Apollo客户端会把从服务端获取到的配置在本地文件系统缓存
-Denv=DEV -Dapollo.cacheDir=/opt/data/apollo-config -Dapollo.cluster=DEFAULTbash
```
-
#### Config Service通知客户端
@@ -1268,7 +1268,7 @@ Apollo客户端会把从服务端获取到的配置在本地文件系统缓存
-Denv=DEV -Dapollo.cacheDir=/opt/data/apollo-config -Dapollo.cluster=DEFAULTbash
```
- +
+ @@ -1366,11 +1366,11 @@ public class AccountApplication {
2. spring-http命名空间在之前已通过关联公共命名空间添加好了,现在来添加spring-boot-druid命名空间
-
@@ -1366,11 +1366,11 @@ public class AccountApplication {
2. spring-http命名空间在之前已通过关联公共命名空间添加好了,现在来添加spring-boot-druid命名空间
- +
+ 3. 添加本地文件中的配置到对应的命名空间,然后发布配置
-
3. 添加本地文件中的配置到对应的命名空间,然后发布配置
- +
+ 4. 在account-service/src/main/resources/application.properties中配置apollo.bootstrap.namespaces需要引入的命名空间(上面写过)
@@ -1458,7 +1458,7 @@ public class AccountController {
* 访问[http://127.0.0.1:63000/account-service/db-url](http://127.0.0.1:63000/account-service/db-url),显示结果
-
4. 在account-service/src/main/resources/application.properties中配置apollo.bootstrap.namespaces需要引入的命名空间(上面写过)
@@ -1458,7 +1458,7 @@ public class AccountController {
* 访问[http://127.0.0.1:63000/account-service/db-url](http://127.0.0.1:63000/account-service/db-url),显示结果
- +
+ #### 创建其它项目
@@ -1474,7 +1474,7 @@ public class AccountController {
具体如下图所示:
-
#### 创建其它项目
@@ -1474,7 +1474,7 @@ public class AccountController {
具体如下图所示:
- +
+ 下面以添加生产环境部署为例
@@ -1523,7 +1523,7 @@ UPDATE ServerConfig SET `Value` = "http://localhost:8081/eureka/" WHERE `key` =
服务配置项统一存储在ApolloPortalDB.ServerConfig表中,可以通过`管理员工具 - 系统参数`页面进行配置:apollo.portal.envs - 可支持的环境列表
-
下面以添加生产环境部署为例
@@ -1523,7 +1523,7 @@ UPDATE ServerConfig SET `Value` = "http://localhost:8081/eureka/" WHERE `key` =
服务配置项统一存储在ApolloPortalDB.ServerConfig表中,可以通过`管理员工具 - 系统参数`页面进行配置:apollo.portal.envs - 可支持的环境列表
- +
+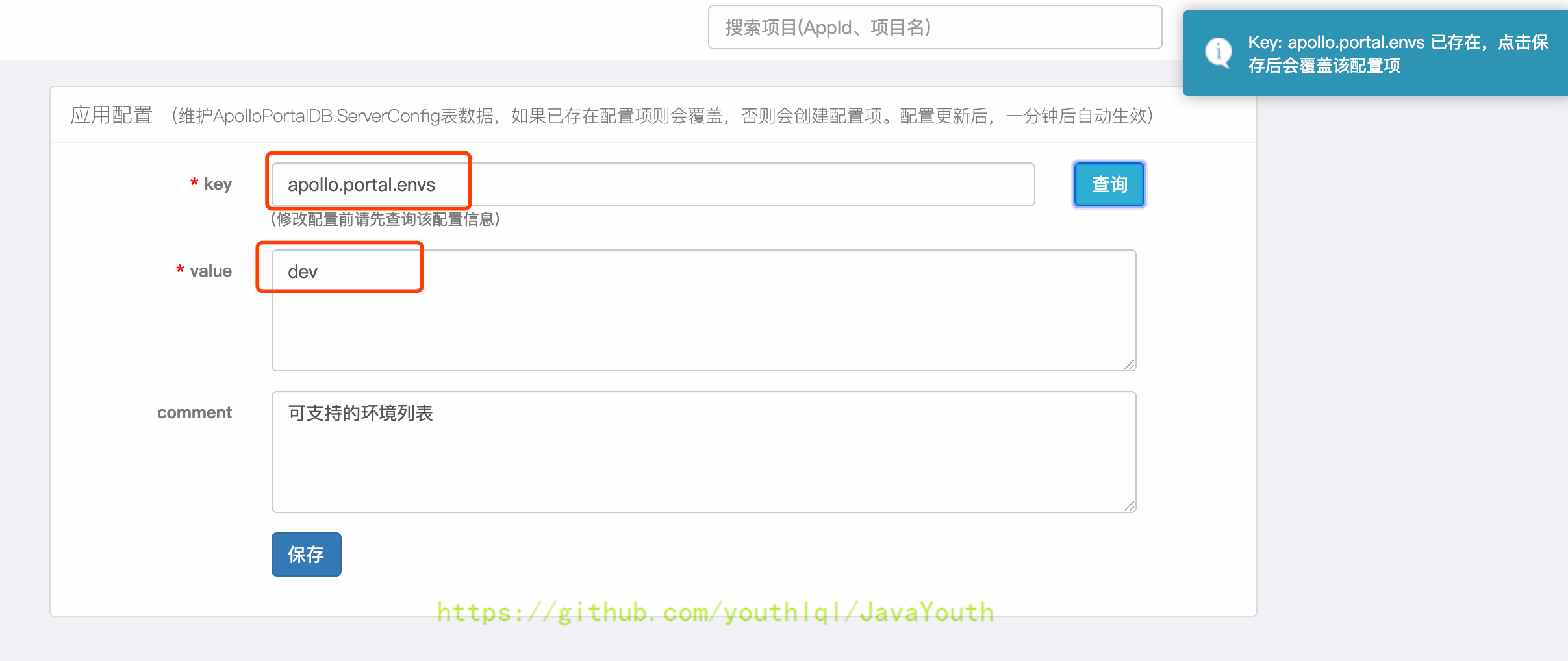 默认值是dev,如果portal需要管理多个环境的话,以逗号分隔即可(大小写不敏感),如:
@@ -1556,7 +1556,7 @@ Apollo Portal需要在不同的环境访问不同的meta service(apollo-configse
1. 启动之后,点击account-service服务配置后会提示环境缺失,此时需要补全上边新增生产环境的配置
-
默认值是dev,如果portal需要管理多个环境的话,以逗号分隔即可(大小写不敏感),如:
@@ -1556,7 +1556,7 @@ Apollo Portal需要在不同的环境访问不同的meta service(apollo-configse
1. 启动之后,点击account-service服务配置后会提示环境缺失,此时需要补全上边新增生产环境的配置
- +
+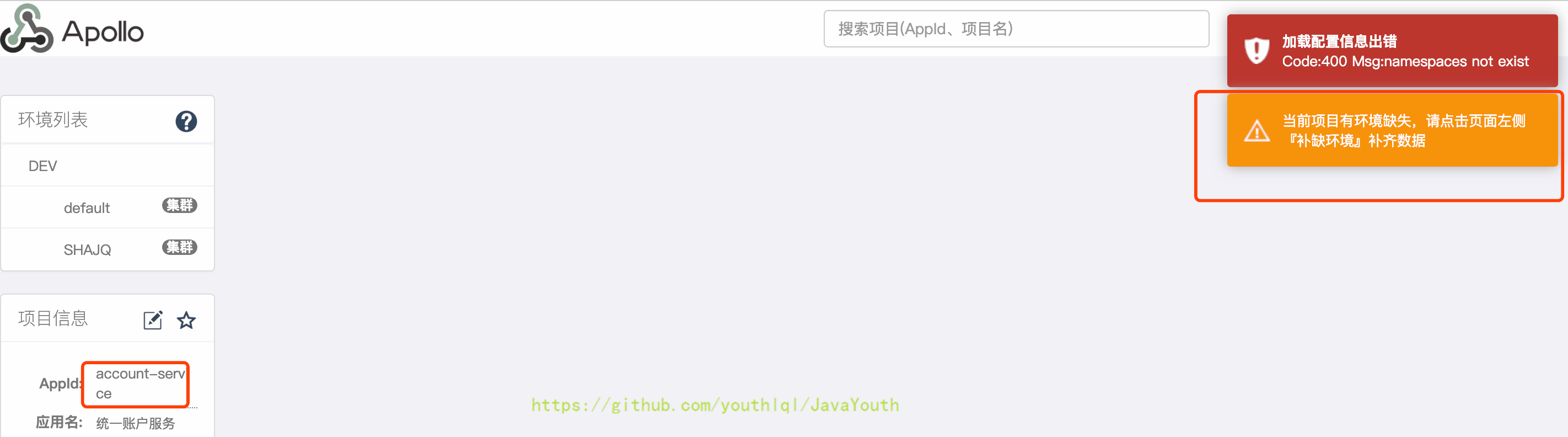 3. 点击左下方的补缺环境
@@ -1564,7 +1564,7 @@ Apollo Portal需要在不同的环境访问不同的meta service(apollo-configse
4. 补缺过生产环境后,切换到PRO环境后会提示有Namespace缺失,点击补缺
-
3. 点击左下方的补缺环境
@@ -1564,7 +1564,7 @@ Apollo Portal需要在不同的环境访问不同的meta service(apollo-configse
4. 补缺过生产环境后,切换到PRO环境后会提示有Namespace缺失,点击补缺
- +
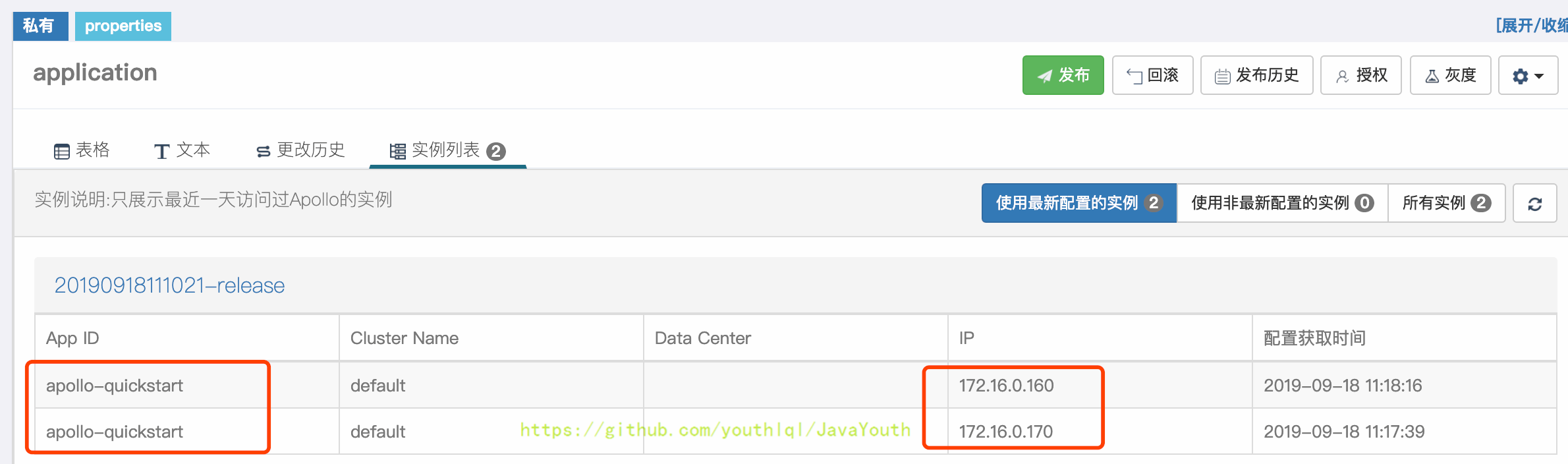
+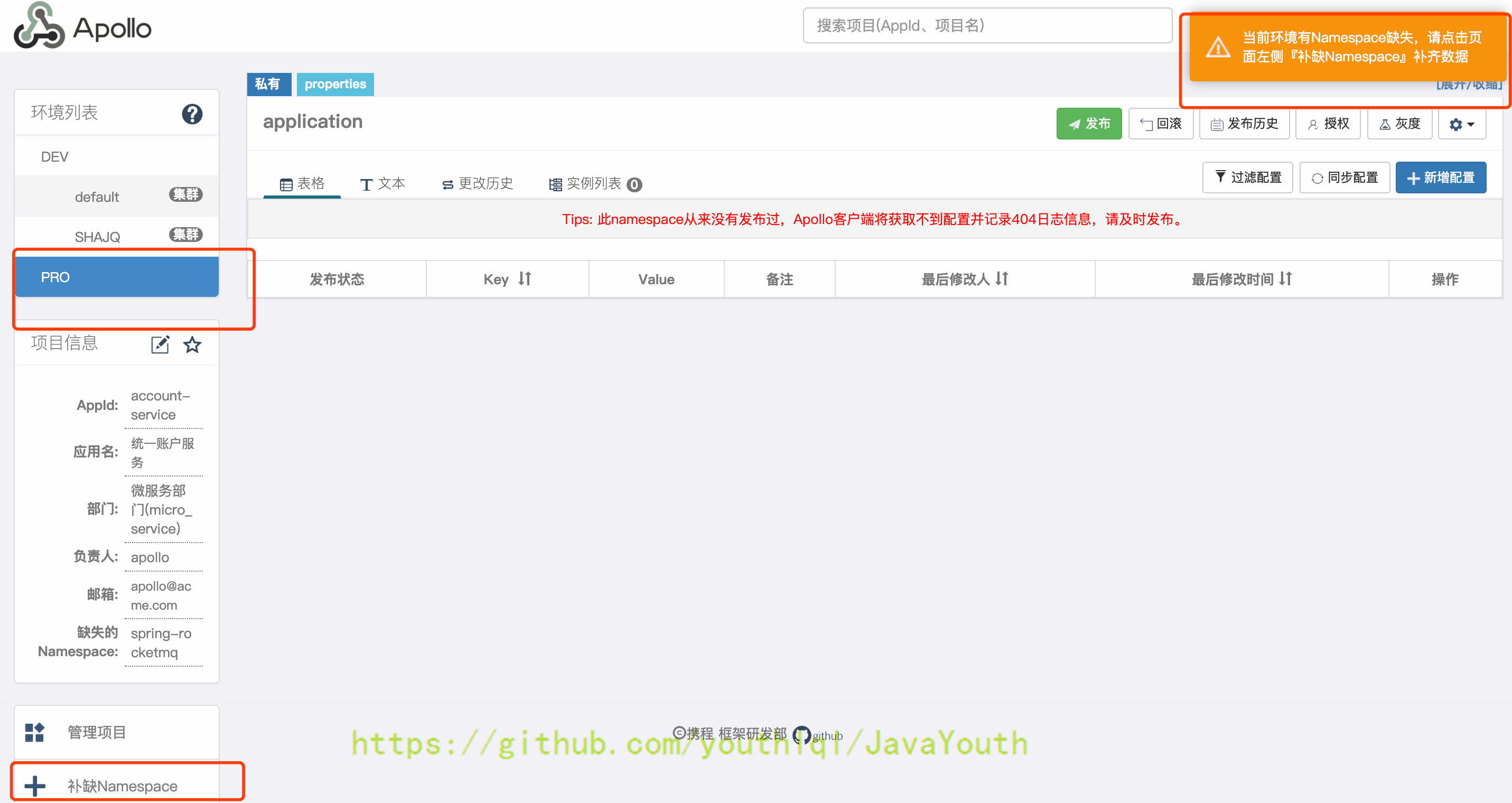 5. 从dev环境同步配置到pro
@@ -1610,7 +1610,7 @@ apollo-quickstart项目有两个客户端:
1. 172.16.0.160
2. 172.16.0.170
-
5. 从dev环境同步配置到pro
@@ -1610,7 +1610,7 @@ apollo-quickstart项目有两个客户端:
1. 172.16.0.160
2. 172.16.0.170
- +
+ **灰度目标**
@@ -1626,7 +1626,7 @@ apollo-quickstart项目有两个客户端:
2. 点击确定后,灰度版本就创建成功了,页面会自动切换到`灰度版本`Tab
-
**灰度目标**
@@ -1626,7 +1626,7 @@ apollo-quickstart项目有两个客户端:
2. 点击确定后,灰度版本就创建成功了,页面会自动切换到`灰度版本`Tab
- +
+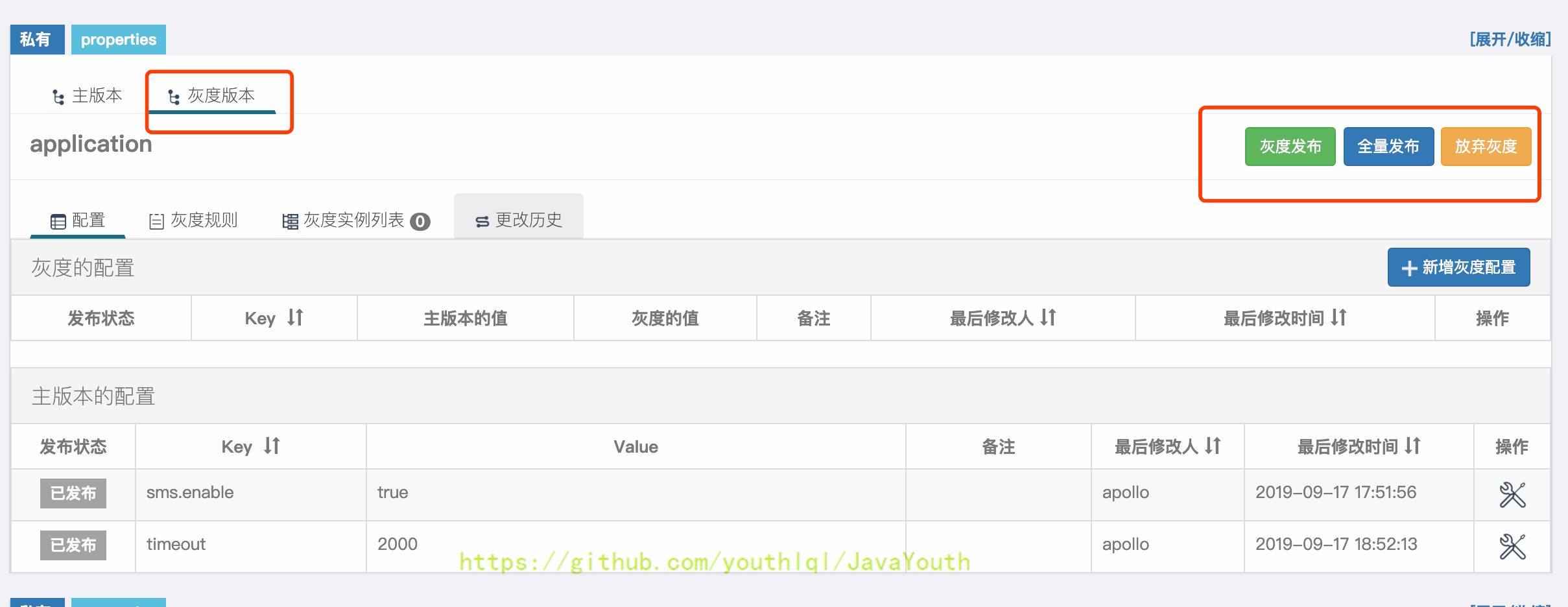 #### 灰度配置
@@ -1634,17 +1634,17 @@ apollo-quickstart项目有两个客户端:
2. 在弹出框中填入要灰度的值:3000,点击提交
-
#### 灰度配置
@@ -1634,17 +1634,17 @@ apollo-quickstart项目有两个客户端:
2. 在弹出框中填入要灰度的值:3000,点击提交
- +
+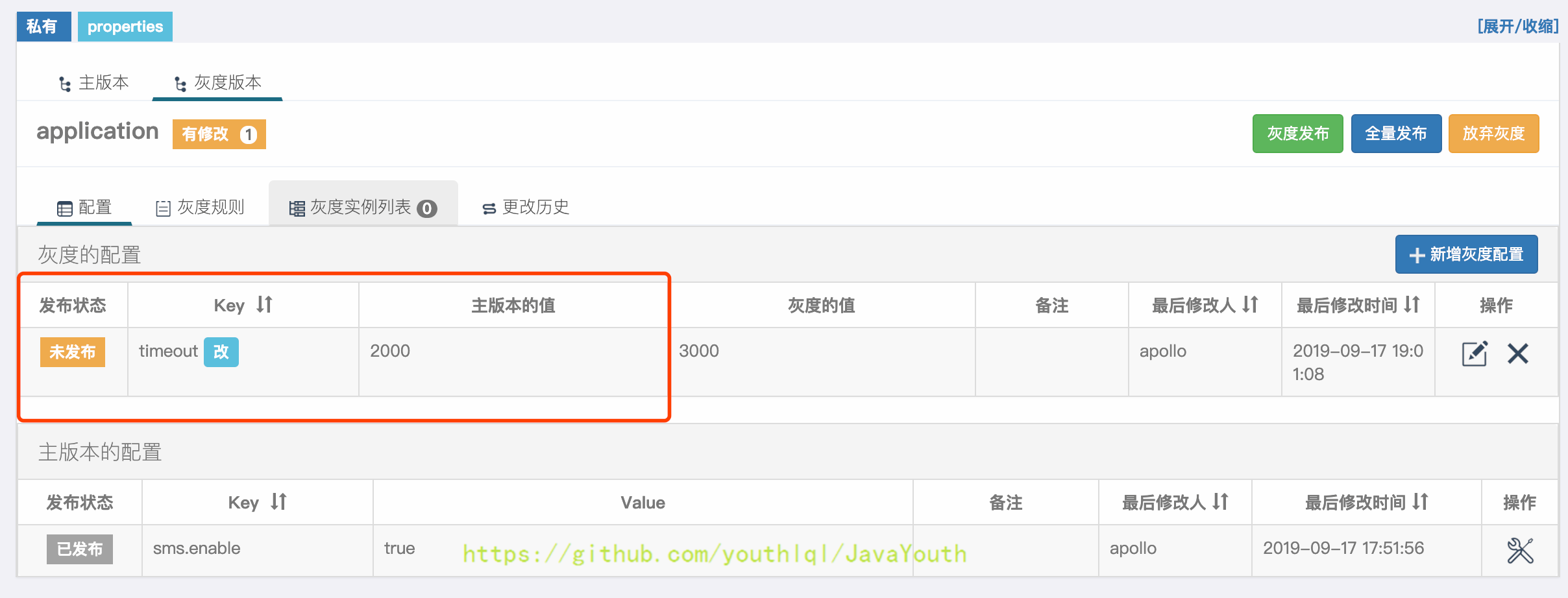 #### 配置灰度规则
1. 切换到`灰度规则`Tab,点击`新增规则`按钮
-
#### 配置灰度规则
1. 切换到`灰度规则`Tab,点击`新增规则`按钮
- +
+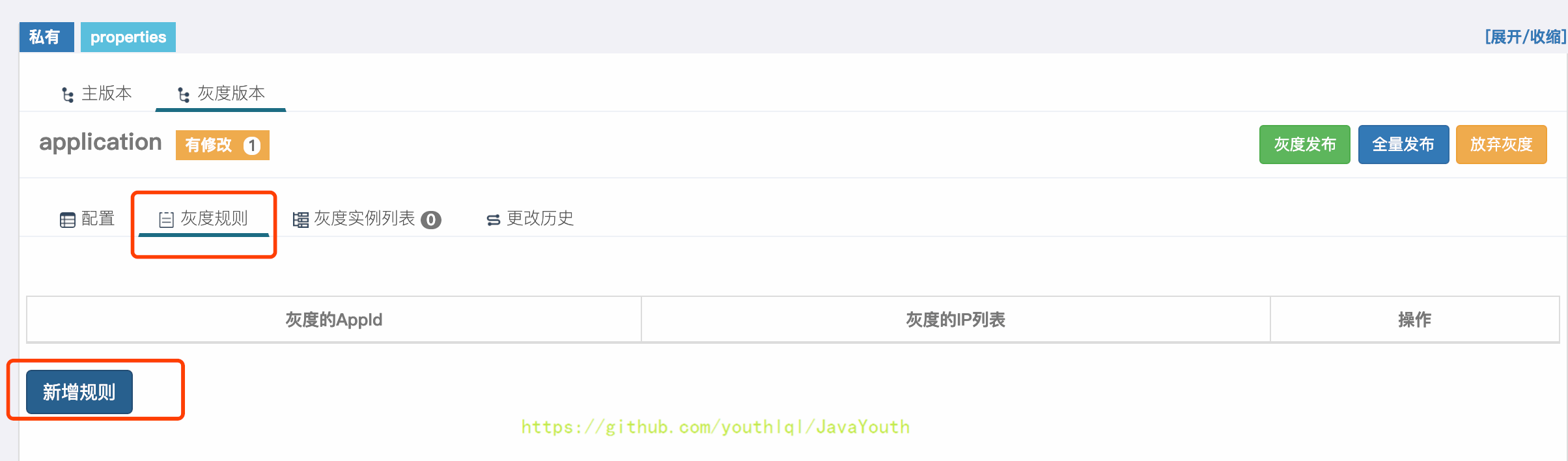 2. 在弹出框中`灰度的IP`下拉框会默认展示当前使用配置的机器列表,选择我们要灰度的IP,点击完成
-
2. 在弹出框中`灰度的IP`下拉框会默认展示当前使用配置的机器列表,选择我们要灰度的IP,点击完成
- +
+ 如果下拉框中没找到需要的IP,说明机器还没从Apollo取过配置,可以点击手动输入IP来输入,输入完后点击添加按钮
@@ -1674,11 +1674,11 @@ vm options: `-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:80
}
```
-
如果下拉框中没找到需要的IP,说明机器还没从Apollo取过配置,可以点击手动输入IP来输入,输入完后点击添加按钮
@@ -1674,11 +1674,11 @@ vm options: `-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:80
}
```
- +
+ 2. 切换到`配置`Tab,再次检查灰度的配置部分,如果没有问题,点击`灰度发布`
-
2. 切换到`配置`Tab,再次检查灰度的配置部分,如果没有问题,点击`灰度发布`
- +
+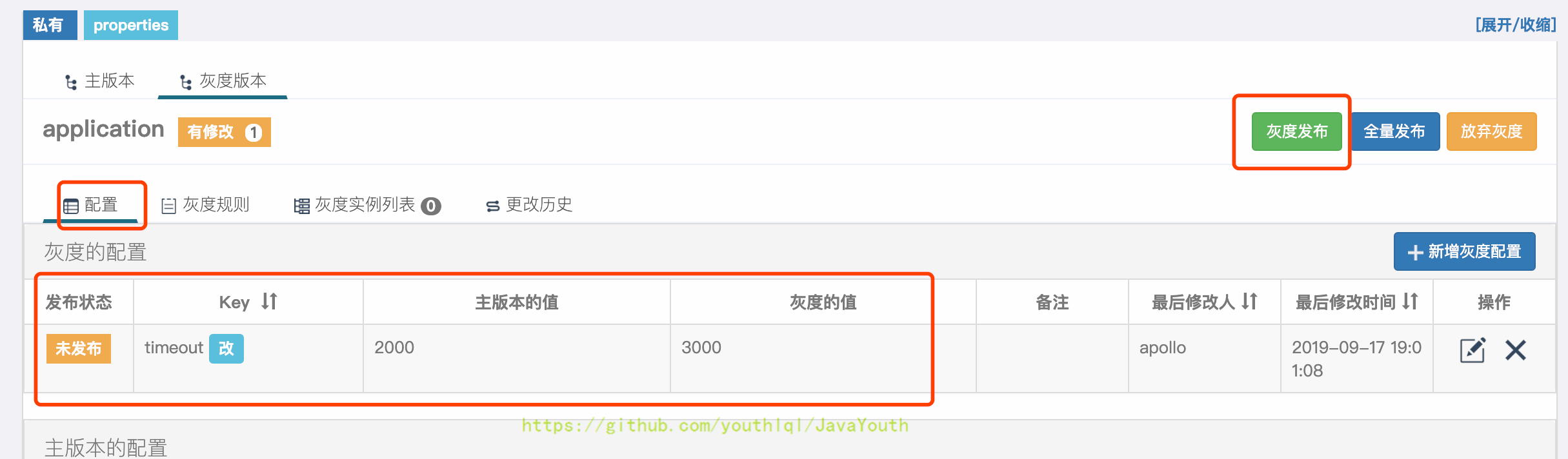 3. 在弹出框中可以看到主版本的值是2000,灰度版本即将发布的值是3000。填入其它信息后,点击发布
@@ -1686,9 +1686,9 @@ vm options: `-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:80
4. 发布后,切换到`灰度实例列表`Tab,就能看到172.16.0.160已经使用了灰度发布的值
-
3. 在弹出框中可以看到主版本的值是2000,灰度版本即将发布的值是3000。填入其它信息后,点击发布
@@ -1686,9 +1686,9 @@ vm options: `-Dapp.id=apollo-quickstart -Denv=DEV -Ddev_meta=http://localhost:80
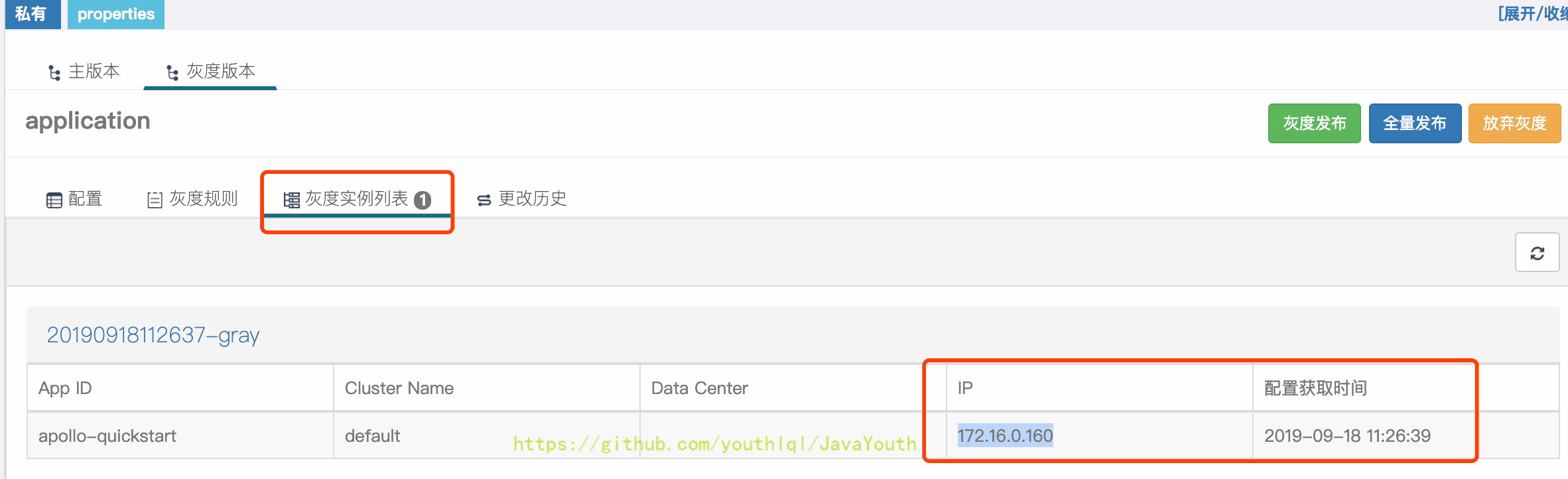
4. 发布后,切换到`灰度实例列表`Tab,就能看到172.16.0.160已经使用了灰度发布的值
- +
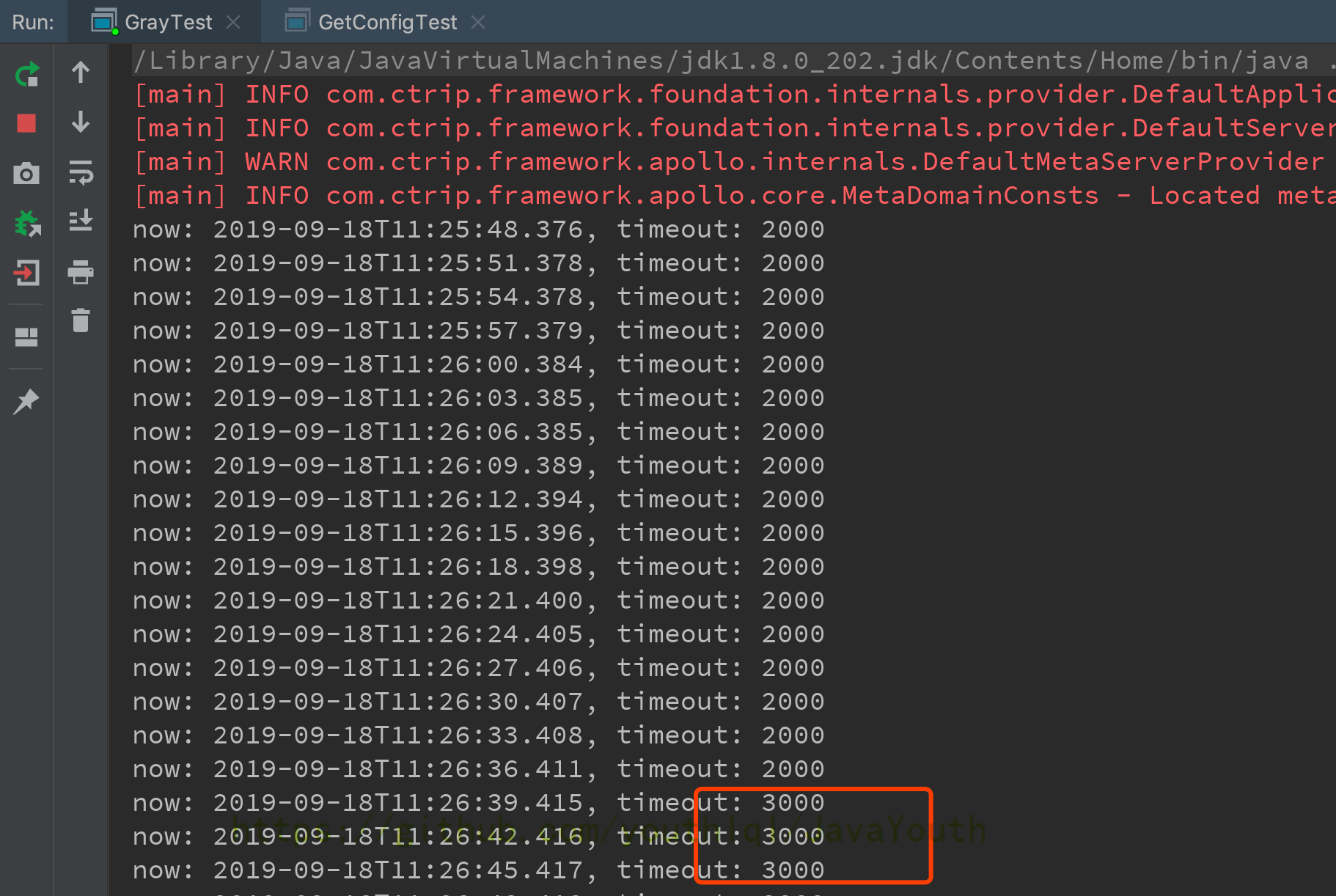
+ -
- +
+ diff --git a/docs/Computer_NetWork/计算机网络-总结.md b/docs/Computer_NetWork/计算机网络-总结.md
index 61ffa6e..289a80c 100644
--- a/docs/Computer_NetWork/计算机网络-总结.md
+++ b/docs/Computer_NetWork/计算机网络-总结.md
@@ -185,7 +185,7 @@ https://blog.csdn.net/iispring/article/details/51615631
## 区别+应用场景
-
diff --git a/docs/Computer_NetWork/计算机网络-总结.md b/docs/Computer_NetWork/计算机网络-总结.md
index 61ffa6e..289a80c 100644
--- a/docs/Computer_NetWork/计算机网络-总结.md
+++ b/docs/Computer_NetWork/计算机网络-总结.md
@@ -185,7 +185,7 @@ https://blog.csdn.net/iispring/article/details/51615631
## 区别+应用场景
- +
+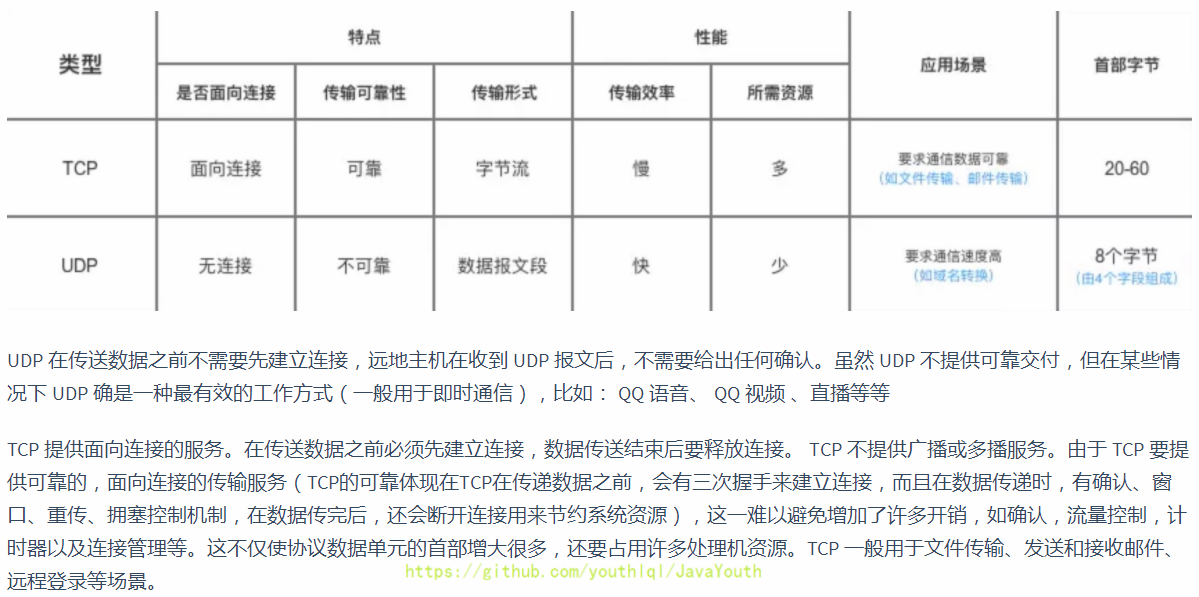 **总结:**
@@ -300,7 +300,7 @@ TCP通过三次握手建立可靠连接
在采用快恢复算法时,慢开始算法只是在TCP连接建立时和网络出现超时时才使用。
-
**总结:**
@@ -300,7 +300,7 @@ TCP通过三次握手建立可靠连接
在采用快恢复算法时,慢开始算法只是在TCP连接建立时和网络出现超时时才使用。
- +
+ diff --git a/docs/Computer_NetWork/计算机网络-概述.md b/docs/Computer_NetWork/计算机网络-概述.md
index fdff780..4232d3b 100644
--- a/docs/Computer_NetWork/计算机网络-概述.md
+++ b/docs/Computer_NetWork/计算机网络-概述.md
@@ -30,15 +30,15 @@ date: 2021-04-03 14:21:58
网络:网络(Network)由若干**结点(Node)**和连接这些结点的**链路(Link)**组成。
-
diff --git a/docs/Computer_NetWork/计算机网络-概述.md b/docs/Computer_NetWork/计算机网络-概述.md
index fdff780..4232d3b 100644
--- a/docs/Computer_NetWork/计算机网络-概述.md
+++ b/docs/Computer_NetWork/计算机网络-概述.md
@@ -30,15 +30,15 @@ date: 2021-04-03 14:21:58
网络:网络(Network)由若干**结点(Node)**和连接这些结点的**链路(Link)**组成。
- +
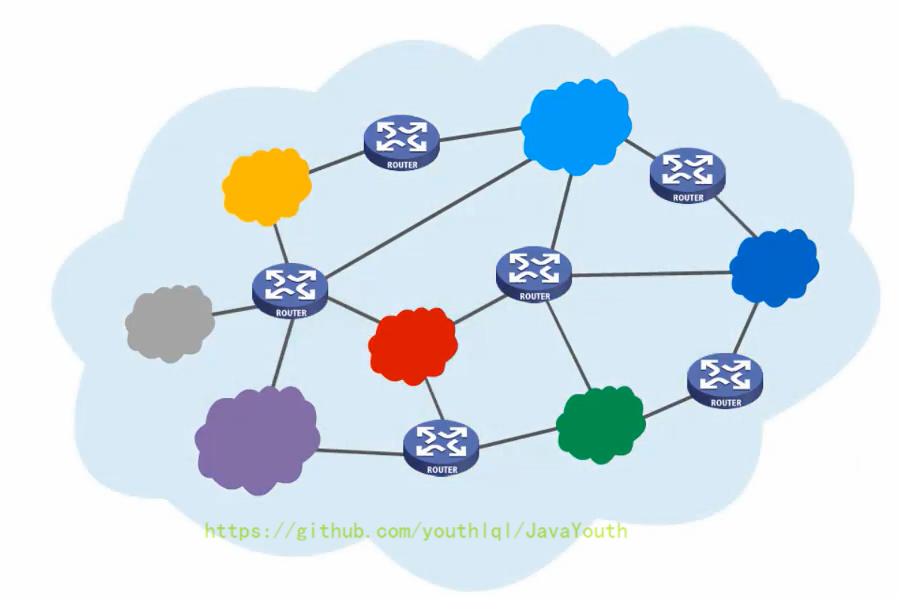
+ 互联网(或互连网):多个网络通过路由器互连起来,这样就构成了一个覆盖范围更大的网络,即互连网(互联网)。因此,互联网又称为“网络的网络(Network of Networks)”。
-
互联网(或互连网):多个网络通过路由器互连起来,这样就构成了一个覆盖范围更大的网络,即互连网(互联网)。因此,互联网又称为“网络的网络(Network of Networks)”。
- +
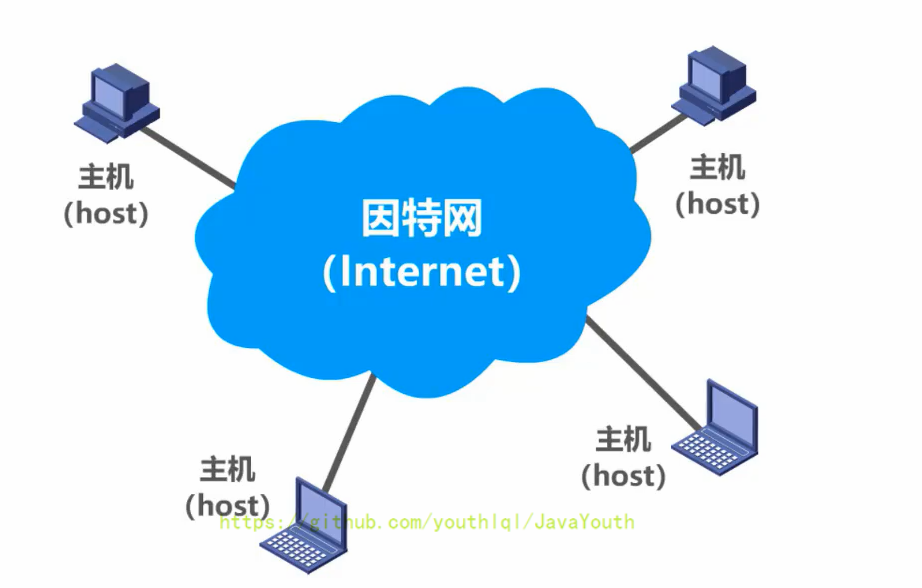
+ 因特网:因特网(Internet)是世界上最大的互连网络(用户数以亿计,互连的网络数以百万计)。
-
因特网:因特网(Internet)是世界上最大的互连网络(用户数以亿计,互连的网络数以百万计)。
- +
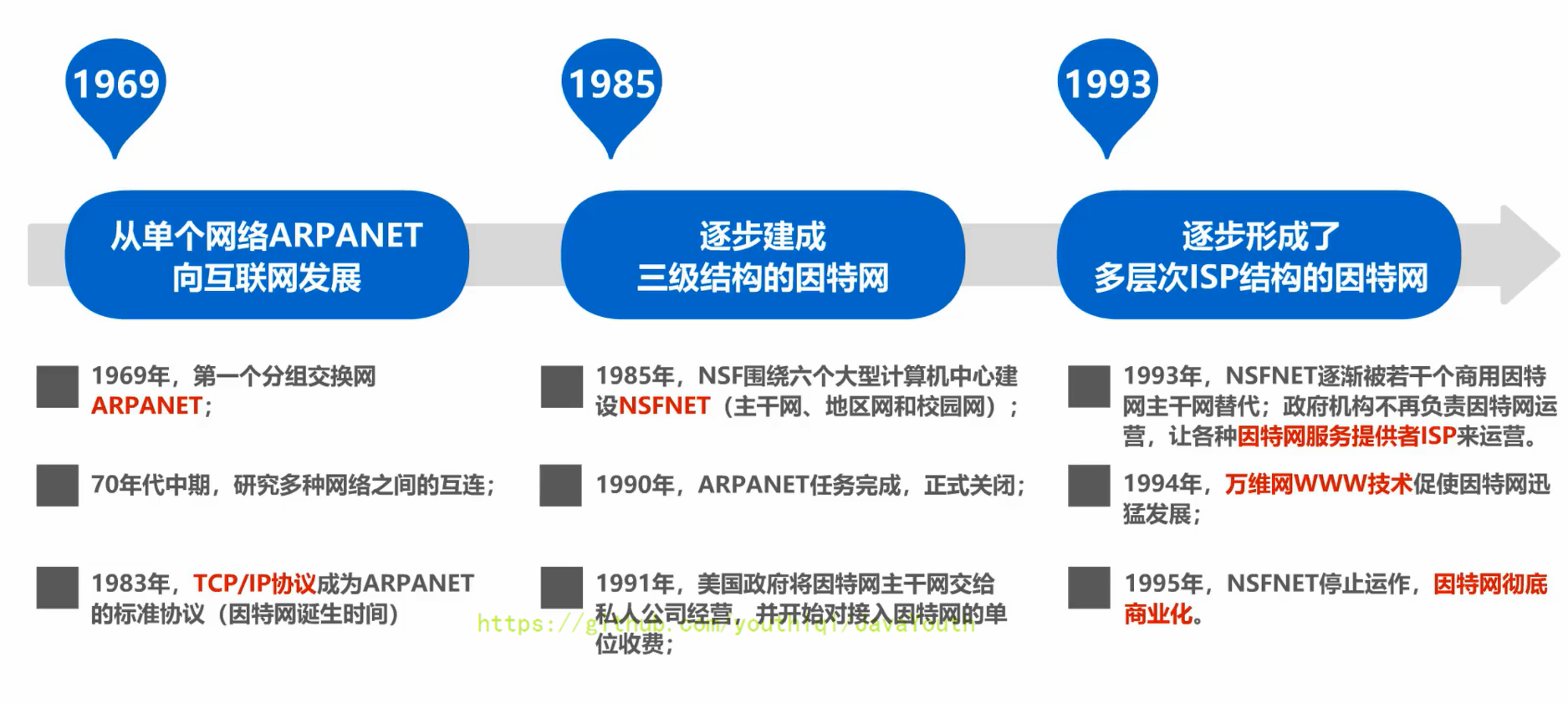
+ @@ -52,13 +52,13 @@ date: 2021-04-03 14:21:58
### 因特网发展的三个阶段
-
@@ -52,13 +52,13 @@ date: 2021-04-03 14:21:58
### 因特网发展的三个阶段
- +
+ **因特网服务提供者`ISP`(`I`nternet `S`ervice `P`rovider)**
-
**因特网服务提供者`ISP`(`I`nternet `S`ervice `P`rovider)**
- +
+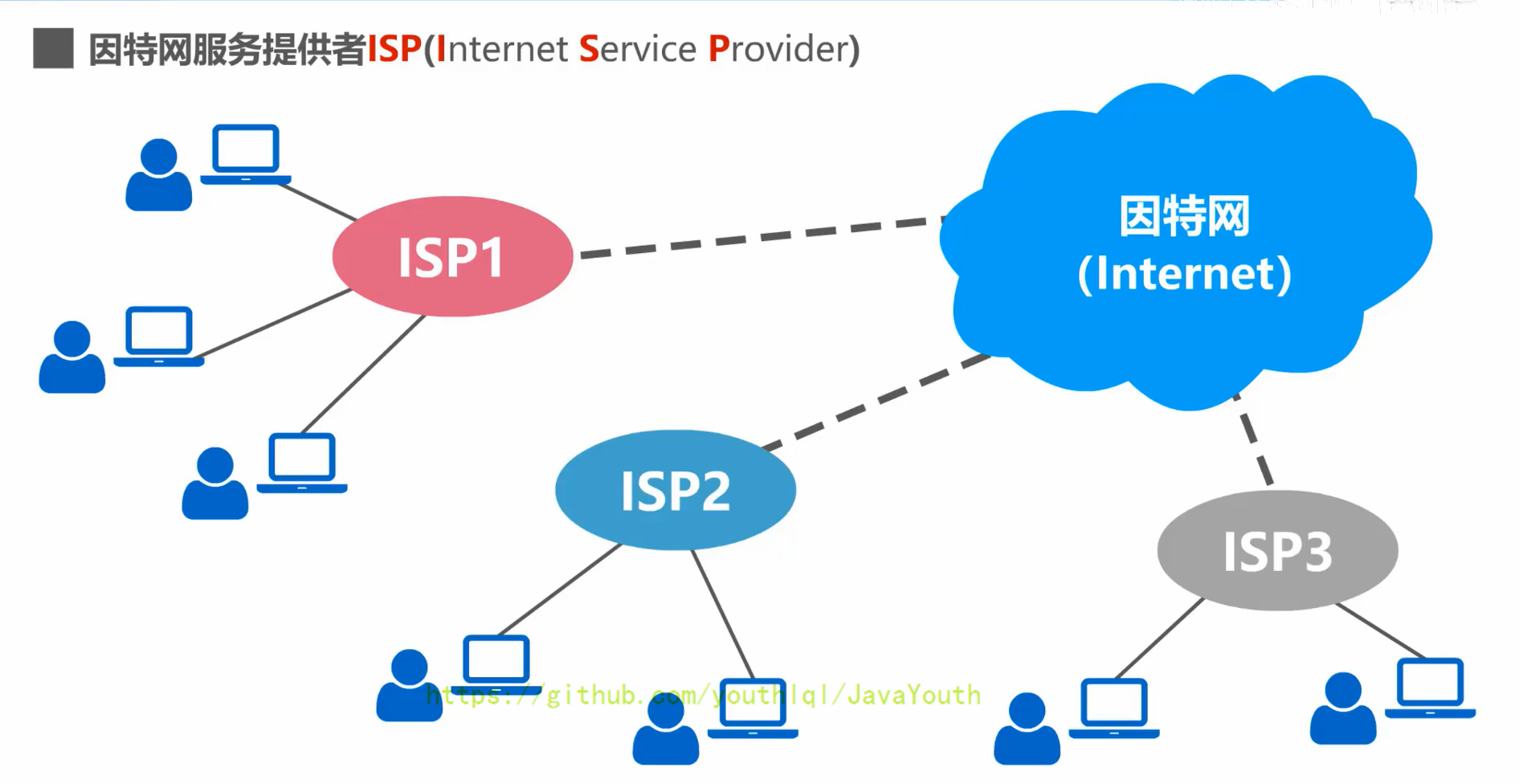 > Q:普通用户是如何接入到因特网的呢?
>
@@ -71,13 +71,13 @@ date: 2021-04-03 14:21:58
**中国的三大`ISP`:中国电信,中国联通,中国移动**
-
> Q:普通用户是如何接入到因特网的呢?
>
@@ -71,13 +71,13 @@ date: 2021-04-03 14:21:58
**中国的三大`ISP`:中国电信,中国联通,中国移动**
- +
+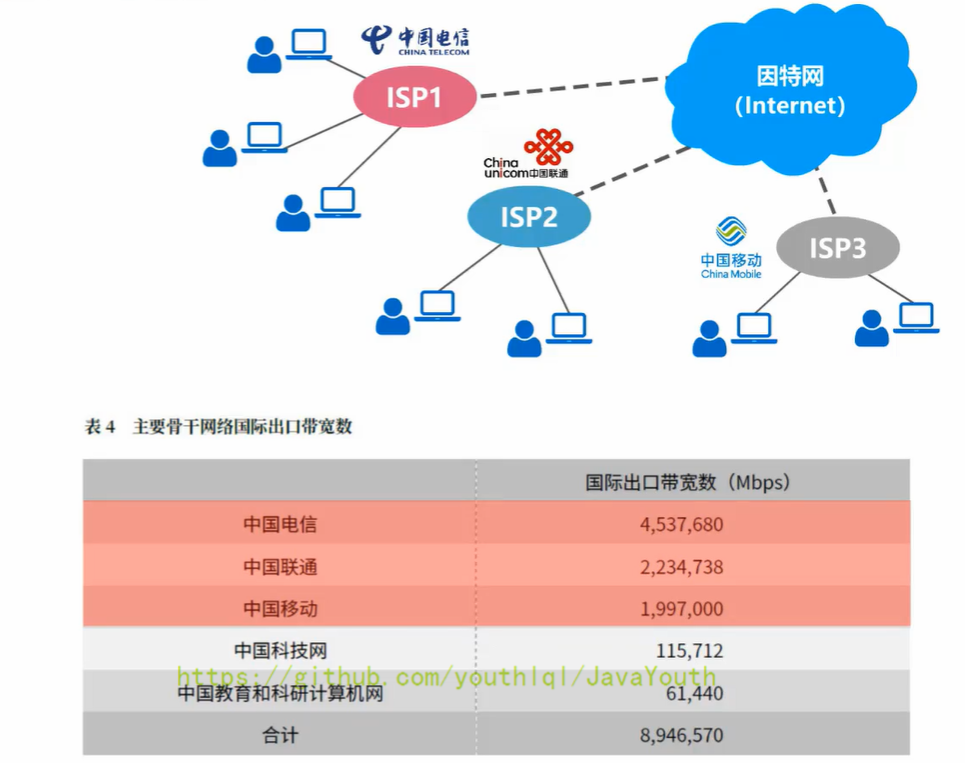 **基于ISP的三层结构的因特网**
-
**基于ISP的三层结构的因特网**
- +
+ 1、图中红线部分是两个私人用户进行通信的大致链路,可以看到需要经过多个ISP层级
@@ -100,7 +100,7 @@ date: 2021-04-03 14:21:58
* 因特网工程部IETF,负责研究中短期工程问题,主要针对协议的开发和标准化;
* 因特网研究部IRTF,从事理论方面的研究和开发一些需要长期考虑的问题。
-
1、图中红线部分是两个私人用户进行通信的大致链路,可以看到需要经过多个ISP层级
@@ -100,7 +100,7 @@ date: 2021-04-03 14:21:58
* 因特网工程部IETF,负责研究中短期工程问题,主要针对协议的开发和标准化;
* 因特网研究部IRTF,从事理论方面的研究和开发一些需要长期考虑的问题。
- +
+ * 制订因特网的正式标准要经过一下**4个阶段**:
@@ -124,7 +124,7 @@ date: 2021-04-03 14:21:58
由**大量网络**和连接这些网络的**路由器**组成。这部分是**为边缘部分提供服务**的(提供连通性和交换)。
-
* 制订因特网的正式标准要经过一下**4个阶段**:
@@ -124,7 +124,7 @@ date: 2021-04-03 14:21:58
由**大量网络**和连接这些网络的**路由器**组成。这部分是**为边缘部分提供服务**的(提供连通性和交换)。
- +
+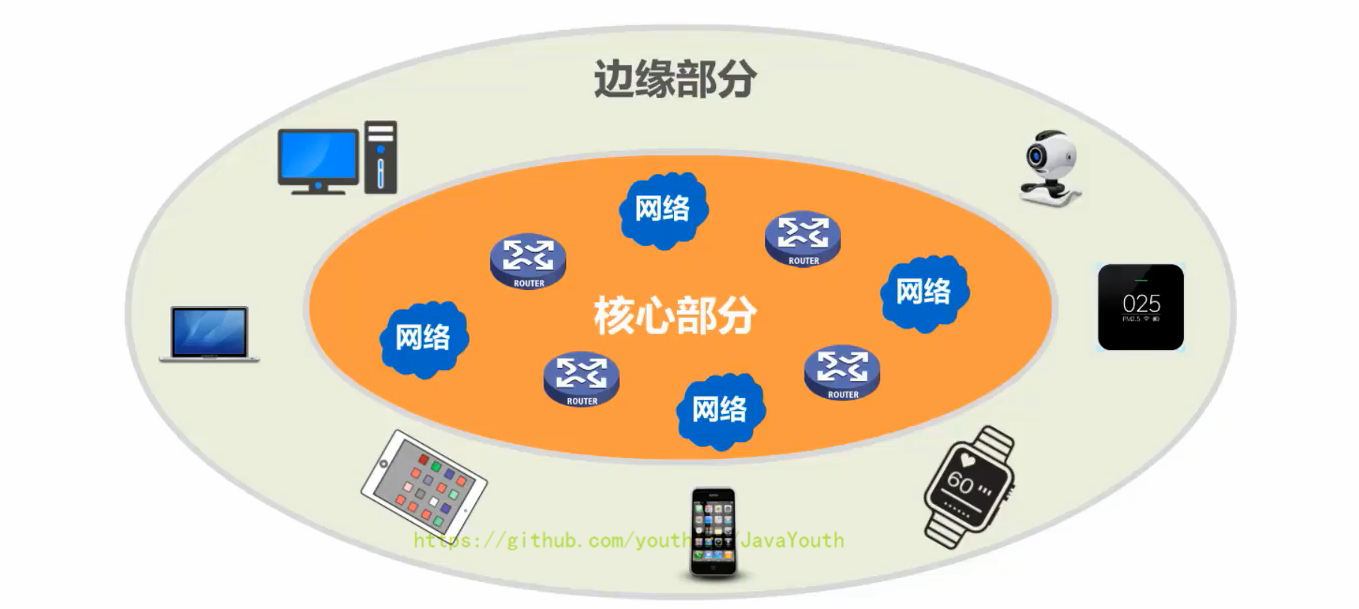 1. 路由器是一种专用计算机,但我们不称它为主机,路由器是实现分组交换的关键构建,其任务是转发收到的分组,这是网络核心最重要的部分。
@@ -142,12 +142,12 @@ date: 2021-04-03 14:21:58
### 电路交换
-
1. 路由器是一种专用计算机,但我们不称它为主机,路由器是实现分组交换的关键构建,其任务是转发收到的分组,这是网络核心最重要的部分。
@@ -142,12 +142,12 @@ date: 2021-04-03 14:21:58
### 电路交换
- +
+ 1. 传统两两相连的方式,当电话数量很多时,电话线也很多,就很不方便
2. 所以要使得每一部电话能够很方便地和另一部电话进行通信,就应该使用一个**中间设备**将这些电话连接起来,这个中间设备就是**电话交换机**
-
1. 传统两两相连的方式,当电话数量很多时,电话线也很多,就很不方便
2. 所以要使得每一部电话能够很方便地和另一部电话进行通信,就应该使用一个**中间设备**将这些电话连接起来,这个中间设备就是**电话交换机**
- +
+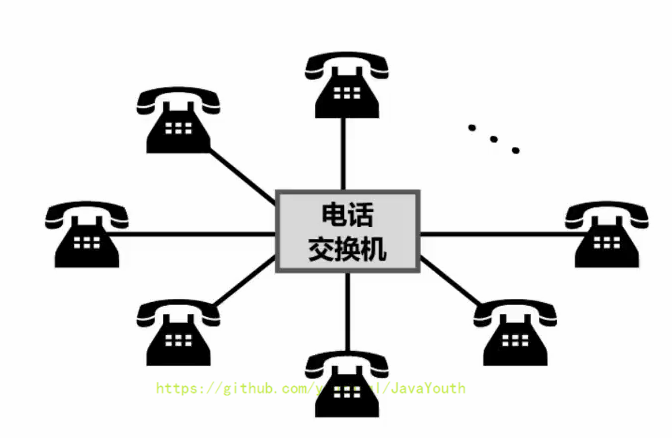 * 电话交换机接通电话线的方式称为电路交换;
@@ -161,7 +161,7 @@ date: 2021-04-03 14:21:58
3、释放连接(归还通信资源)
-
* 电话交换机接通电话线的方式称为电路交换;
@@ -161,7 +161,7 @@ date: 2021-04-03 14:21:58
3、释放连接(归还通信资源)
- +
+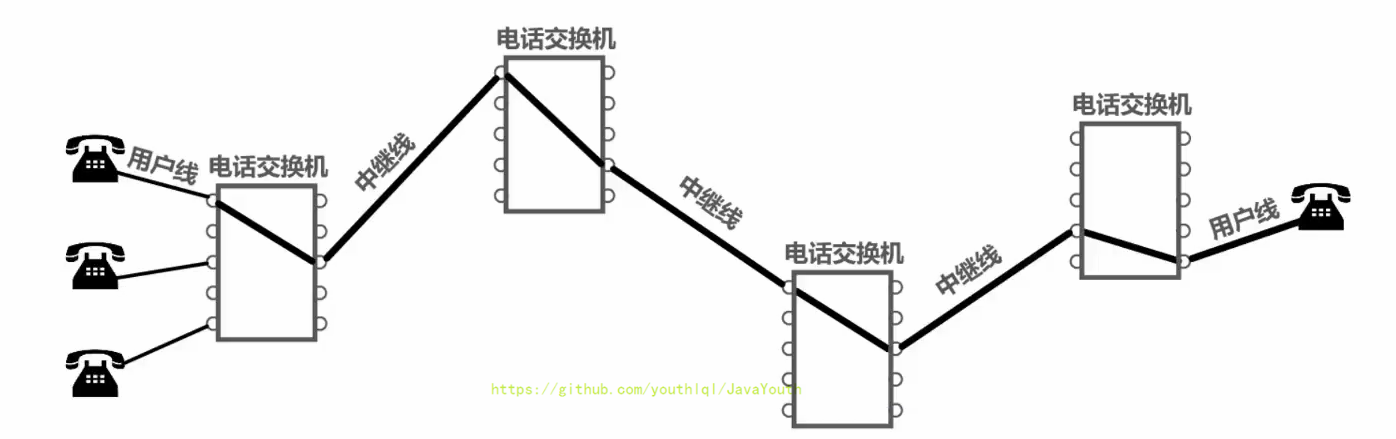 1. 当使用电路交换来传送计算机数据时,其线路的传输效率往往很低。这是因为计算机数据是突发式地出现在传输线路上的,而不是像打电话一样一直占用着通信资源。
2. 试想一下这种情况,当用户正在输入和编辑一份待传输的文件时,用户所占用的通信资源暂时未被利用,该通信资源也不能被其它用户利用,宝贵的通信线路资源白白被浪费了
@@ -169,7 +169,7 @@ date: 2021-04-03 14:21:58
### 分组交换
-
1. 当使用电路交换来传送计算机数据时,其线路的传输效率往往很低。这是因为计算机数据是突发式地出现在传输线路上的,而不是像打电话一样一直占用着通信资源。
2. 试想一下这种情况,当用户正在输入和编辑一份待传输的文件时,用户所占用的通信资源暂时未被利用,该通信资源也不能被其它用户利用,宝贵的通信线路资源白白被浪费了
@@ -169,7 +169,7 @@ date: 2021-04-03 14:21:58
### 分组交换
- +
+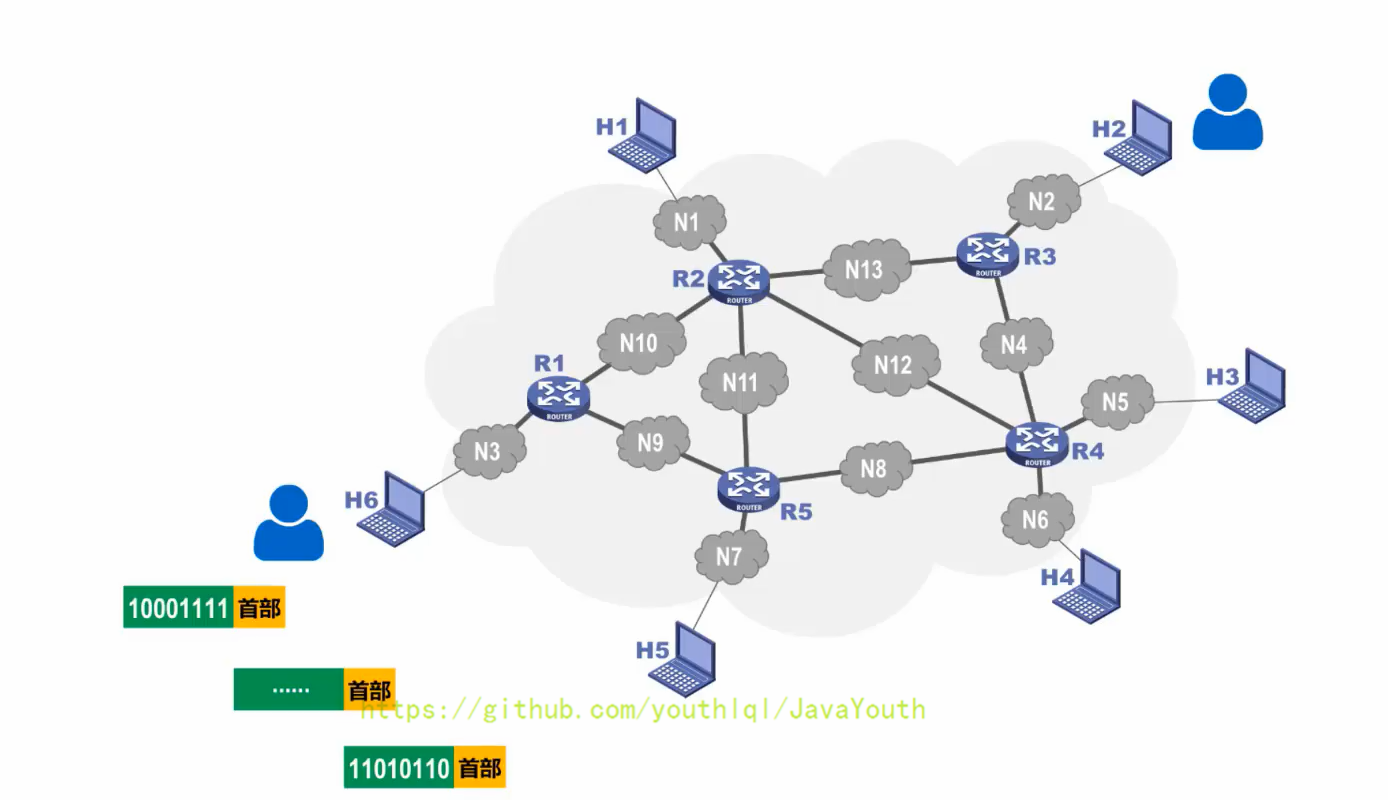 1. 通常我们把表示该消息的整块数据成为一个**报文**。
2. 在发送报文之前,先把较长的报文划分成一个个更小的等长数据段,在每一个数据段前面。加上一些由必要的控制信息组成的首部后,就构成一个分组,也可简称为“包”,相应地,首部也可称为“包头”。首部起到了很大的作用,首先首部中肯定包含了分组的目的地址,否则分组传输路径中的各分组交换机(也就是个路由器)就不知道如何转发分组了
@@ -212,7 +212,7 @@ date: 2021-04-03 14:21:58
假设A,B,C,D是分组传输路径所要经过的4个结点交换机,纵坐标为时间
-
1. 通常我们把表示该消息的整块数据成为一个**报文**。
2. 在发送报文之前,先把较长的报文划分成一个个更小的等长数据段,在每一个数据段前面。加上一些由必要的控制信息组成的首部后,就构成一个分组,也可简称为“包”,相应地,首部也可称为“包头”。首部起到了很大的作用,首先首部中肯定包含了分组的目的地址,否则分组传输路径中的各分组交换机(也就是个路由器)就不知道如何转发分组了
@@ -212,7 +212,7 @@ date: 2021-04-03 14:21:58
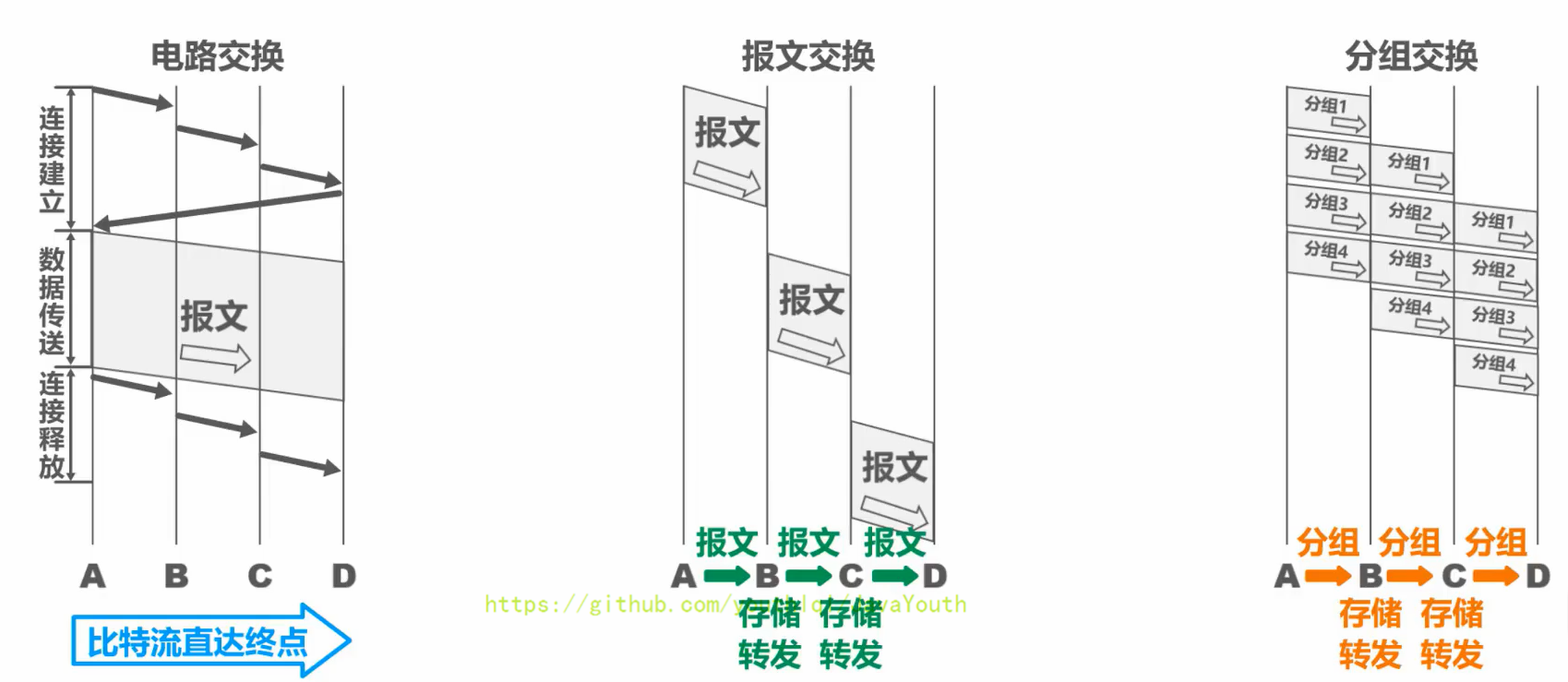
假设A,B,C,D是分组传输路径所要经过的4个结点交换机,纵坐标为时间
- +
+ @@ -232,7 +232,7 @@ date: 2021-04-03 14:21:58
* 可以随时发送分组,而不需要事先建立连接。构成原始报文的**一个个分组**,**依次**在各结点交换机上存储转发。各结点交换机在发送分组的同时,还缓存接收到的分组。
* **构成原始报文的一个个分组**,在各结点交换机上进行存储转发,相比报文交换,减少了转发时延,还可以避免过长的报文长时间占用链路,同时也有利于进行差错控制。
-
@@ -232,7 +232,7 @@ date: 2021-04-03 14:21:58
* 可以随时发送分组,而不需要事先建立连接。构成原始报文的**一个个分组**,**依次**在各结点交换机上存储转发。各结点交换机在发送分组的同时,还缓存接收到的分组。
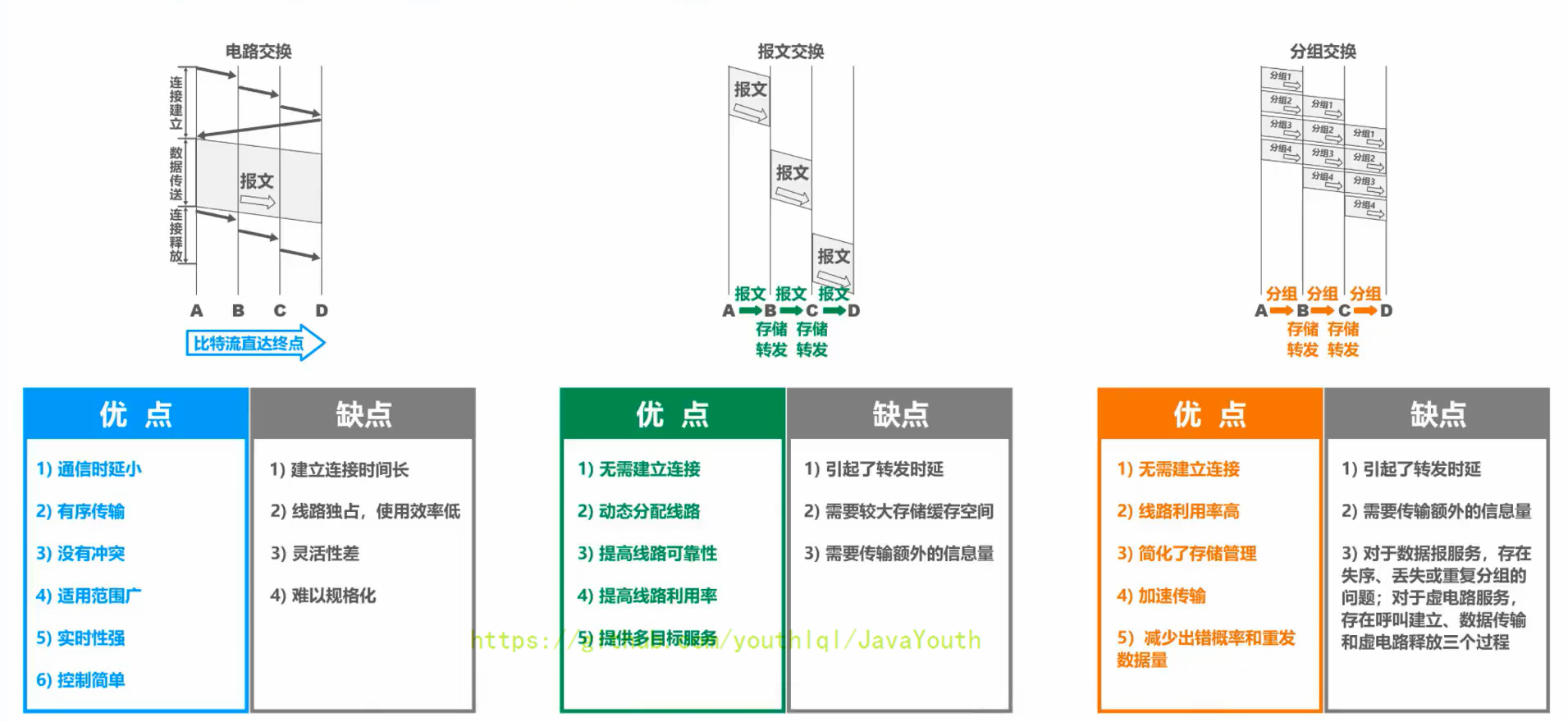
* **构成原始报文的一个个分组**,在各结点交换机上进行存储转发,相比报文交换,减少了转发时延,还可以避免过长的报文长时间占用链路,同时也有利于进行差错控制。
- +
+ @@ -249,7 +249,7 @@ date: 2021-04-03 14:21:58
* 计算机网络所连接的硬件,并不限于一般的计算机,而是包括了智能手机等智能硬件。
* 计算机网络并非专门用来传送数据,而是能够支持很多种的应用(包括今后可能出现的各种应用)。
-
@@ -249,7 +249,7 @@ date: 2021-04-03 14:21:58
* 计算机网络所连接的硬件,并不限于一般的计算机,而是包括了智能手机等智能硬件。
* 计算机网络并非专门用来传送数据,而是能够支持很多种的应用(包括今后可能出现的各种应用)。
- +
+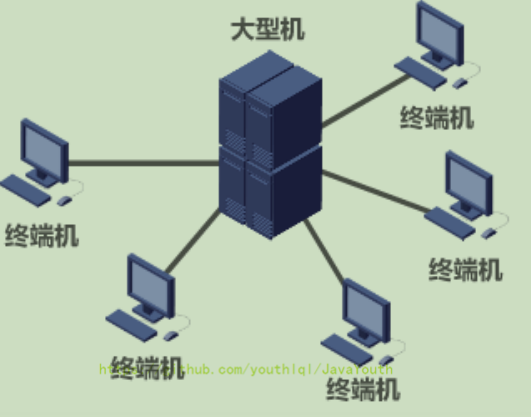 上图所示的各终端机只是具有显示和输入设备的终端,而并不是自治的计算机,所以上图并不是计算机网络,只是一个运行分时系统的大型机系统。
@@ -293,7 +293,7 @@ date: 2021-04-03 14:21:58
* 总线型网络
-
上图所示的各终端机只是具有显示和输入设备的终端,而并不是自治的计算机,所以上图并不是计算机网络,只是一个运行分时系统的大型机系统。
@@ -293,7 +293,7 @@ date: 2021-04-03 14:21:58
* 总线型网络
- +
+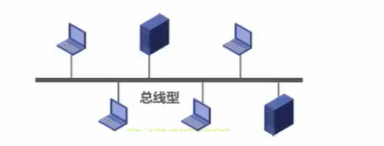 优点:建网容易,增减节点方便,节省线路
@@ -301,7 +301,7 @@ date: 2021-04-03 14:21:58
* 星型网络
-
优点:建网容易,增减节点方便,节省线路
@@ -301,7 +301,7 @@ date: 2021-04-03 14:21:58
* 星型网络
- +
+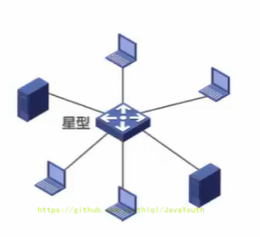 星型网络图中的中央设备现在一般是交换机或路由器,
@@ -313,13 +313,13 @@ date: 2021-04-03 14:21:58
* 环形网络
-
星型网络图中的中央设备现在一般是交换机或路由器,
@@ -313,13 +313,13 @@ date: 2021-04-03 14:21:58
* 环形网络
- +
+ 环中信号是单向传输的
* 网状型网络
-
环中信号是单向传输的
* 网状型网络
- +
+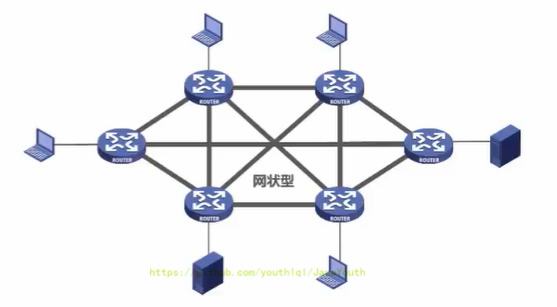 一般情况下,每个节点至少由两条路径与其他节点相连,多用在广域网中
@@ -333,15 +333,15 @@ date: 2021-04-03 14:21:58
### 速率
-
一般情况下,每个节点至少由两条路径与其他节点相连,多用在广域网中
@@ -333,15 +333,15 @@ date: 2021-04-03 14:21:58
### 速率
- +
+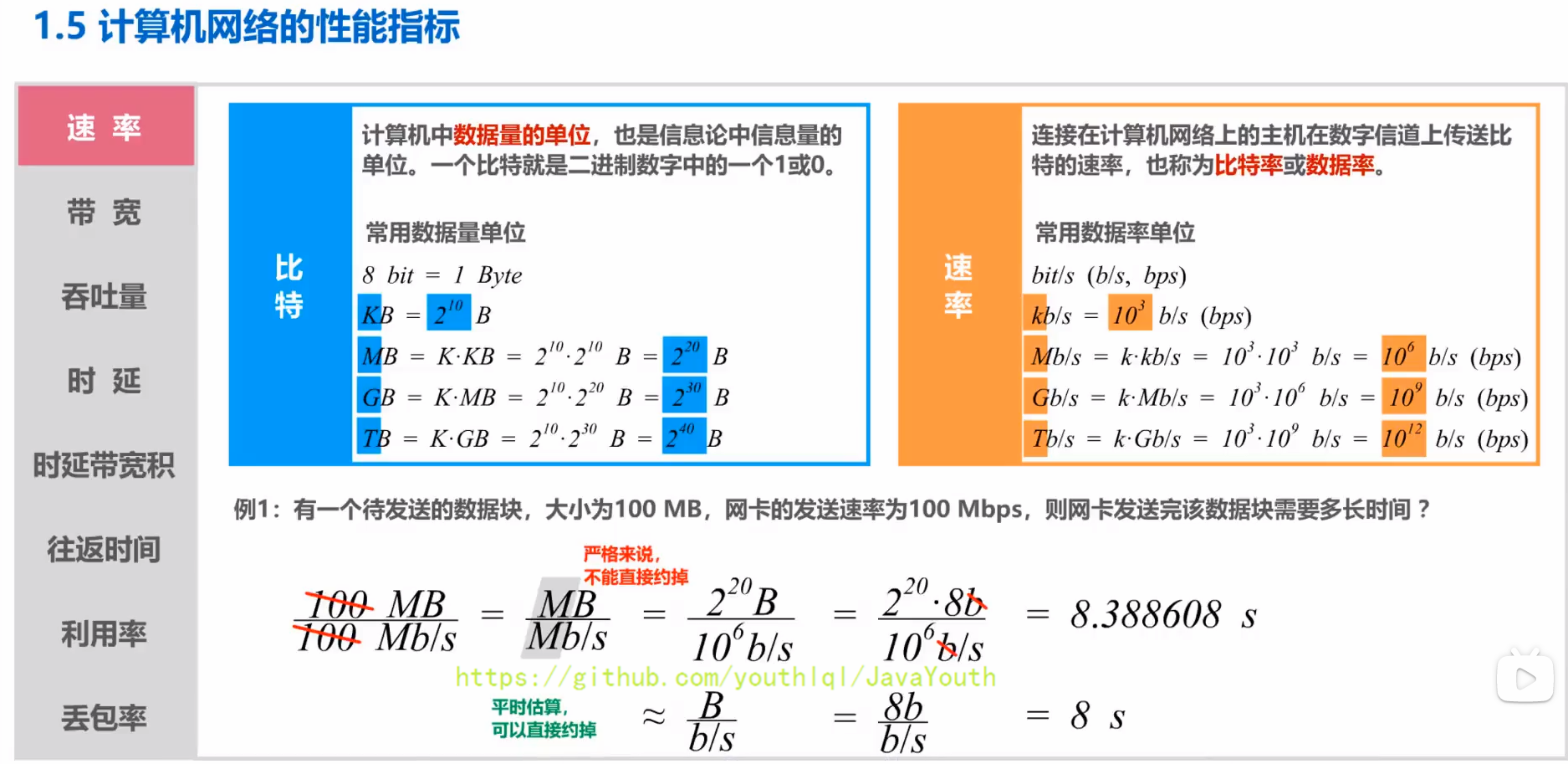 ### 带宽
-
### 带宽
- +
+ ### 吞吐量
-
### 吞吐量
- +
+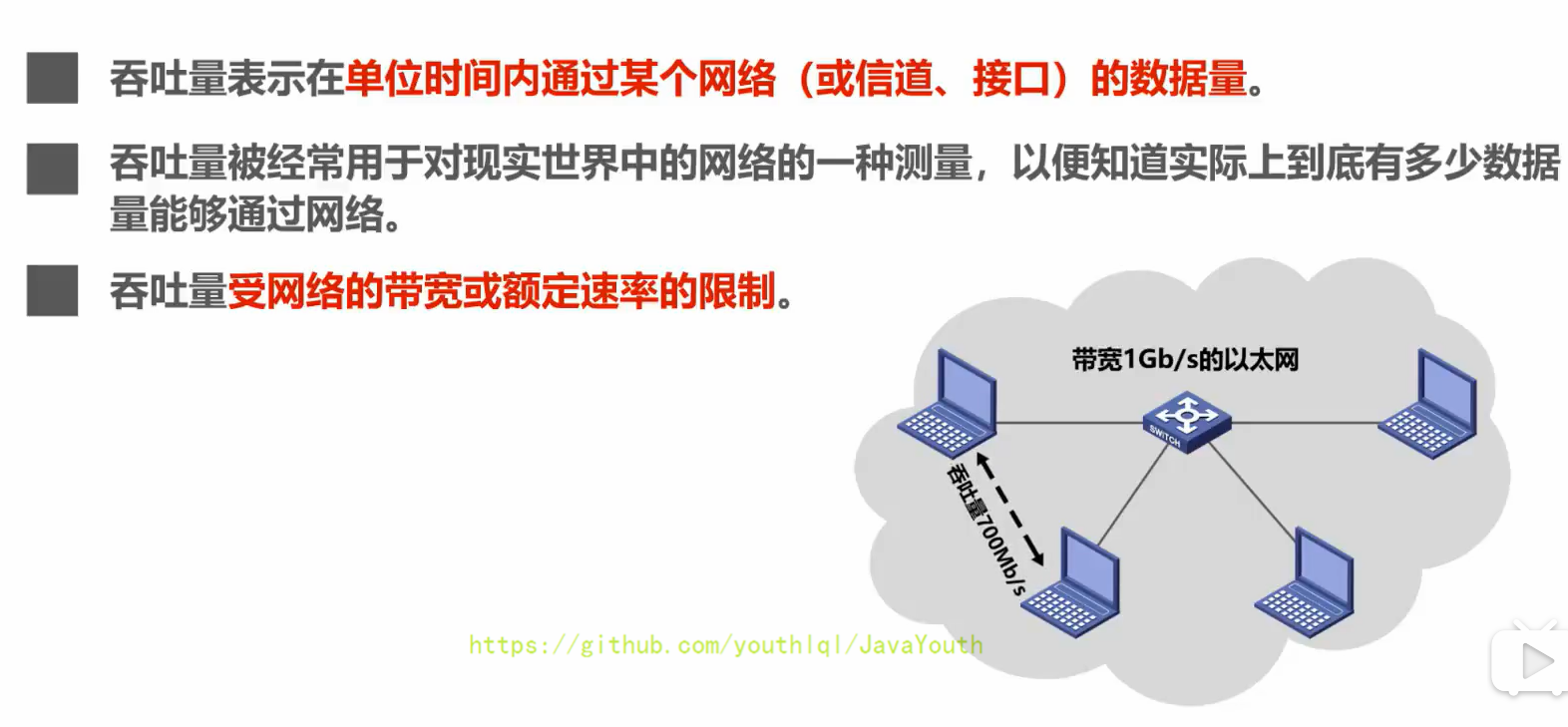 带宽1 Gb/s的以太网,代表其额定速率是1 Gb/s,这个数值也是该以太网的吞吐量的上限值。实际上,对于带宽1 Gb/s的以太网,可能实际吞吐量只有 700 Mb/s,甚至更低。
@@ -361,33 +361,33 @@ date: 2021-04-03 14:21:58
网卡的发送速率,信道带宽,交换机的接口速率,它们共同决定着主机的发送速率。
-
带宽1 Gb/s的以太网,代表其额定速率是1 Gb/s,这个数值也是该以太网的吞吐量的上限值。实际上,对于带宽1 Gb/s的以太网,可能实际吞吐量只有 700 Mb/s,甚至更低。
@@ -361,33 +361,33 @@ date: 2021-04-03 14:21:58
网卡的发送速率,信道带宽,交换机的接口速率,它们共同决定着主机的发送速率。
- +
+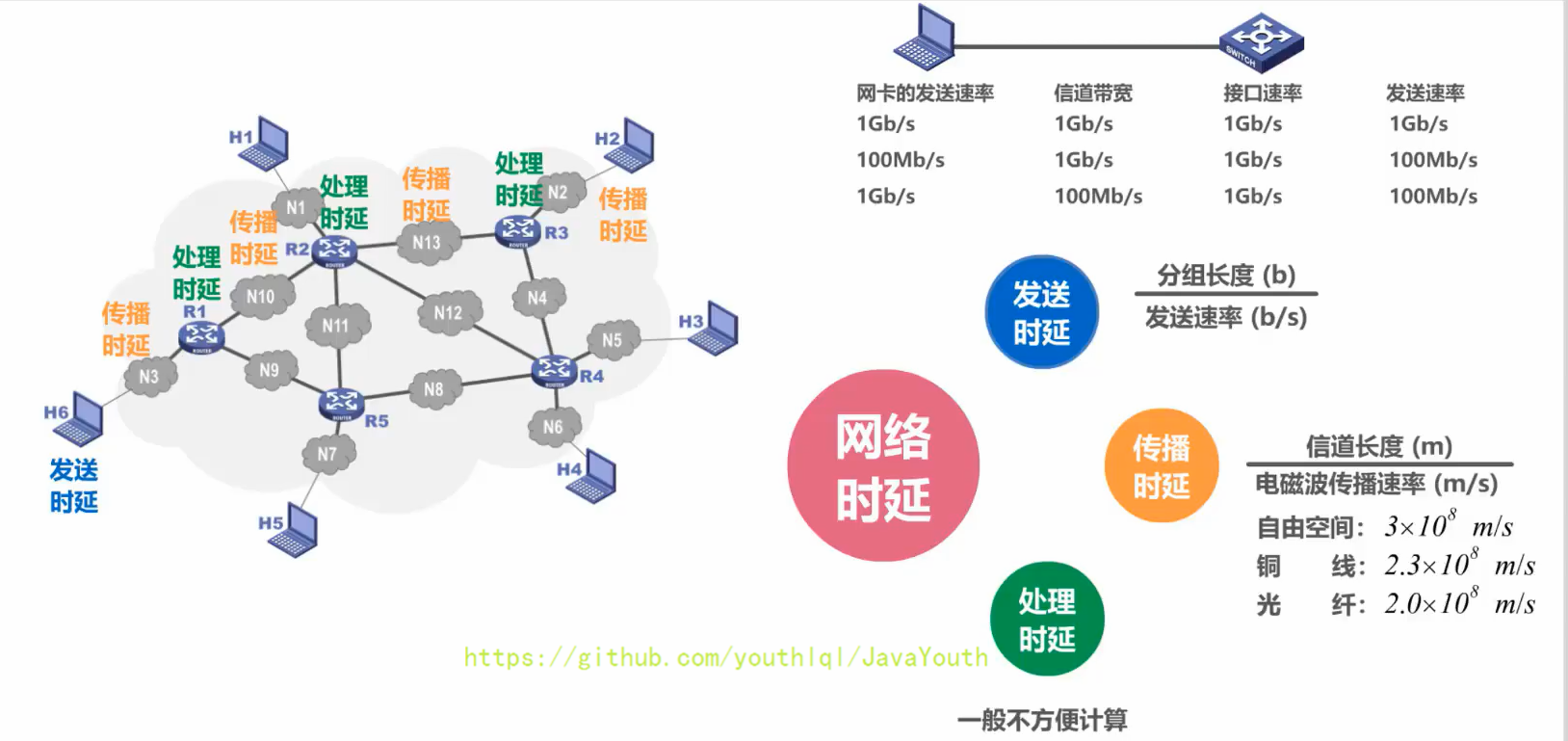 当处理时延忽略不计时,发送时延和传播时延谁占主导,要具体情况具体分析
-
当处理时延忽略不计时,发送时延和传播时延谁占主导,要具体情况具体分析
- +
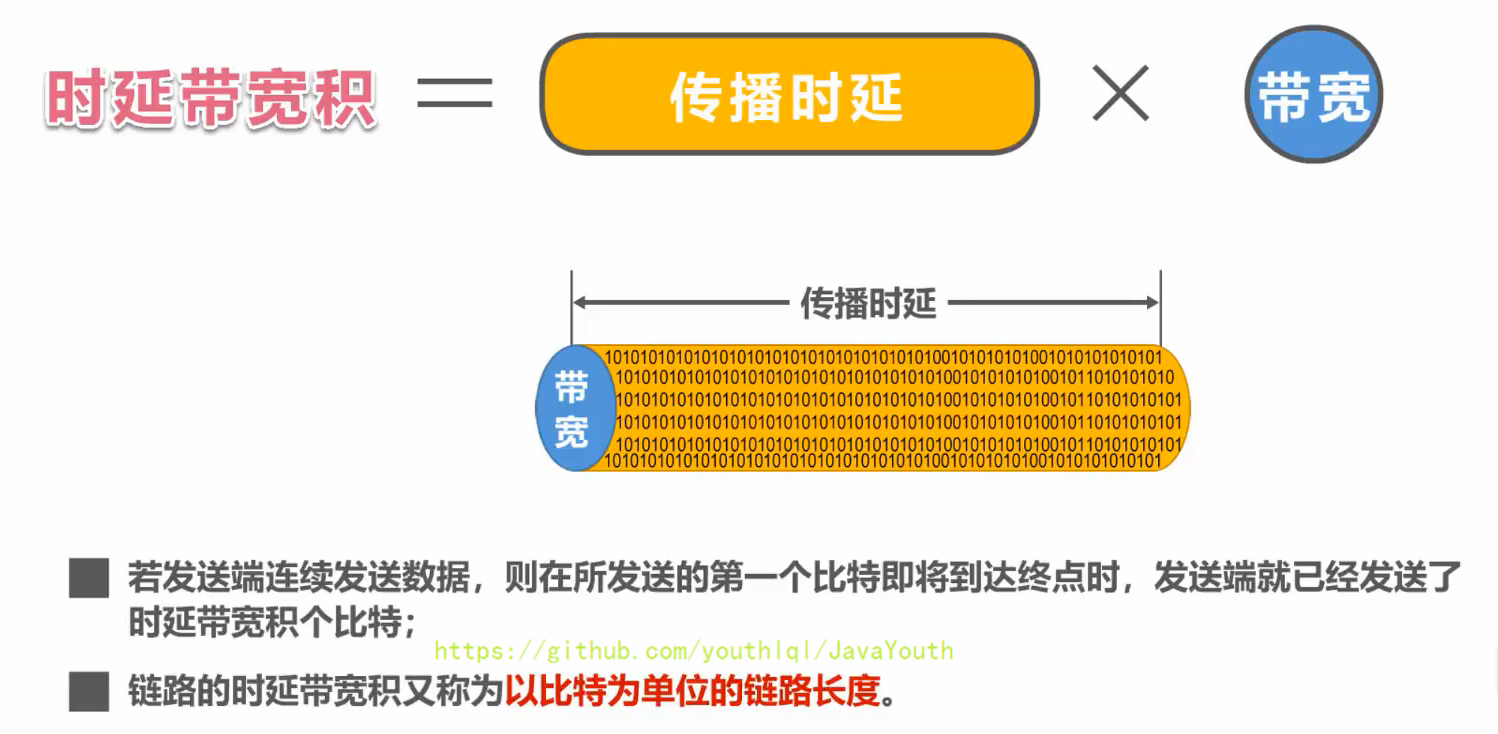
+ ### 时延带宽积
-
### 时延带宽积
- +
+ ### 往返时间
-
### 往返时间
- +
+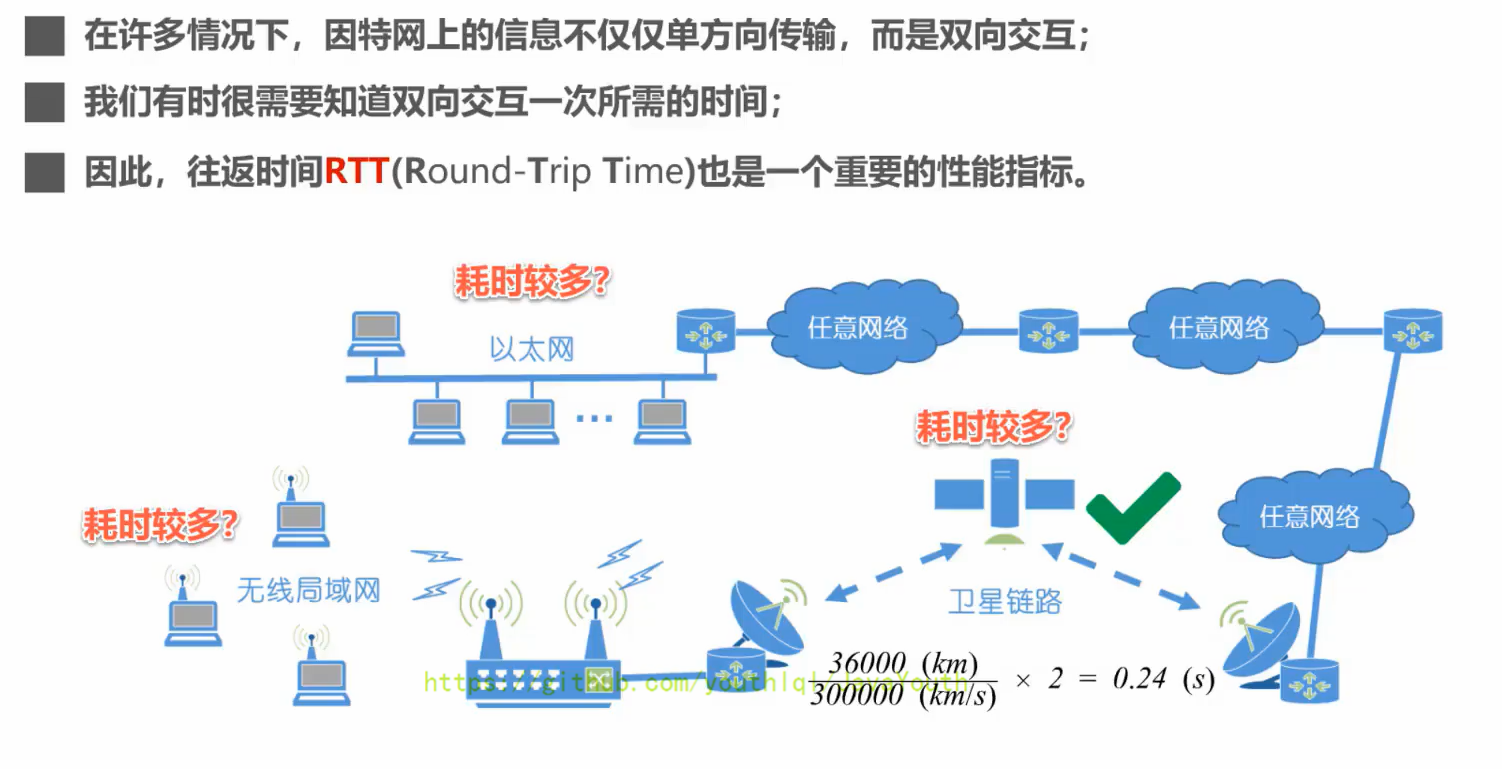 ### 利用率
-
### 利用率
-  +
+ 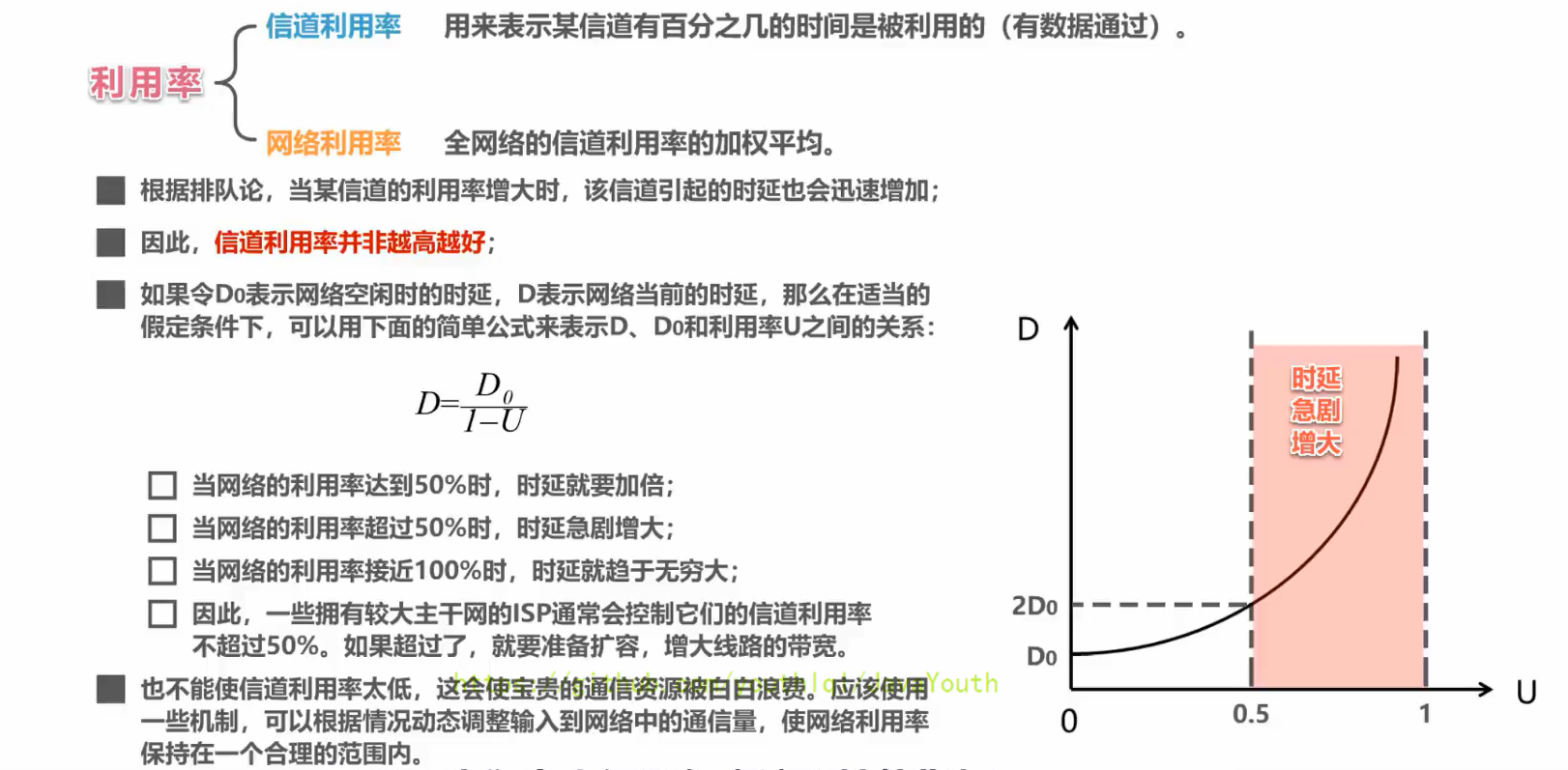 ### 丢包率
-
### 丢包率
- +
+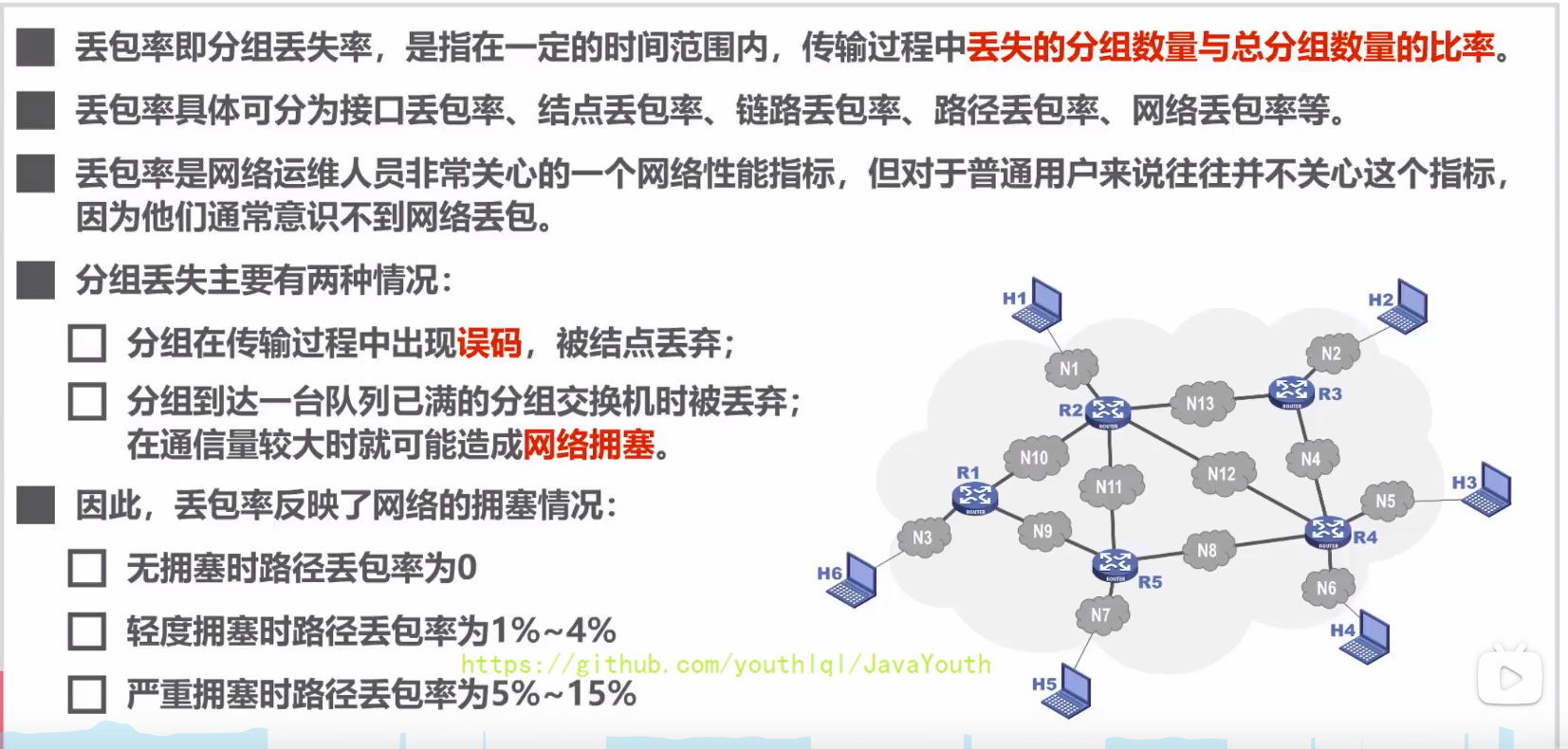 @@ -397,7 +397,7 @@ date: 2021-04-03 14:21:58
### 常见的计算机网络体系结构
-
@@ -397,7 +397,7 @@ date: 2021-04-03 14:21:58
### 常见的计算机网络体系结构
- +
+ 1、如今用的最多的是TCP/IP体系结构,现今规模最大的、覆盖全球的、基于TCP/IP的互联网并未使用OSI标准。TCP/IP体系结构相当于将OSI体系结构的物理层和数据链路层合并为了网络接口层,并去掉了会话层和表示层。
@@ -405,7 +405,7 @@ date: 2021-04-03 14:21:58
-
1、如今用的最多的是TCP/IP体系结构,现今规模最大的、覆盖全球的、基于TCP/IP的互联网并未使用OSI标准。TCP/IP体系结构相当于将OSI体系结构的物理层和数据链路层合并为了网络接口层,并去掉了会话层和表示层。
@@ -405,7 +405,7 @@ date: 2021-04-03 14:21:58
- +
+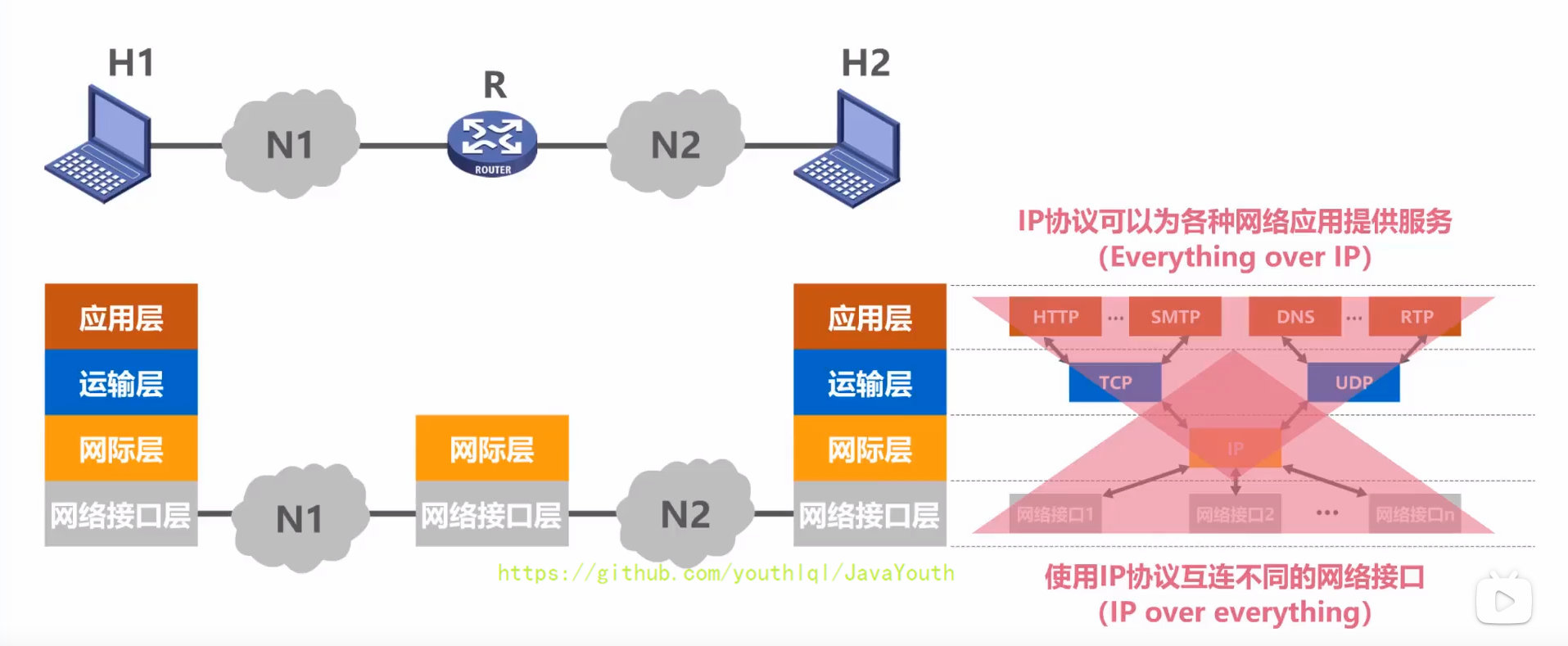 1、在用户主机的操作系统中,通常都带有符合TCP/IP体系结构标准的TCP/IP协议族。而用于网络互连的路由器中,也带有符合TCP/IP体系结构标准的TCP/IP协议族。只不过路由器一般只包含网络接口层和网际层。
@@ -435,7 +435,7 @@ date: 2021-04-03 14:21:58
-
1、在用户主机的操作系统中,通常都带有符合TCP/IP体系结构标准的TCP/IP协议族。而用于网络互连的路由器中,也带有符合TCP/IP体系结构标准的TCP/IP协议族。只不过路由器一般只包含网络接口层和网际层。
@@ -435,7 +435,7 @@ date: 2021-04-03 14:21:58
- +
+ @@ -443,11 +443,11 @@ date: 2021-04-03 14:21:58
### 分层的必要性
-
@@ -443,11 +443,11 @@ date: 2021-04-03 14:21:58
### 分层的必要性
- +
+ **物理层问题**
-
**物理层问题**
- +
+ @@ -455,7 +455,7 @@ date: 2021-04-03 14:21:58
**数据链路层问题**
-
@@ -455,7 +455,7 @@ date: 2021-04-03 14:21:58
**数据链路层问题**
- +
+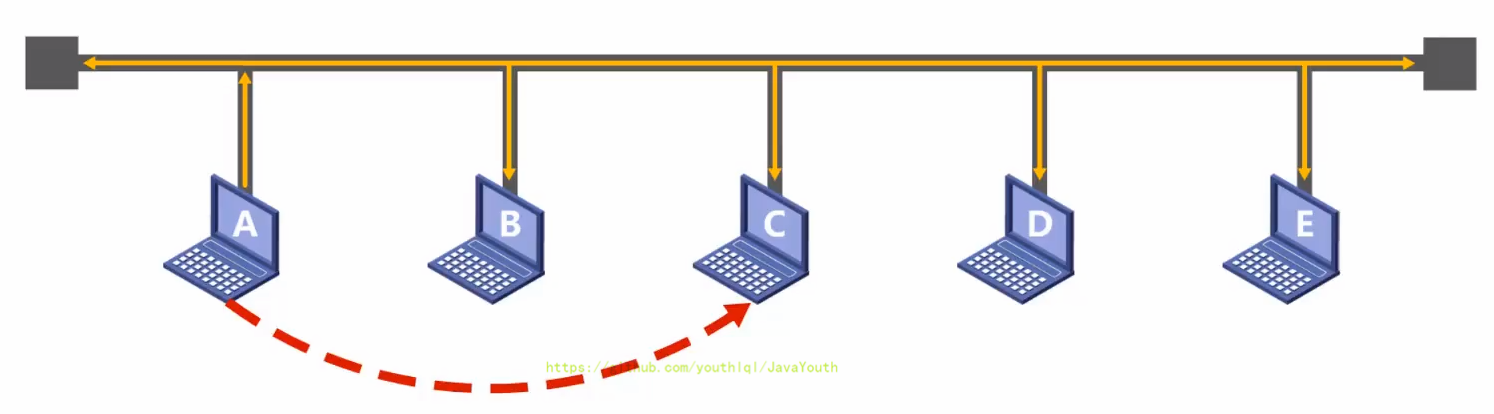 1、如图所示,主机A要给主机C发送数据。
@@ -479,7 +479,7 @@ A:也就是需要解决分组的封装格式问题
Q:另外对于总线型的网络,还会出现下面这种典型的问题
-
1、如图所示,主机A要给主机C发送数据。
@@ -479,7 +479,7 @@ A:也就是需要解决分组的封装格式问题
Q:另外对于总线型的网络,还会出现下面这种典型的问题
- +
+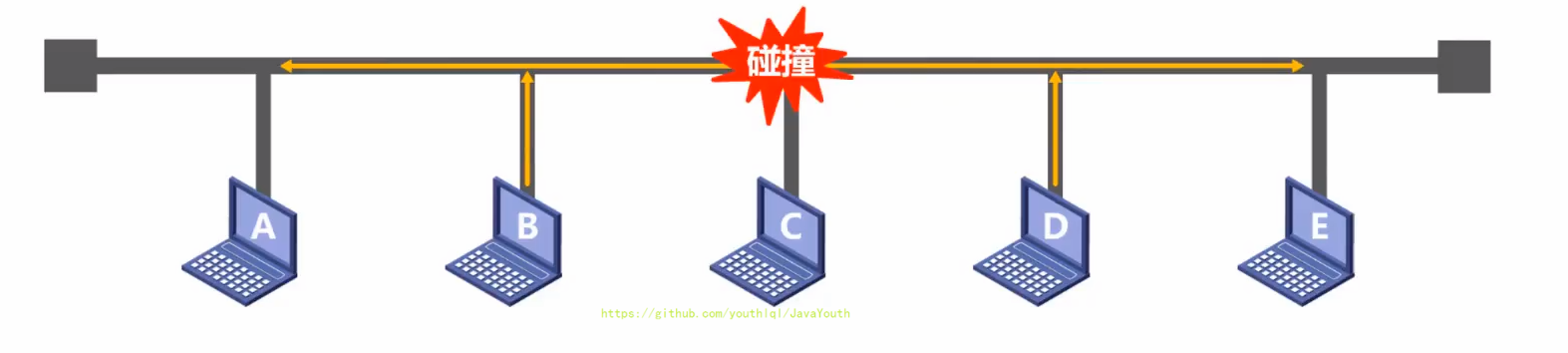 @@ -493,7 +493,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
-
@@ -493,7 +493,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
- +
+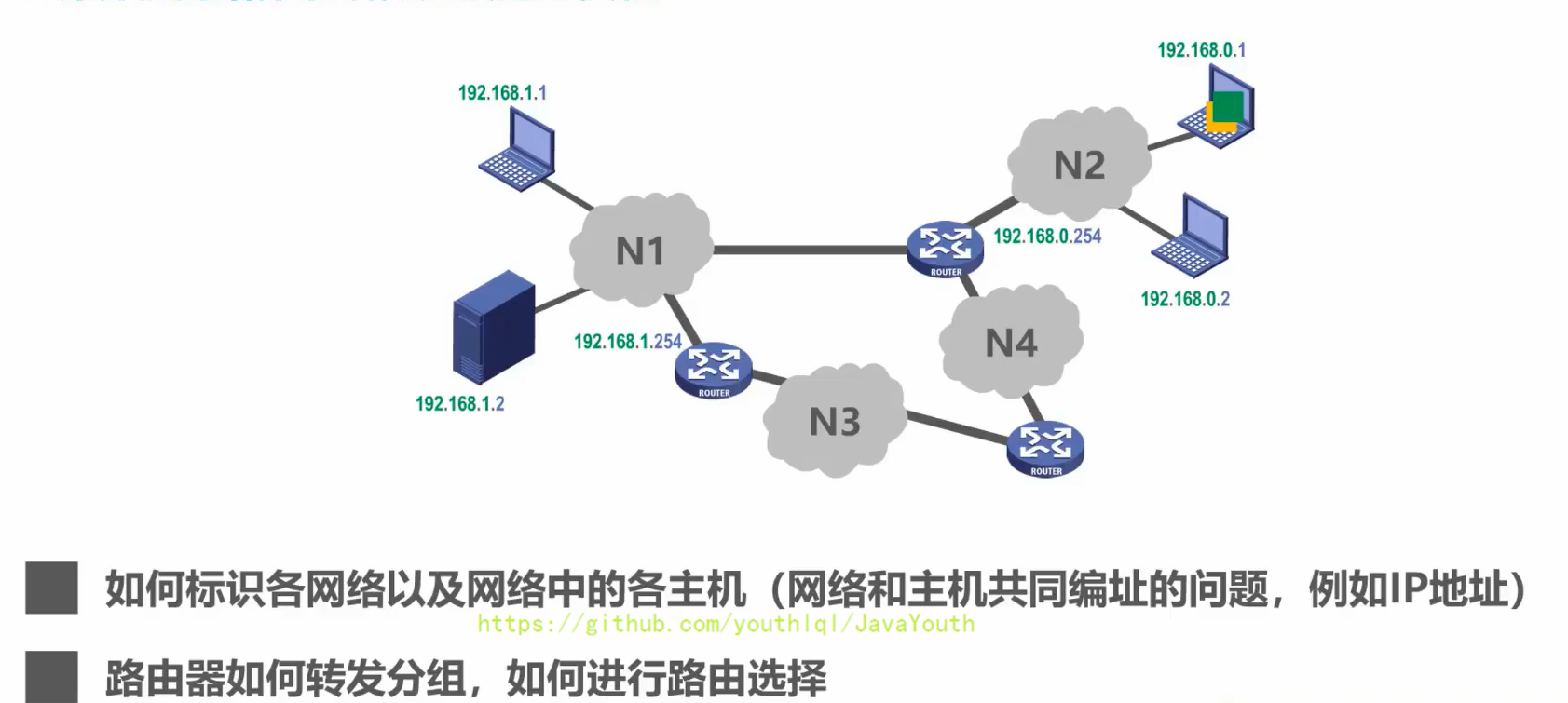 @@ -503,13 +503,13 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
- 引出了我们如何标识与网络通信相关的引用进程,进而解决进程之间基于网络通信的问题。
-
@@ -503,13 +503,13 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
- 引出了我们如何标识与网络通信相关的引用进程,进而解决进程之间基于网络通信的问题。
- +
+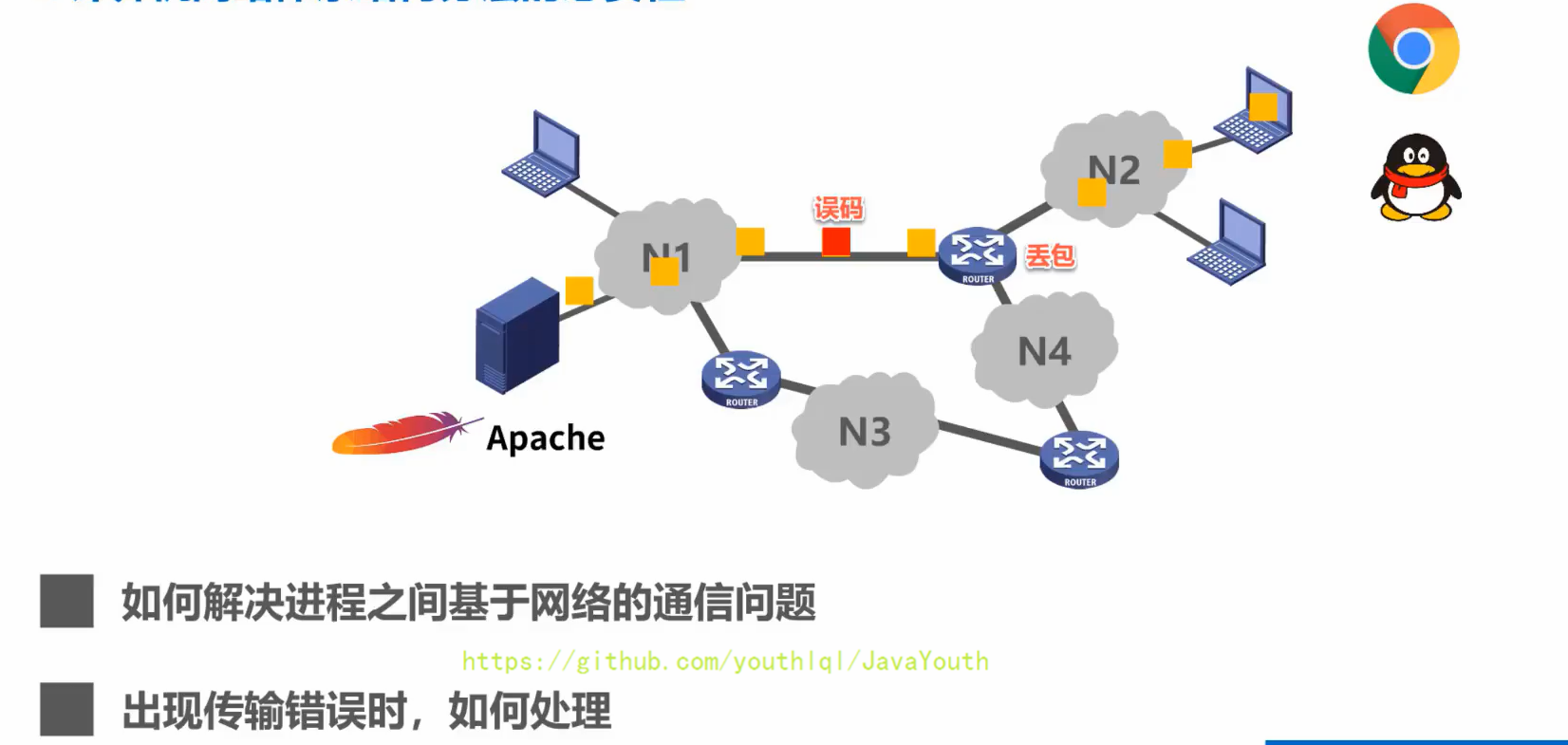 **应用层问题**
-
**应用层问题**
- +
+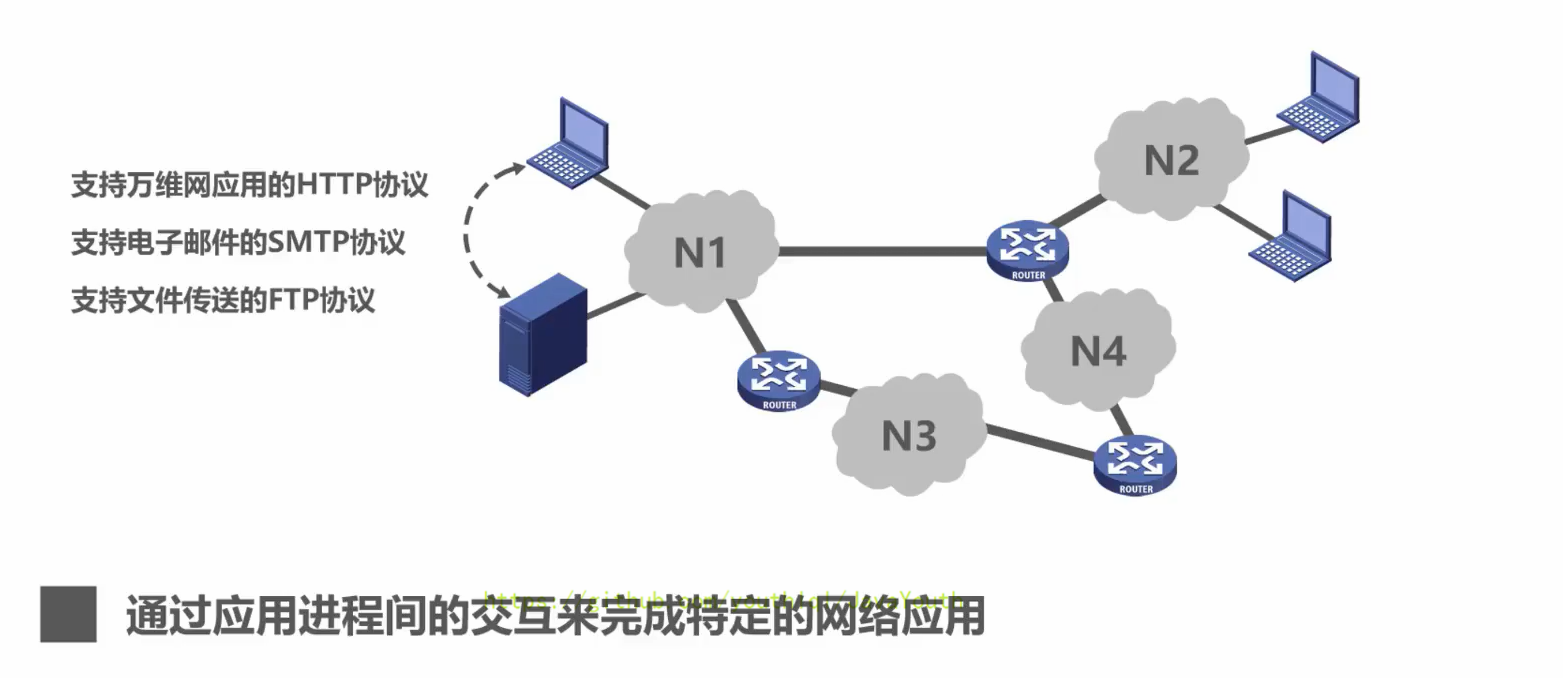 @@ -517,7 +517,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
-
@@ -517,7 +517,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
- +
+ ### 分层思想举例
@@ -525,7 +525,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
假设网络拓扑如下所示
-
### 分层思想举例
@@ -525,7 +525,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
假设网络拓扑如下所示
- +
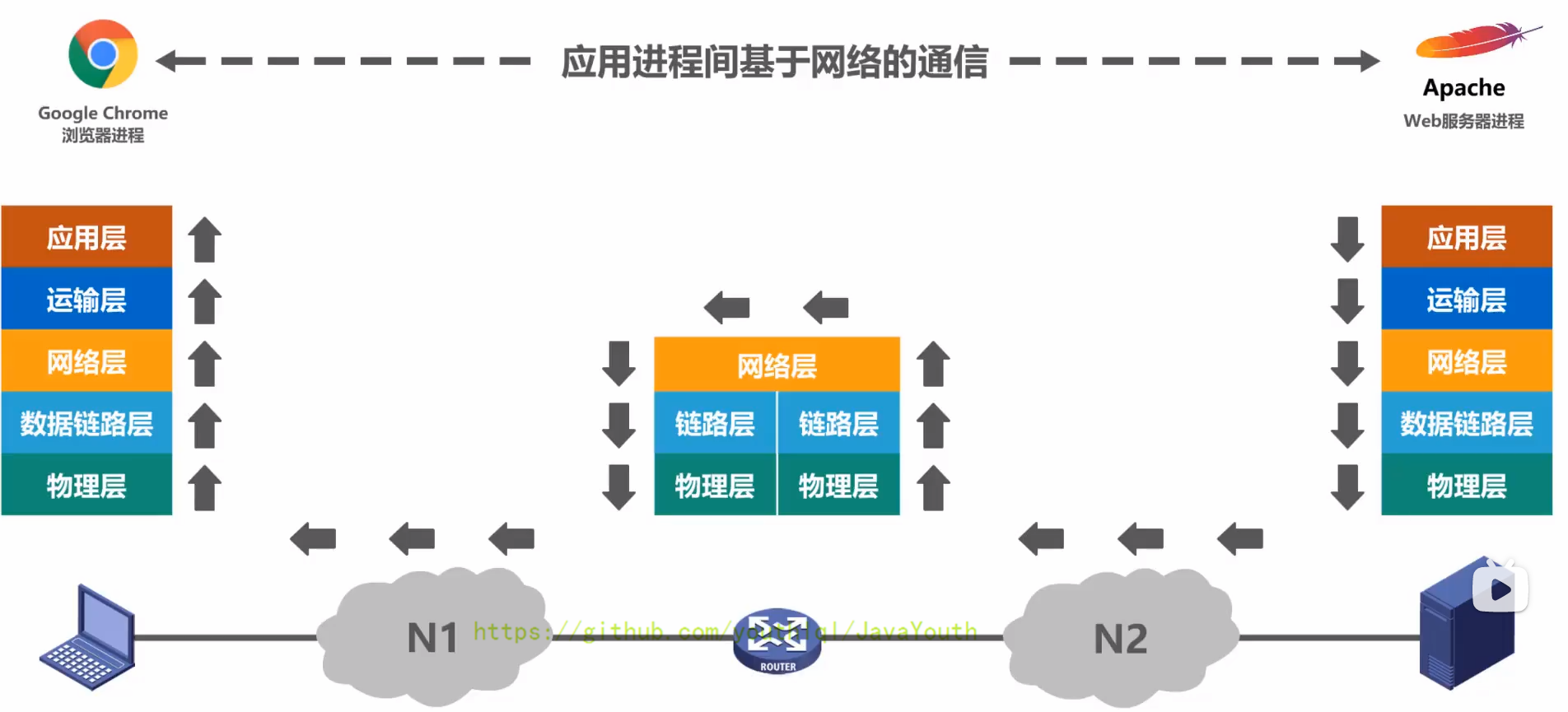
+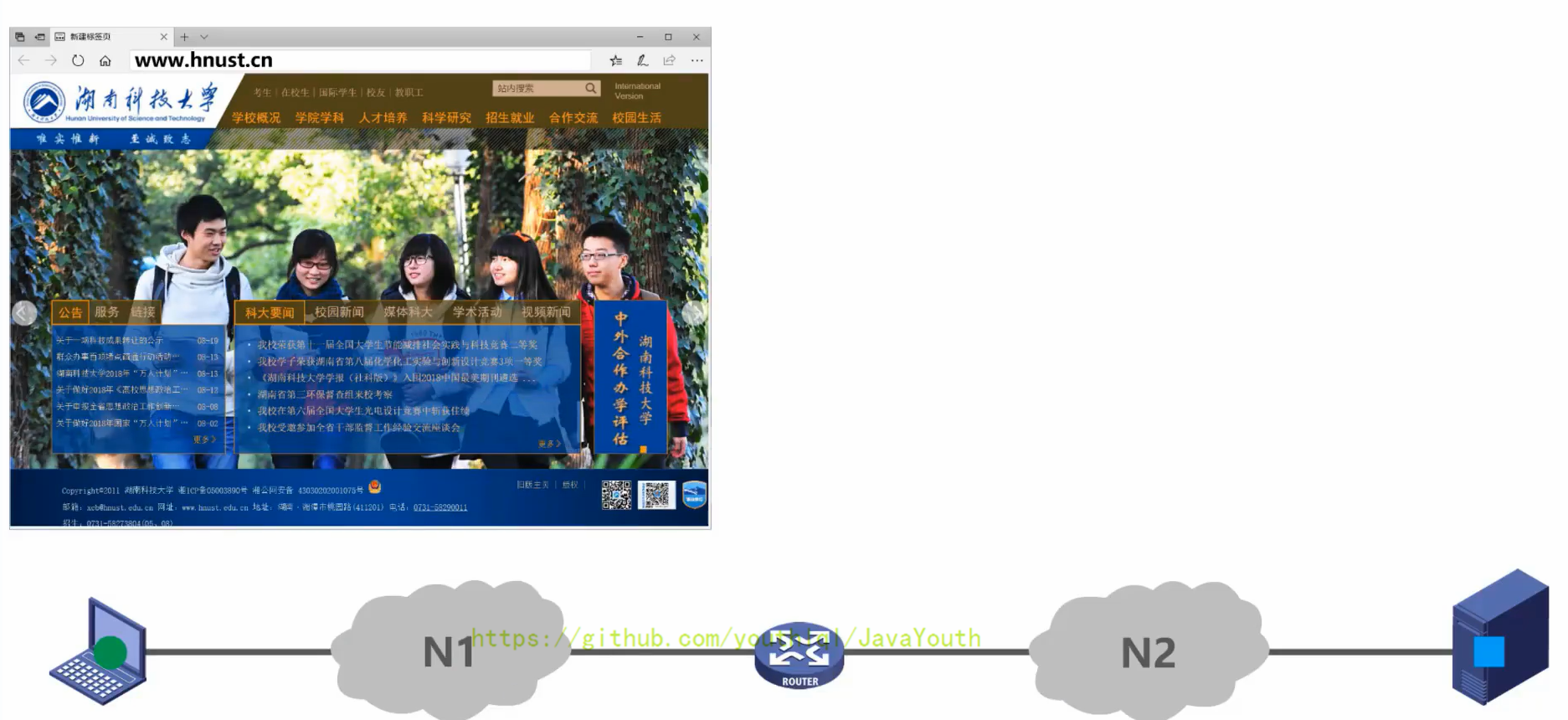 @@ -533,7 +533,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
主机和Web服务器之间基于网络的通信,实际上是主机中的浏览器应用进程与Web服务器中的Web服务器应用进程之间基于网络的通信
-
@@ -533,7 +533,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
主机和Web服务器之间基于网络的通信,实际上是主机中的浏览器应用进程与Web服务器中的Web服务器应用进程之间基于网络的通信
- +
+ @@ -545,7 +545,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
- 应用层将HTTP请求报文交付给运输层处理
-
@@ -545,7 +545,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
- 应用层将HTTP请求报文交付给运输层处理
- +
+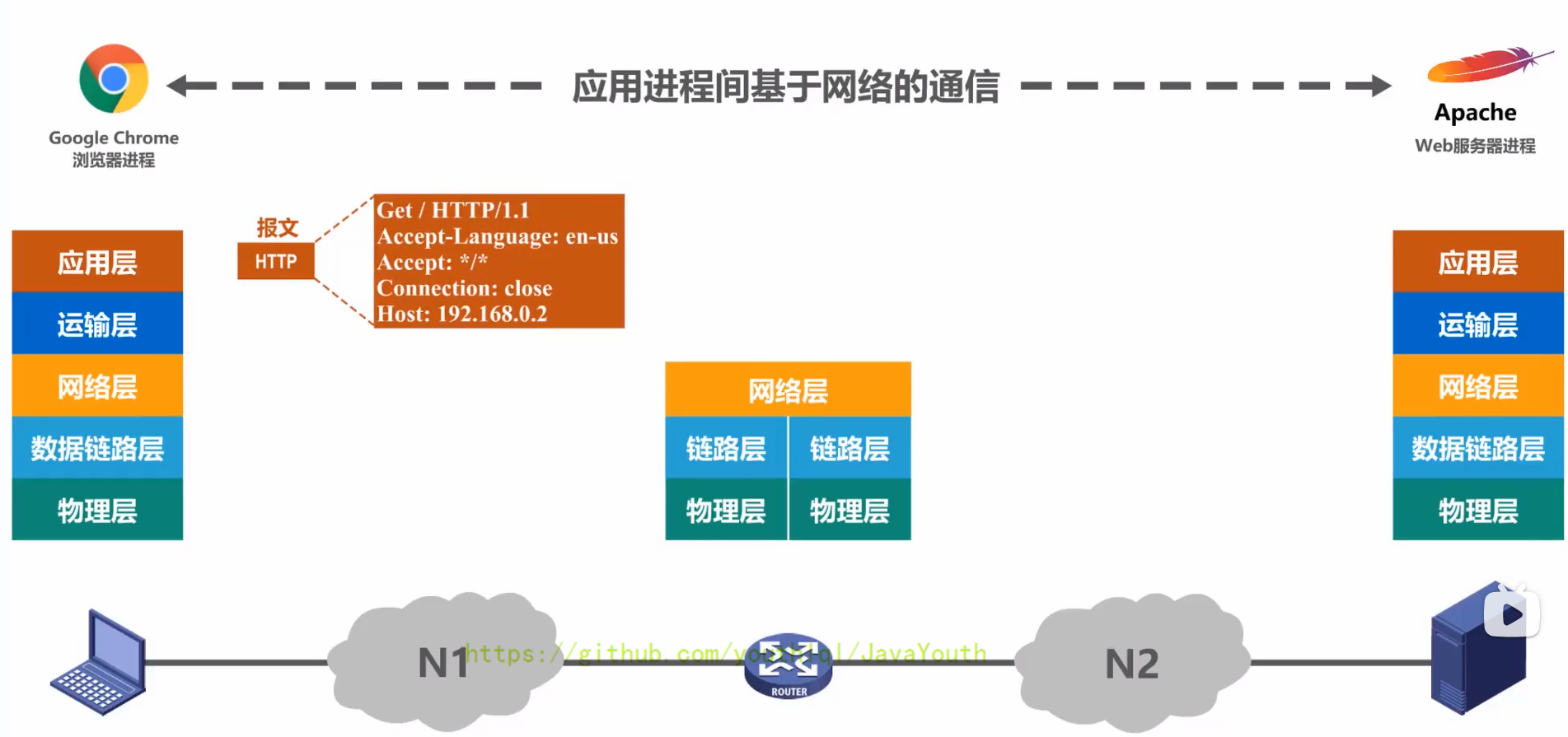 @@ -559,7 +559,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
- 运输层将TCP报文段交付给网络层处理
-
@@ -559,7 +559,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
- 运输层将TCP报文段交付给网络层处理
- +
+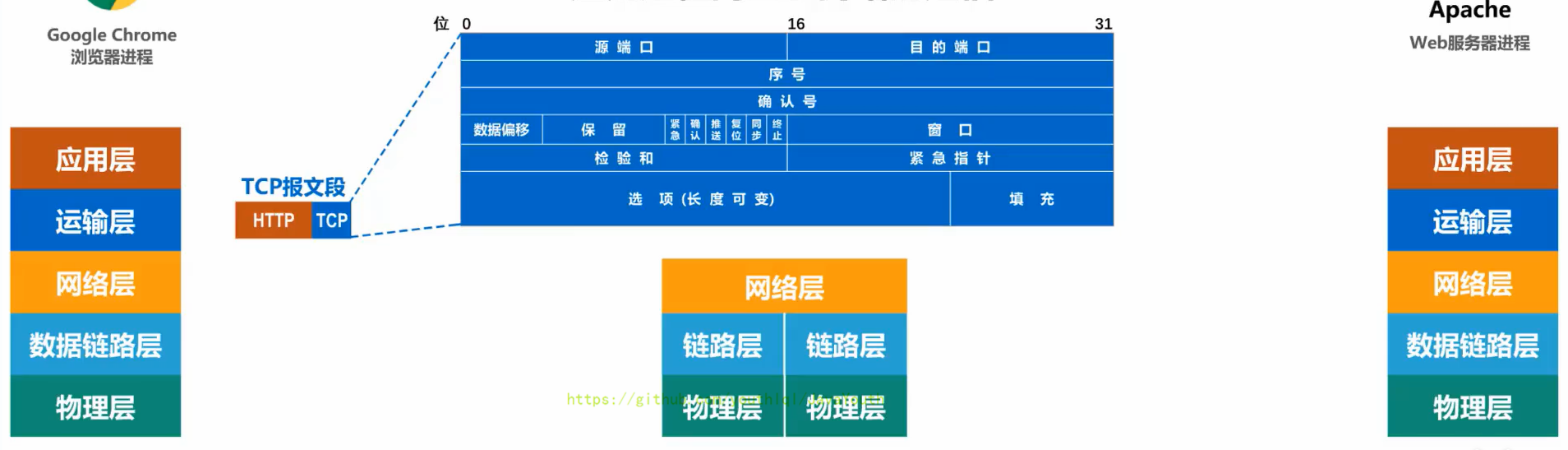 @@ -571,7 +571,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
- 网络层将IP数据报交付给数据链路层处理
-
@@ -571,7 +571,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
- 网络层将IP数据报交付给数据链路层处理
- +
+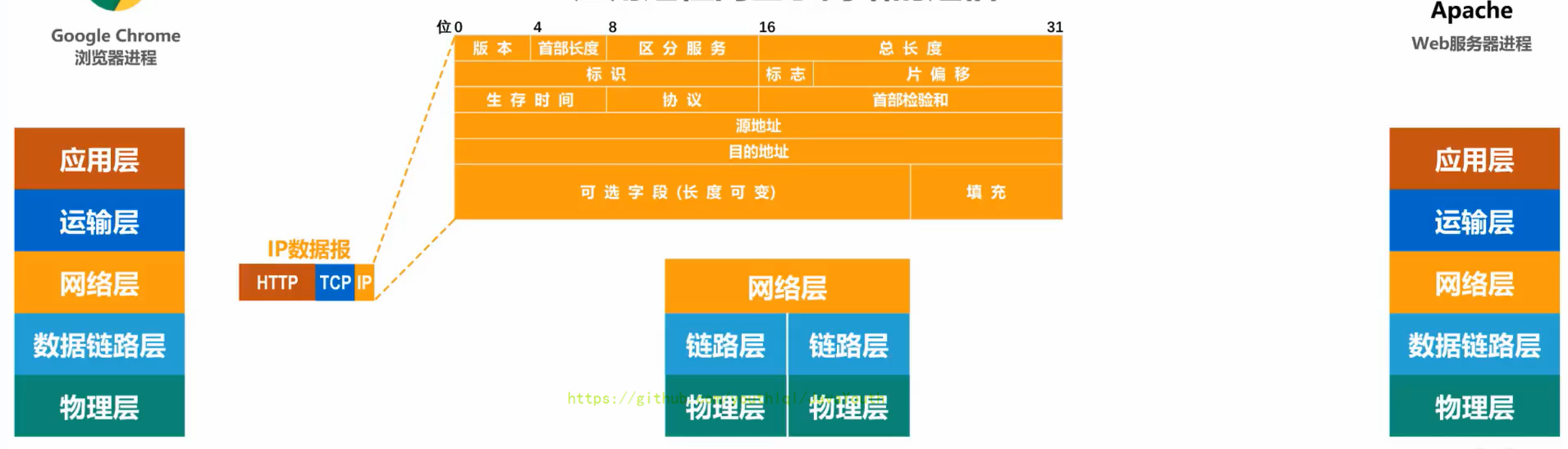 @@ -589,7 +589,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
-
@@ -589,7 +589,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
- +
+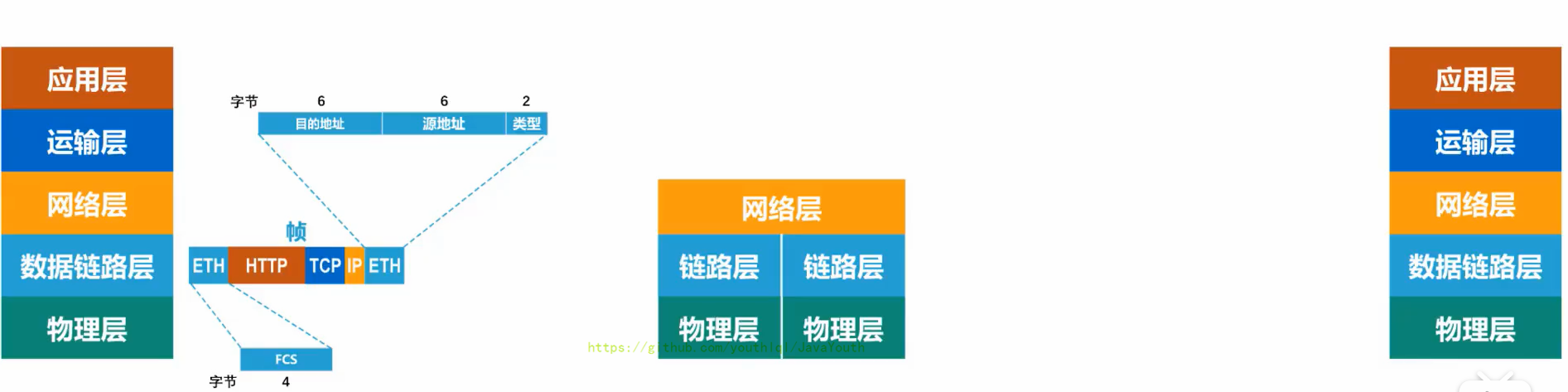 @@ -599,7 +599,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
* 前导码的作用是为了让目的主机做好接收帧的准备
* 物理层将装有前导码的比特流变换成相应的信号发送给传输媒体
-
@@ -599,7 +599,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
* 前导码的作用是为了让目的主机做好接收帧的准备
* 物理层将装有前导码的比特流变换成相应的信号发送给传输媒体
- +
+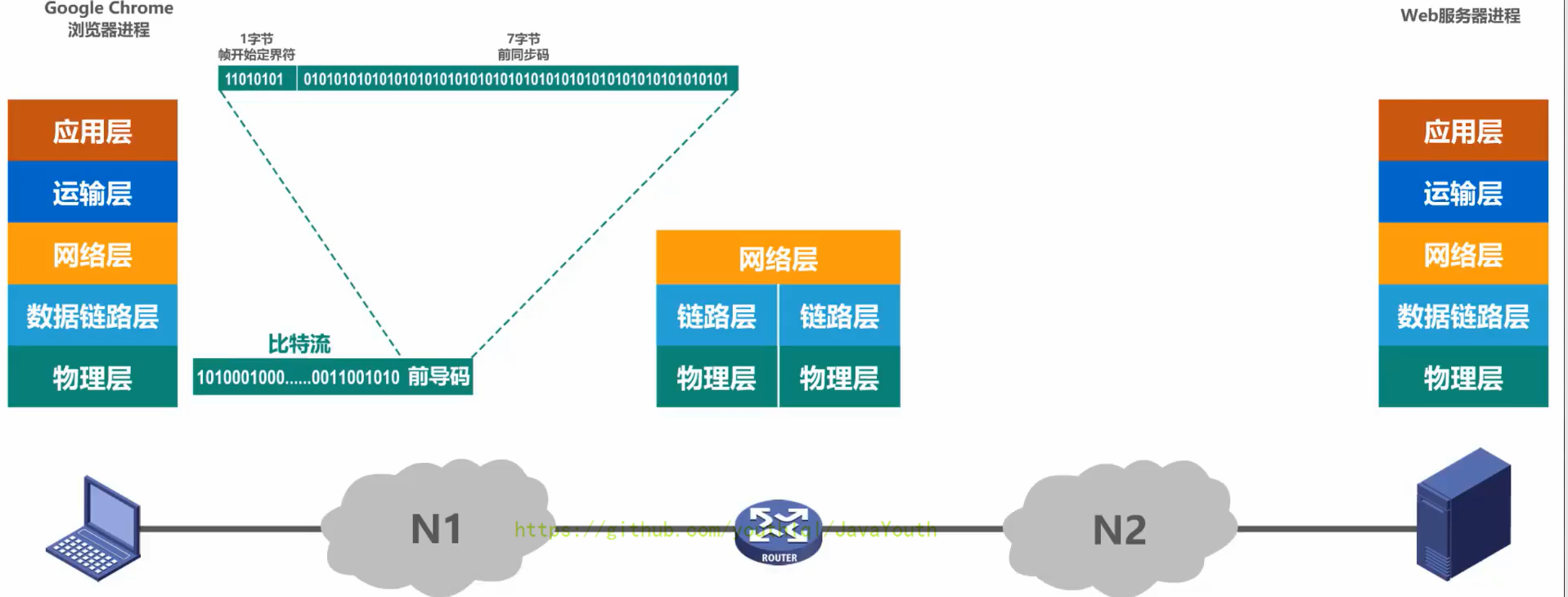 @@ -607,7 +607,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
- 信号通过传输媒体到达路由器
-
@@ -607,7 +607,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
- 信号通过传输媒体到达路由器
- +
+ @@ -646,7 +646,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
**发回响应报文的步骤和之前过程类似**
-
@@ -646,7 +646,7 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
**发回响应报文的步骤和之前过程类似**
- +
+ ### 专用术语
@@ -654,13 +654,13 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
**实体**
-
### 专用术语
@@ -654,13 +654,13 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
**实体**
- +
+ **协议**
-
**协议**
- +
+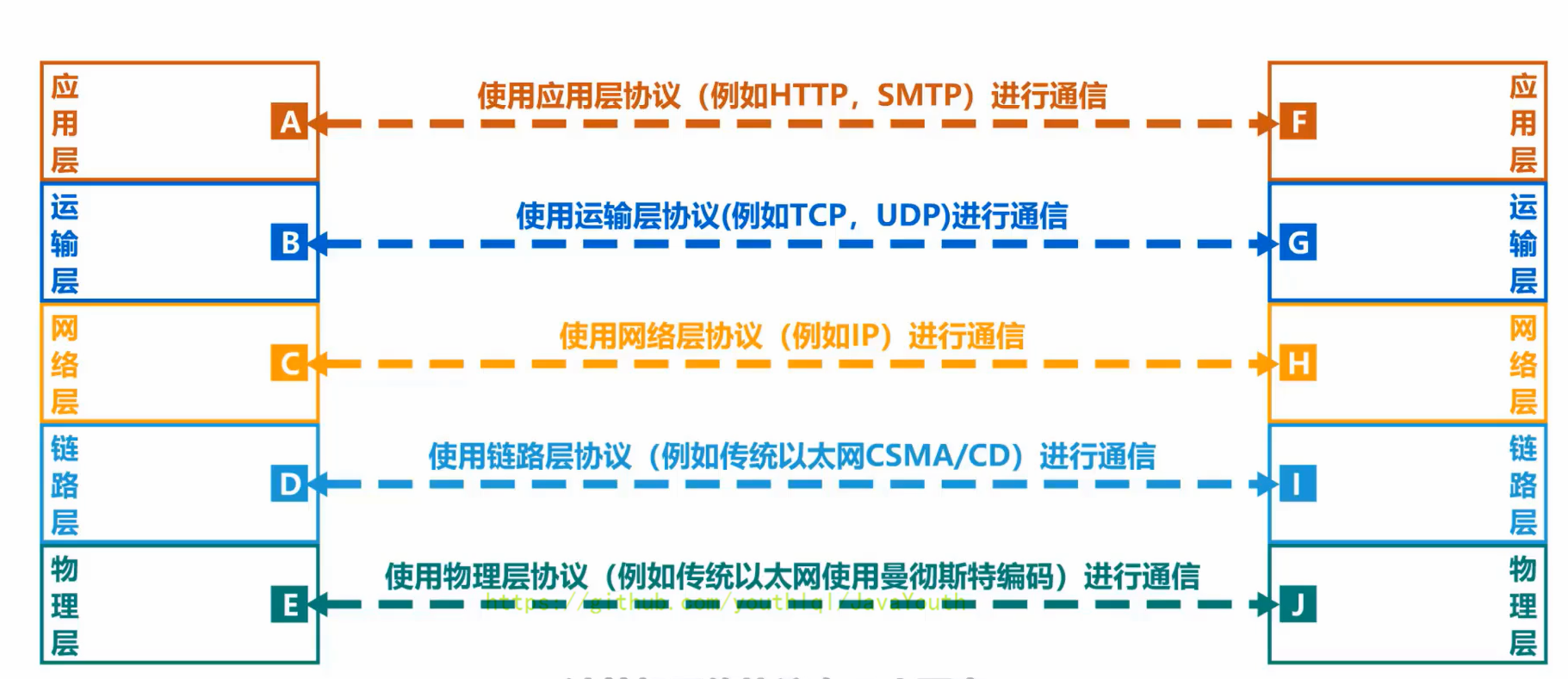 1、协议:控制两个对等实体进行逻辑通信的规则的集合
@@ -676,13 +676,13 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
**服务**
-
1、协议:控制两个对等实体进行逻辑通信的规则的集合
@@ -676,13 +676,13 @@ Q:另外对于总线型的网络,还会出现下面这种典型的问题
**服务**
- +
+ -
- +
+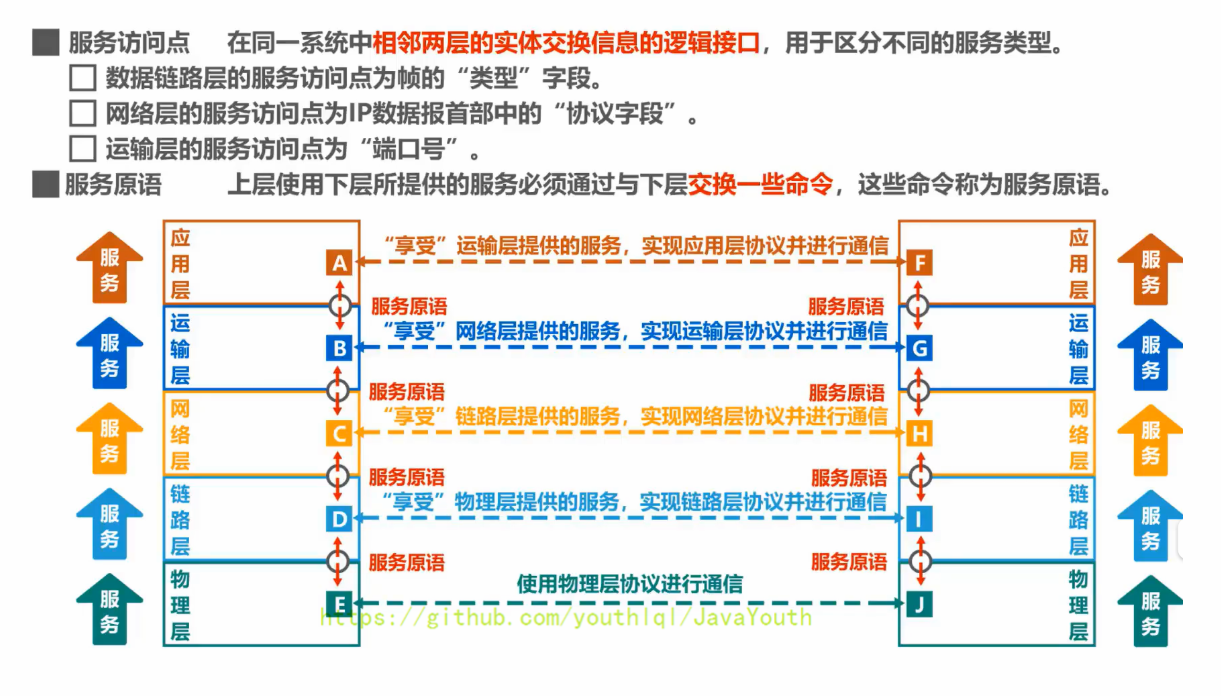 -
- +
+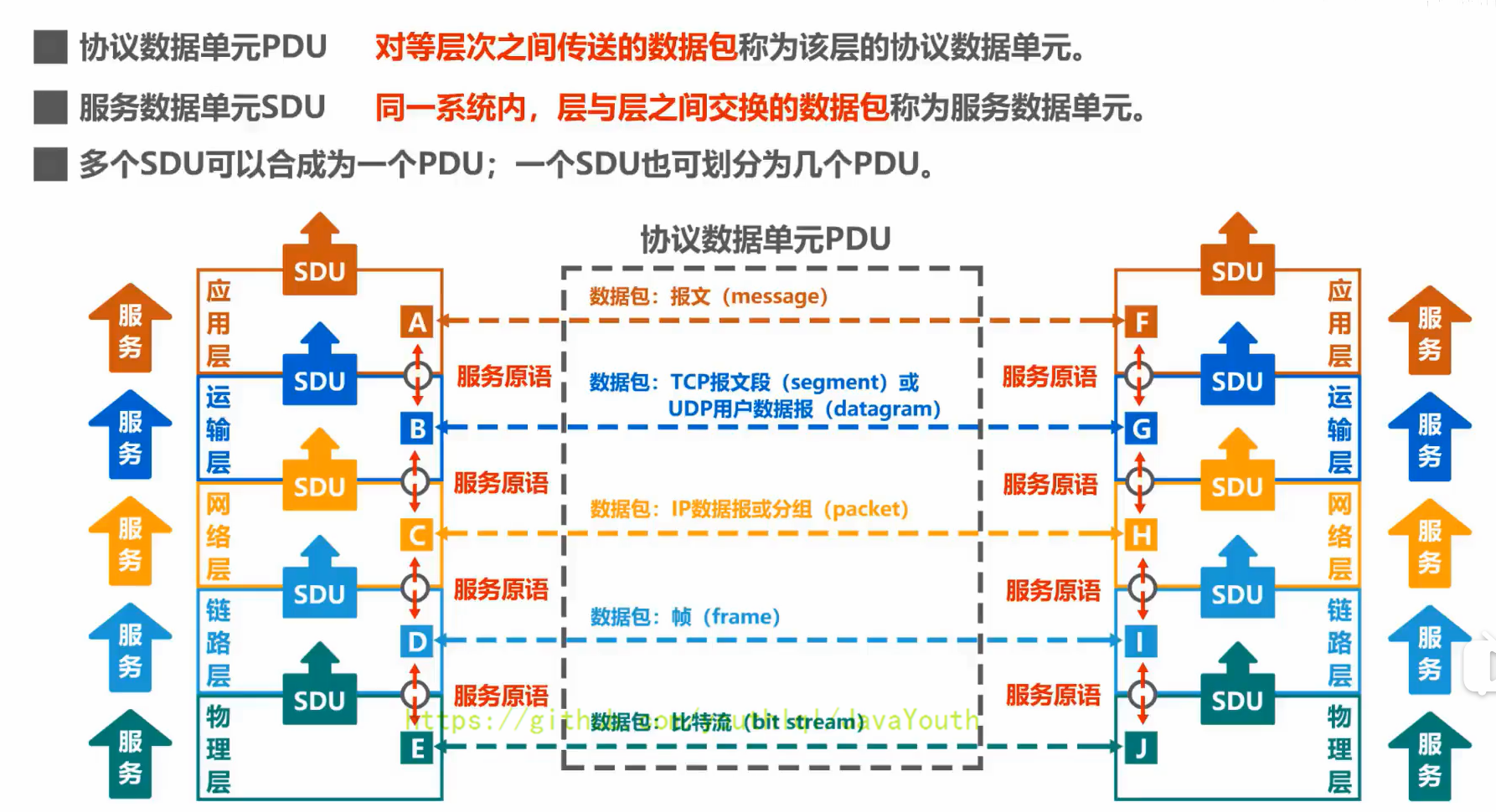 diff --git a/docs/ElasticSearch/ElasticSearch-入门.md b/docs/ElasticSearch/ElasticSearch-入门.md
index b310a69..b0e62ac 100644
--- a/docs/ElasticSearch/ElasticSearch-入门.md
+++ b/docs/ElasticSearch/ElasticSearch-入门.md
@@ -46,7 +46,7 @@ date: 2020-02-03 13:11:45
下图是ElasticSearch的索引结构,下边黑色部分是物理结构,上边黄色部分是逻辑结构,逻辑结构也是为了更好的 去描述ElasticSearch的工作原理及去使用物理结构中的索引文件。
-
diff --git a/docs/ElasticSearch/ElasticSearch-入门.md b/docs/ElasticSearch/ElasticSearch-入门.md
index b310a69..b0e62ac 100644
--- a/docs/ElasticSearch/ElasticSearch-入门.md
+++ b/docs/ElasticSearch/ElasticSearch-入门.md
@@ -46,7 +46,7 @@ date: 2020-02-03 13:11:45
下图是ElasticSearch的索引结构,下边黑色部分是物理结构,上边黄色部分是逻辑结构,逻辑结构也是为了更好的 去描述ElasticSearch的工作原理及去使用物理结构中的索引文件。
- +
+ 逻辑结构部分是一个倒排索引表:
@@ -58,11 +58,11 @@ date: 2020-02-03 13:11:45
如下:
-
逻辑结构部分是一个倒排索引表:
@@ -58,11 +58,11 @@ date: 2020-02-03 13:11:45
如下:
- +
+ 现在,如果我们想搜到`quick brown`我们只需要查找包含每个词条的文档:
-
现在,如果我们想搜到`quick brown`我们只需要查找包含每个词条的文档:
- +
+ 两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 , 那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳
@@ -236,7 +236,7 @@ http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000
使用postman测试:
-
两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 , 那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳
@@ -236,7 +236,7 @@ http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000
使用postman测试:
- +
+ diff --git a/docs/JVM/JVM系列-第10章-垃圾回收概述和相关算法.md b/docs/JVM/JVM系列-第10章-垃圾回收概述和相关算法.md
index 5ccf255..1b7dbbe 100644
--- a/docs/JVM/JVM系列-第10章-垃圾回收概述和相关算法.md
+++ b/docs/JVM/JVM系列-第10章-垃圾回收概述和相关算法.md
@@ -20,7 +20,7 @@ date: 2020-11-16 18:14:02
-
diff --git a/docs/JVM/JVM系列-第10章-垃圾回收概述和相关算法.md b/docs/JVM/JVM系列-第10章-垃圾回收概述和相关算法.md
index 5ccf255..1b7dbbe 100644
--- a/docs/JVM/JVM系列-第10章-垃圾回收概述和相关算法.md
+++ b/docs/JVM/JVM系列-第10章-垃圾回收概述和相关算法.md
@@ -20,7 +20,7 @@ date: 2020-11-16 18:14:02
- +
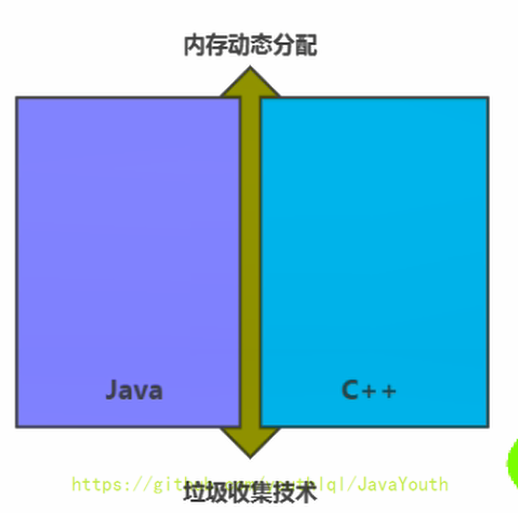
+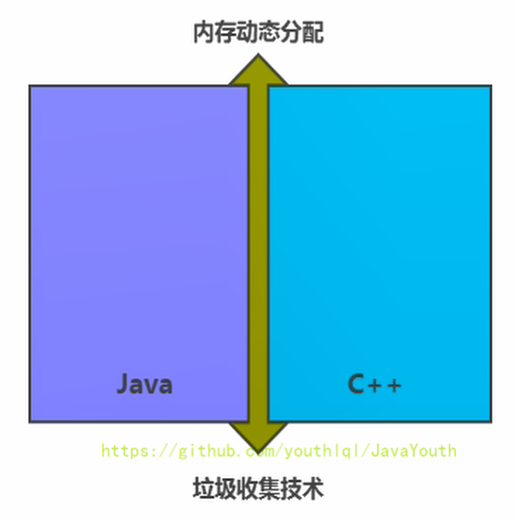 1. Java 和 C++语言的区别,就在于垃圾收集技术和内存动态分配上,C++语言没有垃圾收集技术,需要程序员手动的收集。
@@ -102,7 +102,7 @@ date: 2020-11-16 18:14:02
**十几年前磁盘碎片整理的日子**
-
1. Java 和 C++语言的区别,就在于垃圾收集技术和内存动态分配上,C++语言没有垃圾收集技术,需要程序员手动的收集。
@@ -102,7 +102,7 @@ date: 2020-11-16 18:14:02
**十几年前磁盘碎片整理的日子**
- +
+ @@ -174,7 +174,7 @@ date: 2020-11-16 18:14:02
### 应该关心哪些区域的回收?
-
@@ -174,7 +174,7 @@ date: 2020-11-16 18:14:02
### 应该关心哪些区域的回收?
- +
+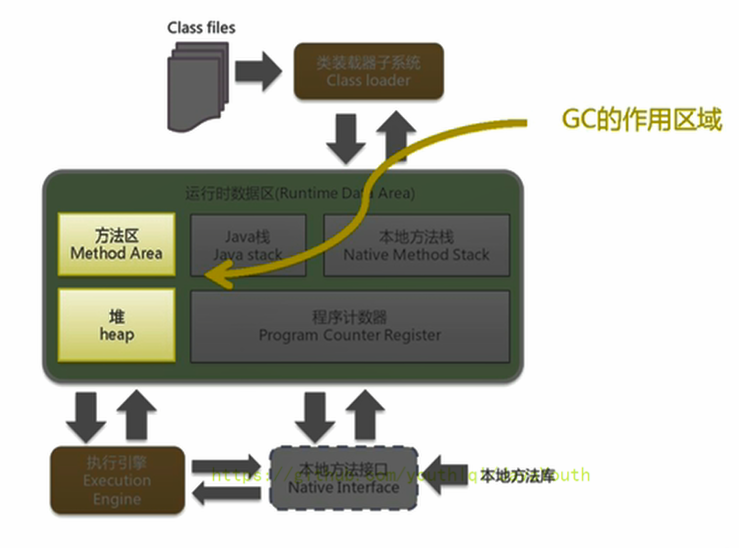 1. 垃圾收集器可以对年轻代回收,也可以对老年代回收,甚至是全栈和方法区的回收,
1. 其中,**Java堆是垃圾收集器的工作重点**
@@ -216,7 +216,7 @@ date: 2020-11-16 18:14:02
### 循环引用
-
1. 垃圾收集器可以对年轻代回收,也可以对老年代回收,甚至是全栈和方法区的回收,
1. 其中,**Java堆是垃圾收集器的工作重点**
@@ -216,7 +216,7 @@ date: 2020-11-16 18:14:02
### 循环引用
- +
+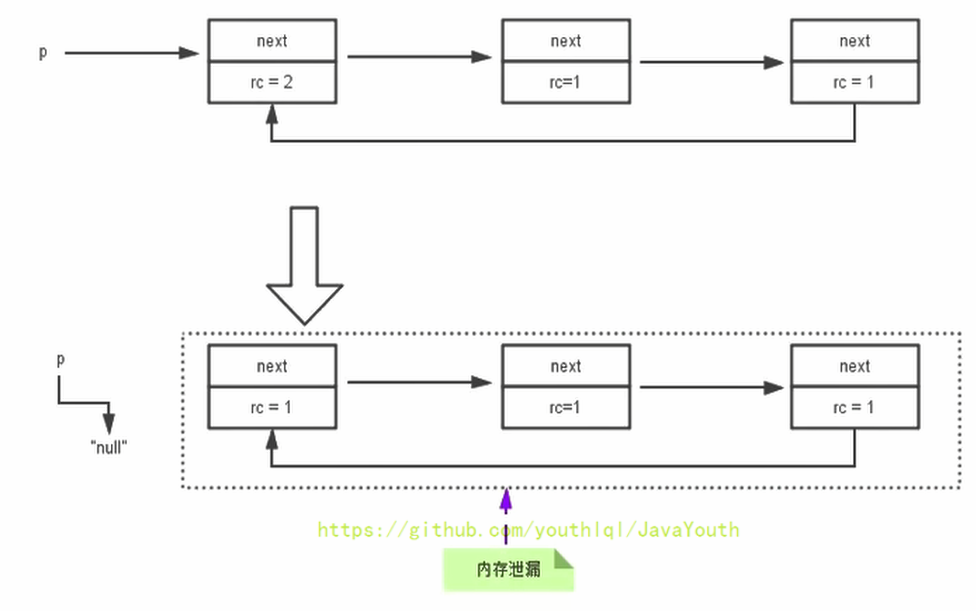 当p的指针断开的时候,内部的引用形成一个循环,计数器都还算1,无法被回收,这就是循环引用,从而造成内存泄漏
@@ -255,7 +255,7 @@ public class RefCountGC {
-
当p的指针断开的时候,内部的引用形成一个循环,计数器都还算1,无法被回收,这就是循环引用,从而造成内存泄漏
@@ -255,7 +255,7 @@ public class RefCountGC {
- +
+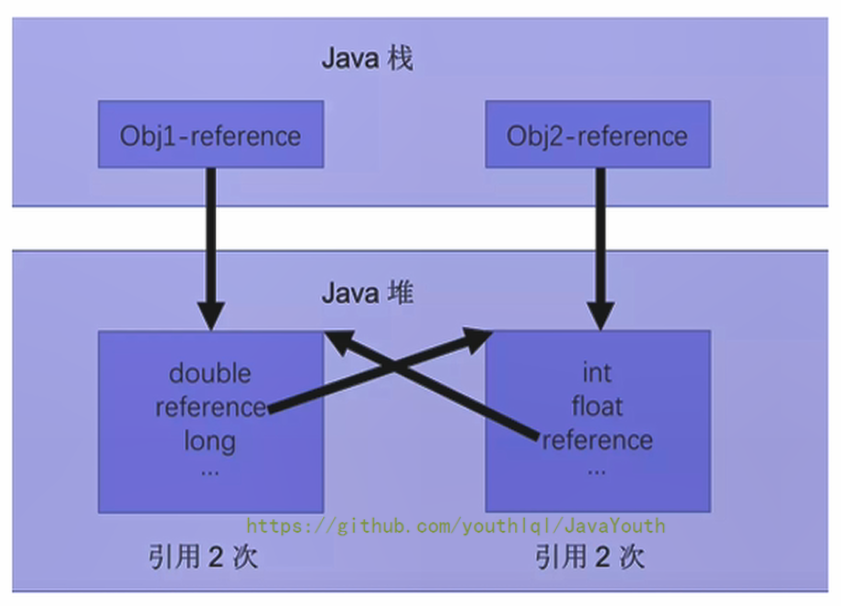 * 如果不小心直接把`obj1.reference`和`obj2.reference`置为null。则在Java堆中的两块内存依然保持着互相引用,无法被回收
@@ -353,7 +353,7 @@ Process finished with exit code 0
3. 如果目标对象没有任何引用链相连,则是不可达的,就意味着该对象己经死亡,可以标记为垃圾对象。
4. 在可达性分析算法中,只有能够被根对象集合直接或者间接连接的对象才是存活对象。
-
* 如果不小心直接把`obj1.reference`和`obj2.reference`置为null。则在Java堆中的两块内存依然保持着互相引用,无法被回收
@@ -353,7 +353,7 @@ Process finished with exit code 0
3. 如果目标对象没有任何引用链相连,则是不可达的,就意味着该对象己经死亡,可以标记为垃圾对象。
4. 在可达性分析算法中,只有能够被根对象集合直接或者间接连接的对象才是存活对象。
- +
+ @@ -371,7 +371,7 @@ Process finished with exit code 0
- 基本数据类型对应的Class对象,一些常驻的异常对象(如:NullPointerException、OutofMemoryError),系统类加载器。
7. 反映java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
-
@@ -371,7 +371,7 @@ Process finished with exit code 0
- 基本数据类型对应的Class对象,一些常驻的异常对象(如:NullPointerException、OutofMemoryError),系统类加载器。
7. 反映java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
- +
+ @@ -453,7 +453,7 @@ Object 类中 finalize() 源码
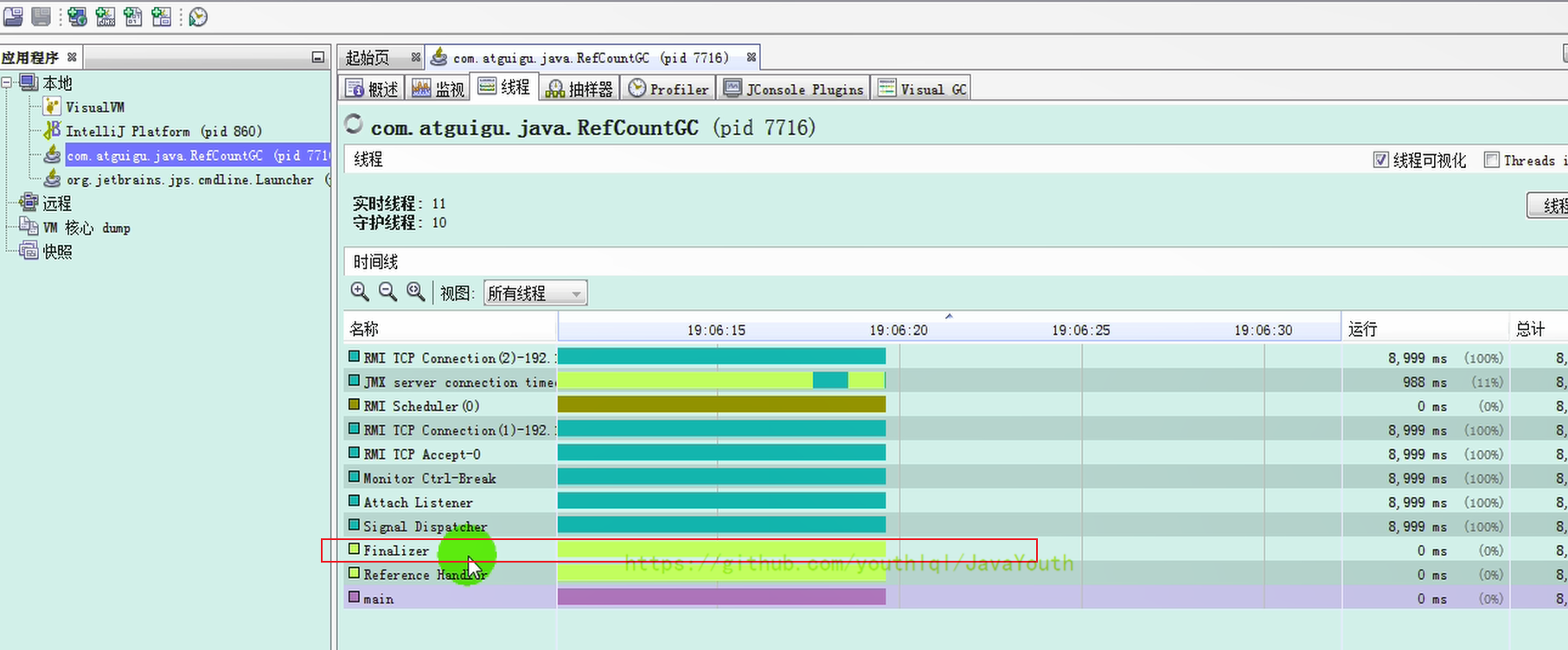
**通过 JVisual VM 查看 Finalizer 线程**
-
@@ -453,7 +453,7 @@ Object 类中 finalize() 源码
**通过 JVisual VM 查看 Finalizer 线程**
- +
+ @@ -579,7 +579,7 @@ MAT与JProfiler的GC Roots溯源
**方式一:命令行使用 jmap**
-
@@ -579,7 +579,7 @@ MAT与JProfiler的GC Roots溯源
**方式一:命令行使用 jmap**
- +
+ @@ -631,23 +631,23 @@ public class GCRootsTest {
1、先执行第一步,然后停下来,去生成此步骤dump文件
-
@@ -631,23 +631,23 @@ public class GCRootsTest {
1、先执行第一步,然后停下来,去生成此步骤dump文件
- +
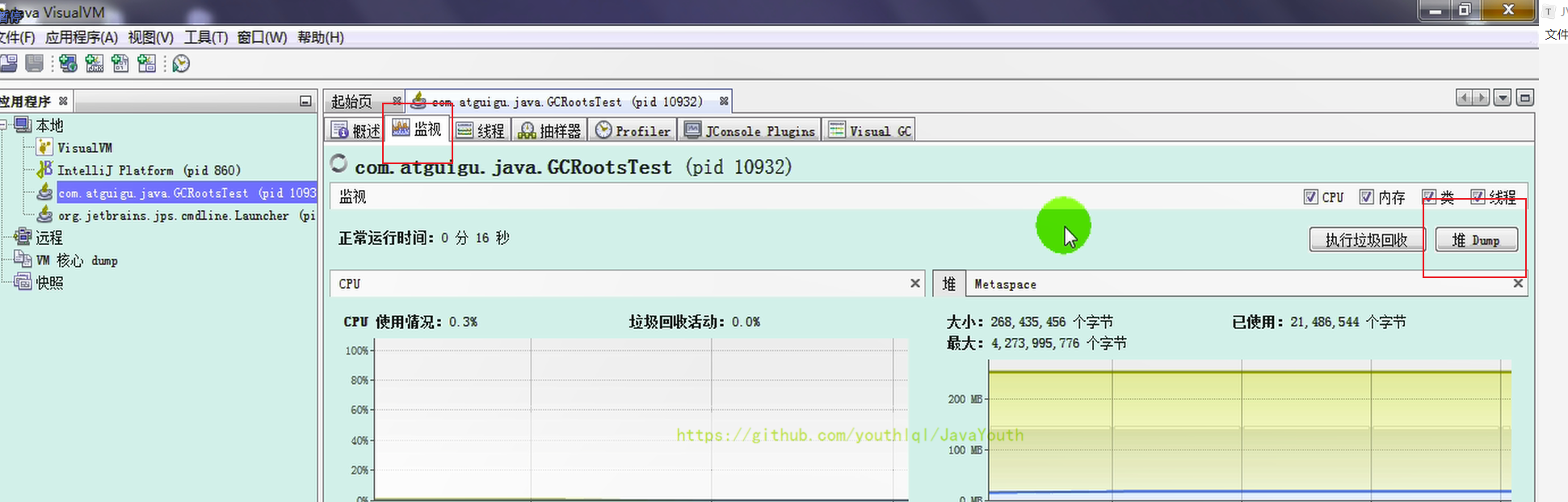
+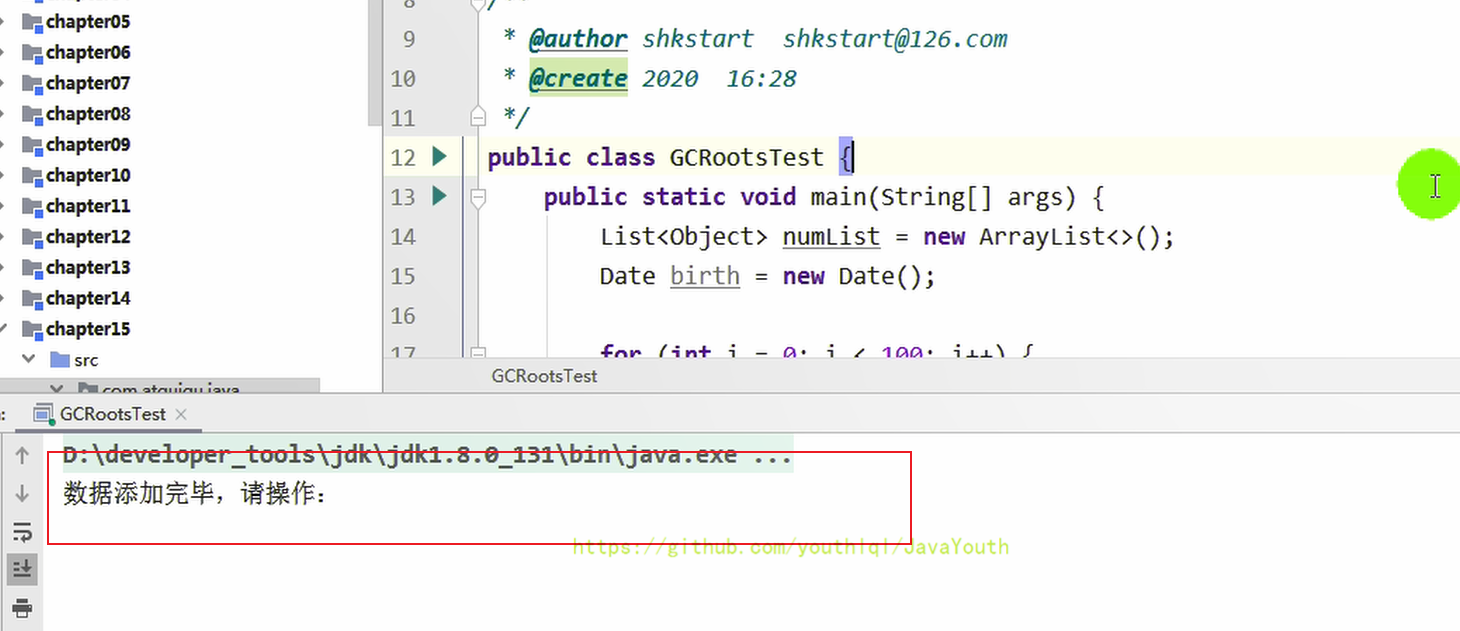 2、 点击【堆 Dump】
-
2、 点击【堆 Dump】
- +
+ 3、右键 --\> 另存为即可
-
3、右键 --\> 另存为即可
- +
+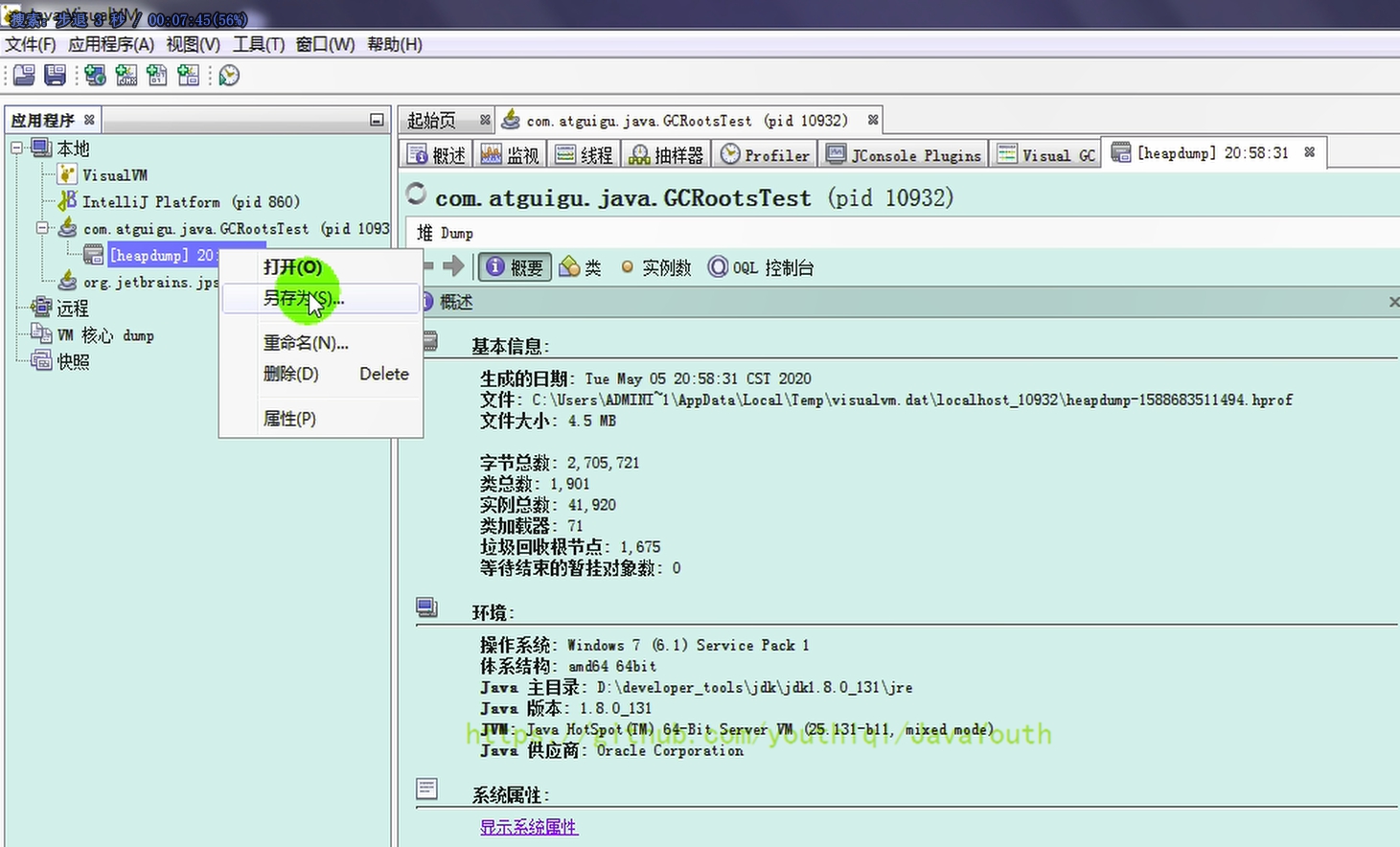 4、输入命令,继续执行程序
-
4、输入命令,继续执行程序
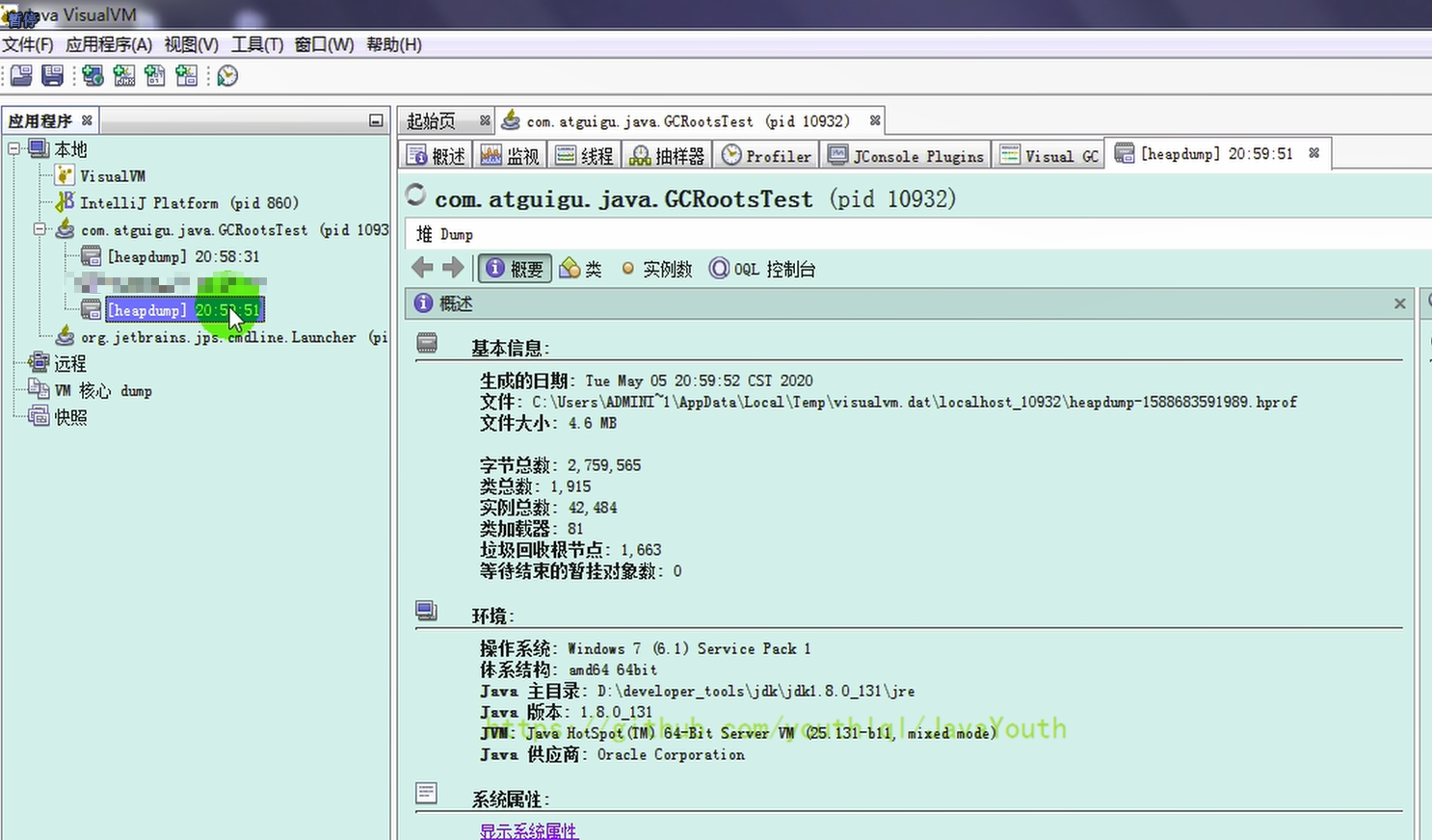
- +
+ 5、我们接着捕获第二张堆内存快照
-
5、我们接着捕获第二张堆内存快照
- +
+ @@ -657,19 +657,19 @@ public class GCRootsTest {
> 点击Open Heap Dump也行
-
@@ -657,19 +657,19 @@ public class GCRootsTest {
> 点击Open Heap Dump也行
- +
+ 2、选择Java Basics --> GC Roots
-
2、选择Java Basics --> GC Roots
- +
+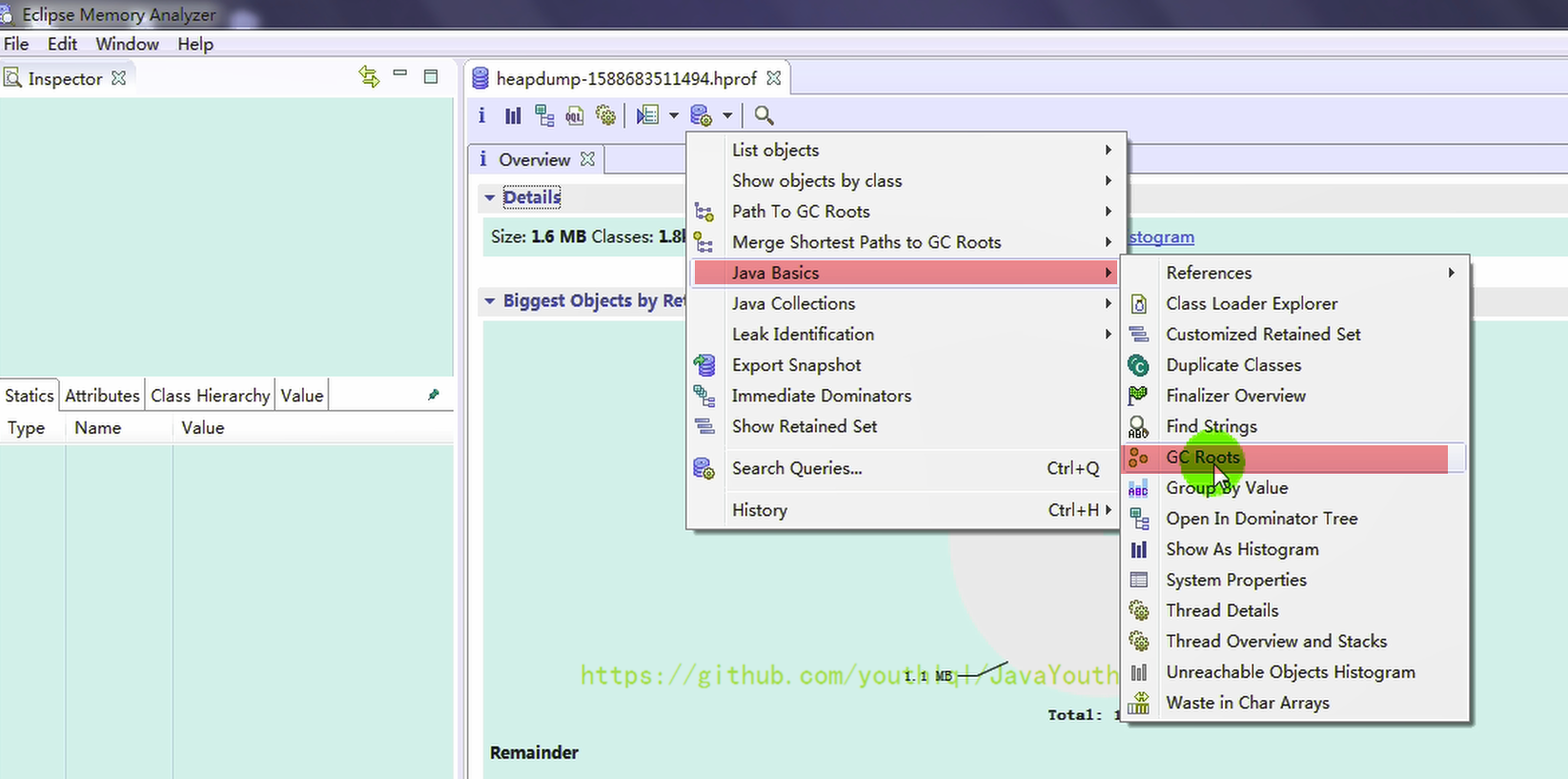 3、第一次捕捉堆内存快照时,GC Roots 中包含我们定义的两个局部变量,类型分别为 ArrayList 和 Date,Total:21
-
3、第一次捕捉堆内存快照时,GC Roots 中包含我们定义的两个局部变量,类型分别为 ArrayList 和 Date,Total:21
- +
+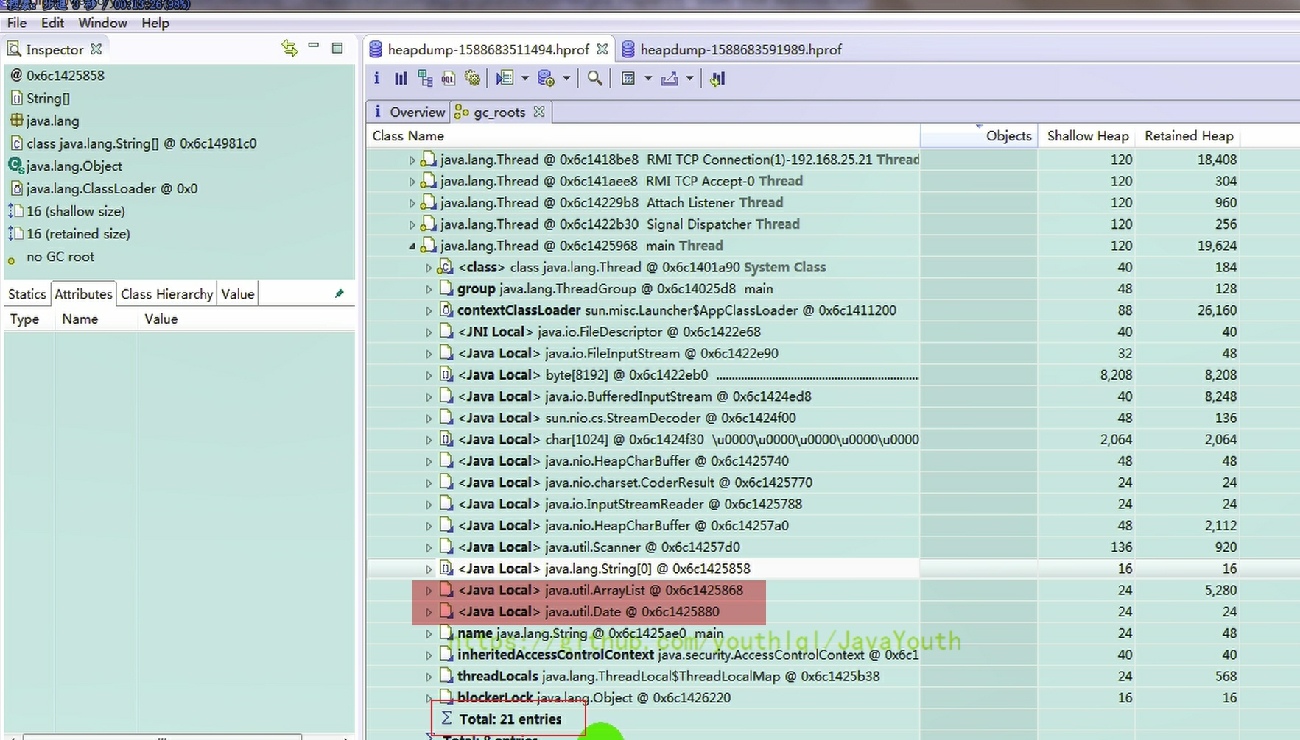 4、打开第二个dump文件,第二次捕获内存快照时,由于两个局部变量引用的对象被释放,所以这两个局部变量不再作为 GC Roots ,从 Total Entries = 19 也可以看出(少了两个 GC Roots)
-
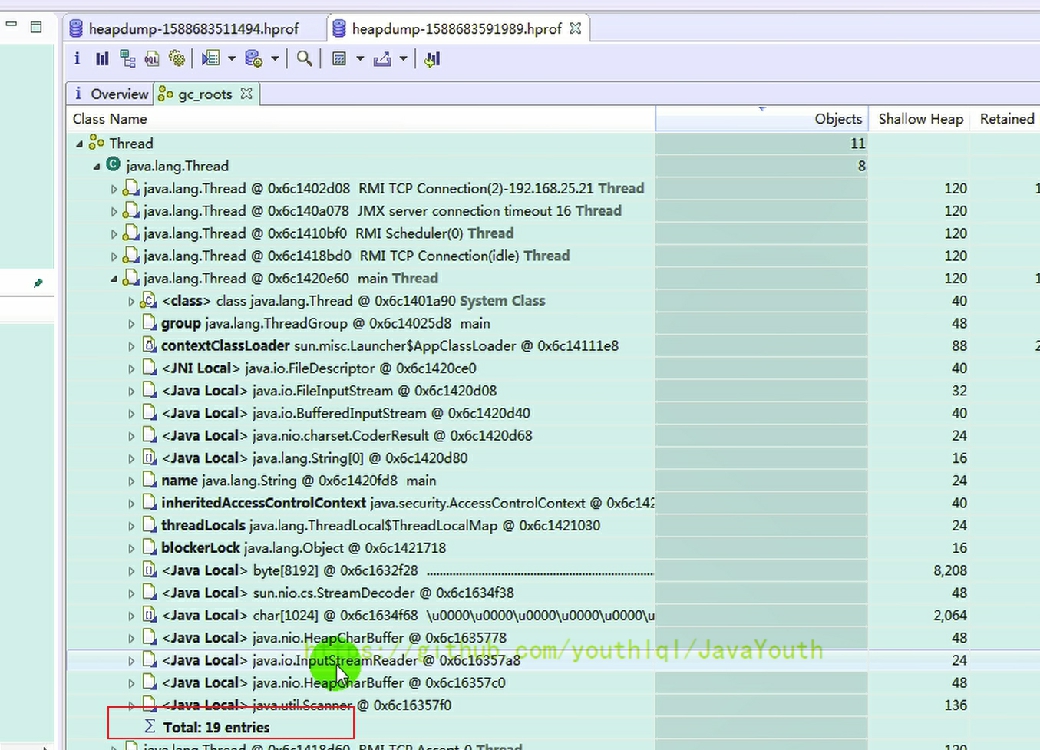
4、打开第二个dump文件,第二次捕获内存快照时,由于两个局部变量引用的对象被释放,所以这两个局部变量不再作为 GC Roots ,从 Total Entries = 19 也可以看出(少了两个 GC Roots)
- +
+ @@ -716,13 +716,13 @@ public class GCRootsTest {
1、
-
@@ -716,13 +716,13 @@ public class GCRootsTest {
1、
- +
+ 2、
-
2、
- +
+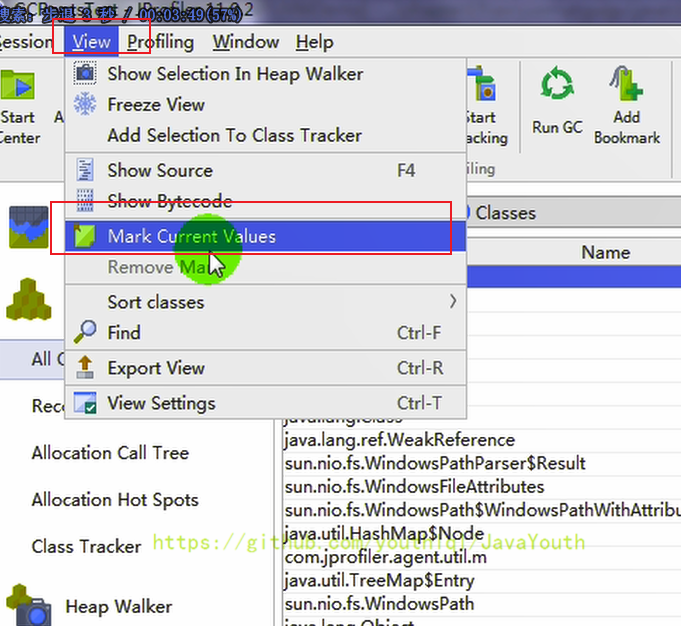 -
- +
+ 可以发现颜色变绿了,可以动态的看变化
@@ -730,11 +730,11 @@ public class GCRootsTest {
3、右击对象,选择 Show Selection In Heap Walker,单独的查看某个对象
-
可以发现颜色变绿了,可以动态的看变化
@@ -730,11 +730,11 @@ public class GCRootsTest {
3、右击对象,选择 Show Selection In Heap Walker,单独的查看某个对象
- +
+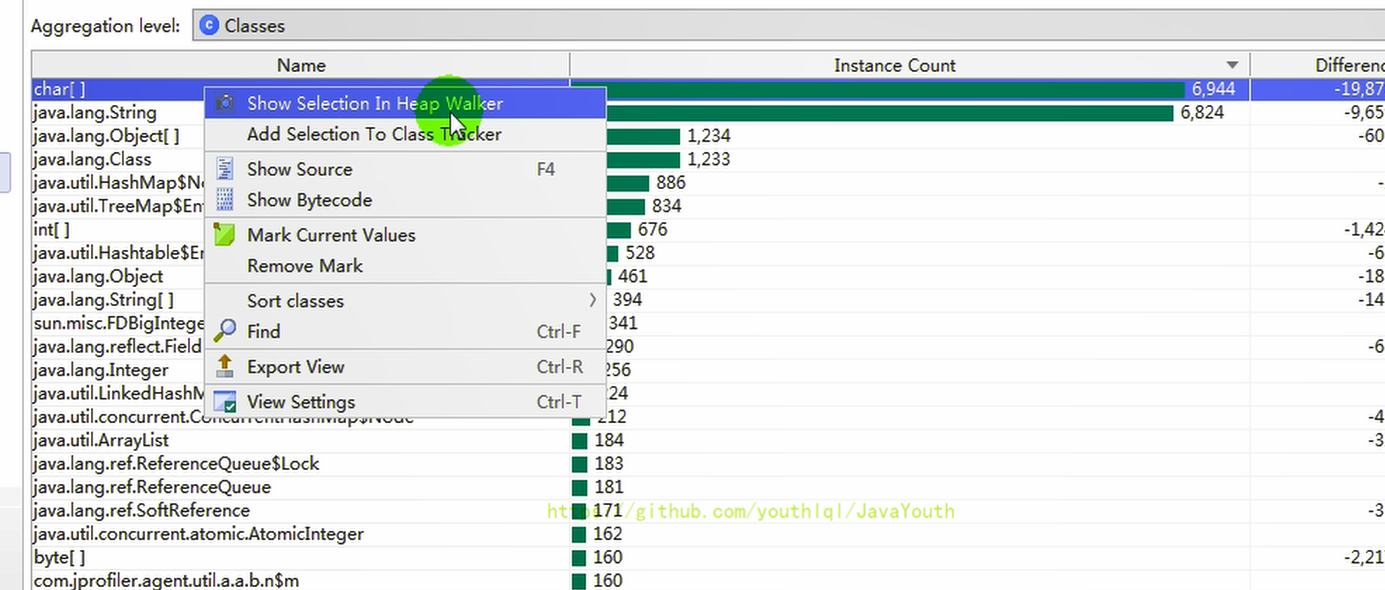 -
- +
+ @@ -742,13 +742,13 @@ public class GCRootsTest {
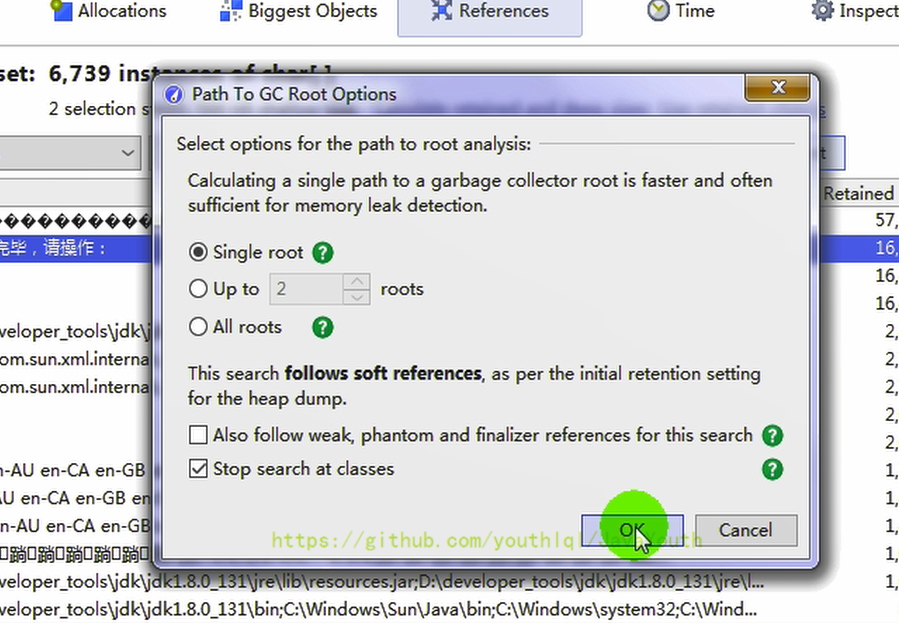
点击Show Paths To GC Roots,在弹出界面中选择默认设置即可
-
@@ -742,13 +742,13 @@ public class GCRootsTest {
点击Show Paths To GC Roots,在弹出界面中选择默认设置即可
- +
+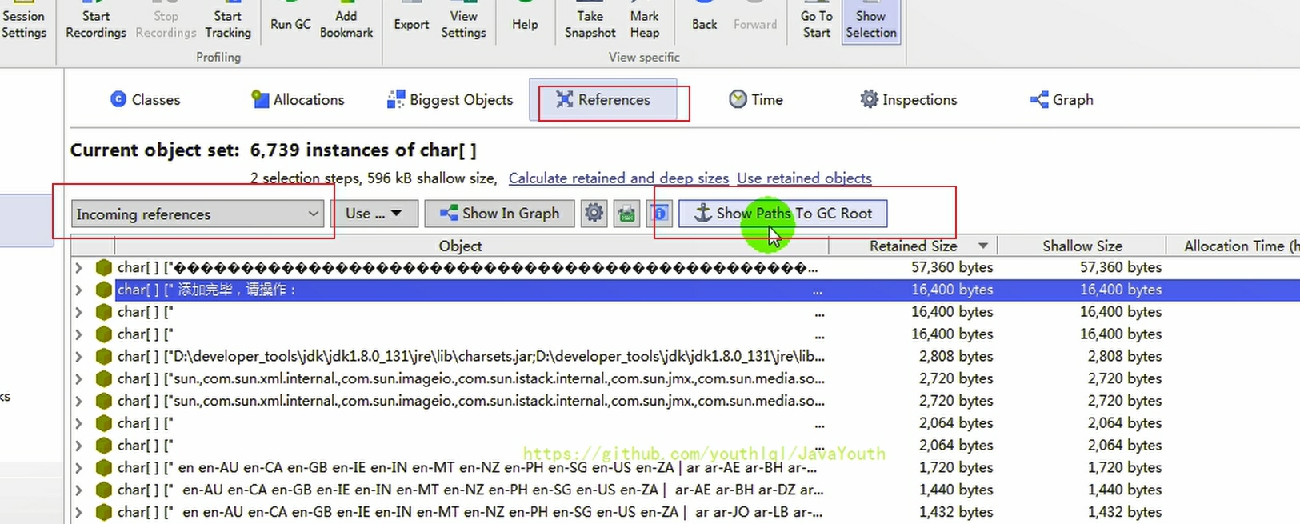 -
- +
+ -
- +
+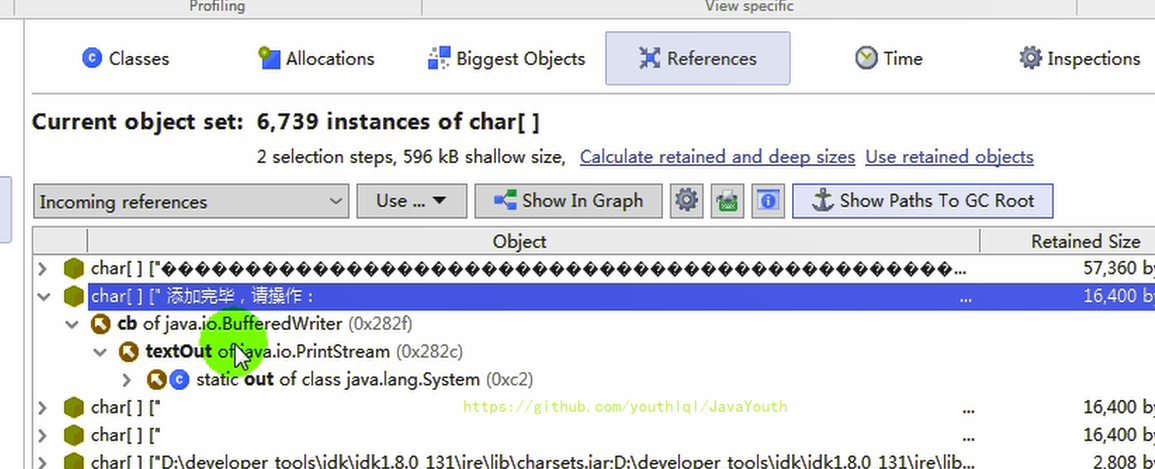 ### JProfiler 分析 OOM
@@ -798,11 +798,11 @@ count = 6
1、看这个超大对象
-
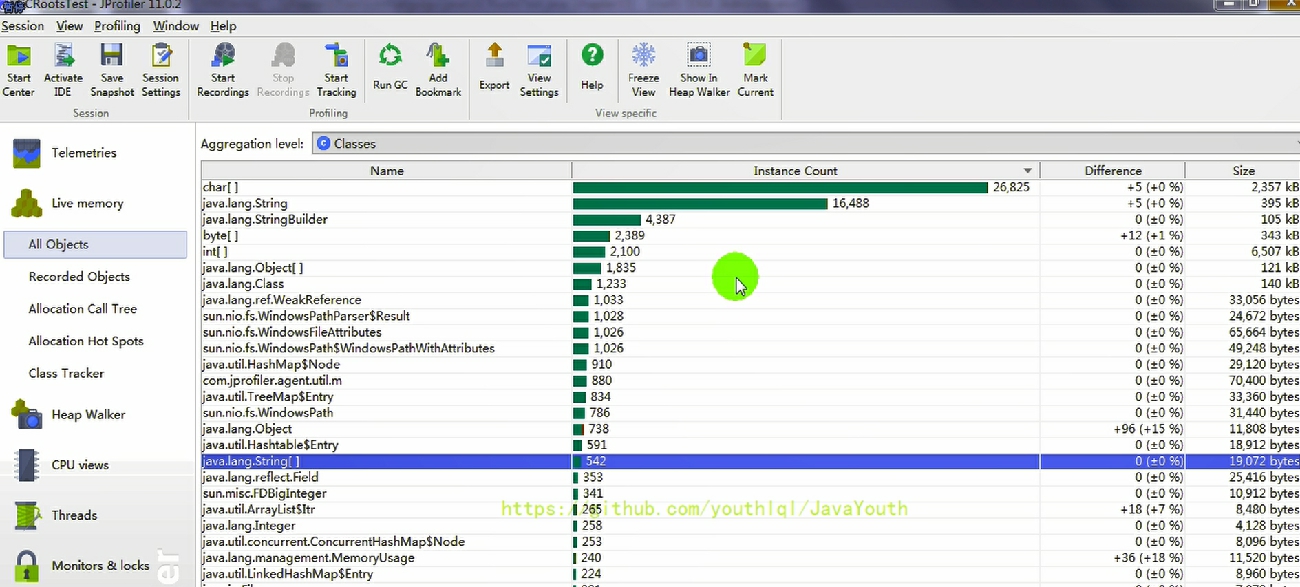
### JProfiler 分析 OOM
@@ -798,11 +798,11 @@ count = 6
1、看这个超大对象
- +
+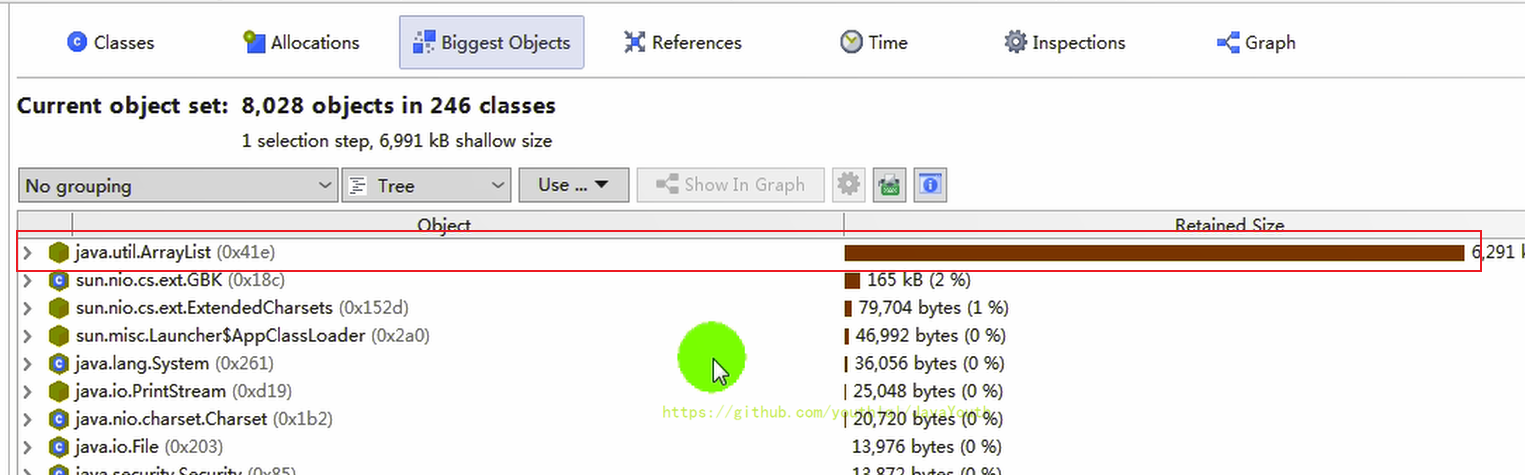 2、揪出 main() 线程中出问题的代码
-
2、揪出 main() 线程中出问题的代码
- +
+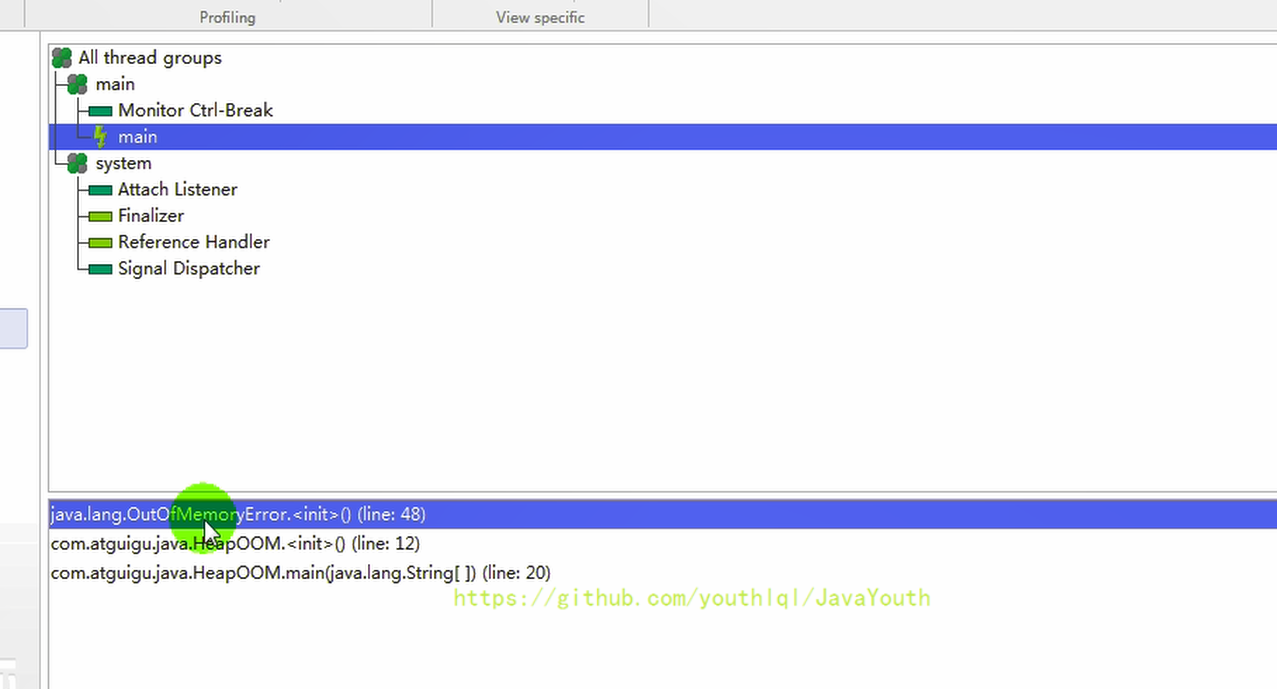 @@ -837,7 +837,7 @@ count = 6
* 注意:标记的是被引用的对象,也就是可达对象,并非标记的是即将被清除的垃圾对象
2. 清除:Collector对堆内存从头到尾进行线性的遍历,如果发现某个对象在其Header中没有标记为可达对象,则将其回收
-
@@ -837,7 +837,7 @@ count = 6
* 注意:标记的是被引用的对象,也就是可达对象,并非标记的是即将被清除的垃圾对象
2. 清除:Collector对堆内存从头到尾进行线性的遍历,如果发现某个对象在其Header中没有标记为可达对象,则将其回收
- +
+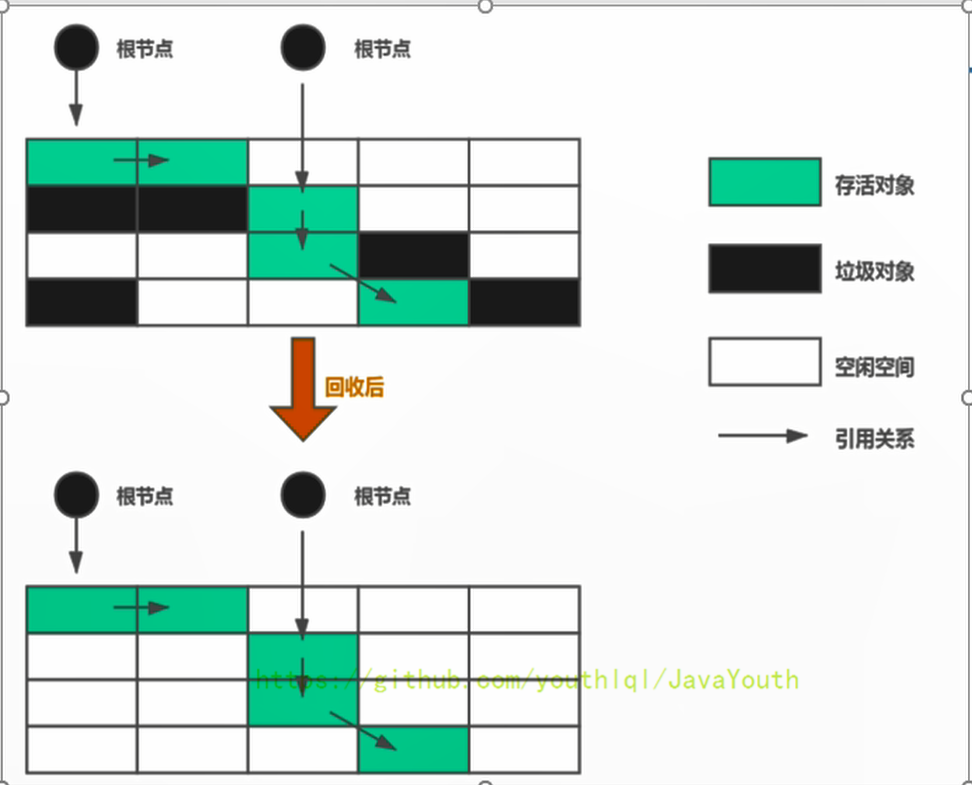 @@ -876,7 +876,7 @@ count = 6
将活着的内存空间分为两块,每次只使用其中一块,在垃圾回收时将正在使用的内存中的存活对象复制到未被使用的内存块中,之后清除正在使用的内存块中的所有对象,交换两个内存的角色,最后完成垃圾回收
-
@@ -876,7 +876,7 @@ count = 6
将活着的内存空间分为两块,每次只使用其中一块,在垃圾回收时将正在使用的内存中的存活对象复制到未被使用的内存块中,之后清除正在使用的内存块中的所有对象,交换两个内存的角色,最后完成垃圾回收
- +
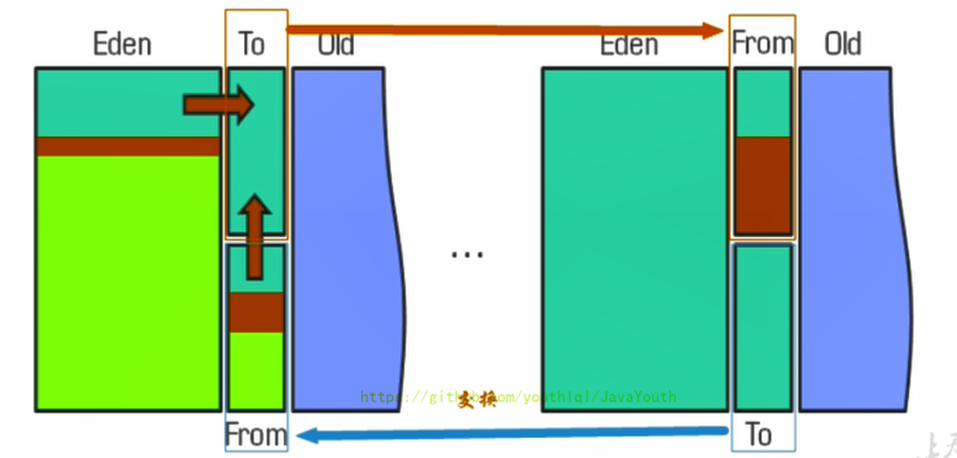
+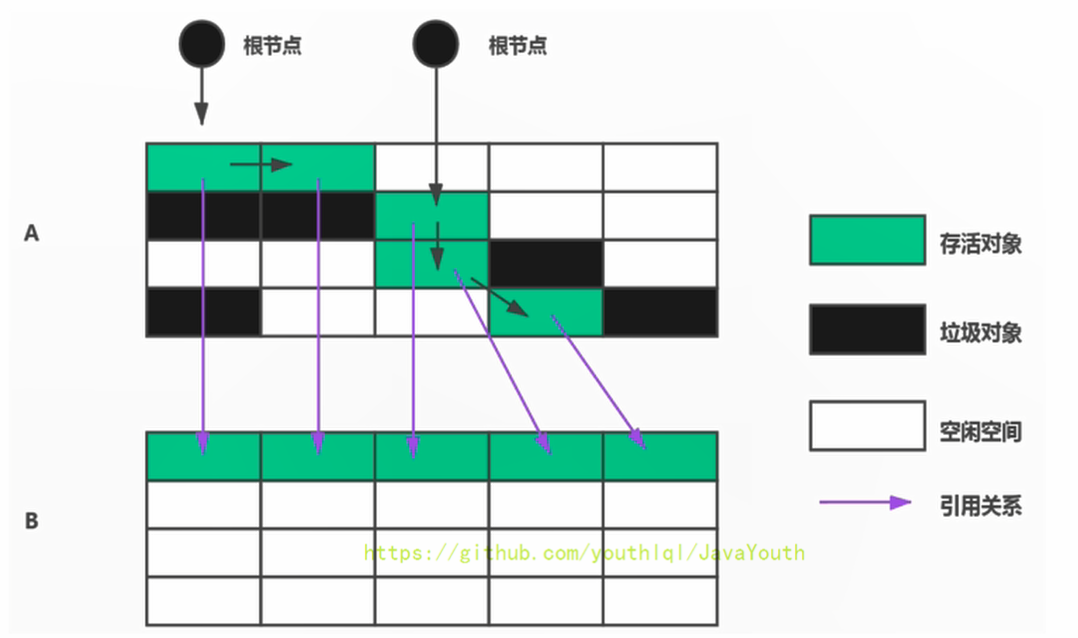 新生代里面就用到了复制算法,Eden区和S0区存活对象整体复制到S1区
@@ -906,7 +906,7 @@ count = 6
2. 老年代大量的对象存活,那么复制的对象将会有很多,效率会很低
3. 在新生代,对常规应用的垃圾回收,一次通常可以回收70% - 99% 的内存空间。回收性价比很高。所以现在的商业虚拟机都是用这种收集算法回收新生代。
-
新生代里面就用到了复制算法,Eden区和S0区存活对象整体复制到S1区
@@ -906,7 +906,7 @@ count = 6
2. 老年代大量的对象存活,那么复制的对象将会有很多,效率会很低
3. 在新生代,对常规应用的垃圾回收,一次通常可以回收70% - 99% 的内存空间。回收性价比很高。所以现在的商业虚拟机都是用这种收集算法回收新生代。
- +
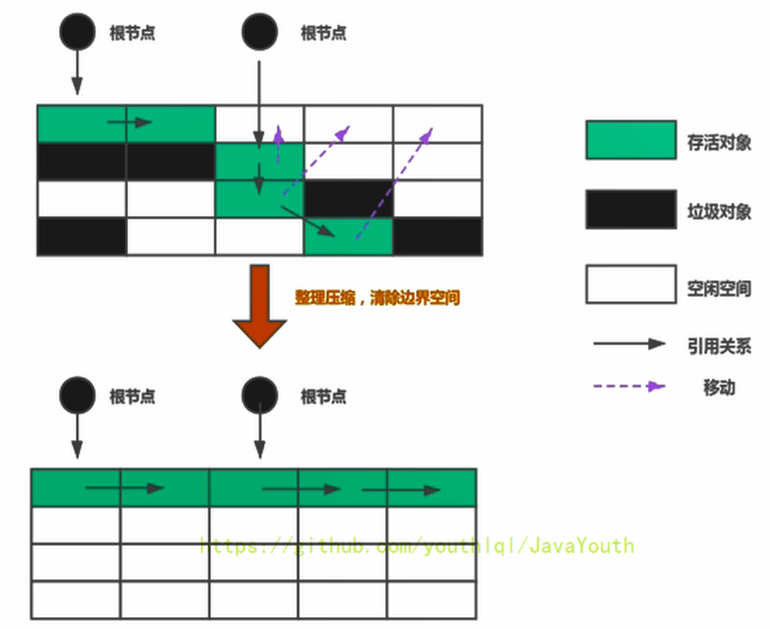
+ @@ -935,7 +935,7 @@ count = 6
2. 第二阶段将所有的存活对象压缩到内存的一端,按顺序排放。之后,清理边界外所有的空间。
-
@@ -935,7 +935,7 @@ count = 6
2. 第二阶段将所有的存活对象压缩到内存的一端,按顺序排放。之后,清理边界外所有的空间。
- +
+ @@ -1066,7 +1066,7 @@ A:无,没有最好的算法,只有最合适的算法
1. 一般来说,在相同条件下,堆空间越大,一次GC时所需要的时间就越长,有关GC产生的停顿也越长。为了更好地控制GC产生的停顿时间,将一块大的内存区域分割成多个小块,根据目标的停顿时间,每次合理地回收若干个小区间,而不是整个堆空间,从而减少一次GC所产生的停顿。
3. 分代算法将按照对象的生命周期长短划分成两个部分,分区算法将整个堆空间划分成连续的不同小区间。每一个小区间都独立使用,独立回收。这种算法的好处是可以控制一次回收多少个小区间。
-
@@ -1066,7 +1066,7 @@ A:无,没有最好的算法,只有最合适的算法
1. 一般来说,在相同条件下,堆空间越大,一次GC时所需要的时间就越长,有关GC产生的停顿也越长。为了更好地控制GC产生的停顿时间,将一块大的内存区域分割成多个小块,根据目标的停顿时间,每次合理地回收若干个小区间,而不是整个堆空间,从而减少一次GC所产生的停顿。
3. 分代算法将按照对象的生命周期长短划分成两个部分,分区算法将整个堆空间划分成连续的不同小区间。每一个小区间都独立使用,独立回收。这种算法的好处是可以控制一次回收多少个小区间。
- +
+ diff --git a/docs/JVM/JVM系列-第11章-垃圾回收相关概念.md b/docs/JVM/JVM系列-第11章-垃圾回收相关概念.md
index 68b6e7b..7052630 100644
--- a/docs/JVM/JVM系列-第11章-垃圾回收相关概念.md
+++ b/docs/JVM/JVM系列-第11章-垃圾回收相关概念.md
@@ -117,7 +117,7 @@ JVM参数:
2、我也查过了大对象阈值的默认值
-
diff --git a/docs/JVM/JVM系列-第11章-垃圾回收相关概念.md b/docs/JVM/JVM系列-第11章-垃圾回收相关概念.md
index 68b6e7b..7052630 100644
--- a/docs/JVM/JVM系列-第11章-垃圾回收相关概念.md
+++ b/docs/JVM/JVM系列-第11章-垃圾回收相关概念.md
@@ -117,7 +117,7 @@ JVM参数:
2、我也查过了大对象阈值的默认值
- +
+ 我不太懂这个默认值为啥是0,我猜测可能是代表什么比例,目前也没有搜到相关的东西。这个不太重要,暂时就没有太深究,希望读者有知道的可以告知我一声。
@@ -185,11 +185,11 @@ Heap
1、来看看字节码:实例方法局部变量表第一个变量肯定是 this
-
我不太懂这个默认值为啥是0,我猜测可能是代表什么比例,目前也没有搜到相关的东西。这个不太重要,暂时就没有太深究,希望读者有知道的可以告知我一声。
@@ -185,11 +185,11 @@ Heap
1、来看看字节码:实例方法局部变量表第一个变量肯定是 this
- +
+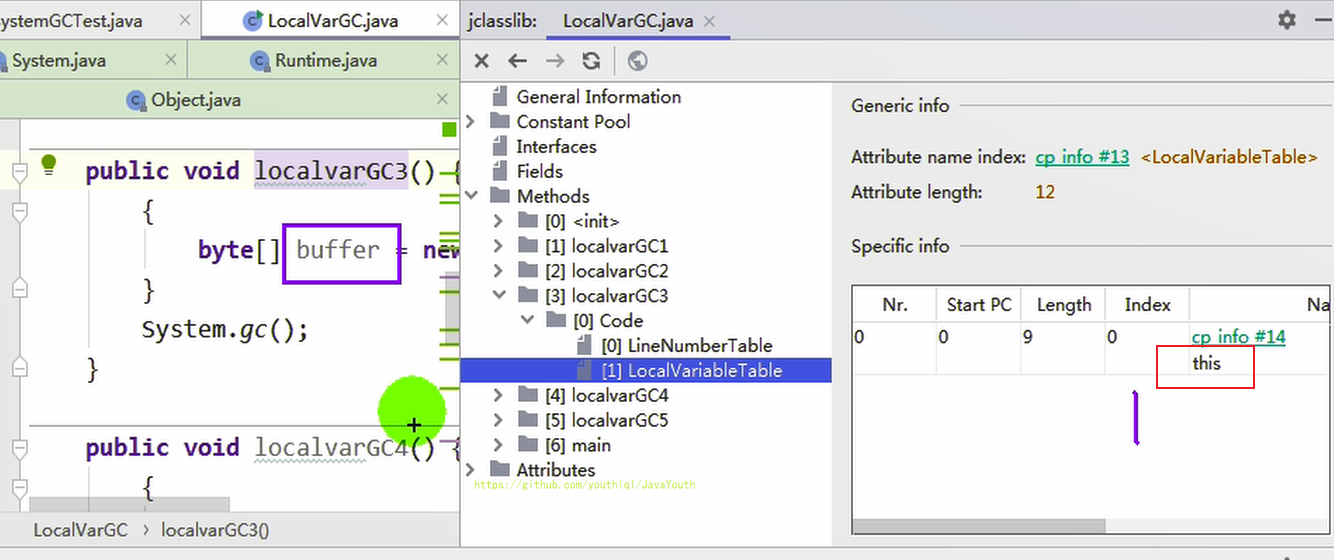 2、你有没有看到,局部变量表的大小是 2。但是局部变量表里只有一个索引为0的啊?那索引为1的是哪个局部变量呢?实际上索引为1的位置是buffer在占用着,执行 System.gc() 时,栈中还有 buffer 变量指向堆中的字节数组,所以没有进行GC
-
2、你有没有看到,局部变量表的大小是 2。但是局部变量表里只有一个索引为0的啊?那索引为1的是哪个局部变量呢?实际上索引为1的位置是buffer在占用着,执行 System.gc() 时,栈中还有 buffer 变量指向堆中的字节数组,所以没有进行GC
- +
+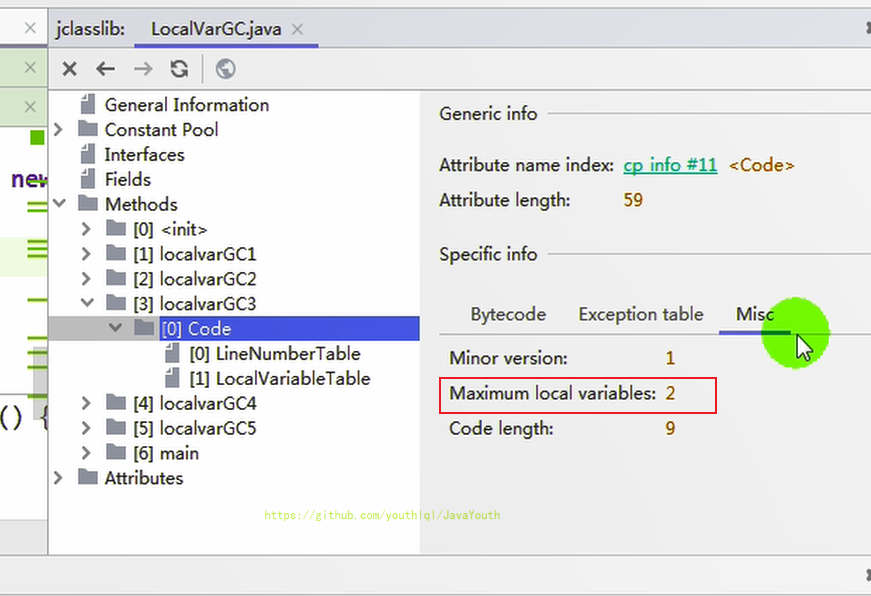 3、那么这种代码块的情况,什么时候会被GC呢?我们来看第四个方法
@@ -217,11 +217,11 @@ A:局部变量表长度为 2 ,这说明了出了代码块时,buffer 就出
> 这点看不懂的可以看我前面的文章:虚拟机栈 --> Slot的重复利用
-
3、那么这种代码块的情况,什么时候会被GC呢?我们来看第四个方法
@@ -217,11 +217,11 @@ A:局部变量表长度为 2 ,这说明了出了代码块时,buffer 就出
> 这点看不懂的可以看我前面的文章:虚拟机栈 --> Slot的重复利用
- +
+ -
- +
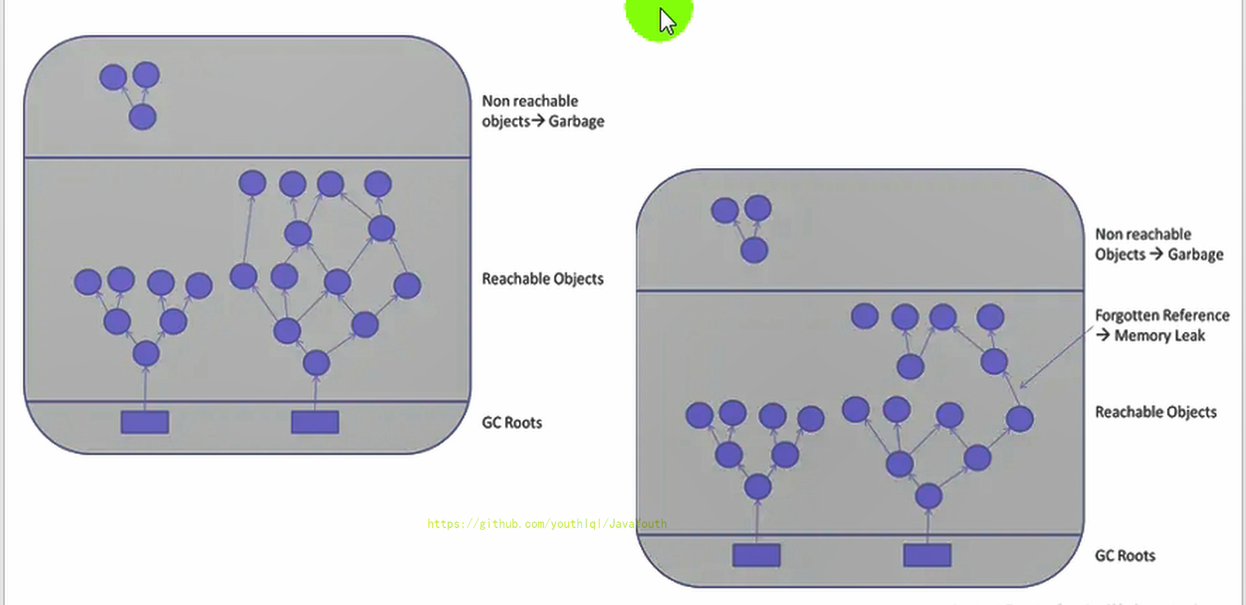
+ @@ -302,7 +302,7 @@ Heap
右边的图:后期有一些对象不用了,按道理应该断开引用,但是存在一些链没有断开(图示中的Forgotten Reference Memory Leak),从而导致没有办法被回收。
-
@@ -302,7 +302,7 @@ Heap
右边的图:后期有一些对象不用了,按道理应该断开引用,但是存在一些链没有断开(图示中的Forgotten Reference Memory Leak),从而导致没有办法被回收。
- +
+ @@ -446,7 +446,7 @@ Process finished with exit code -1
2. 并发不是真正意义上的“同时进行”,只是CPU把一个时间段划分成几个时间片段(时间区间),然后在这几个时间区间之间来回切换。由于CPU处理的速度非常快,只要时间间隔处理得当,即可让用户感觉是多个应用程序同时在进行
-
@@ -446,7 +446,7 @@ Process finished with exit code -1
2. 并发不是真正意义上的“同时进行”,只是CPU把一个时间段划分成几个时间片段(时间区间),然后在这几个时间区间之间来回切换。由于CPU处理的速度非常快,只要时间间隔处理得当,即可让用户感觉是多个应用程序同时在进行
- +
+ @@ -461,7 +461,7 @@ Process finished with exit code -1
3. 适合科学计算,后台处理等弱交互场景
-
@@ -461,7 +461,7 @@ Process finished with exit code -1
3. 适合科学计算,后台处理等弱交互场景
- +
+ > **并发与并行的对比**
@@ -482,7 +482,7 @@ Process finished with exit code -1
* 相较于并行的概念,单线程执行。
* 如果内存不够,则程序暂停,启动JVM垃圾回收器进行垃圾回收(单线程)
-
> **并发与并行的对比**
@@ -482,7 +482,7 @@ Process finished with exit code -1
* 相较于并行的概念,单线程执行。
* 如果内存不够,则程序暂停,启动JVM垃圾回收器进行垃圾回收(单线程)
- +
+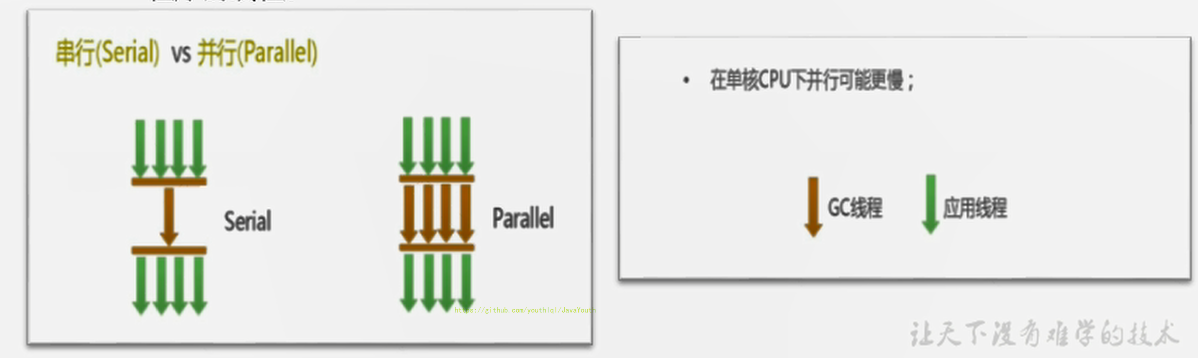 @@ -492,7 +492,7 @@ Process finished with exit code -1
- 比如用户程序在继续运行,而垃圾收集程序线程运行于另一个CPU上;
2. 典型垃圾回收器:CMS、G1
-
@@ -492,7 +492,7 @@ Process finished with exit code -1
- 比如用户程序在继续运行,而垃圾收集程序线程运行于另一个CPU上;
2. 典型垃圾回收器:CMS、G1
- +
+ @@ -551,7 +551,7 @@ Process finished with exit code -1
1、一般的垃圾回收算法至少会划分出两个年代,年轻代和老年代。但是单纯的分代理论在垃圾回收的时候存在一个巨大的缺陷:为了找到年轻代中的存活对象,却不得不遍历整个老年代,反过来也是一样的。
-
@@ -551,7 +551,7 @@ Process finished with exit code -1
1、一般的垃圾回收算法至少会划分出两个年代,年轻代和老年代。但是单纯的分代理论在垃圾回收的时候存在一个巨大的缺陷:为了找到年轻代中的存活对象,却不得不遍历整个老年代,反过来也是一样的。
- +
+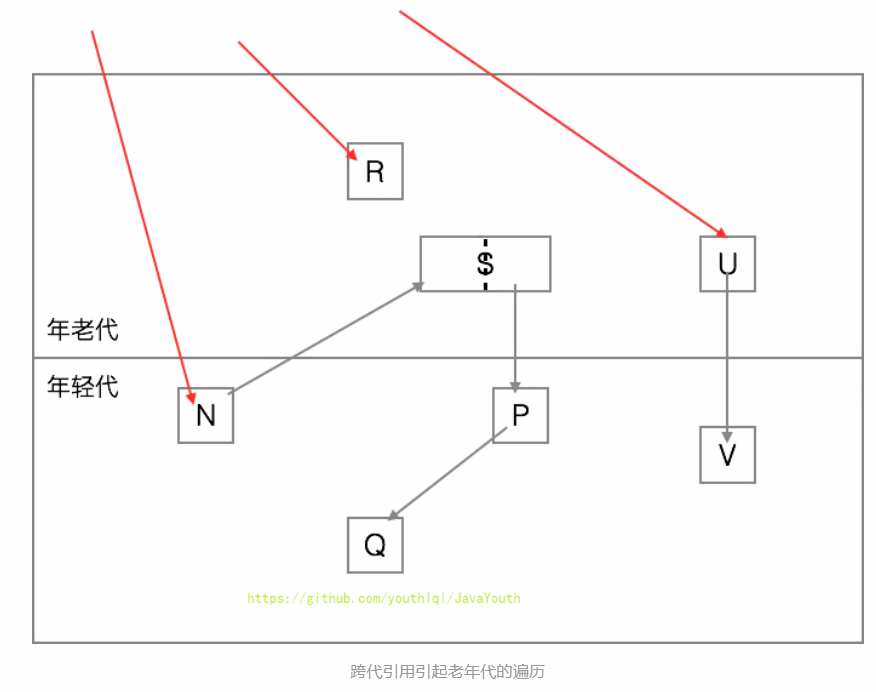 2、如果我们从年轻代开始遍历,那么可以断定N, S, P, Q都是存活对象。但是,V却不会被认为是存活对象,其占据的内存会被回收了。这就是一个惊天的大漏洞!因为U本身是老年代对象,而且有外部引用指向它,也就是说U是存活对象,而U指向了V,也就是说V也应该是存活对象才是!而这都是因为我们只遍历年轻代对象!
@@ -599,7 +599,7 @@ Process finished with exit code -1
4. 这4种引用强度依次逐渐减弱。除强引用外,其他3种引用均可以在java.lang.ref包中找到它们的身影。如下图,显示了这3种引用类型对应的类,开发人员可以在应用程序中直接使用它们。
-
2、如果我们从年轻代开始遍历,那么可以断定N, S, P, Q都是存活对象。但是,V却不会被认为是存活对象,其占据的内存会被回收了。这就是一个惊天的大漏洞!因为U本身是老年代对象,而且有外部引用指向它,也就是说U是存活对象,而U指向了V,也就是说V也应该是存活对象才是!而这都是因为我们只遍历年轻代对象!
@@ -599,7 +599,7 @@ Process finished with exit code -1
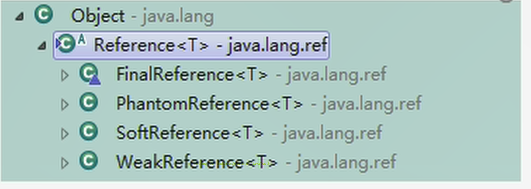
4. 这4种引用强度依次逐渐减弱。除强引用外,其他3种引用均可以在java.lang.ref包中找到它们的身影。如下图,显示了这3种引用类型对应的类,开发人员可以在应用程序中直接使用它们。
- +
+ @@ -661,7 +661,7 @@ Hello,尚硅谷
`StringBuffer str = new StringBuffer("hello,尚硅谷");`
-
@@ -661,7 +661,7 @@ Hello,尚硅谷
`StringBuffer str = new StringBuffer("hello,尚硅谷");`
- +
+ diff --git a/docs/JVM/JVM系列-第12章-垃圾回收器.md b/docs/JVM/JVM系列-第12章-垃圾回收器.md
index e170a4e..246315f 100644
--- a/docs/JVM/JVM系列-第12章-垃圾回收器.md
+++ b/docs/JVM/JVM系列-第12章-垃圾回收器.md
@@ -44,7 +44,7 @@ GC 分类与性能指标
**按线程数分(垃圾回收线程数),可以分为串行垃圾回收器和并行垃圾回收器。**
-
diff --git a/docs/JVM/JVM系列-第12章-垃圾回收器.md b/docs/JVM/JVM系列-第12章-垃圾回收器.md
index e170a4e..246315f 100644
--- a/docs/JVM/JVM系列-第12章-垃圾回收器.md
+++ b/docs/JVM/JVM系列-第12章-垃圾回收器.md
@@ -44,7 +44,7 @@ GC 分类与性能指标
**按线程数分(垃圾回收线程数),可以分为串行垃圾回收器和并行垃圾回收器。**
- +
+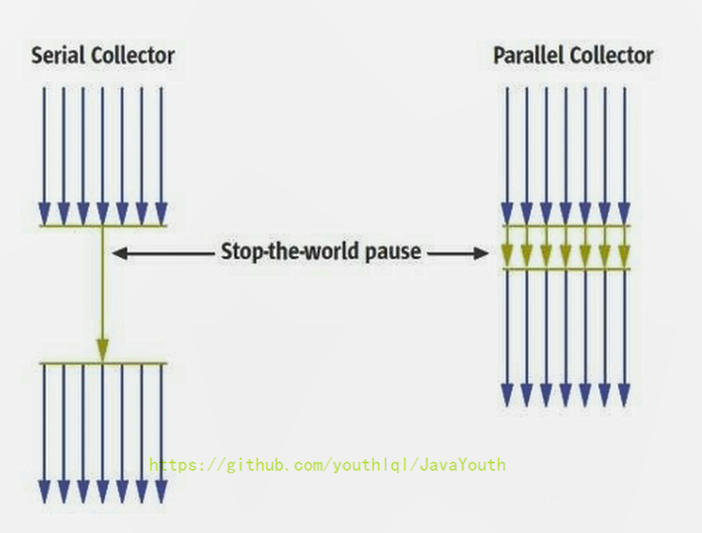 1. 串行回收指的是在同一时间段内只允许有一个CPU用于执行垃圾回收操作,此时工作线程被暂停,直至垃圾收集工作结束。
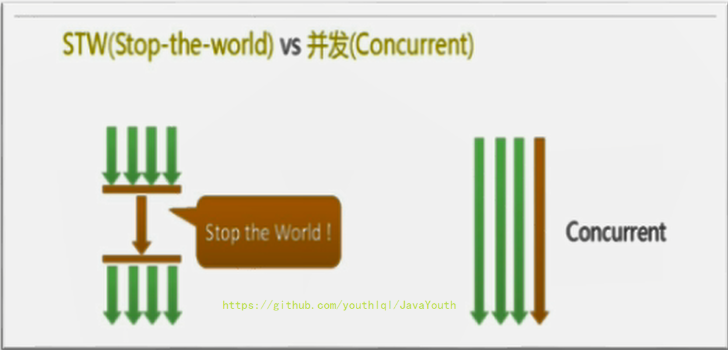
1. 在诸如单CPU处理器或者较小的应用内存等硬件平台不是特别优越的场合,串行回收器的性能表现可以超过并行回收器和并发回收器。所以,串行回收默认被应用在客户端的Client模式下的JVM中
@@ -60,7 +60,7 @@ GC 分类与性能指标
1. 并发式垃圾回收器与应用程序线程交替工作,以尽可能减少应用程序的停顿时间。
2. 独占式垃圾回收器(Stop the World)一旦运行,就停止应用程序中的所有用户线程,直到垃圾回收过程完全结束。
-
1. 串行回收指的是在同一时间段内只允许有一个CPU用于执行垃圾回收操作,此时工作线程被暂停,直至垃圾收集工作结束。
1. 在诸如单CPU处理器或者较小的应用内存等硬件平台不是特别优越的场合,串行回收器的性能表现可以超过并行回收器和并发回收器。所以,串行回收默认被应用在客户端的Client模式下的JVM中
@@ -60,7 +60,7 @@ GC 分类与性能指标
1. 并发式垃圾回收器与应用程序线程交替工作,以尽可能减少应用程序的停顿时间。
2. 独占式垃圾回收器(Stop the World)一旦运行,就停止应用程序中的所有用户线程,直到垃圾回收过程完全结束。
- +
+ @@ -105,7 +105,7 @@ GC 分类与性能指标
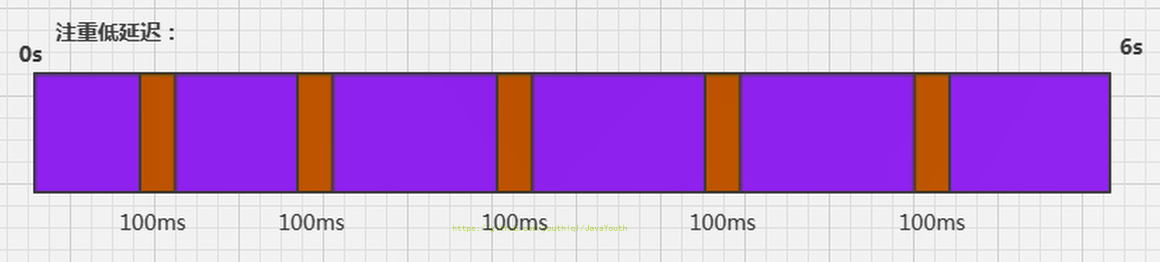
2. 这种情况下,应用程序能容忍较高的暂停时间,因此,高吞吐量的应用程序有更长的时间基准,快速响应是不必考虑的
3. 吞吐量优先,意味着在单位时间内,STW的时间最短:0.2+0.2=0.4
-
@@ -105,7 +105,7 @@ GC 分类与性能指标
2. 这种情况下,应用程序能容忍较高的暂停时间,因此,高吞吐量的应用程序有更长的时间基准,快速响应是不必考虑的
3. 吞吐量优先,意味着在单位时间内,STW的时间最短:0.2+0.2=0.4
- +
+ @@ -115,7 +115,7 @@ GC 分类与性能指标
- 例如,GC期间100毫秒的暂停时间意味着在这100毫秒期间内没有应用程序线程是活动的
2. 暂停时间优先,意味着尽可能让单次STW的时间最短:0.1+0.1 + 0.1+ 0.1+ 0.1=0.5,但是总的GC时间可能会长
-
@@ -115,7 +115,7 @@ GC 分类与性能指标
- 例如,GC期间100毫秒的暂停时间意味着在这100毫秒期间内没有应用程序线程是活动的
2. 暂停时间优先,意味着尽可能让单次STW的时间最短:0.1+0.1 + 0.1+ 0.1+ 0.1=0.5,但是总的GC时间可能会长
- +
+ @@ -169,17 +169,17 @@ GC 分类与性能指标
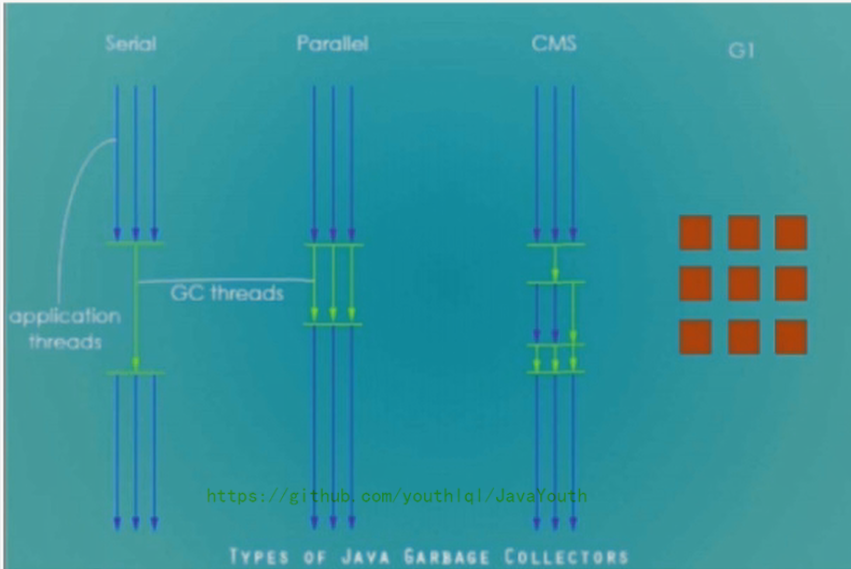
2. 并行回收器:ParNew、Parallel Scavenge、Parallel old
3. 并发回收器:CMS、G1
-
@@ -169,17 +169,17 @@ GC 分类与性能指标
2. 并行回收器:ParNew、Parallel Scavenge、Parallel old
3. 并发回收器:CMS、G1
- +
+ **官方文档**
-
**官方文档**
- +
+ **7款经典回收器与垃圾分代之间的关系**
-
**7款经典回收器与垃圾分代之间的关系**
- +
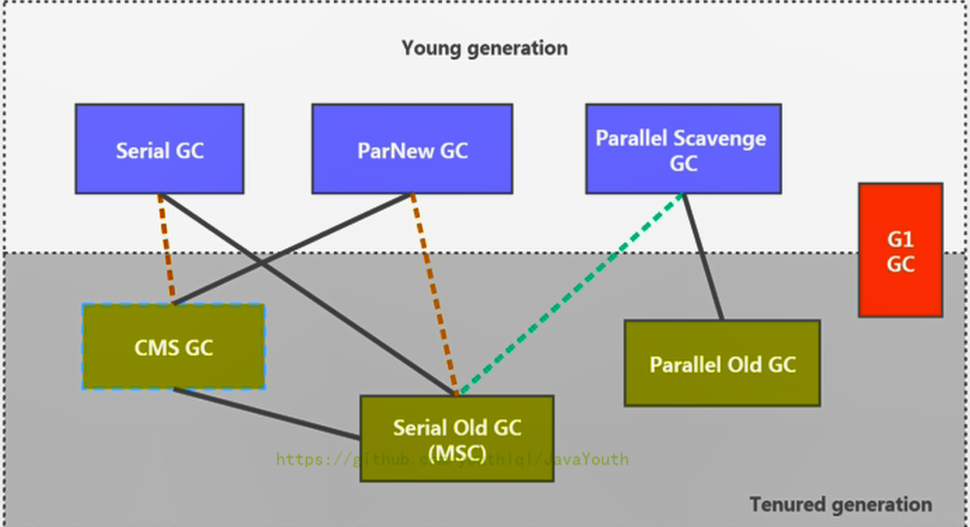
+ 1. 新生代收集器:Serial、ParNew、Parallel Scavenge;
@@ -192,7 +192,7 @@ GC 分类与性能指标
### 垃圾收集器的组合关系
-
1. 新生代收集器:Serial、ParNew、Parallel Scavenge;
@@ -192,7 +192,7 @@ GC 分类与性能指标
### 垃圾收集器的组合关系
- +
+ @@ -251,11 +251,11 @@ jinfo -flag UseParallelOldGC 进程id
JDK 8 中默认使用 ParallelGC 和 ParallelOldGC 的组合
-
@@ -251,11 +251,11 @@ jinfo -flag UseParallelOldGC 进程id
JDK 8 中默认使用 ParallelGC 和 ParallelOldGC 的组合
- +
+ #### JDK9
-
#### JDK9
- +
+ @@ -281,7 +281,7 @@ Serial 回收器:串行回收
这个收集器是一个单线程的收集器,“单线程”的意义:它只会使用一个CPU(串行)或一条收集线程去完成垃圾收集工作。更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束(Stop The World)
-
@@ -281,7 +281,7 @@ Serial 回收器:串行回收
这个收集器是一个单线程的收集器,“单线程”的意义:它只会使用一个CPU(串行)或一条收集线程去完成垃圾收集工作。更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束(Stop The World)
- +
+ @@ -313,7 +313,7 @@ ParNew 回收器:并行回收
2. ParNew 收集器除了采用**并行回收**的方式执行内存回收外,两款垃圾收集器之间几乎没有任何区别。ParNew收集器在年轻代中同样也是采用复制算法、"Stop-the-World"机制。
3. ParNew 是很多JVM运行在Server模式下新生代的默认垃圾收集器。
-
@@ -313,7 +313,7 @@ ParNew 回收器:并行回收
2. ParNew 收集器除了采用**并行回收**的方式执行内存回收外,两款垃圾收集器之间几乎没有任何区别。ParNew收集器在年轻代中同样也是采用复制算法、"Stop-the-World"机制。
3. ParNew 是很多JVM运行在Server模式下新生代的默认垃圾收集器。
- +
+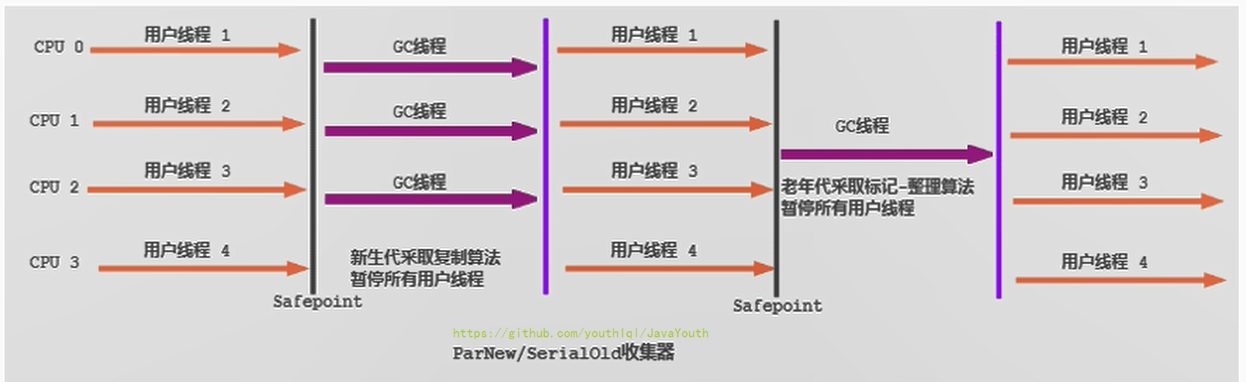 1. 对于新生代,回收次数频繁,使用并行方式高效。
2. 对于老年代,回收次数少,使用串行方式节省资源。(CPU并行需要切换线程,串行可以省去切换线程的资源)
@@ -361,7 +361,7 @@ Parallel 回收器:吞吐量优先
5. Parallel Old收集器采用了标记-压缩算法,但同样也是基于并行回收和"Stop-the-World"机制。
-
1. 对于新生代,回收次数频繁,使用并行方式高效。
2. 对于老年代,回收次数少,使用串行方式节省资源。(CPU并行需要切换线程,串行可以省去切换线程的资源)
@@ -361,7 +361,7 @@ Parallel 回收器:吞吐量优先
5. Parallel Old收集器采用了标记-压缩算法,但同样也是基于并行回收和"Stop-the-World"机制。
- +
+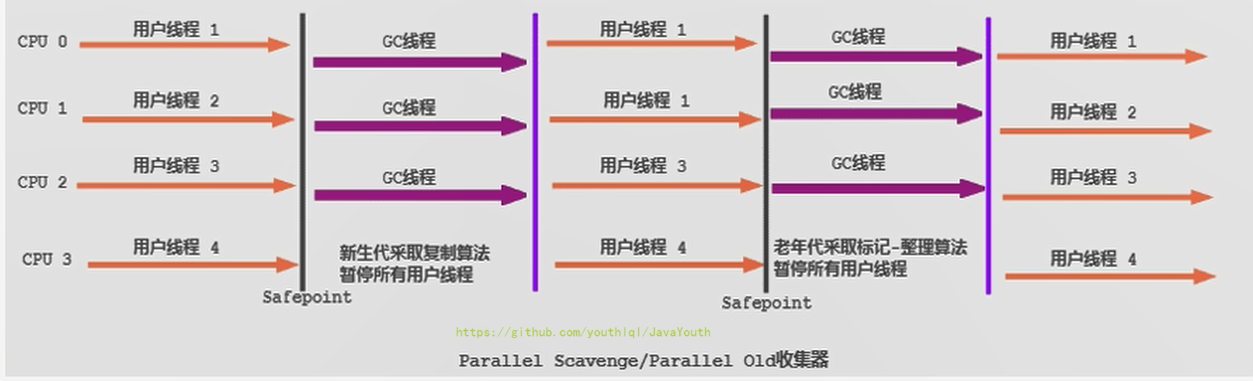 1. 在程序吞吐量优先的应用场景中,Parallel收集器和Parallel Old收集器的组合,在server模式下的内存回收性能很不错。
2. **在Java8中,默认是此垃圾收集器。**
@@ -418,7 +418,7 @@ CMS 回收器:低延迟
### CMS 工作原理(过程)
-
1. 在程序吞吐量优先的应用场景中,Parallel收集器和Parallel Old收集器的组合,在server模式下的内存回收性能很不错。
2. **在Java8中,默认是此垃圾收集器。**
@@ -418,7 +418,7 @@ CMS 回收器:低延迟
### CMS 工作原理(过程)
- +
+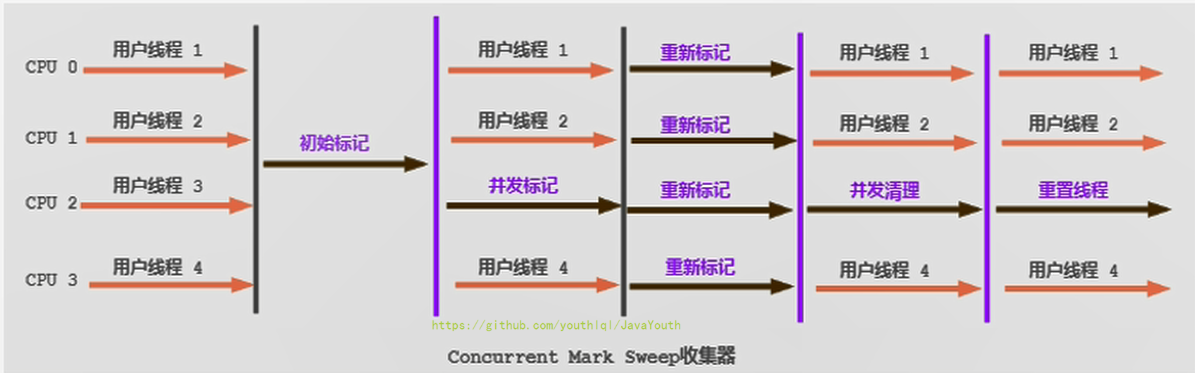 CMS整个过程比之前的收集器要复杂,整个过程分为4个主要阶段,即初始标记阶段、并发标记阶段、重新标记阶段和并发清除阶段。(涉及STW的阶段主要是:初始标记 和 重新标记)
@@ -438,7 +438,7 @@ CMS整个过程比之前的收集器要复杂,整个过程分为4个主要阶
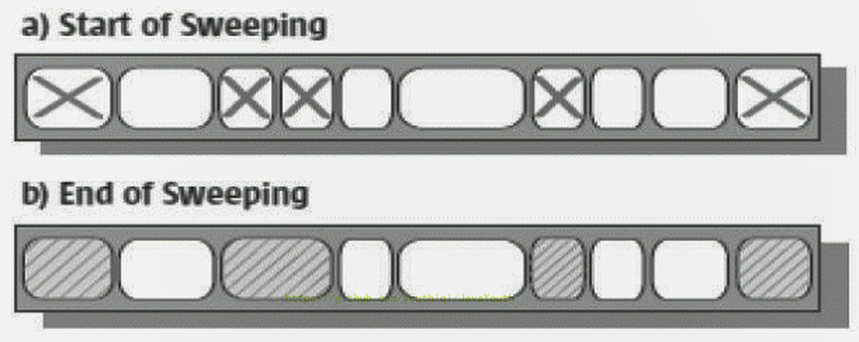
3. 另外,由于在垃圾收集阶段用户线程没有中断,所以在CMS回收过程中,还应该确保应用程序用户线程有足够的内存可用。因此,CMS收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,**而是当堆内存使用率达到某一阈值时,便开始进行回收**,以确保应用程序在CMS工作过程中依然有足够的空间支持应用程序运行。要是CMS运行期间预留的内存无法满足程序需要,就会出现一次**“Concurrent Mode Failure”** 失败,这时虚拟机将启动后备预案:临时启用Serial old收集器来重新进行老年代的垃圾收集,这样停顿时间就很长了。
4. CMS收集器的垃圾收集算法采用的是**标记清除算法**,这意味着每次执行完内存回收后,由于被执行内存回收的无用对象所占用的内存空间极有可能是不连续的一些内存块,**不可避免地将会产生一些内存碎片**。那么CMS在为新对象分配内存空间时,将无法使用指针碰撞(Bump the Pointer)技术,而只能够选择空闲列表(Free List)执行内存分配。
-
CMS整个过程比之前的收集器要复杂,整个过程分为4个主要阶段,即初始标记阶段、并发标记阶段、重新标记阶段和并发清除阶段。(涉及STW的阶段主要是:初始标记 和 重新标记)
@@ -438,7 +438,7 @@ CMS整个过程比之前的收集器要复杂,整个过程分为4个主要阶
3. 另外,由于在垃圾收集阶段用户线程没有中断,所以在CMS回收过程中,还应该确保应用程序用户线程有足够的内存可用。因此,CMS收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,**而是当堆内存使用率达到某一阈值时,便开始进行回收**,以确保应用程序在CMS工作过程中依然有足够的空间支持应用程序运行。要是CMS运行期间预留的内存无法满足程序需要,就会出现一次**“Concurrent Mode Failure”** 失败,这时虚拟机将启动后备预案:临时启用Serial old收集器来重新进行老年代的垃圾收集,这样停顿时间就很长了。
4. CMS收集器的垃圾收集算法采用的是**标记清除算法**,这意味着每次执行完内存回收后,由于被执行内存回收的无用对象所占用的内存空间极有可能是不连续的一些内存块,**不可避免地将会产生一些内存碎片**。那么CMS在为新对象分配内存空间时,将无法使用指针碰撞(Bump the Pointer)技术,而只能够选择空闲列表(Free List)执行内存分配。
- +
+ @@ -558,11 +558,11 @@ G1 回收器:区域化分代式
G1的分代,已经不是下面这样的了
-
@@ -558,11 +558,11 @@ G1 回收器:区域化分代式
G1的分代,已经不是下面这样的了
- +
+ G1的分区是这样的一个区域
-
G1的分区是这样的一个区域
- +
+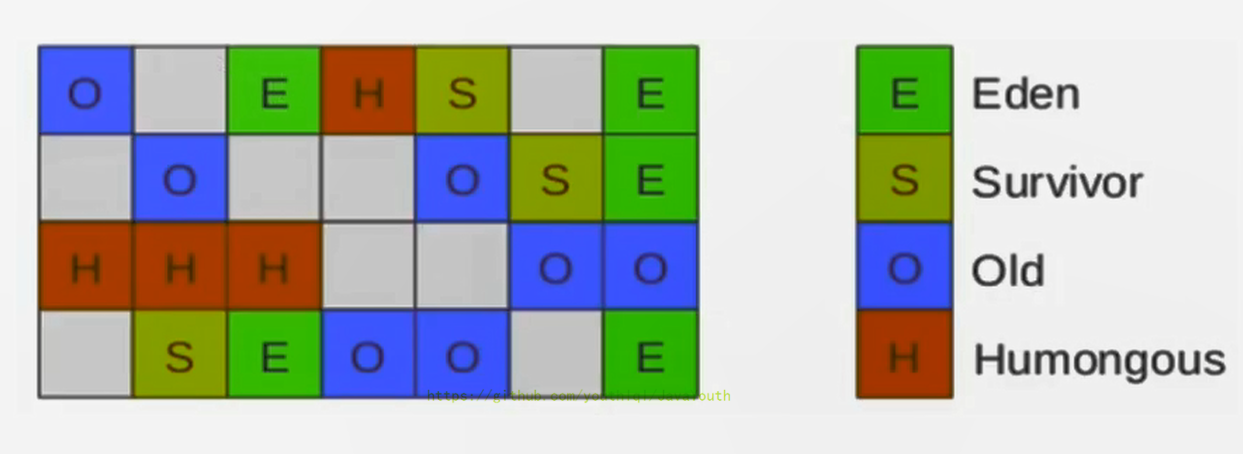 **空间整合**
@@ -655,7 +655,7 @@ G1中提供了三种垃圾回收模式:YoungGC、Mixed GC和Full GC,在不
>
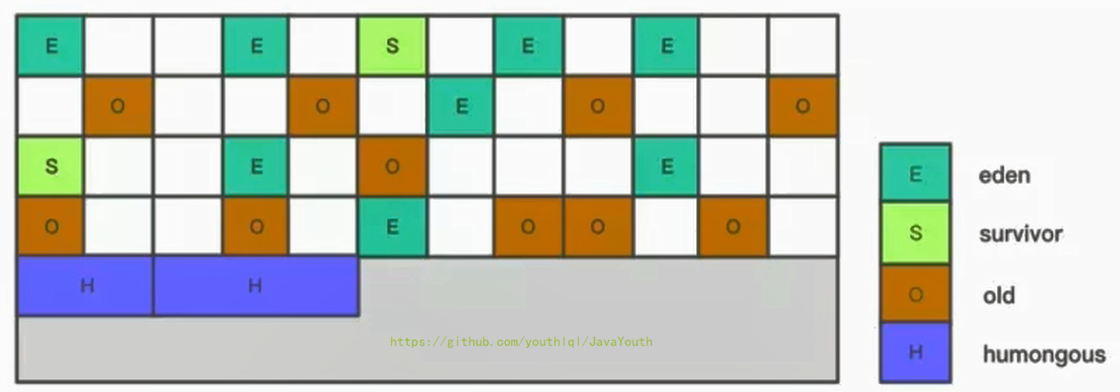
> 如图所示,可以将区域分配到Eden,幸存者和旧时代区域。 此外,还有第四种类型的物体被称为巨大区域。 这些区域旨在容纳标准区域大小的50%或更大的对象。 它们存储为一组连续区域。 最后,最后一种区域类型是堆的未使用区域。
-
**空间整合**
@@ -655,7 +655,7 @@ G1中提供了三种垃圾回收模式:YoungGC、Mixed GC和Full GC,在不
>
> 如图所示,可以将区域分配到Eden,幸存者和旧时代区域。 此外,还有第四种类型的物体被称为巨大区域。 这些区域旨在容纳标准区域大小的50%或更大的对象。 它们存储为一组连续区域。 最后,最后一种区域类型是堆的未使用区域。
- +
+ @@ -667,7 +667,7 @@ G1中提供了三种垃圾回收模式:YoungGC、Mixed GC和Full GC,在不
**Regio的细节**
-
@@ -667,7 +667,7 @@ G1中提供了三种垃圾回收模式:YoungGC、Mixed GC和Full GC,在不
**Regio的细节**
- +
+ 1. 每个Region都是通过指针碰撞来分配空间
2. G1为每一个Region设 计了两个名为TAMS(Top at Mark Start)的指针,把Region中的一部分空间划分出来用于并发回收过程中的新对象分配,并发回收时新分配的对象地址都必须要在这两个指针位置以上。
@@ -686,7 +686,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
* 混合回收(Mixed GC)
* (如果需要,单线程、独占式、高强度的Full GC还是继续存在的。它针对GC的评估失败提供了一种失败保护机制,即强力回收。)
-
1. 每个Region都是通过指针碰撞来分配空间
2. G1为每一个Region设 计了两个名为TAMS(Top at Mark Start)的指针,把Region中的一部分空间划分出来用于并发回收过程中的新对象分配,并发回收时新分配的对象地址都必须要在这两个指针位置以上。
@@ -686,7 +686,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
* 混合回收(Mixed GC)
* (如果需要,单线程、独占式、高强度的Full GC还是继续存在的。它针对GC的评估失败提供了一种失败保护机制,即强力回收。)
- +
+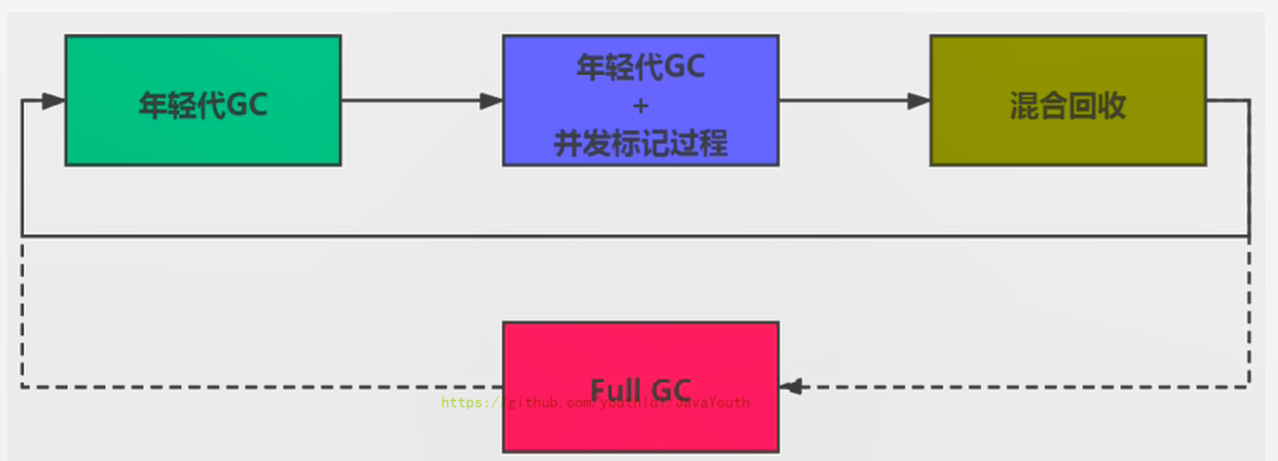 顺时针,Young GC --> Young GC+Concurrent Marking --> Mixed GC顺序,进行垃圾回收
@@ -731,7 +731,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
-
顺时针,Young GC --> Young GC+Concurrent Marking --> Mixed GC顺序,进行垃圾回收
@@ -731,7 +731,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
- +
+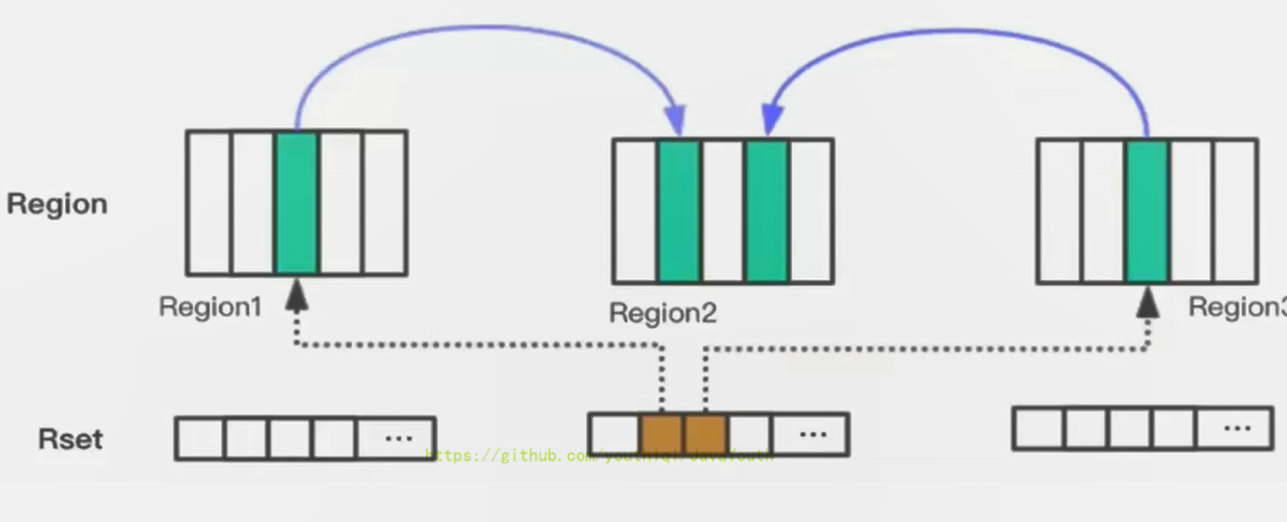 1. 在回收 Region 时,为了不进行全堆的扫描,引入了 Remembered Set
2. Remembered Set 记录了当前 Region 中的对象被哪个对象引用了
@@ -748,7 +748,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
2. 年轻代回收只回收Eden区和Survivor区
3. YGC时,首先G1停止应用程序的执行(Stop-The-World),G1创建回收集(Collection Set),回收集是指需要被回收的内存分段的集合,年轻代回收过程的回收集包含年轻代Eden区和Survivor区所有的内存分段。
-
1. 在回收 Region 时,为了不进行全堆的扫描,引入了 Remembered Set
2. Remembered Set 记录了当前 Region 中的对象被哪个对象引用了
@@ -748,7 +748,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
2. 年轻代回收只回收Eden区和Survivor区
3. YGC时,首先G1停止应用程序的执行(Stop-The-World),G1创建回收集(Collection Set),回收集是指需要被回收的内存分段的集合,年轻代回收过程的回收集包含年轻代Eden区和Survivor区所有的内存分段。
- +
+ 图的大致意思就是:
@@ -804,7 +804,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
当越来越多的对象晋升到老年代Old Region时,为了避免堆内存被耗尽,虚拟机会触发一个混合的垃圾收集器,即Mixed GC,该算法并不是一个Old GC,除了回收整个Young Region,还会回收一部分的Old Region。这里需要注意:是一部分老年代,而不是全部老年代。可以选择哪些Old Region进行收集,从而可以对垃圾回收的耗时时间进行控制。也要注意的是Mixed GC并不是Full GC。
-
图的大致意思就是:
@@ -804,7 +804,7 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
当越来越多的对象晋升到老年代Old Region时,为了避免堆内存被耗尽,虚拟机会触发一个混合的垃圾收集器,即Mixed GC,该算法并不是一个Old GC,除了回收整个Young Region,还会回收一部分的Old Region。这里需要注意:是一部分老年代,而不是全部老年代。可以选择哪些Old Region进行收集,从而可以对垃圾回收的耗时时间进行控制。也要注意的是Mixed GC并不是Full GC。
- +
+ @@ -854,11 +854,11 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
截止JDK1.8,一共有7款不同的垃圾收集器。每一款的垃圾收集器都有不同的特点,在具体使用的时候,需要根据具体的情况选用不同的垃圾收集器。
-
@@ -854,11 +854,11 @@ G1 GC的垃圾回收过程主要包括如下三个环节:
截止JDK1.8,一共有7款不同的垃圾收集器。每一款的垃圾收集器都有不同的特点,在具体使用的时候,需要根据具体的情况选用不同的垃圾收集器。
- +
+ -
- +
+ @@ -922,11 +922,11 @@ GC 日志分析
2、这个只会显示总的GC堆的变化,如下:
-
@@ -922,11 +922,11 @@ GC 日志分析
2、这个只会显示总的GC堆的变化,如下:
- +
+ 3、参数解析
-
3、参数解析
- +
+ @@ -938,11 +938,11 @@ GC 日志分析
2、输入信息如下
-
@@ -938,11 +938,11 @@ GC 日志分析
2、输入信息如下
- +
+ 3、参数解析
-
3、参数解析
- +
+ @@ -954,7 +954,7 @@ GC 日志分析
2、输出信息如下
-
@@ -954,7 +954,7 @@ GC 日志分析
2、输出信息如下
- +
+ 3、说明:日志带上了日期和时间
@@ -989,13 +989,13 @@ GC 日志分析
#### Young GC
-
3、说明:日志带上了日期和时间
@@ -989,13 +989,13 @@ GC 日志分析
#### Young GC
- +
+ #### Full GC
-
#### Full GC
- +
+ @@ -1029,11 +1029,11 @@ public class GCLogTest1 {
1、首先我们会将3个2M的数组存放到Eden区,然后后面4M的数组来了后,将无法存储,因为Eden区只剩下2M的剩余空间了,那么将会进行一次Young GC操作,将原来Eden区的内容,存放到Survivor区,但是Survivor区也存放不下,那么就会直接晋级存入Old 区
-
@@ -1029,11 +1029,11 @@ public class GCLogTest1 {
1、首先我们会将3个2M的数组存放到Eden区,然后后面4M的数组来了后,将无法存储,因为Eden区只剩下2M的剩余空间了,那么将会进行一次Young GC操作,将原来Eden区的内容,存放到Survivor区,但是Survivor区也存放不下,那么就会直接晋级存入Old 区
- +
+ 2、然后我们将4M对象存入到Eden区中
-
2、然后我们将4M对象存入到Eden区中
- +
+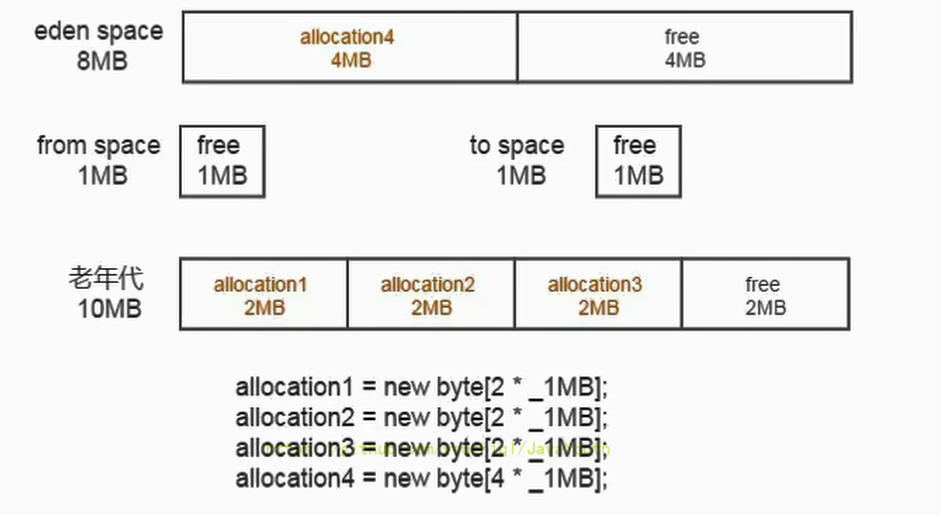 老年代图画的有问题,free应该是4M
@@ -1056,7 +1056,7 @@ Process finished with exit code 0
```
-
老年代图画的有问题,free应该是4M
@@ -1056,7 +1056,7 @@ Process finished with exit code 0
```
- +
+ 与 JDK7 不同的是,JDK8 直接判定 4M 的数组为大对象,直接怼到老年区去了
@@ -1082,15 +1082,15 @@ GCViewer、GCEasy、GCHisto、GCLogViewer、Hpjmeter、garbagecat等
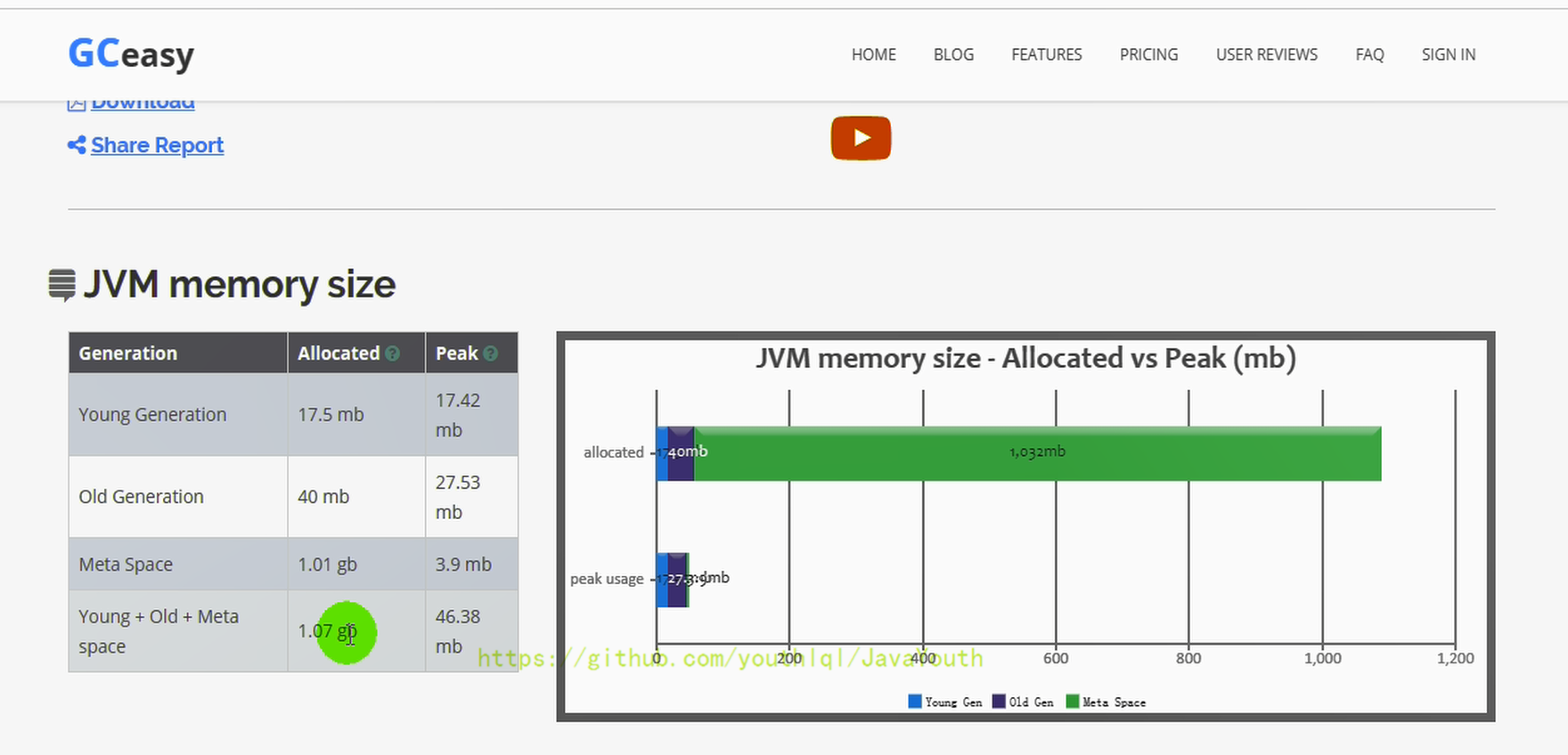
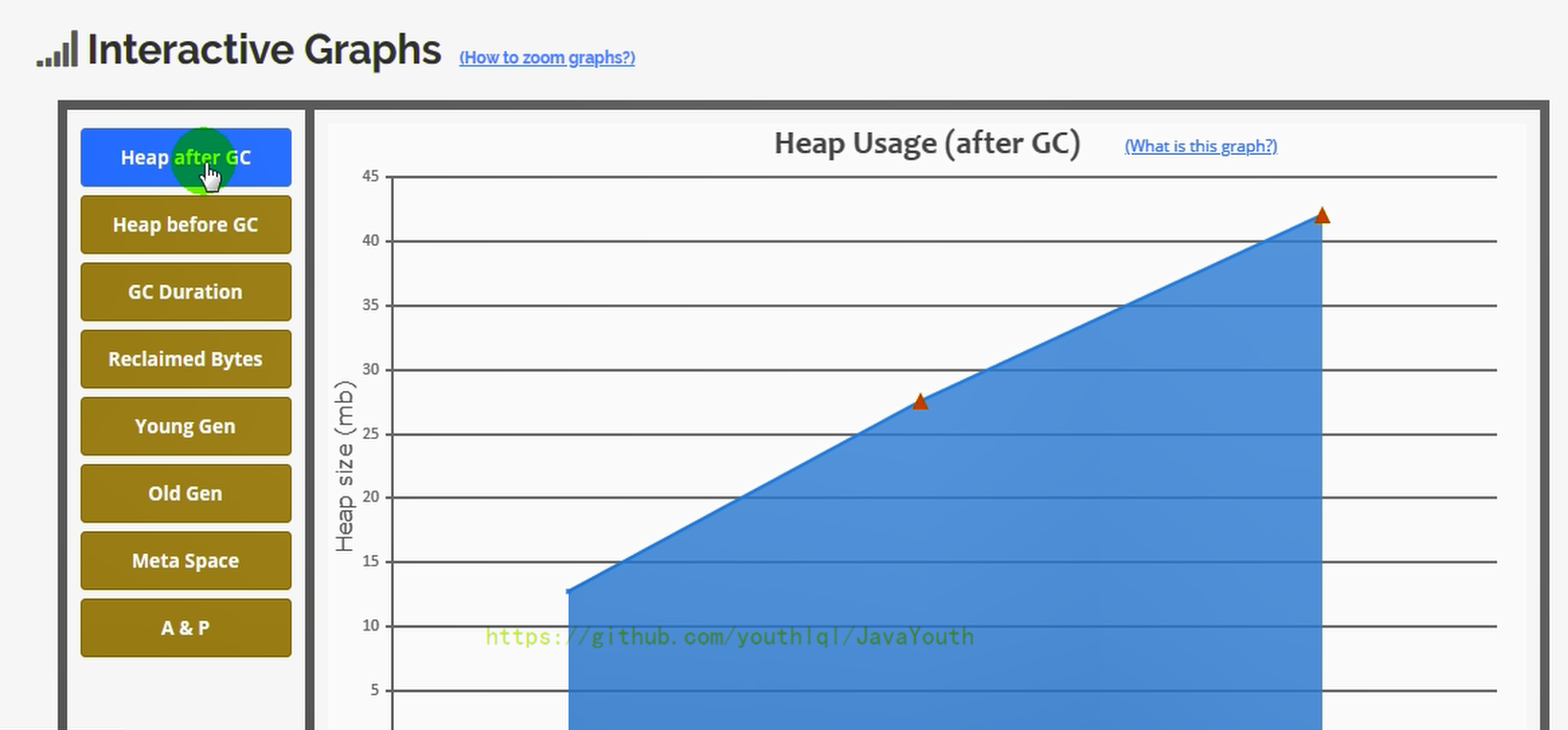
在线分析网址:gceasy.io
-
与 JDK7 不同的是,JDK8 直接判定 4M 的数组为大对象,直接怼到老年区去了
@@ -1082,15 +1082,15 @@ GCViewer、GCEasy、GCHisto、GCLogViewer、Hpjmeter、garbagecat等
在线分析网址:gceasy.io
- +
+ -
- +
+ -
- +
+ @@ -1126,7 +1126,7 @@ GCViewer、GCEasy、GCHisto、GCLogViewer、Hpjmeter、garbagecat等
1. 停顿时间比其他几款收集器确实有了质的飞跃,但也未实现最大停顿时间控制在十毫秒以内的目标。
2. 而吞吐量方面出现了明显的下降,总运行时间是所有测试收集器里最长的。
-
@@ -1126,7 +1126,7 @@ GCViewer、GCEasy、GCHisto、GCLogViewer、Hpjmeter、garbagecat等
1. 停顿时间比其他几款收集器确实有了质的飞跃,但也未实现最大停顿时间控制在十毫秒以内的目标。
2. 而吞吐量方面出现了明显的下降,总运行时间是所有测试收集器里最长的。
- +
+ @@ -1156,7 +1156,7 @@ GCViewer、GCEasy、GCHisto、GCLogViewer、Hpjmeter、garbagecat等
**吞吐量**
-
@@ -1156,7 +1156,7 @@ GCViewer、GCEasy、GCHisto、GCLogViewer、Hpjmeter、garbagecat等
**吞吐量**
- +
+ max-JOPS:以低延迟为首要前提下的数据
@@ -1166,13 +1166,13 @@ critical-JOPS:不考虑低延迟下的数据
**低延迟**
-
max-JOPS:以低延迟为首要前提下的数据
@@ -1166,13 +1166,13 @@ critical-JOPS:不考虑低延迟下的数据
**低延迟**
- +
+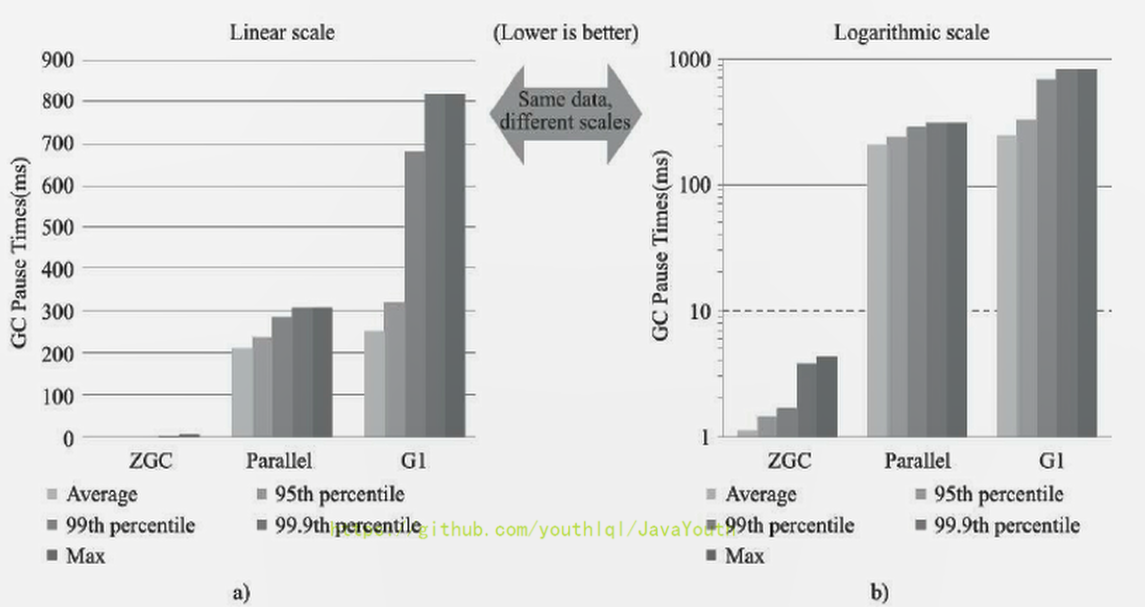 在ZGC的强项停顿时间测试上,它毫不留情的将Parallel、G1拉开了两个数量级的差距。无论平均停顿、95%停顿、998停顿、99. 98停顿,还是最大停顿时间,ZGC都能毫不费劲控制在10毫秒以内。
虽然ZGC还在试验状态,没有完成所有特性,但此时性能已经相当亮眼,用“令人震惊、革命性”来形容,不为过。未来将在服务端、大内存、低延迟应用的首选垃圾收集器。
-
在ZGC的强项停顿时间测试上,它毫不留情的将Parallel、G1拉开了两个数量级的差距。无论平均停顿、95%停顿、998停顿、99. 98停顿,还是最大停顿时间,ZGC都能毫不费劲控制在10毫秒以内。
虽然ZGC还在试验状态,没有完成所有特性,但此时性能已经相当亮眼,用“令人震惊、革命性”来形容,不为过。未来将在服务端、大内存、低延迟应用的首选垃圾收集器。
- +
+ @@ -1192,4 +1192,4 @@ critical-JOPS:不考虑低延迟下的数据
AliGC是阿里巴巴JVM团队基于G1算法,面向大堆(LargeHeap)应用场景。指定场景下的对比:
-
@@ -1192,4 +1192,4 @@ critical-JOPS:不考虑低延迟下的数据
AliGC是阿里巴巴JVM团队基于G1算法,面向大堆(LargeHeap)应用场景。指定场景下的对比:
- \ No newline at end of file
+
\ No newline at end of file
+ \ No newline at end of file
diff --git a/docs/JVM/JVM系列-第1章-JVM与Java体系结构.md b/docs/JVM/JVM系列-第1章-JVM与Java体系结构.md
index 34d3b67..862fc5e 100644
--- a/docs/JVM/JVM系列-第1章-JVM与Java体系结构.md
+++ b/docs/JVM/JVM系列-第1章-JVM与Java体系结构.md
@@ -38,7 +38,7 @@ date: 2020-11-02 11:51:56
3. 新项目上线,对各种JVM参数设置一脸茫然,直接默认吧然后就JJ了。
4. 每次面试之前都要重新背一遍JVM的一些原理概念性的东西,然而面试官却经常问你在实际项目中如何调优VM参数,如何解决GC、OOM等问题,一脸懵逼。
-
\ No newline at end of file
diff --git a/docs/JVM/JVM系列-第1章-JVM与Java体系结构.md b/docs/JVM/JVM系列-第1章-JVM与Java体系结构.md
index 34d3b67..862fc5e 100644
--- a/docs/JVM/JVM系列-第1章-JVM与Java体系结构.md
+++ b/docs/JVM/JVM系列-第1章-JVM与Java体系结构.md
@@ -38,7 +38,7 @@ date: 2020-11-02 11:51:56
3. 新项目上线,对各种JVM参数设置一脸茫然,直接默认吧然后就JJ了。
4. 每次面试之前都要重新背一遍JVM的一些原理概念性的东西,然而面试官却经常问你在实际项目中如何调优VM参数,如何解决GC、OOM等问题,一脸懵逼。
- +
+ 大部分Java开发人员,除了会在项目中使用到与Java平台相关的各种高精尖技术,对于Java技术的核心Java虚拟机了解甚少。
@@ -50,7 +50,7 @@ date: 2020-11-02 11:51:56
1. 一些有一定工作经验的开发人员,打心眼儿里觉得SSM、微服务等上层技术才是重点,基础技术并不重要,这其实是一种本末倒置的“病态”。
2. 如果我们把核心类库的API比做数学公式的话,那么Java虚拟机的知识就好比公式的推导过程。
-
大部分Java开发人员,除了会在项目中使用到与Java平台相关的各种高精尖技术,对于Java技术的核心Java虚拟机了解甚少。
@@ -50,7 +50,7 @@ date: 2020-11-02 11:51:56
1. 一些有一定工作经验的开发人员,打心眼儿里觉得SSM、微服务等上层技术才是重点,基础技术并不重要,这其实是一种本末倒置的“病态”。
2. 如果我们把核心类库的API比做数学公式的话,那么Java虚拟机的知识就好比公式的推导过程。
- +
+ - 计算机系统体系对我们来说越来越远,在不了解底层实现方式的前提下,通过高级语言很容易编写程序代码。但事实上计算机并不认识高级语言。
@@ -87,7 +87,7 @@ Java VS C++
1. 垃圾收集机制为我们打理了很多繁琐的工作,大大提高了开发的效率,但是,垃圾收集也不是万能的,懂得JVM内部的内存结构、工作机制,是设计高扩展性应用和诊断运行时问题的基础,也是Java工程师进阶的必备能力。
2. C++语言需要程序员自己来分配内存和回收内存,对于高手来说可能更加舒服,但是对于普通开发者,如果技术实力不够,很容易造成内存泄漏。而Java全部交给JVM进行内存分配和回收,这也是一种趋势,减少程序员的工作量。
-
- 计算机系统体系对我们来说越来越远,在不了解底层实现方式的前提下,通过高级语言很容易编写程序代码。但事实上计算机并不认识高级语言。
@@ -87,7 +87,7 @@ Java VS C++
1. 垃圾收集机制为我们打理了很多繁琐的工作,大大提高了开发的效率,但是,垃圾收集也不是万能的,懂得JVM内部的内存结构、工作机制,是设计高扩展性应用和诊断运行时问题的基础,也是Java工程师进阶的必备能力。
2. C++语言需要程序员自己来分配内存和回收内存,对于高手来说可能更加舒服,但是对于普通开发者,如果技术实力不够,很容易造成内存泄漏。而Java全部交给JVM进行内存分配和回收,这也是一种趋势,减少程序员的工作量。
- +
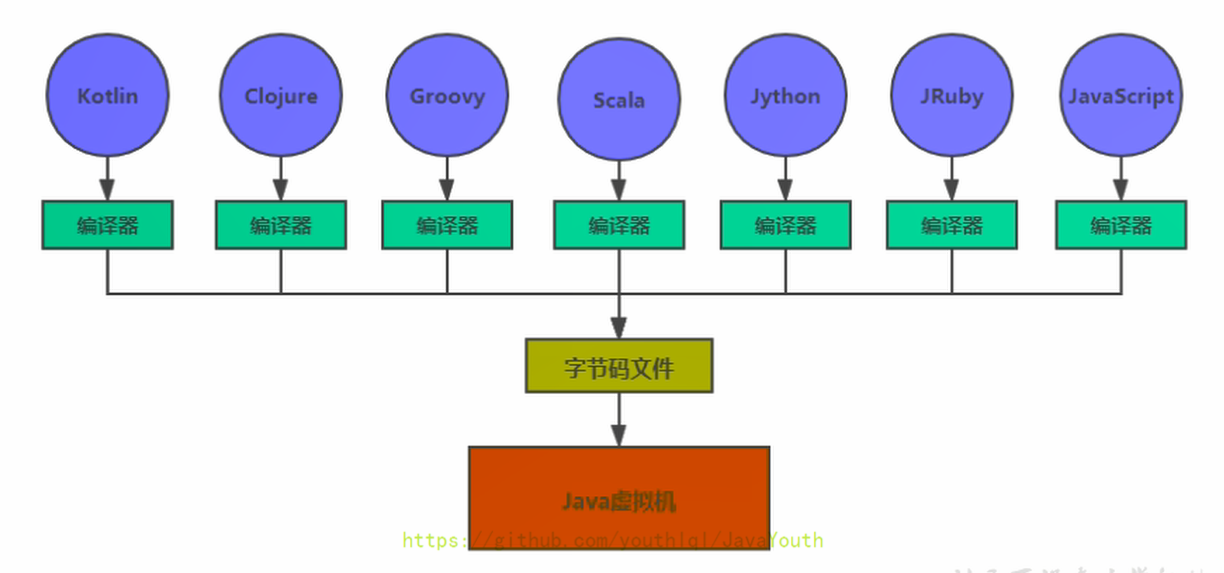
+ ## 什么人需要学JVM?
@@ -103,26 +103,26 @@ Java VS C++
**英文文档规范**:https://docs.oracle.com/javase/specs/index.html
-
## 什么人需要学JVM?
@@ -103,26 +103,26 @@ Java VS C++
**英文文档规范**:https://docs.oracle.com/javase/specs/index.html
- +
+ **中文书籍:**
-
**中文书籍:**
- +
+ > 周志明老师的这本书**非常推荐看**,不过只推荐看第三版,第三版较第二版更新了很多,个人觉得没必要再看第二版。
-
> 周志明老师的这本书**非常推荐看**,不过只推荐看第三版,第三版较第二版更新了很多,个人觉得没必要再看第二版。
- +
+ -
- +
+ TIOBE排行榜
-----------
**TIOBE 排行榜**:https://www.tiobe.com/tiobe-index/
-
TIOBE排行榜
-----------
**TIOBE 排行榜**:https://www.tiobe.com/tiobe-index/
- +
+ - 世界上没有最好的编程语言,只有最适用于具体应用场景的编程语言。
- 目前网上一直流传Java被python,go撼动Java第一的地位。学习者不需要太担心,Java强大的生态圈,也不是说是朝夕之间可以被撼动的。
@@ -148,14 +148,14 @@ Java-跨平台的语言
-
- 世界上没有最好的编程语言,只有最适用于具体应用场景的编程语言。
- 目前网上一直流传Java被python,go撼动Java第一的地位。学习者不需要太担心,Java强大的生态圈,也不是说是朝夕之间可以被撼动的。
@@ -148,14 +148,14 @@ Java-跨平台的语言
- +
+ JVM-跨语言的平台
------
-
JVM-跨语言的平台
------
- +
+ @@ -187,7 +187,7 @@ JVM-跨语言的平台
2. 自己动手写一个Java虚拟机,难吗?
3. 天下事有难易乎?为之,则难者亦易矣;不为,则易者亦难矣
-
@@ -187,7 +187,7 @@ JVM-跨语言的平台
2. 自己动手写一个Java虚拟机,难吗?
3. 天下事有难易乎?为之,则难者亦易矣;不为,则易者亦难矣
- +
+ Java发展重大事件
------------
@@ -215,7 +215,7 @@ Java发展重大事件
## Open JDK和Oracle JDK
-
Java发展重大事件
------------
@@ -215,7 +215,7 @@ Java发展重大事件
## Open JDK和Oracle JDK
- +
+ - 在JDK11之前,Oracle JDK中还会存在一些Open JDK中没有的,闭源的功能。但在JDK11中,我们可以认为Open JDK和Oracle JDK代码实质上已经达到完全一致的程度了。
- 主要的区别就是两者更新周期不一样
@@ -258,11 +258,11 @@ JVM的位置
JVM是运行在操作系统之上的,它与硬件没有直接的交互
-
- 在JDK11之前,Oracle JDK中还会存在一些Open JDK中没有的,闭源的功能。但在JDK11中,我们可以认为Open JDK和Oracle JDK代码实质上已经达到完全一致的程度了。
- 主要的区别就是两者更新周期不一样
@@ -258,11 +258,11 @@ JVM的位置
JVM是运行在操作系统之上的,它与硬件没有直接的交互
- +
+ -
- +
+ @@ -275,7 +275,7 @@ JVM的整体结构
-
@@ -275,7 +275,7 @@ JVM的整体结构
- +
+ @@ -284,7 +284,7 @@ Java代码执行流程
凡是能生成被Java虚拟机所能解释、运行的字节码文件,那么理论上我们就可以自己设计一套语言了
-
@@ -284,7 +284,7 @@ Java代码执行流程
凡是能生成被Java虚拟机所能解释、运行的字节码文件,那么理论上我们就可以自己设计一套语言了
- +
+ diff --git a/docs/JVM/JVM系列-第2章-类加载子系统.md b/docs/JVM/JVM系列-第2章-类加载子系统.md
index ab0f8cd..8de7e2c 100644
--- a/docs/JVM/JVM系列-第2章-类加载子系统.md
+++ b/docs/JVM/JVM系列-第2章-类加载子系统.md
@@ -25,19 +25,19 @@ date: 2020-11-02 21:31:58
### 简图
-
diff --git a/docs/JVM/JVM系列-第2章-类加载子系统.md b/docs/JVM/JVM系列-第2章-类加载子系统.md
index ab0f8cd..8de7e2c 100644
--- a/docs/JVM/JVM系列-第2章-类加载子系统.md
+++ b/docs/JVM/JVM系列-第2章-类加载子系统.md
@@ -25,19 +25,19 @@ date: 2020-11-02 21:31:58
### 简图
- +
+ ### 详细图
英文版
-
### 详细图
英文版
- +
+ 中文版
-
中文版
- +
+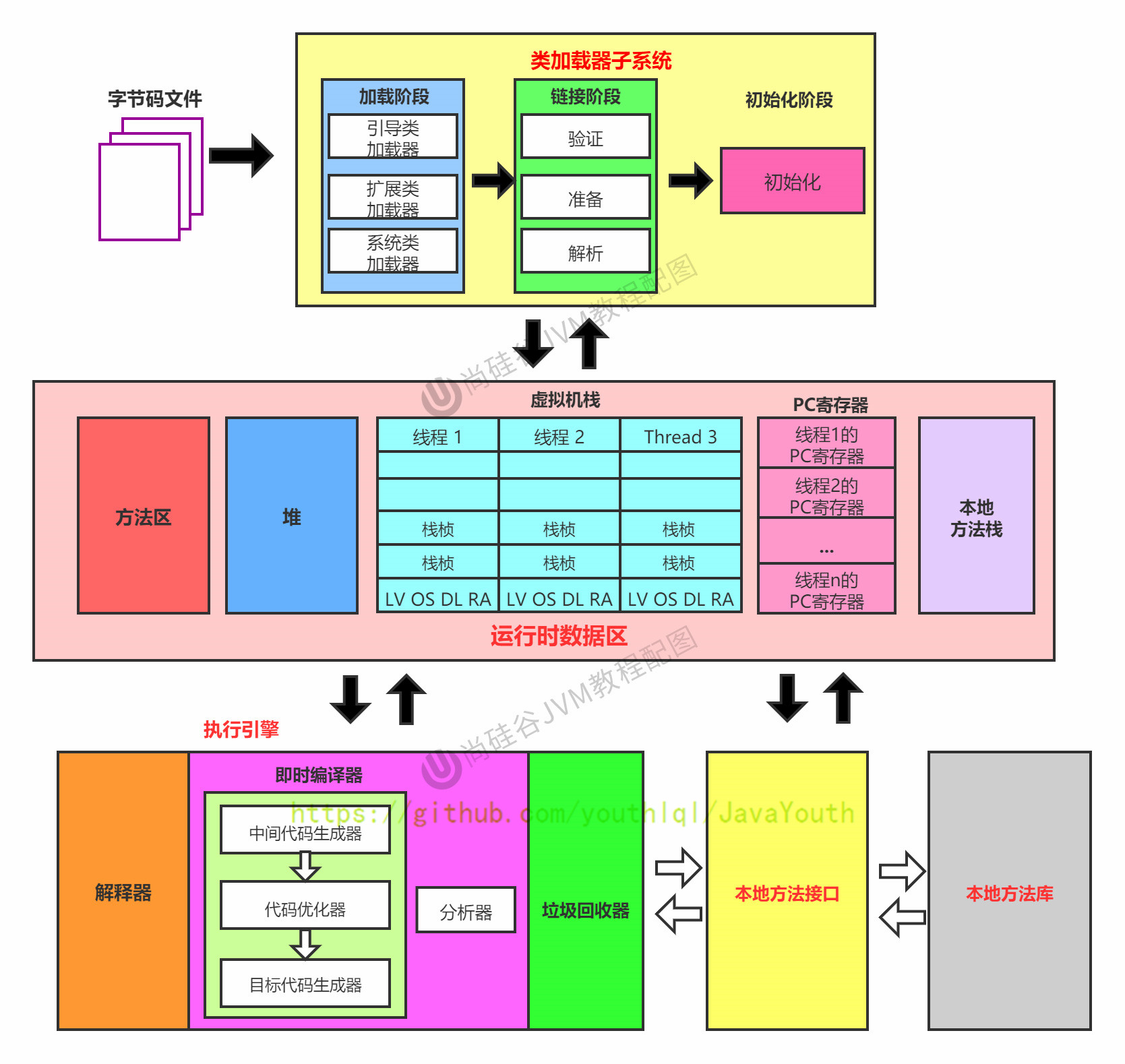 注意:方法区只有HotSpot虚拟机有,J9,JRockit都没有
@@ -59,7 +59,7 @@ date: 2020-11-02 21:31:58
3. **加载的类信息存放于一块称为方法区的内存空间**。除了类的信息外,方法区中还会存放运行时常量池信息,可能还包括字符串字面量和数字常量(这部分常量信息是Class文件中常量池部分的内存映射)
-
注意:方法区只有HotSpot虚拟机有,J9,JRockit都没有
@@ -59,7 +59,7 @@ date: 2020-11-02 21:31:58
3. **加载的类信息存放于一块称为方法区的内存空间**。除了类的信息外,方法区中还会存放运行时常量池信息,可能还包括字符串字面量和数字常量(这部分常量信息是Class文件中常量池部分的内存映射)
- +
+ @@ -71,7 +71,7 @@ date: 2020-11-02 21:31:58
-
@@ -71,7 +71,7 @@ date: 2020-11-02 21:31:58
- +
+ 类加载过程
-------
@@ -96,11 +96,11 @@ public class HelloLoader {
* 加载成功,则进行链接、初始化等操作。完成后调用 HelloLoader 类中的静态方法 main
* 加载失败则抛出异常
-
类加载过程
-------
@@ -96,11 +96,11 @@ public class HelloLoader {
* 加载成功,则进行链接、初始化等操作。完成后调用 HelloLoader 类中的静态方法 main
* 加载失败则抛出异常
- +
+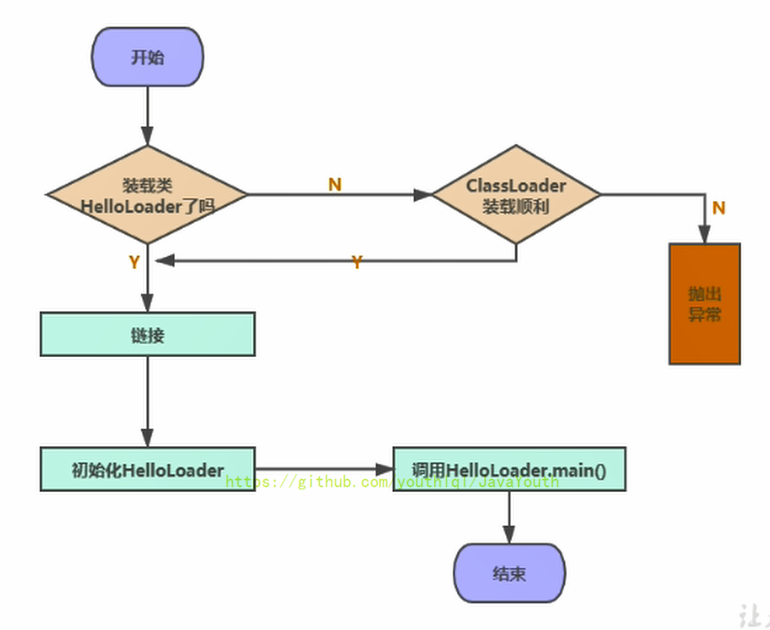 完整的流程图如下所示:
-
完整的流程图如下所示:
- +
+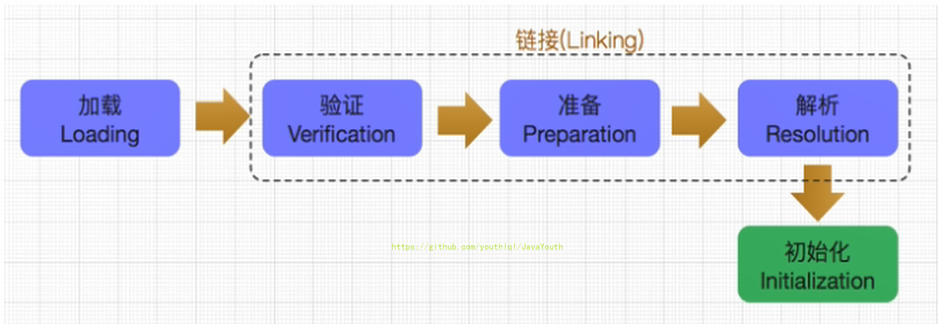 @@ -142,7 +142,7 @@ public class HelloLoader {
使用 BinaryViewer软件查看字节码文件,其开头均为 CAFE BABE ,如果出现不合法的字节码文件,那么将会验证不通过。
-
@@ -142,7 +142,7 @@ public class HelloLoader {
使用 BinaryViewer软件查看字节码文件,其开头均为 CAFE BABE ,如果出现不合法的字节码文件,那么将会验证不通过。
- +
+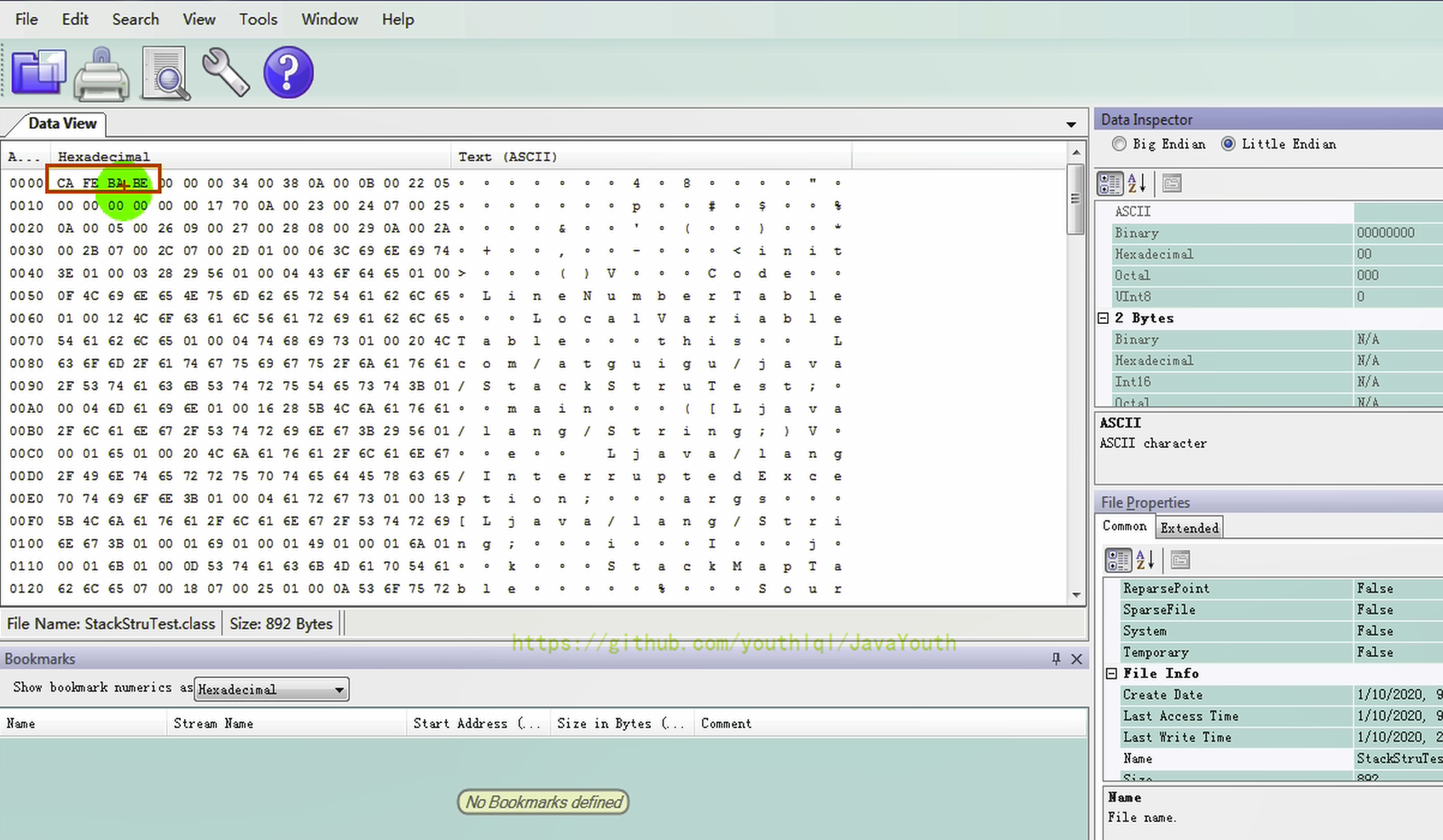 #### 准备(Prepare)
@@ -185,7 +185,7 @@ public class HelloApp {
* 反编译 class 文件后可以查看符号引用,下面带# 的就是符号引用
-
#### 准备(Prepare)
@@ -185,7 +185,7 @@ public class HelloApp {
* 反编译 class 文件后可以查看符号引用,下面带# 的就是符号引用
- +
+ ### 初始化阶段
@@ -225,7 +225,7 @@ public class HelloApp {
查看下面这个代码的字节码,可以发现有一个`()`方法。
-
### 初始化阶段
@@ -225,7 +225,7 @@ public class HelloApp {
查看下面这个代码的字节码,可以发现有一个`()`方法。
- +
+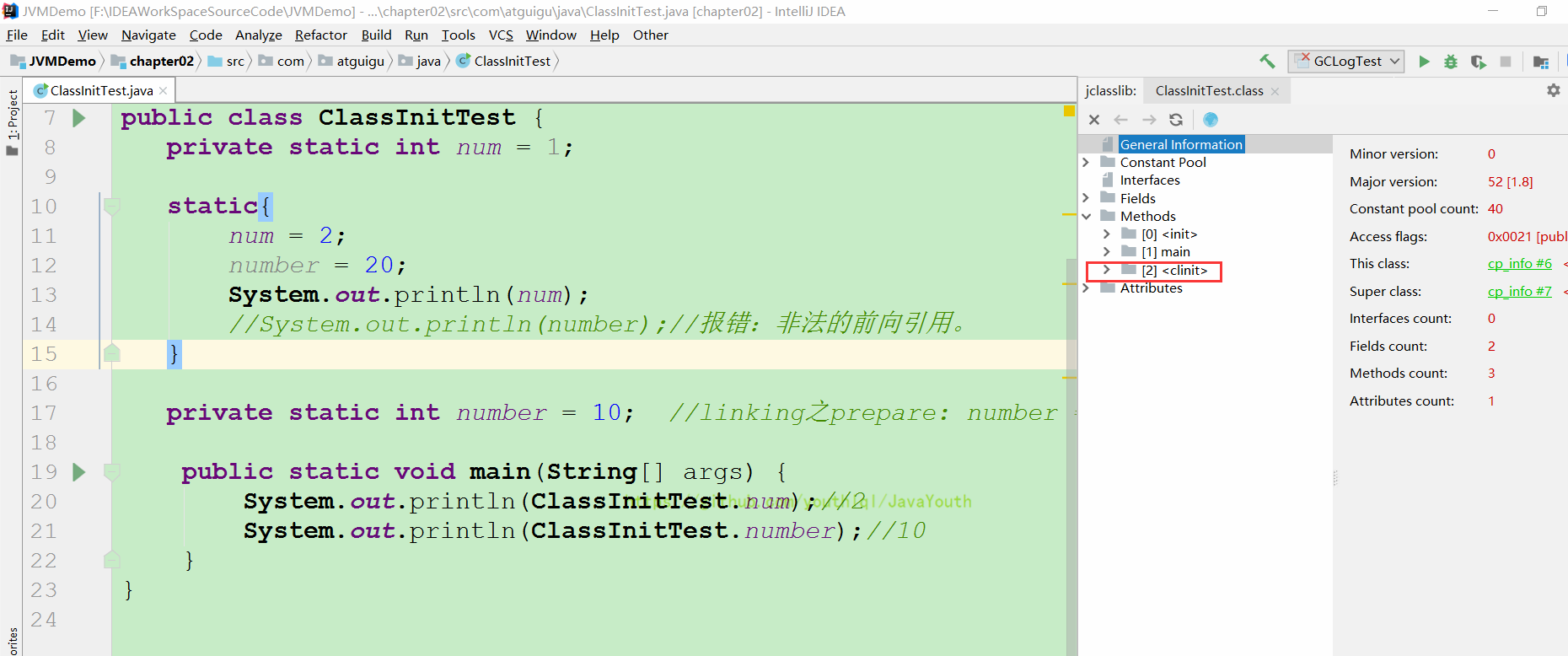 ```java
public class ClassInitTest {
@@ -277,15 +277,15 @@ public class ClassInitTest {
**举例2:无 static 变量**
-
```java
public class ClassInitTest {
@@ -277,15 +277,15 @@ public class ClassInitTest {
**举例2:无 static 变量**
- +
+ 加上之后就有了
-
加上之后就有了
- +
+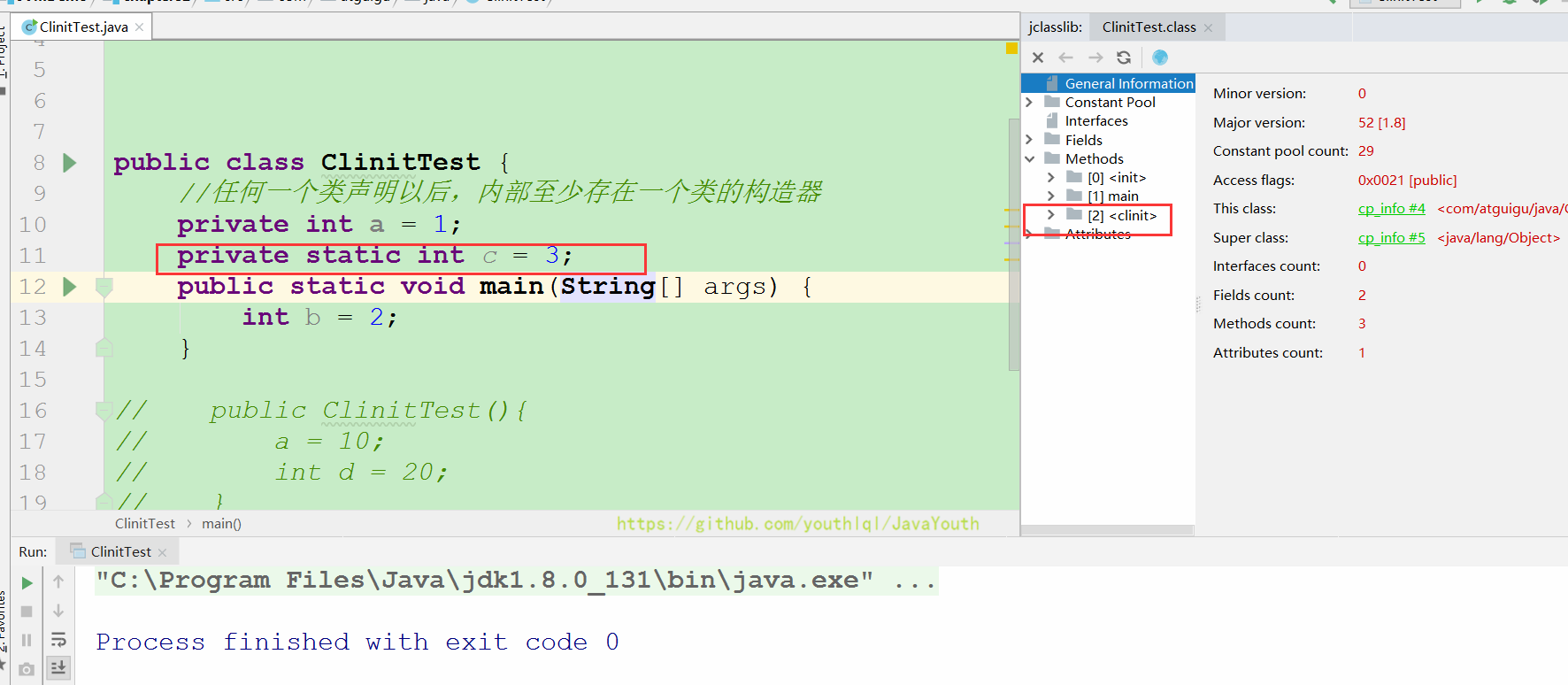 #### 4说明
-
#### 4说明
- +
+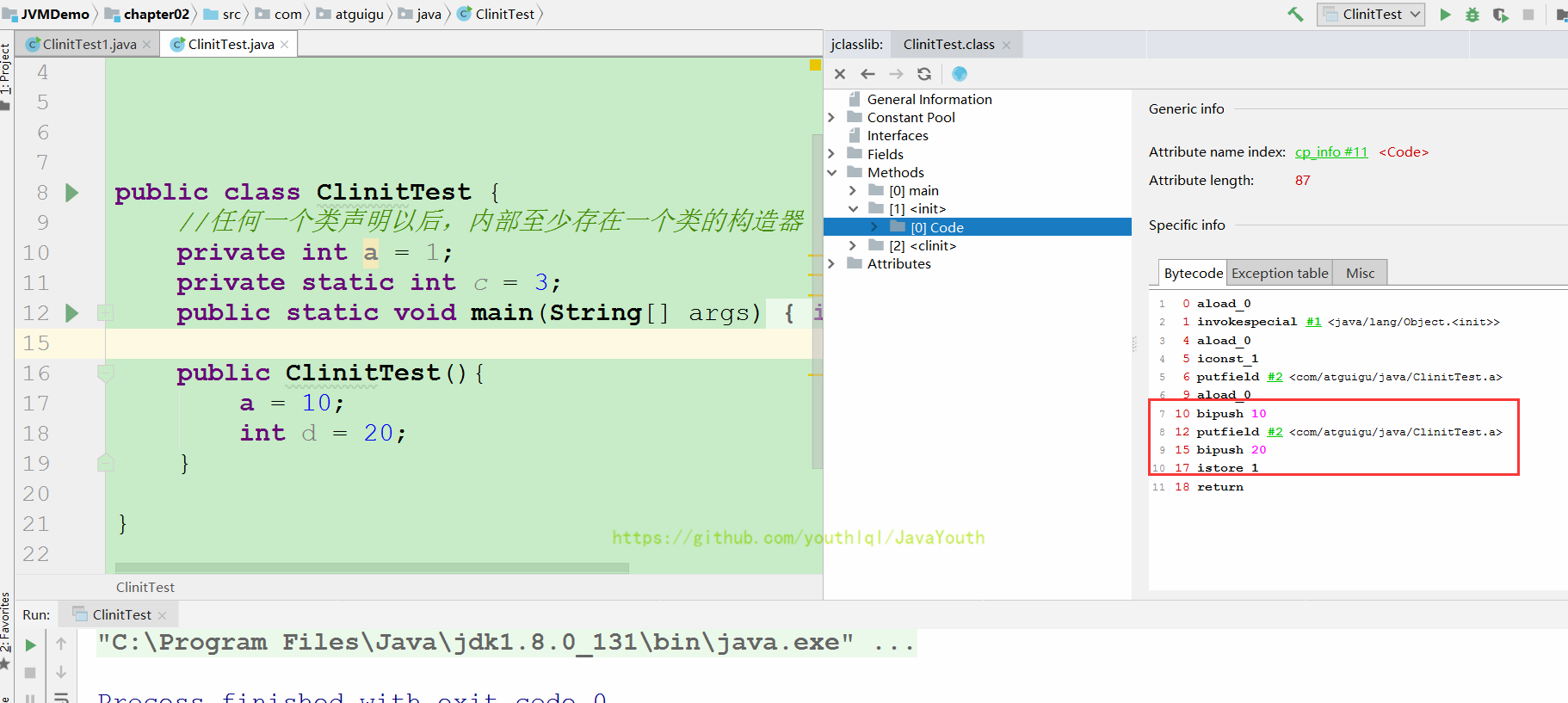 在构造器中:
@@ -296,7 +296,7 @@ public class ClassInitTest {
若该类具有父类,JVM会保证子类的`()`执行前,父类的`()`已经执行完毕
-
在构造器中:
@@ -296,7 +296,7 @@ public class ClassInitTest {
若该类具有父类,JVM会保证子类的`()`执行前,父类的`()`已经执行完毕
- +
+ 如上代码,加载流程如下:
@@ -374,17 +374,17 @@ class DeadThread{
-
如上代码,加载流程如下:
@@ -374,17 +374,17 @@ class DeadThread{
- +
+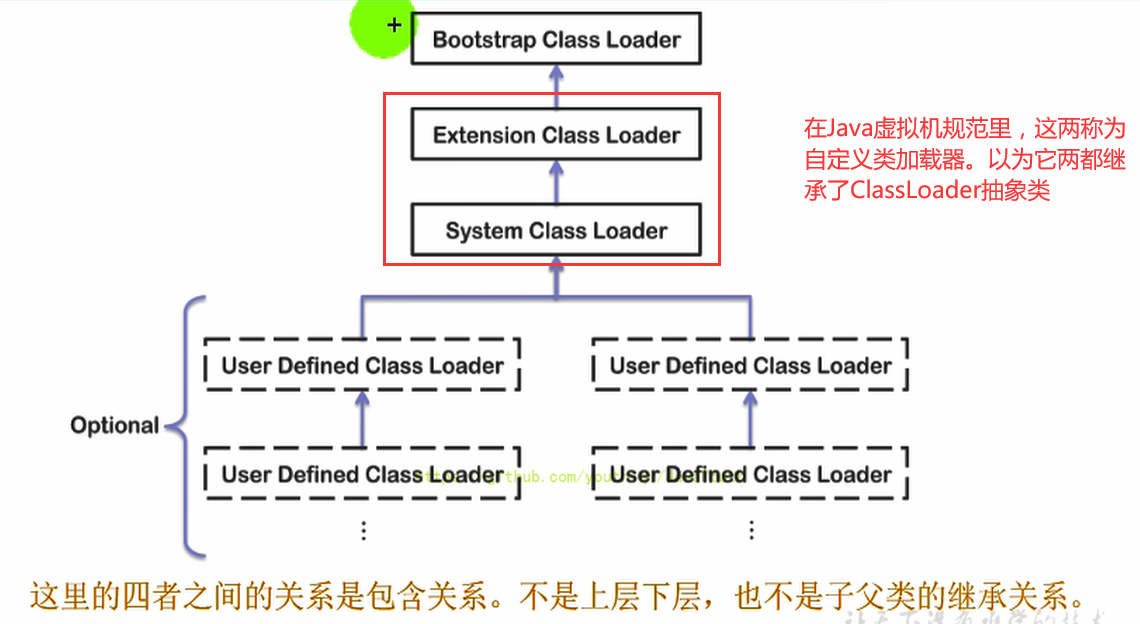 **ExtClassLoader**
-
**ExtClassLoader**
- +
+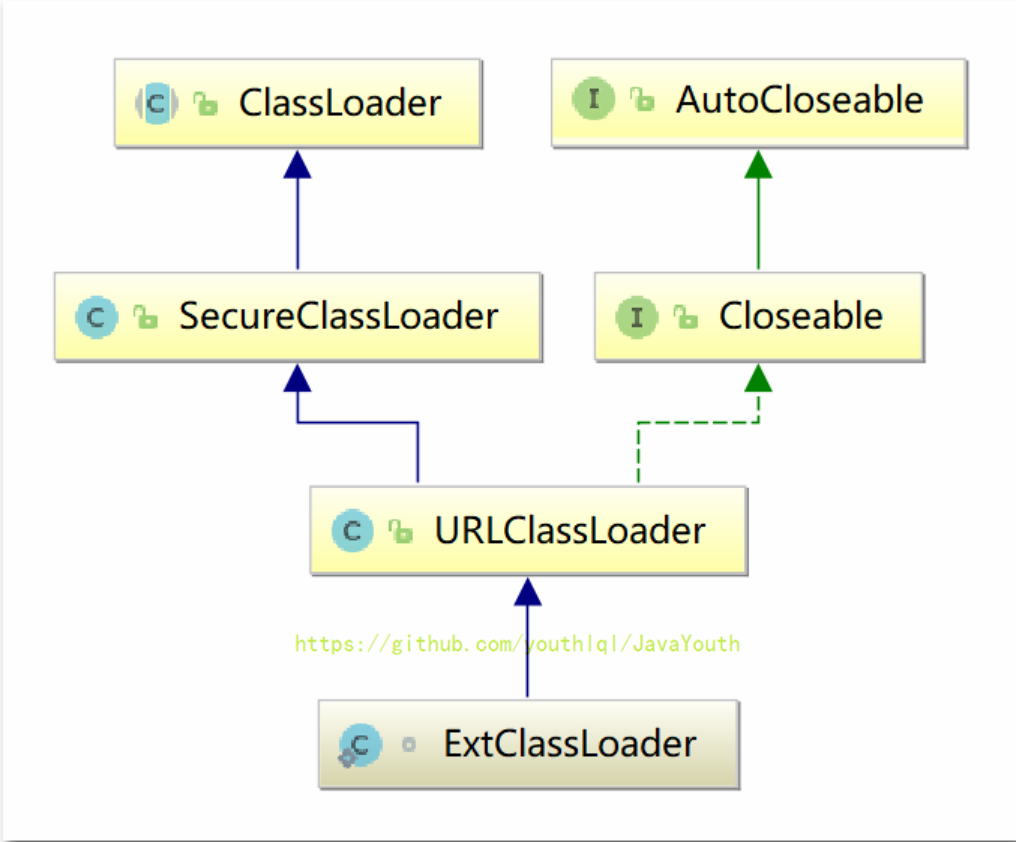 **AppClassLoader**
-
**AppClassLoader**
- +
+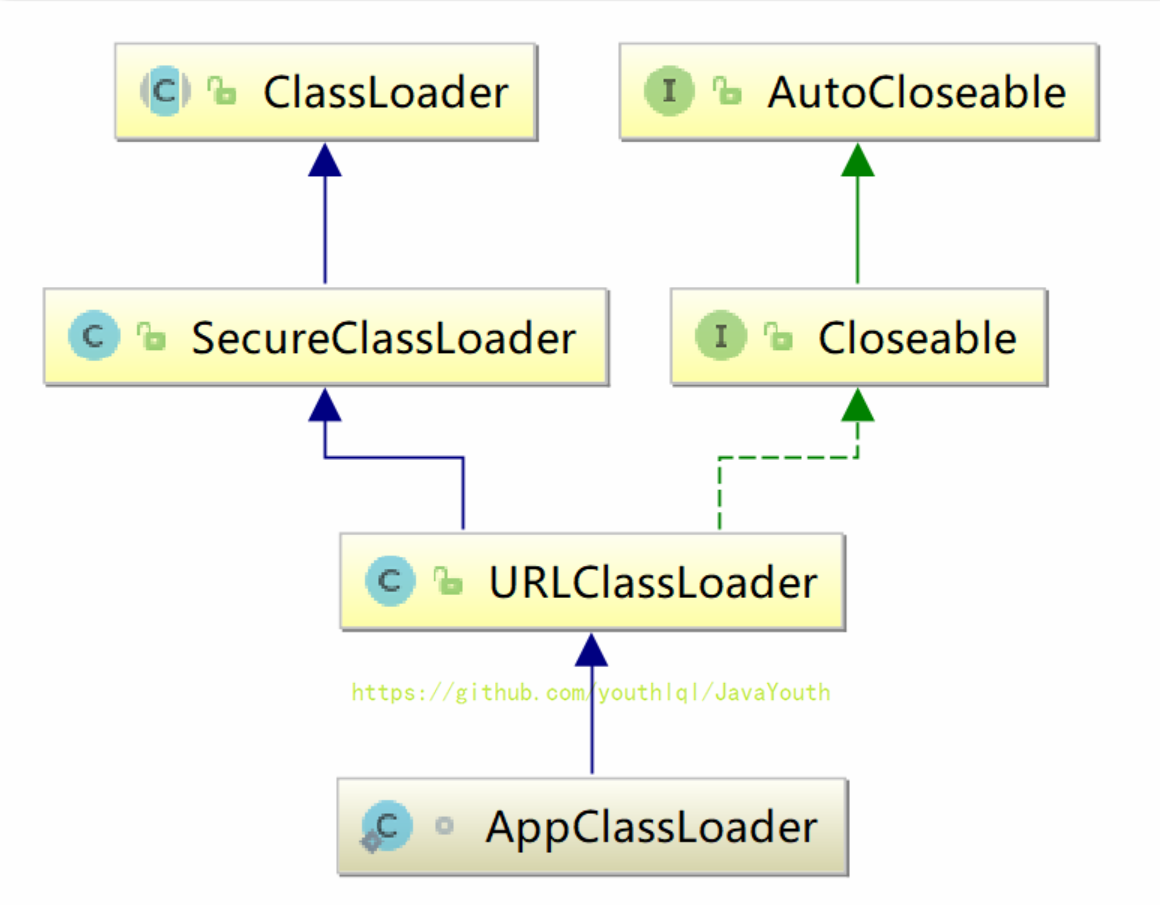 @@ -579,15 +579,15 @@ public class CustomClassLoader extends ClassLoader {
ClassLoader类,它是一个抽象类,其后所有的类加载器都继承自ClassLoader(不包括启动类加载器)
-
@@ -579,15 +579,15 @@ public class CustomClassLoader extends ClassLoader {
ClassLoader类,它是一个抽象类,其后所有的类加载器都继承自ClassLoader(不包括启动类加载器)
- +
+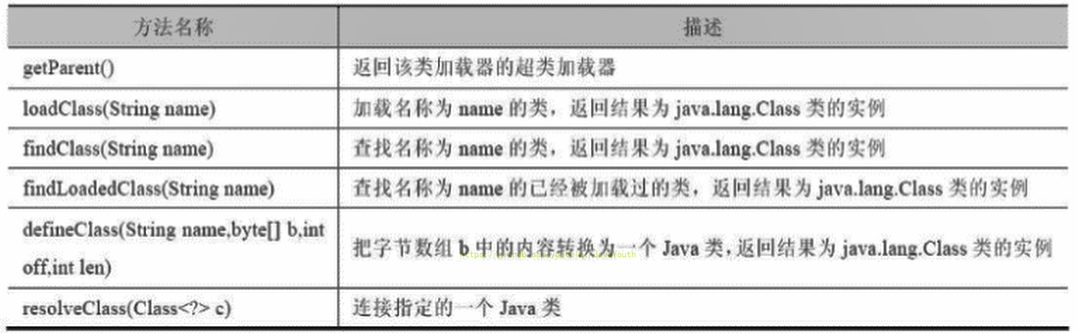 sun.misc.Launcher 它是一个java虚拟机的入口应用
-
sun.misc.Launcher 它是一个java虚拟机的入口应用
- +
+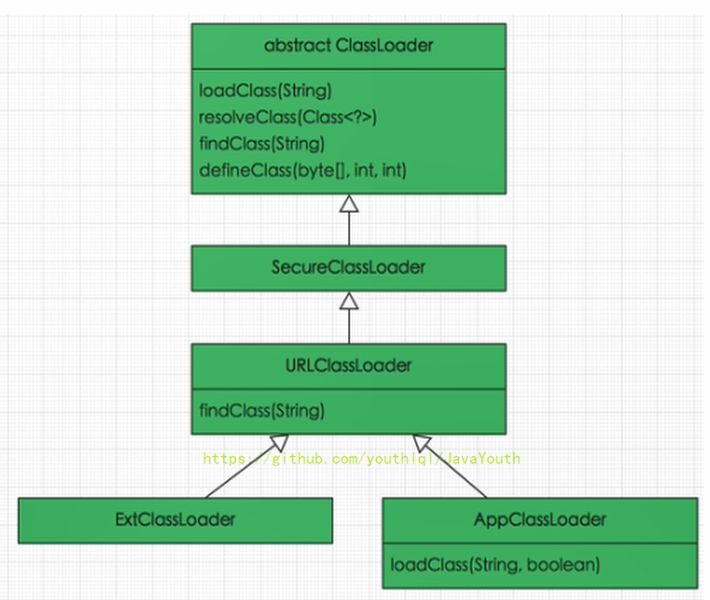 #### 获取ClassLoader途径
-
#### 获取ClassLoader途径
- +
+ @@ -640,7 +640,7 @@ Java虚拟机对class文件采用的是**按需加载**的方式,也就是说
3. 如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式。
4. 父类加载器一层一层往下分配任务,如果子类加载器能加载,则加载此类,如果将加载任务分配至系统类加载器也无法加载此类,则抛出异常
-
@@ -640,7 +640,7 @@ Java虚拟机对class文件采用的是**按需加载**的方式,也就是说
3. 如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式。
4. 父类加载器一层一层往下分配任务,如果子类加载器能加载,则加载此类,如果将加载任务分配至系统类加载器也无法加载此类,则抛出异常
- +
+ ### 双亲委派机制代码演示
@@ -707,7 +707,7 @@ public class String {
}
```
-
### 双亲委派机制代码演示
@@ -707,7 +707,7 @@ public class String {
}
```
- +
+ 由于双亲委派机制一直找父类,所以最后找到了Bootstrap ClassLoader,Bootstrap ClassLoader找到的是 JDK 自带的 String 类,在那个String类中并没有 main() 方法,所以就报了上面的错误。
@@ -765,7 +765,7 @@ Process finished with exit code 1
-
由于双亲委派机制一直找父类,所以最后找到了Bootstrap ClassLoader,Bootstrap ClassLoader找到的是 JDK 自带的 String 类,在那个String类中并没有 main() 方法,所以就报了上面的错误。
@@ -765,7 +765,7 @@ Process finished with exit code 1
- +
+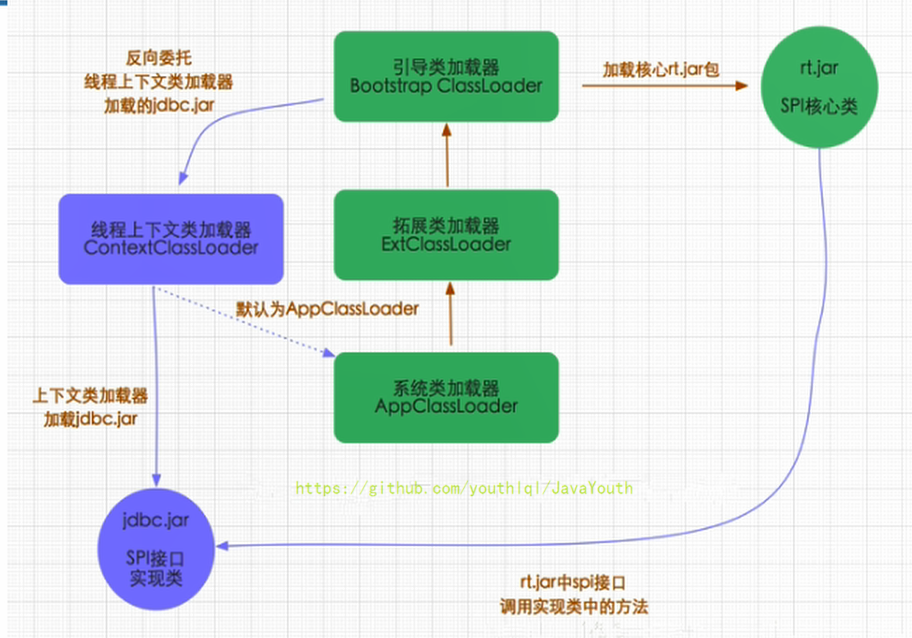 diff --git a/docs/JVM/JVM系列-第3章-运行时数据区.md b/docs/JVM/JVM系列-第3章-运行时数据区.md
index b904ce9..a696abe 100644
--- a/docs/JVM/JVM系列-第3章-运行时数据区.md
+++ b/docs/JVM/JVM系列-第3章-运行时数据区.md
@@ -27,15 +27,15 @@ date: 2020-11-09 15:38:42
本节主要讲的是运行时数据区,也就是下图这部分,它是在类加载完成后的阶段
-
diff --git a/docs/JVM/JVM系列-第3章-运行时数据区.md b/docs/JVM/JVM系列-第3章-运行时数据区.md
index b904ce9..a696abe 100644
--- a/docs/JVM/JVM系列-第3章-运行时数据区.md
+++ b/docs/JVM/JVM系列-第3章-运行时数据区.md
@@ -27,15 +27,15 @@ date: 2020-11-09 15:38:42
本节主要讲的是运行时数据区,也就是下图这部分,它是在类加载完成后的阶段
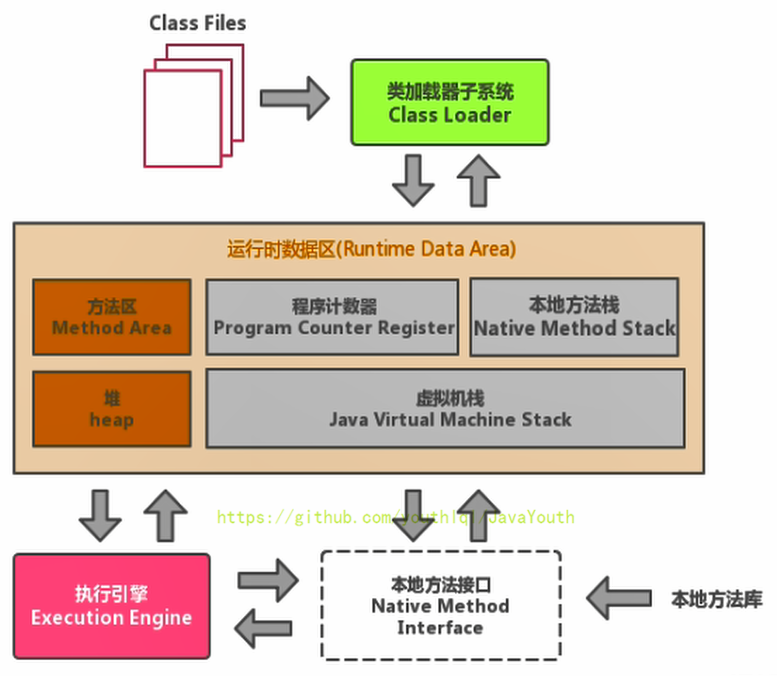
- +
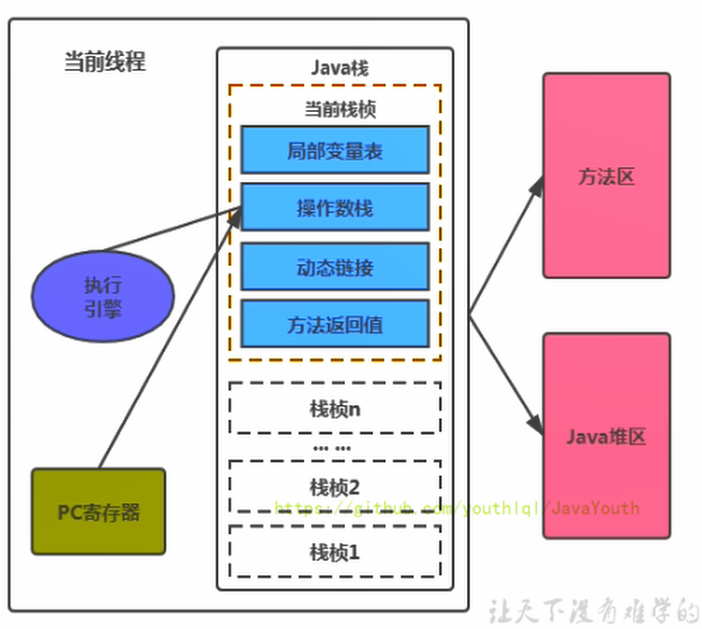
+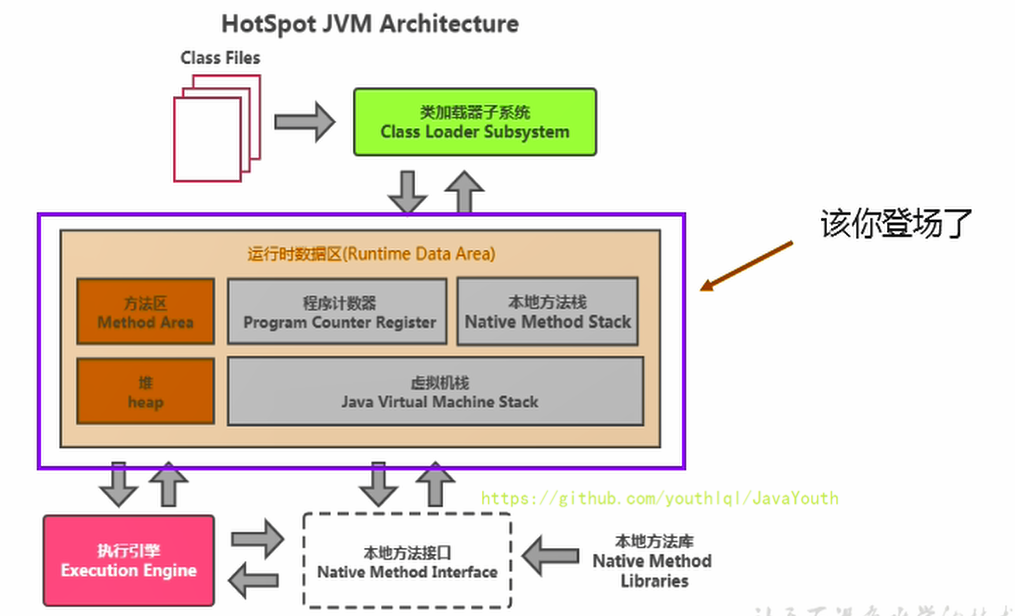 当我们通过前面的:类的加载 --> 验证 --> 准备 --> 解析 --\> 初始化,这几个阶段完成后,就会用到执行引擎对我们的类进行使用,同时执行引擎将会使用到我们运行时数据区
-
当我们通过前面的:类的加载 --> 验证 --> 准备 --> 解析 --\> 初始化,这几个阶段完成后,就会用到执行引擎对我们的类进行使用,同时执行引擎将会使用到我们运行时数据区
- +
+ 类比一下也就是大厨做饭,我们把大厨后面的东西(切好的菜,刀,调料),比作是运行时数据区。而厨师可以类比于执行引擎,将通过准备的东西进行制作成精美的菜品。
-
类比一下也就是大厨做饭,我们把大厨后面的东西(切好的菜,刀,调料),比作是运行时数据区。而厨师可以类比于执行引擎,将通过准备的东西进行制作成精美的菜品。
- +
+ @@ -50,7 +50,7 @@ date: 2020-11-09 15:38:42
> 下图来自阿里巴巴手册JDK8
-
@@ -50,7 +50,7 @@ date: 2020-11-09 15:38:42
> 下图来自阿里巴巴手册JDK8
- +
+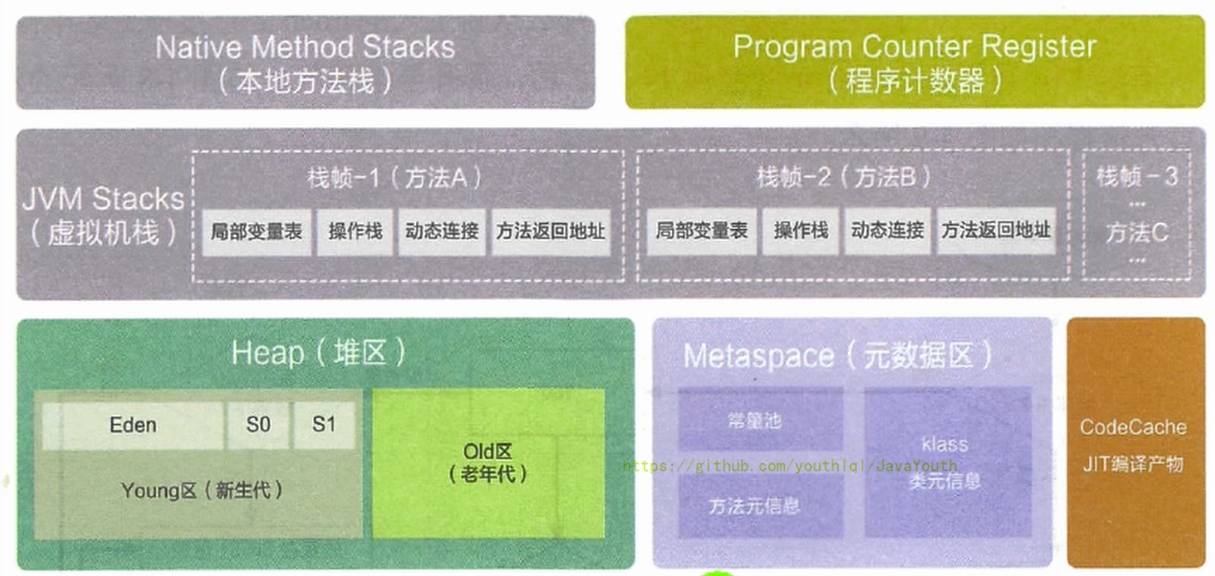 @@ -62,7 +62,7 @@ date: 2020-11-09 15:38:42
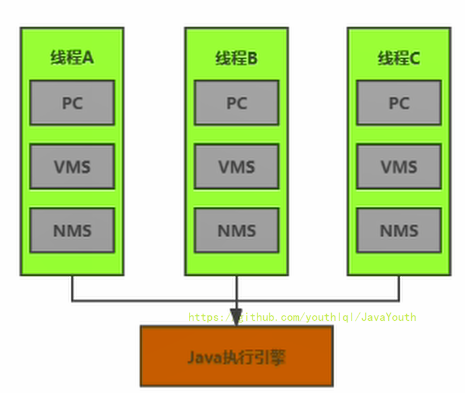
- 线程独有:独立包括程序计数器、栈、本地方法栈
- 线程间共享:堆、堆外内存(永久代或元空间、代码缓存)
-
@@ -62,7 +62,7 @@ date: 2020-11-09 15:38:42
- 线程独有:独立包括程序计数器、栈、本地方法栈
- 线程间共享:堆、堆外内存(永久代或元空间、代码缓存)
- +
+ @@ -70,7 +70,7 @@ date: 2020-11-09 15:38:42
**每个JVM只有一个Runtime实例**。即为运行时环境,相当于内存结构的中间的那个框框:运行时环境。
-
@@ -70,7 +70,7 @@ date: 2020-11-09 15:38:42
**每个JVM只有一个Runtime实例**。即为运行时环境,相当于内存结构的中间的那个框框:运行时环境。
- +
+ @@ -114,7 +114,7 @@ PC寄存器介绍
> 官方文档网址:https://docs.oracle.com/javase/specs/jvms/se8/html/index.html
-
@@ -114,7 +114,7 @@ PC寄存器介绍
> 官方文档网址:https://docs.oracle.com/javase/specs/jvms/se8/html/index.html
- +
+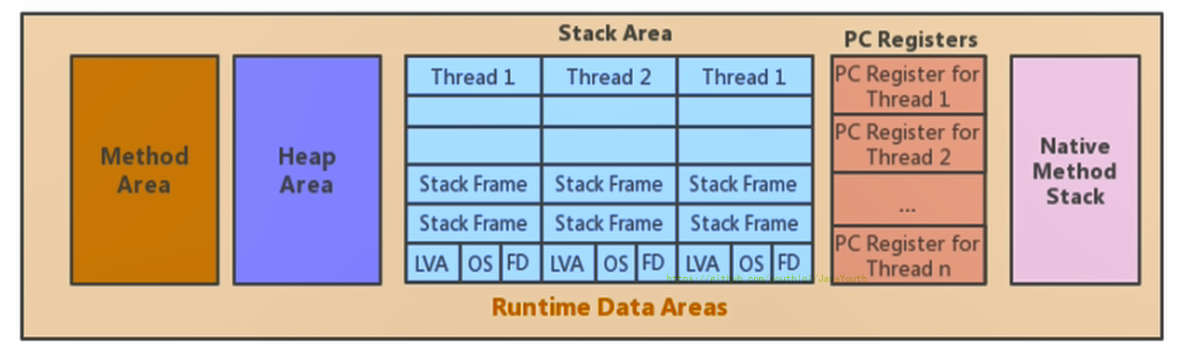 1. JVM中的程序计数寄存器(Program Counter Register)中,Register的命名源于CPU的寄存器,**寄存器存储指令相关的现场信息**。CPU只有把数据装载到寄存器才能够运行。
2. 这里,并非是广义上所指的物理寄存器,或许将其翻译为PC计数器(或指令计数器)会更加贴切(也称为程序钩子),并且也不容易引起一些不必要的误会。**JVM中的PC寄存器是对物理PC寄存器的一种抽象模拟**。
@@ -132,7 +132,7 @@ PC寄存器介绍
PC寄存器用来存储指向下一条指令的地址,也即将要执行的指令代码。由执行引擎读取下一条指令,并执行该指令。
-
1. JVM中的程序计数寄存器(Program Counter Register)中,Register的命名源于CPU的寄存器,**寄存器存储指令相关的现场信息**。CPU只有把数据装载到寄存器才能够运行。
2. 这里,并非是广义上所指的物理寄存器,或许将其翻译为PC计数器(或指令计数器)会更加贴切(也称为程序钩子),并且也不容易引起一些不必要的误会。**JVM中的PC寄存器是对物理PC寄存器的一种抽象模拟**。
@@ -132,7 +132,7 @@ PC寄存器介绍
PC寄存器用来存储指向下一条指令的地址,也即将要执行的指令代码。由执行引擎读取下一条指令,并执行该指令。
- +
+ @@ -268,7 +268,7 @@ SourceFile: "PCRegisterTest.java"
* 左边的数字代表**指令地址(指令偏移)**,即 PC 寄存器中可能存储的值,然后执行引擎读取 PC 寄存器中的值,并执行该指令
-
@@ -268,7 +268,7 @@ SourceFile: "PCRegisterTest.java"
* 左边的数字代表**指令地址(指令偏移)**,即 PC 寄存器中可能存储的值,然后执行引擎读取 PC 寄存器中的值,并执行该指令
- +
+ @@ -282,7 +282,7 @@ SourceFile: "PCRegisterTest.java"
2. JVM的字节码解释器就需要通过改变PC寄存器的值来明确下一条应该执行什么样的字节码指令
-
@@ -282,7 +282,7 @@ SourceFile: "PCRegisterTest.java"
2. JVM的字节码解释器就需要通过改变PC寄存器的值来明确下一条应该执行什么样的字节码指令
- +
+ @@ -306,7 +306,7 @@ CPU 时间片
3. 但在微观上:由于只有一个CPU,一次只能处理程序要求的一部分,如何处理公平,一种方法就是引入时间片,**每个程序轮流执行**。
-
@@ -306,7 +306,7 @@ CPU 时间片
3. 但在微观上:由于只有一个CPU,一次只能处理程序要求的一部分,如何处理公平,一种方法就是引入时间片,**每个程序轮流执行**。
- +
+ @@ -314,7 +314,7 @@ CPU 时间片
## 本地方法
-
@@ -314,7 +314,7 @@ CPU 时间片
## 本地方法
- +
+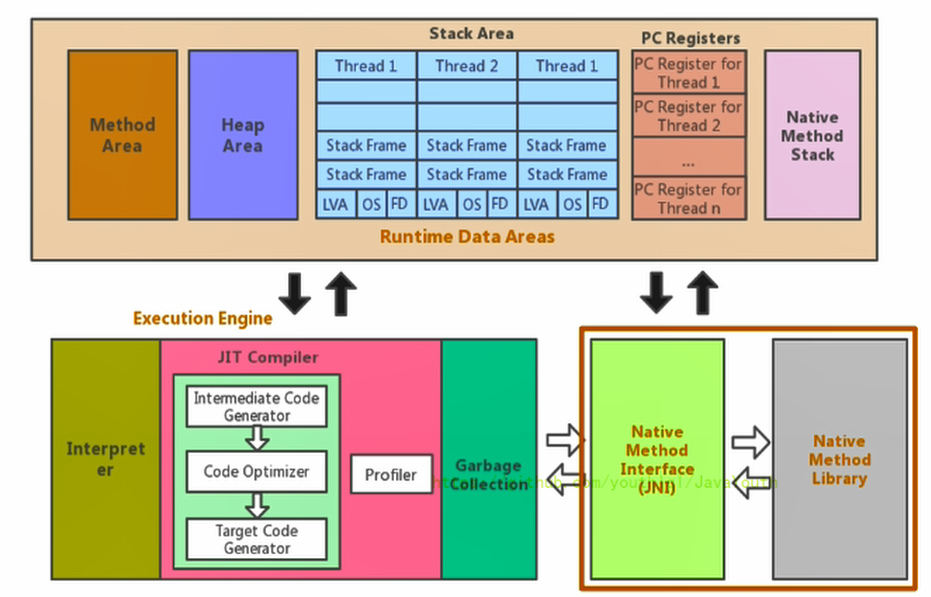 @@ -393,7 +393,7 @@ Java使用起来非常方便,然而有些层次的任务用Java实现起来不
4. 本地方法一般是使用C语言或C++语言实现的。
5. 它的具体做法是Native Method Stack中登记native方法,在Execution Engine 执行时加载本地方法库。
-
@@ -393,7 +393,7 @@ Java使用起来非常方便,然而有些层次的任务用Java实现起来不
4. 本地方法一般是使用C语言或C++语言实现的。
5. 它的具体做法是Native Method Stack中登记native方法,在Execution Engine 执行时加载本地方法库。
- +
+ diff --git a/docs/JVM/JVM系列-第4章-虚拟机栈.md b/docs/JVM/JVM系列-第4章-虚拟机栈.md
index 4dc02d7..a26d98a 100644
--- a/docs/JVM/JVM系列-第4章-虚拟机栈.md
+++ b/docs/JVM/JVM系列-第4章-虚拟机栈.md
@@ -31,7 +31,7 @@ date: 2020-11-10 10:38:42
1. 首先栈是运行时的单位,而堆是存储的单位。
2. 即:栈解决程序的运行问题,即程序如何执行,或者说如何处理数据。堆解决的是数据存储的问题,即数据怎么放,放哪里
-
diff --git a/docs/JVM/JVM系列-第4章-虚拟机栈.md b/docs/JVM/JVM系列-第4章-虚拟机栈.md
index 4dc02d7..a26d98a 100644
--- a/docs/JVM/JVM系列-第4章-虚拟机栈.md
+++ b/docs/JVM/JVM系列-第4章-虚拟机栈.md
@@ -31,7 +31,7 @@ date: 2020-11-10 10:38:42
1. 首先栈是运行时的单位,而堆是存储的单位。
2. 即:栈解决程序的运行问题,即程序如何执行,或者说如何处理数据。堆解决的是数据存储的问题,即数据怎么放,放哪里
- +
+ @@ -66,7 +66,7 @@ date: 2020-11-10 10:38:42
-
@@ -66,7 +66,7 @@ date: 2020-11-10 10:38:42
- +
+ - 虚拟机栈的生命周期
- 生命周期和线程一致,也就是线程结束了,该虚拟机栈也销毁了
@@ -90,7 +90,7 @@ date: 2020-11-10 10:38:42
- 对于栈来说不存在垃圾回收问题
- 栈不需要GC,但是可能存在OOM
-
- 虚拟机栈的生命周期
- 生命周期和线程一致,也就是线程结束了,该虚拟机栈也销毁了
@@ -90,7 +90,7 @@ date: 2020-11-10 10:38:42
- 对于栈来说不存在垃圾回收问题
- 栈不需要GC,但是可能存在OOM
- +
+ ### 虚拟机栈的异常
@@ -164,7 +164,7 @@ Exception in thread "main" java.lang.StackOverflowError
**设置栈参数之后**
-
### 虚拟机栈的异常
@@ -164,7 +164,7 @@ Exception in thread "main" java.lang.StackOverflowError
**设置栈参数之后**
- +
+ 部分输出结果
@@ -202,7 +202,7 @@ Exception in thread "main" java.lang.StackOverflowError
4. 如果在该方法中调用了其他方法,对应的新的栈帧会被创建出来,放在栈的顶端,成为新的当前帧。
-
部分输出结果
@@ -202,7 +202,7 @@ Exception in thread "main" java.lang.StackOverflowError
4. 如果在该方法中调用了其他方法,对应的新的栈帧会被创建出来,放在栈的顶端,成为新的当前帧。
- +
+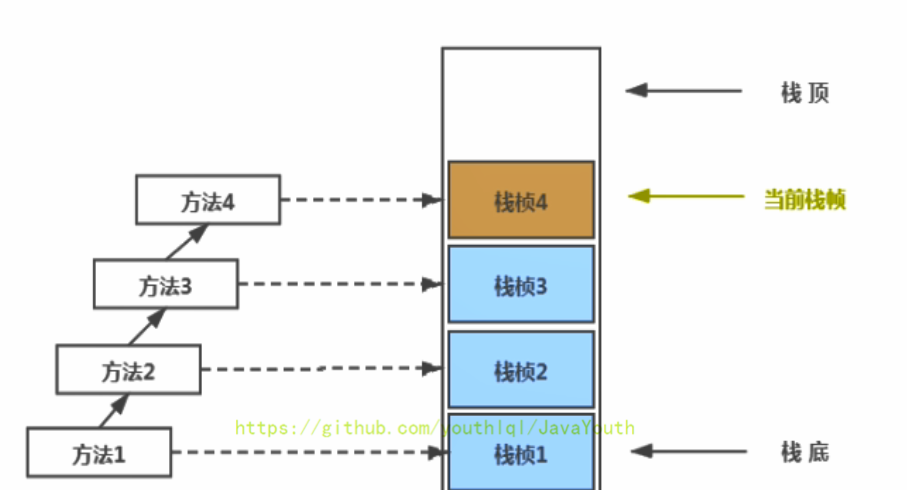 1. **不同线程中所包含的栈帧是不允许存在相互引用的**,即不可能在一个栈帧之中引用另外一个线程的栈帧。
2. 如果当前方法调用了其他方法,方法返回之际,当前栈帧会传回此方法的执行结果给前一个栈帧,接着,虚拟机会丢弃当前栈帧,使得前一个栈帧重新成为当前栈帧。
@@ -230,11 +230,11 @@ Exception in thread "main" java.lang.StackOverflowError
- 一些附加信息
-
1. **不同线程中所包含的栈帧是不允许存在相互引用的**,即不可能在一个栈帧之中引用另外一个线程的栈帧。
2. 如果当前方法调用了其他方法,方法返回之际,当前栈帧会传回此方法的执行结果给前一个栈帧,接着,虚拟机会丢弃当前栈帧,使得前一个栈帧重新成为当前栈帧。
@@ -230,11 +230,11 @@ Exception in thread "main" java.lang.StackOverflowError
- 一些附加信息
- +
+ 并行每个线程下的栈都是私有的,因此每个线程都有自己各自的栈,并且每个栈里面都有很多栈帧,栈帧的大小主要由局部变量表 和 操作数栈决定的
-
并行每个线程下的栈都是私有的,因此每个线程都有自己各自的栈,并且每个栈里面都有很多栈帧,栈帧的大小主要由局部变量表 和 操作数栈决定的
- +
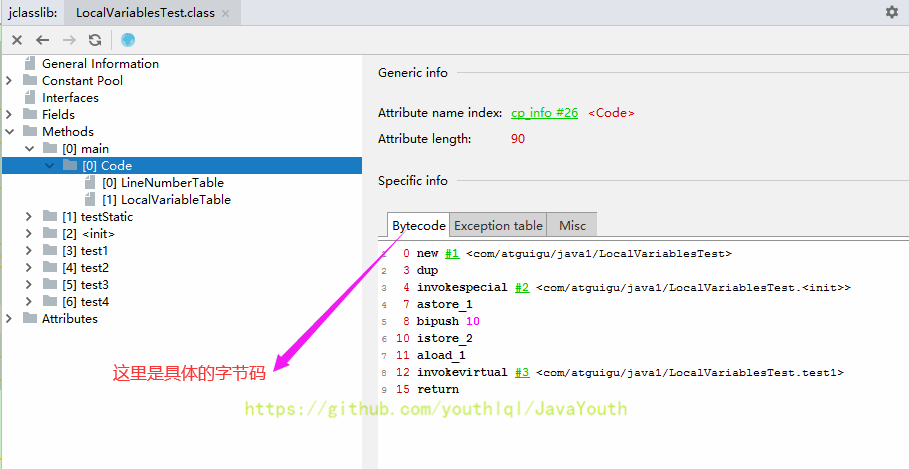
+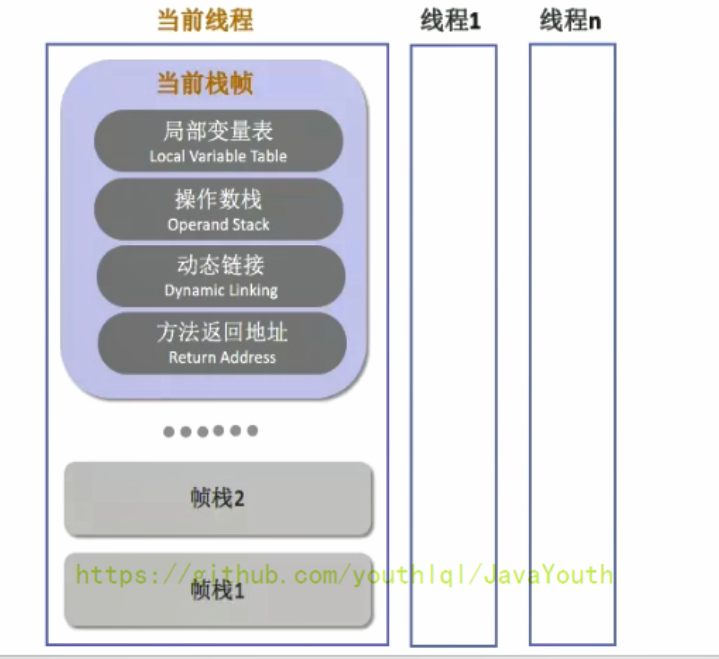 局部变量表
-------
@@ -312,7 +312,7 @@ public class LocalVariablesTest {
}
```
-
局部变量表
-------
@@ -312,7 +312,7 @@ public class LocalVariablesTest {
}
```
- +
+ 看完字节码后,可得结论:所以局部变量表所需的容量大小是在编译期确定下来的。
@@ -324,29 +324,29 @@ public class LocalVariablesTest {
1、0-15 也就是有16行字节码
-
看完字节码后,可得结论:所以局部变量表所需的容量大小是在编译期确定下来的。
@@ -324,29 +324,29 @@ public class LocalVariablesTest {
1、0-15 也就是有16行字节码
- +
+ 2、方法异常信息表
-
2、方法异常信息表
- +
+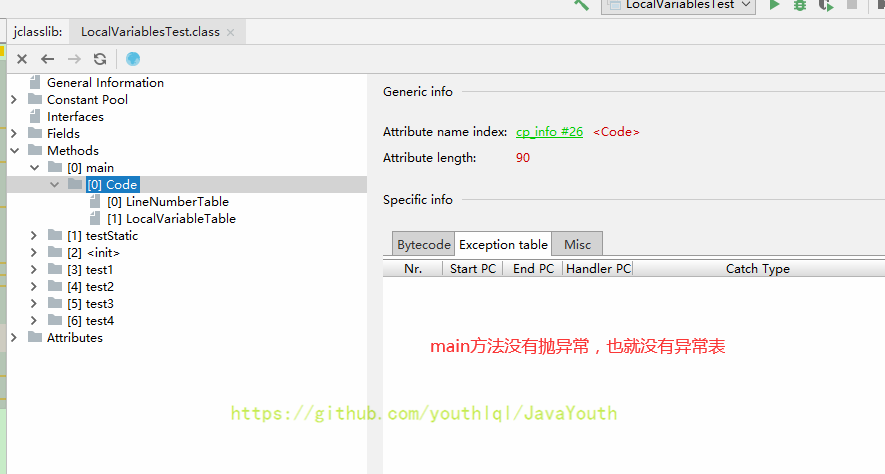 3、Misc
-
3、Misc
- +
+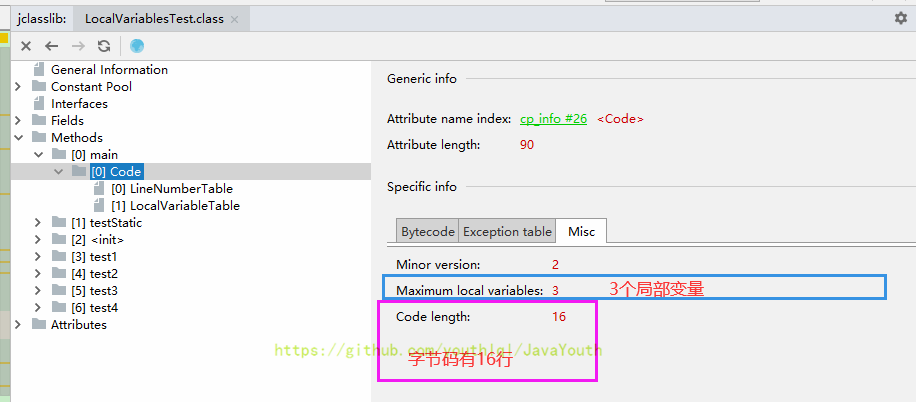 4、行号表
Java代码的行号和字节码指令行号的对应关系
-
4、行号表
Java代码的行号和字节码指令行号的对应关系
- +
+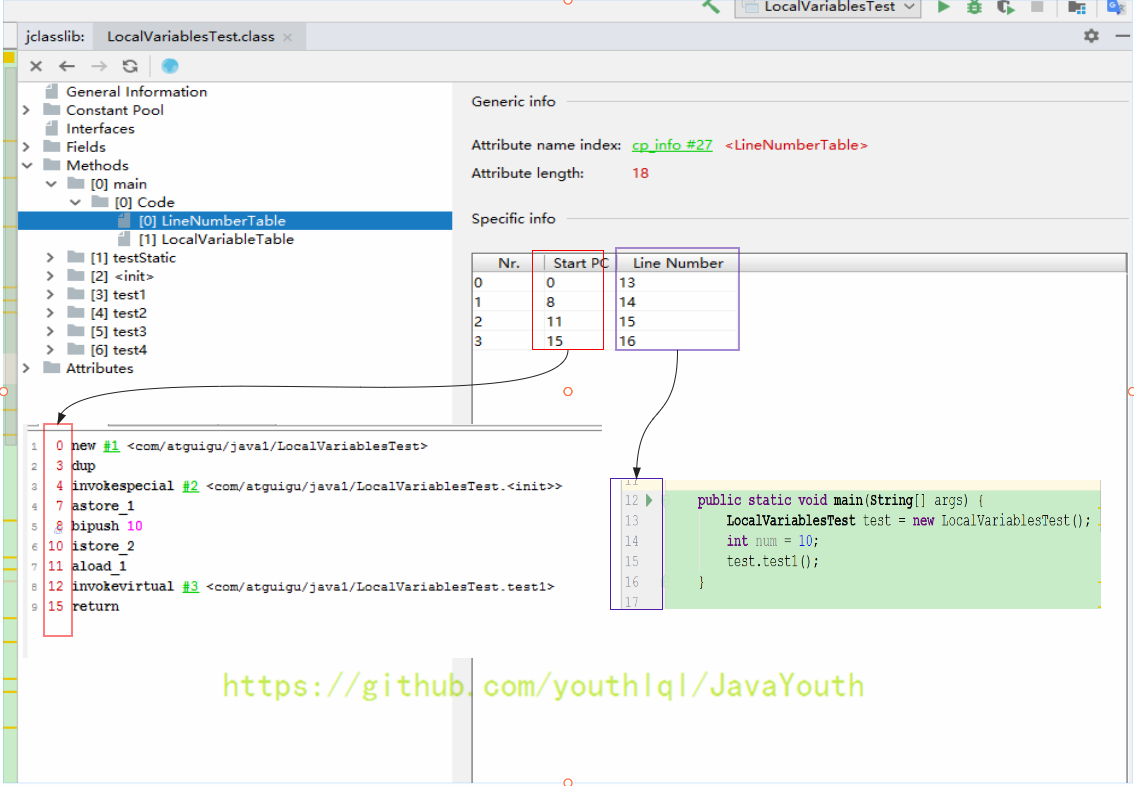 5、注意:生效行数和剩余有效行数都是针对于字节码文件的行数
-
5、注意:生效行数和剩余有效行数都是针对于字节码文件的行数
- +
+ 1、图中圈的东西表示该局部变量的作用域
@@ -370,7 +370,7 @@ Java代码的行号和字节码指令行号的对应关系
6. 如果需要访问局部变量表中一个64bit的局部变量值时,只需要使用前一个索引即可。(比如:访问long或double类型变量)
7. 如果当前帧是由构造方法或者实例方法创建的,那么**该对象引用this将会存放在index为0的slot处**,其余的参数按照参数表顺序继续排列。(this也相当于一个变量)
-
1、图中圈的东西表示该局部变量的作用域
@@ -370,7 +370,7 @@ Java代码的行号和字节码指令行号的对应关系
6. 如果需要访问局部变量表中一个64bit的局部变量值时,只需要使用前一个索引即可。(比如:访问long或double类型变量)
7. 如果当前帧是由构造方法或者实例方法创建的,那么**该对象引用this将会存放在index为0的slot处**,其余的参数按照参数表顺序继续排列。(this也相当于一个变量)
- +
+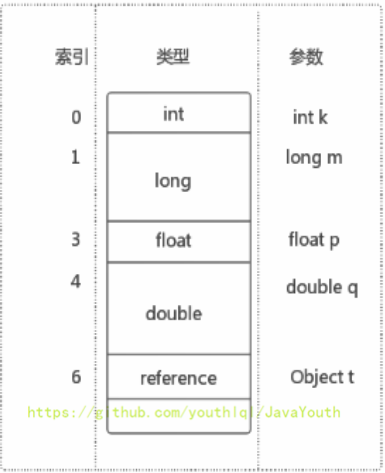 ### Slot代码示例
@@ -388,7 +388,7 @@ Java代码的行号和字节码指令行号的对应关系
局部变量表:this 存放在 index = 0 的位置
-
### Slot代码示例
@@ -388,7 +388,7 @@ Java代码的行号和字节码指令行号的对应关系
局部变量表:this 存放在 index = 0 的位置
- +
+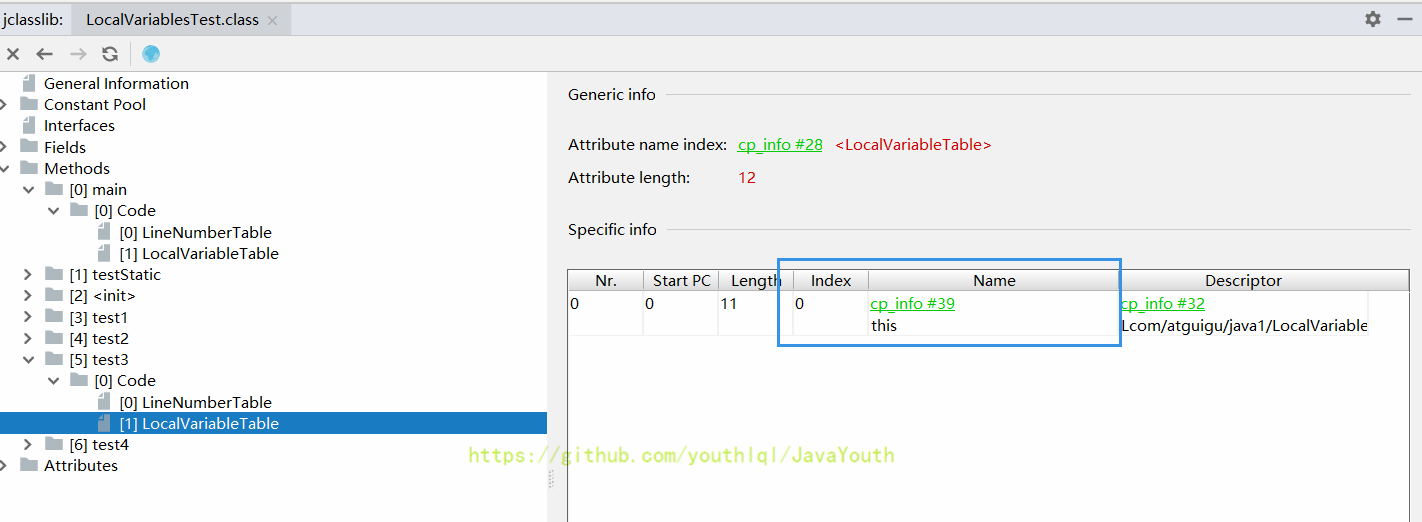 @@ -408,7 +408,7 @@ Java代码的行号和字节码指令行号的对应关系
weight 为 double 类型,index 直接从 3 蹦到了 5
-
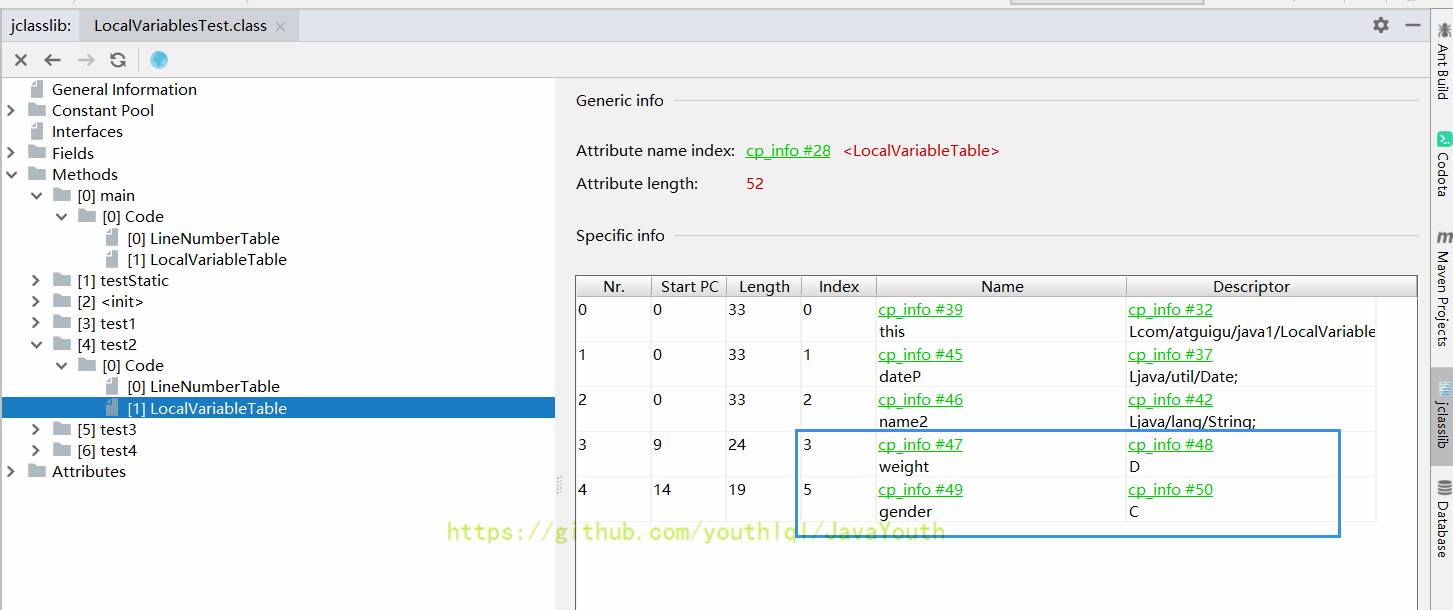
@@ -408,7 +408,7 @@ Java代码的行号和字节码指令行号的对应关系
weight 为 double 类型,index 直接从 3 蹦到了 5
- +
+ @@ -451,7 +451,7 @@ this 不存在与 static 方法的局部变量表中,所以无法调用
局部变量 c 重用了局部变量 b 的 slot 位置
-
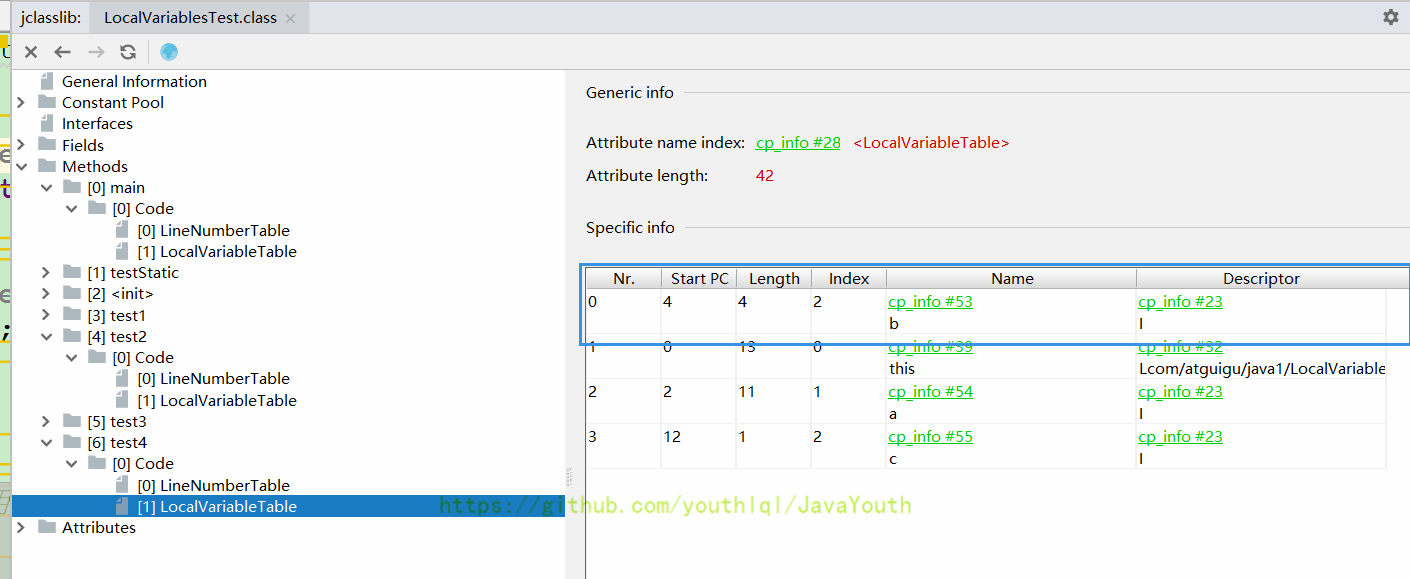
@@ -451,7 +451,7 @@ this 不存在与 static 方法的局部变量表中,所以无法调用
局部变量 c 重用了局部变量 b 的 slot 位置
- +
+ @@ -499,13 +499,13 @@ this 不存在与 static 方法的局部变量表中,所以无法调用
- 比如:执行复制、交换、求和等操作
-
@@ -499,13 +499,13 @@ this 不存在与 static 方法的局部变量表中,所以无法调用
- 比如:执行复制、交换、求和等操作
- +
+ -
- +
+ @@ -536,7 +536,7 @@ this 不存在与 static 方法的局部变量表中,所以无法调用
-
@@ -536,7 +536,7 @@ this 不存在与 static 方法的局部变量表中,所以无法调用
- +
+ 局部变量表就相当于食材
@@ -571,23 +571,23 @@ this 不存在与 static 方法的局部变量表中,所以无法调用
10 return
```
-
局部变量表就相当于食材
@@ -571,23 +571,23 @@ this 不存在与 static 方法的局部变量表中,所以无法调用
10 return
```
- +
+ ### 一步一步看流程
1、首先执行第一条语句,PC寄存器指向的是0,也就是指令地址为0,然后使用bipush让操作数15入操作数栈。
-
### 一步一步看流程
1、首先执行第一条语句,PC寄存器指向的是0,也就是指令地址为0,然后使用bipush让操作数15入操作数栈。
- +
+ 2、执行完后,PC寄存器往下移,指向下一行代码,下一行代码就是将操作数栈的元素存储到局部变量表1的位置(istore_1),我们可以看到局部变量表的已经增加了一个元素。并且操作数栈为空了
* 解释为什么局部变量表索引从 1 开始,因为该方法为实例方法,局部变量表索引为 0 的位置存放的是 this
-
2、执行完后,PC寄存器往下移,指向下一行代码,下一行代码就是将操作数栈的元素存储到局部变量表1的位置(istore_1),我们可以看到局部变量表的已经增加了一个元素。并且操作数栈为空了
* 解释为什么局部变量表索引从 1 开始,因为该方法为实例方法,局部变量表索引为 0 的位置存放的是 this
- +
+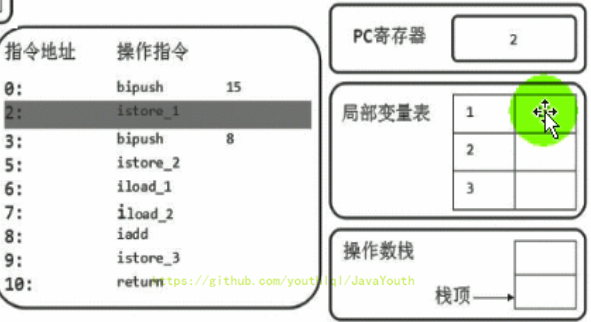 3、然后PC下移,指向的是下一行。让操作数8也入栈,同时执行store操作,存入局部变量表中
-
3、然后PC下移,指向的是下一行。让操作数8也入栈,同时执行store操作,存入局部变量表中
- +
+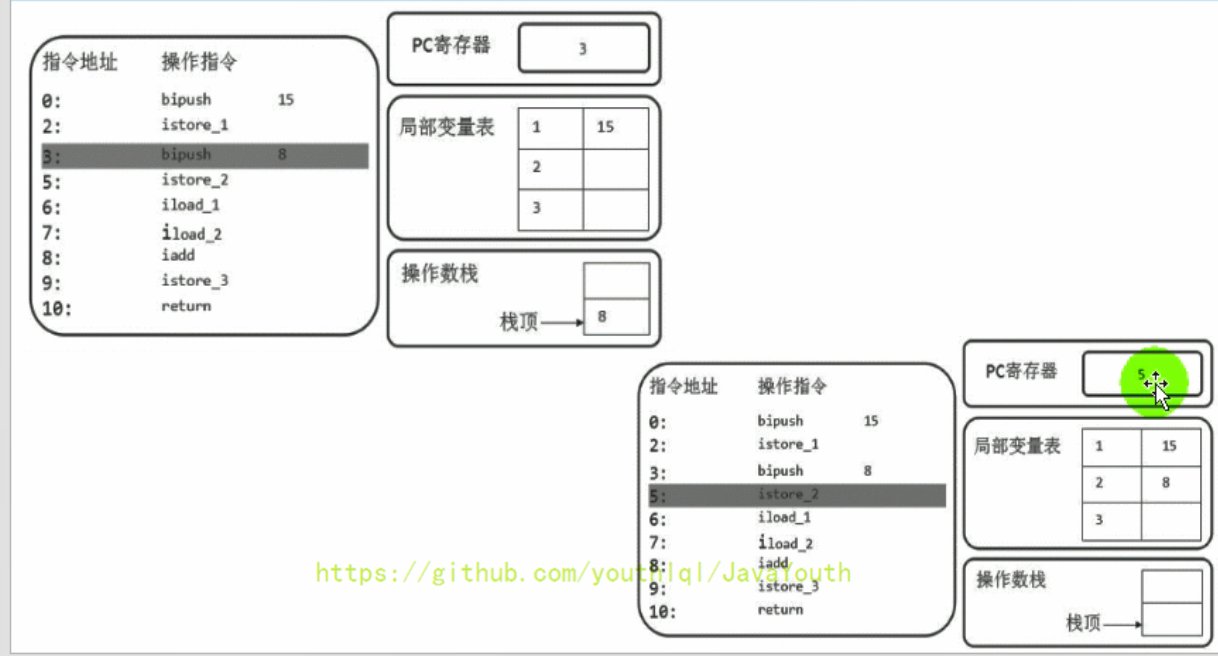 @@ -595,11 +595,11 @@ this 不存在与 static 方法的局部变量表中,所以无法调用
iload_1:取出局部变量表中索引为1的数据入操作数栈
-
@@ -595,11 +595,11 @@ this 不存在与 static 方法的局部变量表中,所以无法调用
iload_1:取出局部变量表中索引为1的数据入操作数栈
- +
+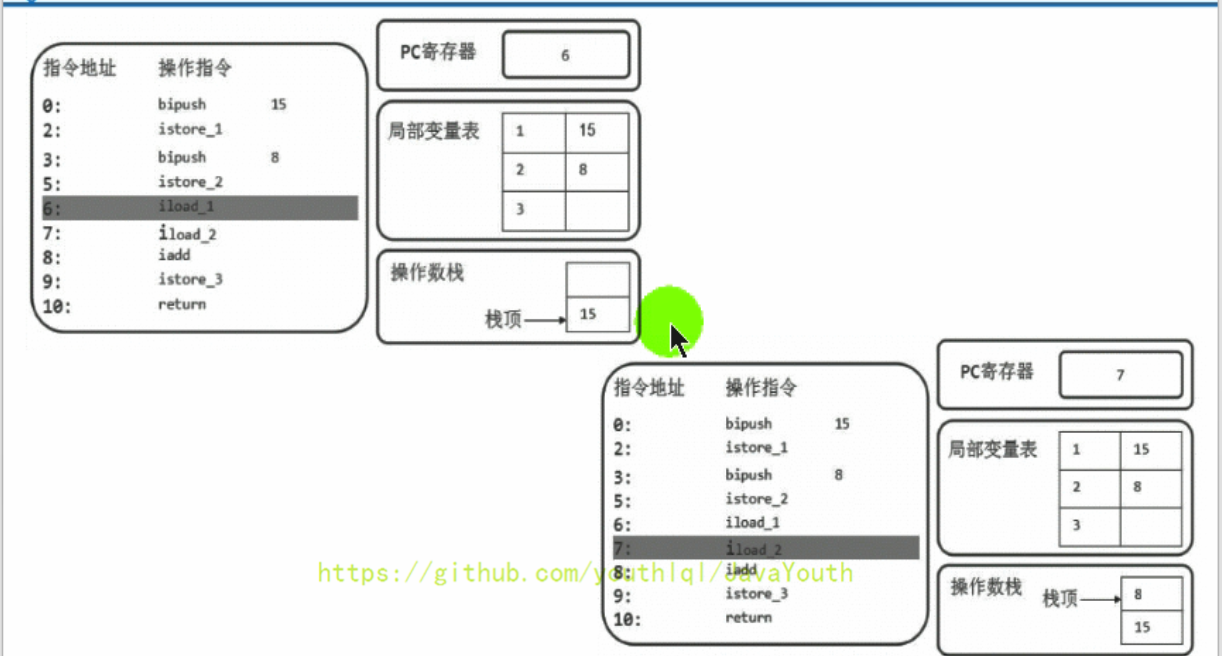 5、然后将操作数栈中的两个元素执行相加操作,并存储在局部变量表3的位置
-
5、然后将操作数栈中的两个元素执行相加操作,并存储在局部变量表3的位置
- +
+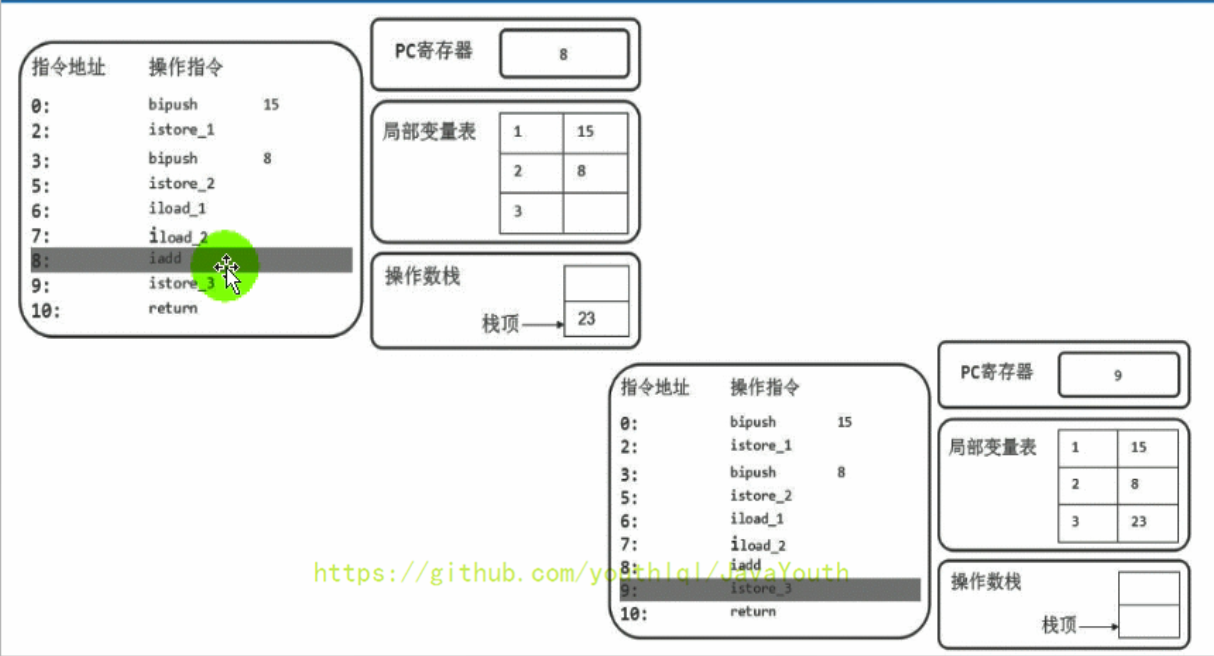 @@ -607,7 +607,7 @@ iload_1:取出局部变量表中索引为1的数据入操作数栈
**关于类型转换的说明**
-
@@ -607,7 +607,7 @@ iload_1:取出局部变量表中索引为1的数据入操作数栈
**关于类型转换的说明**
- +
+ @@ -616,7 +616,7 @@ iload_1:取出局部变量表中索引为1的数据入操作数栈
-
@@ -616,7 +616,7 @@ iload_1:取出局部变量表中索引为1的数据入操作数栈
- +
+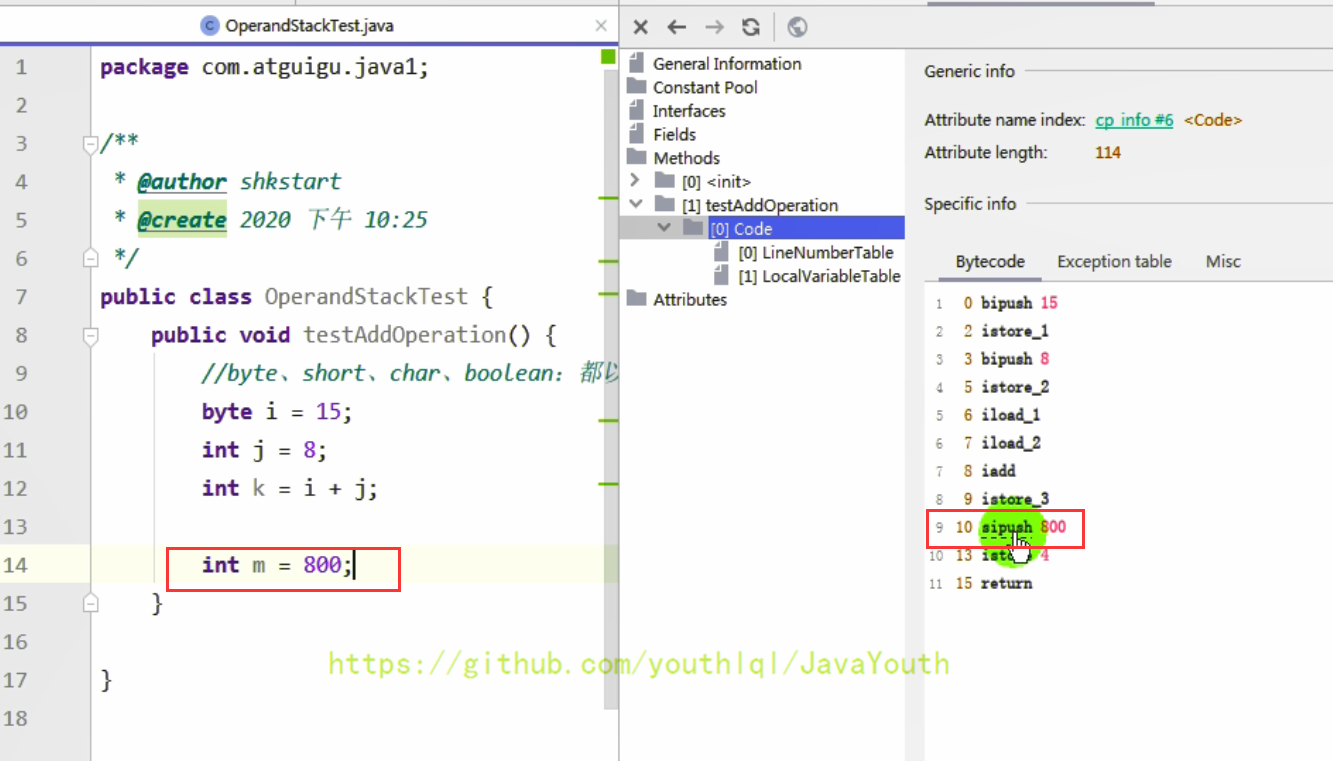 - m改成800之后,byte存储不了,就成了short型,sipush 800
@@ -645,11 +645,11 @@ iload_1:取出局部变量表中索引为1的数据入操作数栈
getSum() 方法字节码指令:最后带着个 ireturn
-
- m改成800之后,byte存储不了,就成了short型,sipush 800
@@ -645,11 +645,11 @@ iload_1:取出局部变量表中索引为1的数据入操作数栈
getSum() 方法字节码指令:最后带着个 ireturn
- +
+ testGetSum() 方法字节码指令:一上来就加载 getSum() 方法的返回值()
-
testGetSum() 方法字节码指令:一上来就加载 getSum() 方法的返回值()
- +
+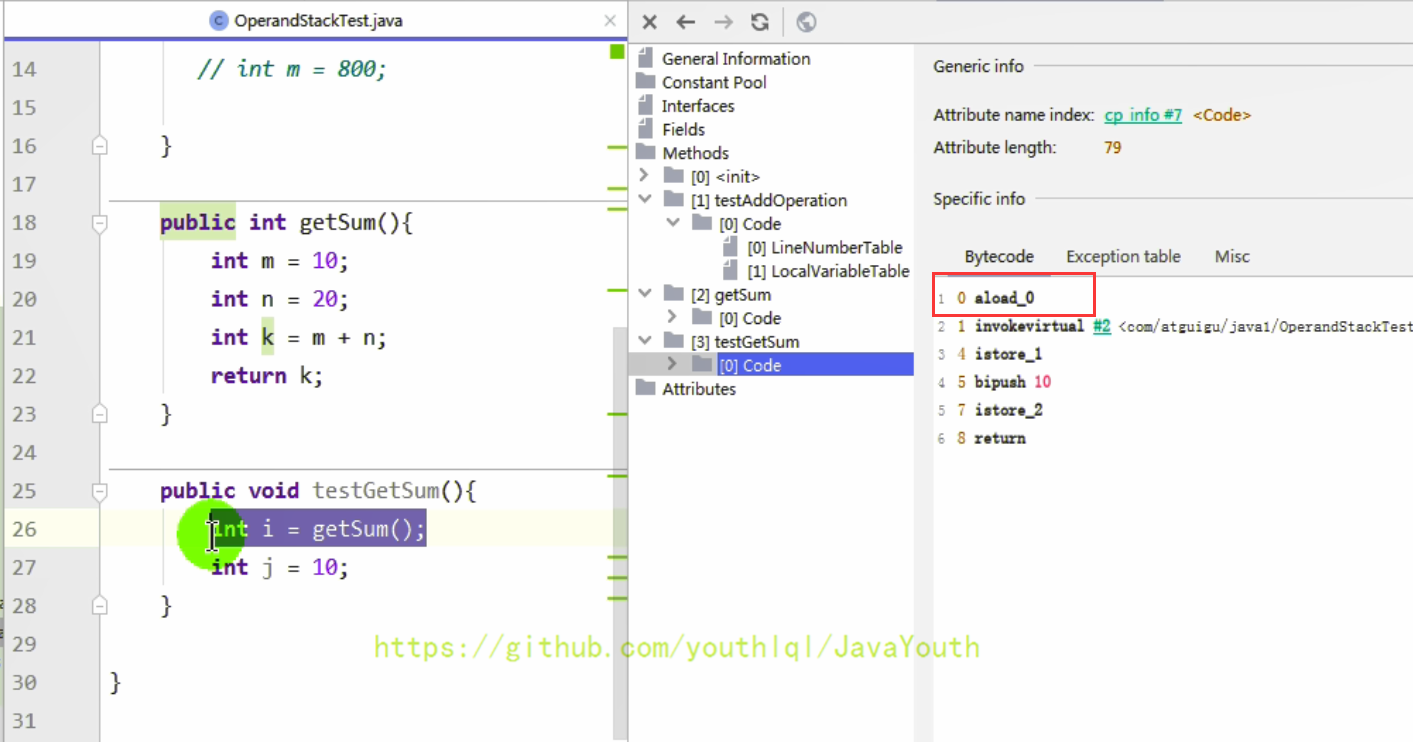 @@ -841,7 +841,7 @@ SourceFile: "DynamicLinkingTest.java"
-
@@ -841,7 +841,7 @@ SourceFile: "DynamicLinkingTest.java"
- +
+ @@ -1136,7 +1136,7 @@ interface MethodInterface {
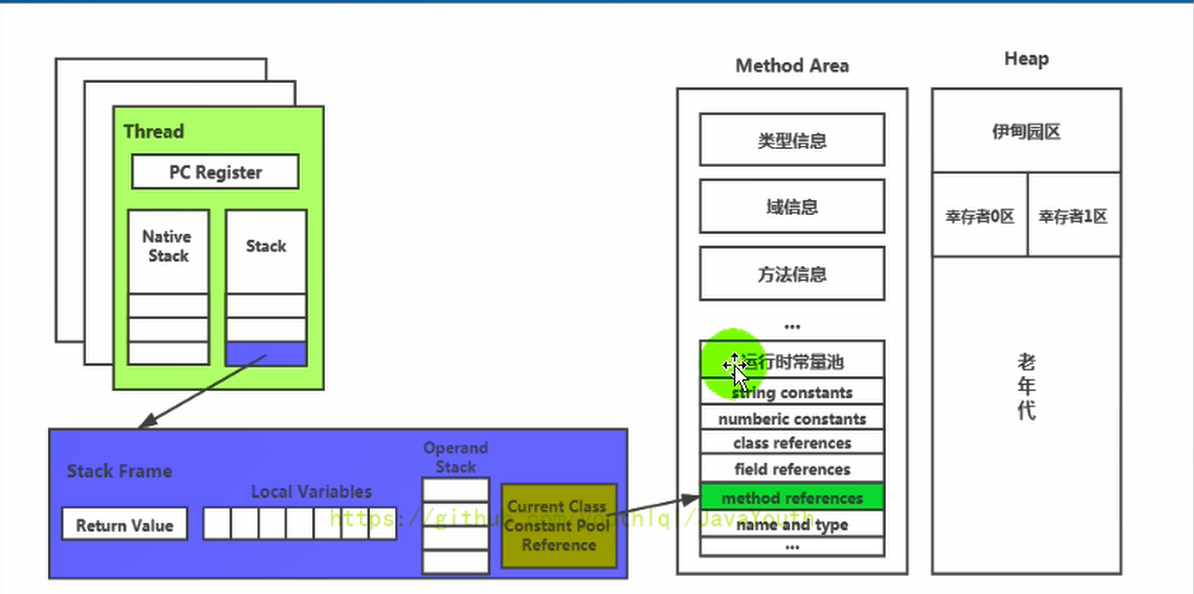
Son 类中 show() 方法的字节码指令如下
-
@@ -1136,7 +1136,7 @@ interface MethodInterface {
Son 类中 show() 方法的字节码指令如下
- +
+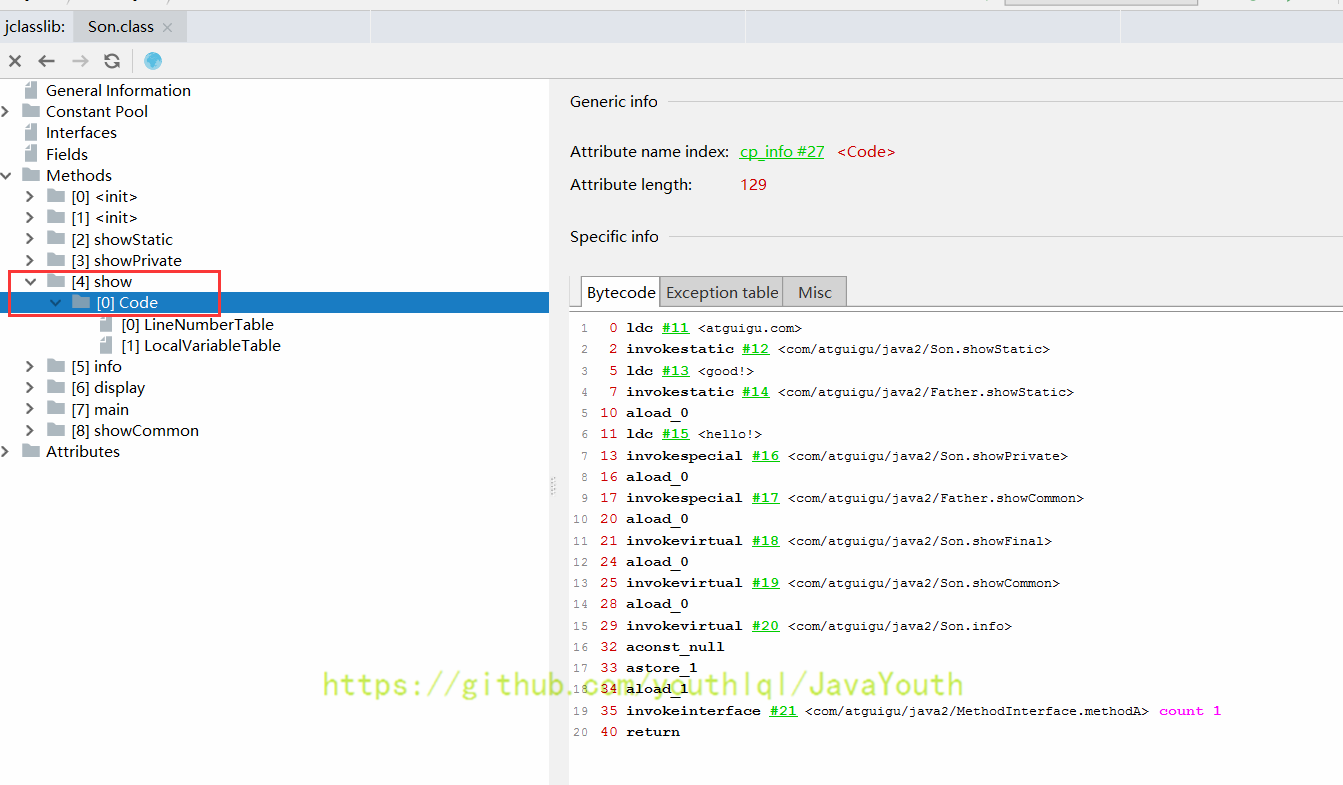 @@ -1176,7 +1176,7 @@ public class Lambda {
}
```
-
@@ -1176,7 +1176,7 @@ public class Lambda {
}
```
- +
+ @@ -1233,7 +1233,7 @@ Java:String info = "mogu blog"; (Java是静态类型语言的,会先
如图所示:如果类中重写了方法,那么调用的时候,就会直接在该类的虚方法表中查找
-
@@ -1233,7 +1233,7 @@ Java:String info = "mogu blog"; (Java是静态类型语言的,会先
如图所示:如果类中重写了方法,那么调用的时候,就会直接在该类的虚方法表中查找
- +
+ 1、比如说son在调用toString的时候,Son没有重写过,Son的父类Father也没有重写过,那就直接调用Object类的toString。那么就直接在虚方法表里指明toString直接指向Object类。
@@ -1243,24 +1243,24 @@ Java:String info = "mogu blog"; (Java是静态类型语言的,会先
**例子2**
-
1、比如说son在调用toString的时候,Son没有重写过,Son的父类Father也没有重写过,那就直接调用Object类的toString。那么就直接在虚方法表里指明toString直接指向Object类。
@@ -1243,24 +1243,24 @@ Java:String info = "mogu blog"; (Java是静态类型语言的,会先
**例子2**
- +
+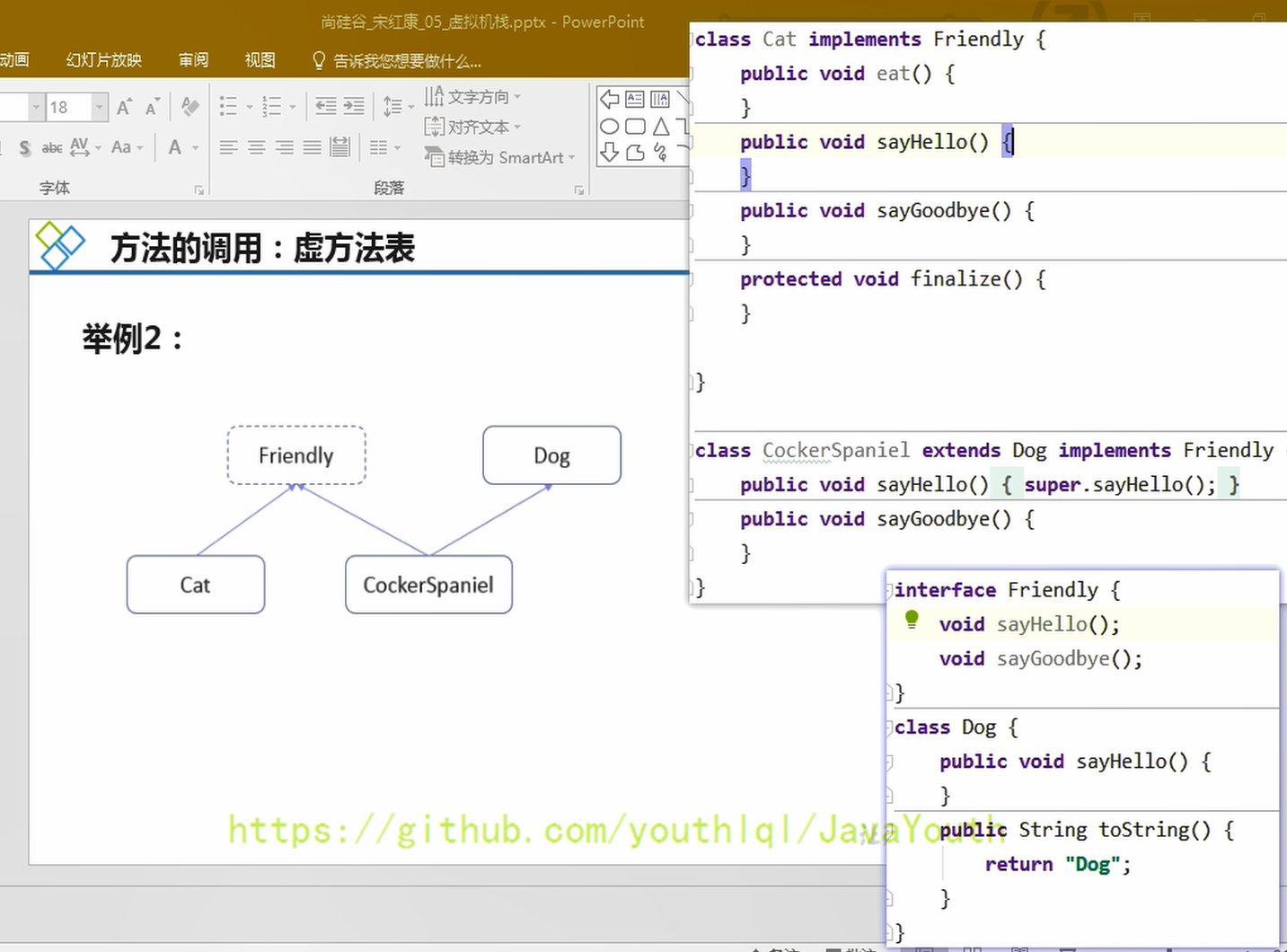 -
- +
+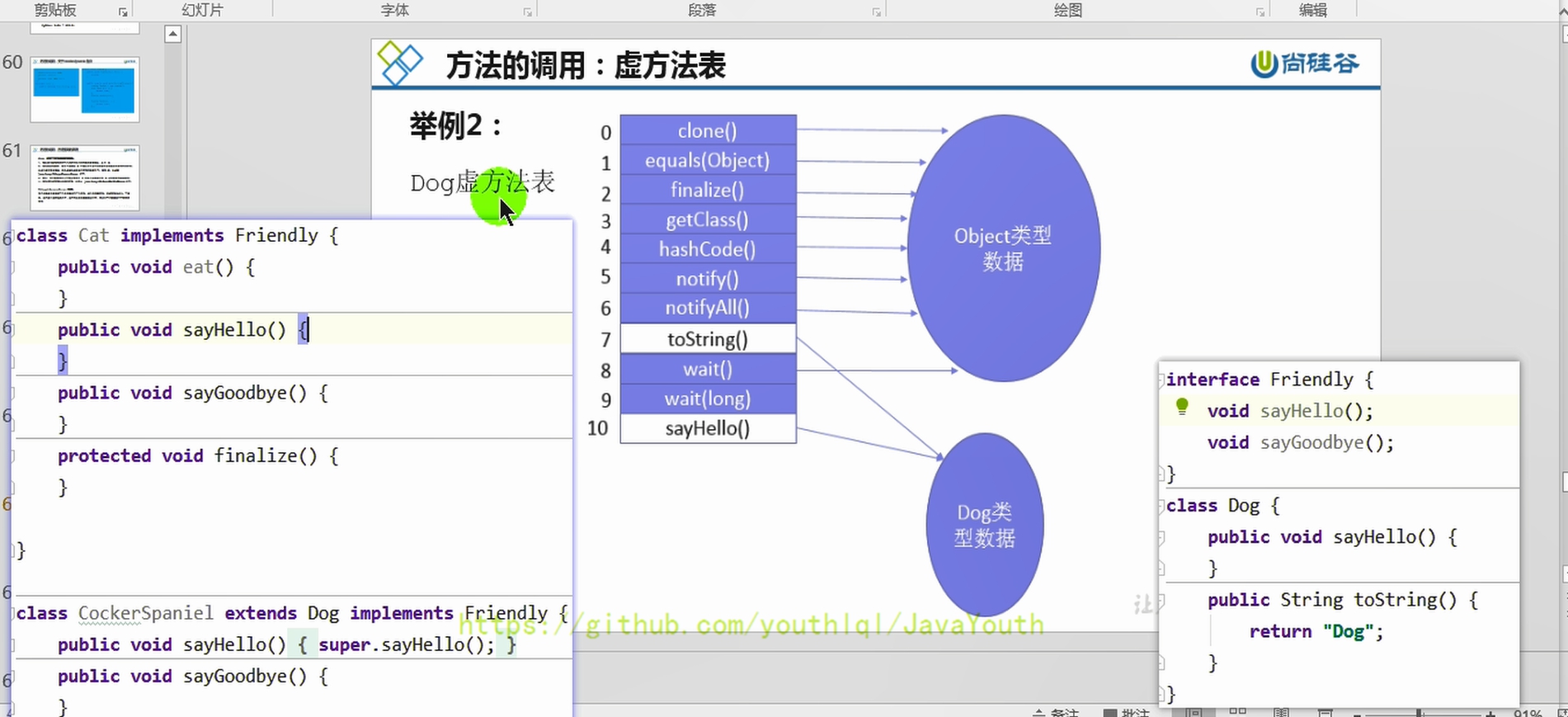 -
- +
+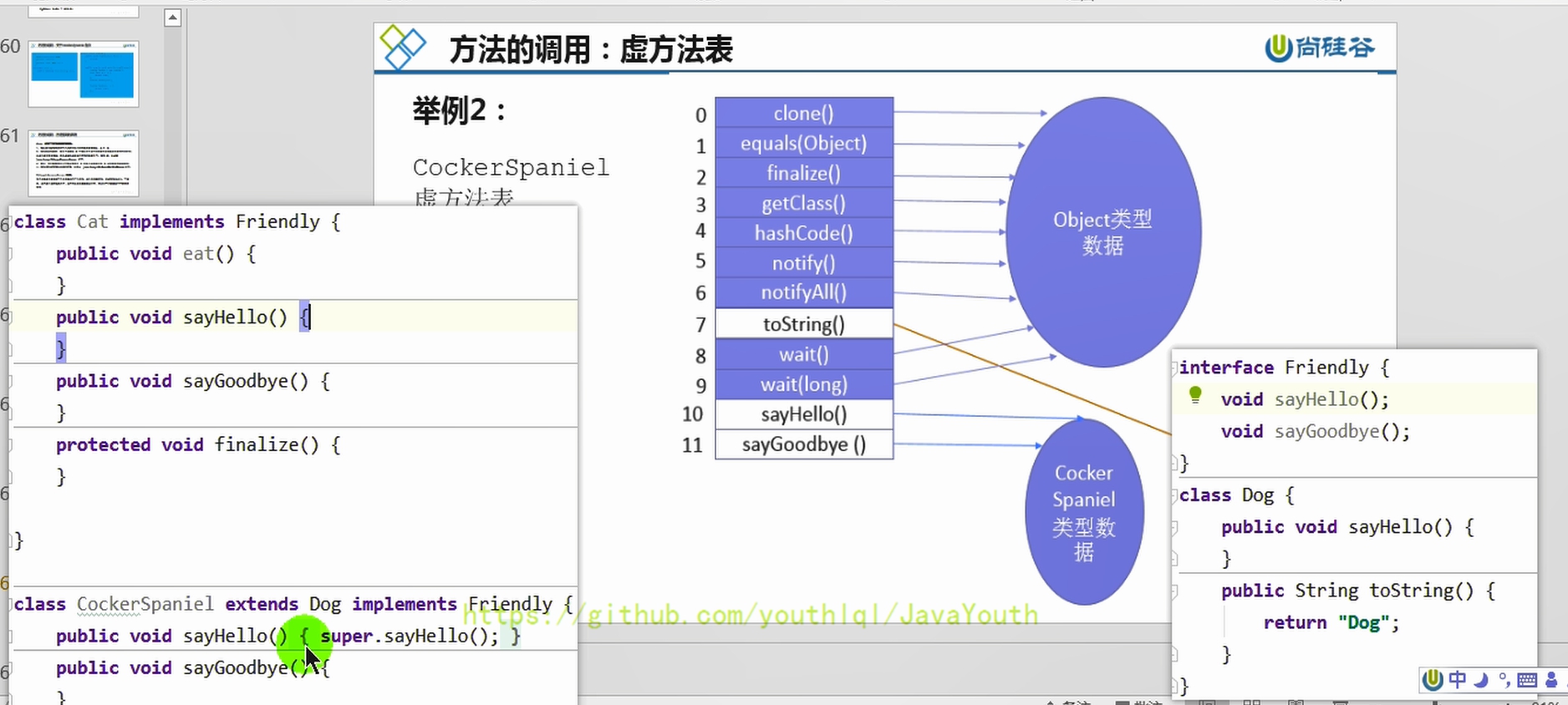 -
- +
+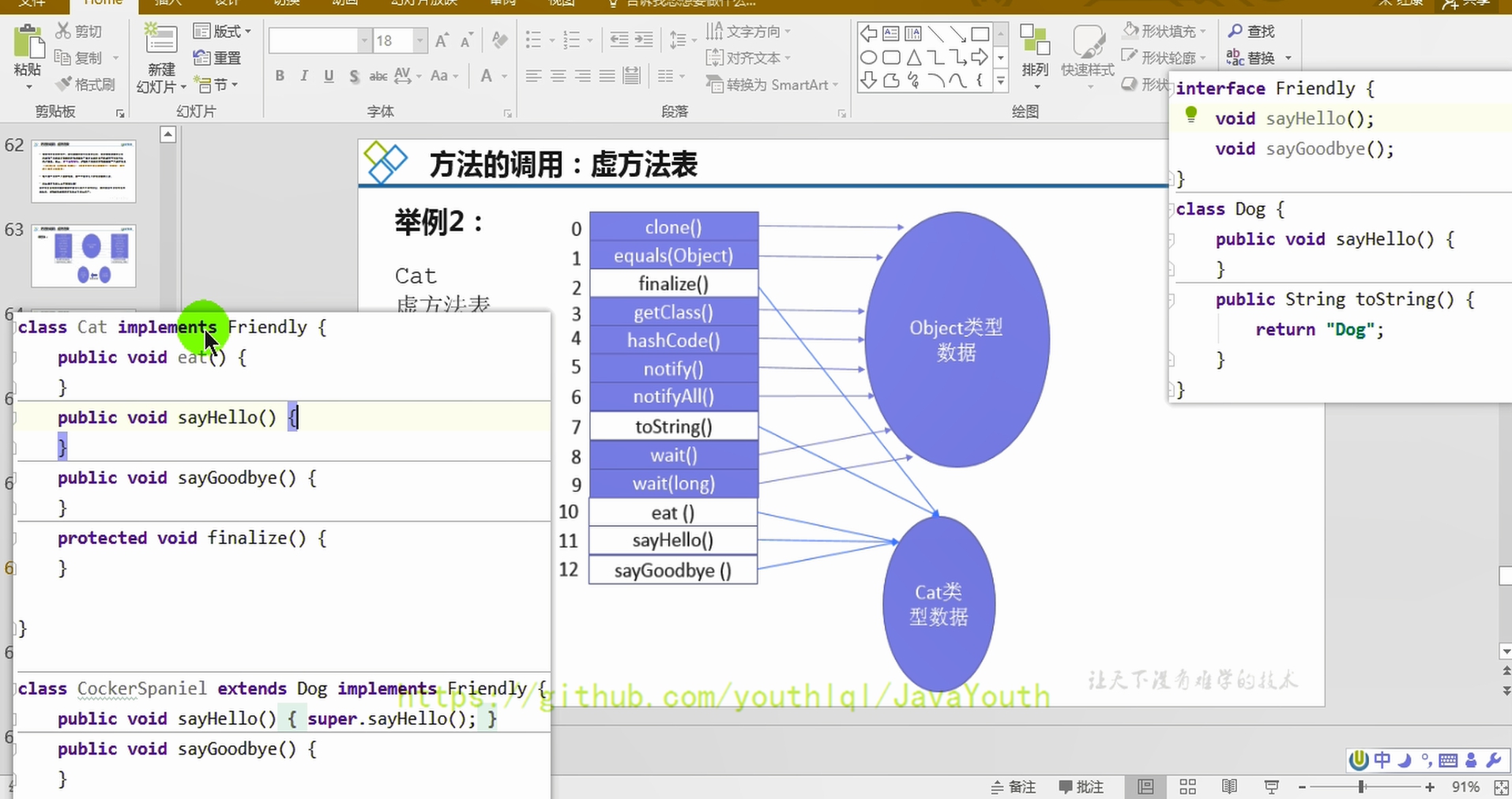 方法返回地址
--------
-
方法返回地址
--------
- +
+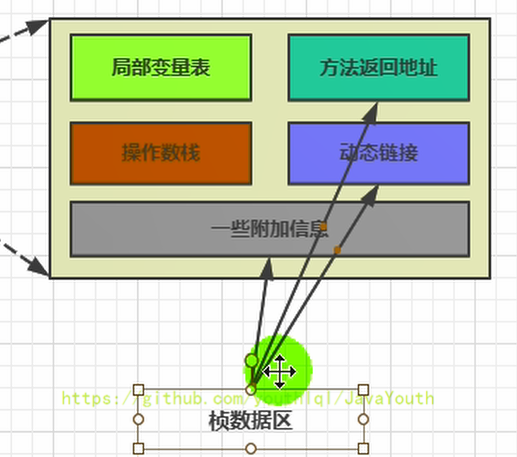 > 在一些帖子里,方法返回地址、动态链接、一些附加信息 也叫做帧数据区
@@ -1309,7 +1309,7 @@ Java:String info = "mogu blog"; (Java是静态类型语言的,会先
2. 方法执行过程中,抛出异常时的异常处理,存储在一个异常处理表,方便在发生异常的时候找到处理异常的代码
-
> 在一些帖子里,方法返回地址、动态链接、一些附加信息 也叫做帧数据区
@@ -1309,7 +1309,7 @@ Java:String info = "mogu blog"; (Java是静态类型语言的,会先
2. 方法执行过程中,抛出异常时的异常处理,存储在一个异常处理表,方便在发生异常的时候找到处理异常的代码
- +
+ @@ -1321,7 +1321,7 @@ Java:String info = "mogu blog"; (Java是静态类型语言的,会先
* target :出现异常跳转至地址为 11 的指令执行
* type :捕获异常的类型
-
@@ -1321,7 +1321,7 @@ Java:String info = "mogu blog"; (Java是静态类型语言的,会先
* target :出现异常跳转至地址为 11 的指令执行
* type :捕获异常的类型
- +
+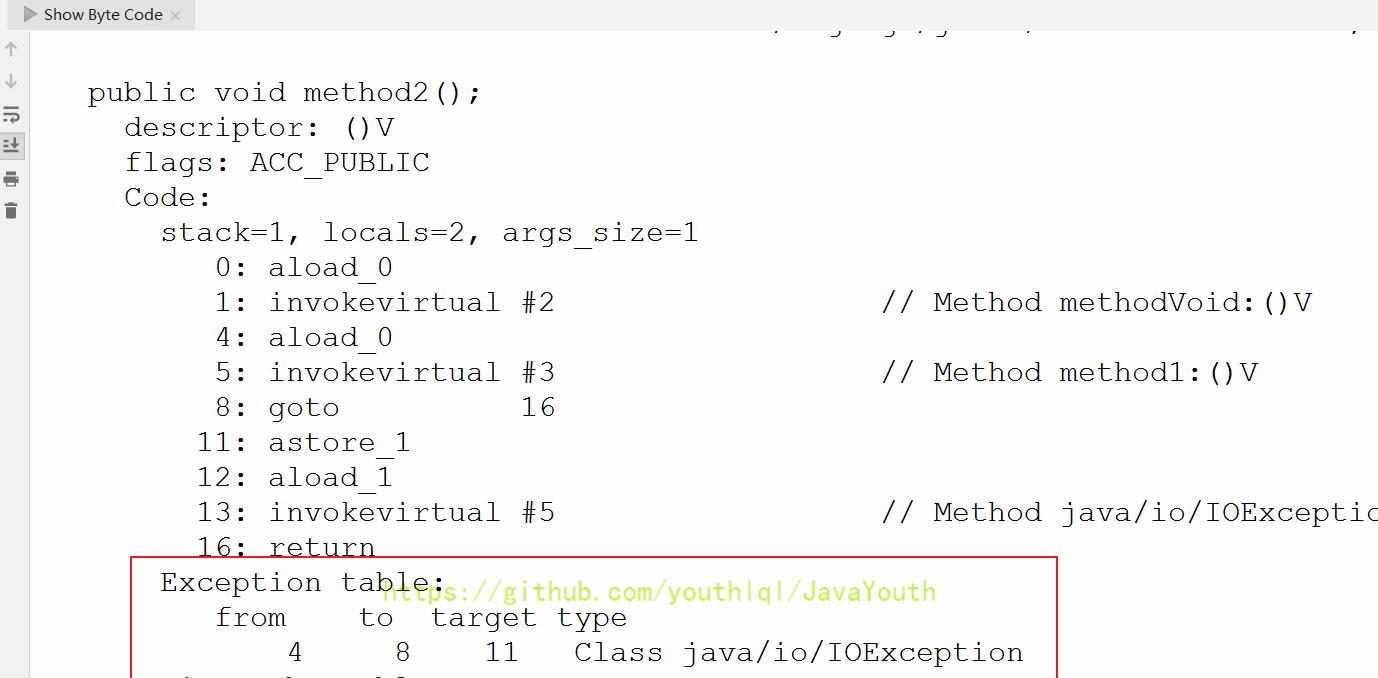 diff --git a/docs/JVM/JVM系列-第5章-堆.md b/docs/JVM/JVM系列-第5章-堆.md
index 98577fe..fb630b1 100644
--- a/docs/JVM/JVM系列-第5章-堆.md
+++ b/docs/JVM/JVM系列-第5章-堆.md
@@ -27,7 +27,7 @@ date: 2020-11-11 20:38:42
1. 堆针对一个JVM进程来说是唯一的。也就是**一个进程只有一个JVM实例**,一个JVM实例中就有一个运行时数据区,一个运行时数据区只有一个堆和一个方法区。
2. 但是**进程包含多个线程,他们是共享同一堆空间的**。
-
diff --git a/docs/JVM/JVM系列-第5章-堆.md b/docs/JVM/JVM系列-第5章-堆.md
index 98577fe..fb630b1 100644
--- a/docs/JVM/JVM系列-第5章-堆.md
+++ b/docs/JVM/JVM系列-第5章-堆.md
@@ -27,7 +27,7 @@ date: 2020-11-11 20:38:42
1. 堆针对一个JVM进程来说是唯一的。也就是**一个进程只有一个JVM实例**,一个JVM实例中就有一个运行时数据区,一个运行时数据区只有一个堆和一个方法区。
2. 但是**进程包含多个线程,他们是共享同一堆空间的**。
- +
+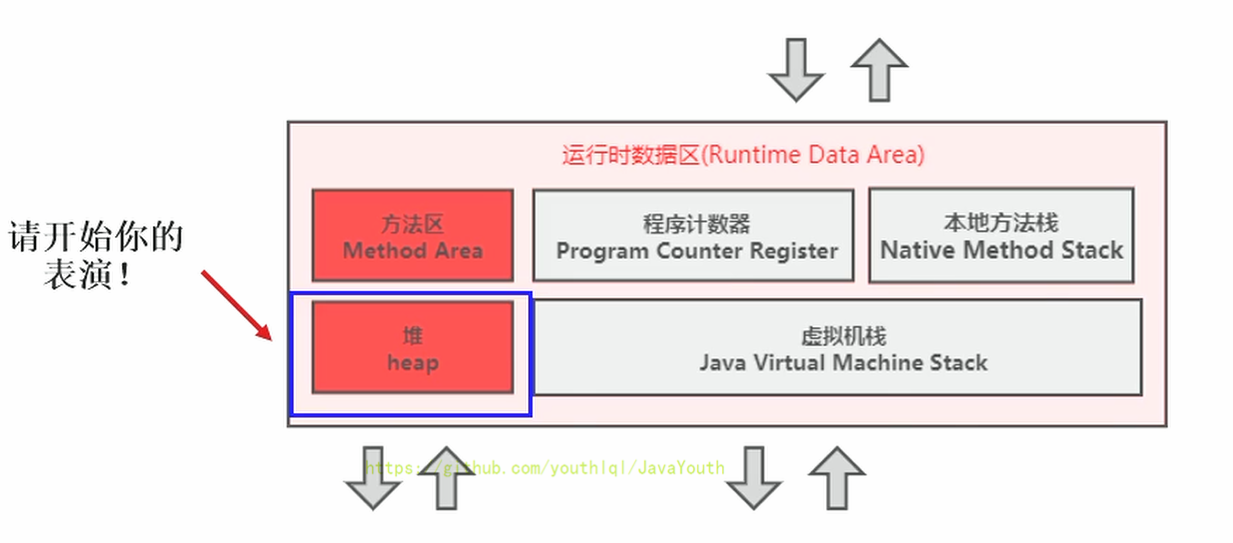 @@ -68,7 +68,7 @@ public class SimpleHeap {
}
```
-
@@ -68,7 +68,7 @@ public class SimpleHeap {
}
```
- +
+ @@ -88,13 +88,13 @@ public class SimpleHeap {
约定:新生区 <–> 新生代 <–> 年轻代 、 养老区 <–> 老年区 <–> 老年代、 永久区 <–\> 永久代
-
@@ -88,13 +88,13 @@ public class SimpleHeap {
约定:新生区 <–> 新生代 <–> 年轻代 、 养老区 <–> 老年区 <–> 老年代、 永久区 <–\> 永久代
- +
+ 2. 堆空间内部结构,JDK1.8之前从永久代 替换成 元空间
-
2. 堆空间内部结构,JDK1.8之前从永久代 替换成 元空间
- +
+ @@ -122,17 +122,17 @@ public class HeapDemo {
1、双击jdk目录下的这个文件
-
@@ -122,17 +122,17 @@ public class HeapDemo {
1、双击jdk目录下的这个文件
- +
+ 2、工具 -> 插件 -> 安装Visual GC插件
-
2、工具 -> 插件 -> 安装Visual GC插件
- +
+ 3、运行上面的代码
-
3、运行上面的代码
- +
+ @@ -215,7 +215,7 @@ public class HeapSpaceInitial {
设置下参数再看
-
@@ -215,7 +215,7 @@ public class HeapSpaceInitial {
设置下参数再看
- +
+ ```java
public class HeapSpaceInitial {
@@ -250,7 +250,7 @@ public class HeapSpaceInitial {
**方式一: jps / jstat -gc 进程id**
-
```java
public class HeapSpaceInitial {
@@ -250,7 +250,7 @@ public class HeapSpaceInitial {
**方式一: jps / jstat -gc 进程id**
- +
+ > jps:查看java进程
>
@@ -285,7 +285,7 @@ OU: 老年代使用的量
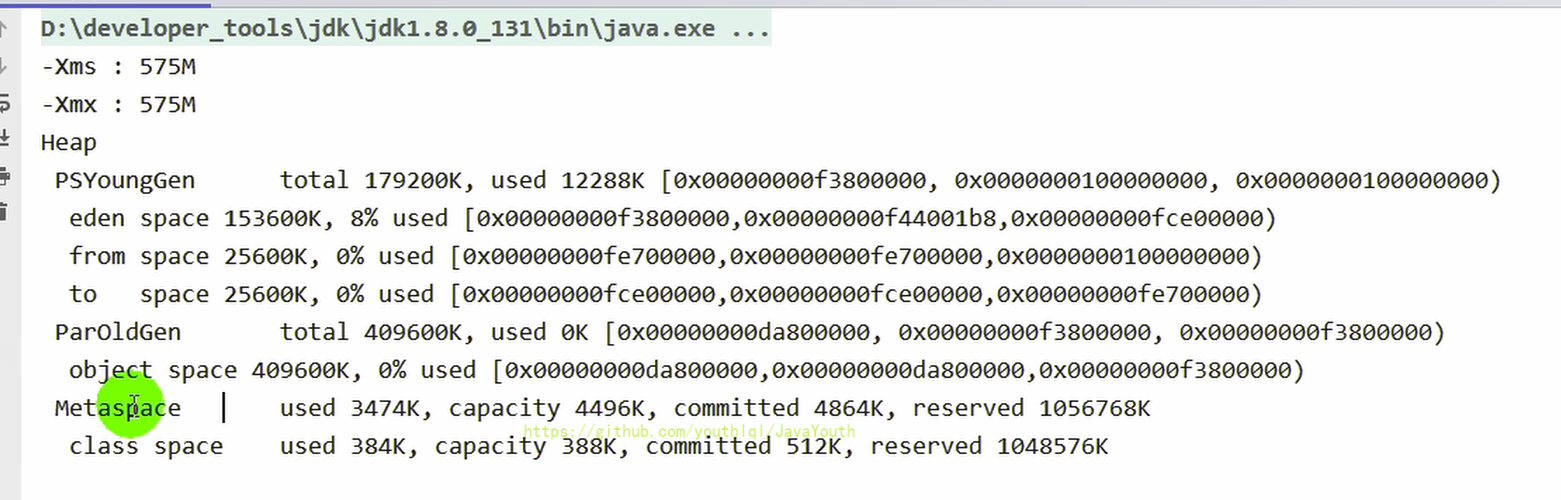
**方式二:-XX:+PrintGCDetails**
-
> jps:查看java进程
>
@@ -285,7 +285,7 @@ OU: 老年代使用的量
**方式二:-XX:+PrintGCDetails**
- +
+ @@ -333,11 +333,11 @@ Process finished with exit code 1
2、堆内存变化图
-
@@ -333,11 +333,11 @@ Process finished with exit code 1
2、堆内存变化图
- +
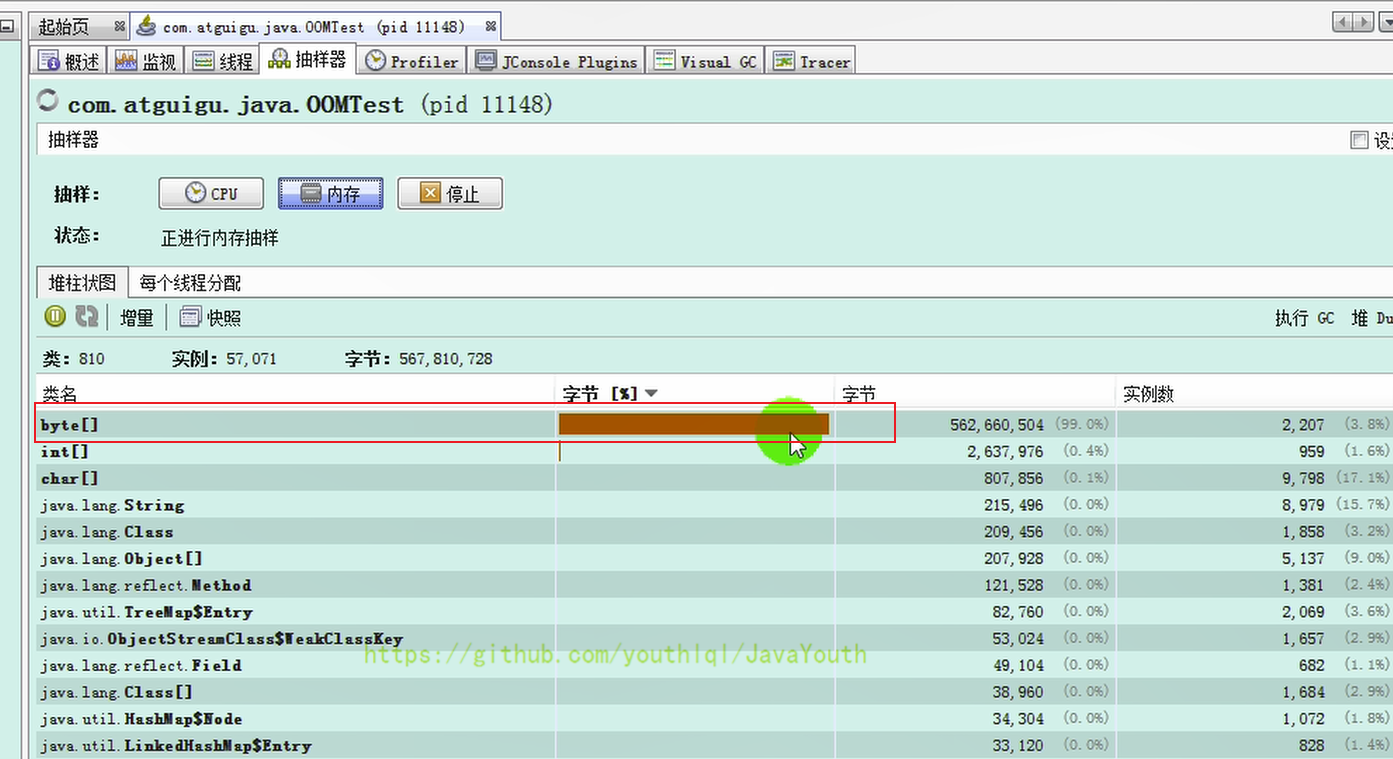
+ 3、原因:大对象导致堆内存溢出
-
3、原因:大对象导致堆内存溢出
- +
+ @@ -357,9 +357,9 @@ Process finished with exit code 1
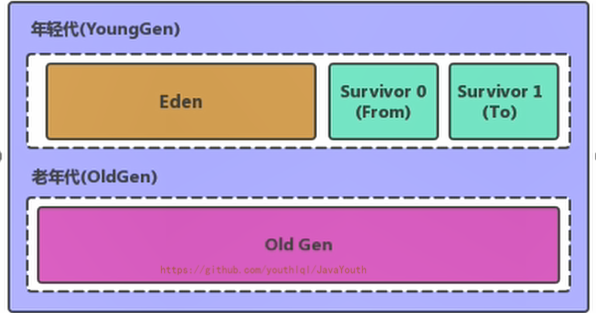
3、其中年轻代又可以划分为Eden空间、Survivor0空间和Survivor1空间(有时也叫做from区、to区)
-
@@ -357,9 +357,9 @@ Process finished with exit code 1
3、其中年轻代又可以划分为Eden空间、Survivor0空间和Survivor1空间(有时也叫做from区、to区)
- +
+ -
- +
+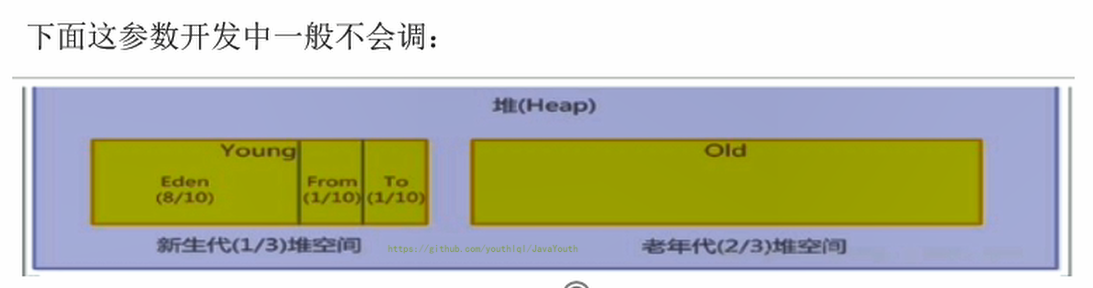 - 配置新生代与老年代在堆结构的占比
@@ -383,7 +383,7 @@ Process finished with exit code 1
-
- 配置新生代与老年代在堆结构的占比
@@ -383,7 +383,7 @@ Process finished with exit code 1
- +
+ @@ -439,7 +439,7 @@ public class EdenSurvivorTest {
1、我们创建的对象,一般都是存放在Eden区的,**当我们Eden区满了后,就会触发GC操作**,一般被称为 YGC / Minor GC操作
-
@@ -439,7 +439,7 @@ public class EdenSurvivorTest {
1、我们创建的对象,一般都是存放在Eden区的,**当我们Eden区满了后,就会触发GC操作**,一般被称为 YGC / Minor GC操作
- +
+ 2、当我们进行一次垃圾收集后,红色的对象将会被回收,而绿色的独享还被占用着,存放在S0(Survivor From)区。同时我们给每个对象设置了一个年龄计数器,经过一次回收后还存在的对象,将其年龄加 1。
@@ -453,11 +453,11 @@ public class EdenSurvivorTest {
>
> 3、也就是说s0区和s1区在互相转换。
-
2、当我们进行一次垃圾收集后,红色的对象将会被回收,而绿色的独享还被占用着,存放在S0(Survivor From)区。同时我们给每个对象设置了一个年龄计数器,经过一次回收后还存在的对象,将其年龄加 1。
@@ -453,11 +453,11 @@ public class EdenSurvivorTest {
>
> 3、也就是说s0区和s1区在互相转换。
- +
+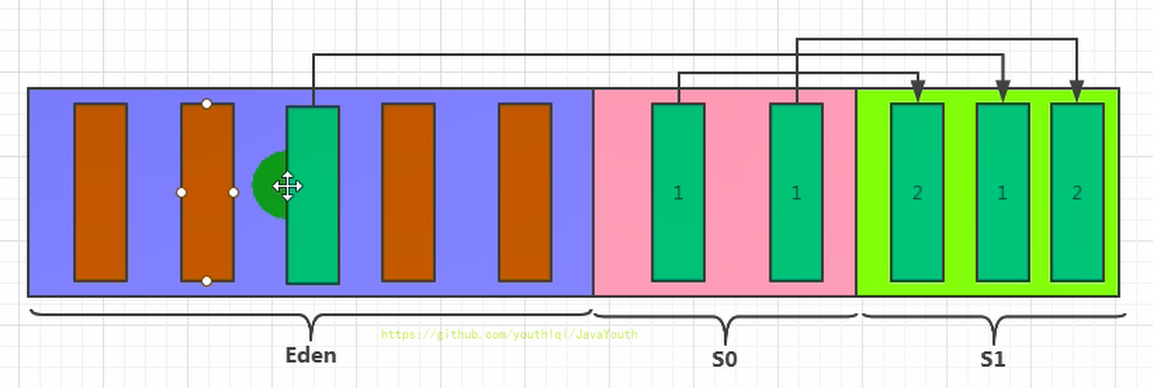 4、我们继续不断的进行对象生成和垃圾回收,当Survivor中的对象的年龄达到15的时候,将会触发一次 Promotion 晋升的操作,也就是将年轻代中的对象晋升到老年代中
-
4、我们继续不断的进行对象生成和垃圾回收,当Survivor中的对象的年龄达到15的时候,将会触发一次 Promotion 晋升的操作,也就是将年轻代中的对象晋升到老年代中
- +
+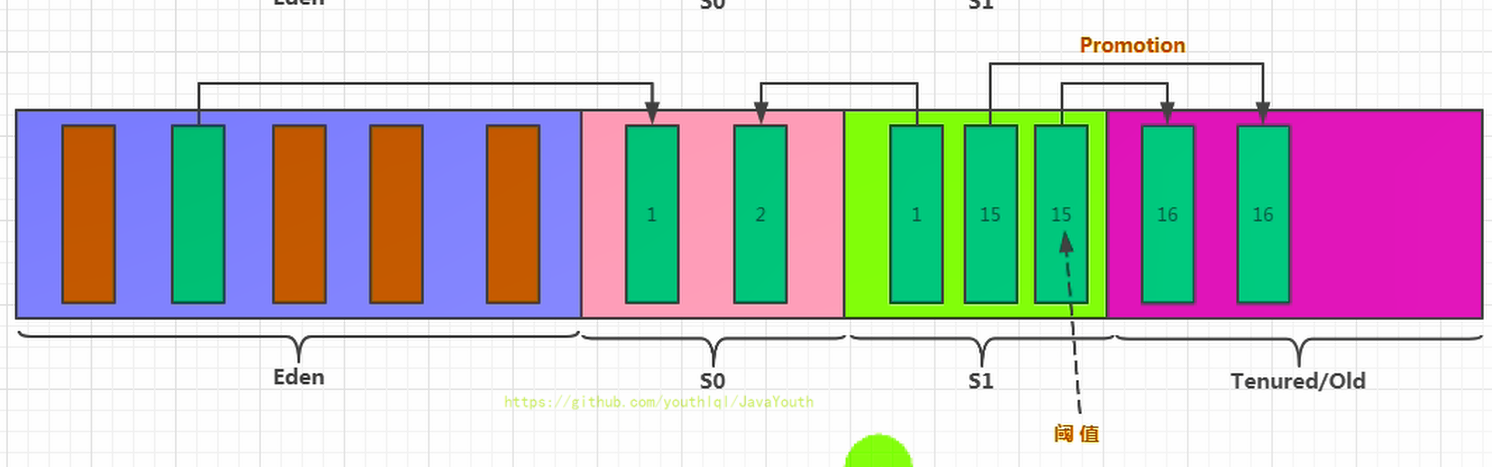 关于垃圾回收:频繁在新生区收集,很少在养老区收集,几乎不在永久区/元空间收集。
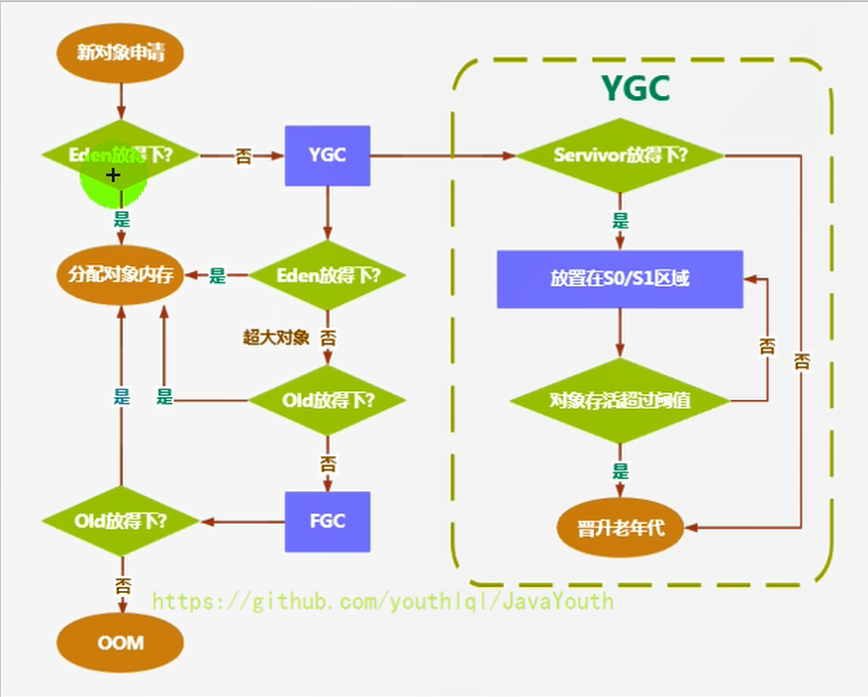
@@ -475,7 +475,7 @@ public class EdenSurvivorTest {
* 那万一老年代都放不下,则先触发FullGC ,再看看能不能放下,放得下最好,但如果还是放不下,那只能报 OOM
3. 如果 Eden 区满了,将对象往幸存区拷贝时,发现幸存区放不下啦,那只能便宜了某些新对象,让他们直接晋升至老年区
-
关于垃圾回收:频繁在新生区收集,很少在养老区收集,几乎不在永久区/元空间收集。
@@ -475,7 +475,7 @@ public class EdenSurvivorTest {
* 那万一老年代都放不下,则先触发FullGC ,再看看能不能放下,放得下最好,但如果还是放不下,那只能报 OOM
3. 如果 Eden 区满了,将对象往幸存区拷贝时,发现幸存区放不下啦,那只能便宜了某些新对象,让他们直接晋升至老年区
- +
+ ### 常用调优工具
@@ -528,7 +528,7 @@ GC分类
3. Minor GC会引发STW(Stop The World),暂停其它用户的线程,等垃圾回收结束,用户线程才恢复运行
-
### 常用调优工具
@@ -528,7 +528,7 @@ GC分类
3. Minor GC会引发STW(Stop The World),暂停其它用户的线程,等垃圾回收结束,用户线程才恢复运行
- +
+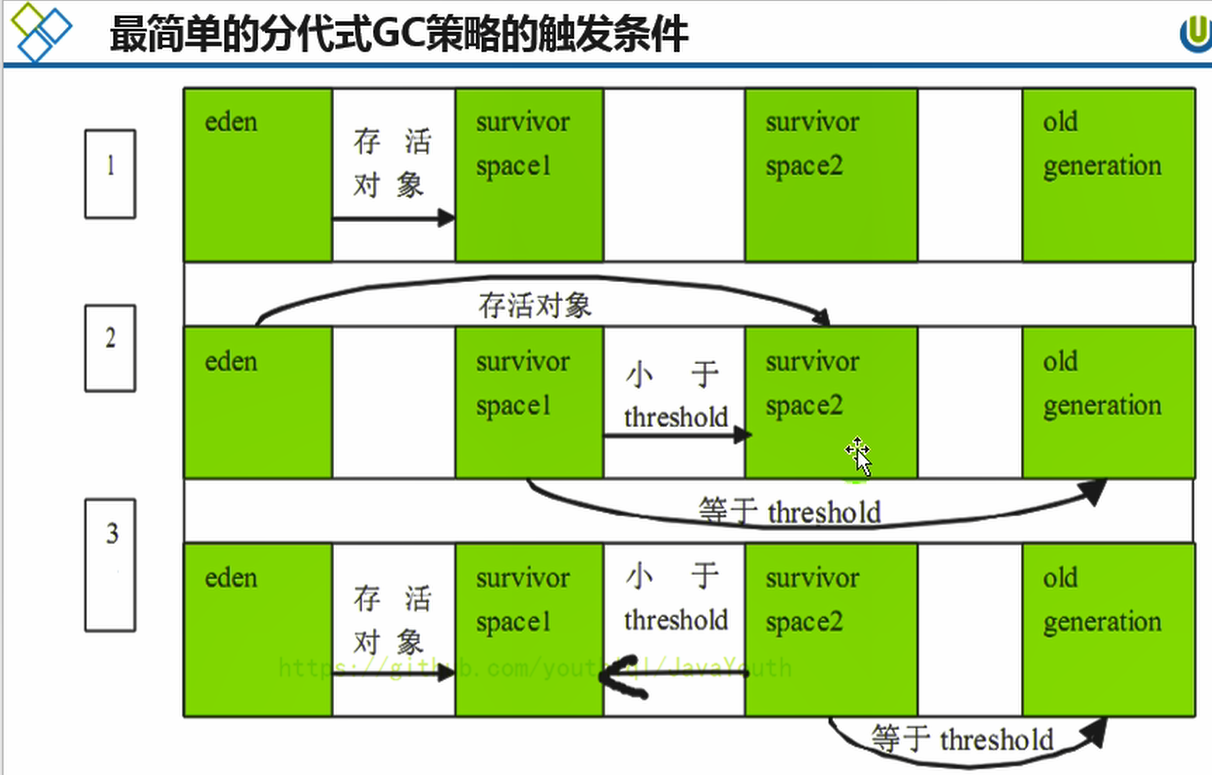 @@ -649,7 +649,7 @@ Heap
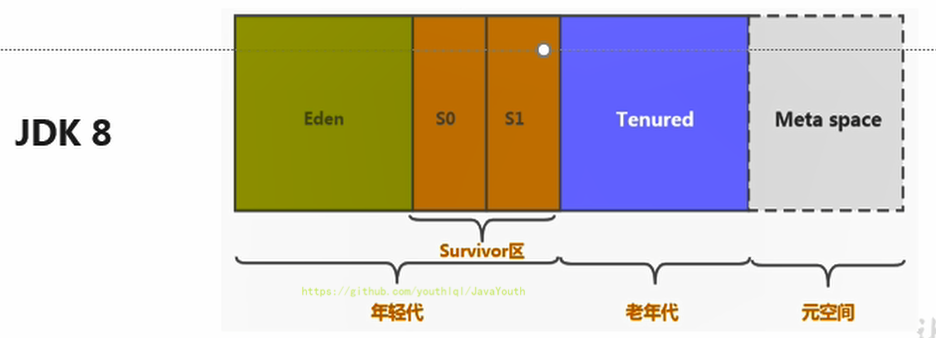
* 新生代:有Eden、两块大小相同的survivor(又称为from/to或s0/s1)构成,to总为空。
* 老年代:存放新生代中经历多次GC仍然存活的对象。
-
@@ -649,7 +649,7 @@ Heap
* 新生代:有Eden、两块大小相同的survivor(又称为from/to或s0/s1)构成,to总为空。
* 老年代:存放新生代中经历多次GC仍然存活的对象。
- +
+ @@ -661,7 +661,7 @@ Heap
-
@@ -661,7 +661,7 @@ Heap
- +
+ @@ -711,7 +711,7 @@ TLAB(Thread Local Allocation Buffer)
2. 多线程同时分配内存时,使用TLAB可以避免一系列的非线程安全问题,同时还能够提升内存分配的吞吐量,因此我们可以将这种内存分配方式称之为**快速分配策略**。
3. 据我所知所有OpenJDK衍生出来的JVM都提供了TLAB的设计。
-
@@ -711,7 +711,7 @@ TLAB(Thread Local Allocation Buffer)
2. 多线程同时分配内存时,使用TLAB可以避免一系列的非线程安全问题,同时还能够提升内存分配的吞吐量,因此我们可以将这种内存分配方式称之为**快速分配策略**。
3. 据我所知所有OpenJDK衍生出来的JVM都提供了TLAB的设计。
- +
+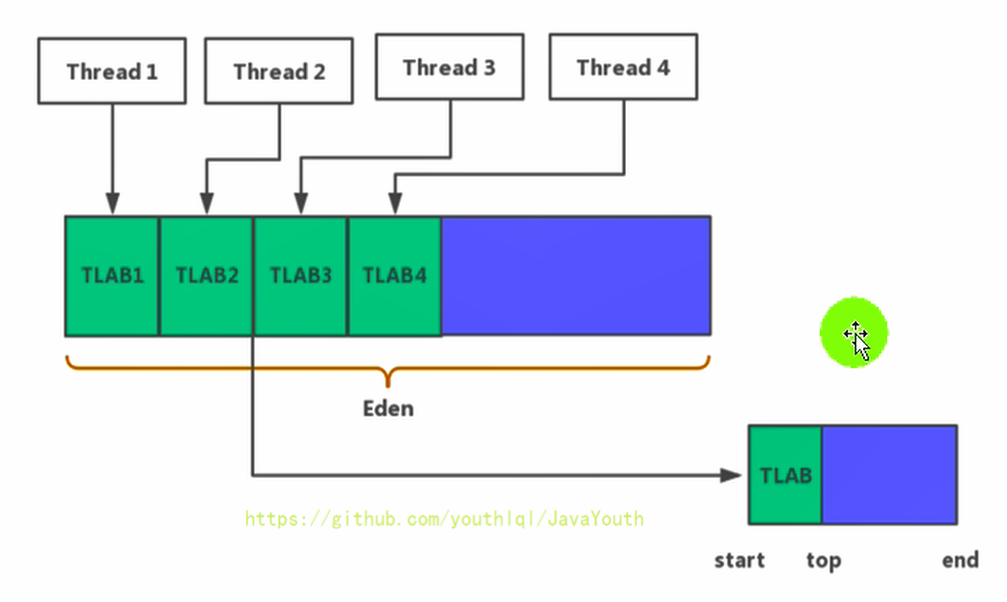 1、每个线程都有一个TLAB空间
@@ -741,7 +741,7 @@ TLAB(Thread Local Allocation Buffer)
**TLAB 分配过程**
-
1、每个线程都有一个TLAB空间
@@ -741,7 +741,7 @@ TLAB(Thread Local Allocation Buffer)
**TLAB 分配过程**
- +
+ diff --git a/docs/JVM/JVM系列-第6章-方法区.md b/docs/JVM/JVM系列-第6章-方法区.md
index 791b7e4..c3acc55 100644
--- a/docs/JVM/JVM系列-第6章-方法区.md
+++ b/docs/JVM/JVM系列-第6章-方法区.md
@@ -24,7 +24,7 @@ date: 2020-11-13 19:38:42
ThreadLocal:如何保证多个线程在并发环境下的安全性?典型场景就是数据库连接管理,以及会话管理。
-
diff --git a/docs/JVM/JVM系列-第6章-方法区.md b/docs/JVM/JVM系列-第6章-方法区.md
index 791b7e4..c3acc55 100644
--- a/docs/JVM/JVM系列-第6章-方法区.md
+++ b/docs/JVM/JVM系列-第6章-方法区.md
@@ -24,7 +24,7 @@ date: 2020-11-13 19:38:42
ThreadLocal:如何保证多个线程在并发环境下的安全性?典型场景就是数据库连接管理,以及会话管理。
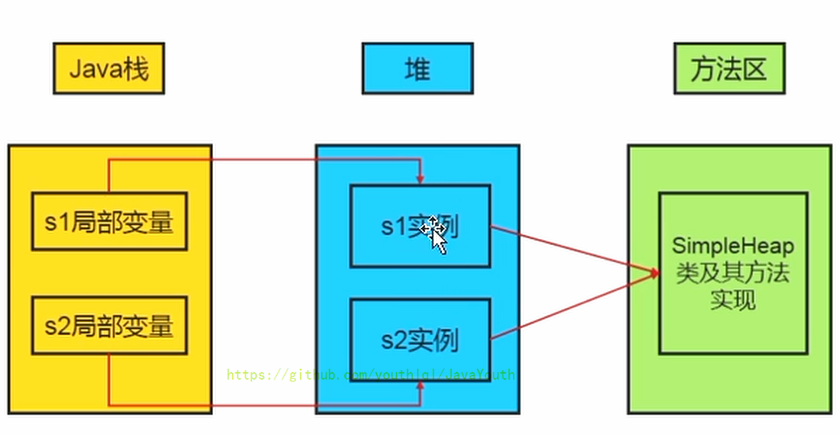
- +
+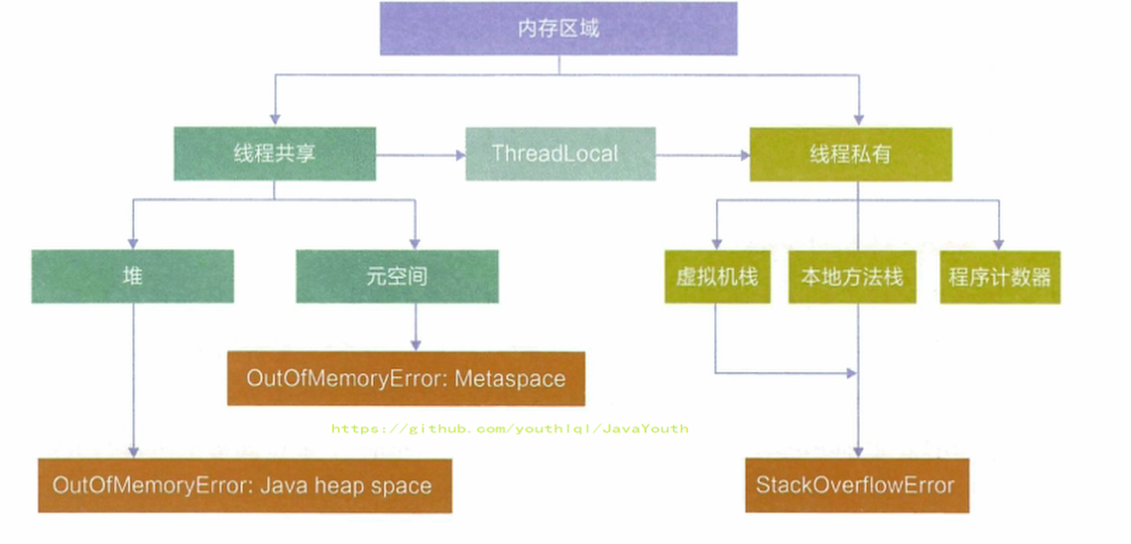 **栈、堆、方法区的交互关系**
@@ -35,7 +35,7 @@ ThreadLocal:如何保证多个线程在并发环境下的安全性?典型场
3. 真正的 person 对象存放在 Java 堆中
4. 在 person 对象中,有个指针指向方法区中的 person 类型数据,表明这个 person 对象是用方法区中的 Person 类 new 出来的
-
**栈、堆、方法区的交互关系**
@@ -35,7 +35,7 @@ ThreadLocal:如何保证多个线程在并发环境下的安全性?典型场
3. 真正的 person 对象存放在 Java 堆中
4. 在 person 对象中,有个指针指向方法区中的 person 类型数据,表明这个 person 对象是用方法区中的 Person 类 new 出来的
- +
+ 方法区的理解
--------
@@ -47,7 +47,7 @@ ThreadLocal:如何保证多个线程在并发环境下的安全性?典型场
1. 《Java虚拟机规范》中明确说明:尽管所有的方法区在逻辑上是属于堆的一部分,但一些简单的实现可能不会选择去进行垃圾收集或者进行压缩。但对于HotSpotJVM而言,方法区还有一个别名叫做Non-Heap(非堆),目的就是要和堆分开。
3. 所以,**方法区可以看作是一块独立于Java堆的内存空间**。
-
方法区的理解
--------
@@ -47,7 +47,7 @@ ThreadLocal:如何保证多个线程在并发环境下的安全性?典型场
1. 《Java虚拟机规范》中明确说明:尽管所有的方法区在逻辑上是属于堆的一部分,但一些简单的实现可能不会选择去进行垃圾收集或者进行压缩。但对于HotSpotJVM而言,方法区还有一个别名叫做Non-Heap(非堆),目的就是要和堆分开。
3. 所以,**方法区可以看作是一块独立于Java堆的内存空间**。
- +
+ @@ -87,7 +87,7 @@ public class MethodAreaDemo {
简单的程序,加载了1600多个类
-
@@ -87,7 +87,7 @@ public class MethodAreaDemo {
简单的程序,加载了1600多个类
- +
+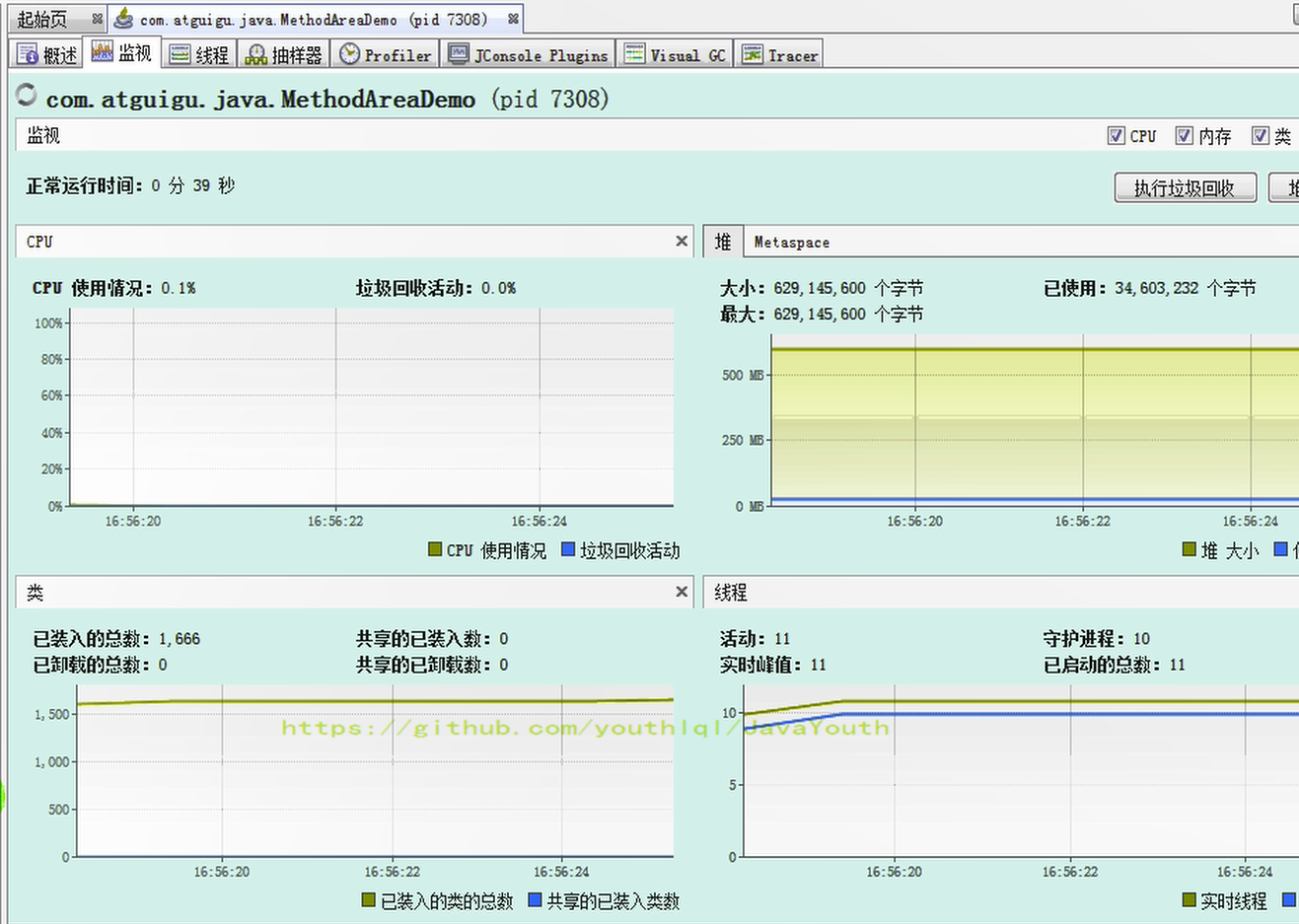 @@ -103,7 +103,7 @@ public class MethodAreaDemo {
5. 永久代、元空间二者并不只是名字变了,内部结构也调整了
6. 根据《Java虚拟机规范》的规定,如果方法区无法满足新的内存分配需求时,将抛出OOM异常
-
@@ -103,7 +103,7 @@ public class MethodAreaDemo {
5. 永久代、元空间二者并不只是名字变了,内部结构也调整了
6. 根据《Java虚拟机规范》的规定,如果方法区无法满足新的内存分配需求时,将抛出OOM异常
- +
+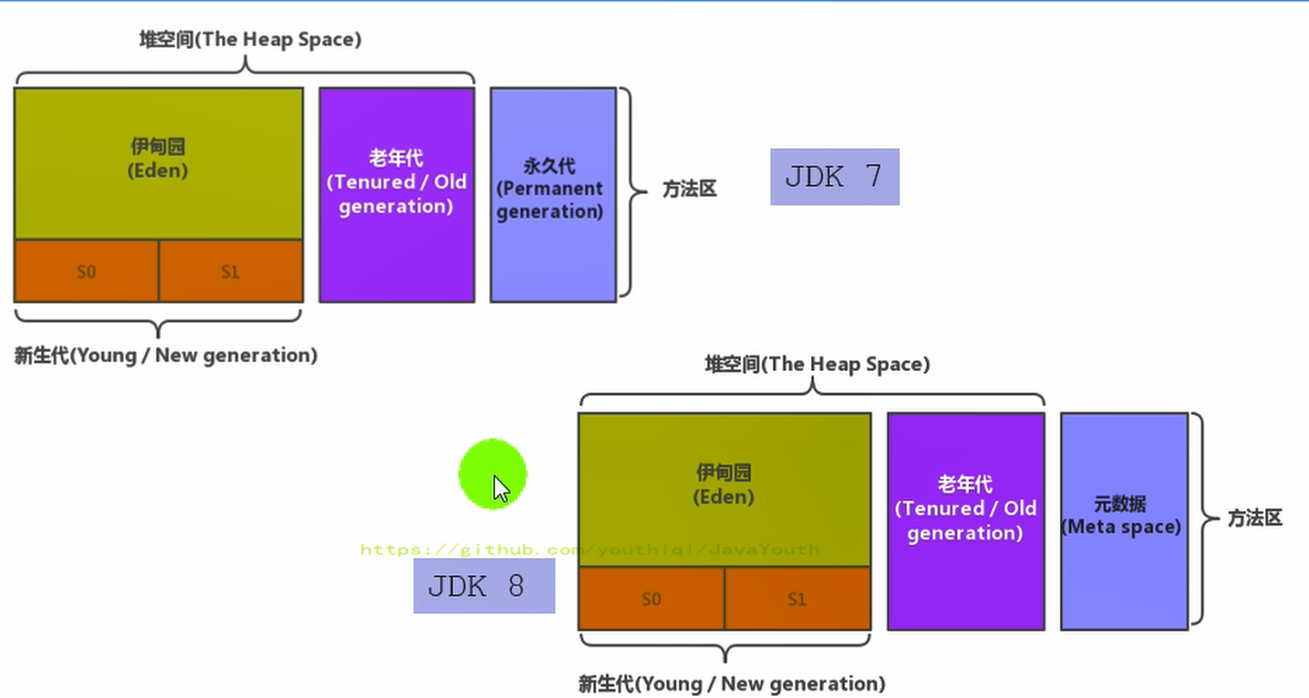 @@ -120,7 +120,7 @@ public class MethodAreaDemo {
2. -XX:MaxPermsize来设定永久代最大可分配空间。32位机器默认是64M,64位机器模式是82M
3. 当JVM加载的类信息容量超过了这个值,会报异常OutofMemoryError:PermGen space。
-
@@ -120,7 +120,7 @@ public class MethodAreaDemo {
2. -XX:MaxPermsize来设定永久代最大可分配空间。32位机器默认是64M,64位机器模式是82M
3. 当JVM加载的类信息容量超过了这个值,会报异常OutofMemoryError:PermGen space。
- +
+ ### JDK8及以后(元空间)
@@ -228,11 +228,11 @@ Exception in thread "main" java.lang.OutOfMemoryError: Metaspace
#### 概念
-
### JDK8及以后(元空间)
@@ -228,11 +228,11 @@ Exception in thread "main" java.lang.OutOfMemoryError: Metaspace
#### 概念
- +
+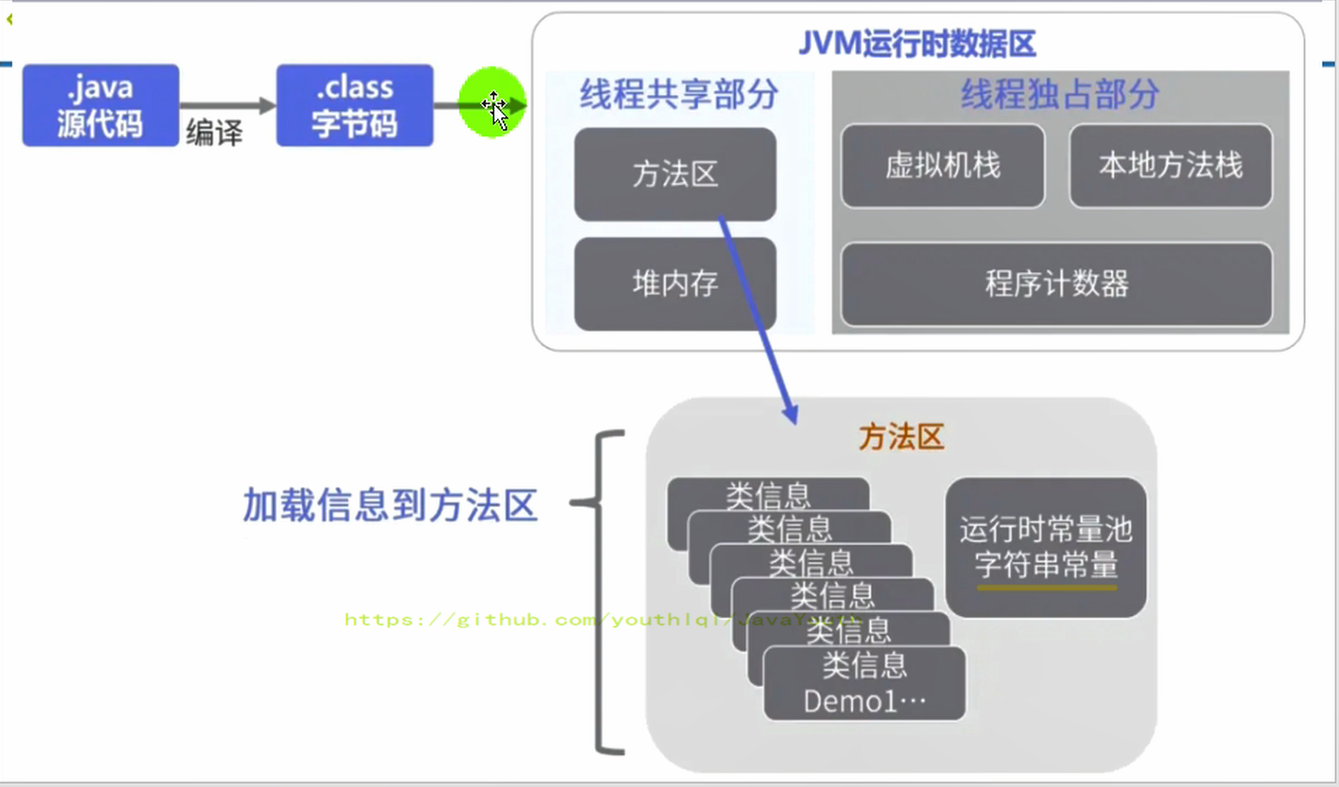 《深入理解Java虚拟机》书中对方法区(Method Area)存储内容描述如下:它用于存储已被虚拟机加载的**类型信息、常量、静态变量、即时编译器编译后的代码缓存**等。
-
《深入理解Java虚拟机》书中对方法区(Method Area)存储内容描述如下:它用于存储已被虚拟机加载的**类型信息、常量、静态变量、即时编译器编译后的代码缓存**等。
- +
+ @@ -714,7 +714,7 @@ public static int count;
-
@@ -714,7 +714,7 @@ public static int count;
- +
+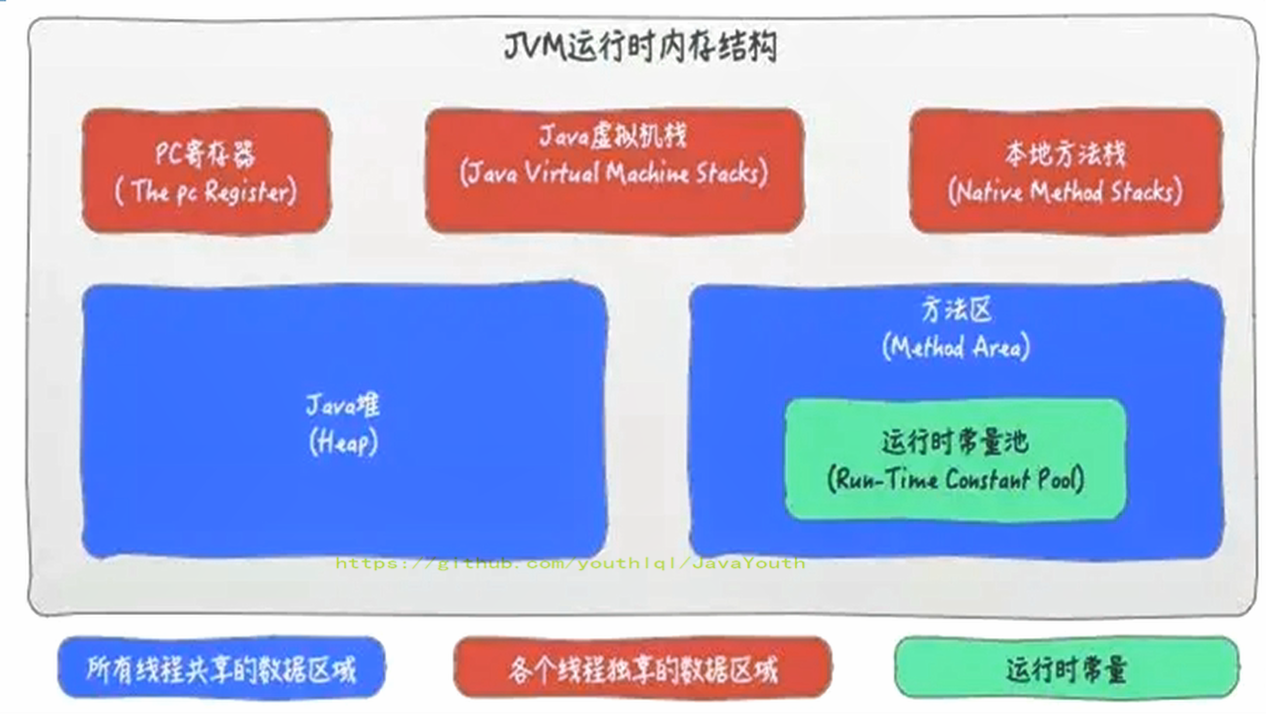 1. 方法区,内部包含了运行时常量池
2. 字节码文件,内部包含了常量池。(之前的字节码文件中已经看到了很多Constant pool的东西,这个就是常量池)
@@ -728,7 +728,7 @@ public static int count;
1. 一个有效的字节码文件中除了包含类的版本信息、字段、方法以及接口等描述符信息外。还包含一项信息就是**常量池表**(**Constant Pool Table**),包括各种字面量和对类型、域和方法的符号引用。
2. 字面量: 10 , “我是某某”这种数字和字符串都是字面量
-
1. 方法区,内部包含了运行时常量池
2. 字节码文件,内部包含了常量池。(之前的字节码文件中已经看到了很多Constant pool的东西,这个就是常量池)
@@ -728,7 +728,7 @@ public static int count;
1. 一个有效的字节码文件中除了包含类的版本信息、字段、方法以及接口等描述符信息外。还包含一项信息就是**常量池表**(**Constant Pool Table**),包括各种字面量和对类型、域和方法的符号引用。
2. 字面量: 10 , “我是某某”这种数字和字符串都是字面量
- +
+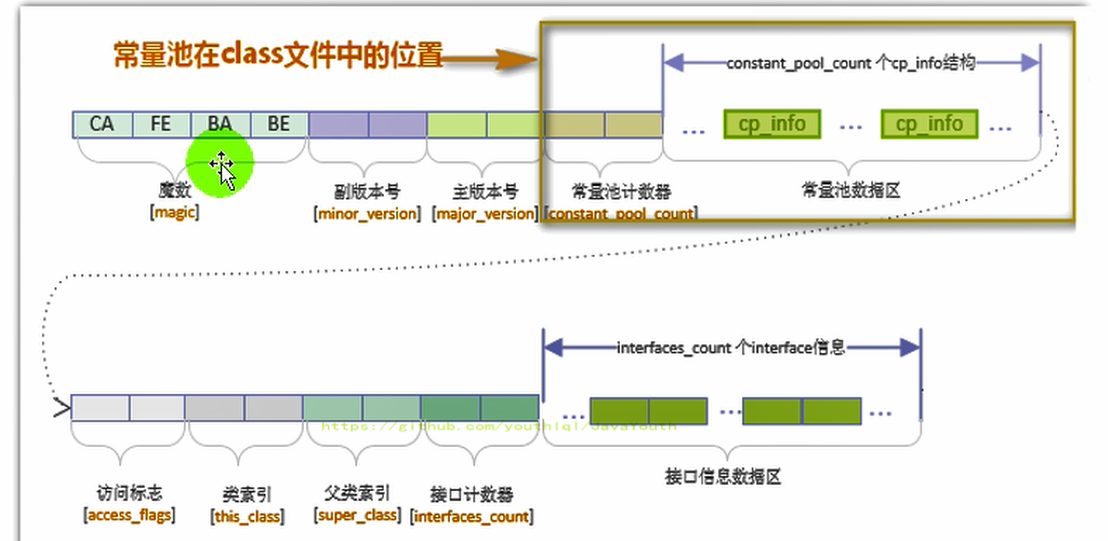 **为什么需要常量池?**
@@ -749,7 +749,7 @@ public static int count;
2. 比如说我们这个文件中有6个地方用到了"hello"这个字符串,如果不用常量池,就需要在6个地方全写一遍,造成臃肿。我们可以将"hello"等所需用到的结构信息记录在常量池中,并通过**引用的方式**,来加载、调用所需的结构
4. 这里的代码量其实很少了,如果代码多的话,引用的结构将会更多,这里就需要用到常量池了。
-
**为什么需要常量池?**
@@ -749,7 +749,7 @@ public static int count;
2. 比如说我们这个文件中有6个地方用到了"hello"这个字符串,如果不用常量池,就需要在6个地方全写一遍,造成臃肿。我们可以将"hello"等所需用到的结构信息记录在常量池中,并通过**引用的方式**,来加载、调用所需的结构
4. 这里的代码量其实很少了,如果代码多的话,引用的结构将会更多,这里就需要用到常量池了。
- +
+ **常量池中有啥?**
@@ -924,69 +924,69 @@ SourceFile: "MethodAreaDemo.java"
1、初始状态
-
**常量池中有啥?**
@@ -924,69 +924,69 @@ SourceFile: "MethodAreaDemo.java"
1、初始状态
- +
+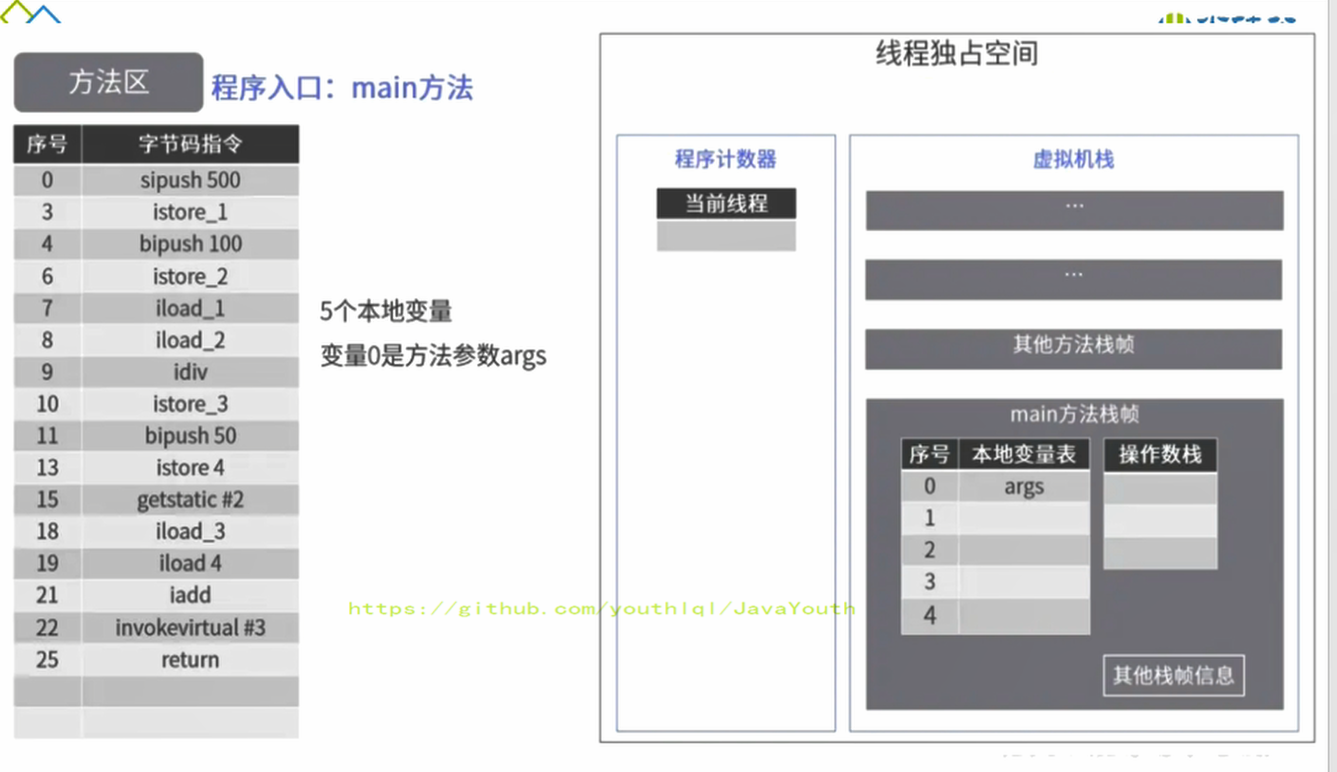 2、首先将操作数500压入操作数栈中
-
2、首先将操作数500压入操作数栈中
- +
+ 3、然后操作数 500 从操作数栈中取出,存储到局部变量表中索引为 1 的位置
-
3、然后操作数 500 从操作数栈中取出,存储到局部变量表中索引为 1 的位置
- +
+ 4、
-
4、
- +
+ 5、
-
5、
- +
+ 6、
-
6、
- +
+ 7、
-
7、
- +
+ 8、
-
8、
- +
+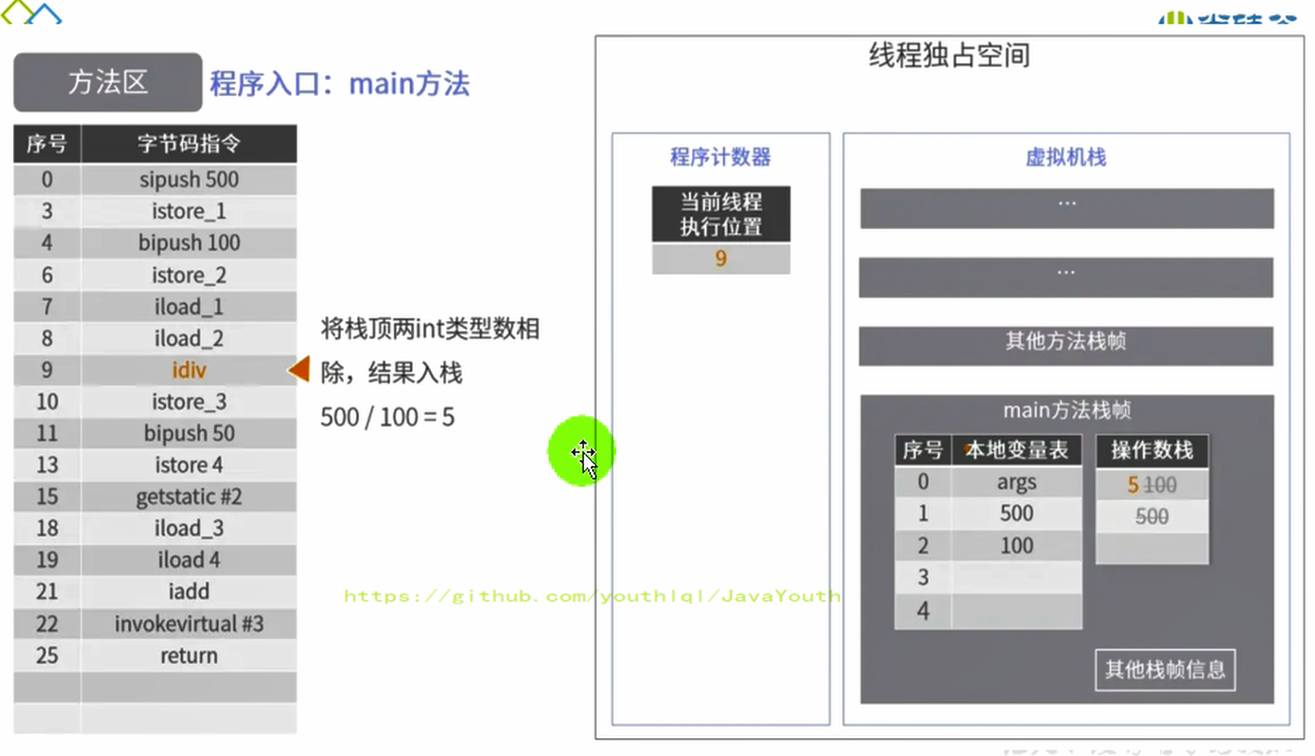 9、
-
9、
- +
+ 10、
-
10、
- +
+ 11、图片写错了是#25和#26(获得System类)
-
11、图片写错了是#25和#26(获得System类)
- +
+ 12、
-
12、
- +
+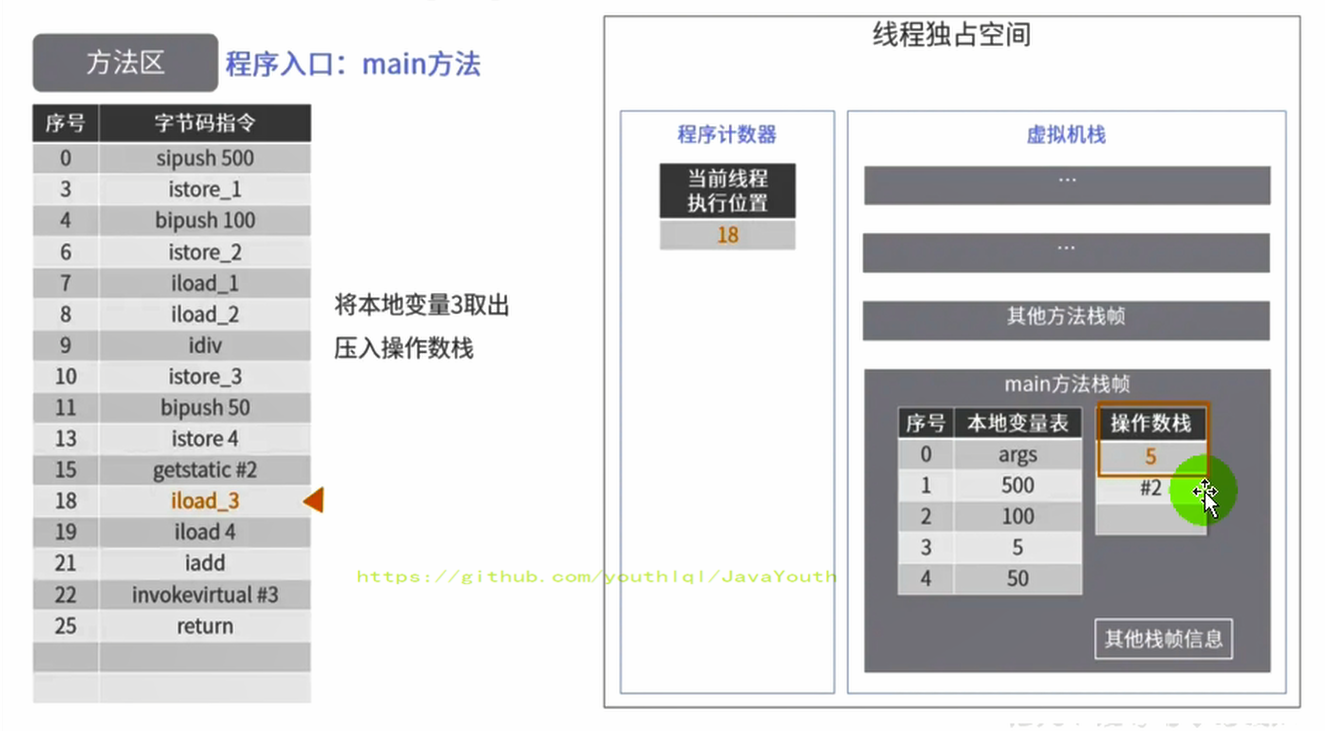 13、
-
13、
- +
+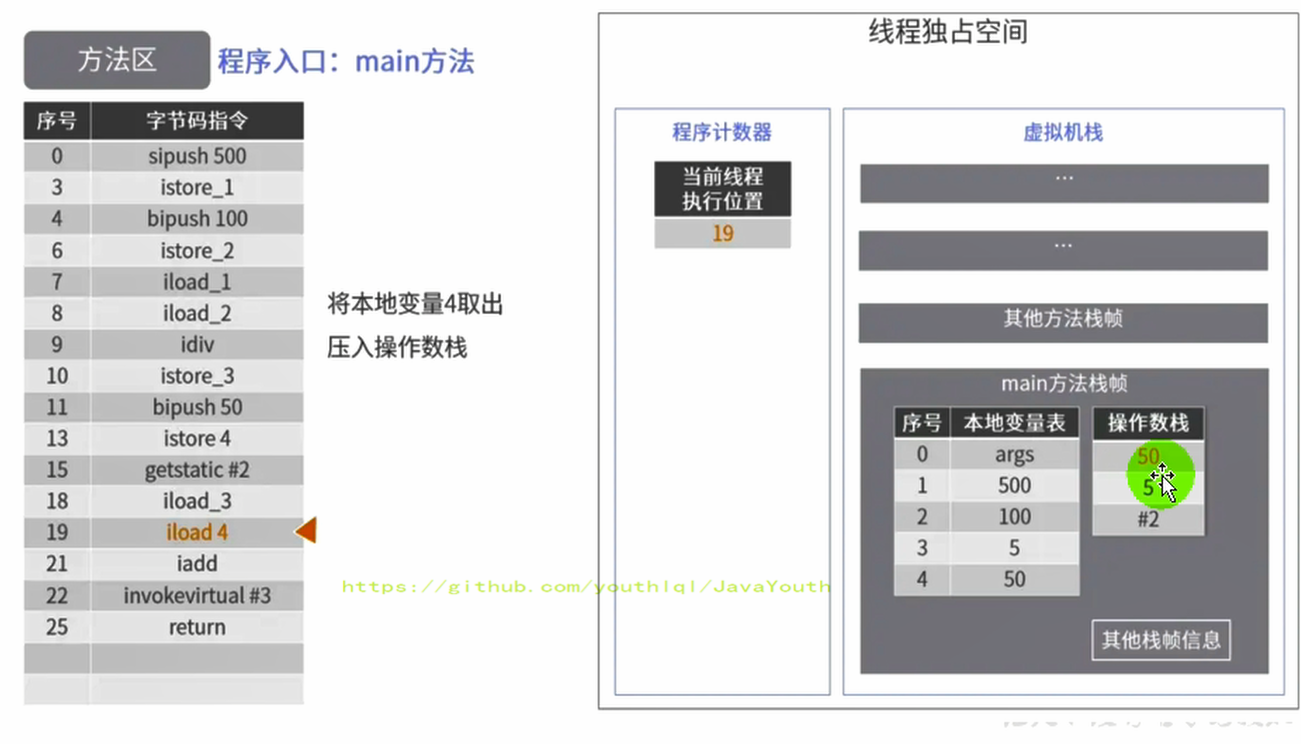 15、执行加法运算后,将计算结果放在操作数栈顶
-
15、执行加法运算后,将计算结果放在操作数栈顶
- +
+ 16、就是真正的打印
-
16、就是真正的打印
- +
+ 17、
-
17、
- +
+ @@ -1021,7 +1021,7 @@ SourceFile: "MethodAreaDemo.java"
方法区由永久代实现,使用 JVM 虚拟机内存(虚拟的内存)
-
@@ -1021,7 +1021,7 @@ SourceFile: "MethodAreaDemo.java"
方法区由永久代实现,使用 JVM 虚拟机内存(虚拟的内存)
- +
+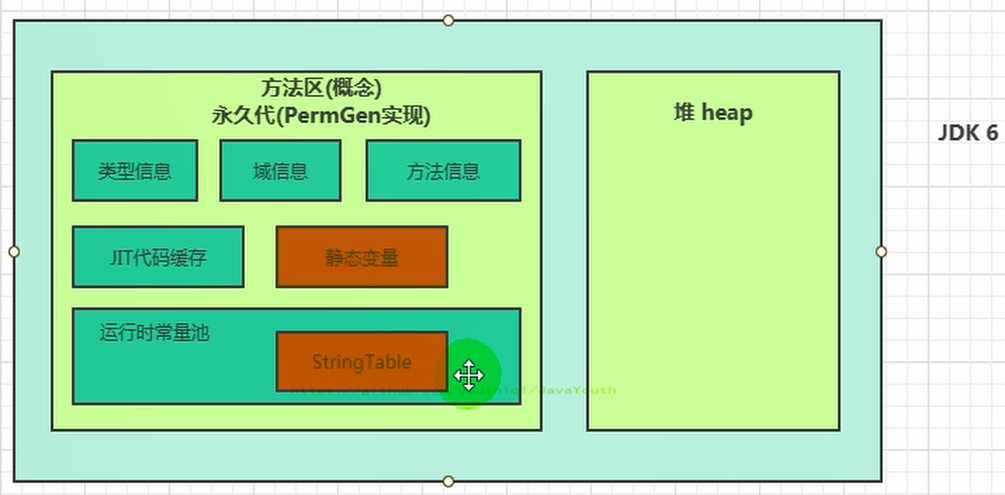 @@ -1029,7 +1029,7 @@ SourceFile: "MethodAreaDemo.java"
方法区由永久代实现,使用 JVM 虚拟机内存
-
@@ -1029,7 +1029,7 @@ SourceFile: "MethodAreaDemo.java"
方法区由永久代实现,使用 JVM 虚拟机内存
- +
+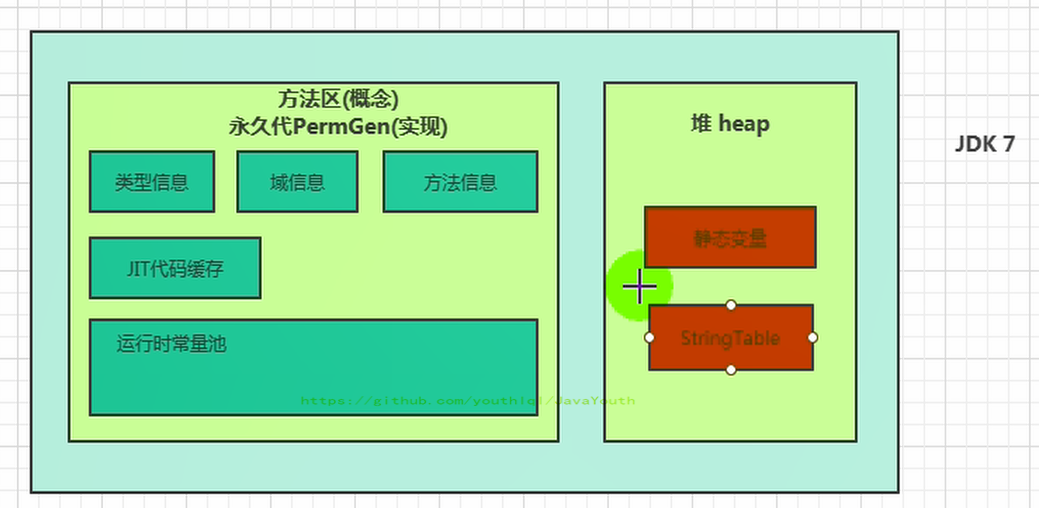 @@ -1037,7 +1037,7 @@ SourceFile: "MethodAreaDemo.java"
方法区由元空间实现,使用物理机本地内存
-
@@ -1037,7 +1037,7 @@ SourceFile: "MethodAreaDemo.java"
方法区由元空间实现,使用物理机本地内存
- +
+ @@ -1095,15 +1095,15 @@ public class StaticFieldTest {
JDK6环境下
-
@@ -1095,15 +1095,15 @@ public class StaticFieldTest {
JDK6环境下
- +
+ JDK7环境下
-
JDK7环境下
- +
+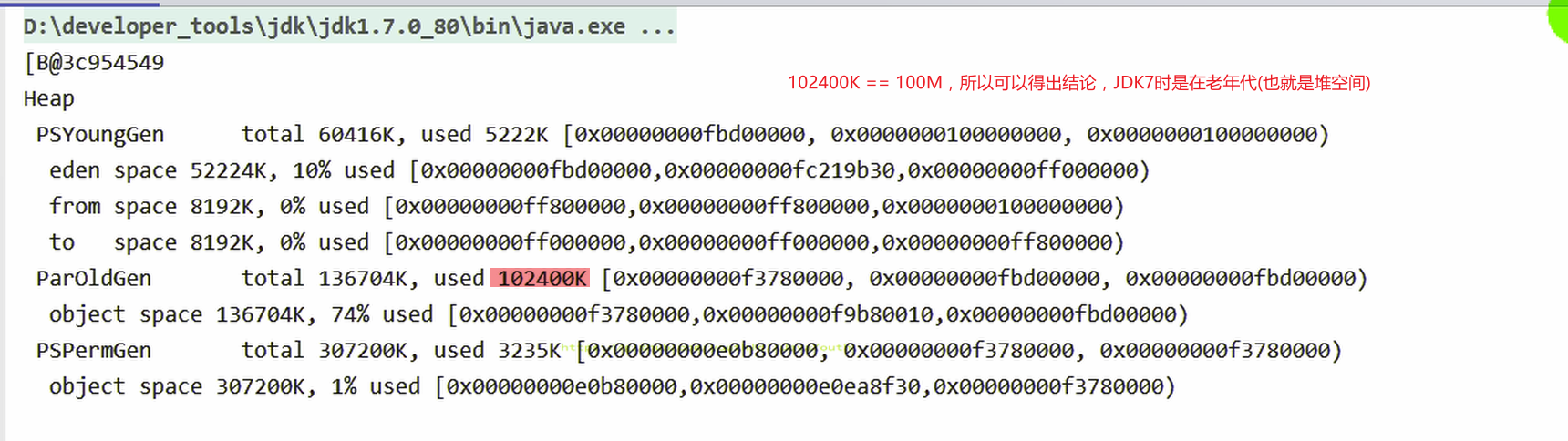 JDK8环境
-
JDK8环境
- +
+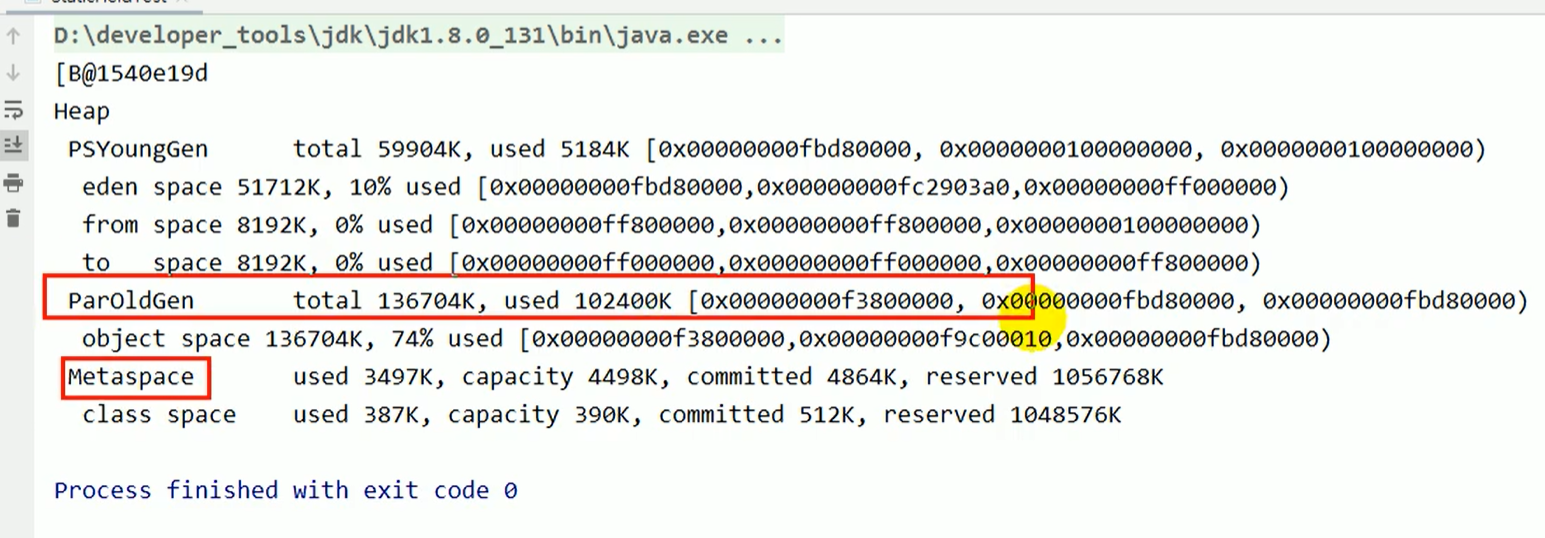 @@ -1150,7 +1150,7 @@ public class StaticObjTest {
4、测试发现:三个对象的数据在内存中的地址都落在Eden区范围内,所以结论:**只要是对象实例必然会在Java堆中分配**。
-
@@ -1150,7 +1150,7 @@ public class StaticObjTest {
4、测试发现:三个对象的数据在内存中的地址都落在Eden区范围内,所以结论:**只要是对象实例必然会在Java堆中分配**。
- +
+ > 1、0x00007f32c7800000(Eden区的起始地址) ---- 0x00007f32c7b50000(Eden区的终止地址)
>
@@ -1162,7 +1162,7 @@ public class StaticObjTest {
5、接着,找到了一个引用该staticObj对象的地方,是在一个java.lang.Class的实例里,并且给出了这个实例的地址,通过Inspector查看该对象实例,可以清楚看到这确实是一个java.lang.Class类型的对象实例,里面有一个名为staticobj的实例字段:
-
> 1、0x00007f32c7800000(Eden区的起始地址) ---- 0x00007f32c7b50000(Eden区的终止地址)
>
@@ -1162,7 +1162,7 @@ public class StaticObjTest {
5、接着,找到了一个引用该staticObj对象的地方,是在一个java.lang.Class的实例里,并且给出了这个实例的地址,通过Inspector查看该对象实例,可以清楚看到这确实是一个java.lang.Class类型的对象实例,里面有一个名为staticobj的实例字段:
- +
+ 从《Java虚拟机规范》所定义的概念模型来看,所有Class相关的信息都应该存放在方法区之中,但方法区该如何实现,《Java虚拟机规范》并未做出规定,这就成了一件允许不同虚拟机自己灵活把握的事情。JDK7及其以后版本的HotSpot虚拟机选择把静态变量与类型在Java语言一端的映射Class对象存放在一起,**存储于Java堆之中**,从我们的实验中也明确验证了这一点
@@ -1217,7 +1217,7 @@ public class StaticObjTest {
-
从《Java虚拟机规范》所定义的概念模型来看,所有Class相关的信息都应该存放在方法区之中,但方法区该如何实现,《Java虚拟机规范》并未做出规定,这就成了一件允许不同虚拟机自己灵活把握的事情。JDK7及其以后版本的HotSpot虚拟机选择把静态变量与类型在Java语言一端的映射Class对象存放在一起,**存储于Java堆之中**,从我们的实验中也明确验证了这一点
@@ -1217,7 +1217,7 @@ public class StaticObjTest {
- +
+ @@ -1271,7 +1271,7 @@ public class BufferTest {
直接占用了 1G 的本地内存
-
@@ -1271,7 +1271,7 @@ public class BufferTest {
直接占用了 1G 的本地内存
- +
+ @@ -1281,13 +1281,13 @@ public class BufferTest {
原来采用BIO的架构,在读写本地文件时,我们需要从用户态切换成内核态
-
@@ -1281,13 +1281,13 @@ public class BufferTest {
原来采用BIO的架构,在读写本地文件时,我们需要从用户态切换成内核态
- +
+ **直接缓冲区(NIO)**
NIO 直接操作物理磁盘,省去了中间过程
-
**直接缓冲区(NIO)**
NIO 直接操作物理磁盘,省去了中间过程
- +
+ ### 直接内存与 OOM
@@ -1351,7 +1351,7 @@ Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory
-
### 直接内存与 OOM
@@ -1351,7 +1351,7 @@ Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory
- +
+ diff --git a/docs/JVM/JVM系列-第7章-对象的实例化内存布局与访问定位.md b/docs/JVM/JVM系列-第7章-对象的实例化内存布局与访问定位.md
index 5d103e5..3c4049d 100644
--- a/docs/JVM/JVM系列-第7章-对象的实例化内存布局与访问定位.md
+++ b/docs/JVM/JVM系列-第7章-对象的实例化内存布局与访问定位.md
@@ -36,7 +36,7 @@ date: 2020-11-14 19:38:42
-
diff --git a/docs/JVM/JVM系列-第7章-对象的实例化内存布局与访问定位.md b/docs/JVM/JVM系列-第7章-对象的实例化内存布局与访问定位.md
index 5d103e5..3c4049d 100644
--- a/docs/JVM/JVM系列-第7章-对象的实例化内存布局与访问定位.md
+++ b/docs/JVM/JVM系列-第7章-对象的实例化内存布局与访问定位.md
@@ -36,7 +36,7 @@ date: 2020-11-14 19:38:42
- +
+ ### 对象创建的方式
@@ -211,7 +211,7 @@ class Account{
对象的内存布局
---------
-
### 对象创建的方式
@@ -211,7 +211,7 @@ class Account{
对象的内存布局
---------
- +
+ @@ -242,7 +242,7 @@ class Account{
图解内存布局
-
@@ -242,7 +242,7 @@ class Account{
图解内存布局
- +
+ @@ -251,7 +251,7 @@ class Account{
**JVM是如何通过栈帧中的对象引用访问到其内部的对象实例呢?**
-
@@ -251,7 +251,7 @@ class Account{
**JVM是如何通过栈帧中的对象引用访问到其内部的对象实例呢?**
- +
+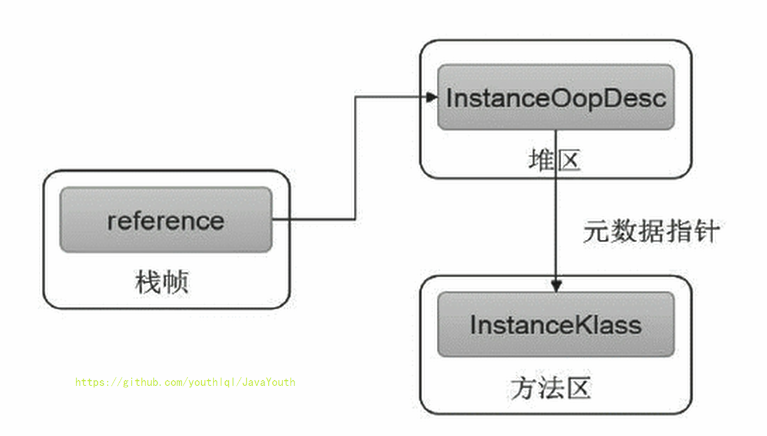 定位,通过栈上reference访问
@@ -262,7 +262,7 @@ class Account{
1. 缺点:在堆空间中开辟了一块空间作为句柄池,句柄池本身也会占用空间;通过两次指针访问才能访问到堆中的对象,效率低
2. 优点:reference中存储稳定句柄地址,对象被移动(垃圾收集时移动对象很普遍)时只会改变句柄中实例数据指针即可,reference本身不需要被修改
-
定位,通过栈上reference访问
@@ -262,7 +262,7 @@ class Account{
1. 缺点:在堆空间中开辟了一块空间作为句柄池,句柄池本身也会占用空间;通过两次指针访问才能访问到堆中的对象,效率低
2. 优点:reference中存储稳定句柄地址,对象被移动(垃圾收集时移动对象很普遍)时只会改变句柄中实例数据指针即可,reference本身不需要被修改
- +
+ @@ -271,4 +271,4 @@ class Account{
1. 优点:直接指针是局部变量表中的引用,直接指向堆中的实例,在对象实例中有类型指针,指向的是方法区中的对象类型数据
2. 缺点:对象被移动(垃圾收集时移动对象很普遍)时需要修改 reference 的值
-
@@ -271,4 +271,4 @@ class Account{
1. 优点:直接指针是局部变量表中的引用,直接指向堆中的实例,在对象实例中有类型指针,指向的是方法区中的对象类型数据
2. 缺点:对象被移动(垃圾收集时移动对象很普遍)时需要修改 reference 的值
- \ No newline at end of file
+
\ No newline at end of file
+ \ No newline at end of file
diff --git a/docs/JVM/JVM系列-第8章-执行引擎.md b/docs/JVM/JVM系列-第8章-执行引擎.md
index b39f0ae..7278d1d 100644
--- a/docs/JVM/JVM系列-第8章-执行引擎.md
+++ b/docs/JVM/JVM系列-第8章-执行引擎.md
@@ -23,7 +23,7 @@ date: 2020-11-15 19:48:42
-
\ No newline at end of file
diff --git a/docs/JVM/JVM系列-第8章-执行引擎.md b/docs/JVM/JVM系列-第8章-执行引擎.md
index b39f0ae..7278d1d 100644
--- a/docs/JVM/JVM系列-第8章-执行引擎.md
+++ b/docs/JVM/JVM系列-第8章-执行引擎.md
@@ -23,7 +23,7 @@ date: 2020-11-15 19:48:42
- +
+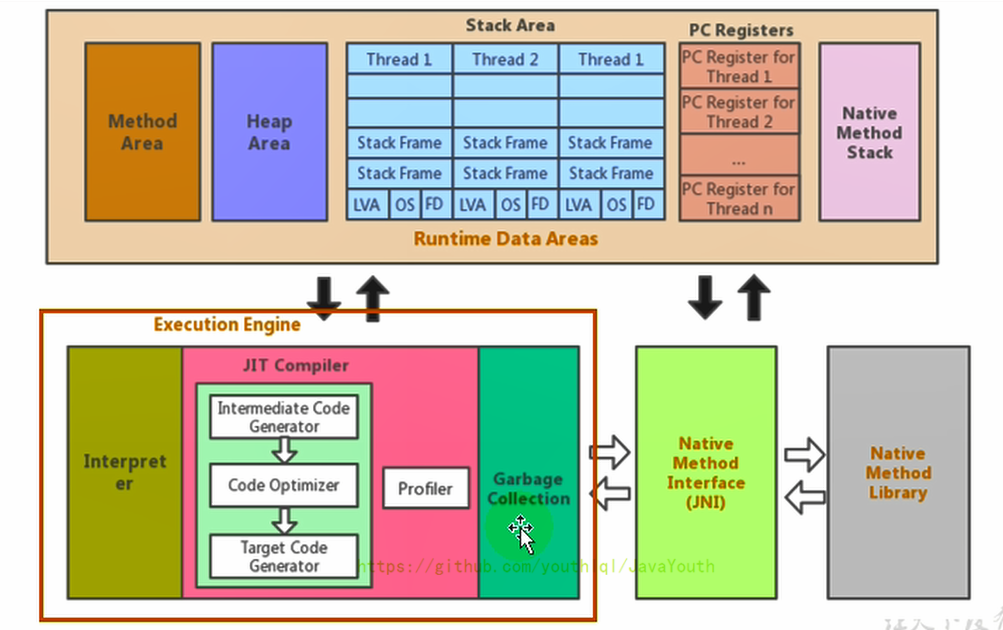 ### 执行引擎概述
@@ -34,7 +34,7 @@ date: 2020-11-15 19:48:42
3. JVM的主要任务是负责**装载字节码到其内部**,但字节码并不能够直接运行在操作系统之上,因为字节码指令并非等价于本地机器指令,它内部包含的仅仅只是一些能够被JVM所识别的字节码指令、符号表,以及其他辅助信息。
4. 那么,如果想要让一个Java程序运行起来,执行引擎(Execution Engine)的任务就是**将字节码指令解释/编译为对应平台上的本地机器指令才可以**。简单来说,JVM中的执行引擎充当了将高级语言翻译为机器语言的译者。
-
### 执行引擎概述
@@ -34,7 +34,7 @@ date: 2020-11-15 19:48:42
3. JVM的主要任务是负责**装载字节码到其内部**,但字节码并不能够直接运行在操作系统之上,因为字节码指令并非等价于本地机器指令,它内部包含的仅仅只是一些能够被JVM所识别的字节码指令、符号表,以及其他辅助信息。
4. 那么,如果想要让一个Java程序运行起来,执行引擎(Execution Engine)的任务就是**将字节码指令解释/编译为对应平台上的本地机器指令才可以**。简单来说,JVM中的执行引擎充当了将高级语言翻译为机器语言的译者。
- +
+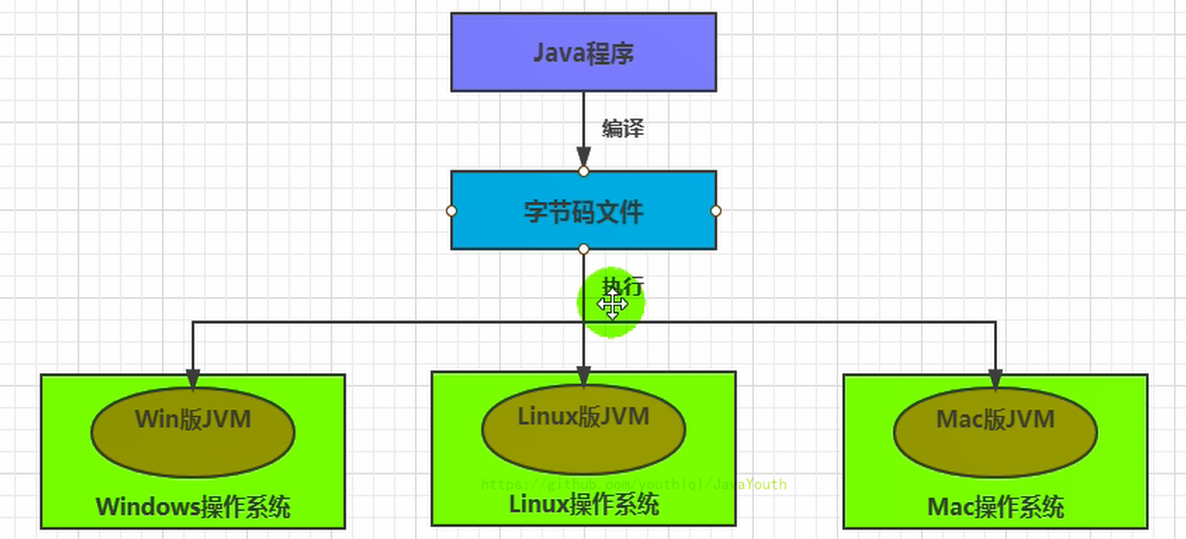 1、前端编译:从Java程序员-字节码文件的这个过程叫前端编译
@@ -51,7 +51,7 @@ date: 2020-11-15 19:48:42
3. 当然方法在执行的过程中,执行引擎有可能会通过存储在局部变量表中的对象引用准确定位到存储在Java堆区中的对象实例信息,以及通过对象头中的元数据指针定位到目标对象的类型信息。
4. 从外观上来看,所有的Java虚拟机的执行引擎输入、处理、输出都是一致的:输入的是字节码二进制流,处理过程是字节码解析执行、即时编译的等效过程,输出的是执行过程。
-
1、前端编译:从Java程序员-字节码文件的这个过程叫前端编译
@@ -51,7 +51,7 @@ date: 2020-11-15 19:48:42
3. 当然方法在执行的过程中,执行引擎有可能会通过存储在局部变量表中的对象引用准确定位到存储在Java堆区中的对象实例信息,以及通过对象头中的元数据指针定位到目标对象的类型信息。
4. 从外观上来看,所有的Java虚拟机的执行引擎输入、处理、输出都是一致的:输入的是字节码二进制流,处理过程是字节码解析执行、即时编译的等效过程,输出的是执行过程。
- +
+ @@ -71,18 +71,18 @@ Java代码编译和执行过程
-
@@ -71,18 +71,18 @@ Java代码编译和执行过程
- +
+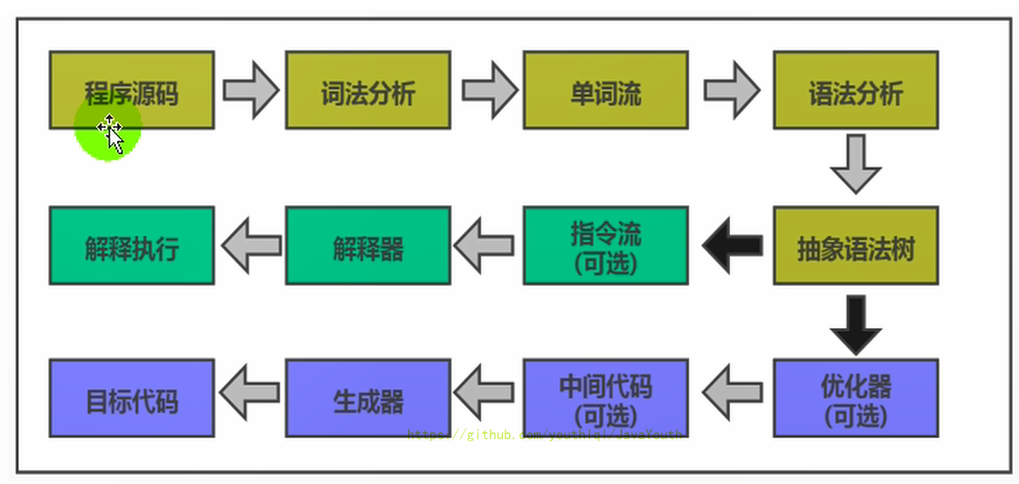 3. javac编译器(前端编译器)流程图如下所示:
-
3. javac编译器(前端编译器)流程图如下所示:
-  +
+ 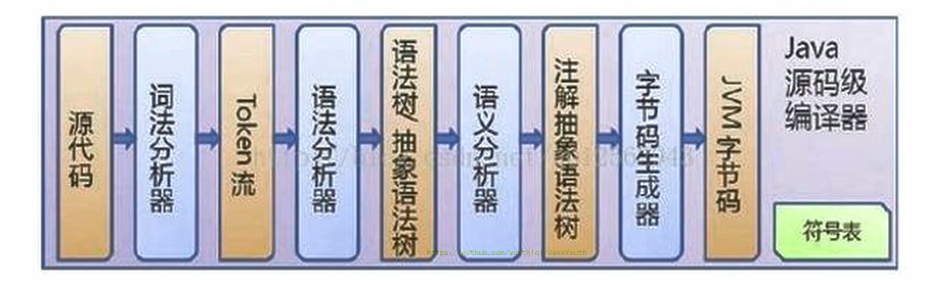 4. Java字节码的执行是由JVM执行引擎来完成,流程图如下所示
-
4. Java字节码的执行是由JVM执行引擎来完成,流程图如下所示
-  +
+  @@ -105,7 +105,7 @@ Java代码编译和执行过程
**用图总结一下**
-
@@ -105,7 +105,7 @@ Java代码编译和执行过程
**用图总结一下**
- +
+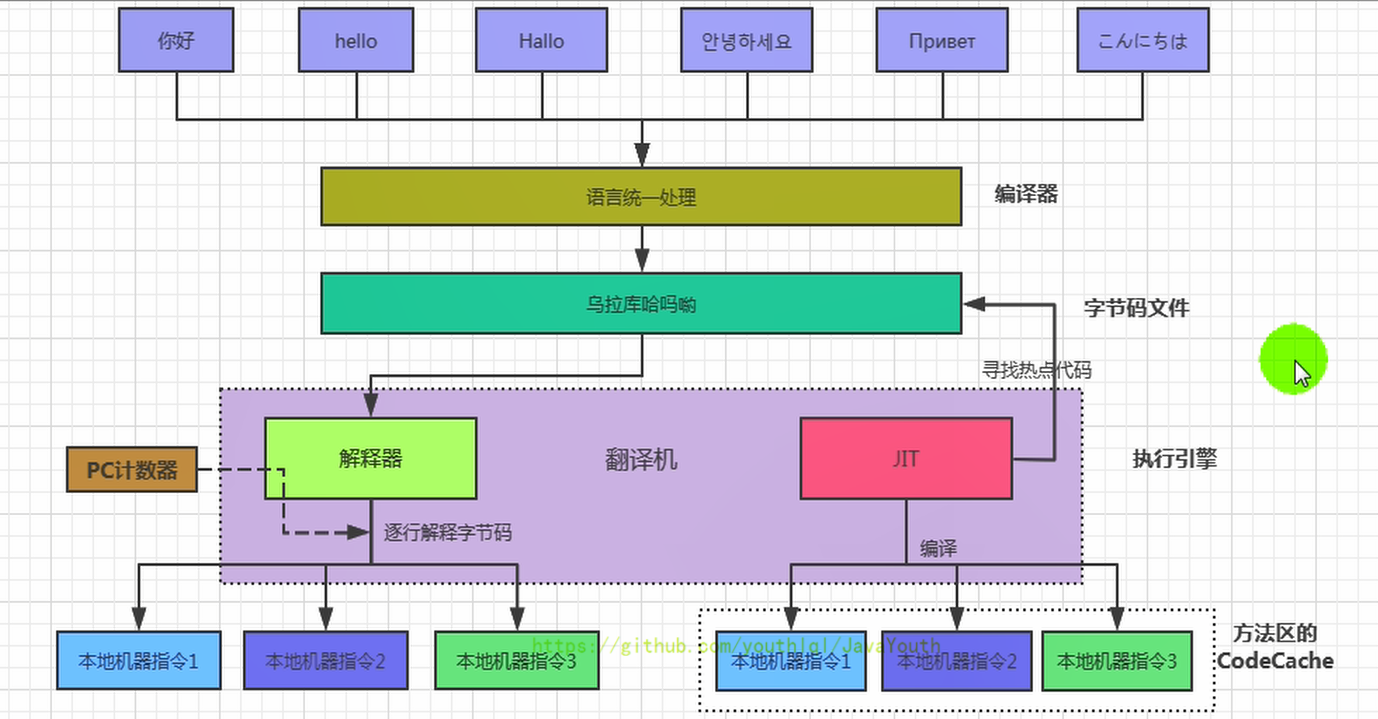 机器码 指令 汇编语言
-------------
@@ -164,7 +164,7 @@ Java代码编译和执行过程
-
机器码 指令 汇编语言
-------------
@@ -164,7 +164,7 @@ Java代码编译和执行过程
- +
+ @@ -193,7 +193,7 @@ Java代码编译和执行过程
2. 汇编过程:实际上指把汇编语言代码翻译成目标机器指令的过程。
-
@@ -193,7 +193,7 @@ Java代码编译和执行过程
2. 汇编过程:实际上指把汇编语言代码翻译成目标机器指令的过程。
- +
+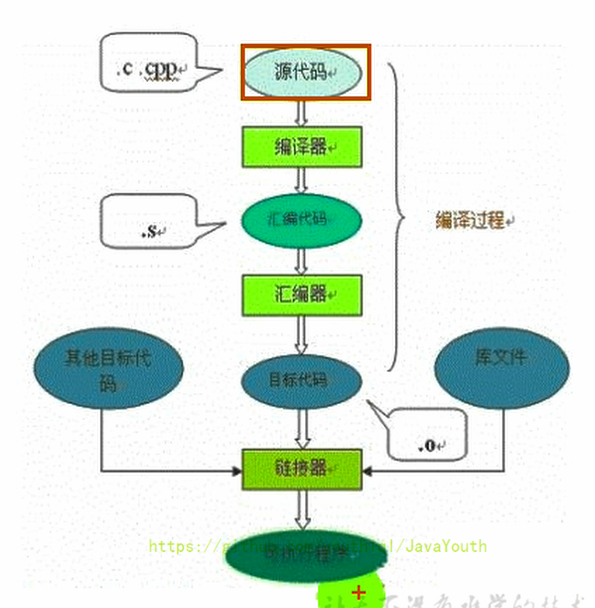 @@ -211,7 +211,7 @@ Java代码编译和执行过程
3. 当一条字节码指令被解释执行完成后,接着再根据PC寄存器中记录的下一条需要被执行的字节码指令执行解释操作。
-
@@ -211,7 +211,7 @@ Java代码编译和执行过程
3. 当一条字节码指令被解释执行完成后,接着再根据PC寄存器中记录的下一条需要被执行的字节码指令执行解释操作。
- +
+ @@ -288,7 +288,7 @@ Java代码编译和执行过程
2. 在生产环境发布过程中,以分批的方式进行发布,根据机器数量划分成多个批次,每个批次的机器数至多占到整个集群的1/8。曾经有这样的故障案例:某程序员在发布平台进行分批发布,在输入发布总批数时,误填写成分为两批发布。如果是热机状态,在正常情况下一半的机器可以勉强承载流量,但由于刚启动的JVM均是解释执行,还没有进行热点代码统计和JIT动态编译,导致机器启动之后,当前1/2发布成功的服务器马上全部宕机,此故障说明了JIT的存在。—**阿里团队**
-
@@ -288,7 +288,7 @@ Java代码编译和执行过程
2. 在生产环境发布过程中,以分批的方式进行发布,根据机器数量划分成多个批次,每个批次的机器数至多占到整个集群的1/8。曾经有这样的故障案例:某程序员在发布平台进行分批发布,在输入发布总批数时,误填写成分为两批发布。如果是热机状态,在正常情况下一半的机器可以勉强承载流量,但由于刚启动的JVM均是解释执行,还没有进行热点代码统计和JIT动态编译,导致机器启动之后,当前1/2发布成功的服务器马上全部宕机,此故障说明了JIT的存在。—**阿里团队**
- +
+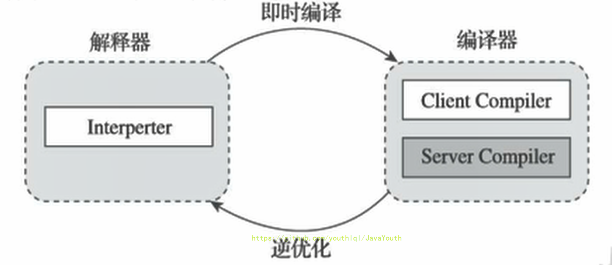 @@ -317,7 +317,7 @@ public class JITTest {
通过 JVisualVM 查看 JIT 编译器执行的编译次数
-
@@ -317,7 +317,7 @@ public class JITTest {
通过 JVisualVM 查看 JIT 编译器执行的编译次数
- +
+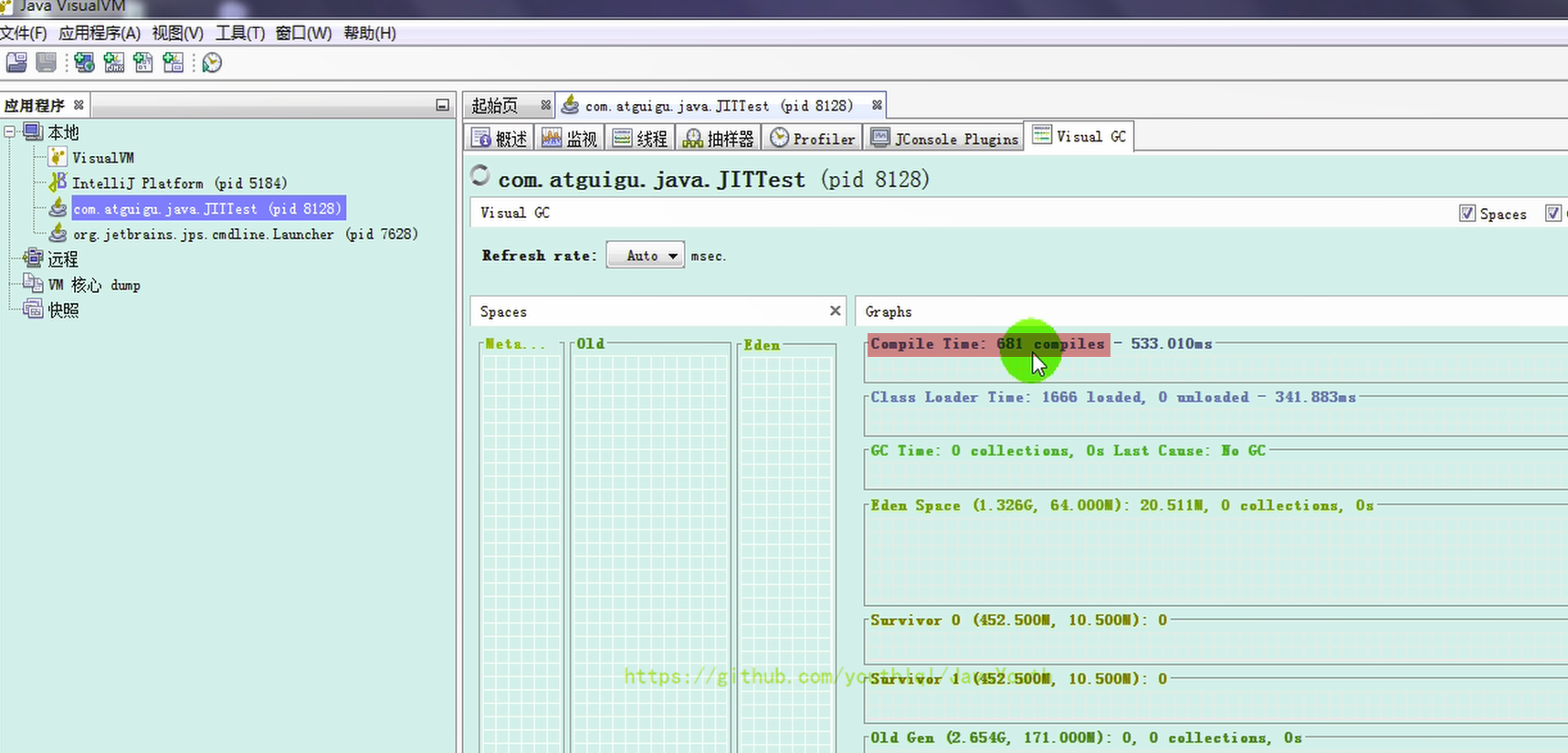 @@ -369,7 +369,7 @@ public class JITTest {
* 如果已超过阈值,那么将会向即时编译器提交一个该方法的代码编译请求。
* 如果未超过阈值,则使用解释器对字节码文件解释执行
-
@@ -369,7 +369,7 @@ public class JITTest {
* 如果已超过阈值,那么将会向即时编译器提交一个该方法的代码编译请求。
* 如果未超过阈值,则使用解释器对字节码文件解释执行
- +
+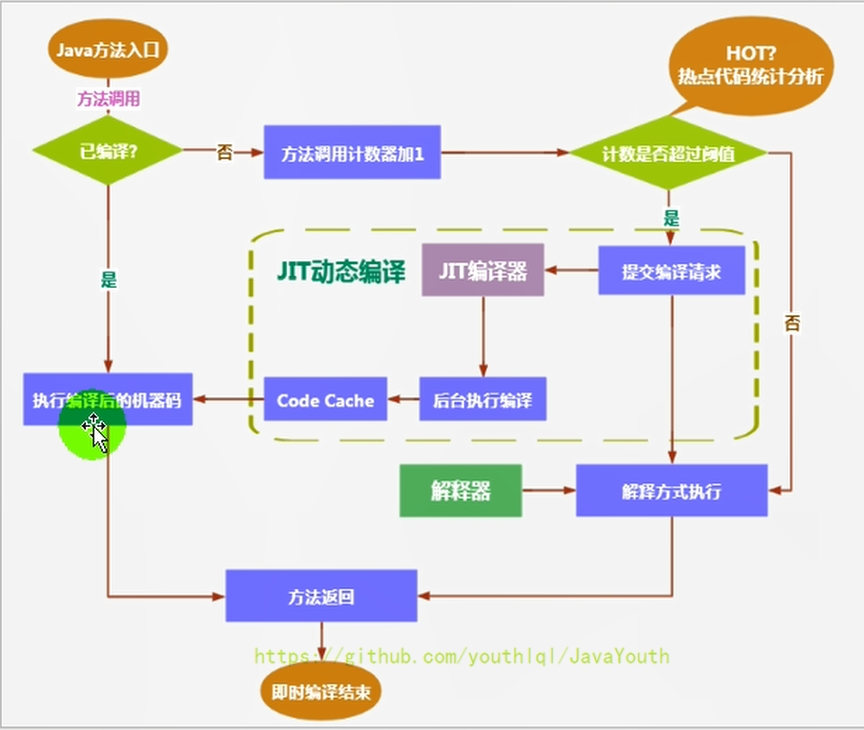 @@ -387,7 +387,7 @@ public class JITTest {
它的作用是统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为“回边”(Back Edge)。显然,建立回边计数器统计的目的就是为了触发OSR编译。
-
@@ -387,7 +387,7 @@ public class JITTest {
它的作用是统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为“回边”(Back Edge)。显然,建立回边计数器统计的目的就是为了触发OSR编译。
- +
+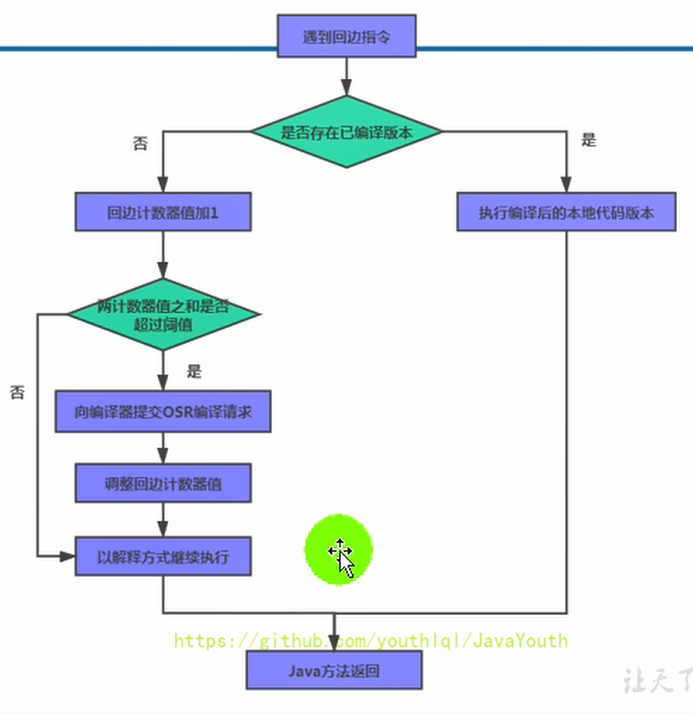 @@ -401,7 +401,7 @@ public class JITTest {
-
@@ -401,7 +401,7 @@ public class JITTest {
- +
+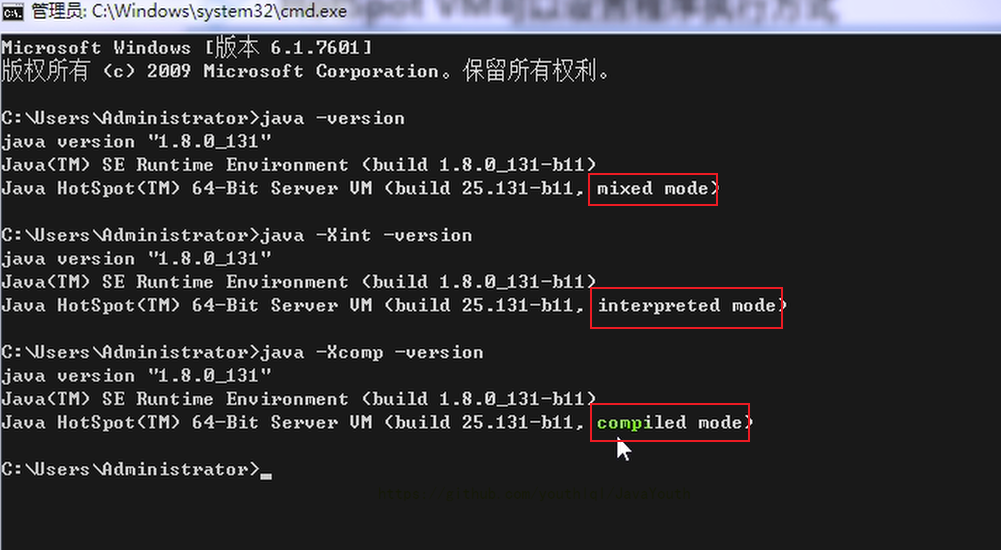 diff --git a/docs/JVM/JVM系列-第9章-StringTable(字符串常量池).md b/docs/JVM/JVM系列-第9章-StringTable(字符串常量池).md
index c284448..440014c 100644
--- a/docs/JVM/JVM系列-第9章-StringTable(字符串常量池).md
+++ b/docs/JVM/JVM系列-第9章-StringTable(字符串常量池).md
@@ -166,11 +166,11 @@ str 的内容并没有变:“test ok” 位于字符串常量池中的另一
4. 在JDK7中,StringTable的长度默认值是60013,StringTablesize设置没有要求
5. 在JDK8中,StringTable的长度默认值是60013,StringTable可以设置的最小值为1009
-
diff --git a/docs/JVM/JVM系列-第9章-StringTable(字符串常量池).md b/docs/JVM/JVM系列-第9章-StringTable(字符串常量池).md
index c284448..440014c 100644
--- a/docs/JVM/JVM系列-第9章-StringTable(字符串常量池).md
+++ b/docs/JVM/JVM系列-第9章-StringTable(字符串常量池).md
@@ -166,11 +166,11 @@ str 的内容并没有变:“test ok” 位于字符串常量池中的另一
4. 在JDK7中,StringTable的长度默认值是60013,StringTablesize设置没有要求
5. 在JDK8中,StringTable的长度默认值是60013,StringTable可以设置的最小值为1009
- +
+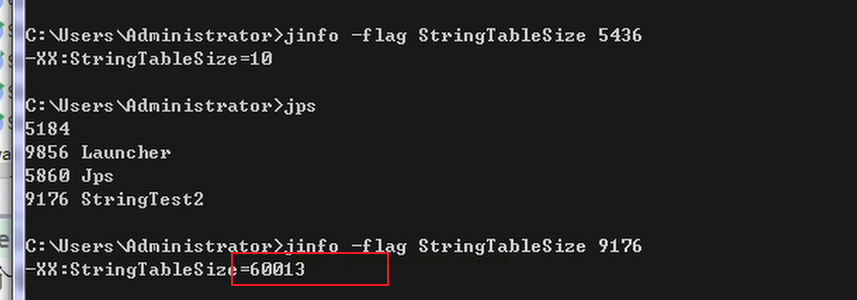 -
- +
+ @@ -276,11 +276,11 @@ String 的内存分配
-
@@ -276,11 +276,11 @@ String 的内存分配
- +
+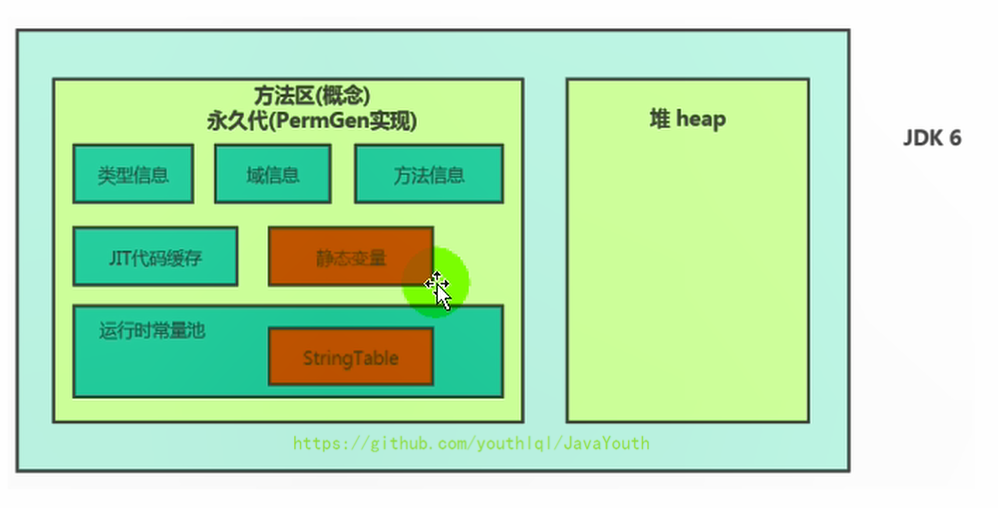 -
- +
+ @@ -382,23 +382,23 @@ public class StringTest4 {
1、程序启动时已经加载了 2293 个字符串常量
-
@@ -382,23 +382,23 @@ public class StringTest4 {
1、程序启动时已经加载了 2293 个字符串常量
- +
+ 2、加载了一个换行符(println),所以多了一个
-
2、加载了一个换行符(println),所以多了一个
- +
+ 3、加载了字符串常量 “1”~“9”
-
3、加载了字符串常量 “1”~“9”
- +
+ 4、加载字符串常量 “10”
-
4、加载字符串常量 “10”
- +
+ 5、之后的字符串"1" 到 "10"不会再次加载
-
5、之后的字符串"1" 到 "10"不会再次加载
- +
+ @@ -425,7 +425,7 @@ class Memory {
分析运行时内存(foo() 方法是实例方法,其实图中少了一个 this 局部变量)
-
@@ -425,7 +425,7 @@ class Memory {
分析运行时内存(foo() 方法是实例方法,其实图中少了一个 this 局部变量)
- +
+ @@ -493,7 +493,7 @@ class Memory {
IDEA 反编译 class 文件后,来看这个问题
-
@@ -493,7 +493,7 @@ class Memory {
IDEA 反编译 class 文件后,来看这个问题
- +
+ @@ -929,7 +929,7 @@ public class StringNewTest {
5. `23 ldc #8 ` :在字符串常量池中放入 “b”(如果之前字符串常量池中没有 “b” 的话)
6. `31 invokevirtual #9 ` :调用 StringBuilder 的 toString() 方法,会生成一个 String 对象
-
@@ -929,7 +929,7 @@ public class StringNewTest {
5. `23 ldc #8 ` :在字符串常量池中放入 “b”(如果之前字符串常量池中没有 “b” 的话)
6. `31 invokevirtual #9 ` :调用 StringBuilder 的 toString() 方法,会生成一个 String 对象
- +
+ @@ -988,13 +988,13 @@ JDK6 :正常眼光判断即可
* new String() 即在堆中
* str.intern() 则把字符串放入常量池中
-
@@ -988,13 +988,13 @@ JDK6 :正常眼光判断即可
* new String() 即在堆中
* str.intern() 则把字符串放入常量池中
- +
+ JDK7及后续版本,**注意大坑**
-
JDK7及后续版本,**注意大坑**
- +
+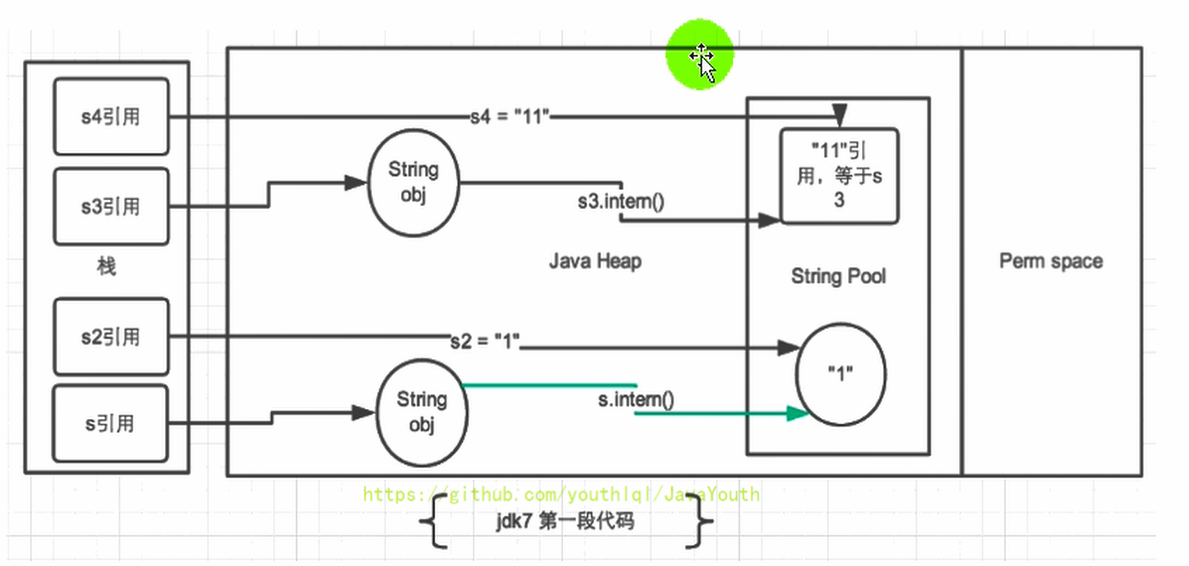 @@ -1053,11 +1053,11 @@ public class StringExer1 {
**JDK6**
-
+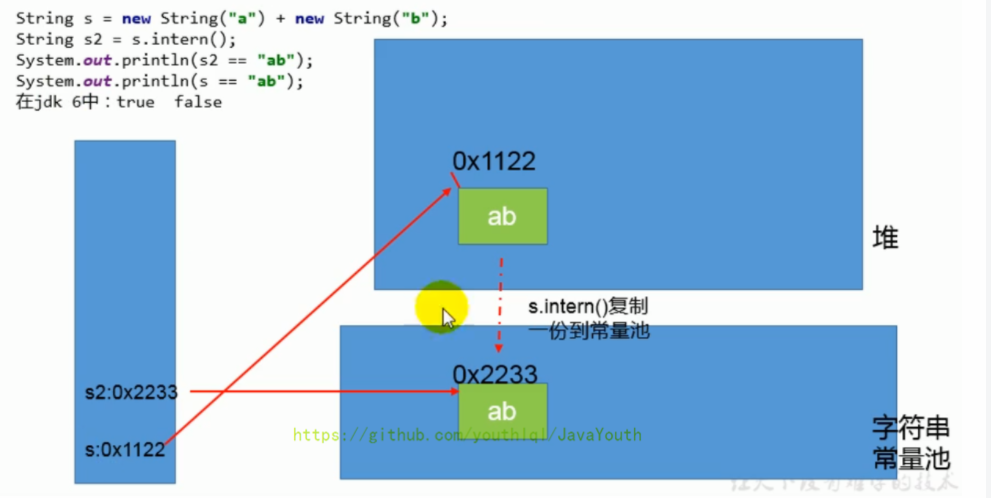
**JDK7/8**
-
@@ -1053,11 +1053,11 @@ public class StringExer1 {
**JDK6**
-
+
**JDK7/8**
- +
+ @@ -1080,7 +1080,7 @@ public class StringExer1 {
}
```
-
@@ -1080,7 +1080,7 @@ public class StringExer1 {
}
```
- +
+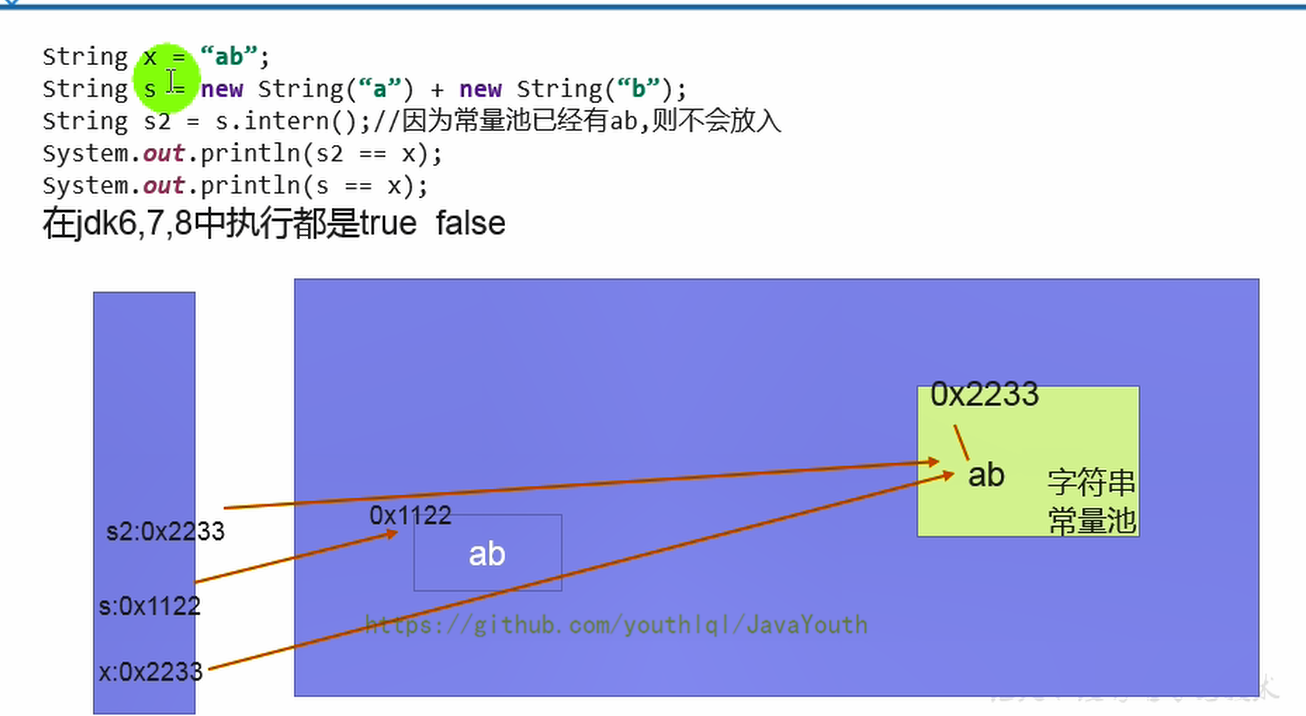 **练习3**
@@ -1169,11 +1169,11 @@ public class StringIntern2 {
arr[i] = new String(String.valueOf(data[i % data.length]));
```
-
**练习3**
@@ -1169,11 +1169,11 @@ public class StringIntern2 {
arr[i] = new String(String.valueOf(data[i % data.length]));
```
- +
+ -
- +
+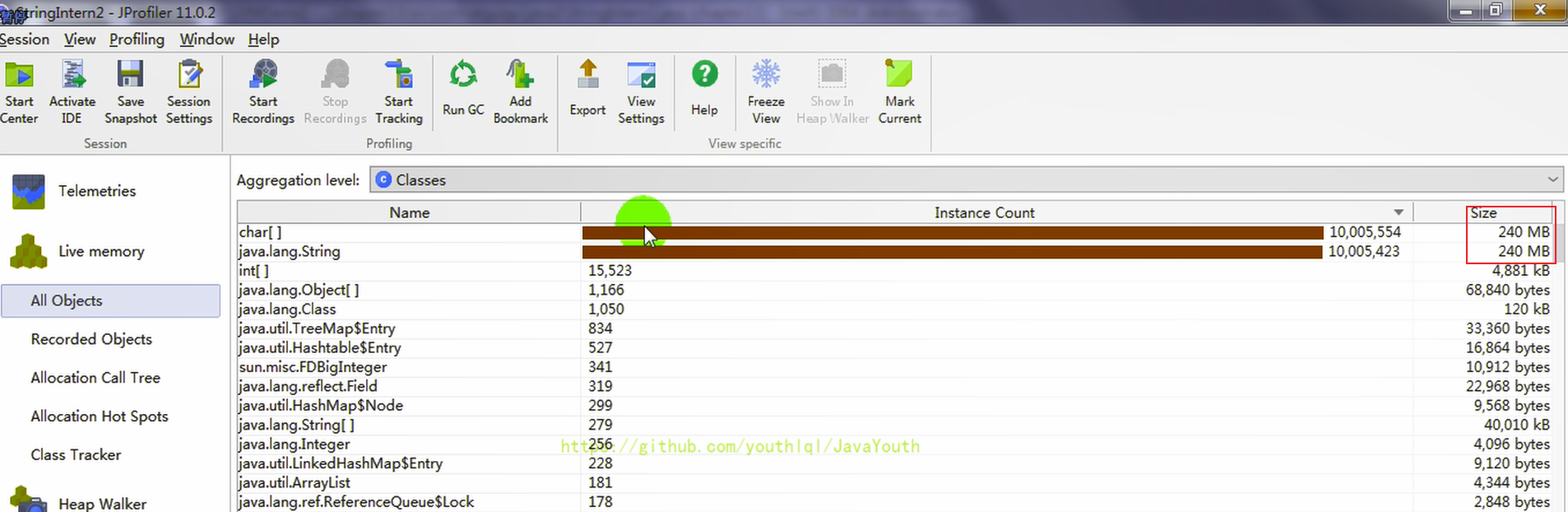 2、使用 intern() 方法:由于数组中字符串的引用都指向字符串常量池中的字符串,所以程序需要维护的 String 对象更少,内存占用也更低
@@ -1182,11 +1182,11 @@ arr[i] = new String(String.valueOf(data[i % data.length]));
arr[i] = new String(String.valueOf(data[i % data.length])).intern();
```
-
2、使用 intern() 方法:由于数组中字符串的引用都指向字符串常量池中的字符串,所以程序需要维护的 String 对象更少,内存占用也更低
@@ -1182,11 +1182,11 @@ arr[i] = new String(String.valueOf(data[i % data.length]));
arr[i] = new String(String.valueOf(data[i % data.length])).intern();
```
- +
+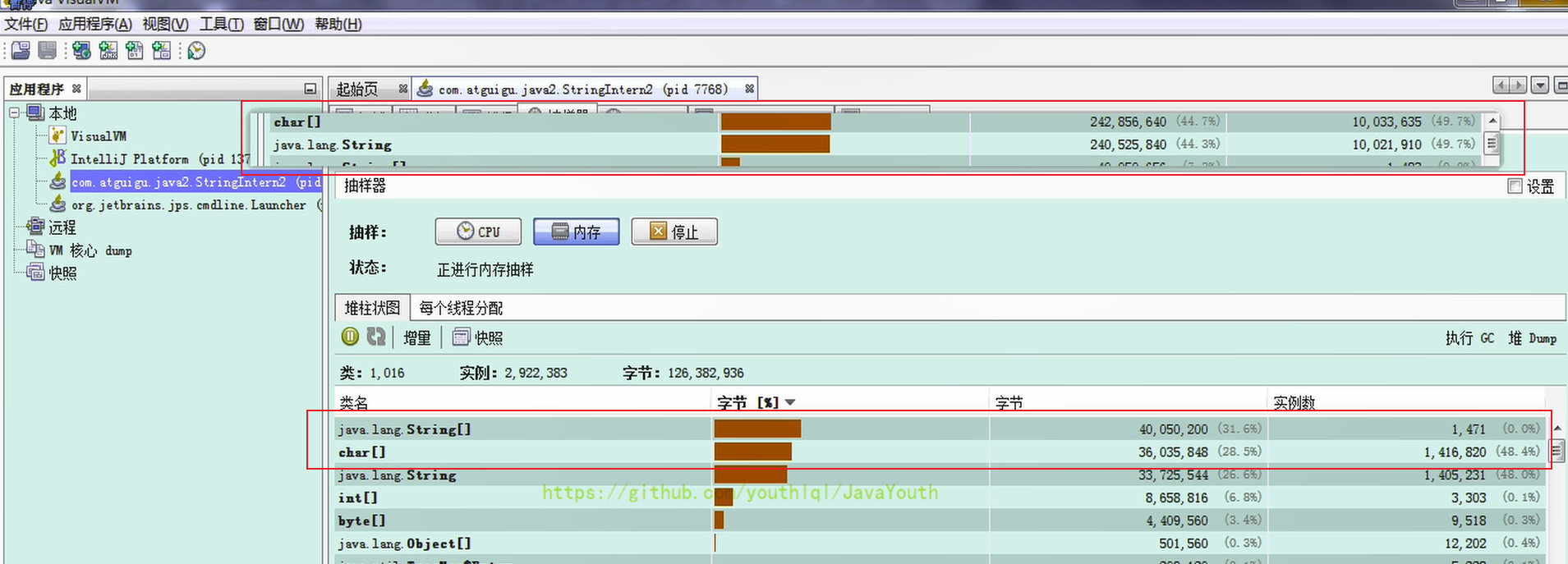 -
- +
+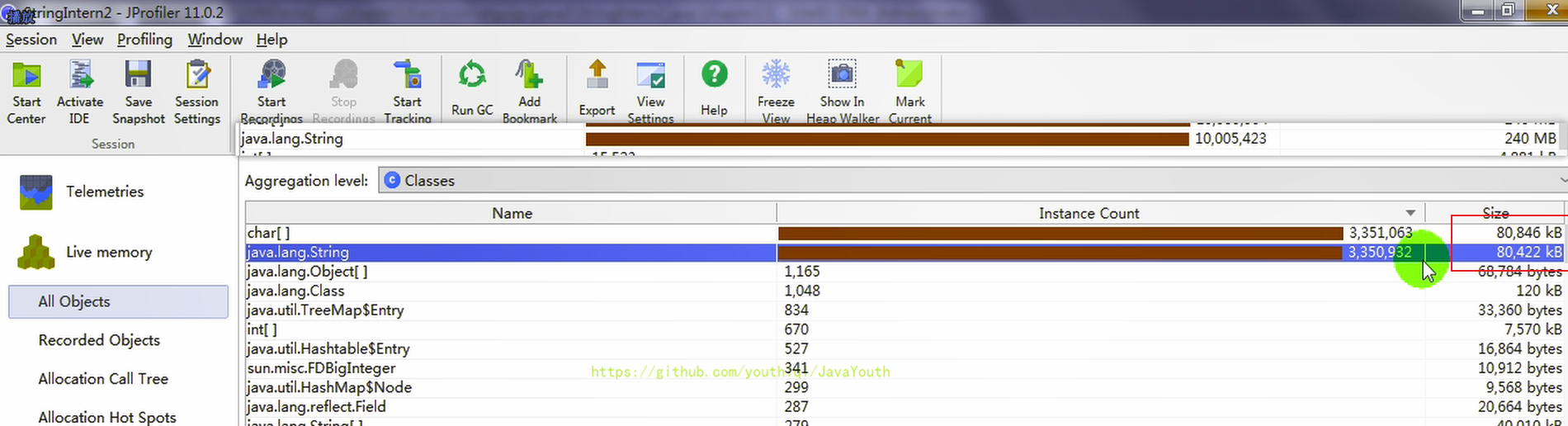 @@ -1218,11 +1218,11 @@ public class StringGCTest {
* Number of entries 和 Number of literals 明显没有 100000
* 以上两点均说明 StringTable 区发生了垃圾回收
-
@@ -1218,11 +1218,11 @@ public class StringGCTest {
* Number of entries 和 Number of literals 明显没有 100000
* 以上两点均说明 StringTable 区发生了垃圾回收
- +
+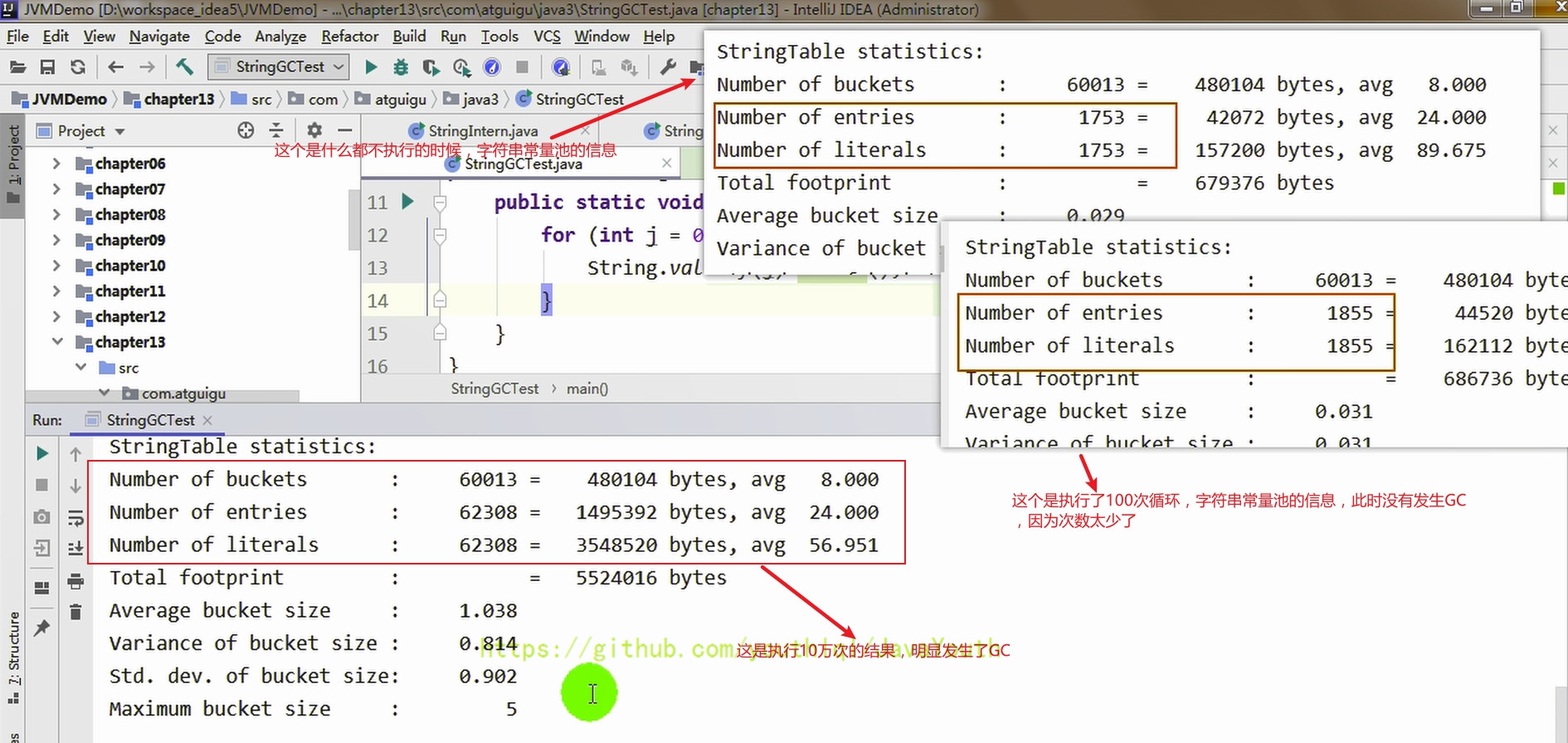 -
- +
+ diff --git a/docs/Java/Basis/Java8新特性.md b/docs/Java/Basis/Java8新特性.md
index 9295f12..7c2dc31 100644
--- a/docs/Java/Basis/Java8新特性.md
+++ b/docs/Java/Basis/Java8新特性.md
@@ -20,7 +20,7 @@ date: 2020-10-19 22:15:58
> 本篇文章只讲解比较重要的
-
diff --git a/docs/Java/Basis/Java8新特性.md b/docs/Java/Basis/Java8新特性.md
index 9295f12..7c2dc31 100644
--- a/docs/Java/Basis/Java8新特性.md
+++ b/docs/Java/Basis/Java8新特性.md
@@ -20,7 +20,7 @@ date: 2020-10-19 22:15:58
> 本篇文章只讲解比较重要的
- +
+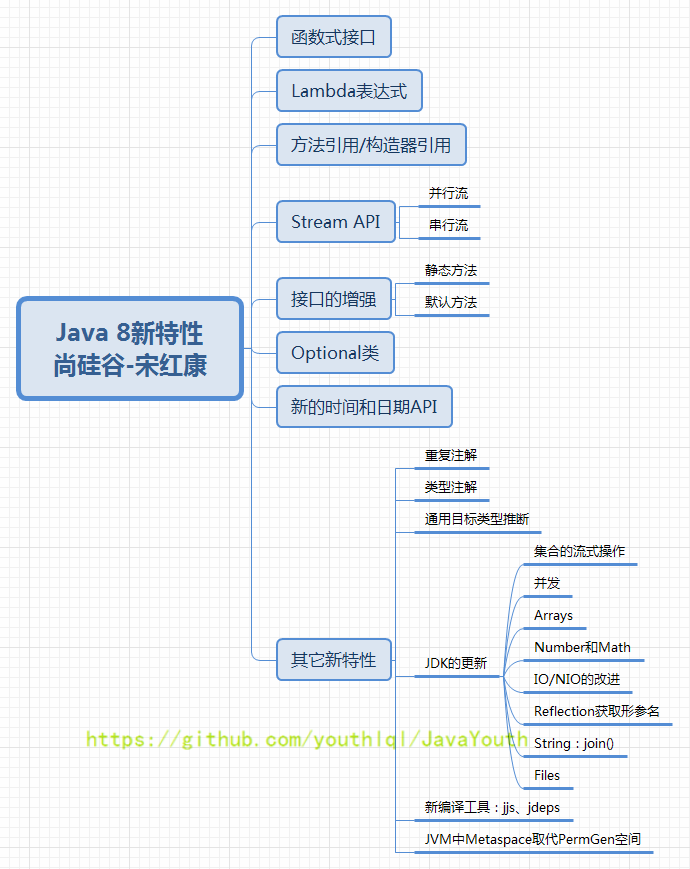 @@ -308,13 +308,13 @@ public class LambdaTest1 {
**核心函数式接口**
-
@@ -308,13 +308,13 @@ public class LambdaTest1 {
**核心函数式接口**
- +
+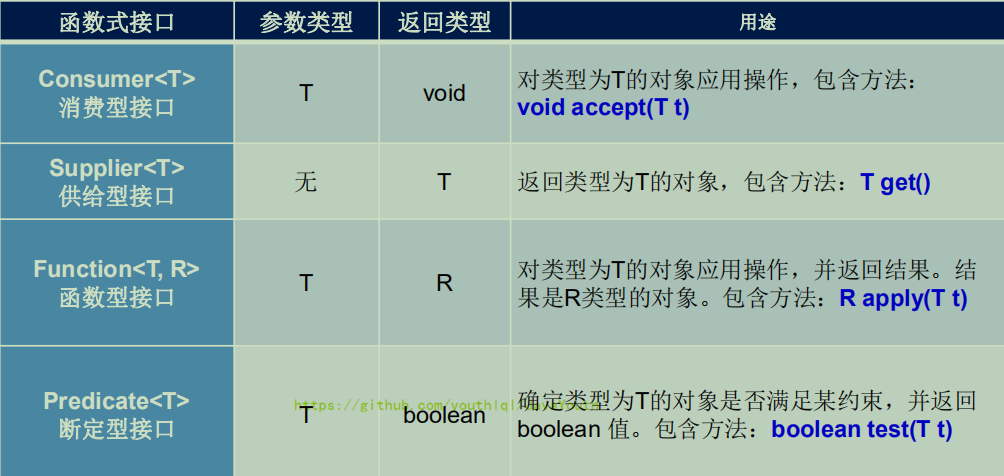 **其它函数式接口**
-
**其它函数式接口**
- +
+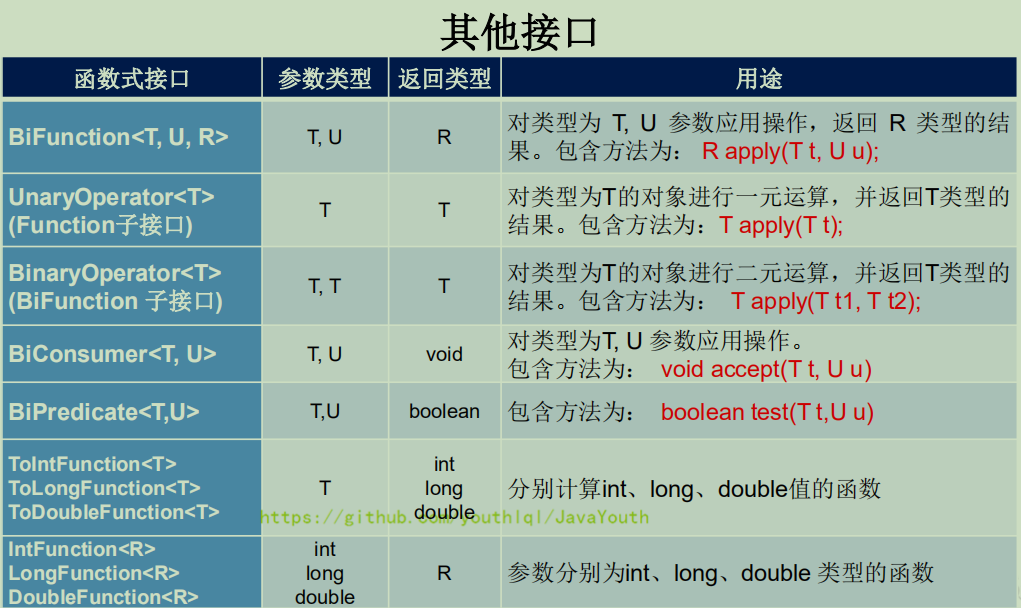 @@ -902,7 +902,7 @@ Stream到底是什么呢?
-
@@ -902,7 +902,7 @@ Stream到底是什么呢?
- +
+ @@ -1219,7 +1219,7 @@ public class StreamAPITest2 {
## 常用API
-
@@ -1219,7 +1219,7 @@ public class StreamAPITest2 {
## 常用API
- +
+ diff --git a/docs/Java/Basis/泛型.md b/docs/Java/Basis/泛型.md
index aefd00f..0fdb8ac 100644
--- a/docs/Java/Basis/泛型.md
+++ b/docs/Java/Basis/泛型.md
@@ -1038,7 +1038,7 @@ class Dog extends Animal {
`test1()`在编译时就会飘红
-
diff --git a/docs/Java/Basis/泛型.md b/docs/Java/Basis/泛型.md
index aefd00f..0fdb8ac 100644
--- a/docs/Java/Basis/泛型.md
+++ b/docs/Java/Basis/泛型.md
@@ -1038,7 +1038,7 @@ class Dog extends Animal {
`test1()`在编译时就会飘红
- +
+ @@ -1290,7 +1290,7 @@ public class Test_difference {
}
```
-
@@ -1290,7 +1290,7 @@ public class Test_difference {
}
```
- +
+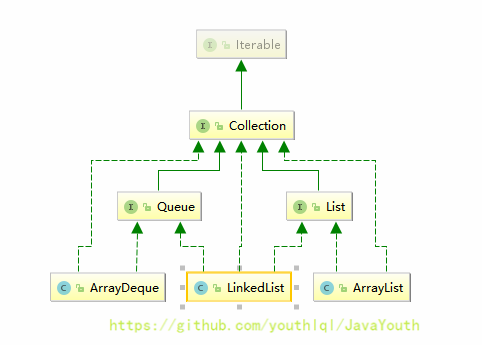 ### 区别3:?通配符可以使用超类限定而T不行
diff --git a/docs/Java/collection/HashMap-JDK7源码讲解.md b/docs/Java/collection/HashMap-JDK7源码讲解.md
index cc1b9fa..1e7bd41 100644
--- a/docs/Java/collection/HashMap-JDK7源码讲解.md
+++ b/docs/Java/collection/HashMap-JDK7源码讲解.md
@@ -202,7 +202,7 @@ hadoop2
大致是这样的一个结构
-
### 区别3:?通配符可以使用超类限定而T不行
diff --git a/docs/Java/collection/HashMap-JDK7源码讲解.md b/docs/Java/collection/HashMap-JDK7源码讲解.md
index cc1b9fa..1e7bd41 100644
--- a/docs/Java/collection/HashMap-JDK7源码讲解.md
+++ b/docs/Java/collection/HashMap-JDK7源码讲解.md
@@ -202,7 +202,7 @@ hadoop2
大致是这样的一个结构
- +
+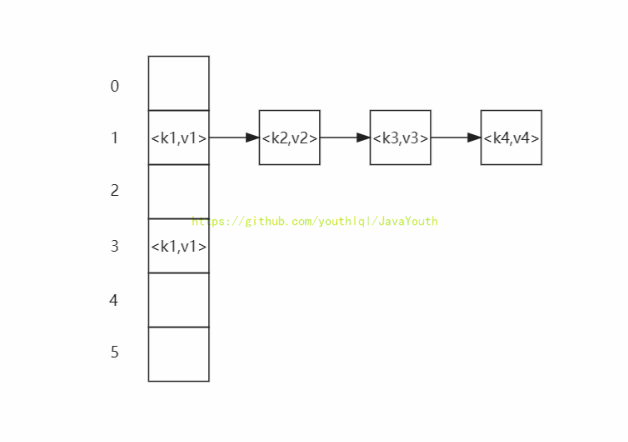 - 每个链表就算哈希表的桶(bucket)
- 链表的节点值就算一个键值对
@@ -398,7 +398,7 @@ static class Entry implements Map.Entry {
`HashMap`中的数组元素 & 链表节点 采用 `Entry`类实现
-
+
1、一个正方形代表一个Entry对象,同时也代表一个键值对。
@@ -769,15 +769,15 @@ void transfer(Entry[] newTable, boolean rehash) {
大概画了一下图:
-
- 每个链表就算哈希表的桶(bucket)
- 链表的节点值就算一个键值对
@@ -398,7 +398,7 @@ static class Entry implements Map.Entry {
`HashMap`中的数组元素 & 链表节点 采用 `Entry`类实现
-
+
1、一个正方形代表一个Entry对象,同时也代表一个键值对。
@@ -769,15 +769,15 @@ void transfer(Entry[] newTable, boolean rehash) {
大概画了一下图:
- +
+ -
- +
+ -
- +
+ -
- +
+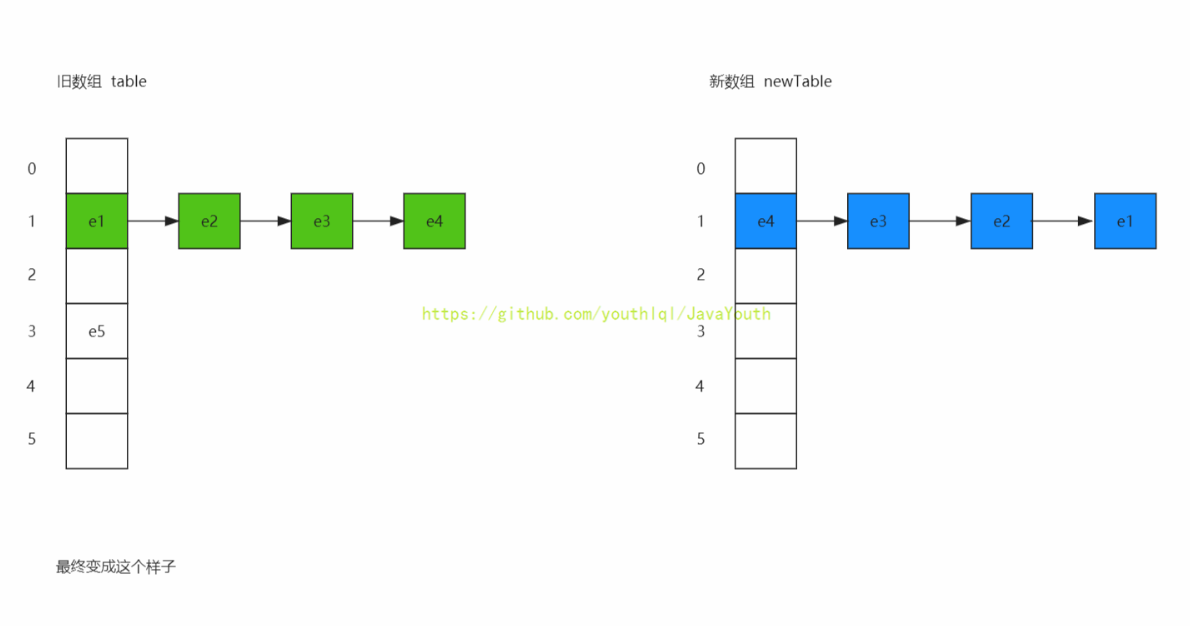 @@ -871,7 +871,7 @@ void transfer(Entry[] newTable, boolean rehash) {
**hashmap初始状态**
-
@@ -871,7 +871,7 @@ void transfer(Entry[] newTable, boolean rehash) {
**hashmap初始状态**
- +
+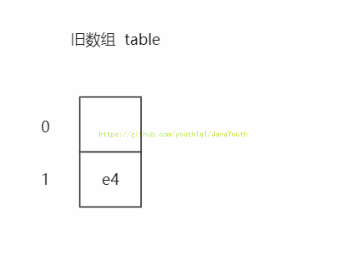 @@ -897,7 +897,7 @@ void transfer(Entry[] newTable, boolean rehash) {
**两个线程调用完毕之后,hashmap目前是这样的。**
-
@@ -897,7 +897,7 @@ void transfer(Entry[] newTable, boolean rehash) {
**两个线程调用完毕之后,hashmap目前是这样的。**
- +
+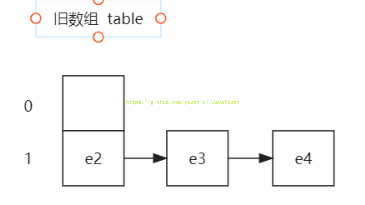 @@ -918,9 +918,9 @@ void transfer(Entry[] newTable, boolean rehash) {
3、来看下此时内存里的状态
-
@@ -918,9 +918,9 @@ void transfer(Entry[] newTable, boolean rehash) {
3、来看下此时内存里的状态
- +
+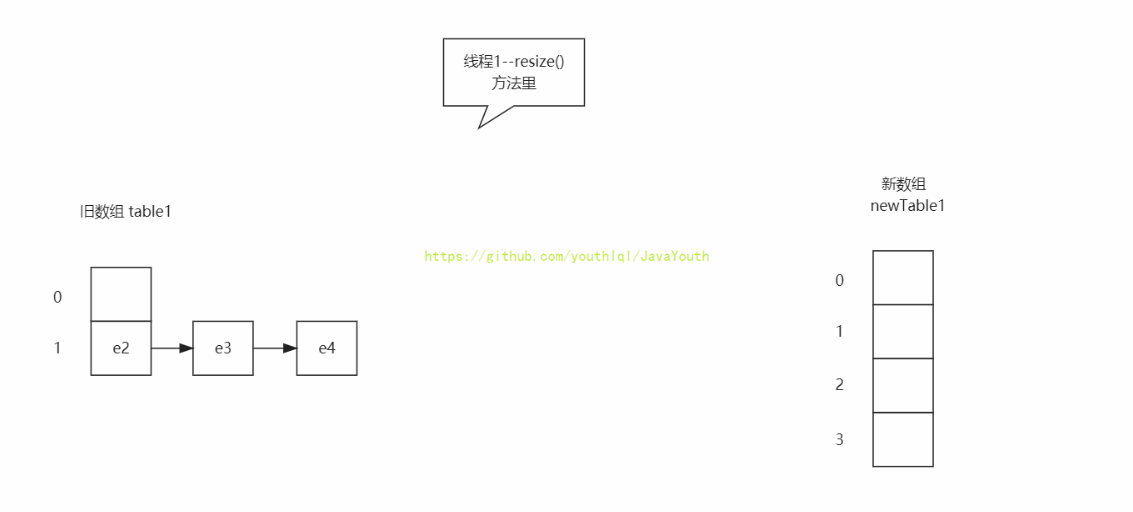 -
- +
+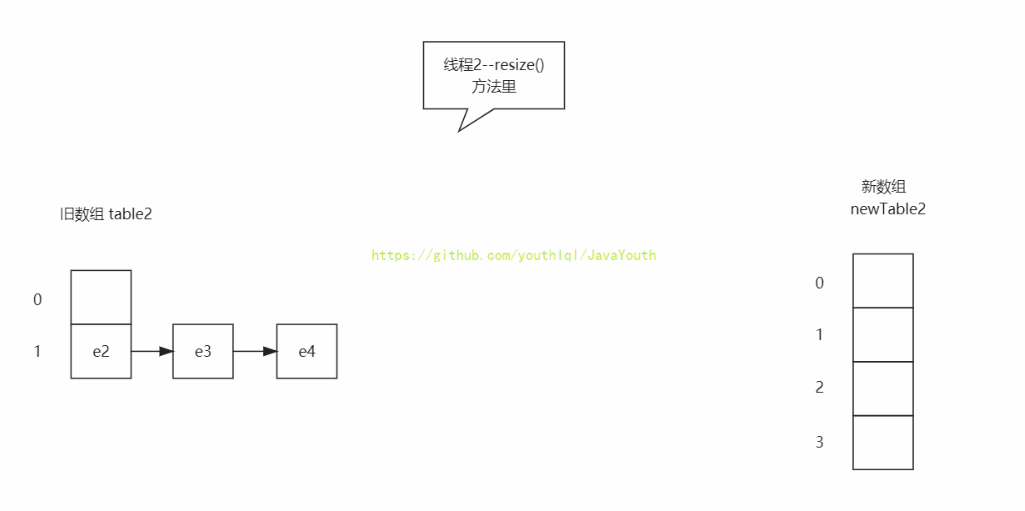 ## 步骤4
@@ -957,7 +957,7 @@ void transfer(Entry[] newTable, boolean rehash) {
2、线程2直接**扩容完毕**,那么完成后的状态是这样【假设e2和e3还是hash到同一个位置】
-
## 步骤4
@@ -957,7 +957,7 @@ void transfer(Entry[] newTable, boolean rehash) {
2、线程2直接**扩容完毕**,那么完成后的状态是这样【假设e2和e3还是hash到同一个位置】
- +
+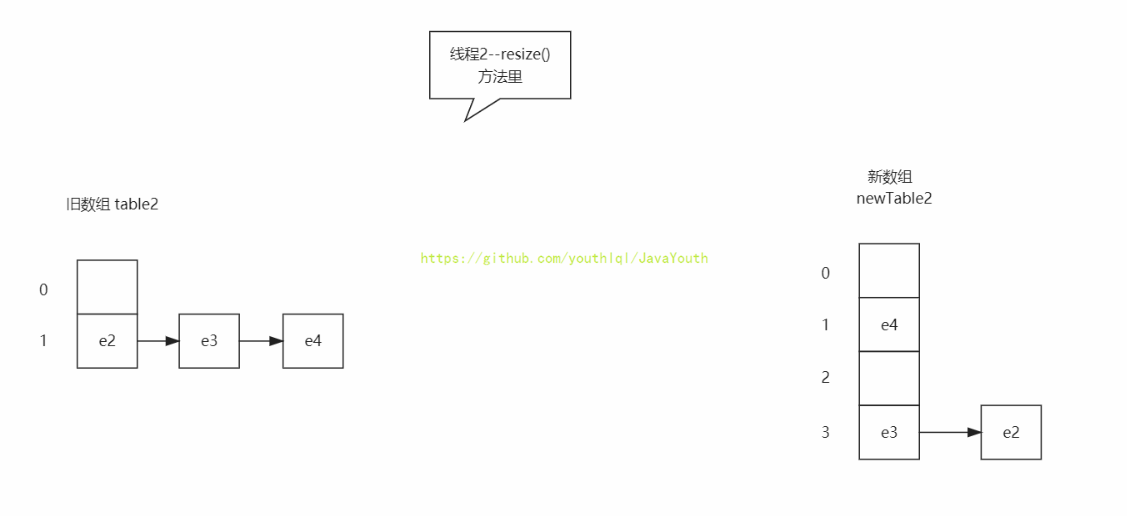 3、线程1还是原来的状态
@@ -967,11 +967,11 @@ void transfer(Entry[] newTable, boolean rehash) {
目前两个线程里的新数组是这样的
-
3、线程1还是原来的状态
@@ -967,11 +967,11 @@ void transfer(Entry[] newTable, boolean rehash) {
目前两个线程里的新数组是这样的
- +
+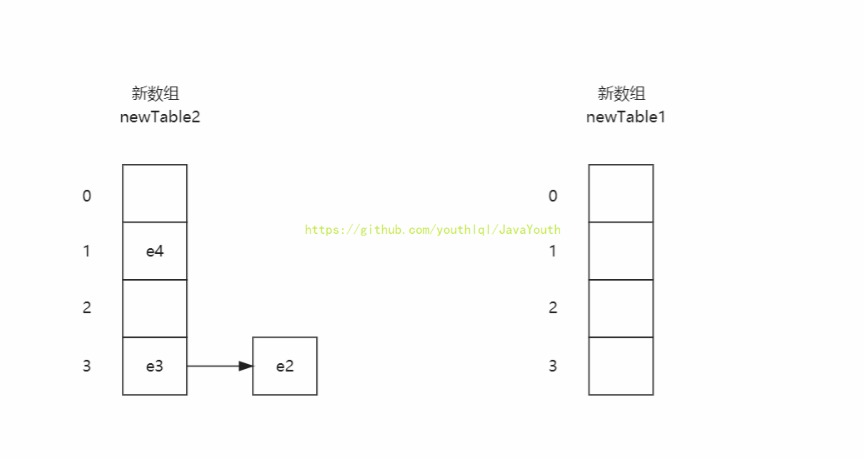 为了方便后面观看,我画成这样。
-
为了方便后面观看,我画成这样。
- +
+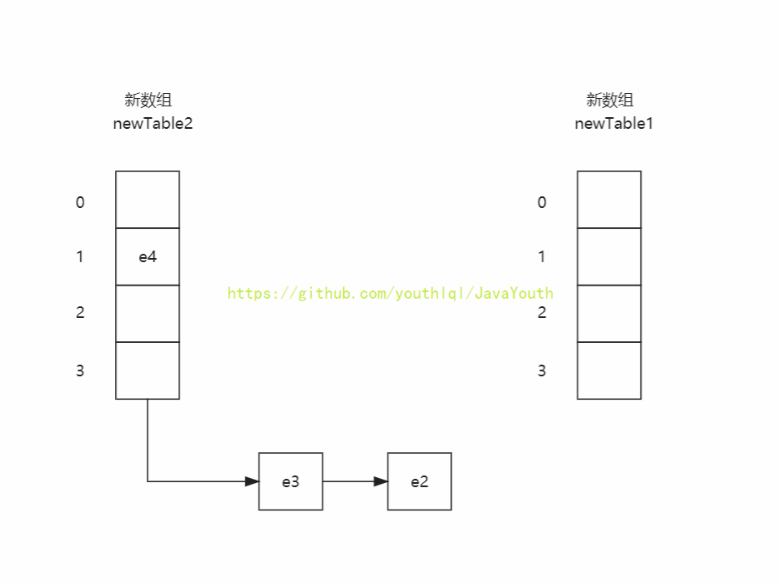 @@ -1015,7 +1015,7 @@ void transfer(Entry[] newTable, boolean rehash) {
也就变成了下面这个样子。
-
@@ -1015,7 +1015,7 @@ void transfer(Entry[] newTable, boolean rehash) {
也就变成了下面这个样子。
- +
+ @@ -1061,7 +1061,7 @@ void transfer(Entry[] newTable, boolean rehash) {
执行完,变成这样。
-
@@ -1061,7 +1061,7 @@ void transfer(Entry[] newTable, boolean rehash) {
执行完,变成这样。
- +
+ @@ -1077,7 +1077,7 @@ void transfer(Entry[] newTable, boolean rehash) {
3、执行pos_3: newTable[i] = e得到 newTable1[3] == e2
-
@@ -1077,7 +1077,7 @@ void transfer(Entry[] newTable, boolean rehash) {
3、执行pos_3: newTable[i] = e得到 newTable1[3] == e2
- +
+ 这样就形成了循环链表,再get()数据就会陷入死循环。
diff --git a/docs/Java/collection/HashMap-JDK8源码讲解及常见面试题.md b/docs/Java/collection/HashMap-JDK8源码讲解及常见面试题.md
index 1bb59fc..b6fda3d 100644
--- a/docs/Java/collection/HashMap-JDK8源码讲解及常见面试题.md
+++ b/docs/Java/collection/HashMap-JDK8源码讲解及常见面试题.md
@@ -27,7 +27,7 @@ date: 2020-11-01 10:22:05
在JDK8中,优化了HashMap的数据结构,引入了红黑树。即HashMap的数据结构:数组+链表+红黑树。HashMap变成了这样。
-
这样就形成了循环链表,再get()数据就会陷入死循环。
diff --git a/docs/Java/collection/HashMap-JDK8源码讲解及常见面试题.md b/docs/Java/collection/HashMap-JDK8源码讲解及常见面试题.md
index 1bb59fc..b6fda3d 100644
--- a/docs/Java/collection/HashMap-JDK8源码讲解及常见面试题.md
+++ b/docs/Java/collection/HashMap-JDK8源码讲解及常见面试题.md
@@ -27,7 +27,7 @@ date: 2020-11-01 10:22:05
在JDK8中,优化了HashMap的数据结构,引入了红黑树。即HashMap的数据结构:数组+链表+红黑树。HashMap变成了这样。
- +
+ ### 为什么要引入红黑树
@@ -456,7 +456,7 @@ Process finished with exit code 0
JDK8 hash的运算原理:高位参与低位运算,使得hash更加均匀。
-
### 为什么要引入红黑树
@@ -456,7 +456,7 @@ Process finished with exit code 0
JDK8 hash的运算原理:高位参与低位运算,使得hash更加均匀。
- +
+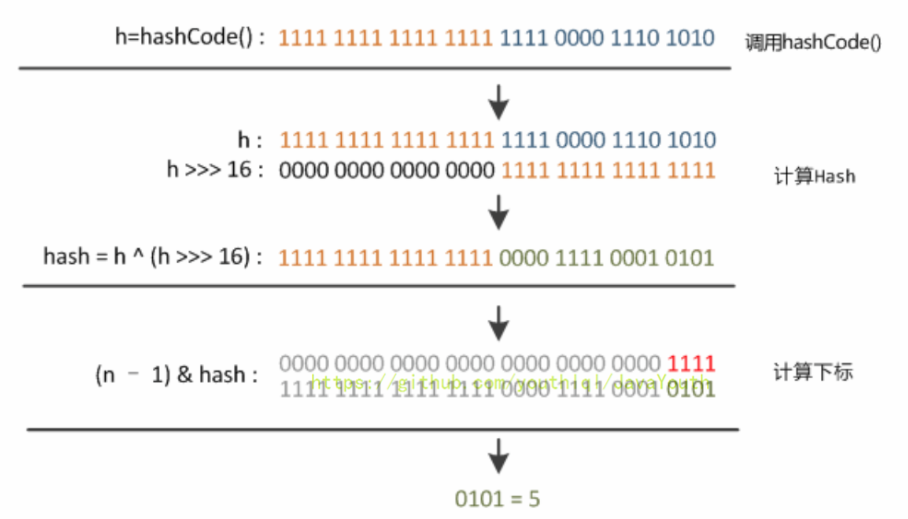 @@ -569,7 +569,7 @@ JDK8 hash的运算原理:高位参与低位运算,使得hash更加均匀。
JDK8扩容时,数据在数组下标的计算方式
-
@@ -569,7 +569,7 @@ JDK8 hash的运算原理:高位参与低位运算,使得hash更加均匀。
JDK8扩容时,数据在数组下标的计算方式
- +
+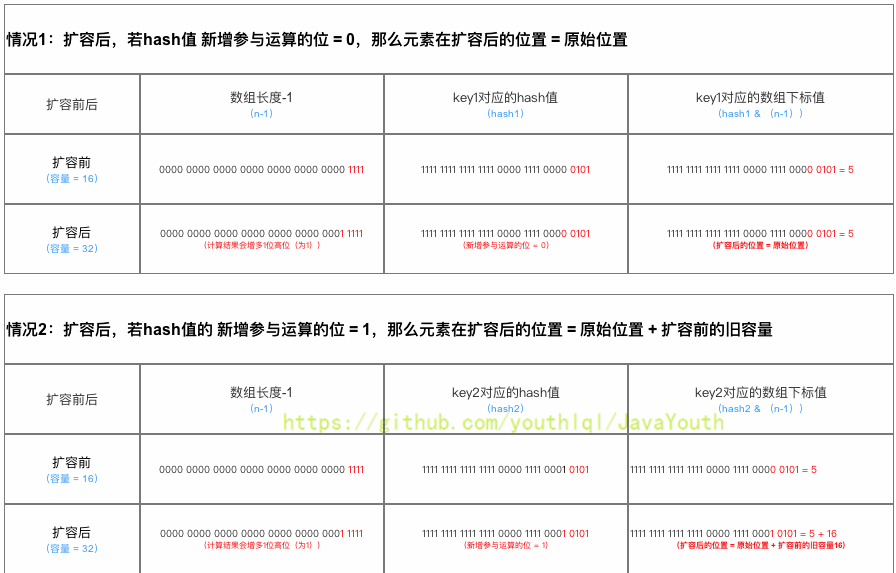 * `JDK8`根据此结论作出的新元素存储位置计算规则非常简单,提高了扩容效率。
diff --git a/docs/design_patterns/设计模式-01.设计思想.md b/docs/design_patterns/设计模式-01.设计思想.md
index bdaacc5..3133c7b 100644
--- a/docs/design_patterns/设计模式-01.设计思想.md
+++ b/docs/design_patterns/设计模式-01.设计思想.md
@@ -198,7 +198,7 @@ public class Ostrich extends AbstractBird { //鸵鸟
1. 这种设计思路虽然可以解决问题,但不够优美。因为除了鸵鸟之外,不会飞的鸟还有很多,比如企鹅。对于这些不会飞的鸟来说,我们都需要重写 fly() 方法,抛出异常。这样的设计,一方面,徒增了编码的工作量;另一方面,也违背了我们之后要讲的最小知识原则(Least Knowledge Principle,也叫最少知识原则或者迪米特法则),暴露不该暴露的接口给外部,增加了类使用过程中被误用的概率。
2. 你可能又会说,那我们再通过 AbstractBird 类派生出两个更加细分的抽象类:会飞的鸟类 AbstractFlyableBird 和不会飞的鸟类 AbstractUnFlyableBird,让麻雀、乌鸦这些会飞的鸟都继承 AbstractFlyableBird,让鸵鸟、企鹅这些不会飞的鸟,都继承 AbstractUnFlyableBird 类,不就可以了吗?具体的继承关系如下图所示:
-
* `JDK8`根据此结论作出的新元素存储位置计算规则非常简单,提高了扩容效率。
diff --git a/docs/design_patterns/设计模式-01.设计思想.md b/docs/design_patterns/设计模式-01.设计思想.md
index bdaacc5..3133c7b 100644
--- a/docs/design_patterns/设计模式-01.设计思想.md
+++ b/docs/design_patterns/设计模式-01.设计思想.md
@@ -198,7 +198,7 @@ public class Ostrich extends AbstractBird { //鸵鸟
1. 这种设计思路虽然可以解决问题,但不够优美。因为除了鸵鸟之外,不会飞的鸟还有很多,比如企鹅。对于这些不会飞的鸟来说,我们都需要重写 fly() 方法,抛出异常。这样的设计,一方面,徒增了编码的工作量;另一方面,也违背了我们之后要讲的最小知识原则(Least Knowledge Principle,也叫最少知识原则或者迪米特法则),暴露不该暴露的接口给外部,增加了类使用过程中被误用的概率。
2. 你可能又会说,那我们再通过 AbstractBird 类派生出两个更加细分的抽象类:会飞的鸟类 AbstractFlyableBird 和不会飞的鸟类 AbstractUnFlyableBird,让麻雀、乌鸦这些会飞的鸟都继承 AbstractFlyableBird,让鸵鸟、企鹅这些不会飞的鸟,都继承 AbstractUnFlyableBird 类,不就可以了吗?具体的继承关系如下图所示:
- +
+ @@ -206,7 +206,7 @@ public class Ostrich extends AbstractBird { //鸵鸟
2. 是否会飞?是否会叫?两个行为搭配起来会产生四种情况:会飞会叫、不会飞会叫、会飞不会叫、不会飞不会叫。如果我们继续沿用刚才的设计思路,那就需要再定义四个抽象类(AbstractFlyableTweetableBird、AbstractFlyableUnTweetableBird、AbstractUnFlyableTweetableBird、AbstractUnFlyableUnTweetableBird)。
-
@@ -206,7 +206,7 @@ public class Ostrich extends AbstractBird { //鸵鸟
2. 是否会飞?是否会叫?两个行为搭配起来会产生四种情况:会飞会叫、不会飞会叫、会飞不会叫、不会飞不会叫。如果我们继续沿用刚才的设计思路,那就需要再定义四个抽象类(AbstractFlyableTweetableBird、AbstractFlyableUnTweetableBird、AbstractUnFlyableTweetableBird、AbstractUnFlyableUnTweetableBird)。
- +
+ @@ -376,7 +376,7 @@ demofunction(client);
-
@@ -376,7 +376,7 @@ demofunction(client);
- +
+ diff --git a/docs/design_patterns/设计模式-02.经典设计原则-第二节[必读].md b/docs/design_patterns/设计模式-02.经典设计原则-第二节[必读].md
index f5470ba..5c73cb4 100644
--- a/docs/design_patterns/设计模式-02.经典设计原则-第二节[必读].md
+++ b/docs/design_patterns/设计模式-02.经典设计原则-第二节[必读].md
@@ -724,7 +724,7 @@ public class UserRepo {
前面也提到,“高内聚”有助于“松耦合”,同理,“低内聚”也会导致“紧耦合”。关于这一点,我画了一张对比图来解释。图中左边部分的代码结构是“高内聚、松耦合”;右边部分正好相反,是“低内聚、紧耦合”。
-
diff --git a/docs/design_patterns/设计模式-02.经典设计原则-第二节[必读].md b/docs/design_patterns/设计模式-02.经典设计原则-第二节[必读].md
index f5470ba..5c73cb4 100644
--- a/docs/design_patterns/设计模式-02.经典设计原则-第二节[必读].md
+++ b/docs/design_patterns/设计模式-02.经典设计原则-第二节[必读].md
@@ -724,7 +724,7 @@ public class UserRepo {
前面也提到,“高内聚”有助于“松耦合”,同理,“低内聚”也会导致“紧耦合”。关于这一点,我画了一张对比图来解释。图中左边部分的代码结构是“高内聚、松耦合”;右边部分正好相反,是“低内聚、紧耦合”。
- +
+ diff --git a/docs/design_patterns/设计模式-03.02-创建型-工厂&建造者&原型.md b/docs/design_patterns/设计模式-03.02-创建型-工厂&建造者&原型.md
index bbe1815..459dcc9 100644
--- a/docs/design_patterns/设计模式-03.02-创建型-工厂&建造者&原型.md
+++ b/docs/design_patterns/设计模式-03.02-创建型-工厂&建造者&原型.md
@@ -727,7 +727,7 @@ public class BeansFactory {
1. 在平时的开发中,创建一个对象最常用的方式是,使用 new 关键字调用类的构造函数来完成。我的问题是,什么情况下这种方式就不适用了,就需要采用建造者模式来创建对象呢?你可以先思考一下,下面我通过一个例子来带你看一下。
2. 假设有这样一道设计面试题:我们需要定义一个资源池配置类 ResourcePoolConfig。这里的资源池,你可以简单理解为线程池、连接池、对象池等。在这个资源池配置类中,有以下几个成员变量,也就是可配置项。现在,请你编写代码实现这个 ResourcePoolConfig 类。
-
diff --git a/docs/design_patterns/设计模式-03.02-创建型-工厂&建造者&原型.md b/docs/design_patterns/设计模式-03.02-创建型-工厂&建造者&原型.md
index bbe1815..459dcc9 100644
--- a/docs/design_patterns/设计模式-03.02-创建型-工厂&建造者&原型.md
+++ b/docs/design_patterns/设计模式-03.02-创建型-工厂&建造者&原型.md
@@ -727,7 +727,7 @@ public class BeansFactory {
1. 在平时的开发中,创建一个对象最常用的方式是,使用 new 关键字调用类的构造函数来完成。我的问题是,什么情况下这种方式就不适用了,就需要采用建造者模式来创建对象呢?你可以先思考一下,下面我通过一个例子来带你看一下。
2. 假设有这样一道设计面试题:我们需要定义一个资源池配置类 ResourcePoolConfig。这里的资源池,你可以简单理解为线程池、连接池、对象池等。在这个资源池配置类中,有以下几个成员变量,也就是可配置项。现在,请你编写代码实现这个 ResourcePoolConfig 类。
- +
+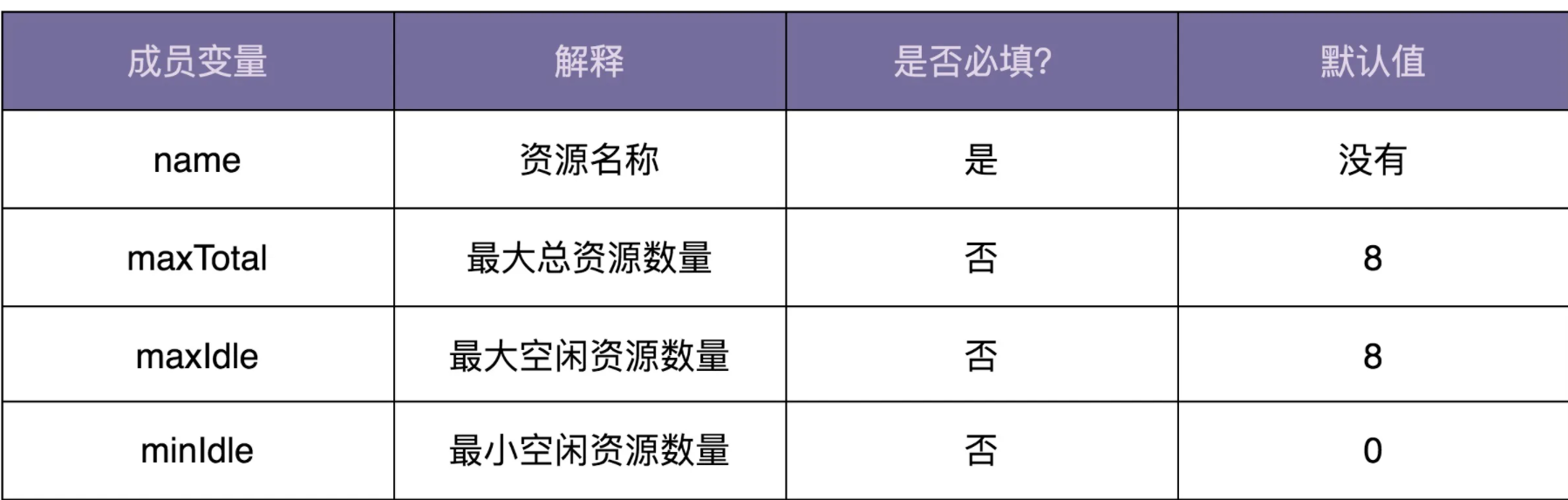 @@ -1003,7 +1003,7 @@ r.setHeight(3); // r is valid
2. 如果你熟悉的是 Java 语言,可以直接使用语言中提供的 HashMap 容器来实现。其中,HashMap 的 key 为搜索关键词,value 为关键词详细信息(比如搜索次数)。我们只需要将数据从数据库中读取出来,放入 HashMap 就可以了。
3. 不过,我们还有另外一个系统 B,专门用来分析搜索日志,定期(比如间隔 10 分钟)批量地更新数据库中的数据,并且标记为新的数据版本。比如,在下面的示例图中,我们对 v2 版本的数据进行更新,得到 v3 版本的数据。这里我们假设只有更新和新添关键词,没有删除关键词的行为。
-
@@ -1003,7 +1003,7 @@ r.setHeight(3); // r is valid
2. 如果你熟悉的是 Java 语言,可以直接使用语言中提供的 HashMap 容器来实现。其中,HashMap 的 key 为搜索关键词,value 为关键词详细信息(比如搜索次数)。我们只需要将数据从数据库中读取出来,放入 HashMap 就可以了。
3. 不过,我们还有另外一个系统 B,专门用来分析搜索日志,定期(比如间隔 10 分钟)批量地更新数据库中的数据,并且标记为新的数据版本。比如,在下面的示例图中,我们对 v2 版本的数据进行更新,得到 v3 版本的数据。这里我们假设只有更新和新添关键词,没有删除关键词的行为。
- +
+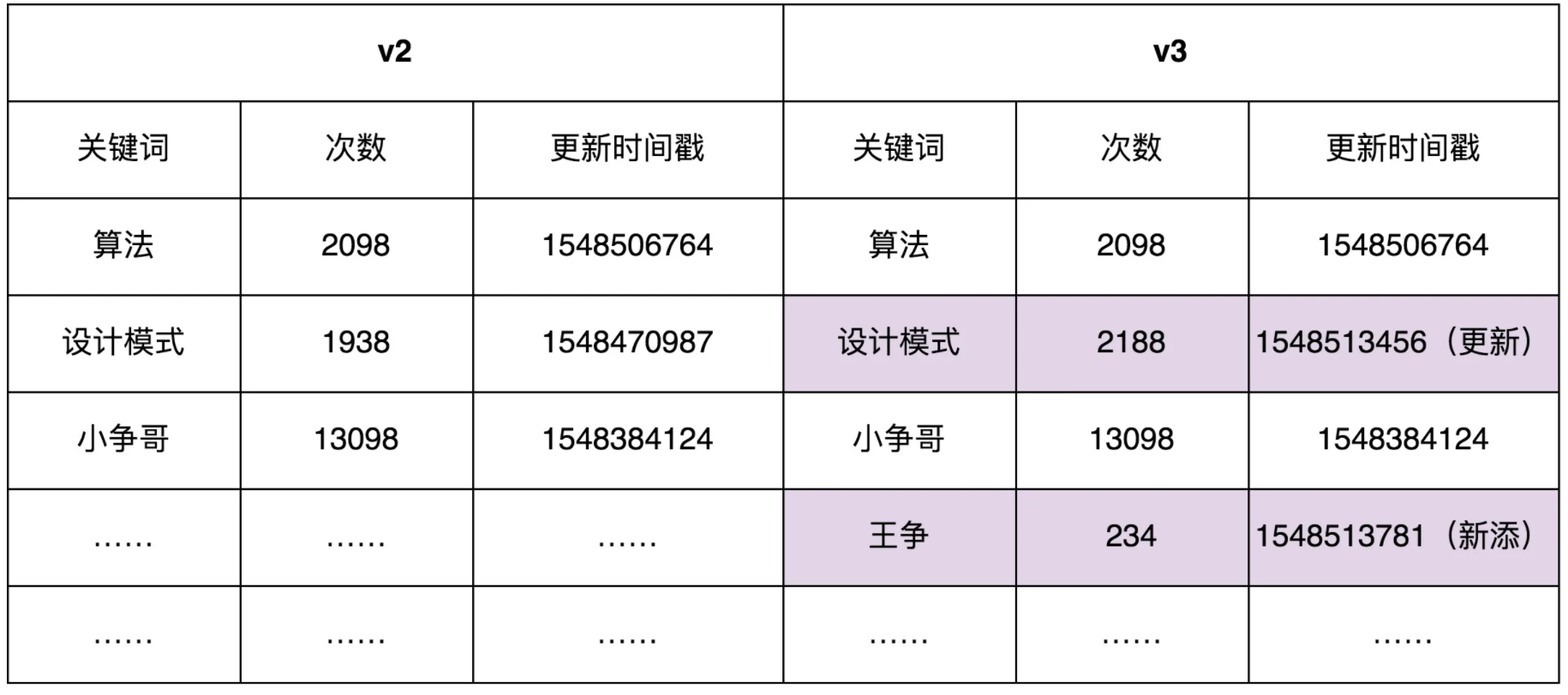 @@ -1150,15 +1150,15 @@ public class Demo {
我们来看,在内存中,用散列表组织的搜索关键词信息是如何存储的。我画了一张示意图,大致结构如下所示。从图中我们可以发现,散列表索引中,每个结点存储的 key 是搜索关键词,value 是 SearchWord 对象的内存地址。SearchWord 对象本身存储在散列表之外的内存空间中。
-
@@ -1150,15 +1150,15 @@ public class Demo {
我们来看,在内存中,用散列表组织的搜索关键词信息是如何存储的。我画了一张示意图,大致结构如下所示。从图中我们可以发现,散列表索引中,每个结点存储的 key 是搜索关键词,value 是 SearchWord 对象的内存地址。SearchWord 对象本身存储在散列表之外的内存空间中。
- +
+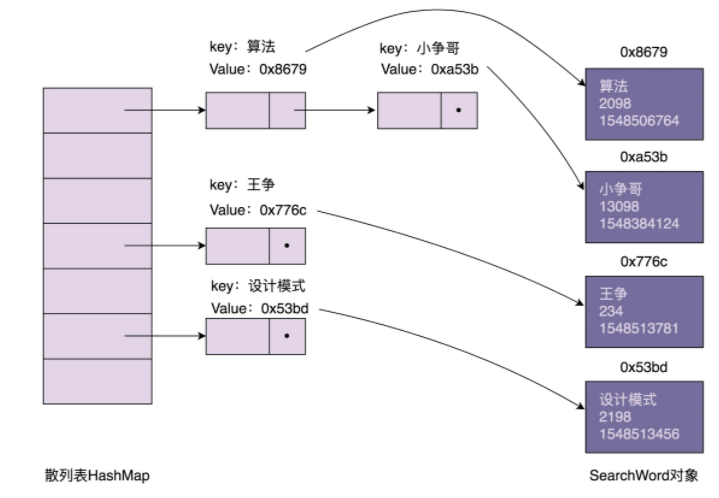 浅拷贝和深拷贝的区别在于,浅拷贝只会复制图中的索引(散列表),不会复制数据(SearchWord 对象)本身。相反,深拷贝不仅仅会复制索引,还会复制数据本身。浅拷贝得到的对象(newKeywords)跟原始对象(currentKeywords)共享数据(SearchWord 对象),而深拷贝得到的是一份完完全全独立的对象。具体的对比如下图所示:
-
浅拷贝和深拷贝的区别在于,浅拷贝只会复制图中的索引(散列表),不会复制数据(SearchWord 对象)本身。相反,深拷贝不仅仅会复制索引,还会复制数据本身。浅拷贝得到的对象(newKeywords)跟原始对象(currentKeywords)共享数据(SearchWord 对象),而深拷贝得到的是一份完完全全独立的对象。具体的对比如下图所示:
- +
+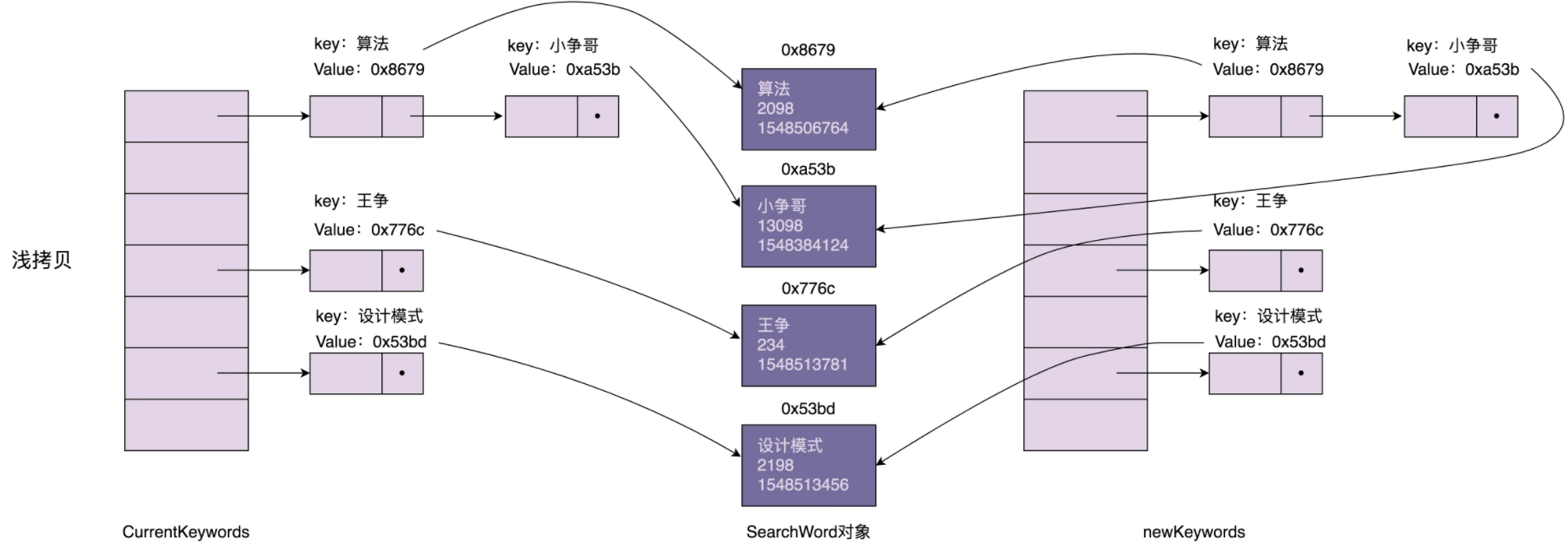 -
- +
+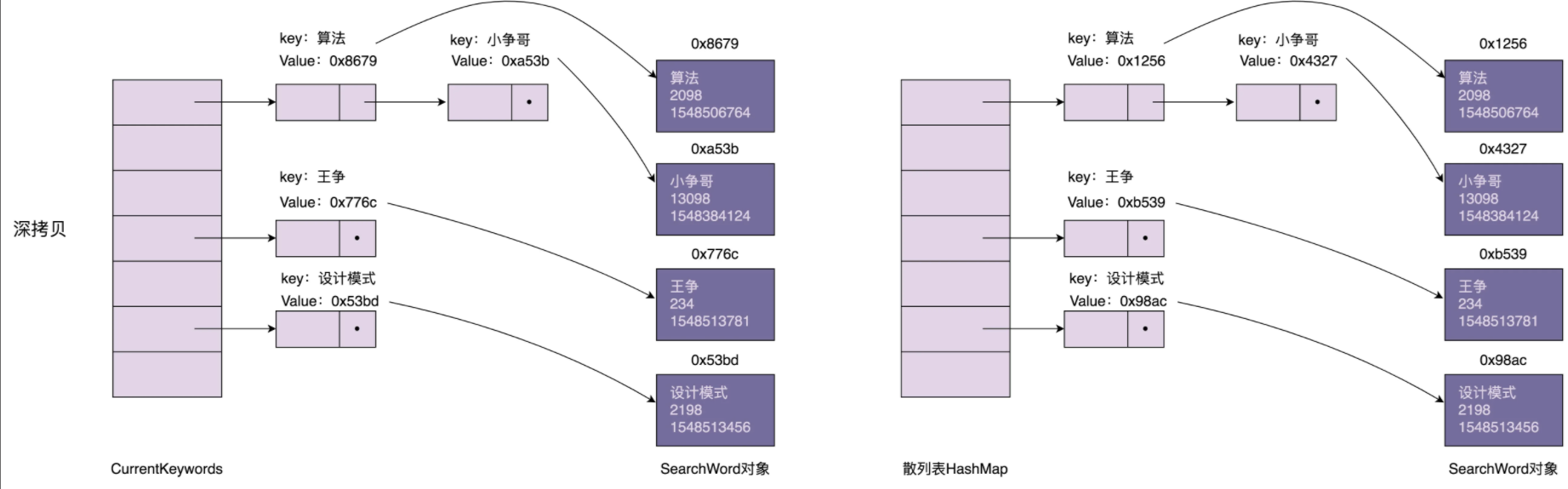 diff --git a/docs/design_patterns/设计模式-04.01-结构型-代理&桥接&装饰器&适配器.md b/docs/design_patterns/设计模式-04.01-结构型-代理&桥接&装饰器&适配器.md
index 0cfd426..e0ef00c 100644
--- a/docs/design_patterns/设计模式-04.01-结构型-代理&桥接&装饰器&适配器.md
+++ b/docs/design_patterns/设计模式-04.01-结构型-代理&桥接&装饰器&适配器.md
@@ -608,7 +608,7 @@ IUserController userController = (IUserController) proxy.createProxy(new UserCon
现在对不同手机类型的不同品牌实现操作编程(比如:开机、关机、上网,打电话等),如图:
-
diff --git a/docs/design_patterns/设计模式-04.01-结构型-代理&桥接&装饰器&适配器.md b/docs/design_patterns/设计模式-04.01-结构型-代理&桥接&装饰器&适配器.md
index 0cfd426..e0ef00c 100644
--- a/docs/design_patterns/设计模式-04.01-结构型-代理&桥接&装饰器&适配器.md
+++ b/docs/design_patterns/设计模式-04.01-结构型-代理&桥接&装饰器&适配器.md
@@ -608,7 +608,7 @@ IUserController userController = (IUserController) proxy.createProxy(new UserCon
现在对不同手机类型的不同品牌实现操作编程(比如:开机、关机、上网,打电话等),如图:
- +
+ @@ -616,7 +616,7 @@ IUserController userController = (IUserController) proxy.createProxy(new UserCon
传统方法对应的类图
-
@@ -616,7 +616,7 @@ IUserController userController = (IUserController) proxy.createProxy(new UserCon
传统方法对应的类图
- +
+ 1. 扩展性问题(**类爆炸**),如果我们再增加手机的样式(旋转式),就需要增加各个品牌手机的类,同样如果我们增加一个手机品牌,也要在各个手机样式类下增加。
2. 违反了单一职责原则,当我们增加手机样式时,要同时增加所有品牌的手机,这样增加了代码维护成本.
@@ -933,7 +933,7 @@ public class DriverManager {
-
1. 扩展性问题(**类爆炸**),如果我们再增加手机的样式(旋转式),就需要增加各个品牌手机的类,同样如果我们增加一个手机品牌,也要在各个手机样式类下增加。
2. 违反了单一职责原则,当我们增加手机样式时,要同时增加所有品牌的手机,这样增加了代码维护成本.
@@ -933,7 +933,7 @@ public class DriverManager {
- +
+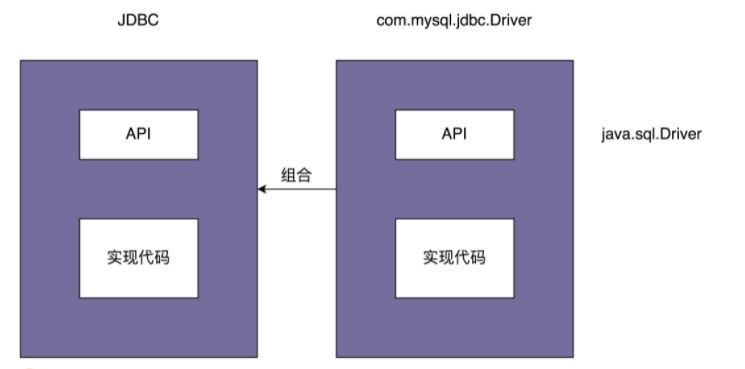 @@ -1112,7 +1112,7 @@ public class TrivialNotification extends Notification {
### 方案一
-
@@ -1112,7 +1112,7 @@ public class TrivialNotification extends Notification {
### 方案一
- +
+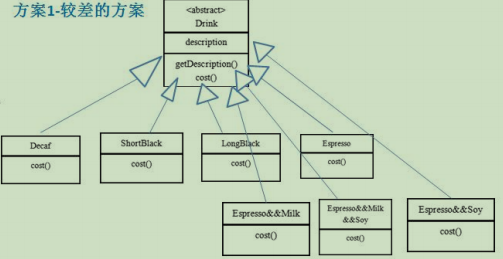 @@ -1127,7 +1127,7 @@ public class TrivialNotification extends Notification {
前面分析到方案 1 因为咖啡单品+调料组合会造成类的倍增,因此可以做改进,将调料内置到 Drink 类,这样就不会造成类数量过多。从而提高项目的维护性(如图)
-
@@ -1127,7 +1127,7 @@ public class TrivialNotification extends Notification {
前面分析到方案 1 因为咖啡单品+调料组合会造成类的倍增,因此可以做改进,将调料内置到 Drink 类,这样就不会造成类数量过多。从而提高项目的维护性(如图)
- +
+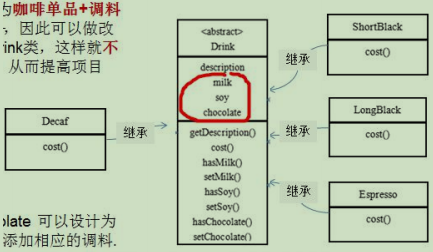 @@ -1142,7 +1142,7 @@ public class TrivialNotification extends Notification {
### 装饰器模式代码
-
@@ -1142,7 +1142,7 @@ public class TrivialNotification extends Notification {
### 装饰器模式代码
- +
+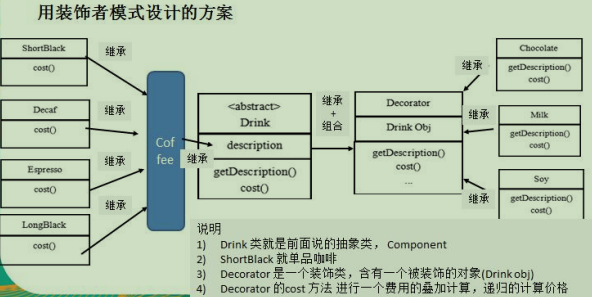 #### Drink【抽象类-主体Component】
@@ -1390,7 +1390,7 @@ Java IO 类库非常庞大和复杂,有几十个类,负责 IO 数据的读
针对不同的读取和写入场景,Java IO 又在这四个父类基础之上,扩展出了很多子类。具体如下所示:
-
#### Drink【抽象类-主体Component】
@@ -1390,7 +1390,7 @@ Java IO 类库非常庞大和复杂,有几十个类,负责 IO 数据的读
针对不同的读取和写入场景,Java IO 又在这四个父类基础之上,扩展出了很多子类。具体如下所示:
- +
+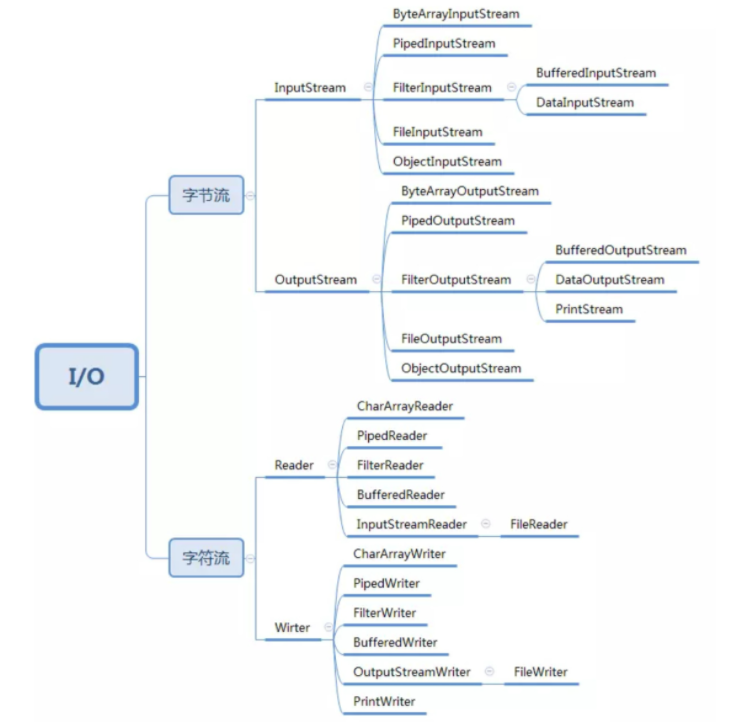 diff --git a/docs/design_patterns/设计模式-04.02-结构型-门面&组合&享元.md b/docs/design_patterns/设计模式-04.02-结构型-门面&组合&享元.md
index 9a63d52..4624173 100644
--- a/docs/design_patterns/设计模式-04.02-结构型-门面&组合&享元.md
+++ b/docs/design_patterns/设计模式-04.02-结构型-门面&组合&享元.md
@@ -75,7 +75,7 @@ date: 2021-07-05 16:51:58
### 传统方案
-
diff --git a/docs/design_patterns/设计模式-04.02-结构型-门面&组合&享元.md b/docs/design_patterns/设计模式-04.02-结构型-门面&组合&享元.md
index 9a63d52..4624173 100644
--- a/docs/design_patterns/设计模式-04.02-结构型-门面&组合&享元.md
+++ b/docs/design_patterns/设计模式-04.02-结构型-门面&组合&享元.md
@@ -75,7 +75,7 @@ date: 2021-07-05 16:51:58
### 传统方案
- +
+ 1. 在 ClientTest 的 main 方法中,创建各个子系统的对象,并直接去调用子系统(对象)相关方法,会造成调用过程 混乱,没有清晰的过程 不利于在 ClientTest 中,去维护对子系统的操作
@@ -623,7 +623,7 @@ public class Demo {
-
1. 在 ClientTest 的 main 方法中,创建各个子系统的对象,并直接去调用子系统(对象)相关方法,会造成调用过程 混乱,没有清晰的过程 不利于在 ClientTest 中,去维护对子系统的操作
@@ -623,7 +623,7 @@ public class Demo {
- +
+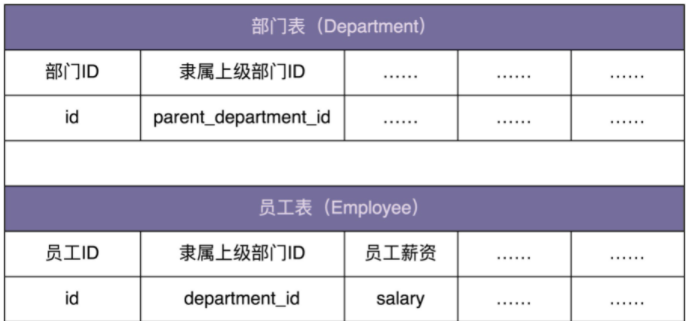 diff --git a/docs/design_patterns/设计模式-05.01-行为型-观察者&模板.md b/docs/design_patterns/设计模式-05.01-行为型-观察者&模板.md
index dc5db09..140f3a5 100644
--- a/docs/design_patterns/设计模式-05.01-行为型-观察者&模板.md
+++ b/docs/design_patterns/设计模式-05.01-行为型-观察者&模板.md
@@ -34,7 +34,7 @@ date: 2021-07-14 16:51:58
### 方案一
-
diff --git a/docs/design_patterns/设计模式-05.01-行为型-观察者&模板.md b/docs/design_patterns/设计模式-05.01-行为型-观察者&模板.md
index dc5db09..140f3a5 100644
--- a/docs/design_patterns/设计模式-05.01-行为型-观察者&模板.md
+++ b/docs/design_patterns/设计模式-05.01-行为型-观察者&模板.md
@@ -34,7 +34,7 @@ date: 2021-07-14 16:51:58
### 方案一
- +
+ @@ -721,11 +721,11 @@ public DObserver{
1. Guava EventBus 的功能我们已经讲清楚了,总体上来说,还是比较简单的。接下来,我们就重复造轮子,“山寨”一个 EventBus 出来。
2. 我们重点来看,EventBus 中两个核心函数 register() 和 post() 的实现原理。弄懂了它们,基本上就弄懂了整个 EventBus 框架。下面两张图是这两个函数的实现原理图。
-
@@ -721,11 +721,11 @@ public DObserver{
1. Guava EventBus 的功能我们已经讲清楚了,总体上来说,还是比较简单的。接下来,我们就重复造轮子,“山寨”一个 EventBus 出来。
2. 我们重点来看,EventBus 中两个核心函数 register() 和 post() 的实现原理。弄懂了它们,基本上就弄懂了整个 EventBus 框架。下面两张图是这两个函数的实现原理图。
- +
+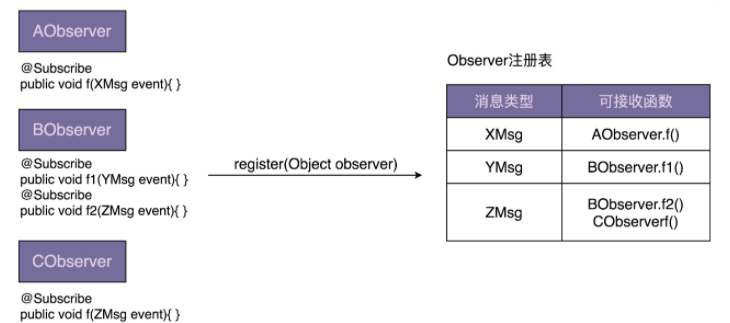 -
- +
+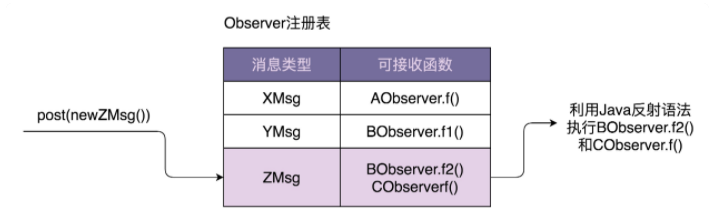 diff --git a/docs/design_patterns/设计模式-05.02-行为型-策略&职责链.md b/docs/design_patterns/设计模式-05.02-行为型-策略&职责链.md
index 029381c..a469a2e 100644
--- a/docs/design_patterns/设计模式-05.02-行为型-策略&职责链.md
+++ b/docs/design_patterns/设计模式-05.02-行为型-策略&职责链.md
@@ -1171,7 +1171,7 @@ public class SensitiveWordFilter {
Servlet Filter 是 Java Servlet 规范中定义的组件,翻译成中文就是过滤器,它可以实现对 HTTP 请求的过滤功能,比如鉴权、限流、记录日志、验证参数等等。因为它是 Servlet 规范的一部分,所以,只要是支持 Servlet 的 Web 容器(比如,Tomcat、Jetty 等),都支持过滤器功能。为了帮助你理解,我画了一张示意图阐述它的工作原理,如下所示。
-
diff --git a/docs/design_patterns/设计模式-05.02-行为型-策略&职责链.md b/docs/design_patterns/设计模式-05.02-行为型-策略&职责链.md
index 029381c..a469a2e 100644
--- a/docs/design_patterns/设计模式-05.02-行为型-策略&职责链.md
+++ b/docs/design_patterns/设计模式-05.02-行为型-策略&职责链.md
@@ -1171,7 +1171,7 @@ public class SensitiveWordFilter {
Servlet Filter 是 Java Servlet 规范中定义的组件,翻译成中文就是过滤器,它可以实现对 HTTP 请求的过滤功能,比如鉴权、限流、记录日志、验证参数等等。因为它是 Servlet 规范的一部分,所以,只要是支持 Servlet 的 Web 容器(比如,Tomcat、Jetty 等),都支持过滤器功能。为了帮助你理解,我画了一张示意图阐述它的工作原理,如下所示。
- +
+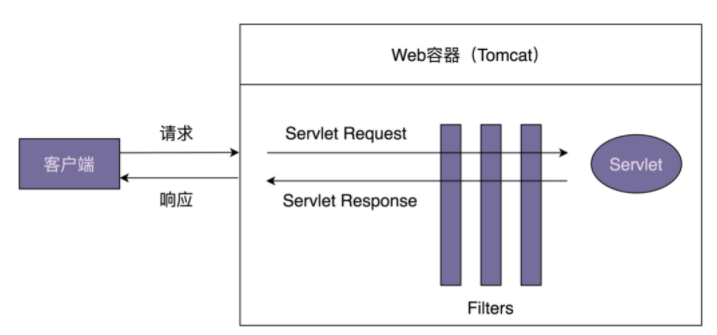 在实际项目中,我们该如何使用 Servlet Filter 呢?我写了一个简单的示例代码,如下所示。添加一个过滤器,我们只需要定义一个实现 javax.servlet.Filter 接口的过滤器类,并且将它配置在 web.xml 配置文件中。Web 容器启动的时候,会读取 web.xml 中的配置,创建过滤器对象。当有请求到来的时候,会先经过过滤器,然后才由 Servlet 来处理。
@@ -1279,7 +1279,7 @@ ApplicationFilterChain 中的 doFilter() 函数的代码实现比较有技巧,
1. 刚刚讲了 Servlet Filter,现在我们来讲一个功能上跟它非常类似的东西,Spring Interceptor,翻译成中文就是拦截器。尽管英文单词和中文翻译都不同,但这两者基本上可以看作一个概念,都用来实现对 HTTP 请求进行拦截处理。
2. 它们不同之处在于,Servlet Filter 是 Servlet 规范的一部分,实现依赖于 Web 容器。Spring Interceptor 是 Spring MVC 框架的一部分,由 Spring MVC 框架来提供实现。客户端发送的请求,会先经过 Servlet Filter,然后再经过 Spring Interceptor,最后到达具体的业务代码中。我画了一张图来阐述一个请求的处理流程,具体如下所示。
-
在实际项目中,我们该如何使用 Servlet Filter 呢?我写了一个简单的示例代码,如下所示。添加一个过滤器,我们只需要定义一个实现 javax.servlet.Filter 接口的过滤器类,并且将它配置在 web.xml 配置文件中。Web 容器启动的时候,会读取 web.xml 中的配置,创建过滤器对象。当有请求到来的时候,会先经过过滤器,然后才由 Servlet 来处理。
@@ -1279,7 +1279,7 @@ ApplicationFilterChain 中的 doFilter() 函数的代码实现比较有技巧,
1. 刚刚讲了 Servlet Filter,现在我们来讲一个功能上跟它非常类似的东西,Spring Interceptor,翻译成中文就是拦截器。尽管英文单词和中文翻译都不同,但这两者基本上可以看作一个概念,都用来实现对 HTTP 请求进行拦截处理。
2. 它们不同之处在于,Servlet Filter 是 Servlet 规范的一部分,实现依赖于 Web 容器。Spring Interceptor 是 Spring MVC 框架的一部分,由 Spring MVC 框架来提供实现。客户端发送的请求,会先经过 Servlet Filter,然后再经过 Spring Interceptor,最后到达具体的业务代码中。我画了一张图来阐述一个请求的处理流程,具体如下所示。
- +
+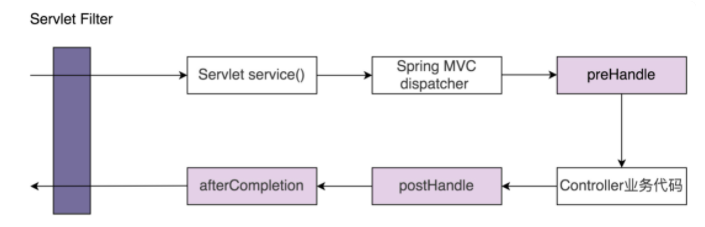 diff --git a/docs/design_patterns/设计模式-05.03-行为型-状态&迭代器.md b/docs/design_patterns/设计模式-05.03-行为型-状态&迭代器.md
index 5835f52..2350b7e 100644
--- a/docs/design_patterns/设计模式-05.03-行为型-状态&迭代器.md
+++ b/docs/design_patterns/设计模式-05.03-行为型-状态&迭代器.md
@@ -30,7 +30,7 @@ date: 2021-08-02 15:51:58
4. 实际上,马里奥形态的转变就是一个状态机。其中,马里奥的不同形态就是状态机中的“状态”,游戏情节(比如吃了蘑菇)就是状态机中的“事件”,加减积分就是状态机中的“动作”。比如,吃蘑菇这个事件,会触发状态的转移:从小马里奥转移到超级马里奥,以及触发动作的执行(增加 100 积分)。
5. 为了方便接下来的讲解,我对游戏背景做了简化,只保留了部分状态和事件。简化之后的状态转移如下图所示:
-
diff --git a/docs/design_patterns/设计模式-05.03-行为型-状态&迭代器.md b/docs/design_patterns/设计模式-05.03-行为型-状态&迭代器.md
index 5835f52..2350b7e 100644
--- a/docs/design_patterns/设计模式-05.03-行为型-状态&迭代器.md
+++ b/docs/design_patterns/设计模式-05.03-行为型-状态&迭代器.md
@@ -30,7 +30,7 @@ date: 2021-08-02 15:51:58
4. 实际上,马里奥形态的转变就是一个状态机。其中,马里奥的不同形态就是状态机中的“状态”,游戏情节(比如吃了蘑菇)就是状态机中的“事件”,加减积分就是状态机中的“动作”。比如,吃蘑菇这个事件,会触发状态的转移:从小马里奥转移到超级马里奥,以及触发动作的执行(增加 100 积分)。
5. 为了方便接下来的讲解,我对游戏背景做了简化,只保留了部分状态和事件。简化之后的状态转移如下图所示:
- +
+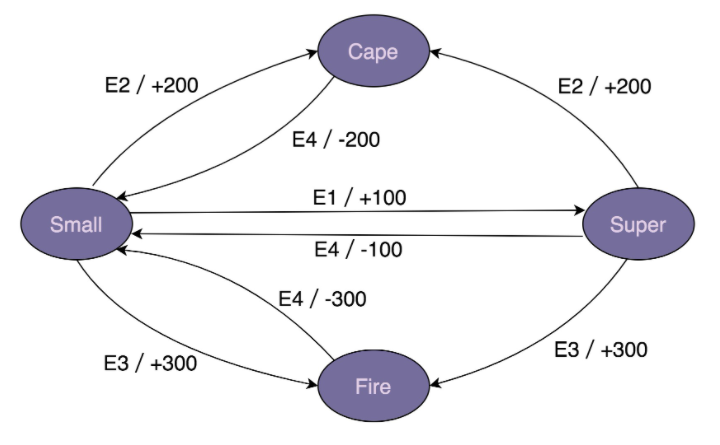 @@ -180,7 +180,7 @@ public class MarioStateMachine {
1. 实际上,上面这种实现方法有点类似 hard code,对于复杂的状态机来说不适用,而状态机的第二种实现方式查表法,就更加合适了。接下来,我们就一块儿来看下,如何利用查表法来补全骨架代码。
2. 实际上,除了用状态转移图来表示之外,状态机还可以用二维表来表示,如下所示。在这个二维表中,第一维表示当前状态,第二维表示事件,值表示当前状态经过事件之后,转移到的新状态及其执行的动作。
-
@@ -180,7 +180,7 @@ public class MarioStateMachine {
1. 实际上,上面这种实现方法有点类似 hard code,对于复杂的状态机来说不适用,而状态机的第二种实现方式查表法,就更加合适了。接下来,我们就一块儿来看下,如何利用查表法来补全骨架代码。
2. 实际上,除了用状态转移图来表示之外,状态机还可以用二维表来表示,如下所示。在这个二维表中,第一维表示当前状态,第二维表示事件,值表示当前状态经过事件之后,转移到的新状态及其执行的动作。
- +
+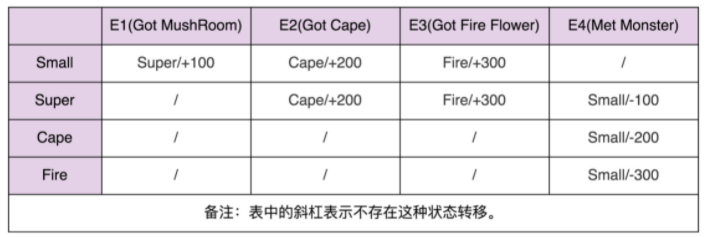 3. 相对于分支逻辑的实现方式,查表法的代码实现更加清晰,可读性和可维护性更好。当修改状态机时,我们只需要修改 transitionTable 和 actionTable 两个二维数组即可。实际上,如果我们把这两个二维数组存储在配置文件中,当需要修改状态机时,我们甚至可以不修改任何代码,只需要修改配置文件就可以了。具体的代码如下所示:
@@ -511,7 +511,7 @@ public class MarioStateMachine {
2. 在开篇中我们讲到,它用来遍历集合对象。这里说的“集合对象”也可以叫“容器”“聚合对象”,实际上就是包含一组对象的对象,比如数组、链表、树、图、跳表。迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一。
3. 迭代器是用来遍历容器的,所以,一个完整的迭代器模式一般会涉及**容器和容器迭代器**部分两部分内容。为了达到基于接口而非实现编程的目的,容器又包含容器接口、容器实现类,迭代器又包含迭代器接口、迭代器实现类。对于迭代器模式,我画了一张简单的类图,你可以看一看,先有个大致的印象。
-
3. 相对于分支逻辑的实现方式,查表法的代码实现更加清晰,可读性和可维护性更好。当修改状态机时,我们只需要修改 transitionTable 和 actionTable 两个二维数组即可。实际上,如果我们把这两个二维数组存储在配置文件中,当需要修改状态机时,我们甚至可以不修改任何代码,只需要修改配置文件就可以了。具体的代码如下所示:
@@ -511,7 +511,7 @@ public class MarioStateMachine {
2. 在开篇中我们讲到,它用来遍历集合对象。这里说的“集合对象”也可以叫“容器”“聚合对象”,实际上就是包含一组对象的对象,比如数组、链表、树、图、跳表。迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一。
3. 迭代器是用来遍历容器的,所以,一个完整的迭代器模式一般会涉及**容器和容器迭代器**部分两部分内容。为了达到基于接口而非实现编程的目的,容器又包含容器接口、容器实现类,迭代器又包含迭代器接口、迭代器实现类。对于迭代器模式,我画了一张简单的类图,你可以看一看,先有个大致的印象。
- +
+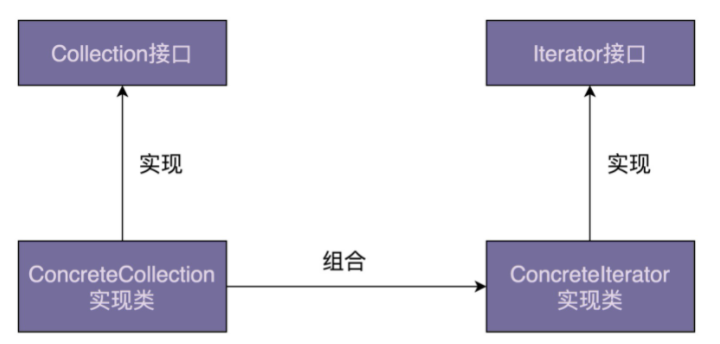 @@ -629,7 +629,7 @@ public class Demo {
2. 结合刚刚的例子,我们来总结一下迭代器的设计思路。总结下来就三句话:迭代器中需要定义 hasNext()、currentItem()、next() 三个最基本的方法。待遍历的容器对象通过依赖注入传递到迭代器类中。容器通过 iterator() 方法来创建迭代器。
3. 这里我画了一张类图,如下所示。实际上就是对上面那张类图的细化,你可以结合着一块看。
-
@@ -629,7 +629,7 @@ public class Demo {
2. 结合刚刚的例子,我们来总结一下迭代器的设计思路。总结下来就三句话:迭代器中需要定义 hasNext()、currentItem()、next() 三个最基本的方法。待遍历的容器对象通过依赖注入传递到迭代器类中。容器通过 iterator() 方法来创建迭代器。
3. 这里我画了一张类图,如下所示。实际上就是对上面那张类图的细化,你可以结合着一块看。
- +
+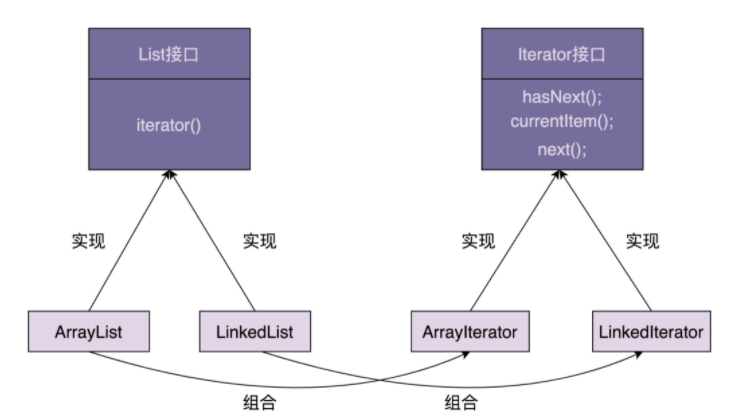 @@ -752,7 +752,7 @@ public class Demo {
4. 为了保持数组存储数据的连续性,数组的删除操作会涉及元素的搬移。当执行到第 57 行代码的时候,我们从数组中将元素 a 删除掉,b、c、d 三个元素会依次往前搬移一位,这就会导致游标本来指向元素 b,现在变成了指向元素 c。原本在执行完第 56 行代码之后,我们还可以遍历到 b、c、d 三个元素,但在执行完第 57 行代码之后,我们只能遍历到 c、d 两个元素,b 遍历不到了。
5. 对于上面的描述,我画了一张图,你可以对照着理解。
-
@@ -752,7 +752,7 @@ public class Demo {
4. 为了保持数组存储数据的连续性,数组的删除操作会涉及元素的搬移。当执行到第 57 行代码的时候,我们从数组中将元素 a 删除掉,b、c、d 三个元素会依次往前搬移一位,这就会导致游标本来指向元素 b,现在变成了指向元素 c。原本在执行完第 56 行代码之后,我们还可以遍历到 b、c、d 三个元素,但在执行完第 57 行代码之后,我们只能遍历到 c、d 两个元素,b 遍历不到了。
5. 对于上面的描述,我画了一张图,你可以对照着理解。
- +
+ 6. 不过,如果第 57 行代码删除的不是游标前面的元素(元素 a)以及游标所在位置的元素(元素 b),而是游标后面的元素(元素 c 和 d),这样就不会存在任何问题了,不会存在某个元素遍历不到的情况了。
7. 所以,我们前面说,在遍历的过程中删除集合元素,结果是不可预期的,有时候没问题(删除元素 c 或 d),有时候就有问题(删除元素 a 或 b),这个要视情况而定(到底删除的是哪个位置的元素),就是这个意思。
@@ -778,7 +778,7 @@ public class Demo {
10. 跟删除情况类似,如果我们在游标的后面添加元素,就不会存在任何问题。所以,在遍历的同时添加集合元素也是一种不可预期行为。
11. 同样,对于上面的添加元素的情况,我们也画了一张图,如下所示,你可以对照着理解。
-
6. 不过,如果第 57 行代码删除的不是游标前面的元素(元素 a)以及游标所在位置的元素(元素 b),而是游标后面的元素(元素 c 和 d),这样就不会存在任何问题了,不会存在某个元素遍历不到的情况了。
7. 所以,我们前面说,在遍历的过程中删除集合元素,结果是不可预期的,有时候没问题(删除元素 c 或 d),有时候就有问题(删除元素 a 或 b),这个要视情况而定(到底删除的是哪个位置的元素),就是这个意思。
@@ -778,7 +778,7 @@ public class Demo {
10. 跟删除情况类似,如果我们在游标的后面添加元素,就不会存在任何问题。所以,在遍历的同时添加集合元素也是一种不可预期行为。
11. 同样,对于上面的添加元素的情况,我们也画了一张图,如下所示,你可以对照着理解。
- +
+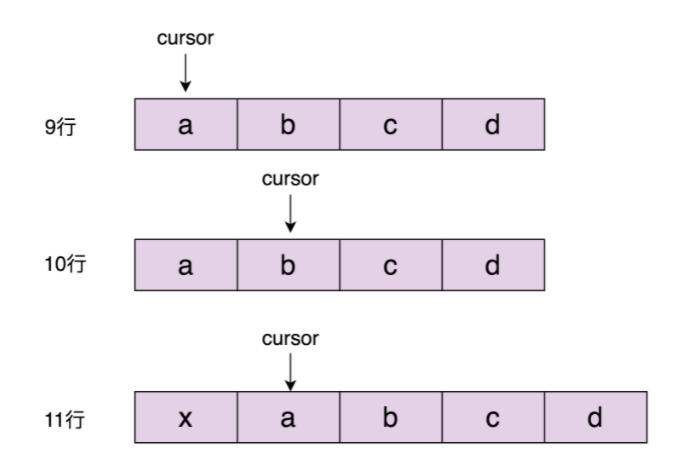 diff --git a/docs/dubbo-sourcecode-v1/01&02.Dubbo源码系列V1-Dubbo第一二节-基本应用与高级应用.md b/docs/dubbo-sourcecode-v1/01&02.Dubbo源码系列V1-Dubbo第一二节-基本应用与高级应用.md
index 13970af..683ffd4 100644
--- a/docs/dubbo-sourcecode-v1/01&02.Dubbo源码系列V1-Dubbo第一二节-基本应用与高级应用.md
+++ b/docs/dubbo-sourcecode-v1/01&02.Dubbo源码系列V1-Dubbo第一二节-基本应用与高级应用.md
@@ -97,7 +97,7 @@ Dubbo网关参考:[https://github.com/apache/dubbo-proxy](https://github.com/a
### 基本原理
-
diff --git a/docs/dubbo-sourcecode-v1/01&02.Dubbo源码系列V1-Dubbo第一二节-基本应用与高级应用.md b/docs/dubbo-sourcecode-v1/01&02.Dubbo源码系列V1-Dubbo第一二节-基本应用与高级应用.md
index 13970af..683ffd4 100644
--- a/docs/dubbo-sourcecode-v1/01&02.Dubbo源码系列V1-Dubbo第一二节-基本应用与高级应用.md
+++ b/docs/dubbo-sourcecode-v1/01&02.Dubbo源码系列V1-Dubbo第一二节-基本应用与高级应用.md
@@ -97,7 +97,7 @@ Dubbo网关参考:[https://github.com/apache/dubbo-proxy](https://github.com/a
### 基本原理
-  +
+  @@ -914,11 +914,11 @@ dubbo.config-center.address=
2. 管理台的**配置管理**作用就是可以实时更改dubbo相关的配置,在这里面写了和在appliaction.properties里面写是一样的效果,这个还不用重启服务。如果appliaction.properties里和管理台写了相同的配置,以管理台的为主。
-
@@ -914,11 +914,11 @@ dubbo.config-center.address=
2. 管理台的**配置管理**作用就是可以实时更改dubbo相关的配置,在这里面写了和在appliaction.properties里面写是一样的效果,这个还不用重启服务。如果appliaction.properties里和管理台写了相同的配置,以管理台的为主。
- +
+ 3. **动态配置**这里,也可以很方便的替代服务提供者@service注解上标注的那些配置。管理台是实时生效的,如果改代码里的@service还需要重启服务。
-
3. **动态配置**这里,也可以很方便的替代服务提供者@service注解上标注的那些配置。管理台是实时生效的,如果改代码里的@service还需要重启服务。
- +
+ 很多配置都可以在管理台上配。管理台上写的配置会持久化在**你配置的配置中心**里。只有注册中心里的服务提供者信息不持久化,如果注册中心是zookeeper,那么服务提供者在zk上就是临时节点。
diff --git a/docs/dubbo-sourcecode-v1/06.Dubbo源码系列V1-Dubbo第六节-服务引入源码解析.md b/docs/dubbo-sourcecode-v1/06.Dubbo源码系列V1-Dubbo第六节-服务引入源码解析.md
index 296e98a..4f247da 100644
--- a/docs/dubbo-sourcecode-v1/06.Dubbo源码系列V1-Dubbo第六节-服务引入源码解析.md
+++ b/docs/dubbo-sourcecode-v1/06.Dubbo源码系列V1-Dubbo第六节-服务引入源码解析.md
@@ -243,7 +243,7 @@ public class Application {
-
很多配置都可以在管理台上配。管理台上写的配置会持久化在**你配置的配置中心**里。只有注册中心里的服务提供者信息不持久化,如果注册中心是zookeeper,那么服务提供者在zk上就是临时节点。
diff --git a/docs/dubbo-sourcecode-v1/06.Dubbo源码系列V1-Dubbo第六节-服务引入源码解析.md b/docs/dubbo-sourcecode-v1/06.Dubbo源码系列V1-Dubbo第六节-服务引入源码解析.md
index 296e98a..4f247da 100644
--- a/docs/dubbo-sourcecode-v1/06.Dubbo源码系列V1-Dubbo第六节-服务引入源码解析.md
+++ b/docs/dubbo-sourcecode-v1/06.Dubbo源码系列V1-Dubbo第六节-服务引入源码解析.md
@@ -243,7 +243,7 @@ public class Application {
-  +
+  ### 源码分析-解析@Reference注解上的配置
@@ -438,19 +438,19 @@ public class Application {
```
-
### 源码分析-解析@Reference注解上的配置
@@ -438,19 +438,19 @@ public class Application {
```
- +
+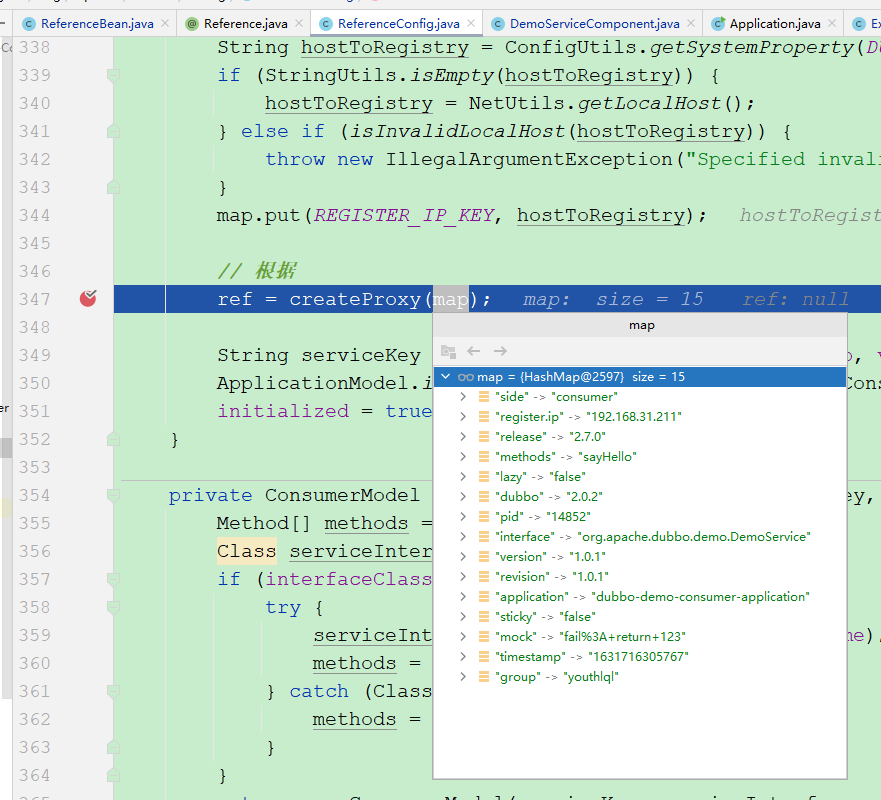 Dubbo官方给的Demo没有配置URL,所以这里就是NULL
-
Dubbo官方给的Demo没有配置URL,所以这里就是NULL
- +
+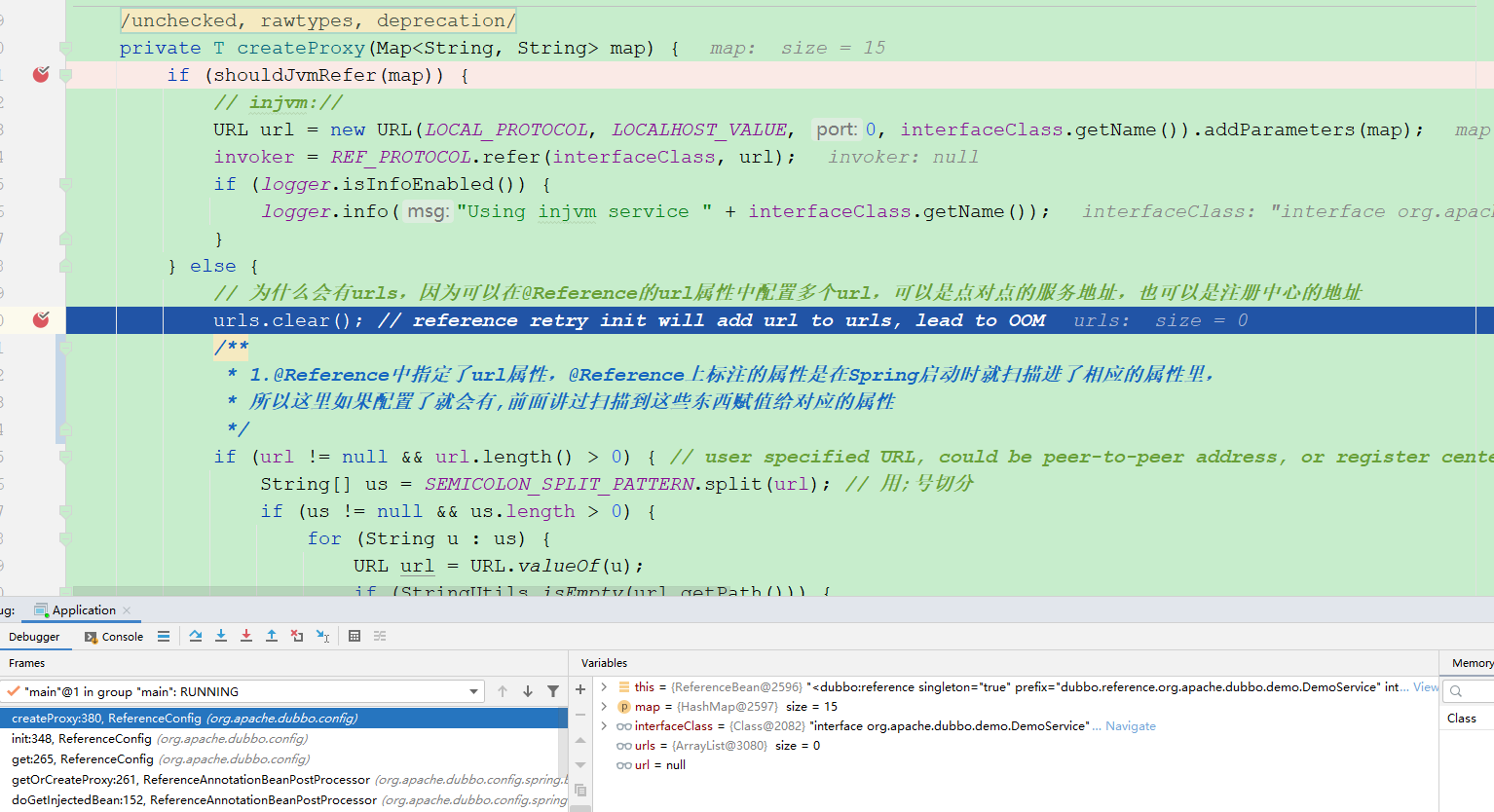 -
- +
+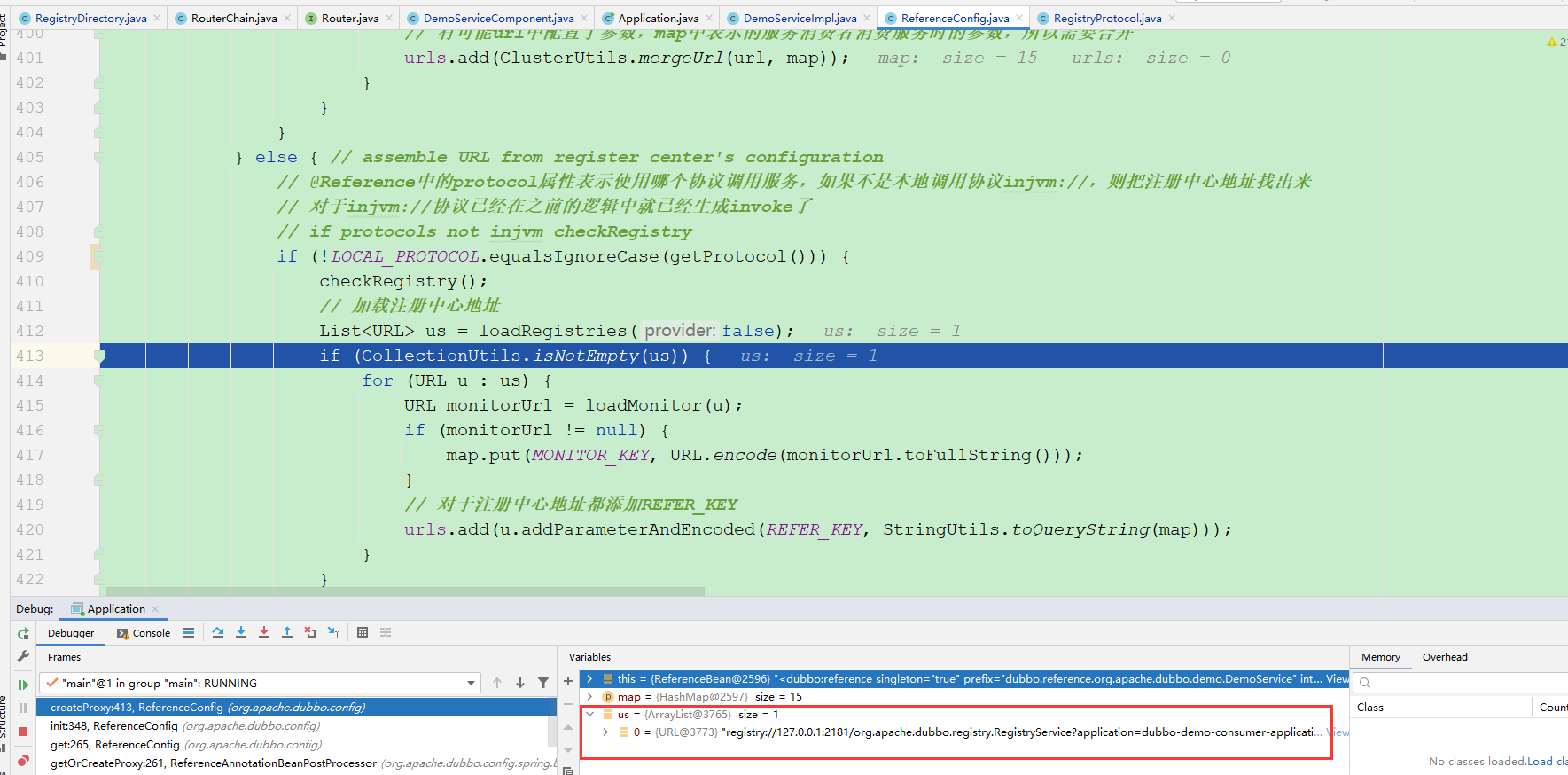 -
- +
+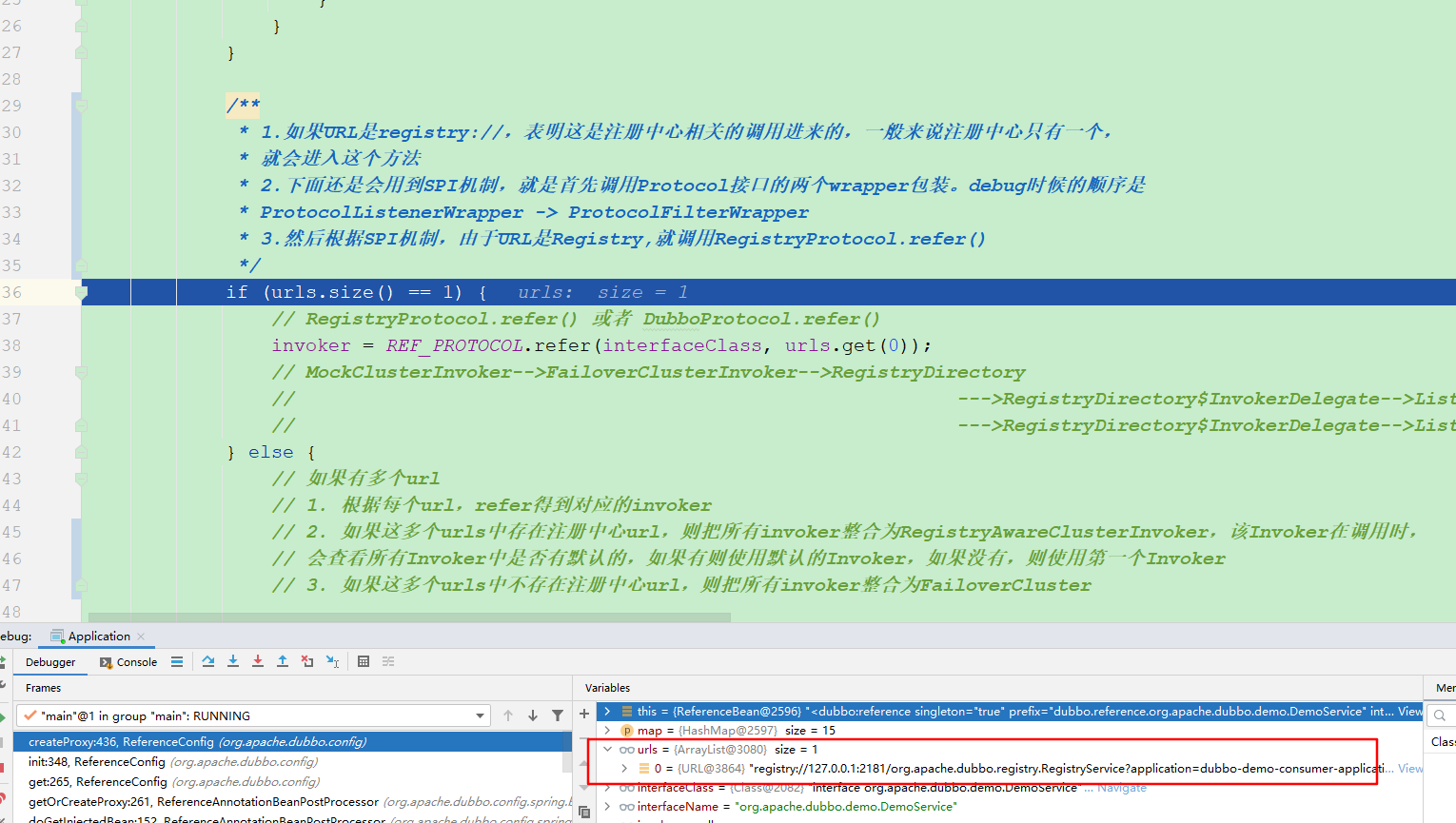 @@ -622,7 +622,7 @@ Dubbo官方给的Demo没有配置URL,所以这里就是NULL
}
```
-
@@ -622,7 +622,7 @@ Dubbo官方给的Demo没有配置URL,所以这里就是NULL
}
```
- +
+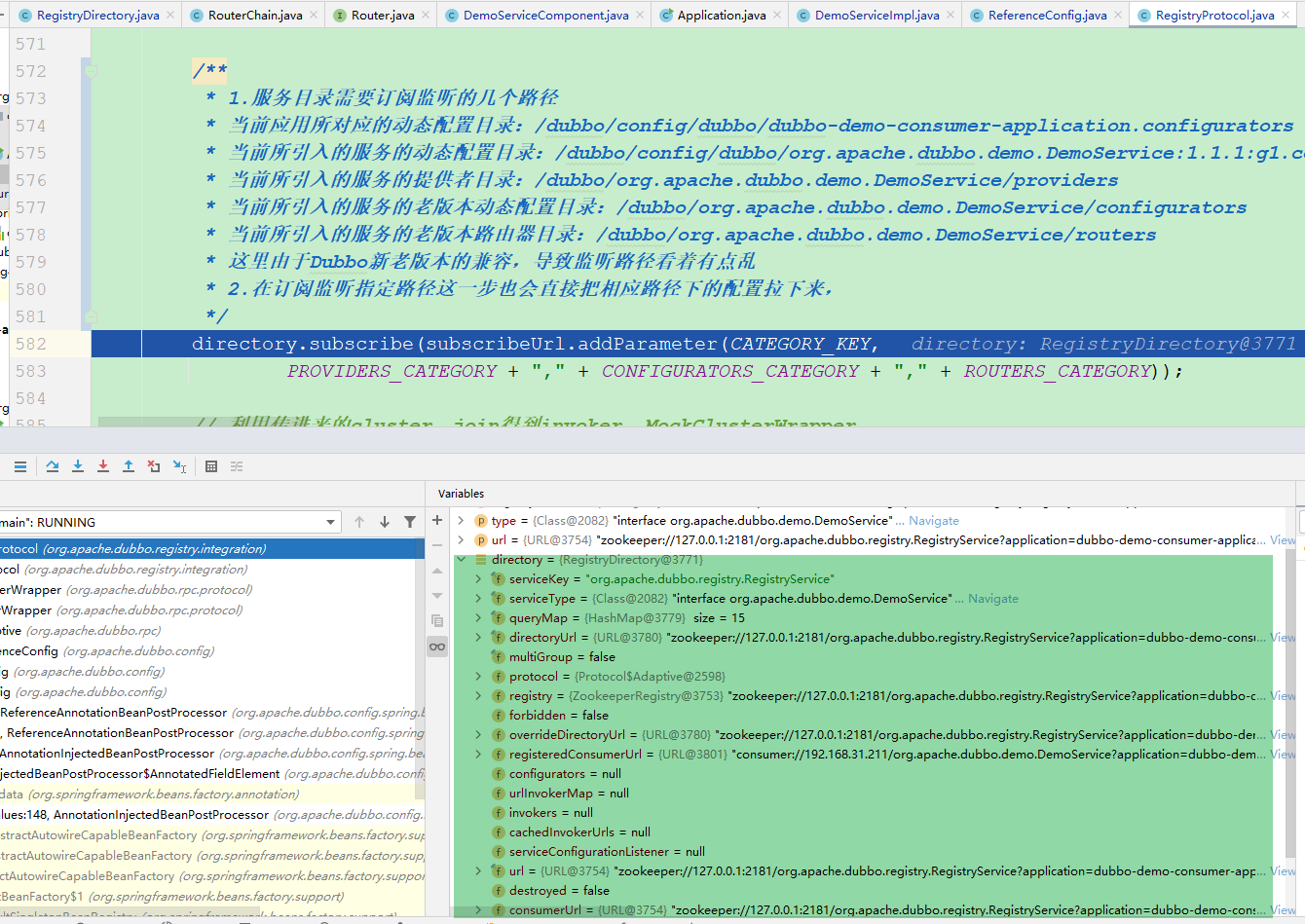 #### RegistryDirectory
@@ -641,7 +641,7 @@ Dubbo官方给的Demo没有配置URL,所以这里就是NULL
3. 看下面的截图,registry属性是zookeeper的URL,所以应该是要调用ZookeeperRegistry的subscribe()方法,但是ZookeeperRegistry没有这个方法,所以我们就要找它的父类了,也就是FailbackRegistry,
4. 然后再调用doSubscribe(),ZookeeperRegistry重写了此方法,很明显这是个模板模式。
-
#### RegistryDirectory
@@ -641,7 +641,7 @@ Dubbo官方给的Demo没有配置URL,所以这里就是NULL
3. 看下面的截图,registry属性是zookeeper的URL,所以应该是要调用ZookeeperRegistry的subscribe()方法,但是ZookeeperRegistry没有这个方法,所以我们就要找它的父类了,也就是FailbackRegistry,
4. 然后再调用doSubscribe(),ZookeeperRegistry重写了此方法,很明显这是个模板模式。
- +
+ #### FailbackRegistry
@@ -843,7 +843,7 @@ Dubbo官方给的Demo没有配置URL,所以这里就是NULL
最终走到了这一步
-
#### FailbackRegistry
@@ -843,7 +843,7 @@ Dubbo官方给的Demo没有配置URL,所以这里就是NULL
最终走到了这一步
- +
+ #### RegistryDirectory
@@ -1097,7 +1097,7 @@ consumer://192.168.0.100/org.apache.dubbo.demo.DemoService?application=dubbo-dem
到此,路由链构造完毕。
-
#### RegistryDirectory
@@ -1097,7 +1097,7 @@ consumer://192.168.0.100/org.apache.dubbo.demo.DemoService?application=dubbo-dem
到此,路由链构造完毕。
-  +
+  diff --git a/docs/java_concurrency/Java并发体系-第一阶段-多线程基础知识.md b/docs/java_concurrency/Java并发体系-第一阶段-多线程基础知识.md
index 85500e0..0f06225 100644
--- a/docs/java_concurrency/Java并发体系-第一阶段-多线程基础知识.md
+++ b/docs/java_concurrency/Java并发体系-第一阶段-多线程基础知识.md
@@ -31,13 +31,13 @@ date: 2020-10-05 22:40:58
概念:进程可进一步细化为线程,是一个程序内部的一条执行路径。
说明:线程作为CPU调度和执行的单位,每个线程拥独立的运行栈和程序计数器(pc),线程切换的开销小。
-
diff --git a/docs/java_concurrency/Java并发体系-第一阶段-多线程基础知识.md b/docs/java_concurrency/Java并发体系-第一阶段-多线程基础知识.md
index 85500e0..0f06225 100644
--- a/docs/java_concurrency/Java并发体系-第一阶段-多线程基础知识.md
+++ b/docs/java_concurrency/Java并发体系-第一阶段-多线程基础知识.md
@@ -31,13 +31,13 @@ date: 2020-10-05 22:40:58
概念:进程可进一步细化为线程,是一个程序内部的一条执行路径。
说明:线程作为CPU调度和执行的单位,每个线程拥独立的运行栈和程序计数器(pc),线程切换的开销小。
- +
+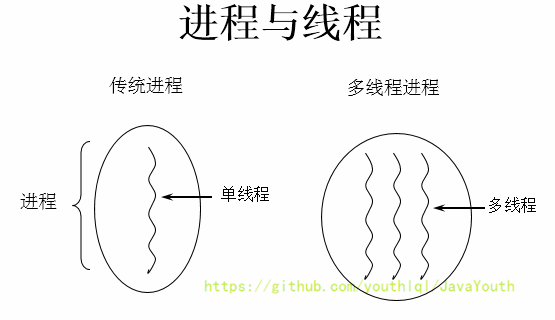 补充:
-
补充:
- +
+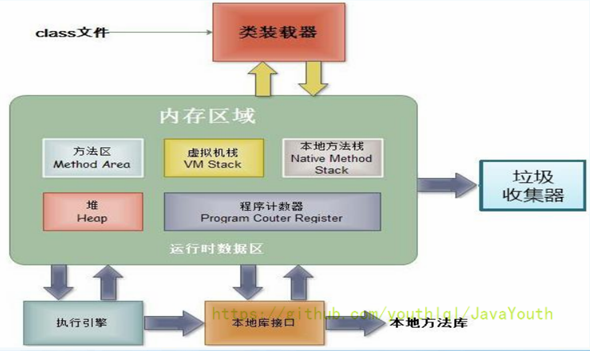 进程可以细化为多个线程。
每个线程,拥有自己独立的:栈、程序计数器
@@ -281,7 +281,7 @@ private void init(ThreadGroup g, Runnable target, String name,
1、多线程的设计之中,使用了代理设计模式的结构,用户自定义的线程主体只是负责项目核心功能的实现,而所有的辅助实现全部交由Thread类来处理。
2、在进行Thread启动多线程的时候调用的是start()方法,而后找到的是run()方法,但通过Thread类的构造方法传递了一个Runnable接口对象的时候,那么该接口对象将被Thread类中的target属性所保存,在start()方法执行的时候会调用Thread类中的run()方法。而这个run()方法去调用实现了Runnable接口的那个类所重写过run()方法,进而执行相应的逻辑。多线程开发的本质实质上是在于多个线程可以进行同一资源的抢占,那么Thread主要描述的是线程,而资源的描述是通过Runnable完成的。如下图所示:
-
进程可以细化为多个线程。
每个线程,拥有自己独立的:栈、程序计数器
@@ -281,7 +281,7 @@ private void init(ThreadGroup g, Runnable target, String name,
1、多线程的设计之中,使用了代理设计模式的结构,用户自定义的线程主体只是负责项目核心功能的实现,而所有的辅助实现全部交由Thread类来处理。
2、在进行Thread启动多线程的时候调用的是start()方法,而后找到的是run()方法,但通过Thread类的构造方法传递了一个Runnable接口对象的时候,那么该接口对象将被Thread类中的target属性所保存,在start()方法执行的时候会调用Thread类中的run()方法。而这个run()方法去调用实现了Runnable接口的那个类所重写过run()方法,进而执行相应的逻辑。多线程开发的本质实质上是在于多个线程可以进行同一资源的抢占,那么Thread主要描述的是线程,而资源的描述是通过Runnable完成的。如下图所示:
- +
+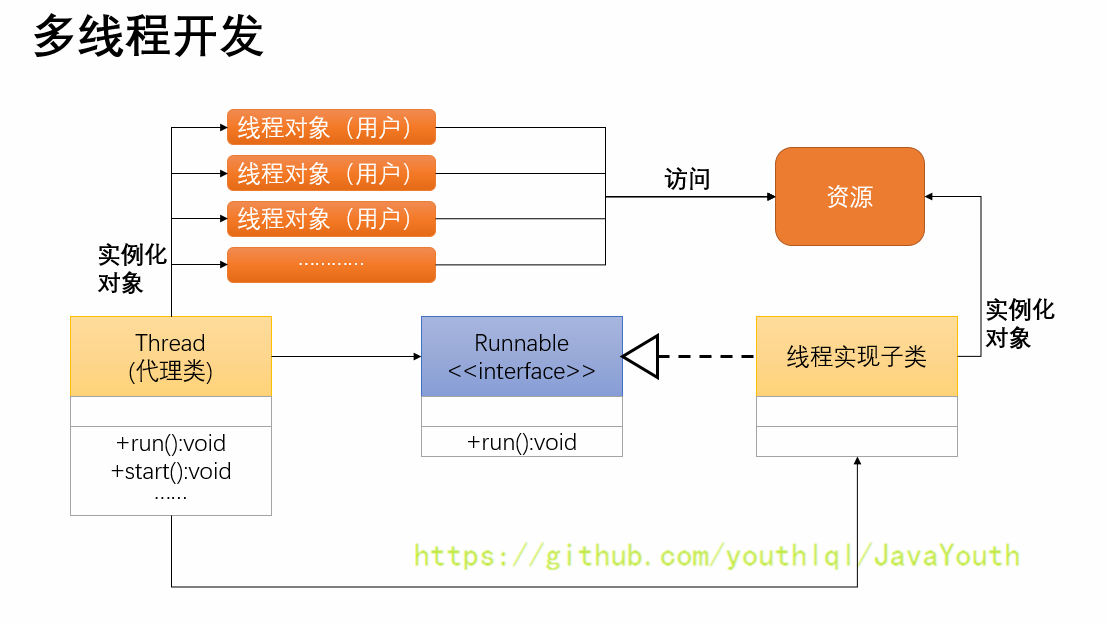 @@ -644,7 +644,7 @@ public void run() {
1、如果直接调用run()方法,相当于就是简单的调用一个普通方法。
-
@@ -644,7 +644,7 @@ public void run() {
1、如果直接调用run()方法,相当于就是简单的调用一个普通方法。
- +
+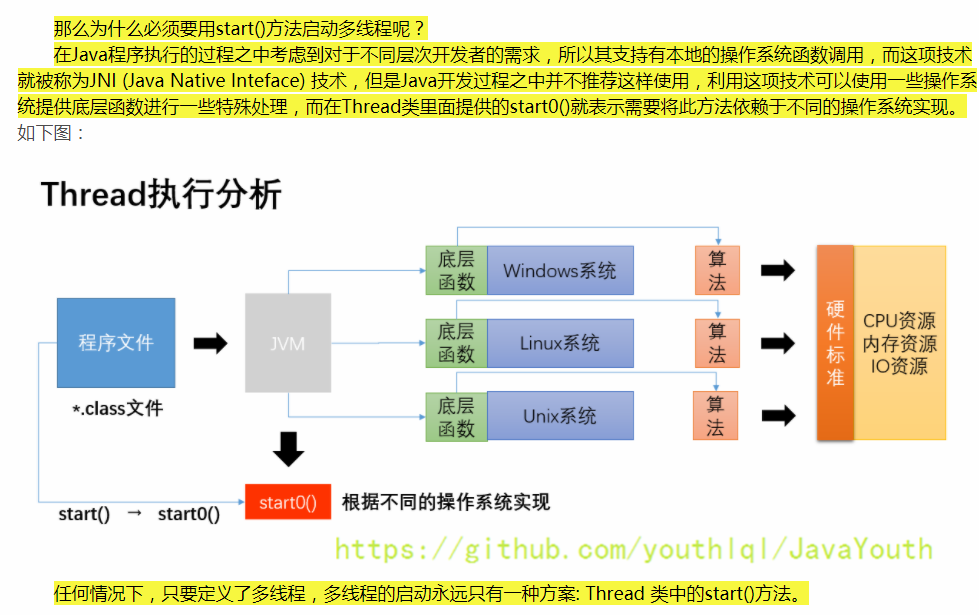 2、run()的调用是在start0()这个Native C++方法里调用的
@@ -654,11 +654,11 @@ public void run() {
Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种不同状态的其中一个状态,这几个状态在Java源码中用枚举来表示。
-
2、run()的调用是在start0()这个Native C++方法里调用的
@@ -654,11 +654,11 @@ public void run() {
Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种不同状态的其中一个状态,这几个状态在Java源码中用枚举来表示。
- +
+ 线程在生命周期中并不是固定处于某一个状态而是随着代码的执行在不同状态之间切换。Java 线程状态变迁如下图所示。
-
线程在生命周期中并不是固定处于某一个状态而是随着代码的执行在不同状态之间切换。Java 线程状态变迁如下图所示。
- +
+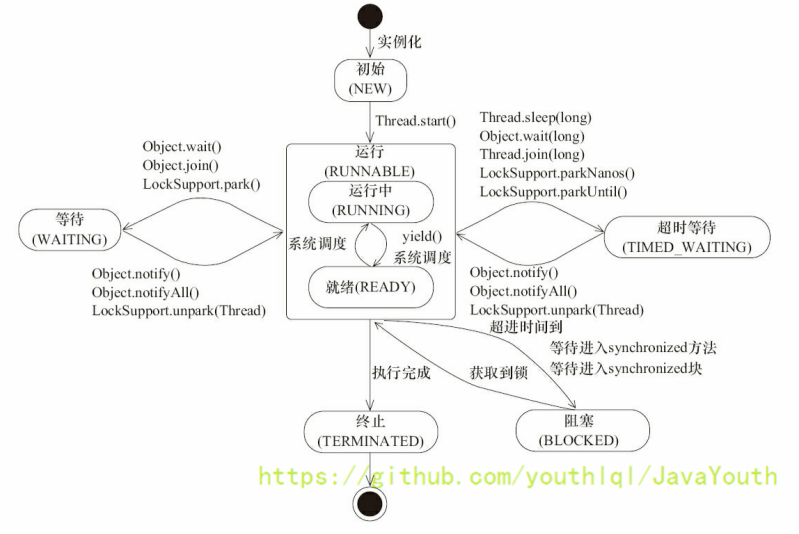 > 图中 wait到 runnable状态的转换中,`join`实际上是`Thread`类的方法,但这里写成了`Object`。
@@ -699,7 +699,7 @@ public static void main(String[] args) {
2、当JVM启动后,实际有多个线程,但是至少有一个非守护线程(比如main线程)。
-
> 图中 wait到 runnable状态的转换中,`join`实际上是`Thread`类的方法,但这里写成了`Object`。
@@ -699,7 +699,7 @@ public static void main(String[] args) {
2、当JVM启动后,实际有多个线程,但是至少有一个非守护线程(比如main线程)。
- +
+ - Finalizer:GC守护线程
@@ -1574,7 +1574,7 @@ volatile自己虽然不能保证原子性,但是和CAS结合起来就可以保
-
- Finalizer:GC守护线程
@@ -1574,7 +1574,7 @@ volatile自己虽然不能保证原子性,但是和CAS结合起来就可以保
- +
+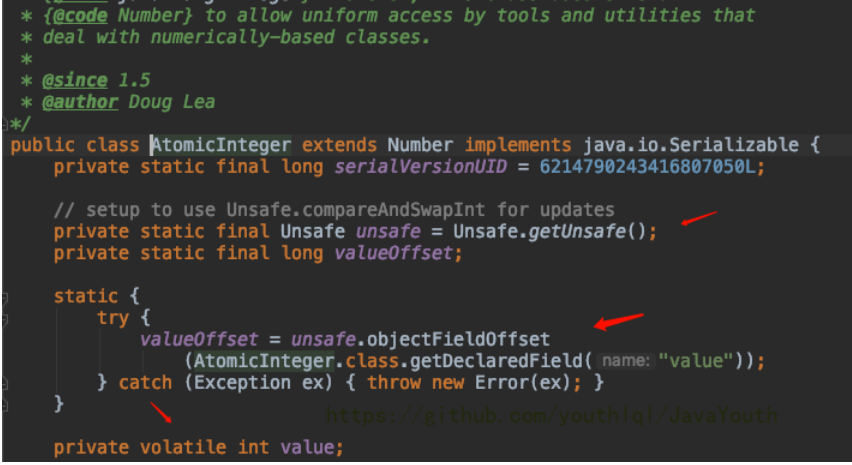 @@ -1782,7 +1782,7 @@ public Unsafe getUnsafe() throws IllegalAccessException {
Unsafe的功能如下图:
-
@@ -1782,7 +1782,7 @@ public Unsafe getUnsafe() throws IllegalAccessException {
Unsafe的功能如下图:
- +
+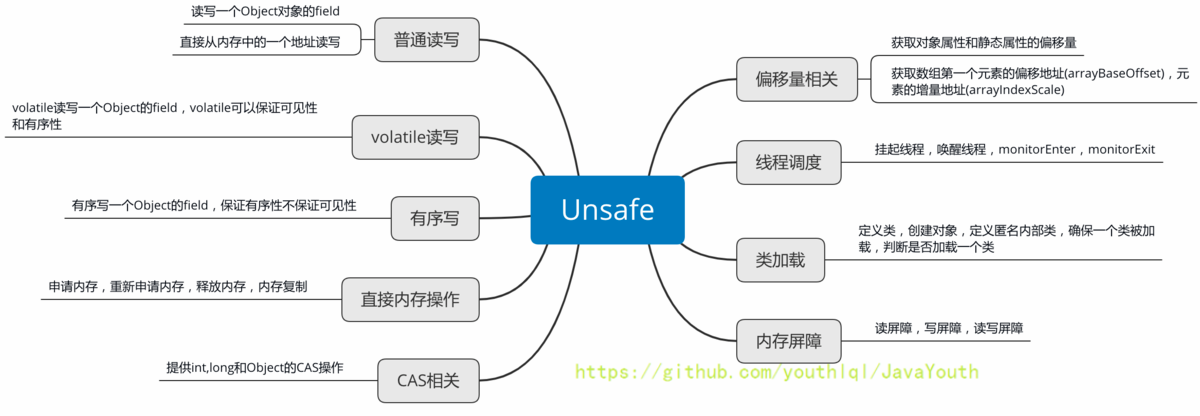 ## CAS相关
diff --git a/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[1].md b/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[1].md
index 24dc944..4d27b2c 100644
--- a/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[1].md
+++ b/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[1].md
@@ -1869,7 +1869,7 @@ public class ForkJoinRecursiveAction {
ForkJoinTask就是ForkJoinPool里面的每一个任务。他主要有两个子类:`RecursiveAction`和`RecursiveTask`。然后通过fork()方法去分配任务执行任务,通过join()方法汇总任务结果。
-
## CAS相关
diff --git a/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[1].md b/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[1].md
index 24dc944..4d27b2c 100644
--- a/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[1].md
+++ b/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[1].md
@@ -1869,7 +1869,7 @@ public class ForkJoinRecursiveAction {
ForkJoinTask就是ForkJoinPool里面的每一个任务。他主要有两个子类:`RecursiveAction`和`RecursiveTask`。然后通过fork()方法去分配任务执行任务,通过join()方法汇总任务结果。
- +
+ ## 小总结
diff --git a/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[2].md b/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[2].md
index 427321e..383e532 100644
--- a/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[2].md
+++ b/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[2].md
@@ -563,7 +563,7 @@ public int getUnarrivedParties()
根据上面的代码,我们可以画出下面这个很简单的图:
-
## 小总结
diff --git a/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[2].md b/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[2].md
index 427321e..383e532 100644
--- a/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[2].md
+++ b/docs/java_concurrency/Java并发体系-第三阶段-JUC并发包-[2].md
@@ -563,7 +563,7 @@ public int getUnarrivedParties()
根据上面的代码,我们可以画出下面这个很简单的图:
-  +
+ 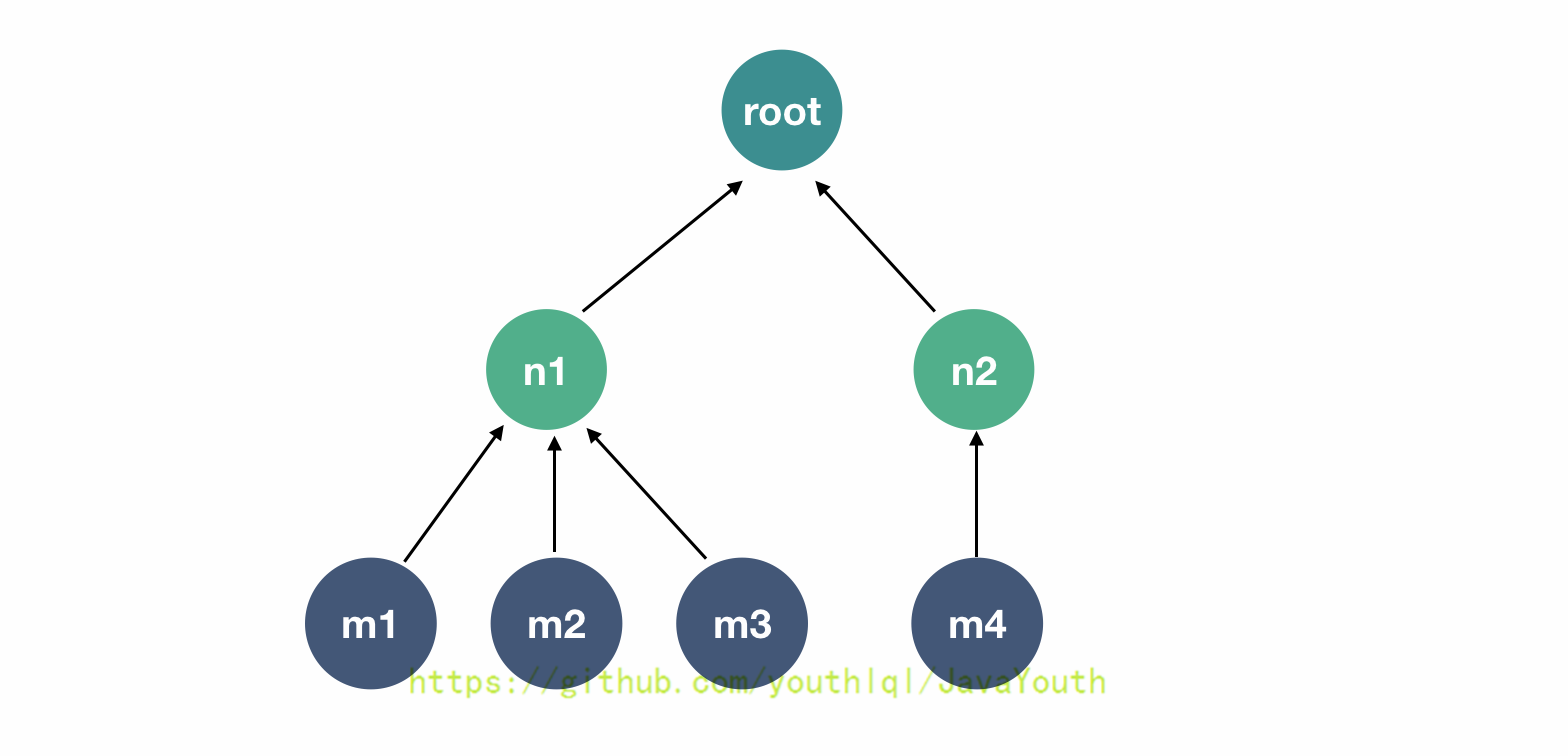 这棵树上有 7 个 phaser 实例,每个 phaser 实例在构造的时候,都指定了 parties 为 5,但是,对于每个拥有子节点的节点来说,每个子节点都是它的一个 party,我们可以通过 phaser.getRegisteredParties() 得到每个节点的 parties 数量:
@@ -952,7 +952,7 @@ public class ThreadPoolDemo {
## 线程池的底层工作流程
-
这棵树上有 7 个 phaser 实例,每个 phaser 实例在构造的时候,都指定了 parties 为 5,但是,对于每个拥有子节点的节点来说,每个子节点都是它的一个 party,我们可以通过 phaser.getRegisteredParties() 得到每个节点的 parties 数量:
@@ -952,7 +952,7 @@ public class ThreadPoolDemo {
## 线程池的底层工作流程
- +
+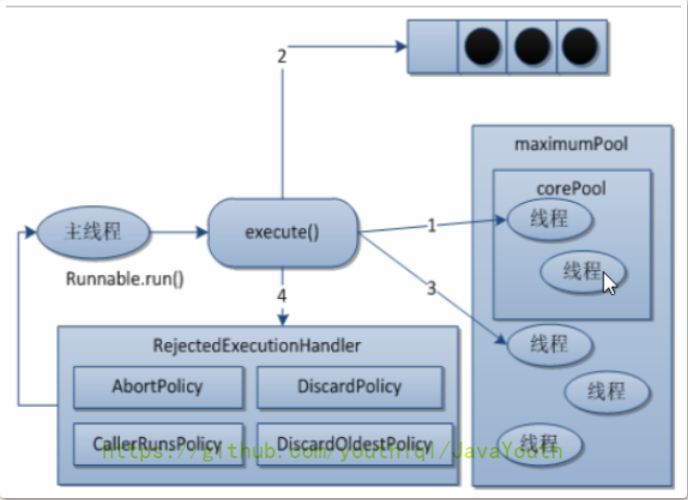 1、创建线程池后,等待请求任务
@@ -1646,7 +1646,7 @@ public class ExecutorCompletionService implements CompletionService {
**执行流程:**
-
1、创建线程池后,等待请求任务
@@ -1646,7 +1646,7 @@ public class ExecutorCompletionService implements CompletionService {
**执行流程:**
- +
+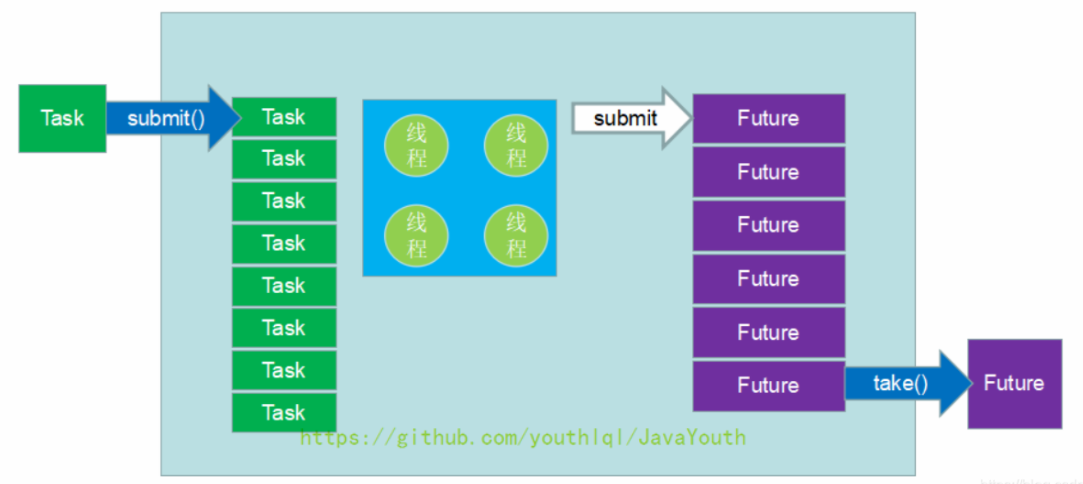 diff --git a/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[1].md b/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[1].md
index 662d4db..a76391a 100644
--- a/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[1].md
+++ b/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[1].md
@@ -291,7 +291,7 @@ d = e - f ;
由于处理器使用缓存和读写缓存冲区,这使得加载(load)和存储(store)操作看上去可能是在乱序执行,因为三级缓存的存在,导致内存与缓存的数据同步存在时间差。
-
diff --git a/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[1].md b/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[1].md
index 662d4db..a76391a 100644
--- a/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[1].md
+++ b/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[1].md
@@ -291,7 +291,7 @@ d = e - f ;
由于处理器使用缓存和读写缓存冲区,这使得加载(load)和存储(store)操作看上去可能是在乱序执行,因为三级缓存的存在,导致内存与缓存的数据同步存在时间差。
- +
+ @@ -343,7 +343,7 @@ int c = a + b;
冯诺依曼,提出计算机由五大组成部分,输入设备,输出设备存储器,控制器,运算器。
-
@@ -343,7 +343,7 @@ int c = a + b;
冯诺依曼,提出计算机由五大组成部分,输入设备,输出设备存储器,控制器,运算器。
- +
+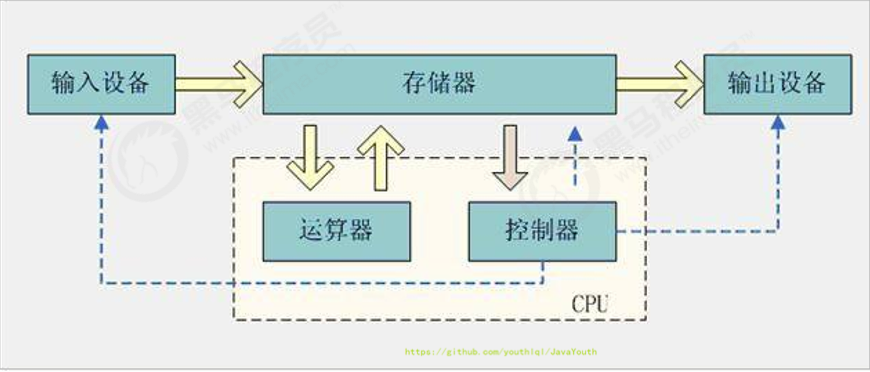 输入设备:鼠标,键盘等等
@@ -367,7 +367,7 @@ int c = a + b;
CPU的运算速度和内存的访问速度相差比较大。这就导致CPU每次操作内存都要耗费很多等待时间。内 存的读写速度成为了计算机运行的瓶颈。于是就有了在CPU和主内存之间增加缓存的设计。靠近CPU 的缓存称为L1,然后依次是 L2,L3和主内存,CPU缓存模型如图下图所示。
-
输入设备:鼠标,键盘等等
@@ -367,7 +367,7 @@ int c = a + b;
CPU的运算速度和内存的访问速度相差比较大。这就导致CPU每次操作内存都要耗费很多等待时间。内 存的读写速度成为了计算机运行的瓶颈。于是就有了在CPU和主内存之间增加缓存的设计。靠近CPU 的缓存称为L1,然后依次是 L2,L3和主内存,CPU缓存模型如图下图所示。
- +
+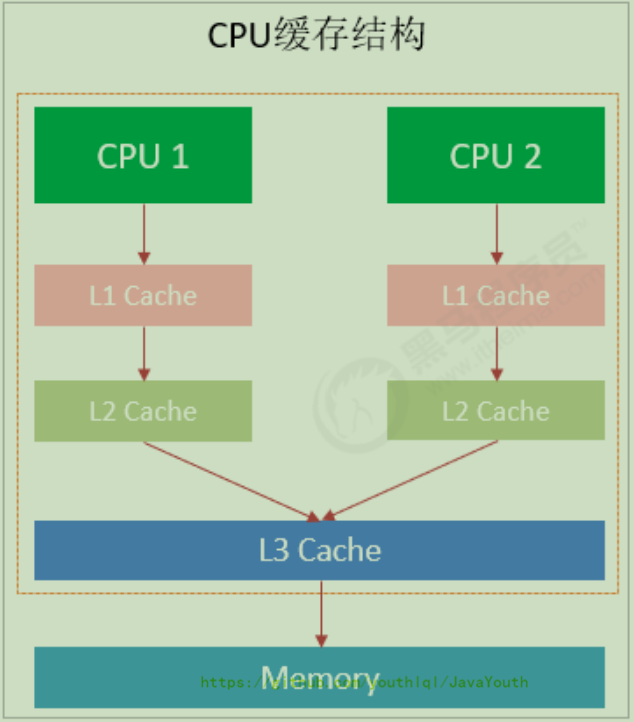 CPU Cache分成了三个级别: L1, L2, L3。级别越小越接近CPU,速度也更快,同时也代表着容量越小。速度越快的价格越贵。
@@ -377,7 +377,7 @@ CPU Cache分成了三个级别: L1, L2, L3。级别越小越接近CPU,速
3、L3 Cache是三级缓存中大的一级,例如12MB,同时也是缓存中慢的一级,在同一个CPU插槽 之间的核共享一个L3 Cache。
-
CPU Cache分成了三个级别: L1, L2, L3。级别越小越接近CPU,速度也更快,同时也代表着容量越小。速度越快的价格越贵。
@@ -377,7 +377,7 @@ CPU Cache分成了三个级别: L1, L2, L3。级别越小越接近CPU,速
3、L3 Cache是三级缓存中大的一级,例如12MB,同时也是缓存中慢的一级,在同一个CPU插槽 之间的核共享一个L3 Cache。
- +
+ 上面的图中有一个Latency指标。比如Memory这个指标为59.4ns,表示CPU在操作内存的时候有59.4ns的延迟,一级缓存最快只有1.2ns。
@@ -409,7 +409,7 @@ Cache的出现是为了解决CPU直接访问内存效率低下问题的。
每一个线程有自己的工作内存,工作内存只存储该线程对共享变量的副本。线程对变量的所有的操 作(读,取)都必须在工作内存中完成,而不能直接读写主内存中的变量,不同线程之间也不能直接 访问对方工作内存中的变量。
-
上面的图中有一个Latency指标。比如Memory这个指标为59.4ns,表示CPU在操作内存的时候有59.4ns的延迟,一级缓存最快只有1.2ns。
@@ -409,7 +409,7 @@ Cache的出现是为了解决CPU直接访问内存效率低下问题的。
每一个线程有自己的工作内存,工作内存只存储该线程对共享变量的副本。线程对变量的所有的操 作(读,取)都必须在工作内存中完成,而不能直接读写主内存中的变量,不同线程之间也不能直接 访问对方工作内存中的变量。
- +
+ Java的线程不能直接在主内存中操作共享变量。而是首先将主内存中的共享变量赋值到自己的工作内存中,再进行操作,操作完成之后,刷回主内存。
@@ -424,7 +424,7 @@ Java内存模型是一套在多线程读写共享数据时,对共享数据的
JMM内存模型与CPU硬件内存架构的关系:
-
Java的线程不能直接在主内存中操作共享变量。而是首先将主内存中的共享变量赋值到自己的工作内存中,再进行操作,操作完成之后,刷回主内存。
@@ -424,7 +424,7 @@ Java内存模型是一套在多线程读写共享数据时,对共享数据的
JMM内存模型与CPU硬件内存架构的关系:
- +
+ 工作内存:可能对应CPU寄存器,也可能对应CPU缓存,也可能对应内存。
@@ -434,9 +434,9 @@ JMM内存模型与CPU硬件内存架构的关系:
## 再谈可见性
-
工作内存:可能对应CPU寄存器,也可能对应CPU缓存,也可能对应内存。
@@ -434,9 +434,9 @@ JMM内存模型与CPU硬件内存架构的关系:
## 再谈可见性
- +
+ -
- +
+ 1、图中所示是 个双核 CPU 系统架构 ,每个核有自己的控制器和运算器,其中控制器包含一组寄存器和操作控制器,运算器执行算术逻辅运算。每个核都有自己的1级缓存,在有些架构里面还有1个所有 CPU 共享的2级缓存。 那么 Java 内存模型里面的工作内存,就对应这里的 Ll 或者 L2 存或者 CPU 寄存器。
@@ -452,7 +452,7 @@ JMM内存模型与CPU硬件内存架构的关系:
为了保证数据交互时数据的正确性,Java内存模型中定义了8种操作来完成这个交互过程,这8种操作本身都是原子性的。虚拟机实现时必须保证下面 提及的每一种操作都是原子的、不可再分的。
-
1、图中所示是 个双核 CPU 系统架构 ,每个核有自己的控制器和运算器,其中控制器包含一组寄存器和操作控制器,运算器执行算术逻辅运算。每个核都有自己的1级缓存,在有些架构里面还有1个所有 CPU 共享的2级缓存。 那么 Java 内存模型里面的工作内存,就对应这里的 Ll 或者 L2 存或者 CPU 寄存器。
@@ -452,7 +452,7 @@ JMM内存模型与CPU硬件内存架构的关系:
为了保证数据交互时数据的正确性,Java内存模型中定义了8种操作来完成这个交互过程,这8种操作本身都是原子性的。虚拟机实现时必须保证下面 提及的每一种操作都是原子的、不可再分的。
- +
+ > (1)lock:作用于主内存的变量,它把一个变量标识为一条线程独占的状态。
>
@@ -478,7 +478,7 @@ JMM内存模型与CPU硬件内存架构的关系:
如果没有synchronized,那就是下面这样的
-
> (1)lock:作用于主内存的变量,它把一个变量标识为一条线程独占的状态。
>
@@ -478,7 +478,7 @@ JMM内存模型与CPU硬件内存架构的关系:
如果没有synchronized,那就是下面这样的
- +
+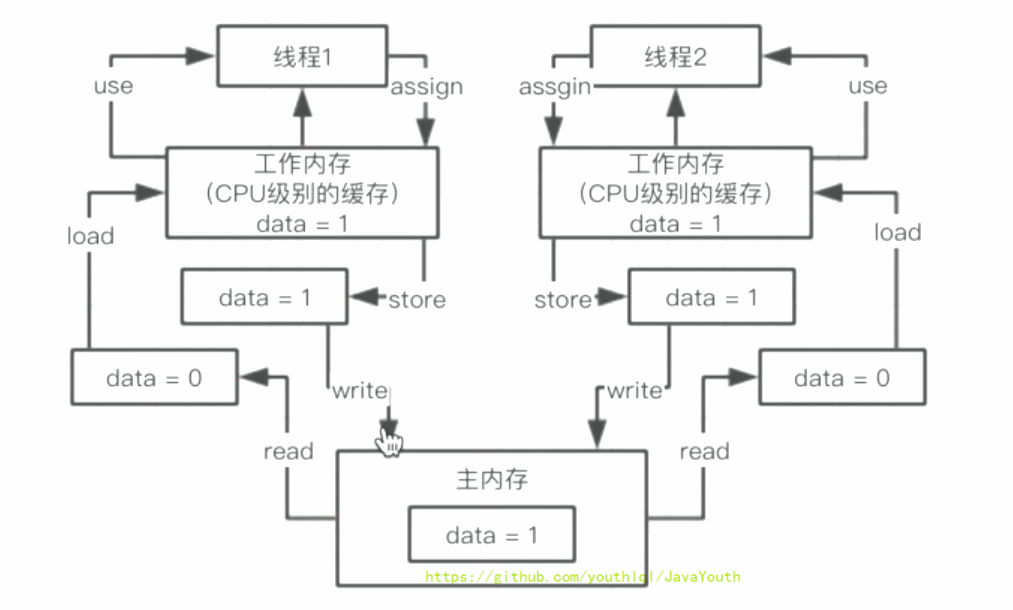 @@ -589,7 +589,7 @@ volatile不保证原子性,只保证可见性和禁止指令重排
## CPU术语介绍
-
@@ -589,7 +589,7 @@ volatile不保证原子性,只保证可见性和禁止指令重排
## CPU术语介绍
- +
+ @@ -717,7 +717,7 @@ public class VolatileExample {
**1、下面是保守策略下,volatile写插入内存屏障后生成的指令序列示意图**
-
@@ -717,7 +717,7 @@ public class VolatileExample {
**1、下面是保守策略下,volatile写插入内存屏障后生成的指令序列示意图**
- +
+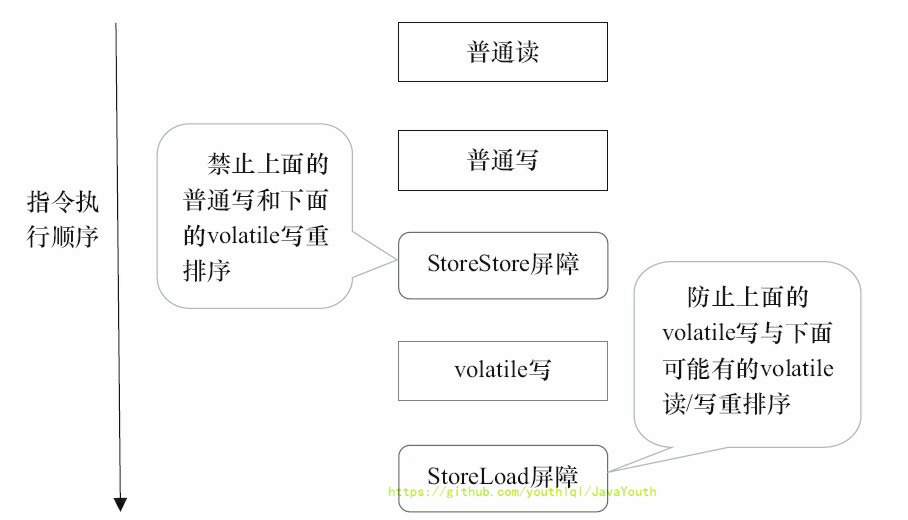 > 图中的StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任 意处理器可见了。这是因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存。这里比较有意思的是,volatile写后面的StoreLoad屏障。此屏障的作用是避免volatile写与 后面可能有的volatile读/写操作重排序。因为编译器常常无法准确判断在一个volatile写的后面 是否需要插入一个StoreLoad屏障(比如,一个volatile写之后方法立即return)。为了保证能正确 实现volatile的内存语义,JMM在采取了保守策略:在每个volatile写的后面,或者在每个volatile 读的前面插入一个StoreLoad屏障。从整体执行效率的角度考虑,JMM最终选择了在每个volatile写的后面插入一个StoreLoad屏障。因为volatile写-读内存语义的常见使用模式是:一个 写线程写volatile变量,多个读线程读同一个volatile变量。当读线程的数量大大超过写线程时, 选择在volatile写之后插入StoreLoad屏障将带来可观的执行效率的提升。从这里可以看到JMM在实现上的一个特点:首先确保正确性,然后再去追求执行效率
@@ -725,7 +725,7 @@ public class VolatileExample {
**2、下面是在保守策略下,volatile读插入内存屏障后生成的指令序列示意图**
-
> 图中的StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任 意处理器可见了。这是因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存。这里比较有意思的是,volatile写后面的StoreLoad屏障。此屏障的作用是避免volatile写与 后面可能有的volatile读/写操作重排序。因为编译器常常无法准确判断在一个volatile写的后面 是否需要插入一个StoreLoad屏障(比如,一个volatile写之后方法立即return)。为了保证能正确 实现volatile的内存语义,JMM在采取了保守策略:在每个volatile写的后面,或者在每个volatile 读的前面插入一个StoreLoad屏障。从整体执行效率的角度考虑,JMM最终选择了在每个volatile写的后面插入一个StoreLoad屏障。因为volatile写-读内存语义的常见使用模式是:一个 写线程写volatile变量,多个读线程读同一个volatile变量。当读线程的数量大大超过写线程时, 选择在volatile写之后插入StoreLoad屏障将带来可观的执行效率的提升。从这里可以看到JMM在实现上的一个特点:首先确保正确性,然后再去追求执行效率
@@ -725,7 +725,7 @@ public class VolatileExample {
**2、下面是在保守策略下,volatile读插入内存屏障后生成的指令序列示意图**
- +
+ > 图中的LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。 LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。 上述volatile写和volatile读的内存屏障插入策略非常保守。在实际执行时,只要不改变volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障。
@@ -752,7 +752,7 @@ class VolatileBarrierExample {
针对readAndWrite()方法,编译器在生成字节码时可以做如下的优化
-
> 图中的LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。 LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。 上述volatile写和volatile读的内存屏障插入策略非常保守。在实际执行时,只要不改变volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障。
@@ -752,7 +752,7 @@ class VolatileBarrierExample {
针对readAndWrite()方法,编译器在生成字节码时可以做如下的优化
- +
+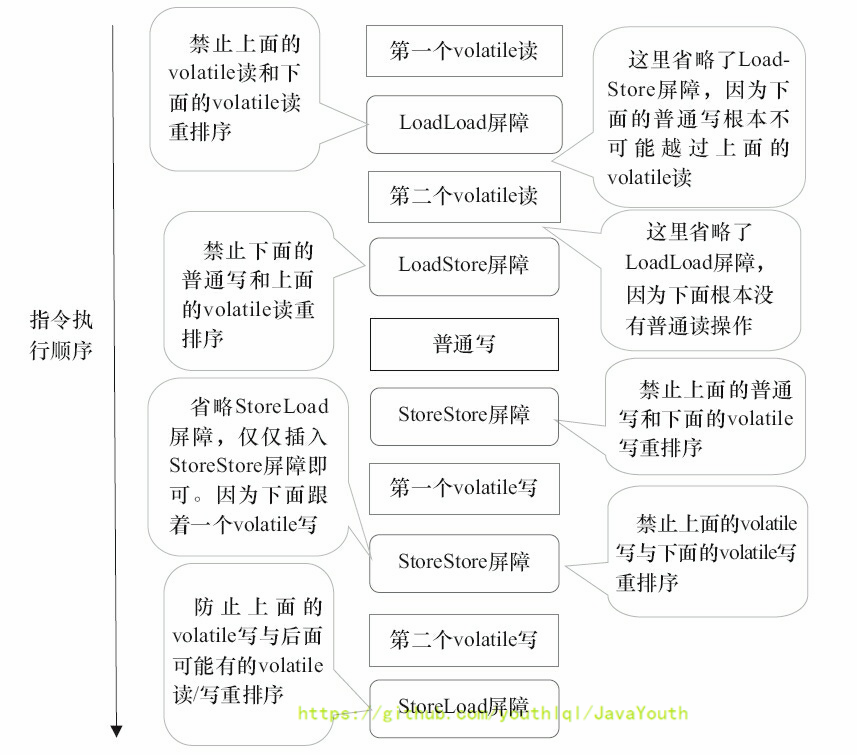 注意,最后的StoreLoad屏障不能省略。因为第二个volatile写之后,方法立即return。此时编译器可能无法准确断定后面是否会有volatile读或写,为了安全起见,编译器通常会在这里插入一个StoreLoad屏障。
@@ -766,7 +766,7 @@ class VolatileBarrierExample {
X86处理器仅会对写-读操作做重排序。X86不会对读-读、读-写和写-写操作 做重排序,因此在X86处理器中会省略掉这3种操作类型对应的内存屏障。在X86中,JMM仅需在volatile写后面插入一个StoreLoad屏障即可正确实现volatile写-读的内存语义。这意味着在X86处理器中,volatile写的开销比volatile读的开销会大很多(因为执行StoreLoad屏障开销会比较大)。
-
注意,最后的StoreLoad屏障不能省略。因为第二个volatile写之后,方法立即return。此时编译器可能无法准确断定后面是否会有volatile读或写,为了安全起见,编译器通常会在这里插入一个StoreLoad屏障。
@@ -766,7 +766,7 @@ class VolatileBarrierExample {
X86处理器仅会对写-读操作做重排序。X86不会对读-读、读-写和写-写操作 做重排序,因此在X86处理器中会省略掉这3种操作类型对应的内存屏障。在X86中,JMM仅需在volatile写后面插入一个StoreLoad屏障即可正确实现volatile写-读的内存语义。这意味着在X86处理器中,volatile写的开销比volatile读的开销会大很多(因为执行StoreLoad屏障开销会比较大)。
- +
+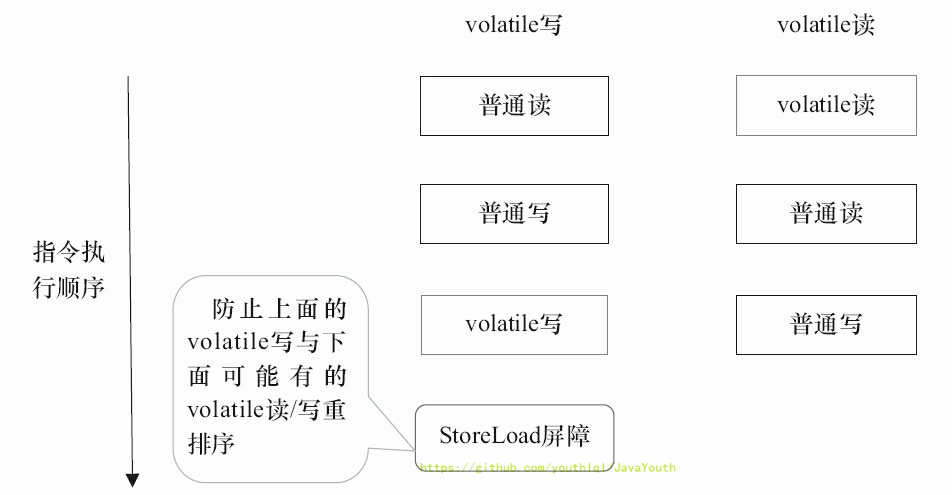 diff --git a/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[2].md b/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[2].md
index 02edbcb..ee4fe81 100644
--- a/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[2].md
+++ b/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[2].md
@@ -18,7 +18,7 @@ date: 2020-10-07 22:10:58
# 可见性设计的硬件
-
diff --git a/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[2].md b/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[2].md
index 02edbcb..ee4fe81 100644
--- a/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[2].md
+++ b/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[2].md
@@ -18,7 +18,7 @@ date: 2020-10-07 22:10:58
# 可见性设计的硬件
- +
+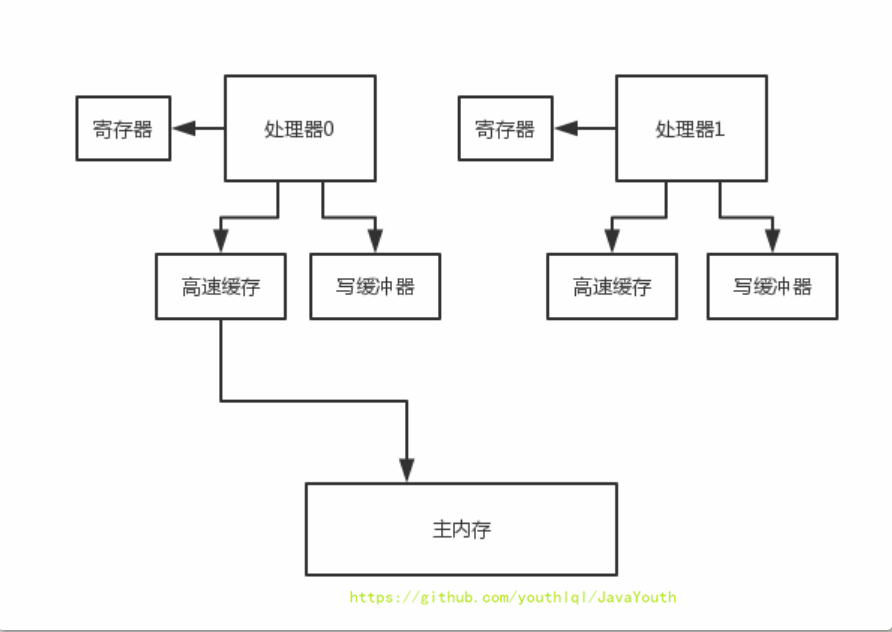 从硬件的级别来考虑一下可见性的问题
@@ -305,13 +305,13 @@ MESI协议规定了一组消息,就说各个处理器在操作内存数据的
-
从硬件的级别来考虑一下可见性的问题
@@ -305,13 +305,13 @@ MESI协议规定了一组消息,就说各个处理器在操作内存数据的
- +
+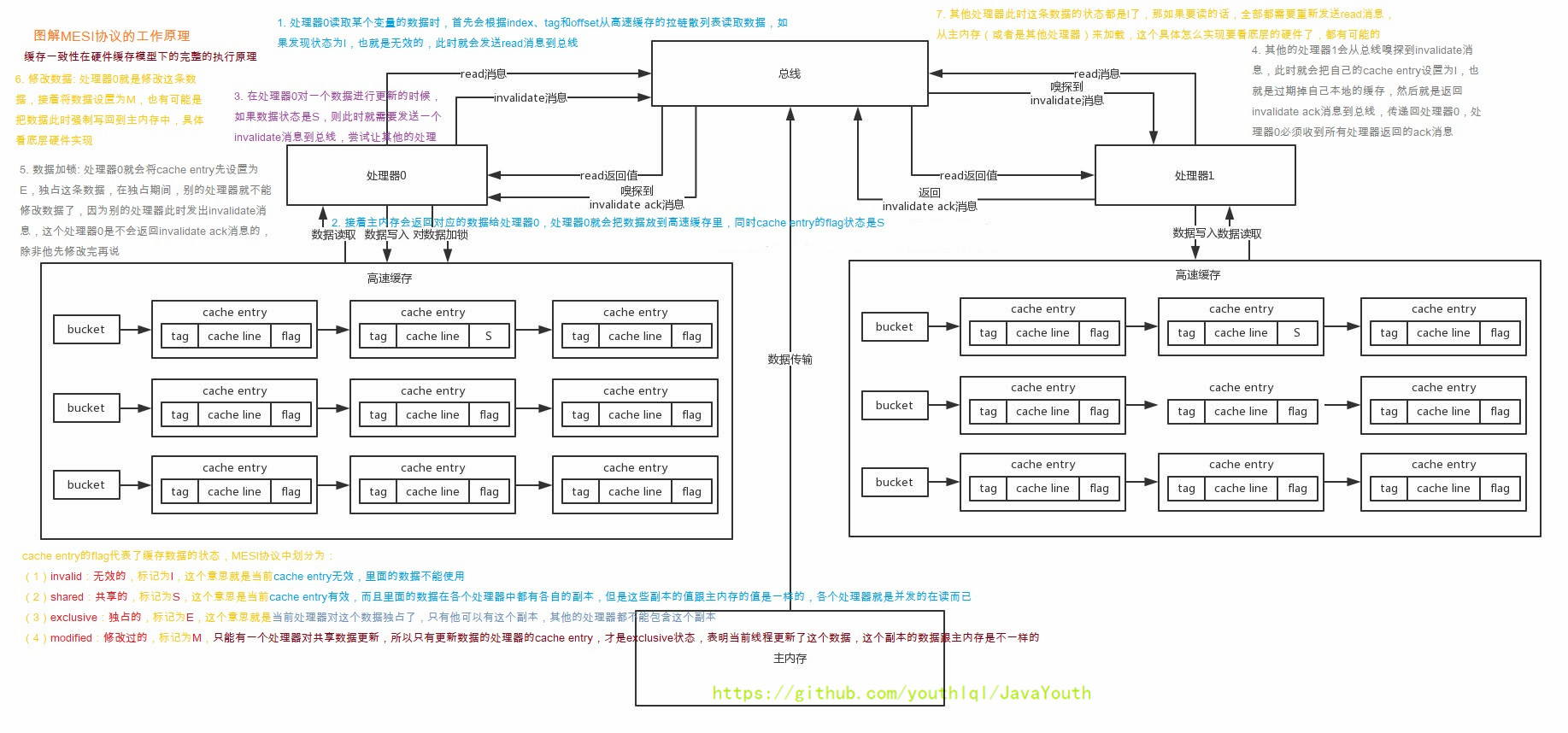 ## MESI-优化
-
## MESI-优化
- +
+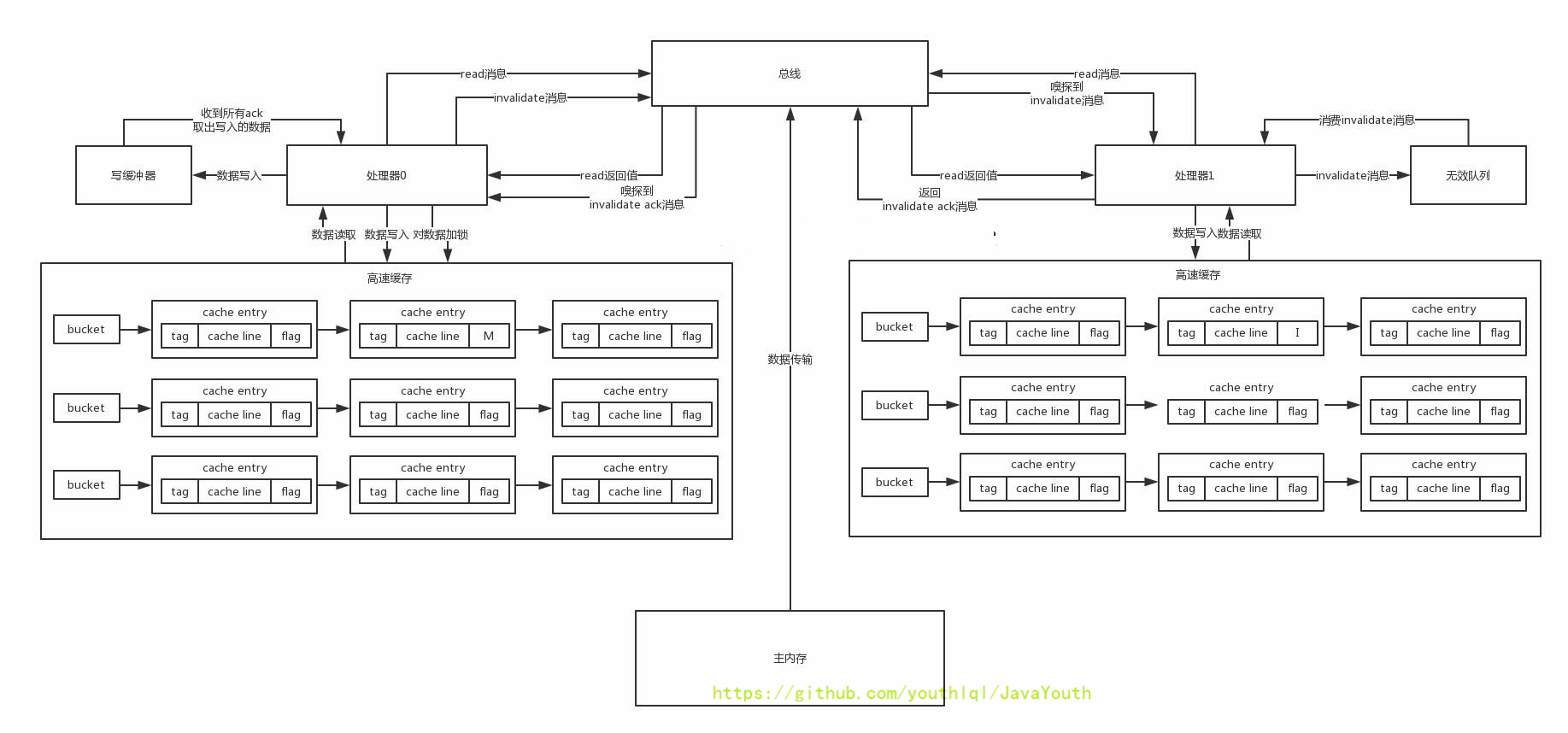 MESI协议如果每次写数据的时候都要发送invalidate消息等待所有处理器返回ack,然后获取独占锁后才能写数据,那可能就会导致性能很差了,因为这个对共享变量的写操作,实际上在硬件级别变成串行的了。所以为了解决这个问题,硬件层面引入了写缓冲器和无效队列
@@ -449,7 +449,7 @@ int b = c; //load
## 相关术语
-
MESI协议如果每次写数据的时候都要发送invalidate消息等待所有处理器返回ack,然后获取独占锁后才能写数据,那可能就会导致性能很差了,因为这个对共享变量的写操作,实际上在硬件级别变成串行的了。所以为了解决这个问题,硬件层面引入了写缓冲器和无效队列
@@ -449,7 +449,7 @@ int b = c; //load
## 相关术语
- +
+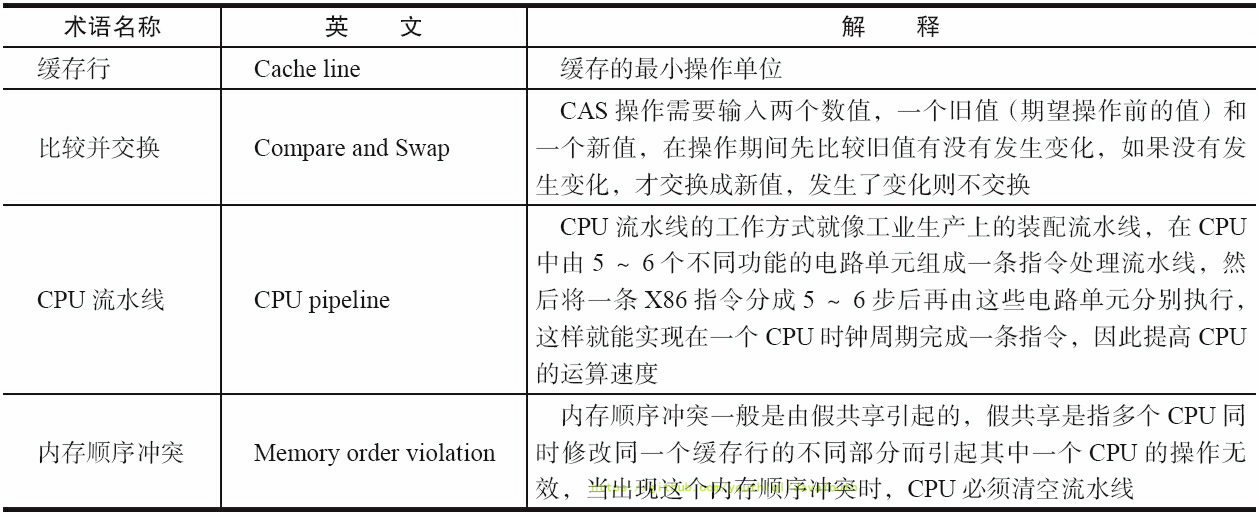 @@ -461,7 +461,7 @@ int b = c; //load
**第一个机制是通过总线锁保证原子性。**如果多个处理器同时对共享变量进行读改写操作 (i++就是经典的读改写操作),那么共享变量就会被多个处理器同时进行操作,这样读改写操 作就不是原子的,操作完之后共享变量的值会和期望的不一致。举个例子,如果i=1,我们进行 两次i++操作,我们期望的结果是3,但是有可能结果是2,如图所示。
-
@@ -461,7 +461,7 @@ int b = c; //load
**第一个机制是通过总线锁保证原子性。**如果多个处理器同时对共享变量进行读改写操作 (i++就是经典的读改写操作),那么共享变量就会被多个处理器同时进行操作,这样读改写操 作就不是原子的,操作完之后共享变量的值会和期望的不一致。举个例子,如果i=1,我们进行 两次i++操作,我们期望的结果是3,但是有可能结果是2,如图所示。
- +
+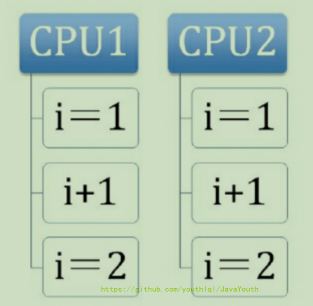 原因可能是多个处理器同时从各自的缓存中读取变量i,分别进行加1操作,然后分别写入 系统内存中。那么,想要保证读改写共享变量的操作是原子的,就必须保证CPU1读改写共享 变量的时候,CPU2不能操作缓存了该共享变量内存地址的缓存。
diff --git a/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[3].md b/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[3].md
index 81ee9d1..cd9c675 100644
--- a/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[3].md
+++ b/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[3].md
@@ -357,17 +357,17 @@ monitorexit释放锁。 monitorexit插入在方法结束处和异常处,JVM保
术语参考: http://openjdk.java.net/groups/hotspot/docs/HotSpotGlossary.html 在JVM中,对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充。如下图所示:
-
原因可能是多个处理器同时从各自的缓存中读取变量i,分别进行加1操作,然后分别写入 系统内存中。那么,想要保证读改写共享变量的操作是原子的,就必须保证CPU1读改写共享 变量的时候,CPU2不能操作缓存了该共享变量内存地址的缓存。
diff --git a/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[3].md b/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[3].md
index 81ee9d1..cd9c675 100644
--- a/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[3].md
+++ b/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[3].md
@@ -357,17 +357,17 @@ monitorexit释放锁。 monitorexit插入在方法结束处和异常处,JVM保
术语参考: http://openjdk.java.net/groups/hotspot/docs/HotSpotGlossary.html 在JVM中,对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充。如下图所示:
- +
+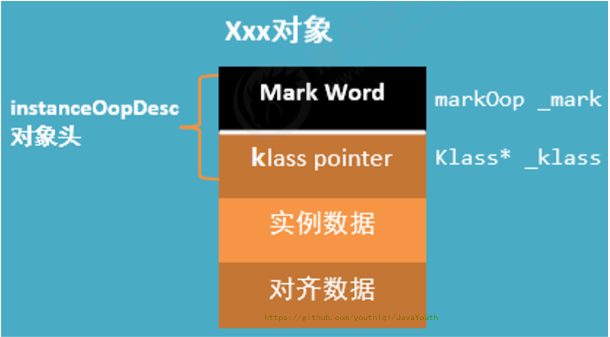 ## 对象头
当一个线程尝试访问synchronized修饰的代码块时,它首先要获得锁,那么这个锁到底存在哪里呢?是 存在锁对象的对象头中的。 HotSpot采用instanceOopDesc和arrayOopDesc来描述对象头,arrayOopDesc对象用来描述数组类型。instanceOopDesc的定义的在Hotspot源码的 instanceOop.hpp 文件中,另外,arrayOopDesc 的定义对应 arrayOop.hpp
-
## 对象头
当一个线程尝试访问synchronized修饰的代码块时,它首先要获得锁,那么这个锁到底存在哪里呢?是 存在锁对象的对象头中的。 HotSpot采用instanceOopDesc和arrayOopDesc来描述对象头,arrayOopDesc对象用来描述数组类型。instanceOopDesc的定义的在Hotspot源码的 instanceOop.hpp 文件中,另外,arrayOopDesc 的定义对应 arrayOop.hpp
- +
+ 从instanceOopDesc代码中可以看到 instanceOopDesc继承自oopDesc,oopDesc的定义载Hotspot 源码中的 oop.hpp 文件中。
-
从instanceOopDesc代码中可以看到 instanceOopDesc继承自oopDesc,oopDesc的定义载Hotspot 源码中的 oop.hpp 文件中。
- +
+ - 在普通实例对象中,oopDesc的定义包含两个成员,分别是 _mark 和 _metadata
@@ -383,21 +383,21 @@ monitorexit释放锁。 monitorexit插入在方法结束处和异常处,JVM保
Mark Word用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、 线程持有的锁、偏向线程ID、偏向时间戳等等,占用内存大小与虚拟机位长一致。Mark Word对应的类 型是 markOop 。源码位于 markOop.hpp 中。
-
- 在普通实例对象中,oopDesc的定义包含两个成员,分别是 _mark 和 _metadata
@@ -383,21 +383,21 @@ monitorexit释放锁。 monitorexit插入在方法结束处和异常处,JVM保
Mark Word用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、 线程持有的锁、偏向线程ID、偏向时间戳等等,占用内存大小与虚拟机位长一致。Mark Word对应的类 型是 markOop 。源码位于 markOop.hpp 中。
- +
+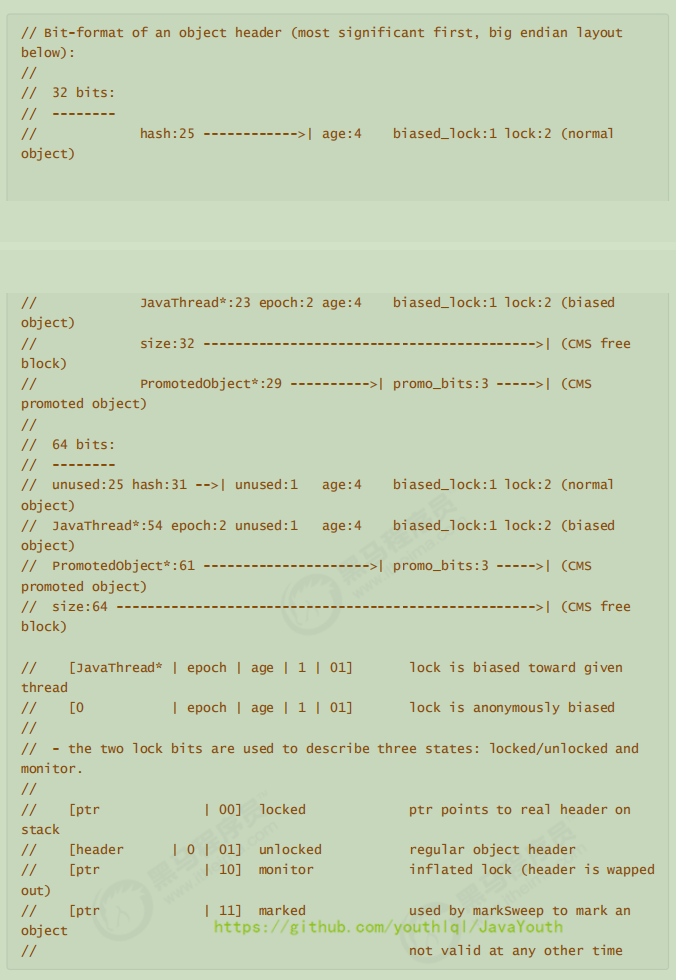 -
- +
+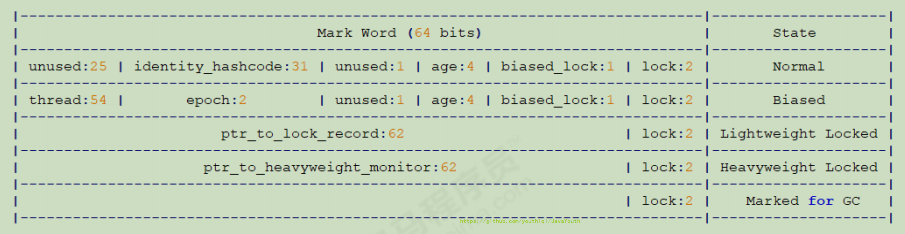 在64位虚拟机下,Mark Word是64bit大小的,其存储结构如下:
-
在64位虚拟机下,Mark Word是64bit大小的,其存储结构如下:
- +
+ 在32位虚拟机下,Mark Word是32bit大小的,其存储结构如下:
-
在32位虚拟机下,Mark Word是32bit大小的,其存储结构如下:
- +
+ 再加一个图对比一下,有一丁点的补充
-
再加一个图对比一下,有一丁点的补充
- +
+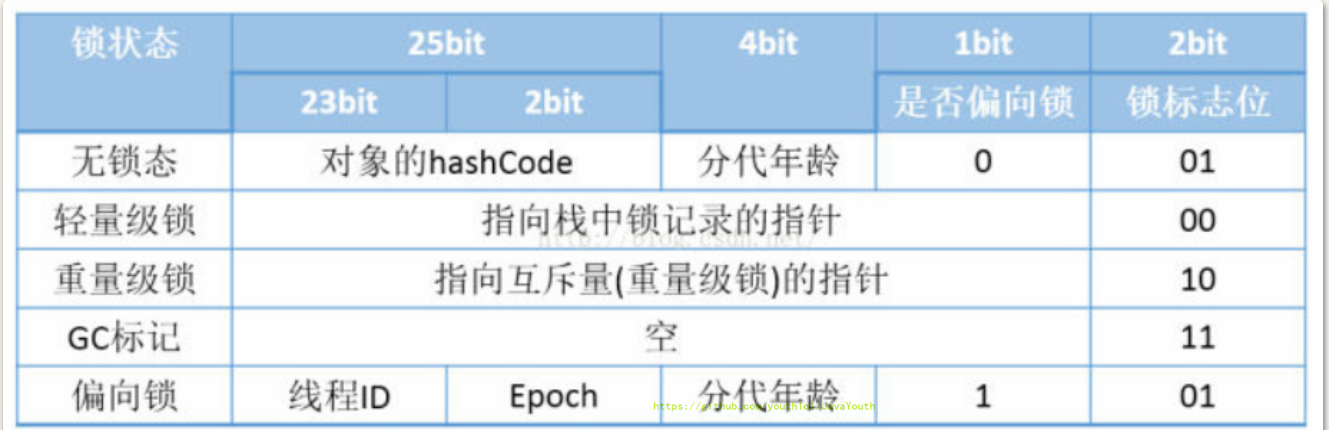 @@ -447,7 +447,7 @@ Mark Word用于存储对象自身的运行时数据,如哈希码(HashCode)
线程在执行同步块之前,JVM会先在当前的线程的栈帧中创建一个`Lock Record`,其包括一个用于存储对象头中的 `mark word`(官方称之为`Displaced Mark Word`)以及一个指向对象的指针。下图右边的部分就是一个`Lock Record`。
-
@@ -447,7 +447,7 @@ Mark Word用于存储对象自身的运行时数据,如哈希码(HashCode)
线程在执行同步块之前,JVM会先在当前的线程的栈帧中创建一个`Lock Record`,其包括一个用于存储对象头中的 `mark word`(官方称之为`Displaced Mark Word`)以及一个指向对象的指针。下图右边的部分就是一个`Lock Record`。
- +
+ @@ -571,7 +571,7 @@ synchronized(obj){
}
```
-
@@ -571,7 +571,7 @@ synchronized(obj){
}
```
- +
+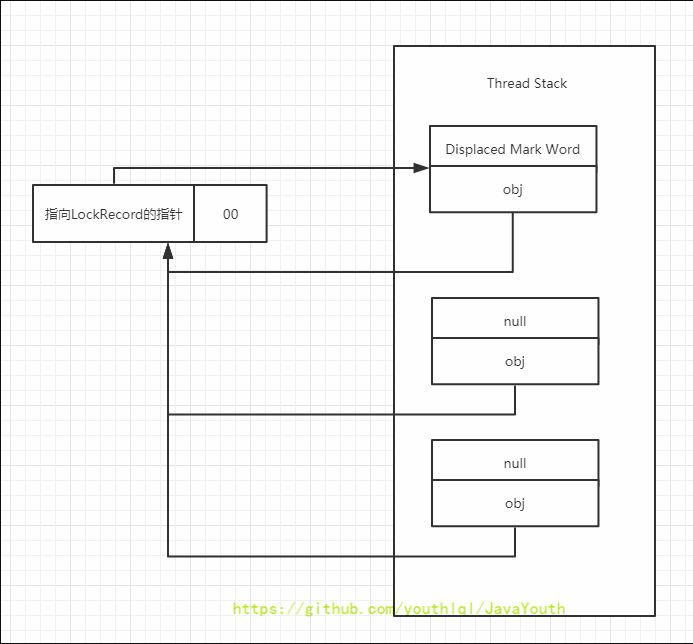 ## 轻量级锁什么时候升级为重量级锁?
@@ -608,7 +608,7 @@ synchronized(obj){
- 重量级锁的状态下,对象的`mark word`为指向一个堆中monitor对象的指针。一个monitor对象包括这么几个关键字段:cxq(下图中的ContentionList),EntryList ,WaitSet,owner。其中cxq ,EntryList ,WaitSet都是由ObjectWaiter的链表结构,owner指向持有锁的线程。
-
## 轻量级锁什么时候升级为重量级锁?
@@ -608,7 +608,7 @@ synchronized(obj){
- 重量级锁的状态下,对象的`mark word`为指向一个堆中monitor对象的指针。一个monitor对象包括这么几个关键字段:cxq(下图中的ContentionList),EntryList ,WaitSet,owner。其中cxq ,EntryList ,WaitSet都是由ObjectWaiter的链表结构,owner指向持有锁的线程。
- +
+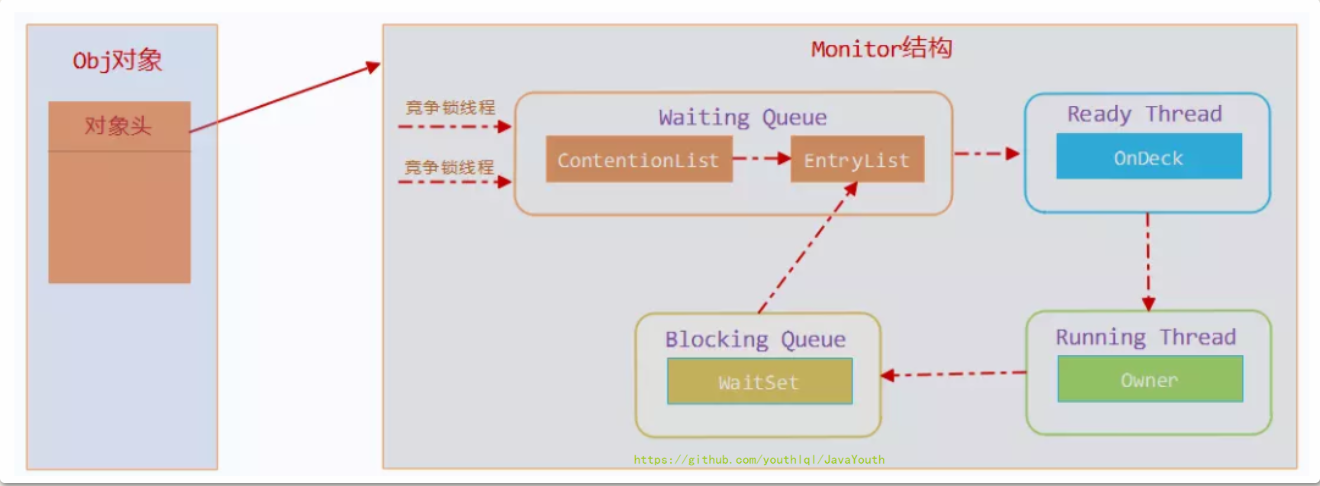 在HotSpot虚拟机中,monitor是由ObjectMonitor实现的。其源码是用c++来实现的,位于HotSpot虚 拟机源码ObjectMonitor.hpp文件中(src/share/vm/runtime/objectMonitor.hpp)。ObjectMonitor主 要数据结构如下:
@@ -661,7 +661,7 @@ ObjectMonitor() {
1、执行monitorenter时,会调用InterpreterRuntime.cpp (位于:src/share/vm/interpreter/interpreterRuntime.cpp) 的 InterpreterRuntime::monitorenter函 数。具体代码可参见HotSpot源码。
-
在HotSpot虚拟机中,monitor是由ObjectMonitor实现的。其源码是用c++来实现的,位于HotSpot虚 拟机源码ObjectMonitor.hpp文件中(src/share/vm/runtime/objectMonitor.hpp)。ObjectMonitor主 要数据结构如下:
@@ -661,7 +661,7 @@ ObjectMonitor() {
1、执行monitorenter时,会调用InterpreterRuntime.cpp (位于:src/share/vm/interpreter/interpreterRuntime.cpp) 的 InterpreterRuntime::monitorenter函 数。具体代码可参见HotSpot源码。
- +
+ @@ -1147,7 +1147,7 @@ if (TryLock(Self) > 0) break ;
可以看到ObjectMonitor的函数调用中会涉及到Atomic::cmpxchg_ptr,Atomic::inc_ptr等内核函数, 执行同步代码块,没有竞争到锁的对象会park()被挂起,竞争到锁的线程会unpark()唤醒。这个时候就 会存在操作系统用户态和内核态的转换,这种切换会消耗大量的系统资源。所以synchronized是Java语 言中是一个重量级(Heavyweight)的操作。 用户态和和内核态是什么东西呢?要想了解用户态和内核态还需要先了解一下Linux系统的体系架构:
-
@@ -1147,7 +1147,7 @@ if (TryLock(Self) > 0) break ;
可以看到ObjectMonitor的函数调用中会涉及到Atomic::cmpxchg_ptr,Atomic::inc_ptr等内核函数, 执行同步代码块,没有竞争到锁的对象会park()被挂起,竞争到锁的线程会unpark()唤醒。这个时候就 会存在操作系统用户态和内核态的转换,这种切换会消耗大量的系统资源。所以synchronized是Java语 言中是一个重量级(Heavyweight)的操作。 用户态和和内核态是什么东西呢?要想了解用户态和内核态还需要先了解一下Linux系统的体系架构:
- +
+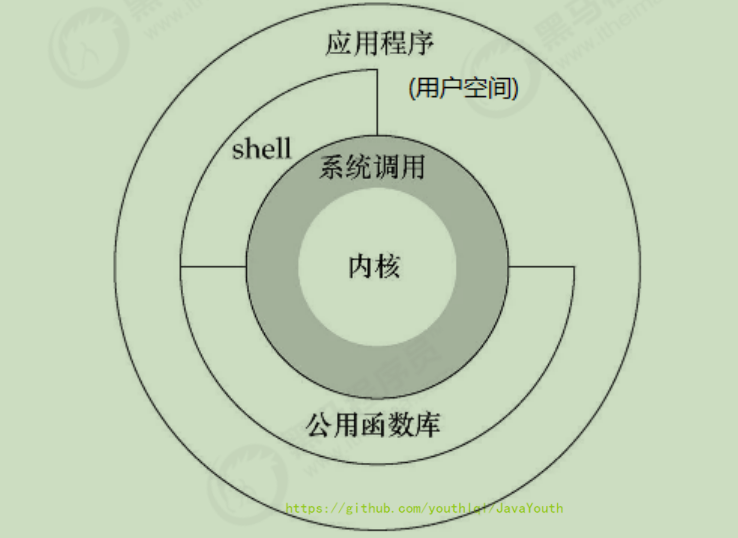 从上图可以看出,Linux操作系统的体系架构分为:用户空间(应用程序的活动空间)和内核。 内核:本质上可以理解为一种软件,控制计算机的硬件资源,并提供上层应用程序运行的环境。 用户空间:上层应用程序活动的空间。应用程序的执行必须依托于内核提供的资源,包括CPU资源、存 储资源、I/O资源等。 系统调用:为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口:即系统调用。
diff --git a/docs/java_concurrency/Java并发体系-第四阶段-AQS源码解读-[1].md b/docs/java_concurrency/Java并发体系-第四阶段-AQS源码解读-[1].md
index 22d52d7..f2a9891 100644
--- a/docs/java_concurrency/Java并发体系-第四阶段-AQS源码解读-[1].md
+++ b/docs/java_concurrency/Java并发体系-第四阶段-AQS源码解读-[1].md
@@ -410,11 +410,11 @@ Process finished with exit code 0
**技术翻译:**是用来构建锁或者其它同步器组件的重量级基础框架及整个JUC体系的基石, 通过内置的FIFO队列来完成资源获取线程的排队工作,并通过一个int类变量`state`表示持有锁的状态。
-
从上图可以看出,Linux操作系统的体系架构分为:用户空间(应用程序的活动空间)和内核。 内核:本质上可以理解为一种软件,控制计算机的硬件资源,并提供上层应用程序运行的环境。 用户空间:上层应用程序活动的空间。应用程序的执行必须依托于内核提供的资源,包括CPU资源、存 储资源、I/O资源等。 系统调用:为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口:即系统调用。
diff --git a/docs/java_concurrency/Java并发体系-第四阶段-AQS源码解读-[1].md b/docs/java_concurrency/Java并发体系-第四阶段-AQS源码解读-[1].md
index 22d52d7..f2a9891 100644
--- a/docs/java_concurrency/Java并发体系-第四阶段-AQS源码解读-[1].md
+++ b/docs/java_concurrency/Java并发体系-第四阶段-AQS源码解读-[1].md
@@ -410,11 +410,11 @@ Process finished with exit code 0
**技术翻译:**是用来构建锁或者其它同步器组件的重量级基础框架及整个JUC体系的基石, 通过内置的FIFO队列来完成资源获取线程的排队工作,并通过一个int类变量`state`表示持有锁的状态。
- +
+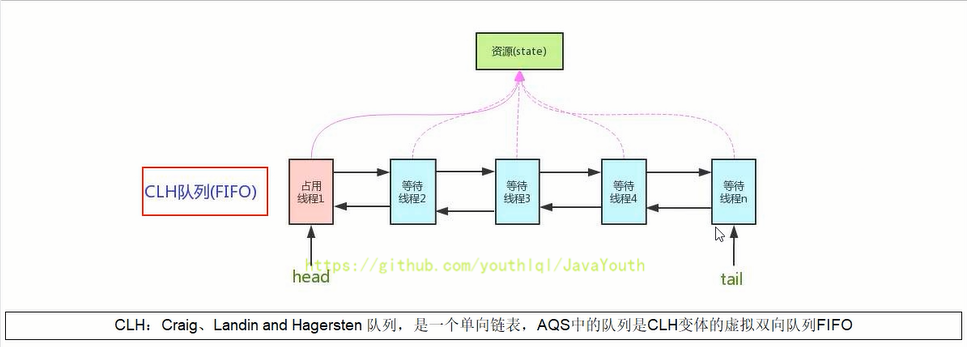 -
- +
+ AbstractOwnableSynchronizer
AbstractQueuedLongSynchronizer
@@ -426,7 +426,7 @@ AbstractQueuedSynchronizer
AQS是一个抽象的父类,可以将其理解为一个框架。基于AQS这个框架,我们可以实现多种同步器,比如下方图中的几个Java内置的同步器。同时我们也可以基于AQS框架实现我们自己的同步器以满足不同的业务场景需求。
-
AbstractOwnableSynchronizer
AbstractQueuedLongSynchronizer
@@ -426,7 +426,7 @@ AbstractQueuedSynchronizer
AQS是一个抽象的父类,可以将其理解为一个框架。基于AQS这个框架,我们可以实现多种同步器,比如下方图中的几个Java内置的同步器。同时我们也可以基于AQS框架实现我们自己的同步器以满足不同的业务场景需求。
- +
+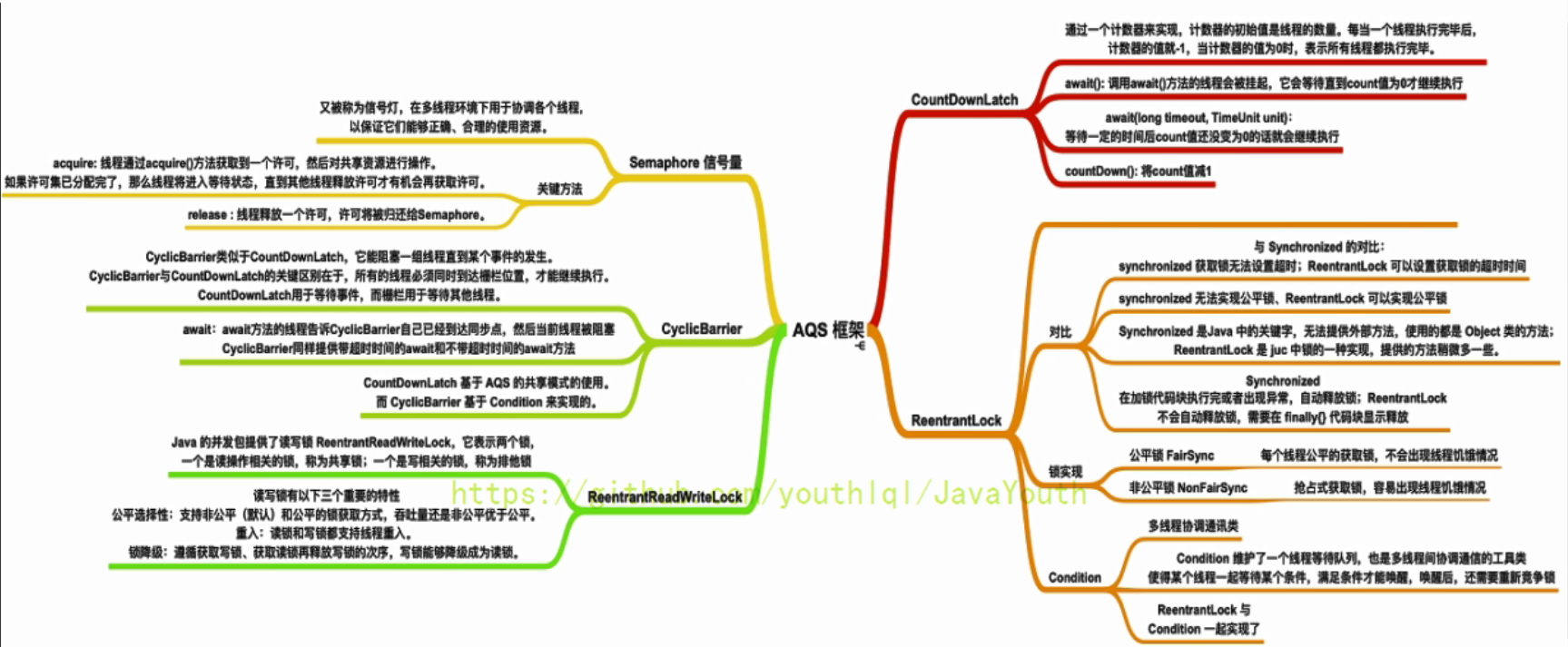 @@ -434,7 +434,7 @@ AQS是一个抽象的父类,可以将其理解为一个框架。基于AQS这
加锁会导致阻塞:有阻塞就需要排队,实现排队必然需要有某种形式的队列来进行管理
-
@@ -434,7 +434,7 @@ AQS是一个抽象的父类,可以将其理解为一个框架。基于AQS这
加锁会导致阻塞:有阻塞就需要排队,实现排队必然需要有某种形式的队列来进行管理
- +
+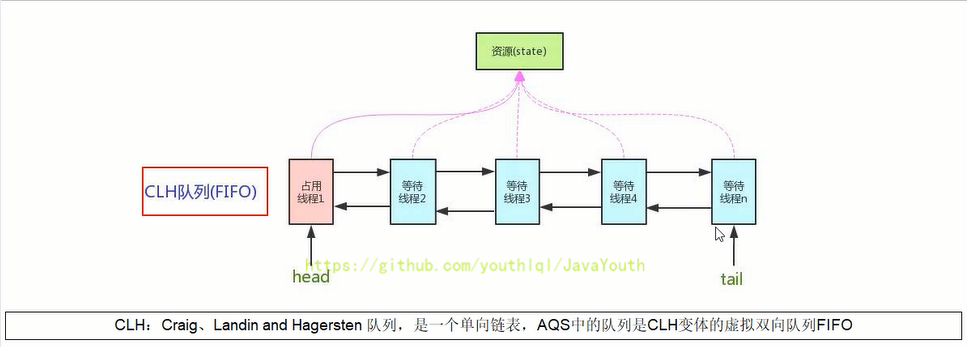 1、抢到资源的线程直接使用办理业务,抢占不到资源的线程的必然涉及一种**排队等候机制**,抢占资源失败的线程继续去等待(类似办理窗口都满了,暂时没有受理窗口的顾客只能去候客区排队等候),仍然保留获取锁的可能且获取锁流程仍在继续(候客区的顾客也在等着叫号,轮到了再去受理窗口办理业务)。
@@ -515,7 +515,7 @@ Node 的数据结构其实也挺简单的,就是 thread + waitStatus + pre + n
## AQS队列基本结构
-
1、抢到资源的线程直接使用办理业务,抢占不到资源的线程的必然涉及一种**排队等候机制**,抢占资源失败的线程继续去等待(类似办理窗口都满了,暂时没有受理窗口的顾客只能去候客区排队等候),仍然保留获取锁的可能且获取锁流程仍在继续(候客区的顾客也在等着叫号,轮到了再去受理窗口办理业务)。
@@ -515,7 +515,7 @@ Node 的数据结构其实也挺简单的,就是 thread + waitStatus + pre + n
## AQS队列基本结构
- +
+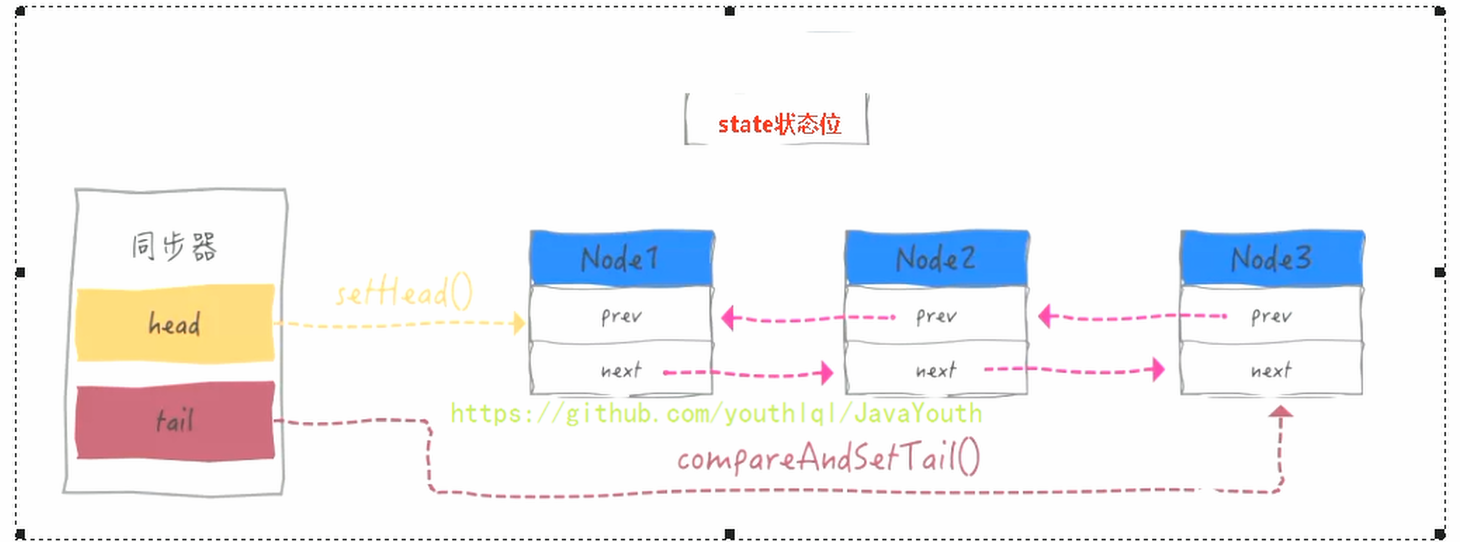 注意排队队列,不包括head(也就是后文要说的哨兵节点)。
@@ -583,7 +583,7 @@ public class AQSDemo {
以这样的一个实际例子说明。
-
注意排队队列,不包括head(也就是后文要说的哨兵节点)。
@@ -583,7 +583,7 @@ public class AQSDemo {
以这样的一个实际例子说明。
- +
+ @@ -765,7 +765,7 @@ public class AQSDemo {
2、C在if逻辑里准备入队,进行相应设置后,变成下面这样。
-
@@ -765,7 +765,7 @@ public class AQSDemo {
2、C在if逻辑里准备入队,进行相应设置后,变成下面这样。
- +
+ @@ -831,7 +831,7 @@ public class AQSDemo {
此时队列变成了下面的样子:
-
@@ -831,7 +831,7 @@ public class AQSDemo {
此时队列变成了下面的样子:
- +
+ 3、然后if结束之后,继续空的for循环,B线程开始了第二轮循环。
@@ -843,11 +843,11 @@ public class AQSDemo {
2、`node.prev = t`,进入if之后,让B节点的prev指针指向t,然后`compareAndSetTail(t, node)`设置尾节点
-
3、然后if结束之后,继续空的for循环,B线程开始了第二轮循环。
@@ -843,11 +843,11 @@ public class AQSDemo {
2、`node.prev = t`,进入if之后,让B节点的prev指针指向t,然后`compareAndSetTail(t, node)`设置尾节点
- +
+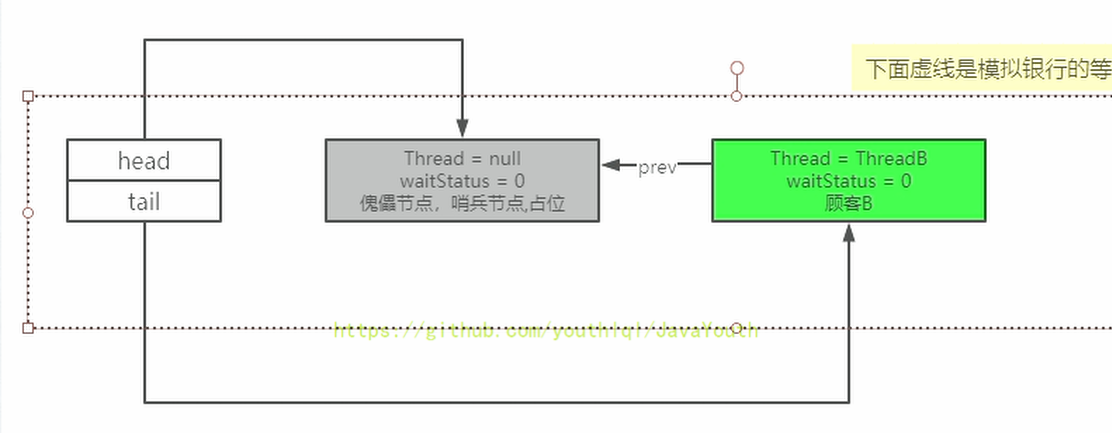 3、CAS设置尾节点成功之后,执行if里的逻辑
-
3、CAS设置尾节点成功之后,执行if里的逻辑
- +
+ @@ -1197,7 +1197,7 @@ protected final void setExclusiveOwnerThread(Thread thread) {
-
@@ -1197,7 +1197,7 @@ protected final void setExclusiveOwnerThread(Thread thread) {
- +
+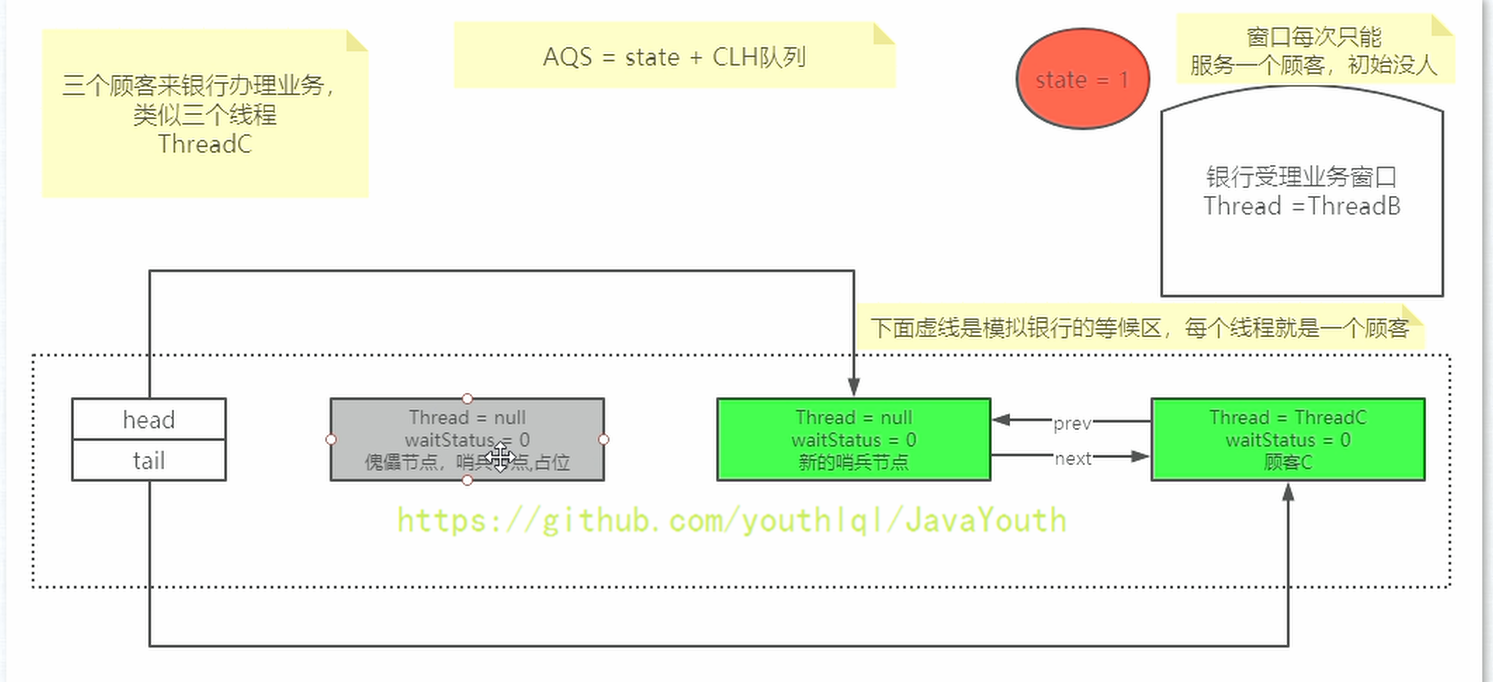 diff --git a/docs/netty/Netty入门-第一话.md b/docs/netty/Netty入门-第一话.md
index c171495..3a5bc9d 100644
--- a/docs/netty/Netty入门-第一话.md
+++ b/docs/netty/Netty入门-第一话.md
@@ -33,7 +33,7 @@ date: 2021-04-08 14:21:58
相对简单的一个体系图
-
diff --git a/docs/netty/Netty入门-第一话.md b/docs/netty/Netty入门-第一话.md
index c171495..3a5bc9d 100644
--- a/docs/netty/Netty入门-第一话.md
+++ b/docs/netty/Netty入门-第一话.md
@@ -33,7 +33,7 @@ date: 2021-04-08 14:21:58
相对简单的一个体系图
- +
+ ## Netty 的应用场景
@@ -67,7 +67,7 @@ date: 2021-04-08 14:21:58
## Netty 的学习资料参考
-
## Netty 的应用场景
@@ -67,7 +67,7 @@ date: 2021-04-08 14:21:58
## Netty 的学习资料参考
- +
+ @@ -97,11 +97,11 @@ date: 2021-04-08 14:21:58
2. `Java` 共支持 `3` 种网络编程模型 `I/O` 模式:`BIO`、`NIO`、`AIO`。
3. `Java BIO`:同步并阻塞(传统阻塞型),服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销。【简单示意图】
-
@@ -97,11 +97,11 @@ date: 2021-04-08 14:21:58
2. `Java` 共支持 `3` 种网络编程模型 `I/O` 模式:`BIO`、`NIO`、`AIO`。
3. `Java BIO`:同步并阻塞(传统阻塞型),服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销。【简单示意图】
- +
+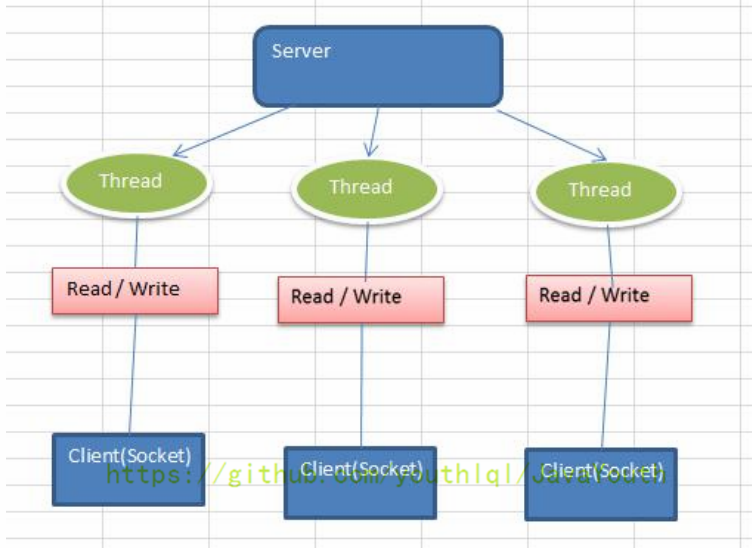 4. `Java NIO`:同步非阻塞,服务器实现模式为一个线程处理多个请求(连接),即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有 `I/O` 请求就进行处理。【简单示意图】
-
4. `Java NIO`:同步非阻塞,服务器实现模式为一个线程处理多个请求(连接),即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有 `I/O` 请求就进行处理。【简单示意图】
- +
+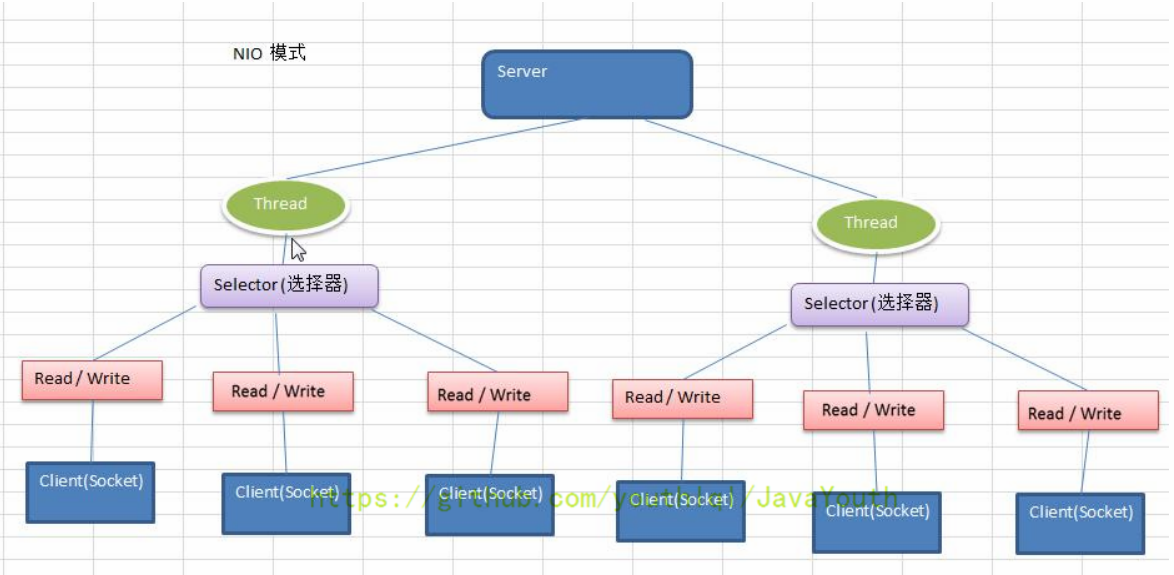 5. `Java AIO(NIO.2)`:异步非阻塞,`AIO` 引入异步通道的概念,采用了 `Proactor` 模式,简化了程序编写,有效的请求才启动线程,它的特点是先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用。
6. 我们依次展开讲解。
@@ -120,7 +120,7 @@ date: 2021-04-08 14:21:58
## Java BIO 工作机制
-
5. `Java AIO(NIO.2)`:异步非阻塞,`AIO` 引入异步通道的概念,采用了 `Proactor` 模式,简化了程序编写,有效的请求才启动线程,它的特点是先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用。
6. 我们依次展开讲解。
@@ -120,7 +120,7 @@ date: 2021-04-08 14:21:58
## Java BIO 工作机制
- +
+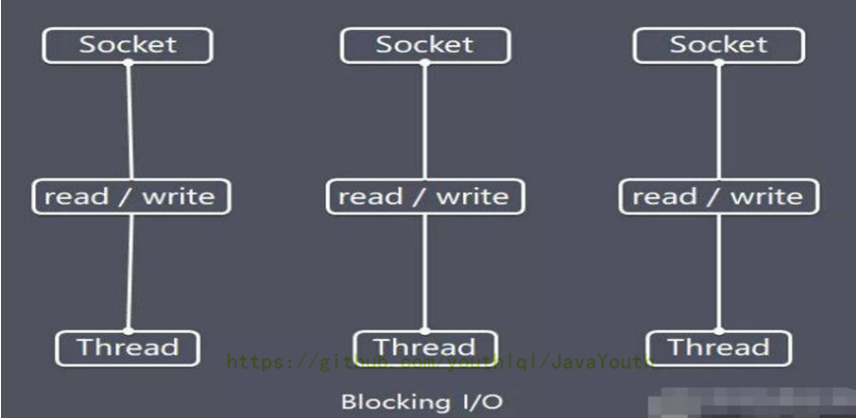 对 `BIO` 编程流程的梳理
@@ -207,7 +207,7 @@ public class BIOServer {
}
```
-
对 `BIO` 编程流程的梳理
@@ -207,7 +207,7 @@ public class BIOServer {
}
```
- +
+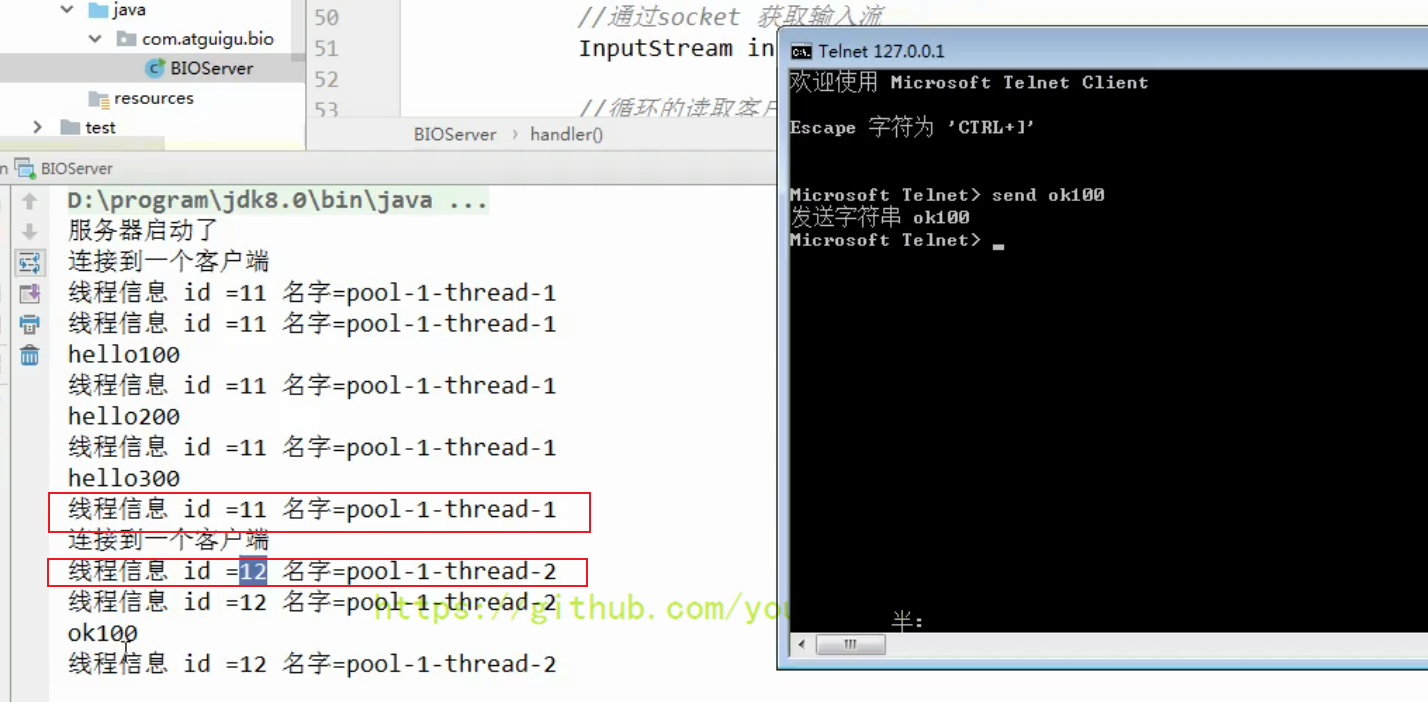 @@ -277,7 +277,7 @@ public class BasicBuffer {
3. `BIO` 基于字节流和字符流进行操作,而 `NIO` 基于 `Channel`(通道)和 `Buffer`(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。`Selector`(选择器)用于监听多个通道的事件(比如:连接请求,数据到达等),因此使用单个线程就可以监听多个客户端通道。
4. Buffer和Channel之间的数据流向是双向的
-
@@ -277,7 +277,7 @@ public class BasicBuffer {
3. `BIO` 基于字节流和字符流进行操作,而 `NIO` 基于 `Channel`(通道)和 `Buffer`(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。`Selector`(选择器)用于监听多个通道的事件(比如:连接请求,数据到达等),因此使用单个线程就可以监听多个客户端通道。
4. Buffer和Channel之间的数据流向是双向的
- +
+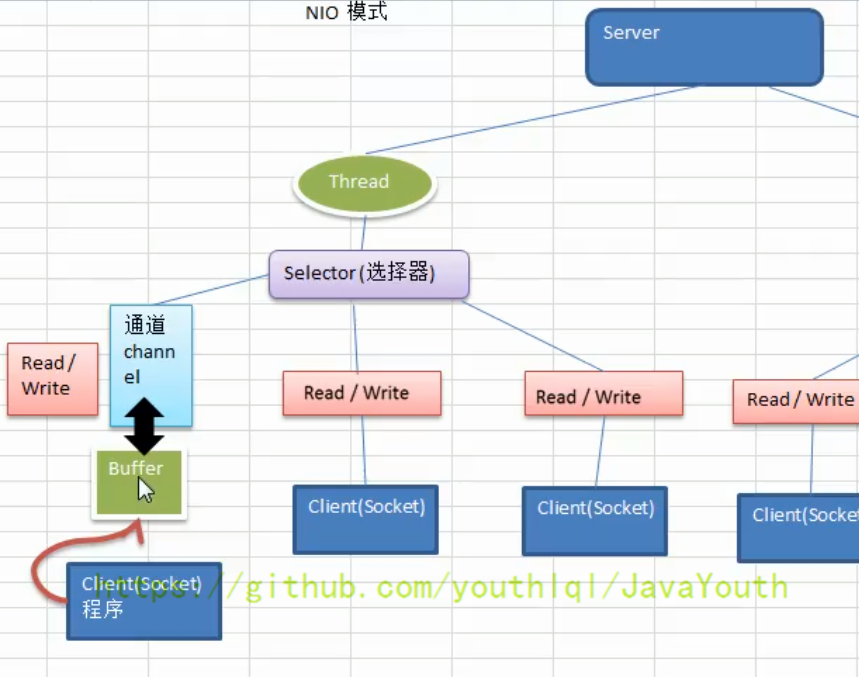 ## NIO 三大核心原理示意图
@@ -287,7 +287,7 @@ public class BasicBuffer {
关系图的说明:
-
## NIO 三大核心原理示意图
@@ -287,7 +287,7 @@ public class BasicBuffer {
关系图的说明:
- +
+ 1. 每个 `Channel` 都会对应一个 `Buffer`。
2. `Selector` 对应一个线程,一个线程对应多个 `Channel`(连接)。
@@ -303,17 +303,17 @@ public class BasicBuffer {
缓冲区(`Buffer`):缓冲区本质上是一个**可以读写数据的内存块**,可以理解成是一个**容器对象(含数组)**,该对象提供了一组方法,可以更轻松地使用内存块,,缓冲区对象内置了一些机制,能够跟踪和记录缓冲区的状态变化情况。`Channel` 提供从文件、网络读取数据的渠道,但是读取或写入的数据都必须经由 `Buffer`,如图:【后面举例说明】
-
1. 每个 `Channel` 都会对应一个 `Buffer`。
2. `Selector` 对应一个线程,一个线程对应多个 `Channel`(连接)。
@@ -303,17 +303,17 @@ public class BasicBuffer {
缓冲区(`Buffer`):缓冲区本质上是一个**可以读写数据的内存块**,可以理解成是一个**容器对象(含数组)**,该对象提供了一组方法,可以更轻松地使用内存块,,缓冲区对象内置了一些机制,能够跟踪和记录缓冲区的状态变化情况。`Channel` 提供从文件、网络读取数据的渠道,但是读取或写入的数据都必须经由 `Buffer`,如图:【后面举例说明】
- +
+ ### Buffer 类及其子类
1. 在 `NIO` 中,`Buffer` 是一个顶层父类,它是一个抽象类,类的层级关系图:
-
### Buffer 类及其子类
1. 在 `NIO` 中,`Buffer` 是一个顶层父类,它是一个抽象类,类的层级关系图:
- +
+ 2. `Buffer` 类定义了所有的缓冲区都具有的四个属性来提供关于其所包含的数据元素的信息:
-
2. `Buffer` 类定义了所有的缓冲区都具有的四个属性来提供关于其所包含的数据元素的信息:
- +
+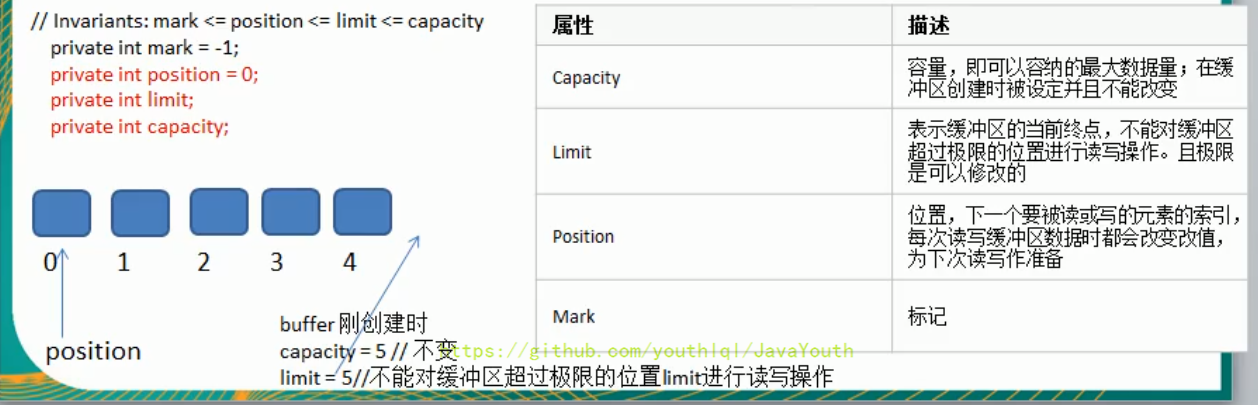 @@ -321,13 +321,13 @@ public class BasicBuffer {
3. `Buffer` 类相关方法一览
-
@@ -321,13 +321,13 @@ public class BasicBuffer {
3. `Buffer` 类相关方法一览
- +
+ ### ByteBuffer
从前面可以看出对于 `Java` 中的基本数据类型(`boolean` 除外),都有一个 `Buffer` 类型与之相对应,最常用的自然是 `ByteBuffer` 类(二进制数据),该类的主要方法如下:
-
### ByteBuffer
从前面可以看出对于 `Java` 中的基本数据类型(`boolean` 除外),都有一个 `Buffer` 类型与之相对应,最常用的自然是 `ByteBuffer` 类(二进制数据),该类的主要方法如下:
- +
+ ## 通道(Channel)
@@ -343,7 +343,7 @@ public class BasicBuffer {
5. `FileChannel` 用于文件的数据读写,`DatagramChannel` 用于 `UDP` 的数据读写,`ServerSocketChannel` 和 `SocketChannel` 用于 `TCP` 的数据读写。
6. 图示
-
## 通道(Channel)
@@ -343,7 +343,7 @@ public class BasicBuffer {
5. `FileChannel` 用于文件的数据读写,`DatagramChannel` 用于 `UDP` 的数据读写,`ServerSocketChannel` 和 `SocketChannel` 用于 `TCP` 的数据读写。
6. 图示
- +
+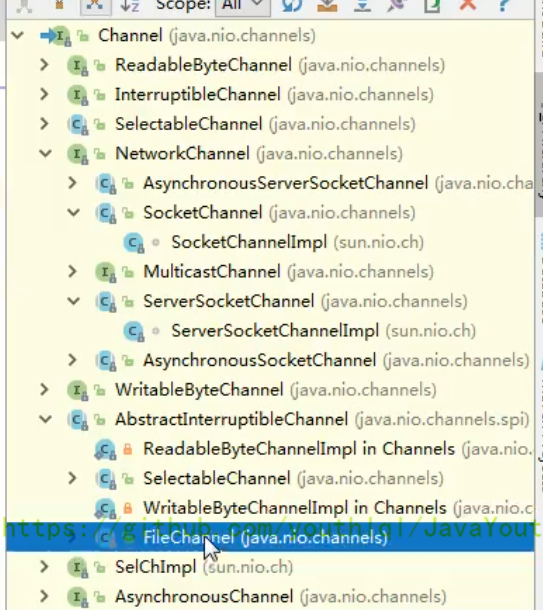 ### FileChannel 类
@@ -444,7 +444,7 @@ public class NIOFileChannel02 {
2. 拷贝一个文本文件 `1.txt`,放在项目下即可
3. 代码演示
-
### FileChannel 类
@@ -444,7 +444,7 @@ public class NIOFileChannel02 {
2. 拷贝一个文本文件 `1.txt`,放在项目下即可
3. 代码演示
- +
+ ```java
package com.atguigu.nio;
@@ -721,7 +721,7 @@ public class ScatteringAndGatheringTest {
### Selector 示意图和特点说明
-
```java
package com.atguigu.nio;
@@ -721,7 +721,7 @@ public class ScatteringAndGatheringTest {
### Selector 示意图和特点说明
- +
+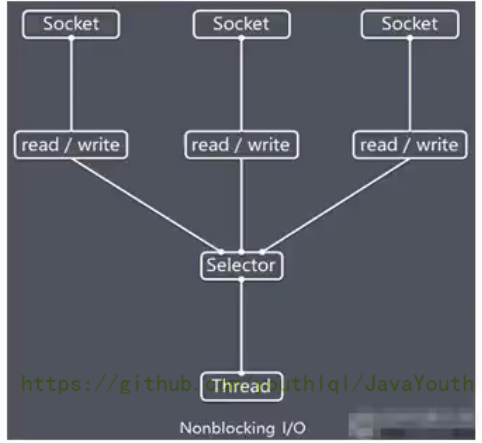 说明如下:
@@ -733,7 +733,7 @@ public class ScatteringAndGatheringTest {
### Selector 类相关方法
-
说明如下:
@@ -733,7 +733,7 @@ public class ScatteringAndGatheringTest {
### Selector 类相关方法
- +
+ ### 注意事项
@@ -748,7 +748,7 @@ public class ScatteringAndGatheringTest {
`NIO` 非阻塞网络编程相关的(`Selector`、`SelectionKey`、`ServerScoketChannel` 和 `SocketChannel`)关系梳理图
-
### 注意事项
@@ -748,7 +748,7 @@ public class ScatteringAndGatheringTest {
`NIO` 非阻塞网络编程相关的(`Selector`、`SelectionKey`、`ServerScoketChannel` 和 `SocketChannel`)关系梳理图
- +
+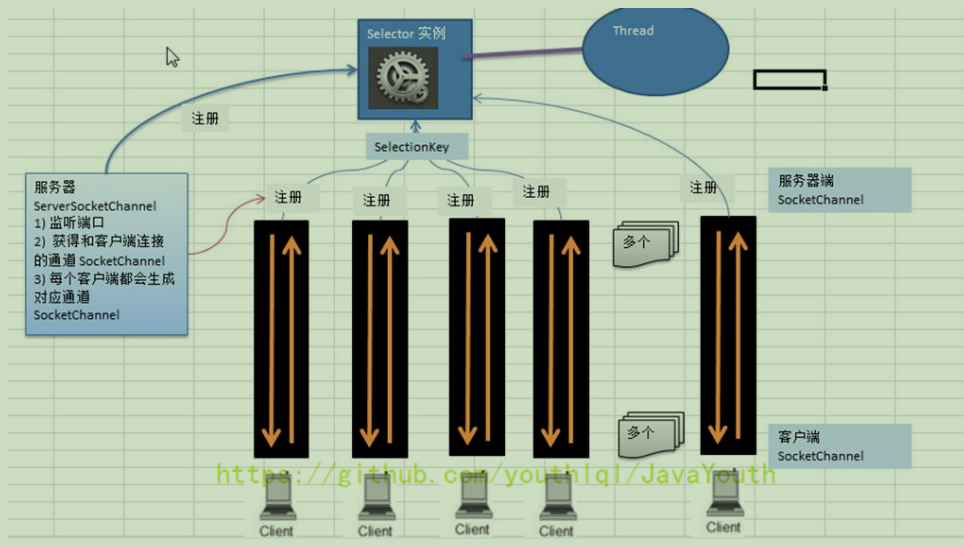 对上图的说明:
@@ -938,21 +938,21 @@ public static final int OP_ACCEPT = 1 << 4;
2. `SelectionKey` 相关方法
-
对上图的说明:
@@ -938,21 +938,21 @@ public static final int OP_ACCEPT = 1 << 4;
2. `SelectionKey` 相关方法
- +
+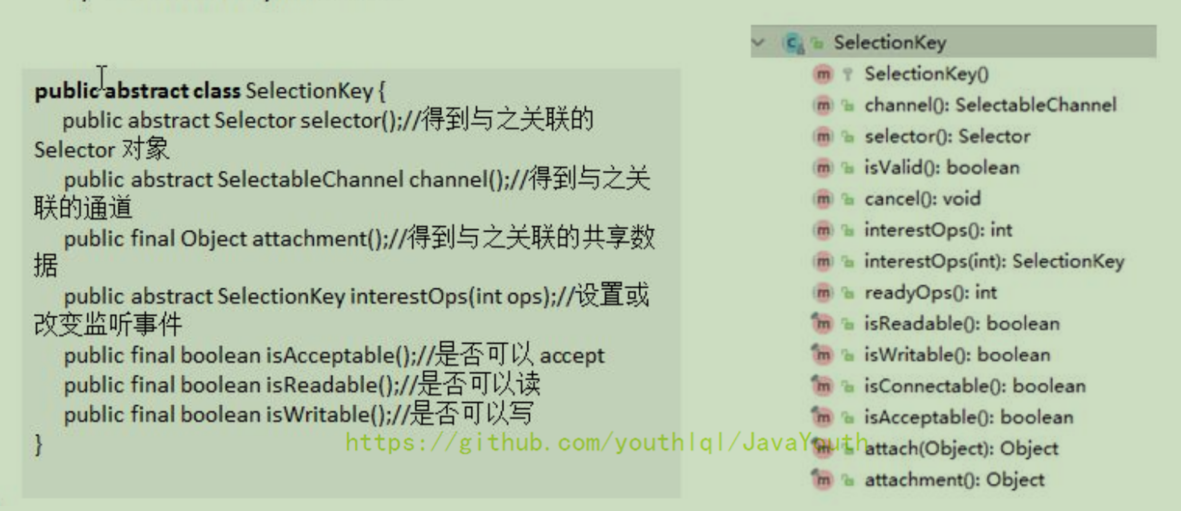 ### ServerSocketChannel
1. `ServerSocketChannel` 在服务器端监听新的客户端 `Socket` 连接,负责监听,不负责实际的读写操作
2. 相关方法如下
-
### ServerSocketChannel
1. `ServerSocketChannel` 在服务器端监听新的客户端 `Socket` 连接,负责监听,不负责实际的读写操作
2. 相关方法如下
- +
+ ### SocketChannel
1. `SocketChannel`,网络 `IO` 通道,**具体负责进行读写操作**。`NIO` 把缓冲区的数据写入通道,或者把通道里的数据读到缓冲区。
2. 相关方法如下
-
### SocketChannel
1. `SocketChannel`,网络 `IO` 通道,**具体负责进行读写操作**。`NIO` 把缓冲区的数据写入通道,或者把通道里的数据读到缓冲区。
2. 相关方法如下
- +
+ ## NIO网络编程应用实例 - 群聊系统
@@ -965,7 +965,7 @@ public static final int OP_ACCEPT = 1 << 4;
5. 目的:进一步理解 `NIO` 非阻塞网络编程机制
6. 示意图分析和代码
-
## NIO网络编程应用实例 - 群聊系统
@@ -965,7 +965,7 @@ public static final int OP_ACCEPT = 1 << 4;
5. 目的:进一步理解 `NIO` 非阻塞网络编程机制
6. 示意图分析和代码
- +
+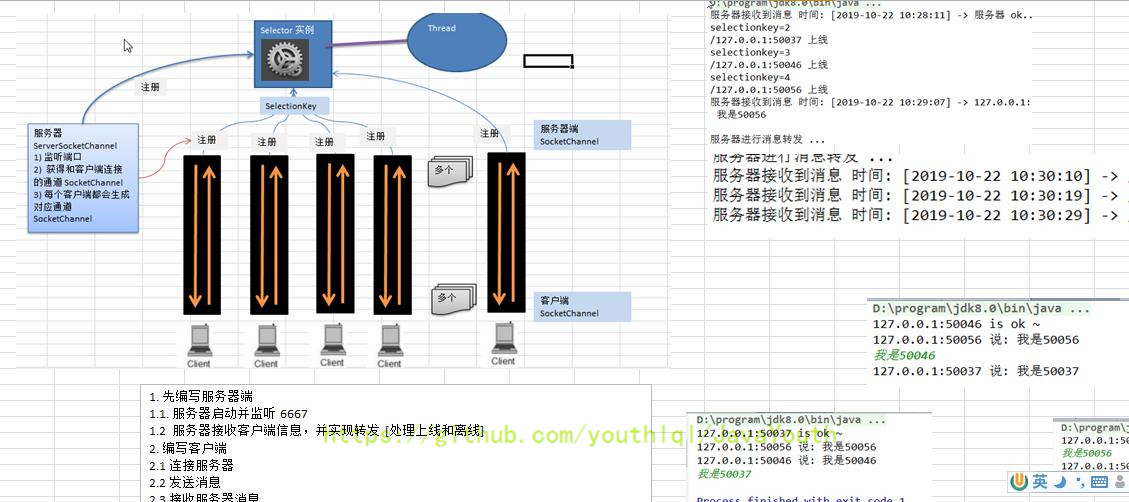 代码:
@@ -1243,7 +1243,7 @@ socket.getOutputStream().write(arr);
### 传统 IO 模型
-
代码:
@@ -1243,7 +1243,7 @@ socket.getOutputStream().write(arr);
### 传统 IO 模型
- +
+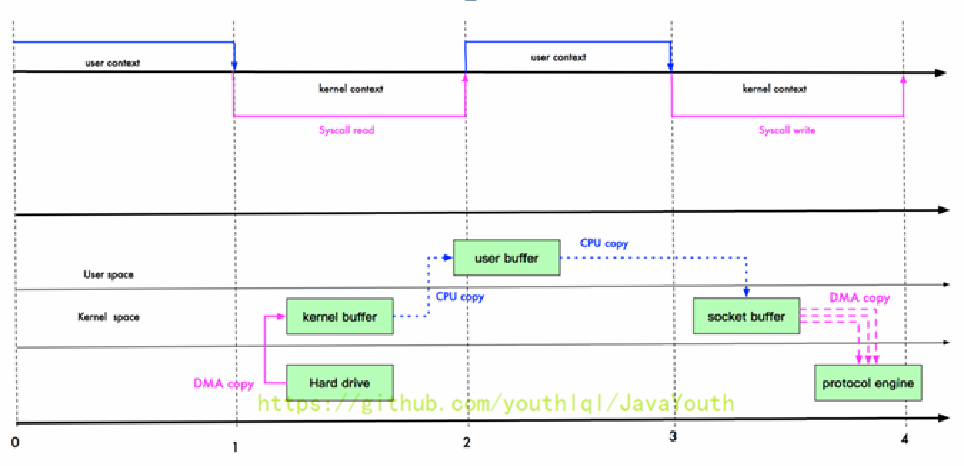 **DMA**:`direct memory access` 直接内存拷贝(不使用 `CPU`)
@@ -1252,19 +1252,19 @@ socket.getOutputStream().write(arr);
1. `mmap` 通过内存映射,将文件映射到内核缓冲区,同时,用户空间可以共享内核空间的数据。这样,在进行网络传输时,就可以减少内核空间到用户空间的拷贝次数。如下图
2. `mmap` 示意图
-
**DMA**:`direct memory access` 直接内存拷贝(不使用 `CPU`)
@@ -1252,19 +1252,19 @@ socket.getOutputStream().write(arr);
1. `mmap` 通过内存映射,将文件映射到内核缓冲区,同时,用户空间可以共享内核空间的数据。这样,在进行网络传输时,就可以减少内核空间到用户空间的拷贝次数。如下图
2. `mmap` 示意图
- +
+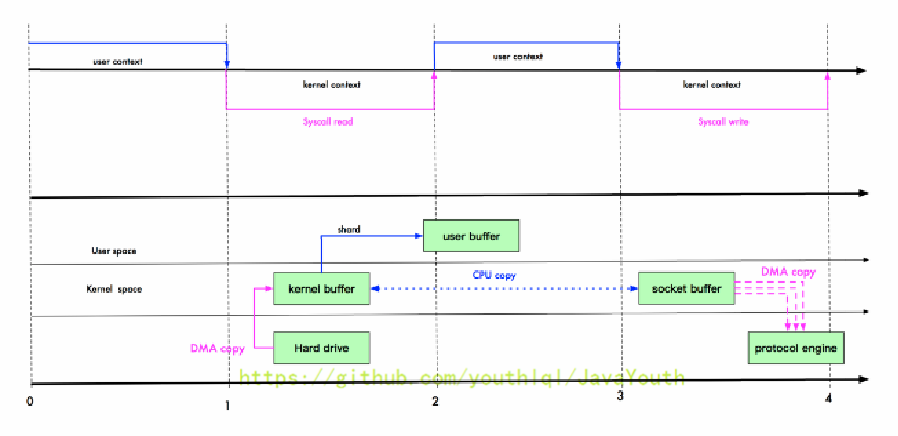 ### sendFile 优化
1. `Linux2.1` 版本提供了 `sendFile` 函数,其基本原理如下:数据根本不经过用户态,直接从内核缓冲区进入到 `SocketBuffer`,同时,由于和用户态完全无关,就减少了一次上下文切换
2. 示意图和小结
-
### sendFile 优化
1. `Linux2.1` 版本提供了 `sendFile` 函数,其基本原理如下:数据根本不经过用户态,直接从内核缓冲区进入到 `SocketBuffer`,同时,由于和用户态完全无关,就减少了一次上下文切换
2. 示意图和小结
- +
+ 3. 提示:零拷贝从操作系统角度,是没有 `cpu` 拷贝
4. `Linux在2.4` 版本中,做了一些修改,避免了从内核缓冲区拷贝到 `Socketbuffer` 的操作,直接拷贝到协议栈,从而再一次减少了数据拷贝。具体如下图和小结:
-
3. 提示:零拷贝从操作系统角度,是没有 `cpu` 拷贝
4. `Linux在2.4` 版本中,做了一些修改,避免了从内核缓冲区拷贝到 `Socketbuffer` 的操作,直接拷贝到协议栈,从而再一次减少了数据拷贝。具体如下图和小结:
- +
+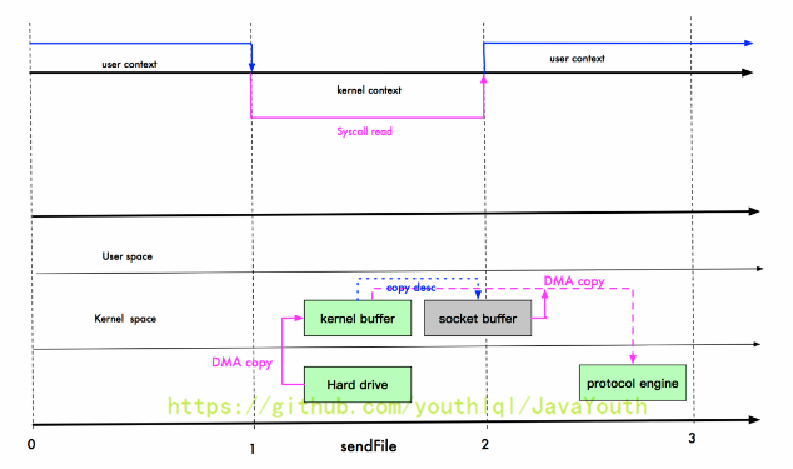 5. 这里其实有一次 `cpu` 拷贝 `kernel buffer` -> `socket buffer` 但是,拷贝的信息很少,比如 `lenght`、`offset` 消耗低,可以忽略
diff --git a/docs/netty/Netty入门-第三话.md b/docs/netty/Netty入门-第三话.md
index 643a996..5490f67 100644
--- a/docs/netty/Netty入门-第三话.md
+++ b/docs/netty/Netty入门-第三话.md
@@ -25,7 +25,7 @@ date: 2021-04-21 17:38:58
1. 编写网络应用程序时,因为数据在网络中传输的都是二进制字节码数据,在发送数据时就需要编码,接收数据时就需要解码[示意图]
2. `codec`(编解码器)的组成部分有两个:`decoder`(解码器)和 `encoder`(编码器)。`encoder` 负责把业务数据转换成字节码数据,`decoder` 负责把字节码数据转换成业务数据
-
5. 这里其实有一次 `cpu` 拷贝 `kernel buffer` -> `socket buffer` 但是,拷贝的信息很少,比如 `lenght`、`offset` 消耗低,可以忽略
diff --git a/docs/netty/Netty入门-第三话.md b/docs/netty/Netty入门-第三话.md
index 643a996..5490f67 100644
--- a/docs/netty/Netty入门-第三话.md
+++ b/docs/netty/Netty入门-第三话.md
@@ -25,7 +25,7 @@ date: 2021-04-21 17:38:58
1. 编写网络应用程序时,因为数据在网络中传输的都是二进制字节码数据,在发送数据时就需要编码,接收数据时就需要解码[示意图]
2. `codec`(编解码器)的组成部分有两个:`decoder`(解码器)和 `encoder`(编码器)。`encoder` 负责把业务数据转换成字节码数据,`decoder` 负责把字节码数据转换成业务数据
- +
+ ## Netty 本身的编码解码的机制和问题分析
@@ -54,7 +54,7 @@ date: 2021-04-21 17:38:58
8. 然后通过 `protoc.exe` 编译器根据 `.proto` 自动生成 `.java` 文件
9. `protobuf` 使用示意图
-
## Netty 本身的编码解码的机制和问题分析
@@ -54,7 +54,7 @@ date: 2021-04-21 17:38:58
8. 然后通过 `protoc.exe` 编译器根据 `.proto` 自动生成 `.java` 文件
9. `protobuf` 使用示意图
- +
+ ## Protobuf 快速入门实例
@@ -91,7 +91,7 @@ message Student { //会在 StudentPOJO 外部类生成一个内部类 Student,
protoc.exe --java_out=.Student.proto
将生成的 StudentPOJO 放入到项目使用
-
## Protobuf 快速入门实例
@@ -91,7 +91,7 @@ message Student { //会在 StudentPOJO 外部类生成一个内部类 Student,
protoc.exe --java_out=.Student.proto
将生成的 StudentPOJO 放入到项目使用
- +
+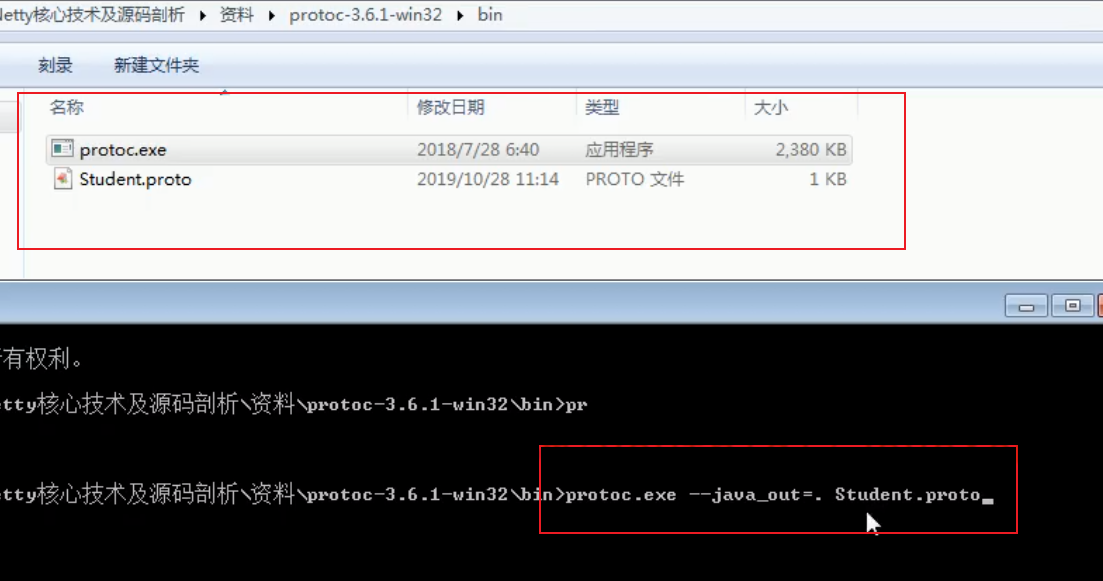 生成的StudentPOJO代码太长就不贴在这里了
@@ -676,7 +676,7 @@ public class NettyClientHandler extends ChannelInboundHandlerAdapter {
2. `ChannelHandler` 充当了处理入站和出站数据的应用程序逻辑的容器。例如,实现 `ChannelInboundHandler` 接口(或 `ChannelInboundHandlerAdapter`),你就可以接收入站事件和数据,这些数据会被业务逻辑处理。当要给客户端发送响应时,也可以从 `ChannelInboundHandler` 冲刷数据。业务逻辑通常写在一个或者多个 `ChannelInboundHandler` 中。`ChannelOutboundHandler` 原理一样,只不过它是用来处理出站数据的
3. `ChannelPipeline` 提供了 `ChannelHandler` 链的容器。以客户端应用程序为例,如果事件的运动方向是从客户端到服务端的,那么我们称这些事件为出站的,即客户端发送给服务端的数据会通过 `pipeline` 中的一系列 `ChannelOutboundHandler`,并被这些 `Handler` 处理,反之则称为入站的
-
生成的StudentPOJO代码太长就不贴在这里了
@@ -676,7 +676,7 @@ public class NettyClientHandler extends ChannelInboundHandlerAdapter {
2. `ChannelHandler` 充当了处理入站和出站数据的应用程序逻辑的容器。例如,实现 `ChannelInboundHandler` 接口(或 `ChannelInboundHandlerAdapter`),你就可以接收入站事件和数据,这些数据会被业务逻辑处理。当要给客户端发送响应时,也可以从 `ChannelInboundHandler` 冲刷数据。业务逻辑通常写在一个或者多个 `ChannelInboundHandler` 中。`ChannelOutboundHandler` 原理一样,只不过它是用来处理出站数据的
3. `ChannelPipeline` 提供了 `ChannelHandler` 链的容器。以客户端应用程序为例,如果事件的运动方向是从客户端到服务端的,那么我们称这些事件为出站的,即客户端发送给服务端的数据会通过 `pipeline` 中的一系列 `ChannelOutboundHandler`,并被这些 `Handler` 处理,反之则称为入站的
- +
+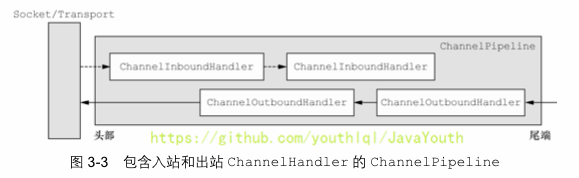 > 出站,入站如果搞不清楚,看下面的**Netty的handler链的调用机制**,通过一个例子和图讲清楚
@@ -689,12 +689,12 @@ public class NettyClientHandler extends ChannelInboundHandlerAdapter {
1. 关系继承图
-
> 出站,入站如果搞不清楚,看下面的**Netty的handler链的调用机制**,通过一个例子和图讲清楚
@@ -689,12 +689,12 @@ public class NettyClientHandler extends ChannelInboundHandlerAdapter {
1. 关系继承图
- +
+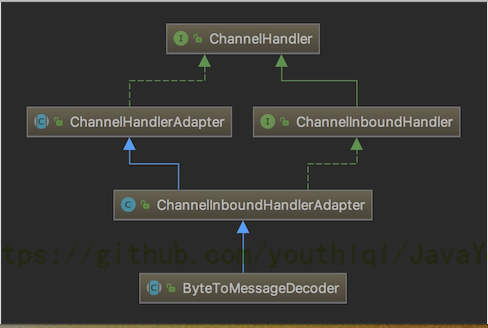 2. 由于不可能知道远程节点是否会一次性发送一个完整的信息,`tcp` 有可能出现粘包拆包的问题,这个类会对入站数据进行缓冲,直到它准备好被处理.【后面有说TCP的粘包和拆包问题】
3. 一个关于 `ByteToMessageDecoder` 实例分析
-
2. 由于不可能知道远程节点是否会一次性发送一个完整的信息,`tcp` 有可能出现粘包拆包的问题,这个类会对入站数据进行缓冲,直到它准备好被处理.【后面有说TCP的粘包和拆包问题】
3. 一个关于 `ByteToMessageDecoder` 实例分析
- +
+ @@ -710,7 +710,7 @@ public class NettyClientHandler extends ChannelInboundHandlerAdapter {
> 读者可以看下这个图,带着这个图去看下面的例子。
-
@@ -710,7 +710,7 @@ public class NettyClientHandler extends ChannelInboundHandlerAdapter {
> 读者可以看下这个图,带着这个图去看下面的例子。
- +
+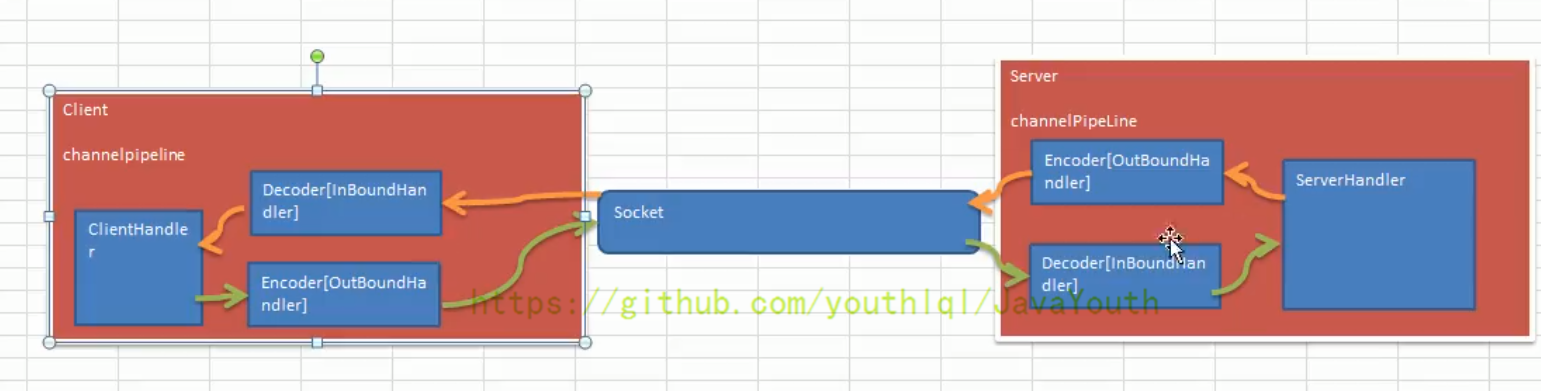 @@ -978,11 +978,11 @@ public class MyLongToByteEncoder extends MessageToByteEncoder {
### 效果
-
@@ -978,11 +978,11 @@ public class MyLongToByteEncoder extends MessageToByteEncoder {
### 效果
- +
+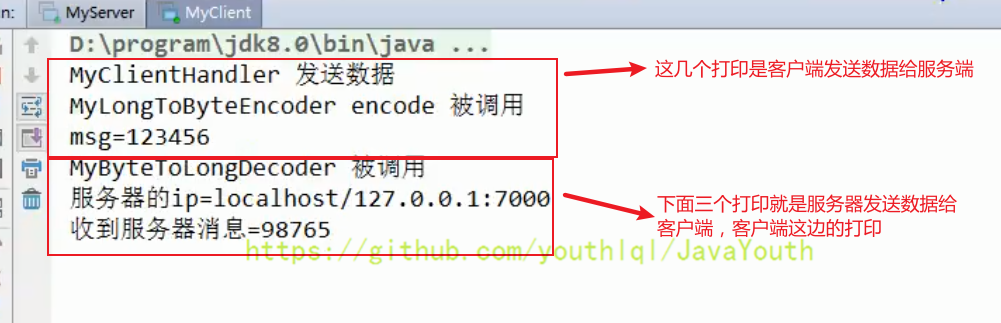 -
- +
+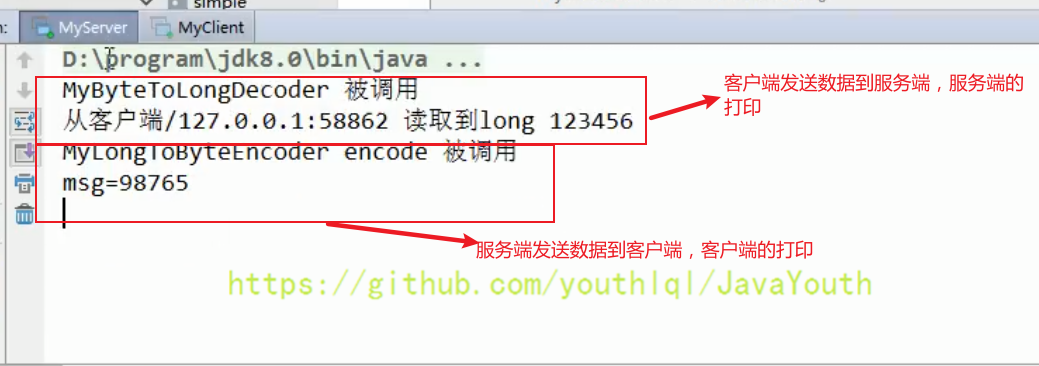 @@ -1002,7 +1002,7 @@ public class MyLongToByteEncoder extends MessageToByteEncoder {
-
+
@@ -1090,13 +1090,13 @@ public class MyByteToLongDecoder extends ByteToMessageDecoder {
如下图验证结果:
-
@@ -1002,7 +1002,7 @@ public class MyLongToByteEncoder extends MessageToByteEncoder {
-
+
@@ -1090,13 +1090,13 @@ public class MyByteToLongDecoder extends ByteToMessageDecoder {
如下图验证结果:
- +
+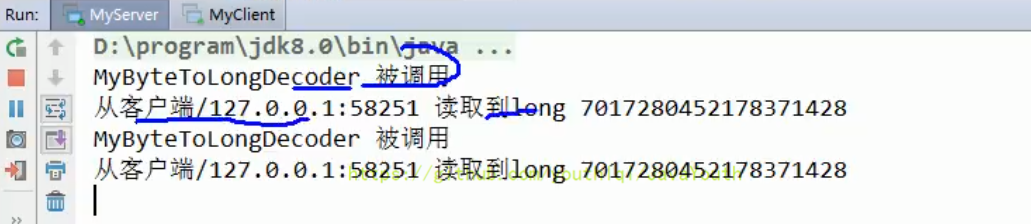 2. 同时又引出了一个小问题
-
2. 同时又引出了一个小问题
-  +
+  当我们`MyClientHandler`传一个Long时,会调用我们的`MyLongToByteEncoder`的编码器。那么控制台就会打印这样一句话:**MyLongToByteEncoder encode 被调用**。但是这里并没有调用编码器,这是为什么呢?
@@ -1149,7 +1149,7 @@ public class MyByteToLongDecoder extends ByteToMessageDecoder {
ctx.writeAndFlush(Unpooled.copiedBuffer("abcdabcdabcdabcd",CharsetUtil.UTF_8));
```
-
当我们`MyClientHandler`传一个Long时,会调用我们的`MyLongToByteEncoder`的编码器。那么控制台就会打印这样一句话:**MyLongToByteEncoder encode 被调用**。但是这里并没有调用编码器,这是为什么呢?
@@ -1149,7 +1149,7 @@ public class MyByteToLongDecoder extends ByteToMessageDecoder {
ctx.writeAndFlush(Unpooled.copiedBuffer("abcdabcdabcdabcd",CharsetUtil.UTF_8));
```
- +
+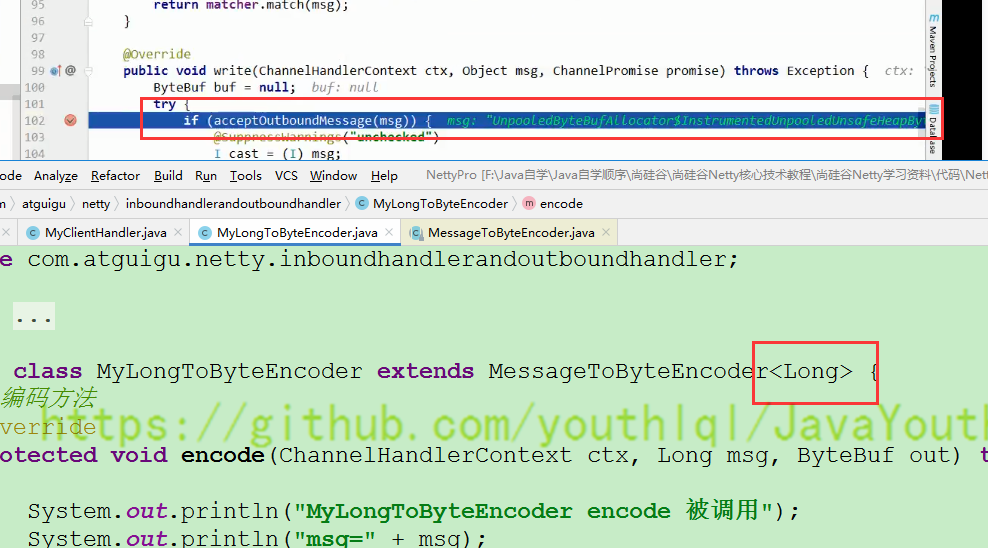 @@ -1198,7 +1198,7 @@ public class MyByteToLongDecoder2 extends ReplayingDecoder {
## 其它编解码器
-
@@ -1198,7 +1198,7 @@ public class MyByteToLongDecoder2 extends ReplayingDecoder {
## 其它编解码器
- +
+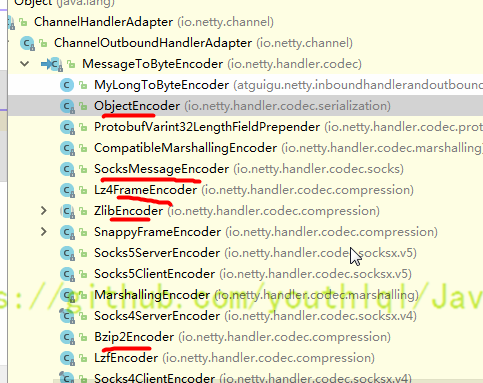 @@ -1249,7 +1249,7 @@ log4j.appender.stdout.layout.ConversionPattern=[%p]%C{1}-%m%n
3. 演示整合
-
@@ -1249,7 +1249,7 @@ log4j.appender.stdout.layout.ConversionPattern=[%p]%C{1}-%m%n
3. 演示整合
- +
+ @@ -1261,7 +1261,7 @@ log4j.appender.stdout.layout.ConversionPattern=[%p]%C{1}-%m%n
2. 由于 `TCP` 无消息保护边界,需要在接收端处理消息边界问题,也就是我们所说的粘包、拆包问题,看一张图
3. `TCP` 粘包、拆包图解
-
@@ -1261,7 +1261,7 @@ log4j.appender.stdout.layout.ConversionPattern=[%p]%C{1}-%m%n
2. 由于 `TCP` 无消息保护边界,需要在接收端处理消息边界问题,也就是我们所说的粘包、拆包问题,看一张图
3. `TCP` 粘包、拆包图解
- +
+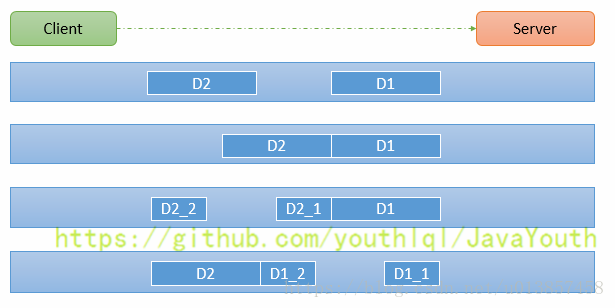 假设客户端分别发送了两个数据包 `D1` 和 `D2` 给服务端,由于服务端一次读取到字节数是不确定的,故可能存在以下四种情况:
@@ -1502,11 +1502,11 @@ public class MyClientHandler extends SimpleChannelInboundHandler {
**Client**
-
假设客户端分别发送了两个数据包 `D1` 和 `D2` 给服务端,由于服务端一次读取到字节数是不确定的,故可能存在以下四种情况:
@@ -1502,11 +1502,11 @@ public class MyClientHandler extends SimpleChannelInboundHandler {
**Client**
- +
+ **Server**
-
**Server**
- +
+ @@ -1514,13 +1514,13 @@ public class MyClientHandler extends SimpleChannelInboundHandler {
**Client**
-
@@ -1514,13 +1514,13 @@ public class MyClientHandler extends SimpleChannelInboundHandler {
**Client**
- +
+ **Server**
-
**Server**
- +
+ @@ -1538,7 +1538,7 @@ public class MyClientHandler extends SimpleChannelInboundHandler {
1. 要求客户端发送 `5` 个 `Message` 对象,客户端每次发送一个 `Message` 对象
2. 服务器端每次接收一个 `Message`,分 `5` 次进行解码,每读取到一个 `Message`,会回复一个 `Message` 对象给客户端。
-
@@ -1538,7 +1538,7 @@ public class MyClientHandler extends SimpleChannelInboundHandler {
1. 要求客户端发送 `5` 个 `Message` 对象,客户端每次发送一个 `Message` 对象
2. 服务器端每次接收一个 `Message`,分 `5` 次进行解码,每读取到一个 `Message`,会回复一个 `Message` 对象给客户端。
- +
+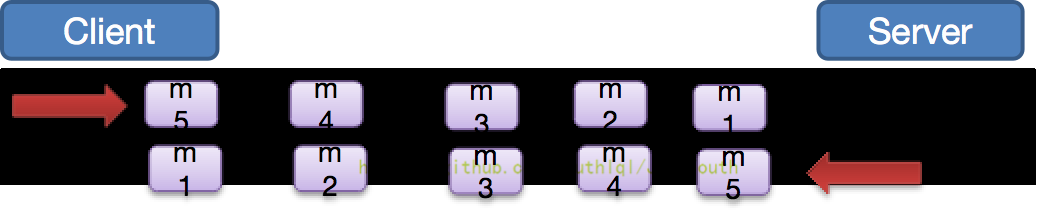 @@ -1996,7 +1996,7 @@ MyMessageEncoder encode 方法被调用
1. `RPC(Remote Procedure Call)`—远程过程调用,是一个计算机通信协议。该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无需额外地为这个交互作用编程
2. 两个或多个应用程序都分布在不同的服务器上,它们之间的调用都像是本地方法调用一样(如图)
-
@@ -1996,7 +1996,7 @@ MyMessageEncoder encode 方法被调用
1. `RPC(Remote Procedure Call)`—远程过程调用,是一个计算机通信协议。该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无需额外地为这个交互作用编程
2. 两个或多个应用程序都分布在不同的服务器上,它们之间的调用都像是本地方法调用一样(如图)
- +
+ 过程:
@@ -2018,11 +2018,11 @@ MyMessageEncoder encode 方法被调用
3. 常见的 `RPC` 框架有:比较知名的如阿里的 `Dubbo`、`Google` 的 `gRPC`、`Go` 语言的 `rpcx`、`Apache` 的 `thrift`,`Spring` 旗下的 `SpringCloud`。
-
过程:
@@ -2018,11 +2018,11 @@ MyMessageEncoder encode 方法被调用
3. 常见的 `RPC` 框架有:比较知名的如阿里的 `Dubbo`、`Google` 的 `gRPC`、`Go` 语言的 `rpcx`、`Apache` 的 `thrift`,`Spring` 旗下的 `SpringCloud`。
- +
+ ## 我们的RPC 调用流程图
-
## 我们的RPC 调用流程图
- +
+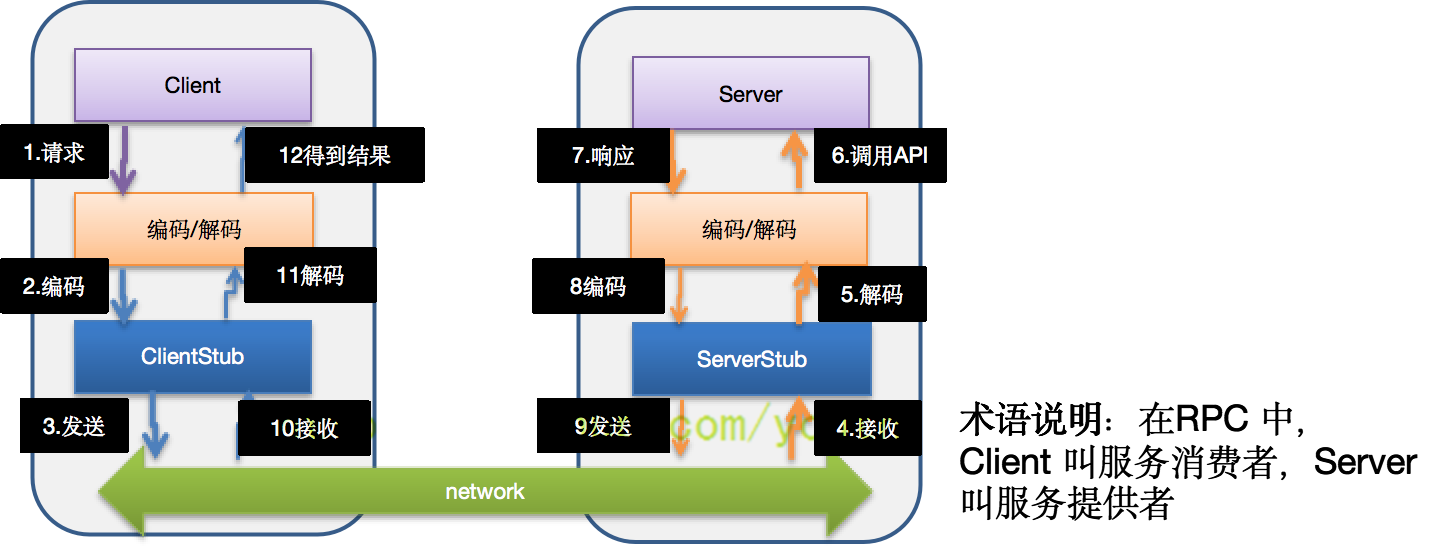 **RPC 调用流程说明**
@@ -2052,7 +2052,7 @@ MyMessageEncoder encode 方法被调用
3. 创建一个消费者,该类需要透明的调用自己不存在的方法,内部需要使用 `Netty` 请求提供者返回数据
4. 开发的分析图
-
**RPC 调用流程说明**
@@ -2052,7 +2052,7 @@ MyMessageEncoder encode 方法被调用
3. 创建一个消费者,该类需要透明的调用自己不存在的方法,内部需要使用 `Netty` 请求提供者返回数据
4. 开发的分析图
- +
+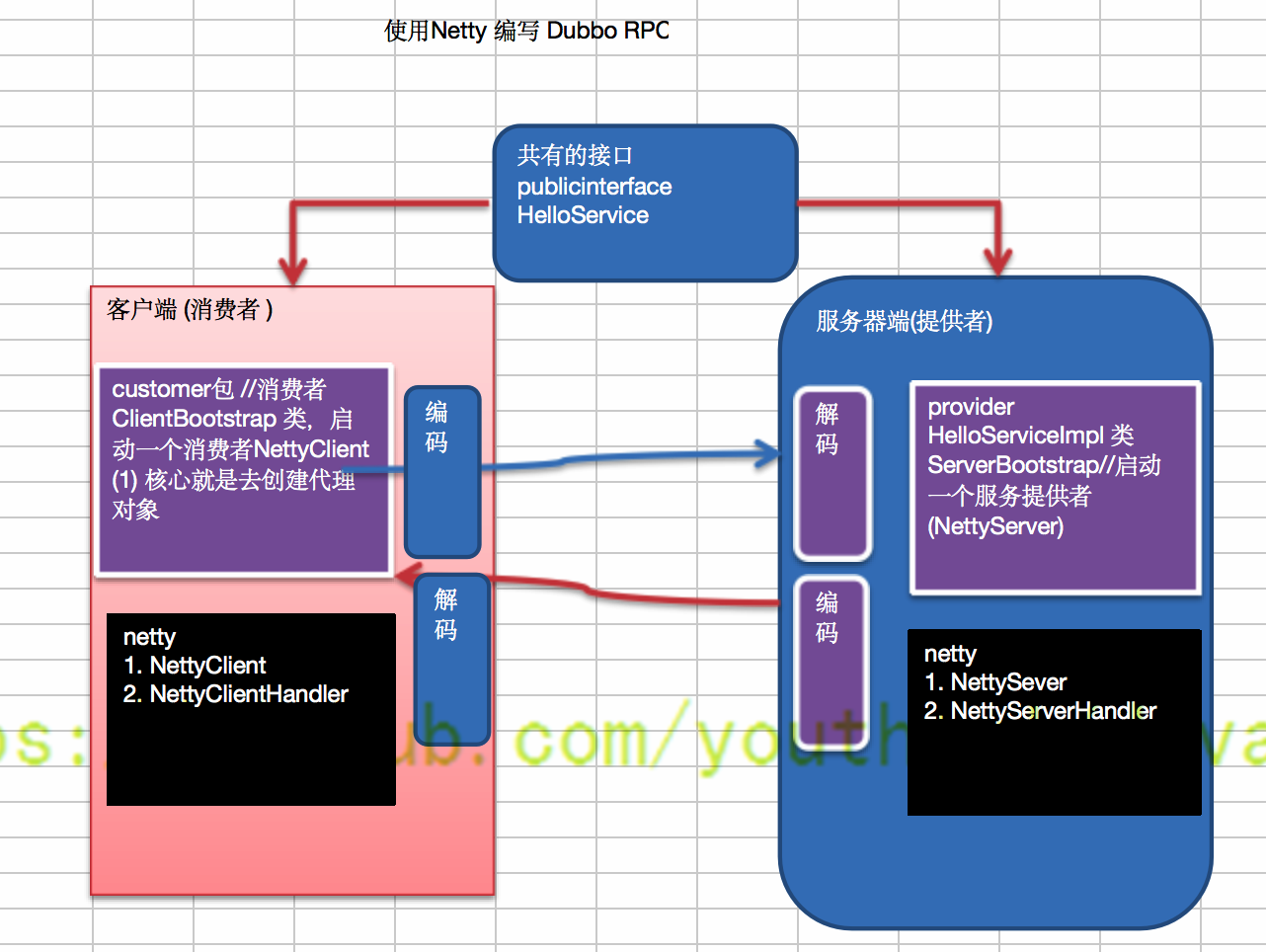 diff --git a/docs/netty/Netty入门-第二话.md b/docs/netty/Netty入门-第二话.md
index 9a7d16c..401c4d3 100644
--- a/docs/netty/Netty入门-第二话.md
+++ b/docs/netty/Netty入门-第二话.md
@@ -29,7 +29,7 @@ date: 2021-04-15 14:21:58
Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients.
-
diff --git a/docs/netty/Netty入门-第二话.md b/docs/netty/Netty入门-第二话.md
index 9a7d16c..401c4d3 100644
--- a/docs/netty/Netty入门-第二话.md
+++ b/docs/netty/Netty入门-第二话.md
@@ -29,7 +29,7 @@ date: 2021-04-15 14:21:58
Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients.
- +
+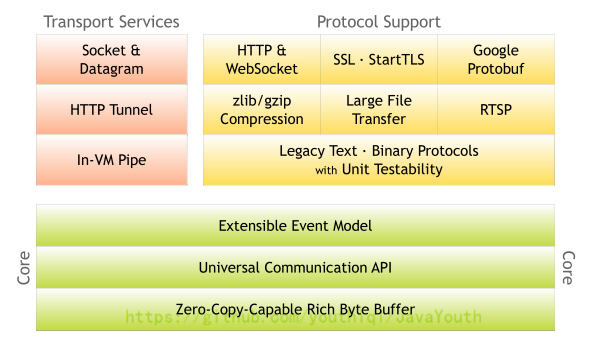 ## Netty 的优点
@@ -80,7 +80,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
1. 当并发数很大,就会创建大量的线程,占用很大系统资源
2. 连接创建后,如果当前线程暂时没有数据可读,该线程会阻塞在 Handler对象中的`read` 操作,导致上面的处理线程资源浪费
-
## Netty 的优点
@@ -80,7 +80,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
1. 当并发数很大,就会创建大量的线程,占用很大系统资源
2. 连接创建后,如果当前线程暂时没有数据可读,该线程会阻塞在 Handler对象中的`read` 操作,导致上面的处理线程资源浪费
- +
+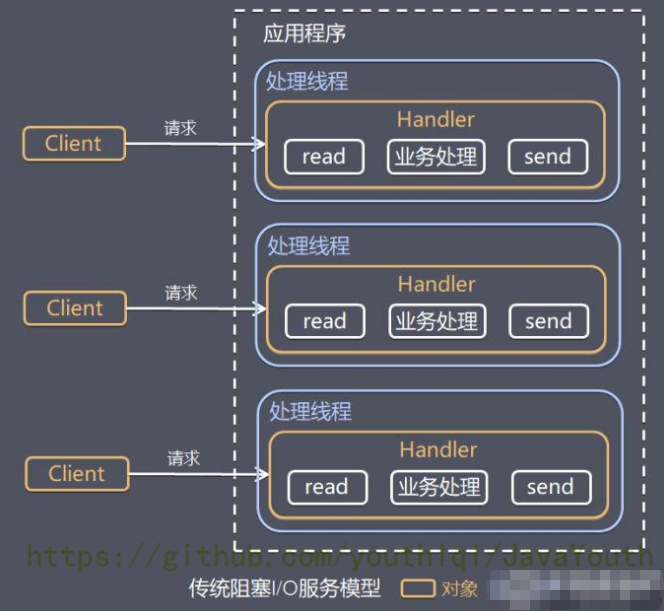 ## Reactor 模式
@@ -97,7 +97,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
1. 基于线程池复用线程资源:不必再为每个连接创建线程,将连接完成后的业务处理任务分配给线程进行处理,一个线程可以处理多个连接的业务。(解决了当并发数很大时,会创建大量线程,占用很大系统资源)
2. 基于 `I/O` 复用模型:多个客户端进行连接,先把连接请求给`ServiceHandler`。多个连接共用一个阻塞对象`ServiceHandler`。假设,当C1连接没有数据要处理时,C1客户端只需要阻塞于`ServiceHandler`,C1之前的处理线程便可以处理其他有数据的连接,不会造成线程资源的浪费。当C1连接再次有数据时,`ServiceHandler`根据线程池的空闲状态,将请求分发给空闲的线程来处理C1连接的任务。(解决了线程资源浪费的那个问题)
-
## Reactor 模式
@@ -97,7 +97,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
1. 基于线程池复用线程资源:不必再为每个连接创建线程,将连接完成后的业务处理任务分配给线程进行处理,一个线程可以处理多个连接的业务。(解决了当并发数很大时,会创建大量线程,占用很大系统资源)
2. 基于 `I/O` 复用模型:多个客户端进行连接,先把连接请求给`ServiceHandler`。多个连接共用一个阻塞对象`ServiceHandler`。假设,当C1连接没有数据要处理时,C1客户端只需要阻塞于`ServiceHandler`,C1之前的处理线程便可以处理其他有数据的连接,不会造成线程资源的浪费。当C1连接再次有数据时,`ServiceHandler`根据线程池的空闲状态,将请求分发给空闲的线程来处理C1连接的任务。(解决了线程资源浪费的那个问题)
- +
+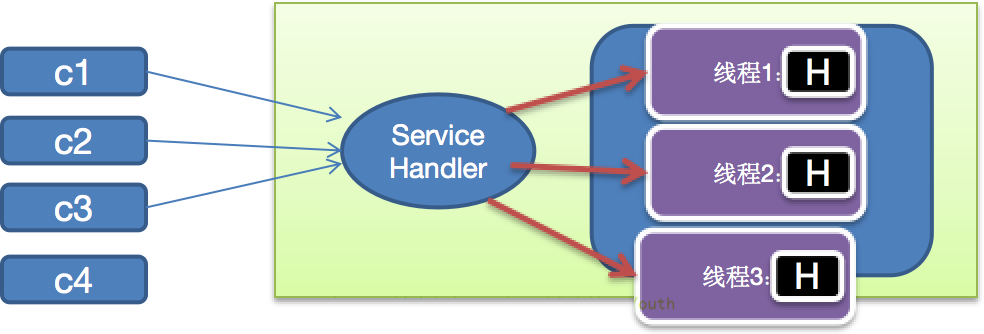 @@ -105,7 +105,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
### I/O 复用结合线程池,就是 Reactor 模式基本设计思想,如图
-
@@ -105,7 +105,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
### I/O 复用结合线程池,就是 Reactor 模式基本设计思想,如图
- +
+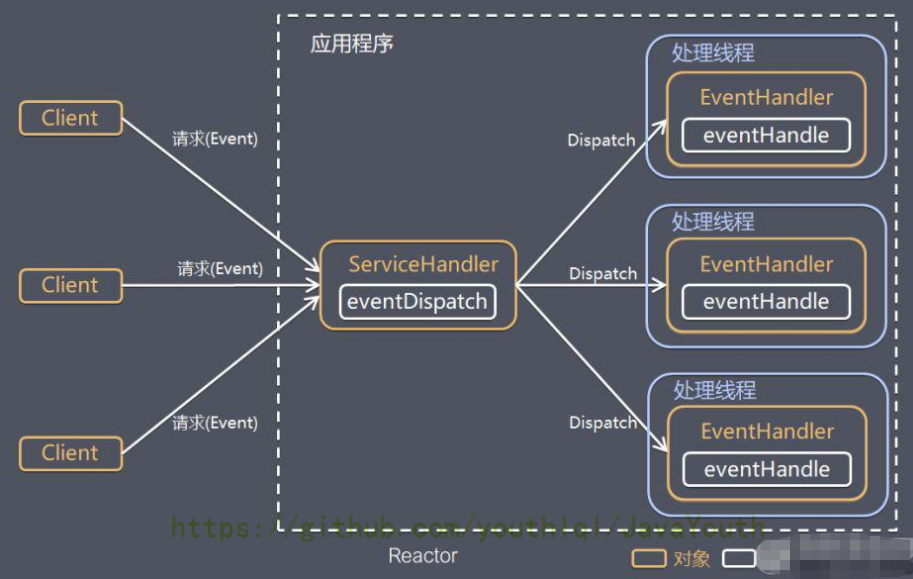 对上图说明:
@@ -132,7 +132,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
原理图,并使用 `NIO` 群聊系统验证
-
对上图说明:
@@ -132,7 +132,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
原理图,并使用 `NIO` 群聊系统验证
- +
+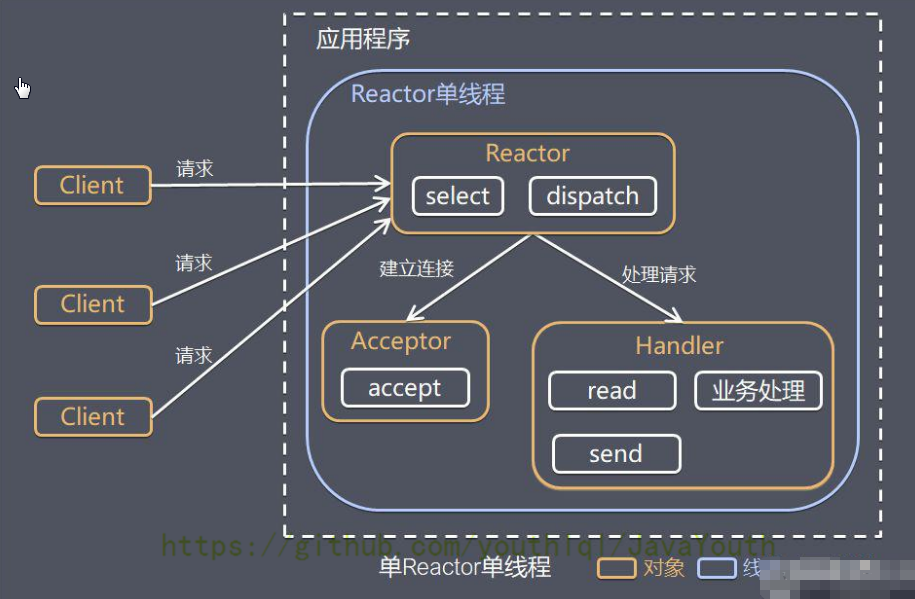 ### 方案说明
@@ -155,7 +155,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
### 方案说明
-
### 方案说明
@@ -155,7 +155,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
### 方案说明
- +
+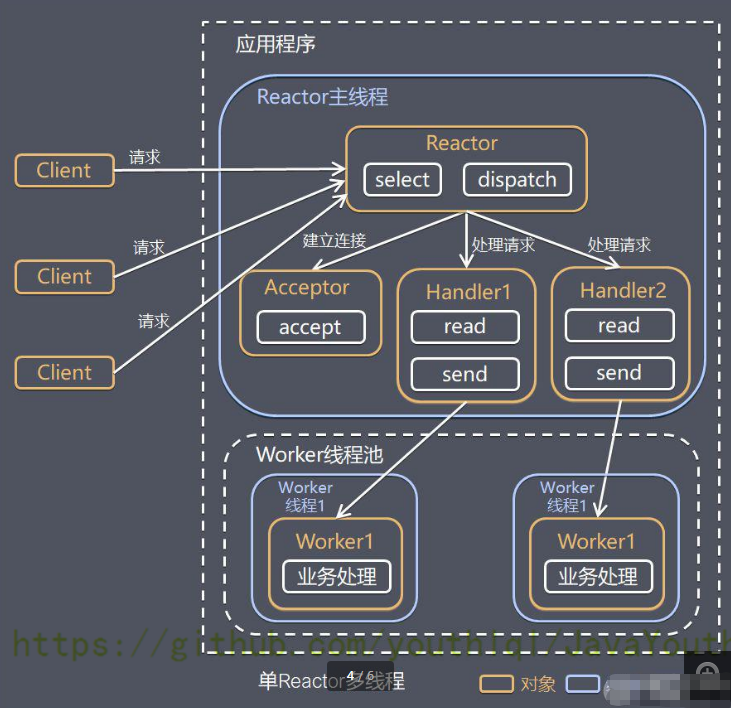 @@ -178,11 +178,11 @@ Netty is an asynchronous event-driven network application framework for rapid de
针对单 `Reactor` 多线程模型中,`Reactor` 在单线程中运行,高并发场景下容易成为性能瓶颈,可以让 `Reactor` 在多线程中运行
-
@@ -178,11 +178,11 @@ Netty is an asynchronous event-driven network application framework for rapid de
针对单 `Reactor` 多线程模型中,`Reactor` 在单线程中运行,高并发场景下容易成为性能瓶颈,可以让 `Reactor` 在多线程中运行
- +
+ -
- +
+ > SubReactor是可以有多个的,如果只有一个SubReactor的话那和`单 Reactor 多线程`就没什么区别了。
@@ -197,7 +197,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
### Scalable IO in Java 对 Multiple Reactors 的原理图解
-
> SubReactor是可以有多个的,如果只有一个SubReactor的话那和`单 Reactor 多线程`就没什么区别了。
@@ -197,7 +197,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
### Scalable IO in Java 对 Multiple Reactors 的原理图解
- +
+ ### 方案优缺点说明
@@ -230,7 +230,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
`Netty` 主要基于主从 `Reactors` 多线程模型(如图)做了一定的改进,其中主从 `Reactor` 多线程模型有多个 `Reactor`
-
### 方案优缺点说明
@@ -230,7 +230,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
`Netty` 主要基于主从 `Reactors` 多线程模型(如图)做了一定的改进,其中主从 `Reactor` 多线程模型有多个 `Reactor`
- +
+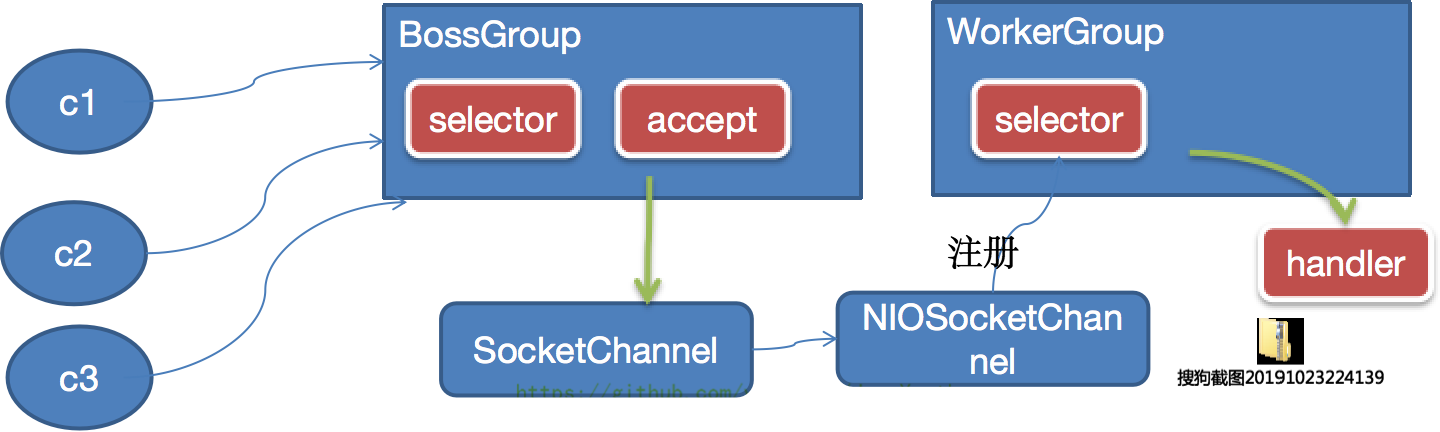 **对上图说明**
@@ -240,7 +240,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
### 工作原理示意图2 - 进阶版
-
**对上图说明**
@@ -240,7 +240,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
### 工作原理示意图2 - 进阶版
- +
+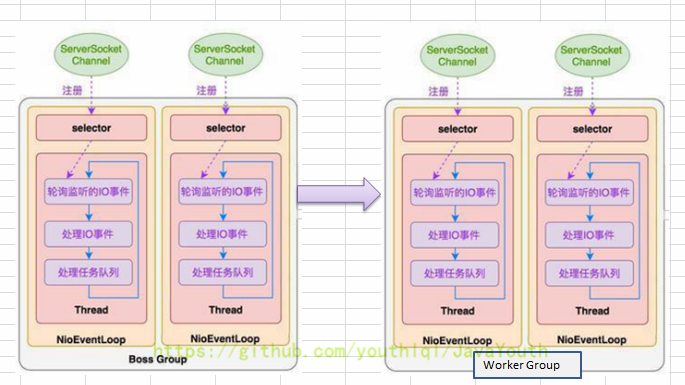 @@ -248,7 +248,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
### 工作原理示意图3 - 详细版
-
@@ -248,7 +248,7 @@ Netty is an asynchronous event-driven network application framework for rapid de
### 工作原理示意图3 - 详细版
- +
+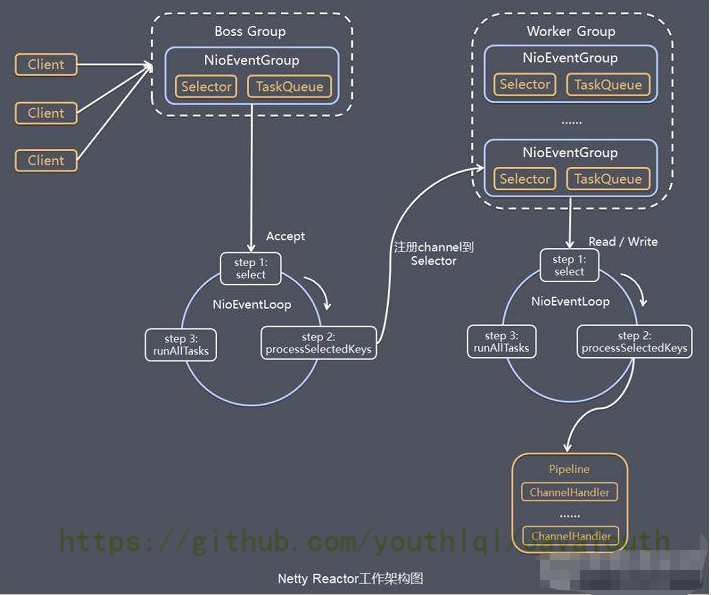 @@ -669,9 +669,9 @@ public class NettyServerHandler extends ChannelInboundHandlerAdapter {
下面第一张图就是管道,中间会经过多个handler
-
@@ -669,9 +669,9 @@ public class NettyServerHandler extends ChannelInboundHandlerAdapter {
下面第一张图就是管道,中间会经过多个handler
- +
+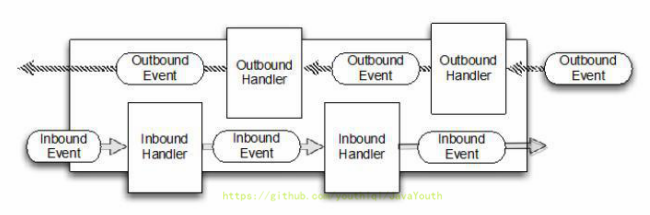 -
- +
+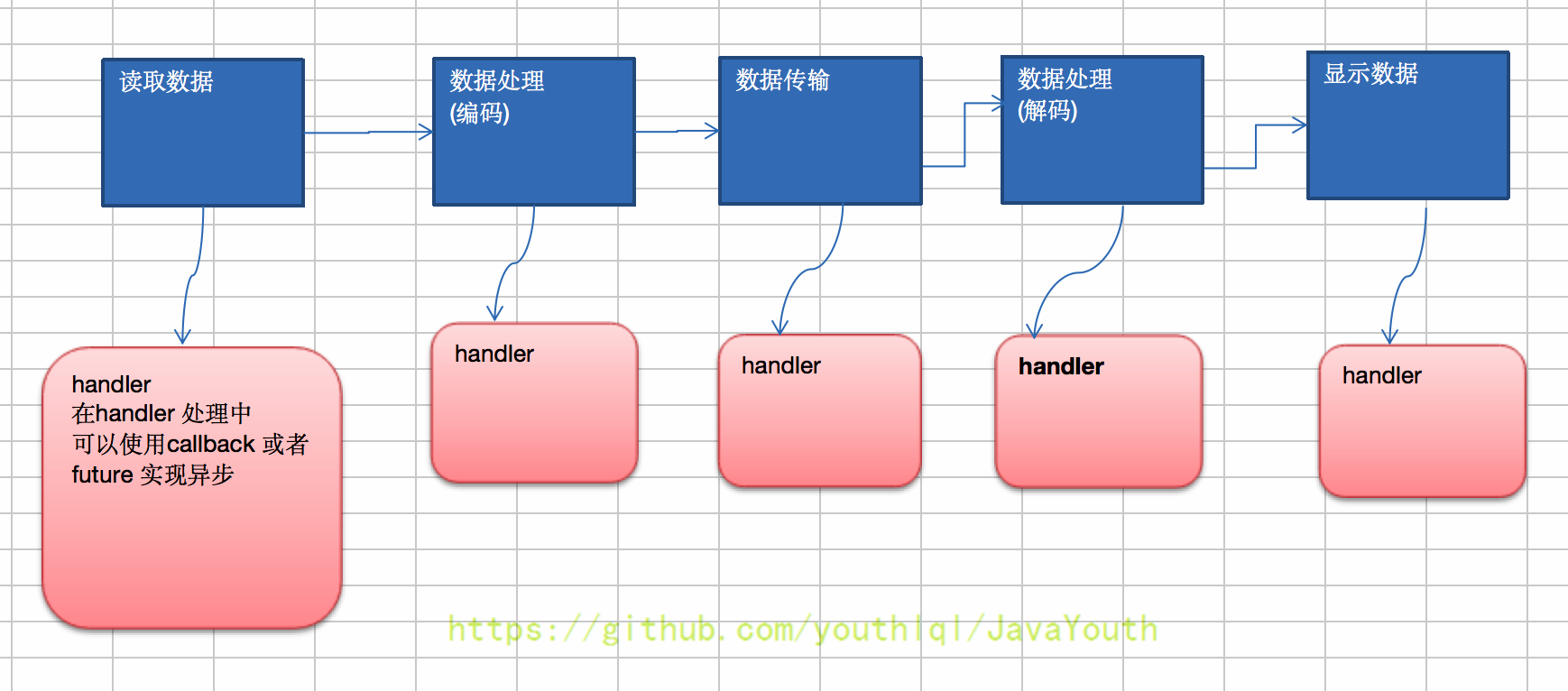 说明:
@@ -917,11 +917,11 @@ public class TestHttpServerHandler extends SimpleChannelInboundHandler
+
说明:
@@ -917,11 +917,11 @@ public class TestHttpServerHandler extends SimpleChannelInboundHandler
+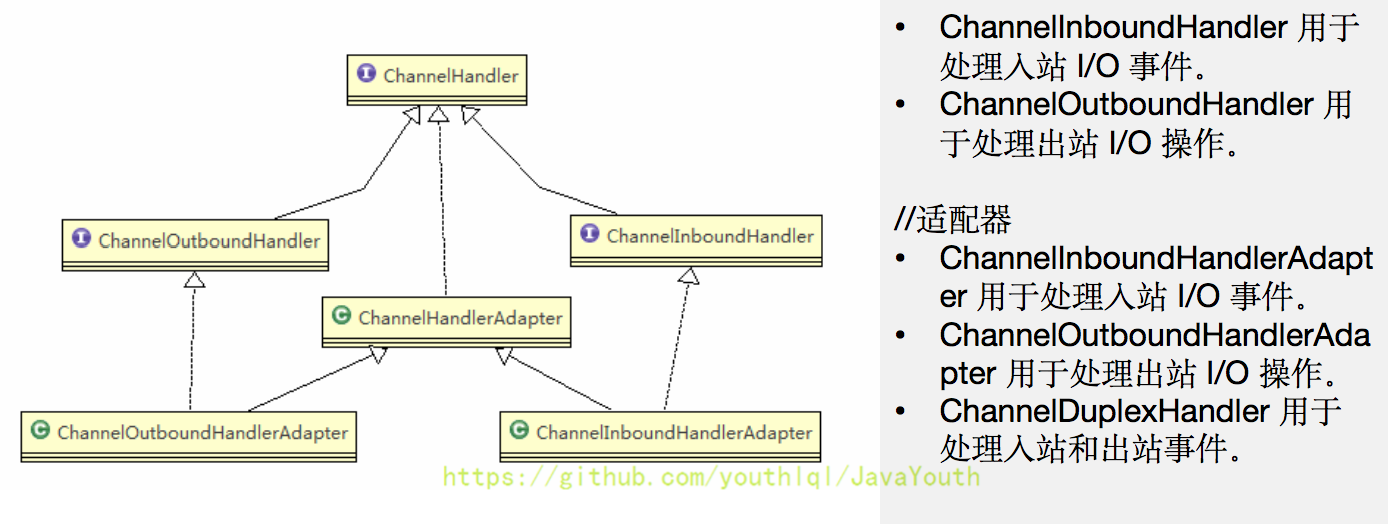 4. 我们经常需要自定义一个 `Handler` 类去继承 `ChannelInboundHandlerAdapter`,然后通过重写相应方法实现业务逻辑,我们接下来看看一般都需要重写哪些方法
-
4. 我们经常需要自定义一个 `Handler` 类去继承 `ChannelInboundHandlerAdapter`,然后通过重写相应方法实现业务逻辑,我们接下来看看一般都需要重写哪些方法
- +
+ ## Pipeline 和 ChannelPipeline
@@ -931,7 +931,7 @@ public class TestHttpServerHandler extends SimpleChannelInboundHandler
+
## Pipeline 和 ChannelPipeline
@@ -931,7 +931,7 @@ public class TestHttpServerHandler extends SimpleChannelInboundHandler
+ 4. 常用方法
`ChannelPipeline addFirst(ChannelHandler... handlers)`,把一个业务处理类(`handler`)添加到链中的第一个位置`ChannelPipeline addLast(ChannelHandler... handlers)`,把一个业务处理类(`handler`)添加到链中的最后一个位置
@@ -940,7 +940,7 @@ public class TestHttpServerHandler extends SimpleChannelInboundHandler
+
4. 常用方法
`ChannelPipeline addFirst(ChannelHandler... handlers)`,把一个业务处理类(`handler`)添加到链中的第一个位置`ChannelPipeline addLast(ChannelHandler... handlers)`,把一个业务处理类(`handler`)添加到链中的最后一个位置
@@ -940,7 +940,7 @@ public class TestHttpServerHandler extends SimpleChannelInboundHandler
+ - `TestServerInitializer`和`HttpServerCodec`这些东西本身也是`handler`
- 一般来说事件从客户端往服务器走我们称为出站,反之则是入站。
@@ -950,7 +950,7 @@ public class TestHttpServerHandler extends SimpleChannelInboundHandler
+
- `TestServerInitializer`和`HttpServerCodec`这些东西本身也是`handler`
- 一般来说事件从客户端往服务器走我们称为出站,反之则是入站。
@@ -950,7 +950,7 @@ public class TestHttpServerHandler extends SimpleChannelInboundHandler
+ 3. 常用方法
@@ -959,14 +959,14 @@ public class TestHttpServerHandler extends SimpleChannelInboundHandler
+
3. 常用方法
@@ -959,14 +959,14 @@ public class TestHttpServerHandler extends SimpleChannelInboundHandler
+ ## ChannelOption
1. `Netty` 在创建 `Channel` 实例后,一般都需要设置 `ChannelOption` 参数。
2. `ChannelOption` 参数如下:
-
## ChannelOption
1. `Netty` 在创建 `Channel` 实例后,一般都需要设置 `ChannelOption` 参数。
2. `ChannelOption` 参数如下:
- +
+ ## EventLoopGroup 和其实现类 NioEventLoopGroup
@@ -974,7 +974,7 @@ public class TestHttpServerHandler extends SimpleChannelInboundHandler
+
## EventLoopGroup 和其实现类 NioEventLoopGroup
@@ -974,7 +974,7 @@ public class TestHttpServerHandler extends SimpleChannelInboundHandler
+ 4. 常用方法
`public NioEventLoopGroup()`,构造方法
@@ -985,11 +985,11 @@ public class TestHttpServerHandler extends SimpleChannelInboundHandler
+
4. 常用方法
`public NioEventLoopGroup()`,构造方法
@@ -985,11 +985,11 @@ public class TestHttpServerHandler extends SimpleChannelInboundHandler
+ 3. 举例说明 `Unpooled` 获取 `Netty` 的数据容器 `ByteBuf` 的基本使用
-
3. 举例说明 `Unpooled` 获取 `Netty` 的数据容器 `ByteBuf` 的基本使用
- +
+ 案例 1
@@ -1096,7 +1096,7 @@ public class NettyByteBuf02 {
-
案例 1
@@ -1096,7 +1096,7 @@ public class NettyByteBuf02 {
- +
+ 代码如下:
@@ -1523,7 +1523,7 @@ public class MyServerHandler extends ChannelInboundHandlerAdapter {
4. 客户端浏览器和服务器端会相互感知,比如服务器关闭了,浏览器会感知,同样浏览器关闭了,服务器会感知
5. 运行界面
-
代码如下:
@@ -1523,7 +1523,7 @@ public class MyServerHandler extends ChannelInboundHandlerAdapter {
4. 客户端浏览器和服务器端会相互感知,比如服务器关闭了,浏览器会感知,同样浏览器关闭了,服务器会感知
5. 运行界面
- +
+ @@ -1724,7 +1724,7 @@ public class MyTextWebSocketFrameHandler extends SimpleChannelInboundHandler
+
@@ -1724,7 +1724,7 @@ public class MyTextWebSocketFrameHandler extends SimpleChannelInboundHandler
+ diff --git a/docs/os/操作系统-IO与零拷贝.md b/docs/os/操作系统-IO与零拷贝.md
index ff66dac..1211710 100644
--- a/docs/os/操作系统-IO与零拷贝.md
+++ b/docs/os/操作系统-IO与零拷贝.md
@@ -47,7 +47,7 @@ date: 2021-04-08 15:21:58
3. 而在用户进程这边,整 个进程会被阻塞。当**内核**一直等到数据准备好了,它就会将数据从**内核**中拷贝到用户内存,然后**内核**返回果,用户进程才解除 block的状态,重新运行起来。
4. **所以,blocking IO的特点就是在IO执行的两个阶段都被block了。**
-
diff --git a/docs/os/操作系统-IO与零拷贝.md b/docs/os/操作系统-IO与零拷贝.md
index ff66dac..1211710 100644
--- a/docs/os/操作系统-IO与零拷贝.md
+++ b/docs/os/操作系统-IO与零拷贝.md
@@ -47,7 +47,7 @@ date: 2021-04-08 15:21:58
3. 而在用户进程这边,整 个进程会被阻塞。当**内核**一直等到数据准备好了,它就会将数据从**内核**中拷贝到用户内存,然后**内核**返回果,用户进程才解除 block的状态,重新运行起来。
4. **所以,blocking IO的特点就是在IO执行的两个阶段都被block了。**
- +
+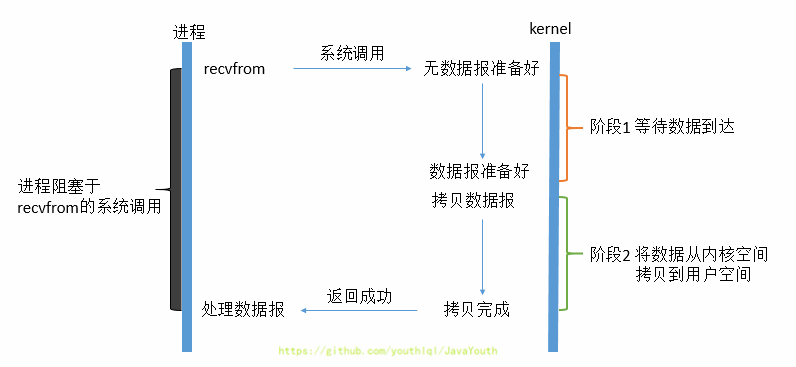 @@ -58,7 +58,7 @@ date: 2021-04-08 15:21:58
3. 虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
4. **所以,用户进程第一个阶段不是阻塞的,需要不断的主动询问内核数据好了没有;第二个阶段依然总是阻塞的。**
-
@@ -58,7 +58,7 @@ date: 2021-04-08 15:21:58
3. 虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
4. **所以,用户进程第一个阶段不是阻塞的,需要不断的主动询问内核数据好了没有;第二个阶段依然总是阻塞的。**
- +
+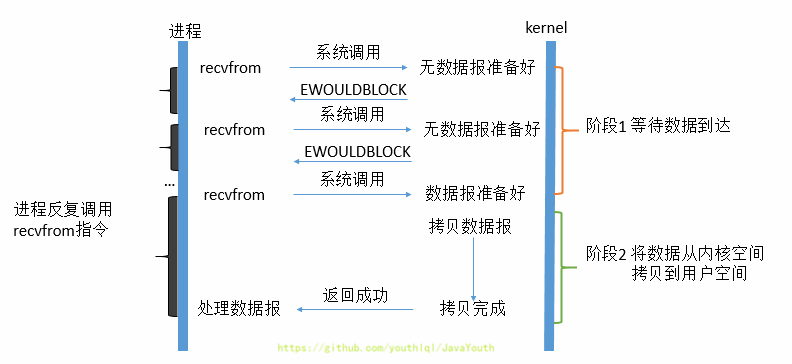 @@ -76,7 +76,7 @@ date: 2021-04-08 15:21:58
2. 它的基本原理就是select /epoll这个函数会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程,正式发起read请求。
3. 从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket(也就是数据准备好了的socket),即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
-
@@ -76,7 +76,7 @@ date: 2021-04-08 15:21:58
2. 它的基本原理就是select /epoll这个函数会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程,正式发起read请求。
3. 从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket(也就是数据准备好了的socket),即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
- +
+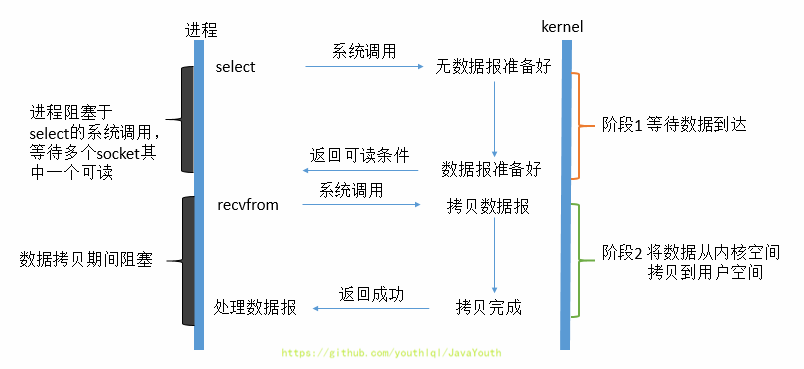 **select函数**
@@ -90,7 +90,7 @@ date: 2021-04-08 15:21:58
4. 通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时(就是数据准备好的时候),则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。
5. 由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。(一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。)
-
**select函数**
@@ -90,7 +90,7 @@ date: 2021-04-08 15:21:58
4. 通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时(就是数据准备好的时候),则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。
5. 由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。(一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。)
- +
+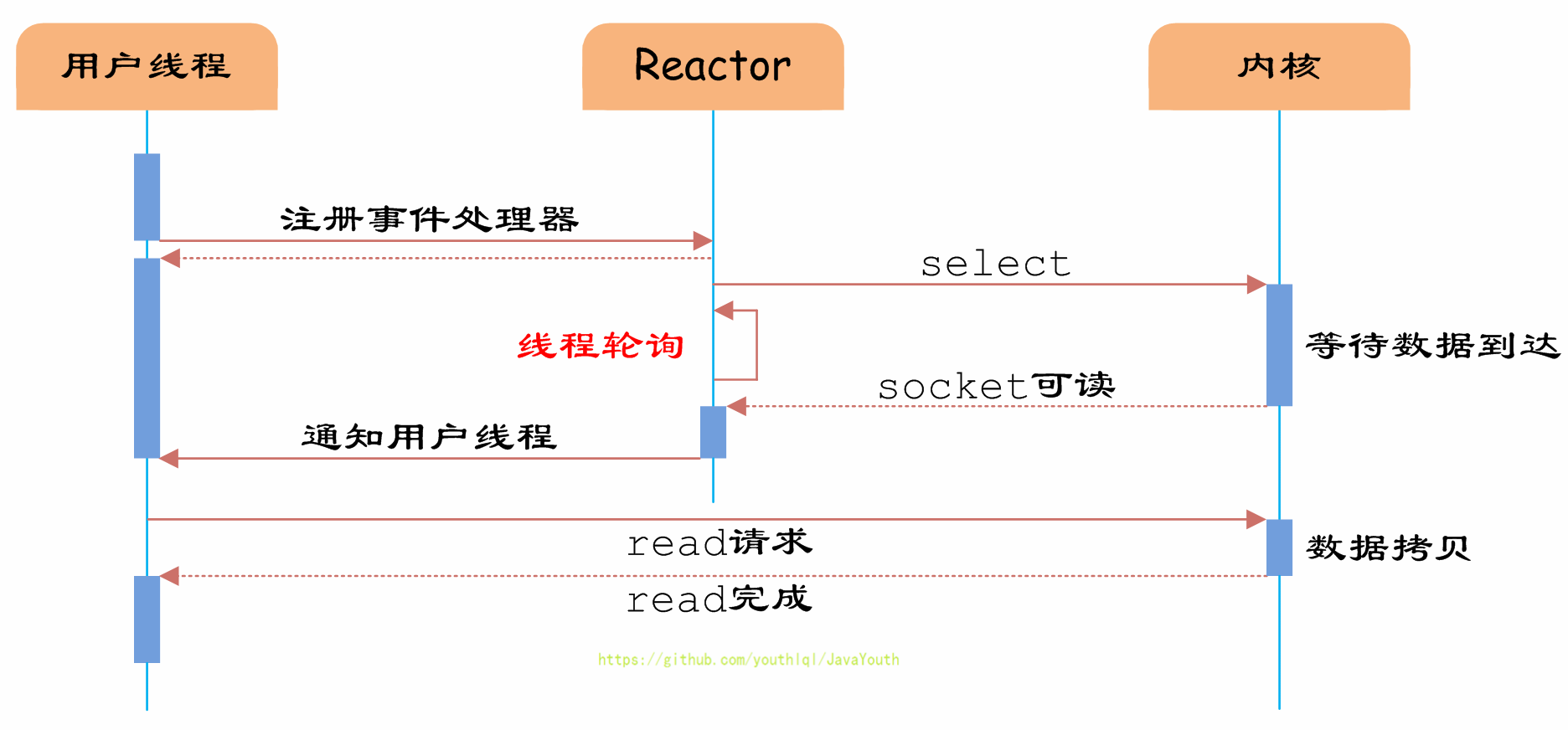 @@ -106,7 +106,7 @@ date: 2021-04-08 15:21:58
3. 而另一方面,从**内核**的角度,当它受到一个异步读之后,首先它会立刻返回,所以不会对用户进程产生任何阻塞。然后,内核会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都 完成之后,**内核**会给用户进程发送一个信号,告诉它read操作完成了,用户线程直接使用即可。 在这整个过程中,进程完全没有被阻塞。
4. 异步IO模型使用了Proactor设计模式实现了这一机制。**(具体怎么搞得,看上面的文章链接)**
-
@@ -106,7 +106,7 @@ date: 2021-04-08 15:21:58
3. 而另一方面,从**内核**的角度,当它受到一个异步读之后,首先它会立刻返回,所以不会对用户进程产生任何阻塞。然后,内核会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都 完成之后,**内核**会给用户进程发送一个信号,告诉它read操作完成了,用户线程直接使用即可。 在这整个过程中,进程完全没有被阻塞。
4. 异步IO模型使用了Proactor设计模式实现了这一机制。**(具体怎么搞得,看上面的文章链接)**
- +
+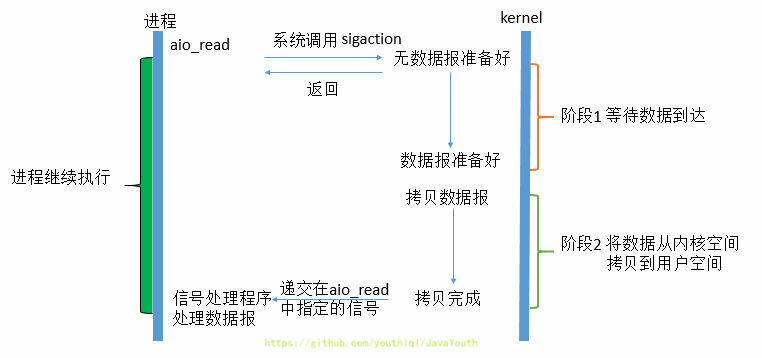 @@ -196,7 +196,7 @@ date: 2021-04-08 15:21:58
1. 来看一个标准设备(不是真实存在的,相当于一个逻辑上抽象的东西),通过它来帮助我们更好地理解设备交互的机制。可以看到一个包含两部分重要组件的设备。第一部分是向系统其他部分展现的硬件接口(interface)。同软件一样,硬件也需要一些接口,让系统软件来控制它的操作。因此,所有设备都有自己的特定接口以及典型交互的协议。
-
@@ -196,7 +196,7 @@ date: 2021-04-08 15:21:58
1. 来看一个标准设备(不是真实存在的,相当于一个逻辑上抽象的东西),通过它来帮助我们更好地理解设备交互的机制。可以看到一个包含两部分重要组件的设备。第一部分是向系统其他部分展现的硬件接口(interface)。同软件一样,硬件也需要一些接口,让系统软件来控制它的操作。因此,所有设备都有自己的特定接口以及典型交互的协议。
- +
+ 2. 第2部分是它的内部结构(internal structure)。这部分包含设备相关的特定实现,负责具体实现设备展示给系统的抽象接口。
@@ -231,11 +231,11 @@ While (STATUS == BUSY);//wait until device is done with your request
1. 没有中断时:进程1在CPU上运行一段时间(对应CPU那一行上重复的1),然后发出一个读取数据的I/O请求给磁盘。如果没有中断,那么操作系统就会简单自旋,不断轮询设备状态,直到设备完成I/O操作(对应其中的p)。当设备完成请求的操作后,进程1又可以继续运行。
-
2. 第2部分是它的内部结构(internal structure)。这部分包含设备相关的特定实现,负责具体实现设备展示给系统的抽象接口。
@@ -231,11 +231,11 @@ While (STATUS == BUSY);//wait until device is done with your request
1. 没有中断时:进程1在CPU上运行一段时间(对应CPU那一行上重复的1),然后发出一个读取数据的I/O请求给磁盘。如果没有中断,那么操作系统就会简单自旋,不断轮询设备状态,直到设备完成I/O操作(对应其中的p)。当设备完成请求的操作后,进程1又可以继续运行。
- +
+ 2. 有了中断后:中断允许计算与I/O重叠(overlap),这是提高CPU利用率的关键。我们利用中断并允许重叠,操作系统就可以在等待磁盘操作时做其他事情。
-
2. 有了中断后:中断允许计算与I/O重叠(overlap),这是提高CPU利用率的关键。我们利用中断并允许重叠,操作系统就可以在等待磁盘操作时做其他事情。
-  +
+  - 在这个例子中,在磁盘处理进程1的请求时,操作系统在CPU上运行进程2。磁盘处理完成后,触发一个中断,然后操作系统唤醒进程1继续运行。这样,在这段时间,无论CPU还是磁盘都可以有效地利用。
@@ -243,7 +243,7 @@ While (STATUS == BUSY);//wait until device is done with your request
中断仍旧存在的缺点:
-
- 在这个例子中,在磁盘处理进程1的请求时,操作系统在CPU上运行进程2。磁盘处理完成后,触发一个中断,然后操作系统唤醒进程1继续运行。这样,在这段时间,无论CPU还是磁盘都可以有效地利用。
@@ -243,7 +243,7 @@ While (STATUS == BUSY);//wait until device is done with your request
中断仍旧存在的缺点:
- +
+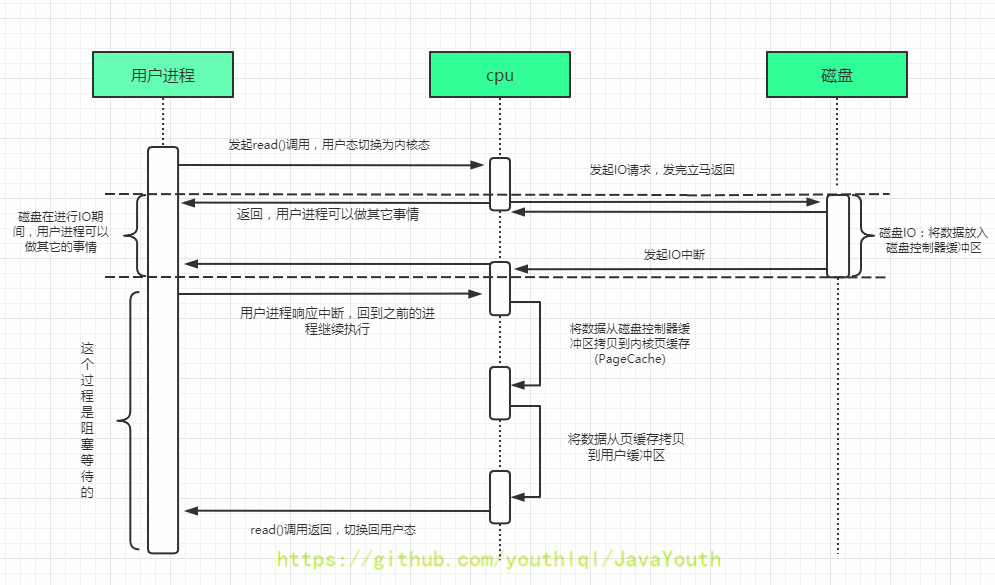 IO过程简述:
@@ -268,7 +268,7 @@ IO过程简述:
>
> 标准协议还有一点需要我们注意。具体来说,如果使用编程的I/O将一大块数据传给设备,CPU又会因为琐碎的任务而变得负载很重,浪费了时间和算力,本来更好是用于运行其他进程。下面的时间线展示了这个问题:
>
->
IO过程简述:
@@ -268,7 +268,7 @@ IO过程简述:
>
> 标准协议还有一点需要我们注意。具体来说,如果使用编程的I/O将一大块数据传给设备,CPU又会因为琐碎的任务而变得负载很重,浪费了时间和算力,本来更好是用于运行其他进程。下面的时间线展示了这个问题:
>
->  +>
+>  >
> 进程1在运行过程中需要向磁盘写一些数据,所以它开始进行I/O操作,将数据从内存拷贝到磁盘(其中标示c的过程)。**拷贝结束后,磁盘上的I/O操作开始执行,此时CPU才可以处理其他请求。**
@@ -278,13 +278,13 @@ IO过程简述:
>
> DMA工作过程如下。为了能够将数据传送给设备,操作系统会通过编程告诉DMA引擎数据在内存的位置,要拷贝的大小以及要拷贝到哪个设备。在此之后,操作系统就可以处理其他请求了。当DMA的任务完成后,DMA控制器会抛出一个中断来告诉操作系统自己已经完成数据传输。修改后的时间线如下:
>
->
>
> 进程1在运行过程中需要向磁盘写一些数据,所以它开始进行I/O操作,将数据从内存拷贝到磁盘(其中标示c的过程)。**拷贝结束后,磁盘上的I/O操作开始执行,此时CPU才可以处理其他请求。**
@@ -278,13 +278,13 @@ IO过程简述:
>
> DMA工作过程如下。为了能够将数据传送给设备,操作系统会通过编程告诉DMA引擎数据在内存的位置,要拷贝的大小以及要拷贝到哪个设备。在此之后,操作系统就可以处理其他请求了。当DMA的任务完成后,DMA控制器会抛出一个中断来告诉操作系统自己已经完成数据传输。修改后的时间线如下:
>
->  +>
+> 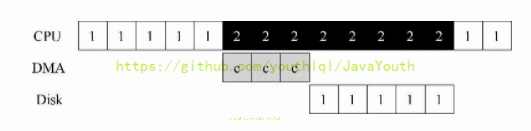 >
> 从时间线中可以看到,数据的拷贝工作都是由DMA控制器来完成的。因为CPU在此时是空闲的,所以操作系统可以让它做一些其他事情,比如此处调度进程2到CPU来运行。因此进程2在进程1再次运行之前可以使用更多的CPU。
为了更好理解,看图:
-
>
> 从时间线中可以看到,数据的拷贝工作都是由DMA控制器来完成的。因为CPU在此时是空闲的,所以操作系统可以让它做一些其他事情,比如此处调度进程2到CPU来运行。因此进程2在进程1再次运行之前可以使用更多的CPU。
为了更好理解,看图:
- +
+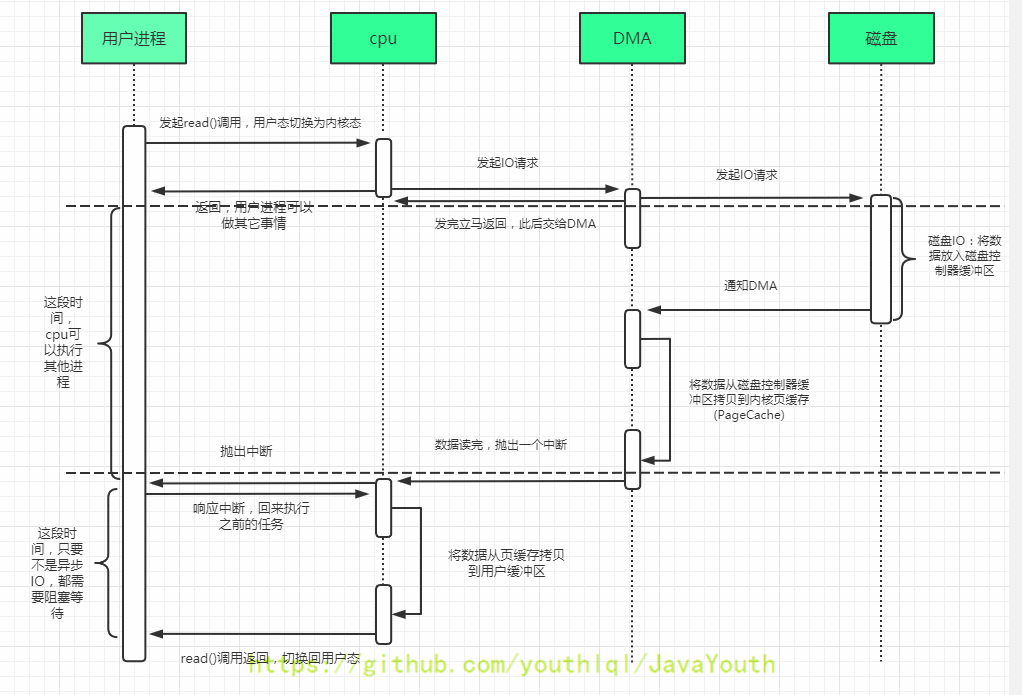 过程:
@@ -302,7 +302,7 @@ IO过程简述:
场景:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。
-
过程:
@@ -302,7 +302,7 @@ IO过程简述:
场景:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。
- +
+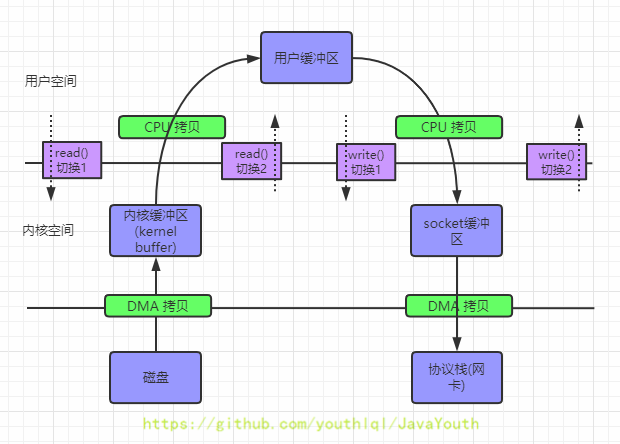 1. 很明显发生了4次拷贝
@@ -326,7 +326,7 @@ IO过程简述:
`read()` 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,为了减少这一步开销,我们可以用 `mmap()` 替换 `read()` 系统调用函数。`mmap()` 系统调用函数会直接把内核缓冲区里的数据映射到用户空间,这样,操作系统内核与用户空间共享缓冲区,就不需要再进行任何的数据拷贝操作。
-
1. 很明显发生了4次拷贝
@@ -326,7 +326,7 @@ IO过程简述:
`read()` 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,为了减少这一步开销,我们可以用 `mmap()` 替换 `read()` 系统调用函数。`mmap()` 系统调用函数会直接把内核缓冲区里的数据映射到用户空间,这样,操作系统内核与用户空间共享缓冲区,就不需要再进行任何的数据拷贝操作。
- +
+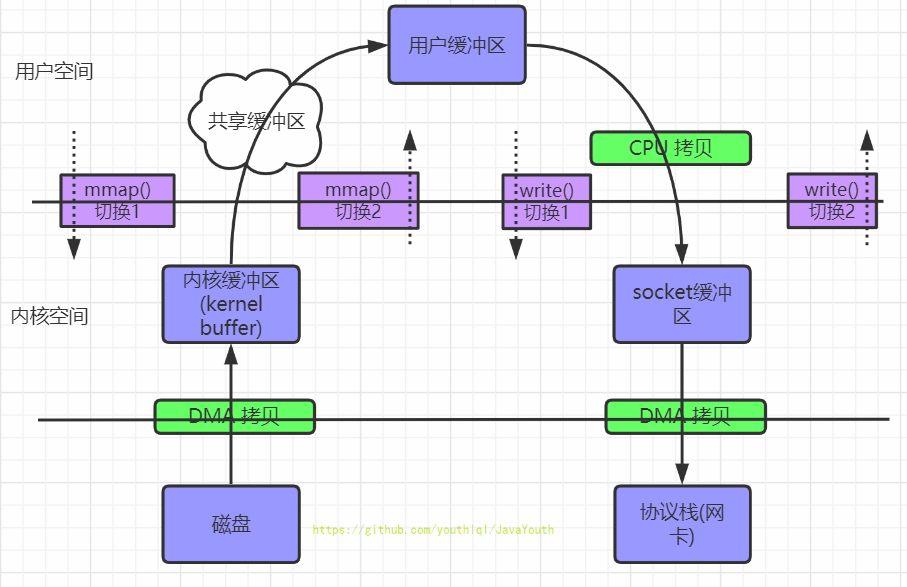 总的来说mmap减少了一次数据拷贝,总共4次上下文切换,3次数据拷贝
@@ -336,7 +336,7 @@ IO过程简述:
`Linux2.1` 版本提供了 `sendFile` 函数,其基本原理如下:数据根本不经过用户态,直接从内核缓冲区进入到 `SocketBuffer`
-
总的来说mmap减少了一次数据拷贝,总共4次上下文切换,3次数据拷贝
@@ -336,7 +336,7 @@ IO过程简述:
`Linux2.1` 版本提供了 `sendFile` 函数,其基本原理如下:数据根本不经过用户态,直接从内核缓冲区进入到 `SocketBuffer`
- +
+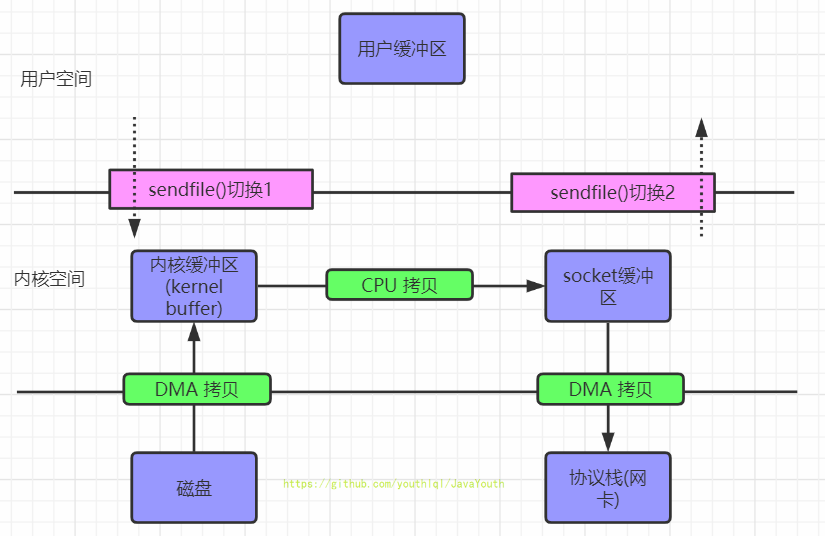 总的来说有2次上下文切换,3次数据拷贝。
@@ -344,7 +344,7 @@ IO过程简述:
`Linux在2.4` 版本中,做了一些修改,避免了从内核缓冲区拷贝到 `Socketbuffer` 的操作,直接拷贝到协议栈,从而再一次减少了数据拷贝
-
总的来说有2次上下文切换,3次数据拷贝。
@@ -344,7 +344,7 @@ IO过程简述:
`Linux在2.4` 版本中,做了一些修改,避免了从内核缓冲区拷贝到 `Socketbuffer` 的操作,直接拷贝到协议栈,从而再一次减少了数据拷贝
- +
+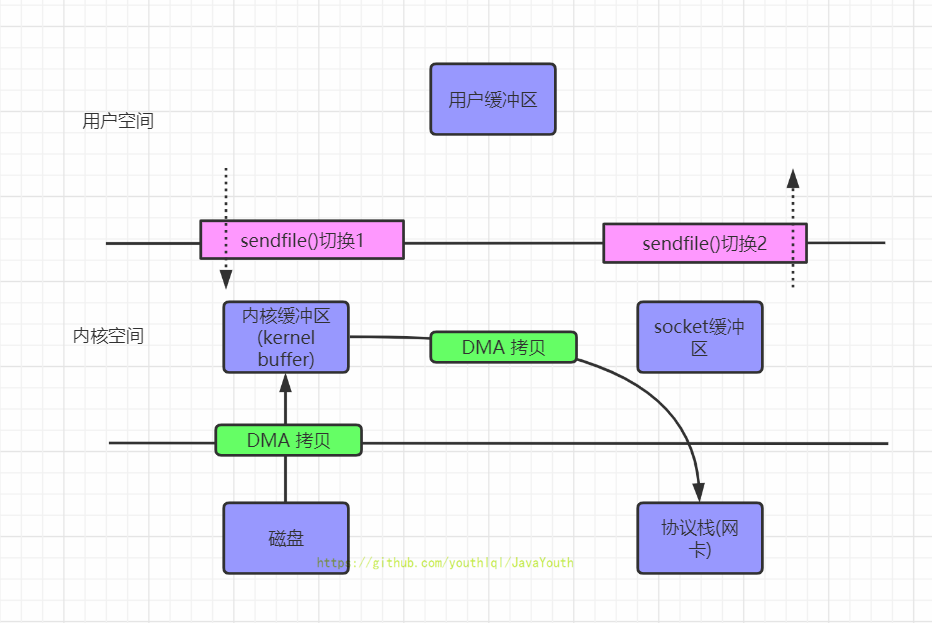 diff --git a/docs/spring-sourcecode-v1/01.第1章-Spring源码纵览.md b/docs/spring-sourcecode-v1/01.第1章-Spring源码纵览.md
index 2cd7105..ab52c4d 100644
--- a/docs/spring-sourcecode-v1/01.第1章-Spring源码纵览.md
+++ b/docs/spring-sourcecode-v1/01.第1章-Spring源码纵览.md
@@ -38,7 +38,7 @@ Spring源码纵览这一节,主要是先了解下Spring的一些核心东西
-
diff --git a/docs/spring-sourcecode-v1/01.第1章-Spring源码纵览.md b/docs/spring-sourcecode-v1/01.第1章-Spring源码纵览.md
index 2cd7105..ab52c4d 100644
--- a/docs/spring-sourcecode-v1/01.第1章-Spring源码纵览.md
+++ b/docs/spring-sourcecode-v1/01.第1章-Spring源码纵览.md
@@ -38,7 +38,7 @@ Spring源码纵览这一节,主要是先了解下Spring的一些核心东西
- +
+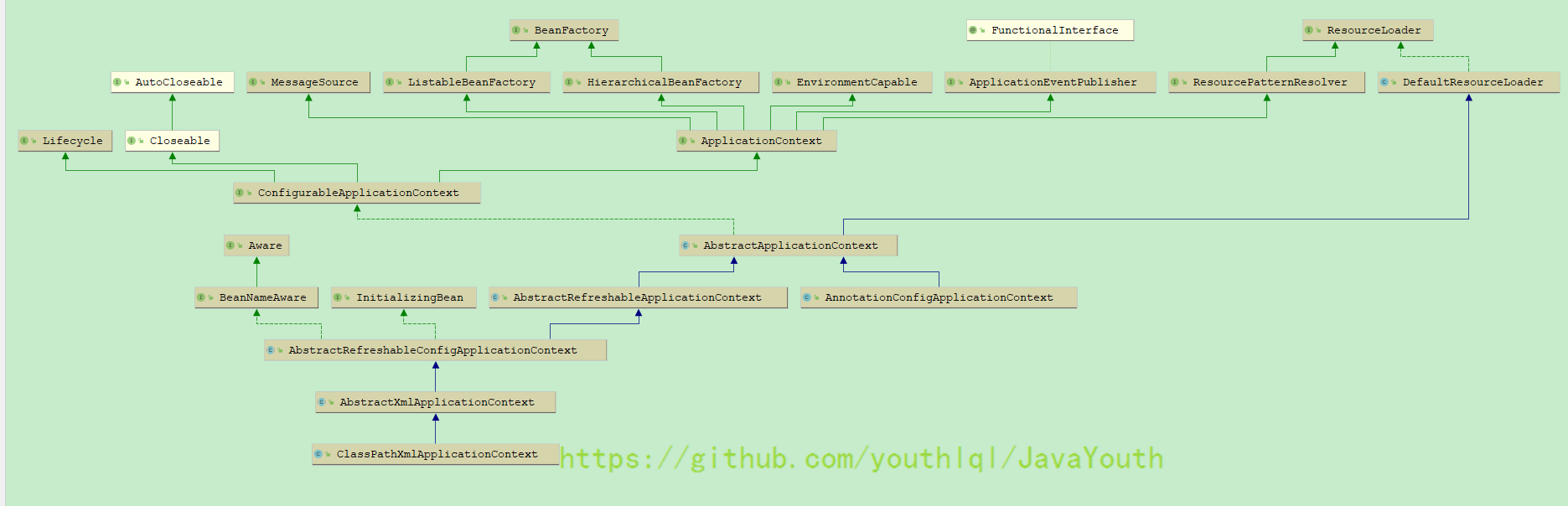 - **蓝色实线箭头**是指继承关系
- **绿色虚线箭头**是指接口实现关系
@@ -91,13 +91,13 @@ BeanPostProcessor
快捷键:ctrl+F12 看类的方法
-
- **蓝色实线箭头**是指继承关系
- **绿色虚线箭头**是指接口实现关系
@@ -91,13 +91,13 @@ BeanPostProcessor
快捷键:ctrl+F12 看类的方法
- +
+ #### 实现类
快捷键:ctrl+h 查看接口实现类
-
#### 实现类
快捷键:ctrl+h 查看接口实现类
- +
+ @@ -189,7 +189,7 @@ public interface ResourceLoader {
#### 实现类
-
@@ -189,7 +189,7 @@ public interface ResourceLoader {
#### 实现类
- +
+ @@ -232,7 +232,7 @@ public interface BeanFactory {
> 源码分析小技巧:看源码时,我们可以先看一个类的接口继承关系,因为接口就是规范,大部分开源框架源码都是遵守这一规范的。
-
@@ -232,7 +232,7 @@ public interface BeanFactory {
> 源码分析小技巧:看源码时,我们可以先看一个类的接口继承关系,因为接口就是规范,大部分开源框架源码都是遵守这一规范的。
- +
+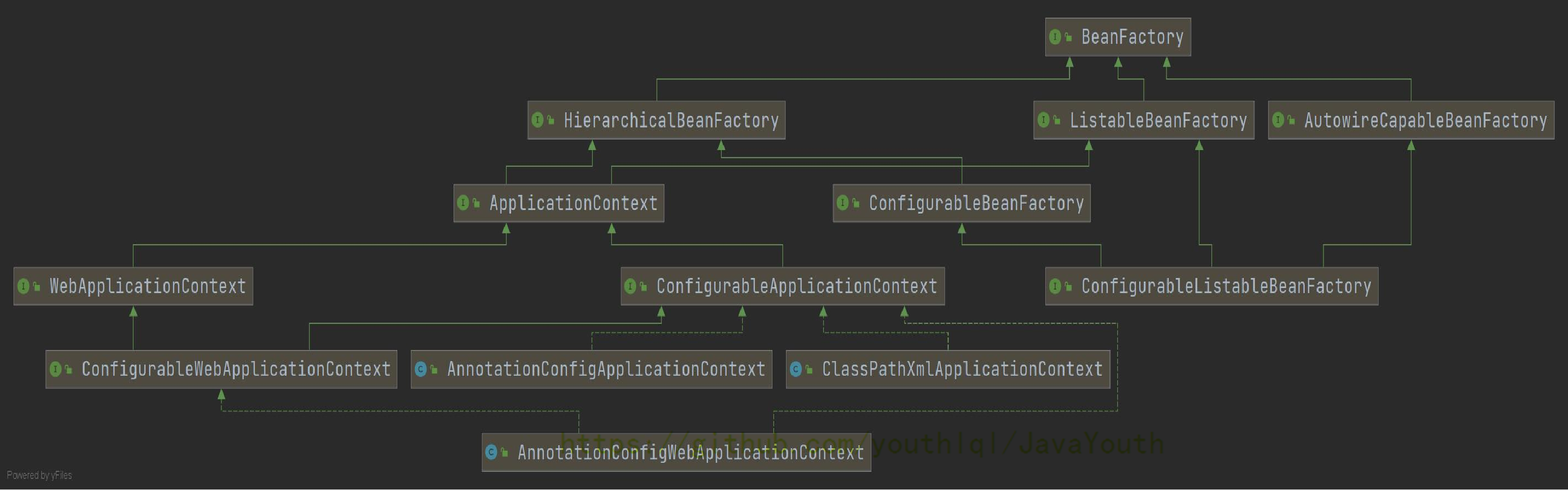 @@ -248,7 +248,7 @@ public interface BeanFactory {
#### AbstractApplicationContext
-
@@ -248,7 +248,7 @@ public interface BeanFactory {
#### AbstractApplicationContext
- +
+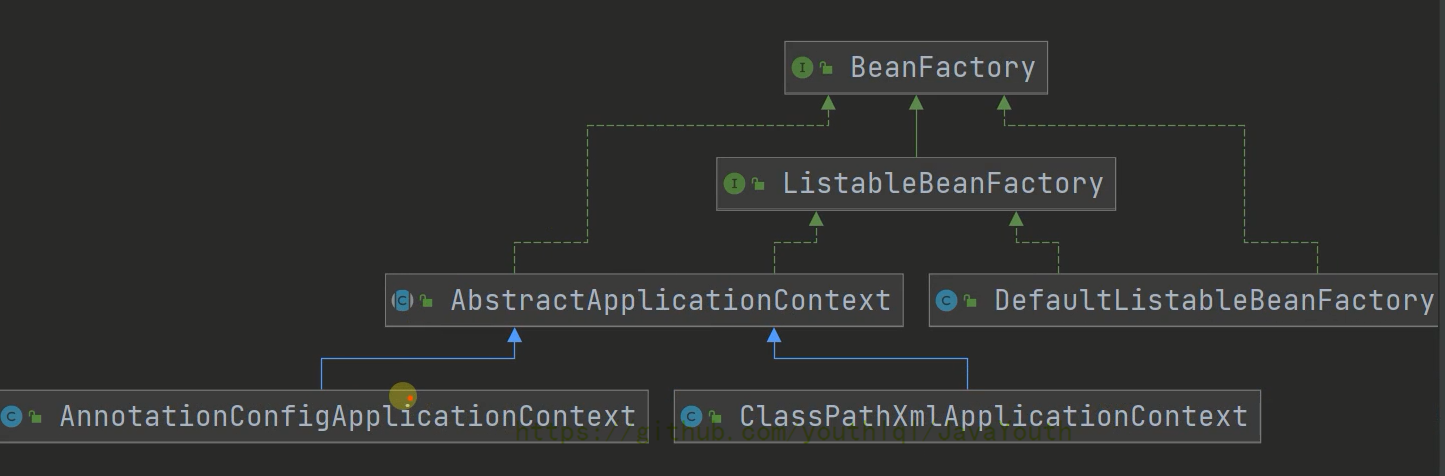 环境类的意思就是谁持有这个策略;这里就解释了上文说ResourceLoader是环境类接口
@@ -265,7 +265,7 @@ public interface BeanFactory {
#### GenericApplicationContext
-
环境类的意思就是谁持有这个策略;这里就解释了上文说ResourceLoader是环境类接口
@@ -265,7 +265,7 @@ public interface BeanFactory {
#### GenericApplicationContext
- +
+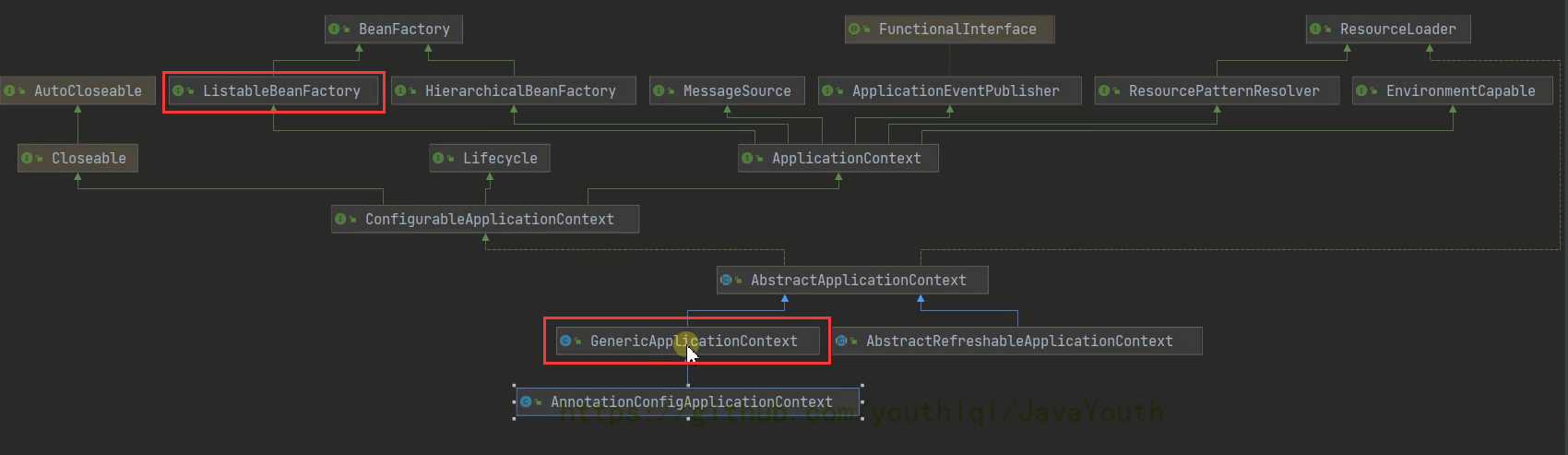 这里组合了DefaultListableBeanFactory
@@ -310,7 +310,7 @@ public class DefaultListableBeanFactory extends AbstractAutowireCapableBeanFacto
-
这里组合了DefaultListableBeanFactory
@@ -310,7 +310,7 @@ public class DefaultListableBeanFactory extends AbstractAutowireCapableBeanFacto
- +
+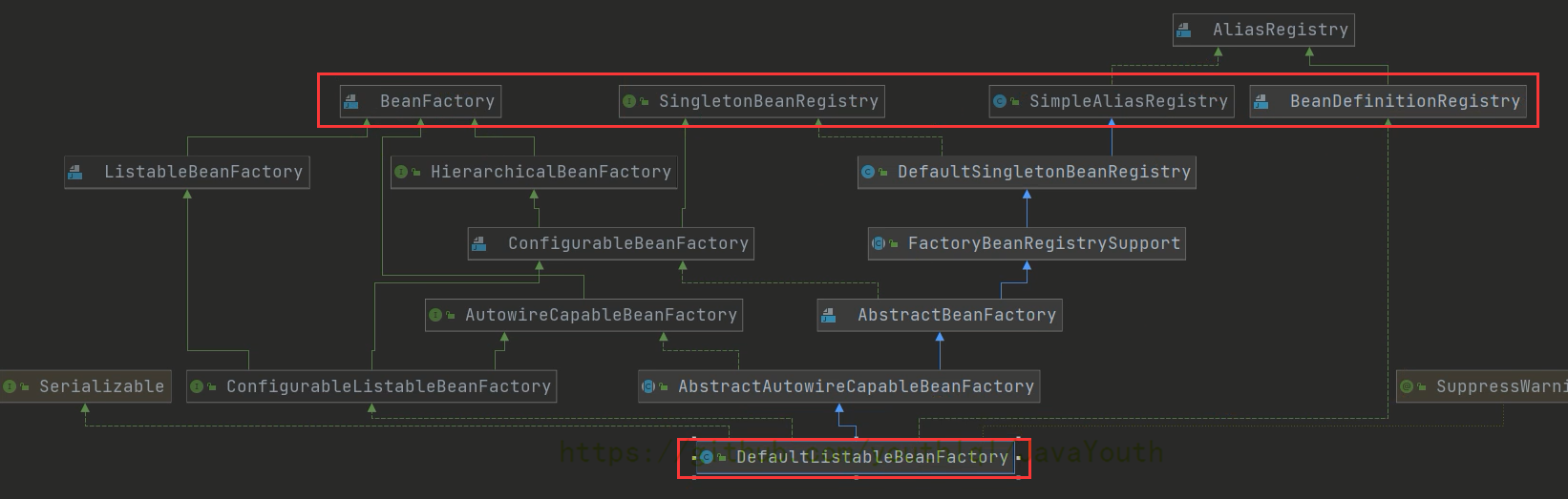 1. BeanDefinitionRegistry:Bean定义信息注册中心
2. SimpleAliasRegistry:别名注册中心
@@ -336,7 +336,7 @@ public class DefaultListableBeanFactory extends AbstractAutowireCapableBeanFacto
#### 流程图-BeanDefinition注册流程
-
1. BeanDefinitionRegistry:Bean定义信息注册中心
2. SimpleAliasRegistry:别名注册中心
@@ -336,7 +336,7 @@ public class DefaultListableBeanFactory extends AbstractAutowireCapableBeanFacto
#### 流程图-BeanDefinition注册流程
- +
+ - 我们要看BeanDefinition是何时被放入到beanDefinitionMap,只需要在DefaultListableBeanFactory用到`beanDefinitionMap.put()`的地方打个断点。
- 我们在DefaultListableBeanFactory里搜索,发现了registerBeanDefinition(注册Bean定义信息)这个方法名很像我们要找的东西,再看里面的代码,果然有`beanDefinitionMap.put()`这串代码,我们试着在这里打个断点
@@ -361,7 +361,7 @@ public class MainTest {
#### Debug调用栈
-
- 我们要看BeanDefinition是何时被放入到beanDefinitionMap,只需要在DefaultListableBeanFactory用到`beanDefinitionMap.put()`的地方打个断点。
- 我们在DefaultListableBeanFactory里搜索,发现了registerBeanDefinition(注册Bean定义信息)这个方法名很像我们要找的东西,再看里面的代码,果然有`beanDefinitionMap.put()`这串代码,我们试着在这里打个断点
@@ -361,7 +361,7 @@ public class MainTest {
#### Debug调用栈
- +
+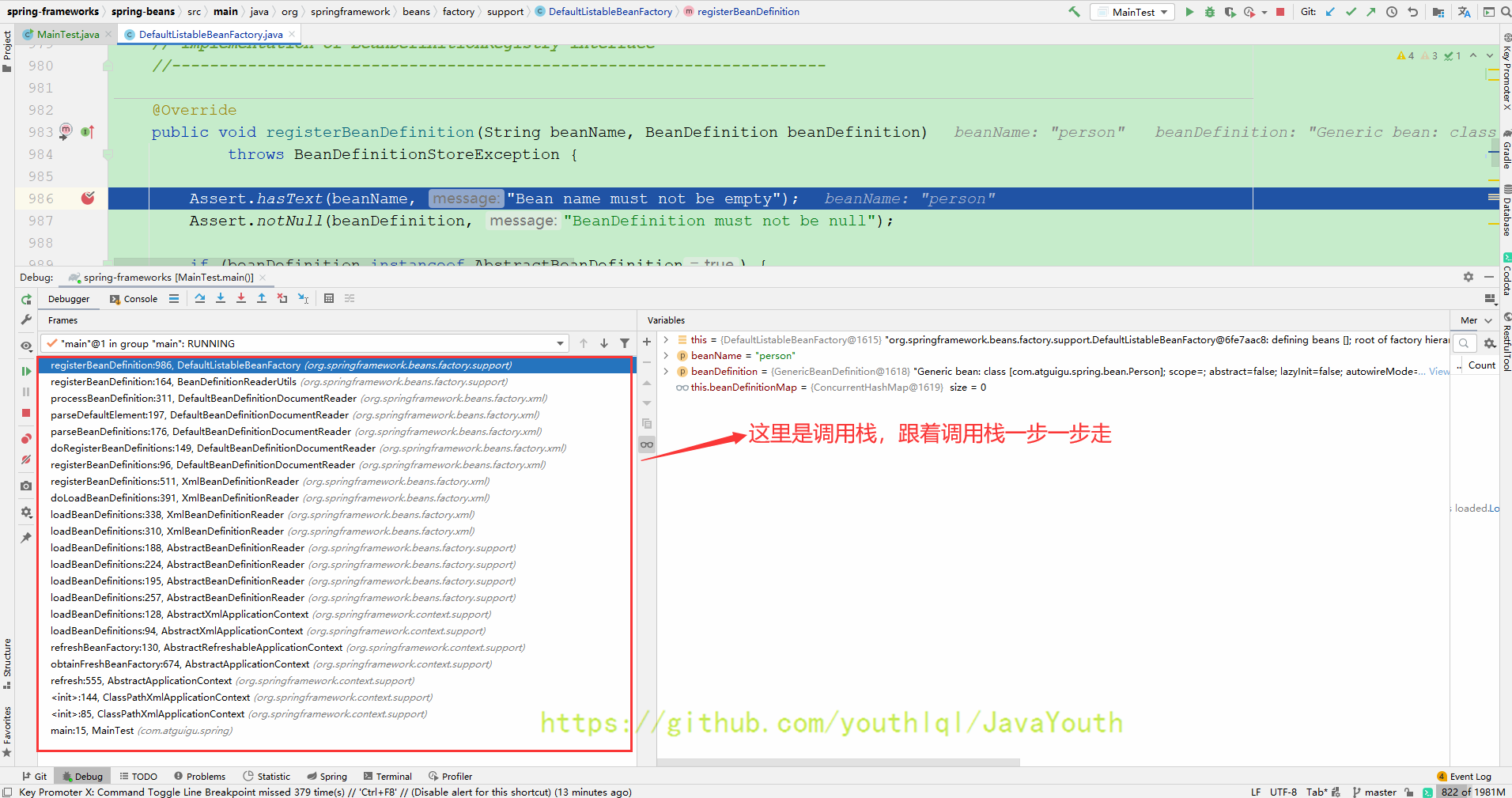 > 调用栈的调用顺序已经非常清楚了,可以把图放大一点看,下面只说一些必要的信息。
@@ -780,7 +780,7 @@ public class MainTest {
- 还有一个debug的猜测方向,想要注册BeanDefinition肯定要new,我们可以直接在AbstractBeanDefinition这个抽象父类的构造函数打断点,我们不知道会走哪个构造函数,所以给三个构造函数都打断点。
- 下面就是打完断点之后,运行MainTest测试类后的调用栈
-
> 调用栈的调用顺序已经非常清楚了,可以把图放大一点看,下面只说一些必要的信息。
@@ -780,7 +780,7 @@ public class MainTest {
- 还有一个debug的猜测方向,想要注册BeanDefinition肯定要new,我们可以直接在AbstractBeanDefinition这个抽象父类的构造函数打断点,我们不知道会走哪个构造函数,所以给三个构造函数都打断点。
- 下面就是打完断点之后,运行MainTest测试类后的调用栈
- +
+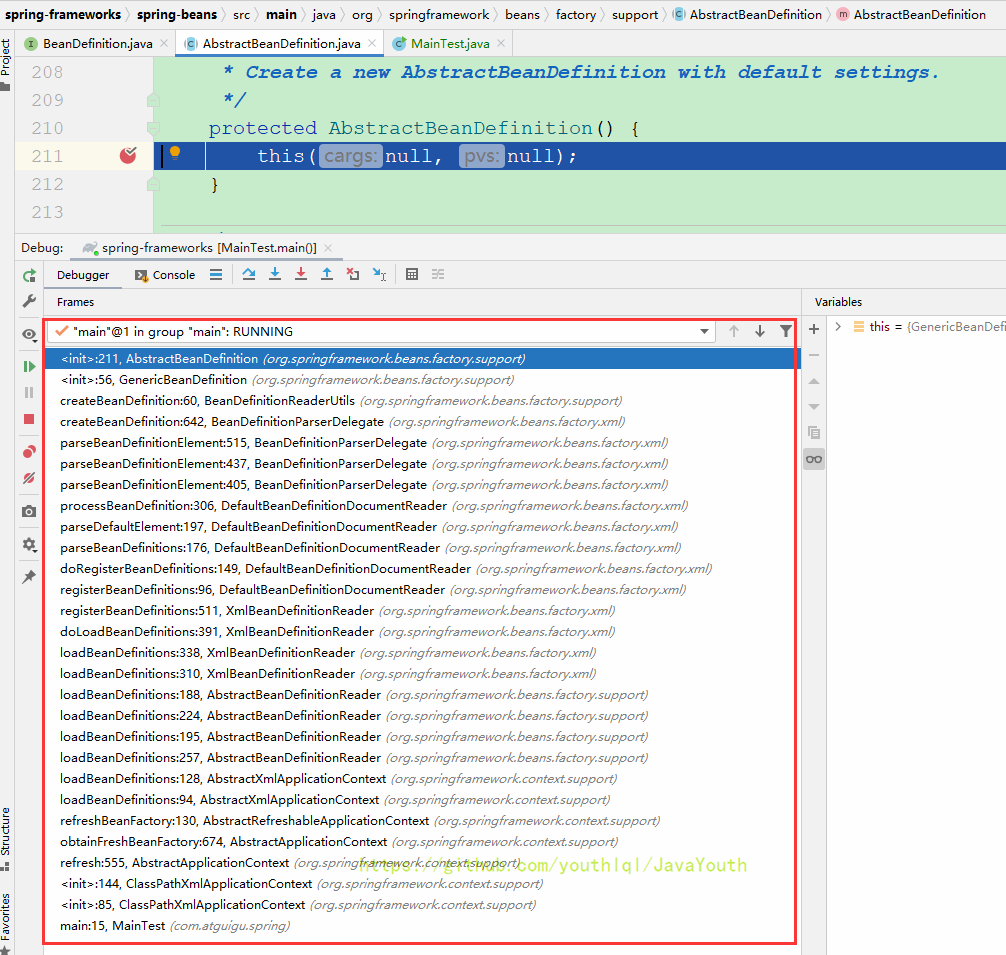 @@ -936,7 +936,7 @@ public class MainTest {
### ApplicationContext接口功能
-
@@ -936,7 +936,7 @@ public class MainTest {
### ApplicationContext接口功能
- +
+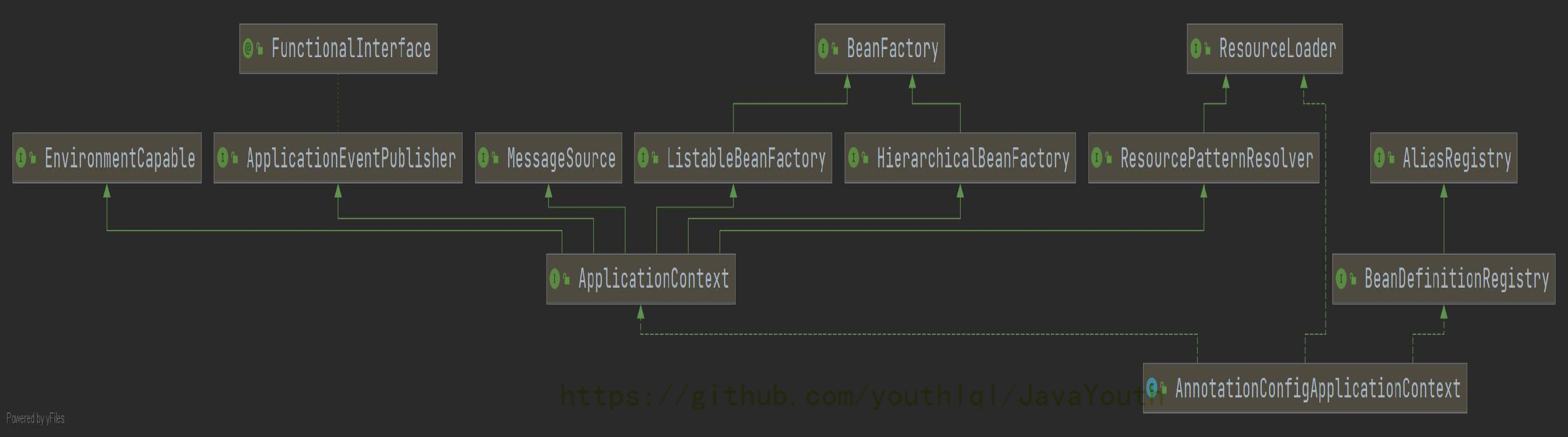 1. ioc事件派发器
2. 国际化解析
@@ -969,7 +969,7 @@ public interface Aware {
2. 注释的大致意思是:Aware是一个标记性的超接口(顶级接口),指示了一个Bean有资格通过回调方法的形式获取Spring容器底层组件。实际回调方法被定义在每一个子接口中,而且通常一个子接口只包含一个接口一个参数并且返回值为void的方法。
3. 说白了:只要实现了Aware子接口的Bean都能获取到一个Spring底层组件。
-
1. ioc事件派发器
2. 国际化解析
@@ -969,7 +969,7 @@ public interface Aware {
2. 注释的大致意思是:Aware是一个标记性的超接口(顶级接口),指示了一个Bean有资格通过回调方法的形式获取Spring容器底层组件。实际回调方法被定义在每一个子接口中,而且通常一个子接口只包含一个接口一个参数并且返回值为void的方法。
3. 说白了:只要实现了Aware子接口的Bean都能获取到一个Spring底层组件。
- +
+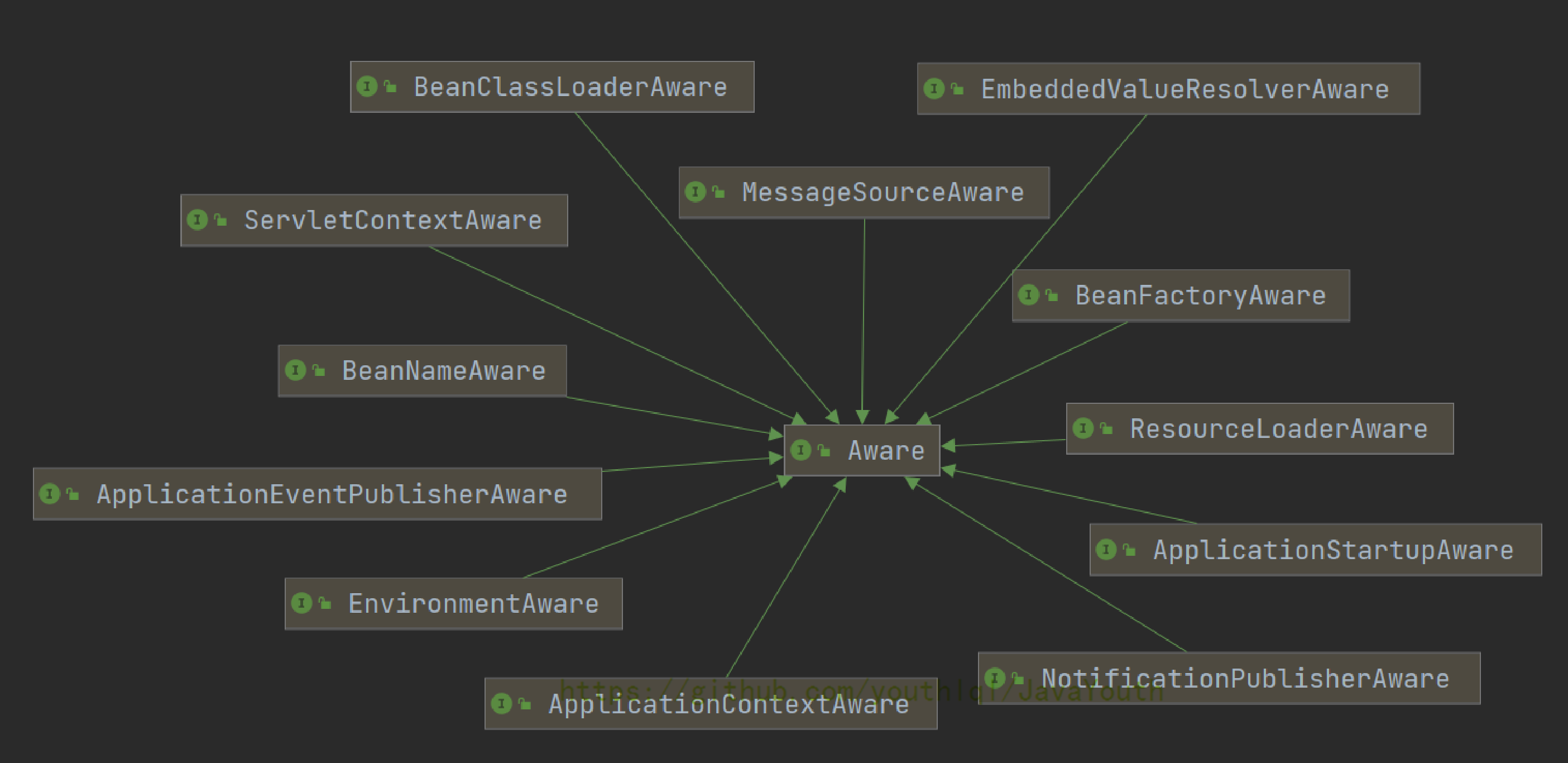 比如实现了ApplicationContextAware接口,实现它的方法,就能通过回调机制拿到ApplicationContext
@@ -979,7 +979,7 @@ public interface Aware {
##### 流程图-Bean对象创建流程
-
比如实现了ApplicationContextAware接口,实现它的方法,就能通过回调机制拿到ApplicationContext
@@ -979,7 +979,7 @@ public interface Aware {
##### 流程图-Bean对象创建流程
- +
+ ##### Debug调用栈
@@ -1055,7 +1055,7 @@ public class MainConfig {
-
##### Debug调用栈
@@ -1055,7 +1055,7 @@ public class MainConfig {
- +
+ 1. 有一些一样的东西不再赘述
2. 在`AbstractApplicationContext#refresh()`里会调用
@@ -1267,7 +1267,7 @@ public class MainConfig {
##### Debug调用栈
-
1. 有一些一样的东西不再赘述
2. 在`AbstractApplicationContext#refresh()`里会调用
@@ -1267,7 +1267,7 @@ public class MainConfig {
##### Debug调用栈
- +
+ @@ -1434,7 +1434,7 @@ public class MainTest {
-
@@ -1434,7 +1434,7 @@ public class MainTest {
- +
+ @@ -1475,7 +1475,7 @@ public class MainTest {
我们看到此时,Person的name属性还是null
-
@@ -1475,7 +1475,7 @@ public class MainTest {
我们看到此时,Person的name属性还是null
- +
+ @@ -1497,7 +1497,7 @@ public class MainTest {
这里拿到属性值
-
@@ -1497,7 +1497,7 @@ public class MainTest {
这里拿到属性值
- +
+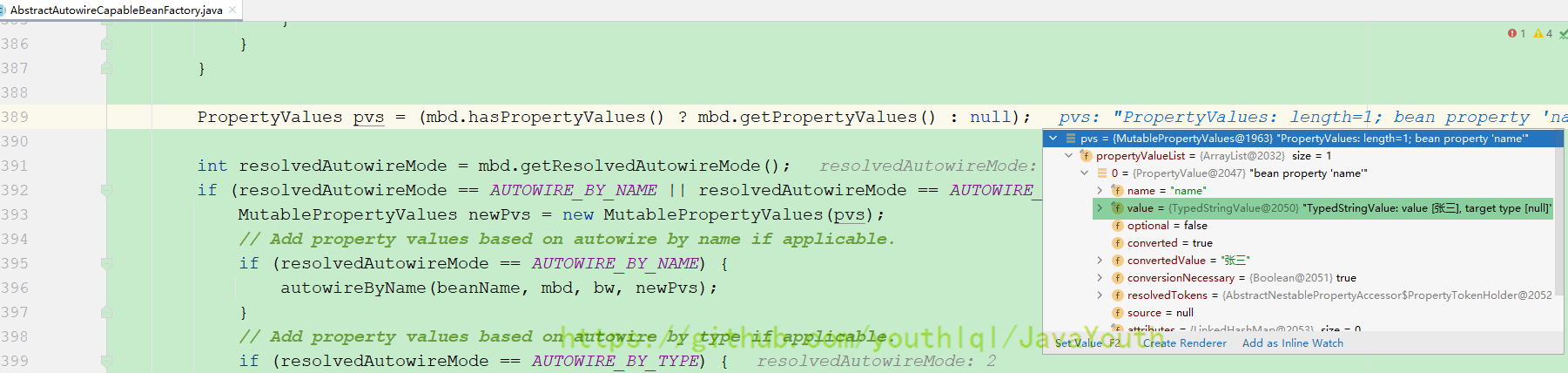 @@ -1512,13 +1512,13 @@ public class MainTest {
}
```
-
@@ -1512,13 +1512,13 @@ public class MainTest {
}
```
- +
+ bw就是上面说的 => 里面封装好了真正的Person对象
-
bw就是上面说的 => 里面封装好了真正的Person对象
- +
+ @@ -1528,7 +1528,7 @@ bw就是上面说的 => 里面封装好了真正的Person对象
这里就是一层一层调,不重要跳过。
-
@@ -1528,7 +1528,7 @@ bw就是上面说的 => 里面封装好了真正的Person对象
这里就是一层一层调,不重要跳过。
- +
+ @@ -1549,7 +1549,7 @@ private void processLocalProperty(PropertyTokenHolder tokens, PropertyValue pv)
-
@@ -1549,7 +1549,7 @@ private void processLocalProperty(PropertyTokenHolder tokens, PropertyValue pv)
- +
+ @@ -1588,7 +1588,7 @@ private class BeanPropertyHandler extends PropertyHandler {
-
@@ -1588,7 +1588,7 @@ private class BeanPropertyHandler extends PropertyHandler {
- +
+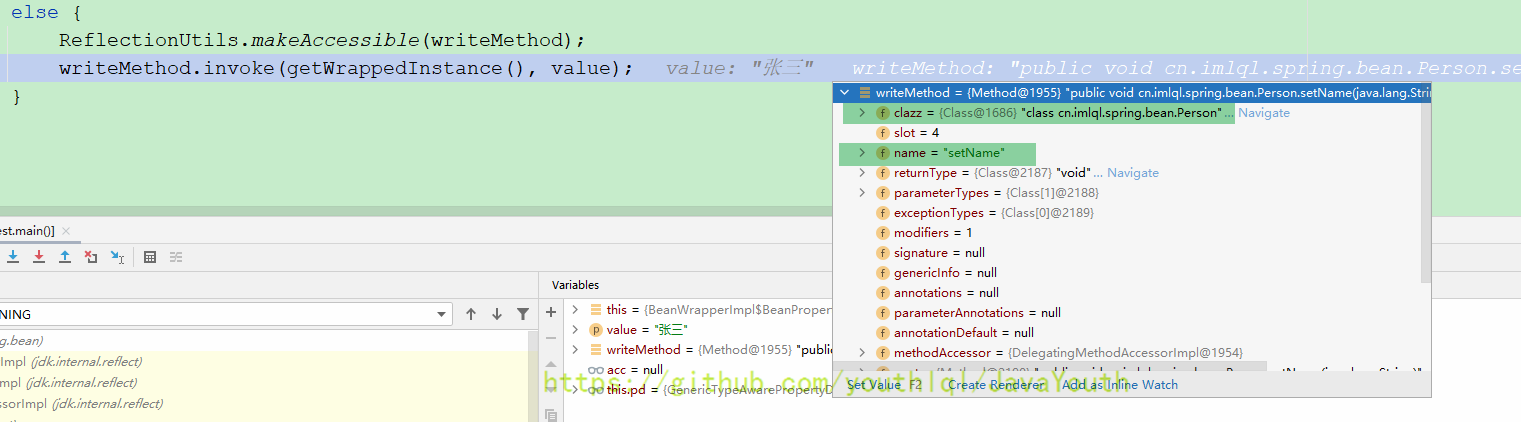 最后就是反射走到了我们的`Person#setName(String name)`
@@ -1598,7 +1598,7 @@ private class BeanPropertyHandler extends PropertyHandler {
### 再来看看messageSource何时赋值
-
最后就是反射走到了我们的`Person#setName(String name)`
@@ -1598,7 +1598,7 @@ private class BeanPropertyHandler extends PropertyHandler {
### 再来看看messageSource何时赋值
- +
+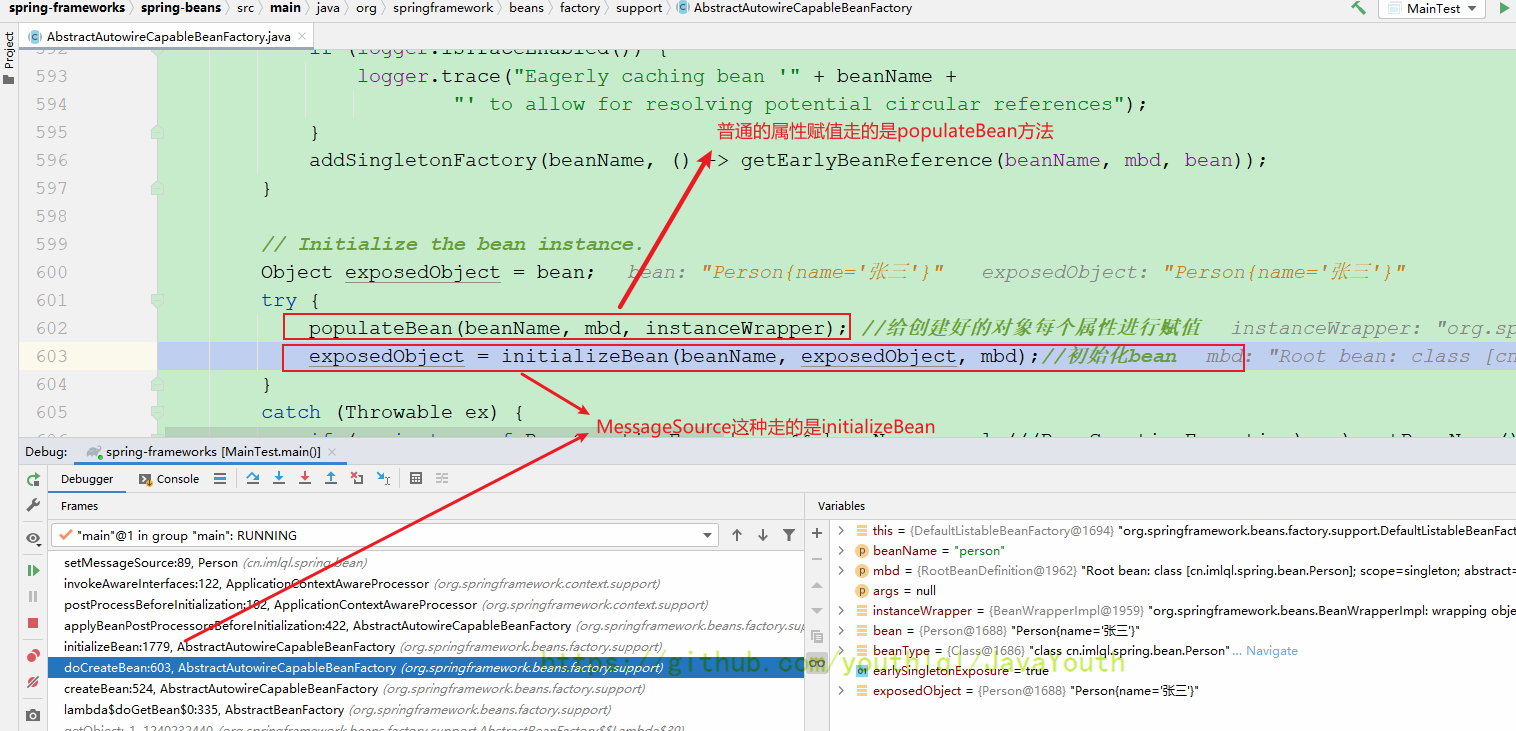 @@ -1742,7 +1742,7 @@ public class Person implements ApplicationContextAware, MessageSourceAware {
老样子,只看不一样的调用栈
-
@@ -1742,7 +1742,7 @@ public class Person implements ApplicationContextAware, MessageSourceAware {
老样子,只看不一样的调用栈
- +
+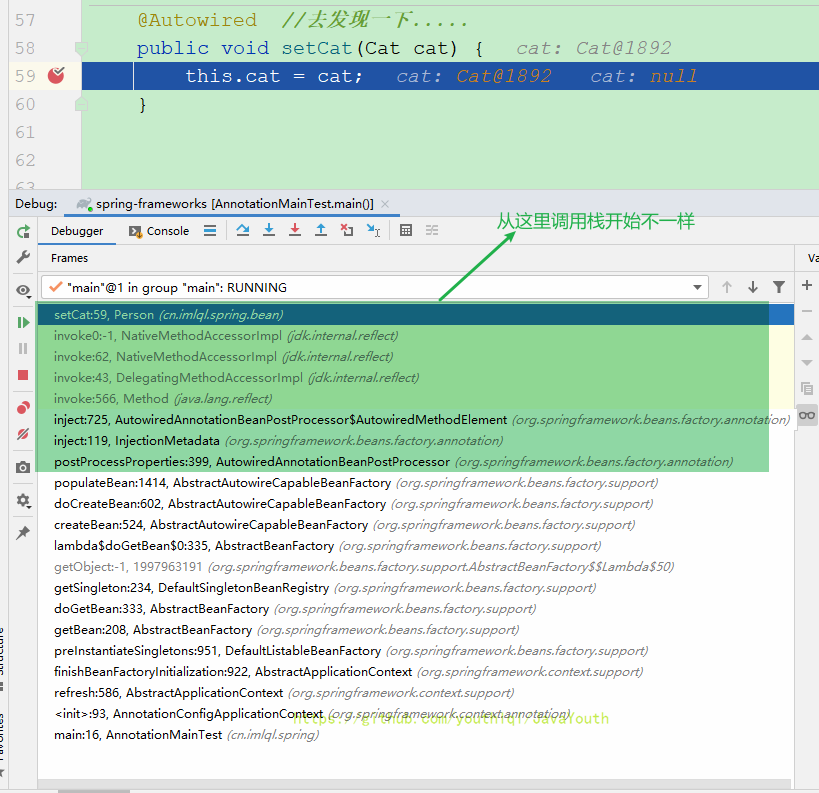 ### AbstractAutowireCapableBeanFactory#populateBean()
@@ -1785,7 +1785,7 @@ public class Person implements ApplicationContextAware, MessageSourceAware {
这里有一个非常著名的后置处理器,`AutowiredAnnotationBeanPostProcessor`自动装配注解后置处理器,顾名思义就是用来处理@Autowired注解自动装配的。
-
### AbstractAutowireCapableBeanFactory#populateBean()
@@ -1785,7 +1785,7 @@ public class Person implements ApplicationContextAware, MessageSourceAware {
这里有一个非常著名的后置处理器,`AutowiredAnnotationBeanPostProcessor`自动装配注解后置处理器,顾名思义就是用来处理@Autowired注解自动装配的。
- +
+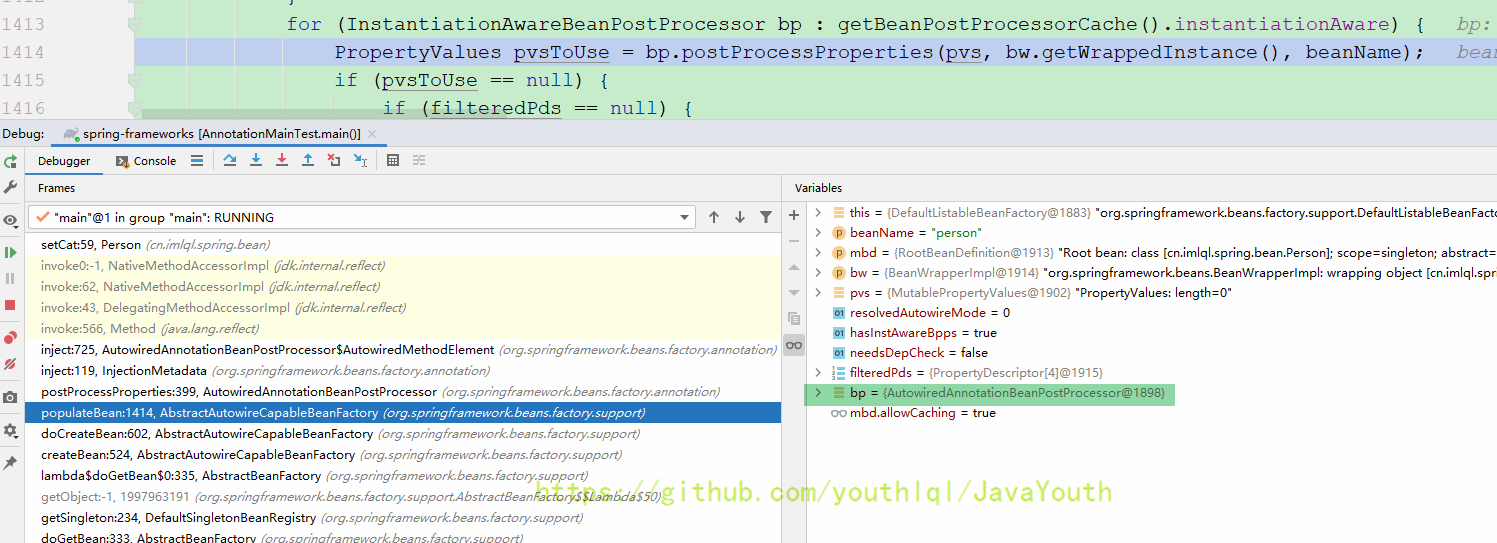 diff --git a/docs/spring-sourcecode-v1/02.第2章-后置工厂处理器和Bean生命周期.md b/docs/spring-sourcecode-v1/02.第2章-后置工厂处理器和Bean生命周期.md
index a920df2..1d823a6 100644
--- a/docs/spring-sourcecode-v1/02.第2章-后置工厂处理器和Bean生命周期.md
+++ b/docs/spring-sourcecode-v1/02.第2章-后置工厂处理器和Bean生命周期.md
@@ -97,7 +97,7 @@ public interface BeanFactoryPostProcessor {
}
```
-
diff --git a/docs/spring-sourcecode-v1/02.第2章-后置工厂处理器和Bean生命周期.md b/docs/spring-sourcecode-v1/02.第2章-后置工厂处理器和Bean生命周期.md
index a920df2..1d823a6 100644
--- a/docs/spring-sourcecode-v1/02.第2章-后置工厂处理器和Bean生命周期.md
+++ b/docs/spring-sourcecode-v1/02.第2章-后置工厂处理器和Bean生命周期.md
@@ -97,7 +97,7 @@ public interface BeanFactoryPostProcessor {
}
```
- +
+ 核心就是我们对于传进来的参数,可以**修改,覆盖,添加**它的东西。对于BeanPostProcessor来说,传进来的参数是`(Object bean, String beanName)` ,它都已经把bean传给你了,这意味着我们可以修改传进来的Bean的任何东西。不管你是事务也好,AOP也好,都是通过这些个后置处理器来添加这些额外功能的。
@@ -106,11 +106,11 @@ BeanFactoryPostProcessor:后置增强BeanFactory,也就是增强Bean工厂
### BeanFactoryPostProcessor的接口关系
-
核心就是我们对于传进来的参数,可以**修改,覆盖,添加**它的东西。对于BeanPostProcessor来说,传进来的参数是`(Object bean, String beanName)` ,它都已经把bean传给你了,这意味着我们可以修改传进来的Bean的任何东西。不管你是事务也好,AOP也好,都是通过这些个后置处理器来添加这些额外功能的。
@@ -106,11 +106,11 @@ BeanFactoryPostProcessor:后置增强BeanFactory,也就是增强Bean工厂
### BeanFactoryPostProcessor的接口关系
- +
+ ### BeanPostProcessor接口关系
-
### BeanPostProcessor接口关系
- +
+ DestructionAwareBeanPostProcessor接口是跟销毁有关的,我们这里不分析
@@ -391,7 +391,7 @@ public class MainTest {
### 流程图-Bean生命周期与后置工厂处理器
-
DestructionAwareBeanPostProcessor接口是跟销毁有关的,我们这里不分析
@@ -391,7 +391,7 @@ public class MainTest {
### 流程图-Bean生命周期与后置工厂处理器
- +
+ ### BeanDefinitionRegistryPostProcessor
@@ -399,7 +399,7 @@ public class MainTest {
##### Debug调用栈
-
### BeanDefinitionRegistryPostProcessor
@@ -399,7 +399,7 @@ public class MainTest {
##### Debug调用栈
- +
+ ##### AbstractApplicationContext#refresh()
@@ -615,9 +615,9 @@ public class MainTest {
> Spring中所有组件的获取都是通过getBean(),容器中有就拿,没有就创建。
-
##### AbstractApplicationContext#refresh()
@@ -615,9 +615,9 @@ public class MainTest {
> Spring中所有组件的获取都是通过getBean(),容器中有就拿,没有就创建。
- +
+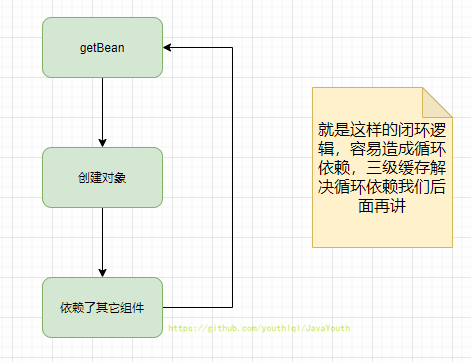 -
- +
+ 下面那个是Spring默认提供的后置处理器,我们后面再讲。
@@ -677,11 +677,11 @@ public interface Ordered {
##### Debug调用栈
-
下面那个是Spring默认提供的后置处理器,我们后面再讲。
@@ -677,11 +677,11 @@ public interface Ordered {
##### Debug调用栈
- +
+ 从PostProcessorRegistrationDelegate 142行开始走不同的调用,代码在上面有注释
-
从PostProcessorRegistrationDelegate 142行开始走不同的调用,代码在上面有注释
- +
+ ##### PostProcessorRegistrationDelegate#invokeBeanDefinitionRegistryPostProcessors()
@@ -706,7 +706,7 @@ private static void invokeBeanDefinitionRegistryPostProcessors(
##### Debug调用栈
-
##### PostProcessorRegistrationDelegate#invokeBeanDefinitionRegistryPostProcessors()
@@ -706,7 +706,7 @@ private static void invokeBeanDefinitionRegistryPostProcessors(
##### Debug调用栈
- +
+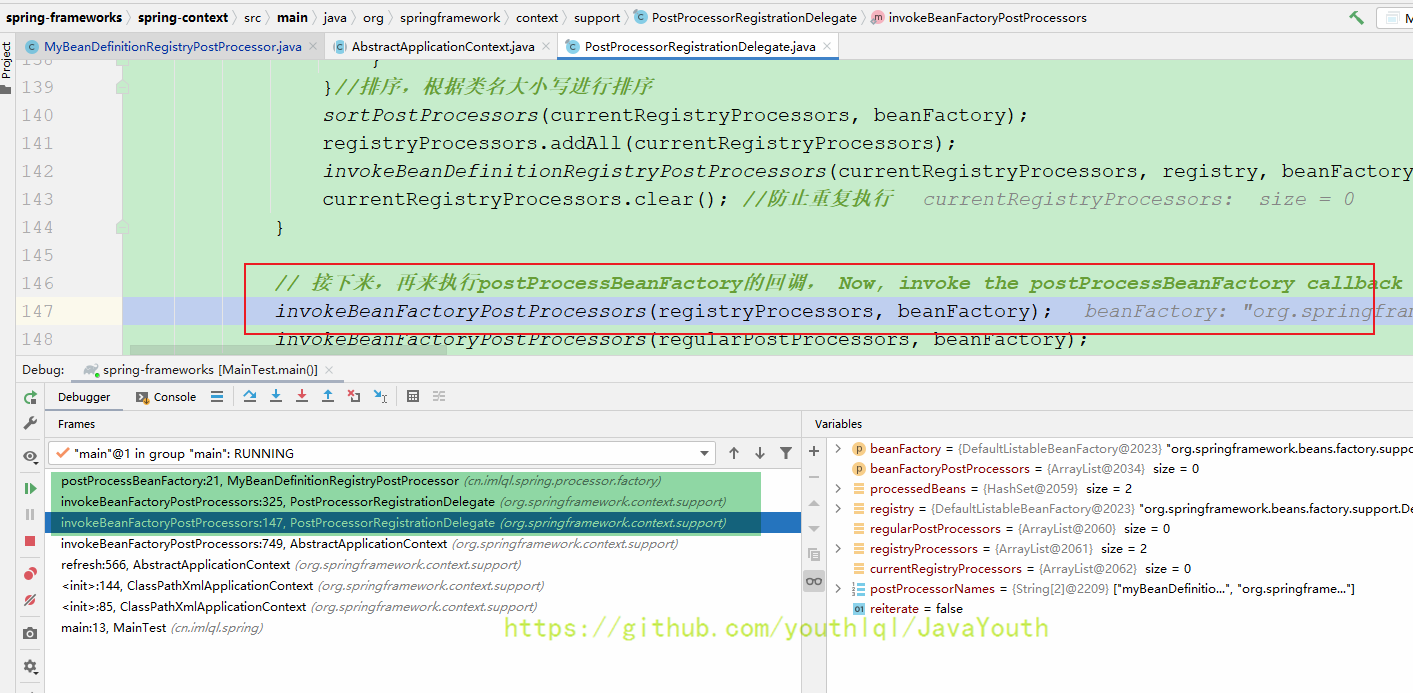 @@ -733,7 +733,7 @@ private static void invokeBeanFactoryPostProcessors(
##### Debug调用栈
-
@@ -733,7 +733,7 @@ private static void invokeBeanFactoryPostProcessors(
##### Debug调用栈
- +
+ @@ -741,7 +741,7 @@ private static void invokeBeanFactoryPostProcessors(
##### Debug调用栈
-
@@ -741,7 +741,7 @@ private static void invokeBeanFactoryPostProcessors(
##### Debug调用栈
- +
+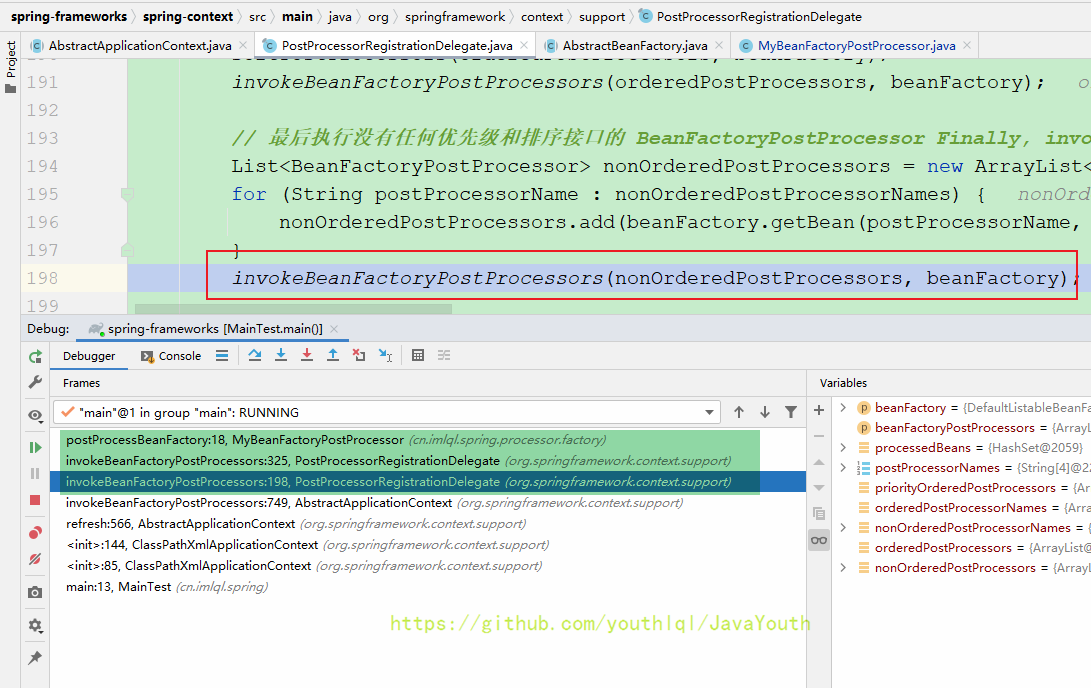 代码注释也是上面那个,BeanDefinitionRegistryPostProcessor和BeanFactoryPostProcessor执行逻辑基本一样
@@ -779,11 +779,11 @@ public class MainConfig {
-
代码注释也是上面那个,BeanDefinitionRegistryPostProcessor和BeanFactoryPostProcessor执行逻辑基本一样
@@ -779,11 +779,11 @@ public class MainConfig {
- +
+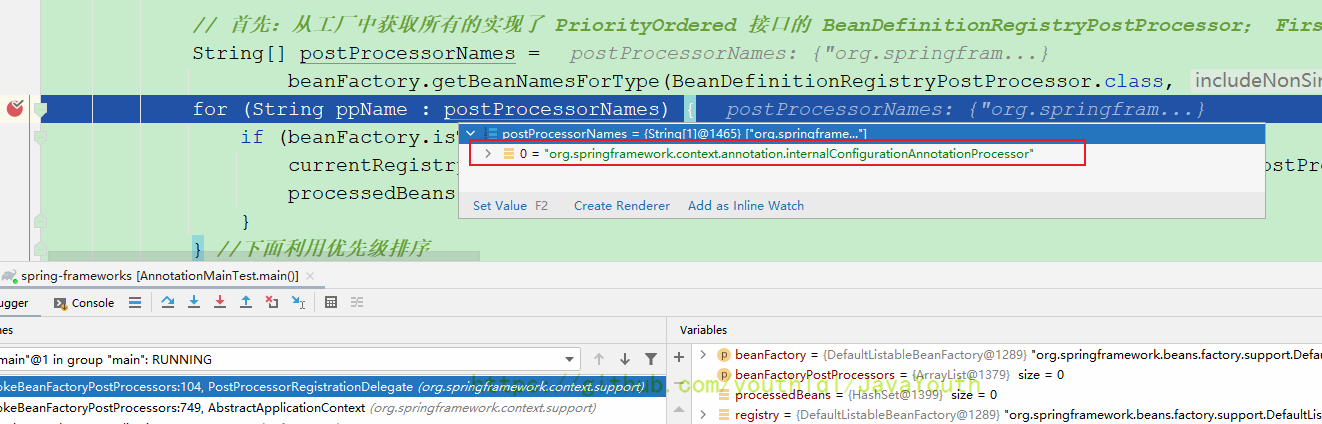 从这一步进来
-
从这一步进来
- +
+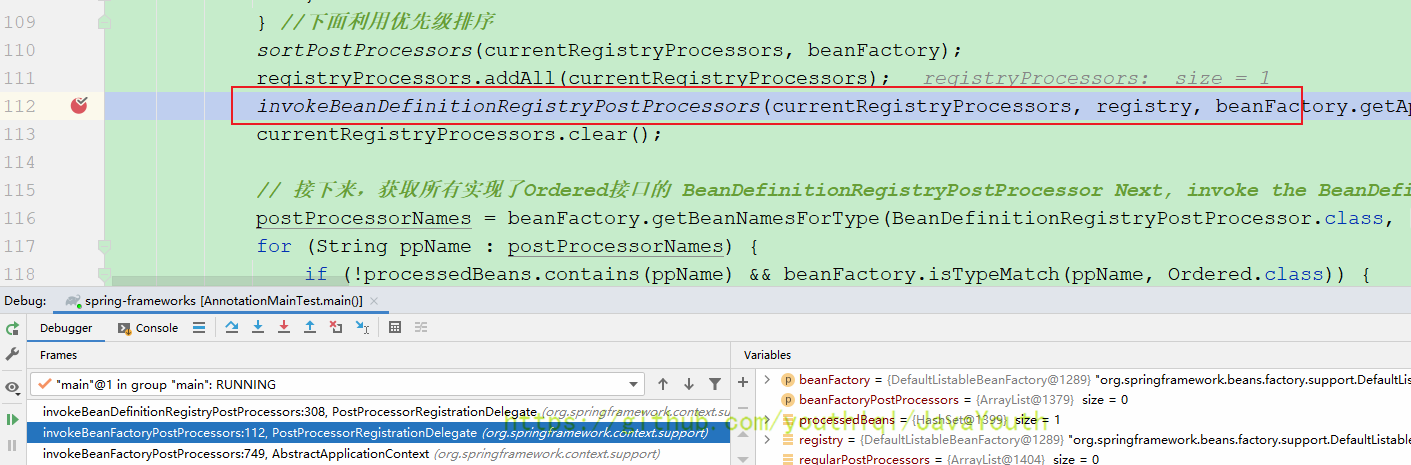 @@ -791,7 +791,7 @@ public class MainConfig {
#### PostProcessorRegistrationDelegate#invokeBeanDefinitionRegistryPostProcessors()
-
@@ -791,7 +791,7 @@ public class MainConfig {
#### PostProcessorRegistrationDelegate#invokeBeanDefinitionRegistryPostProcessors()
- +
+ F7进入
@@ -799,7 +799,7 @@ F7进入
ConfigurationClassPostProcessor配置类的后置处理
-
F7进入
@@ -799,7 +799,7 @@ F7进入
ConfigurationClassPostProcessor配置类的后置处理
- +
+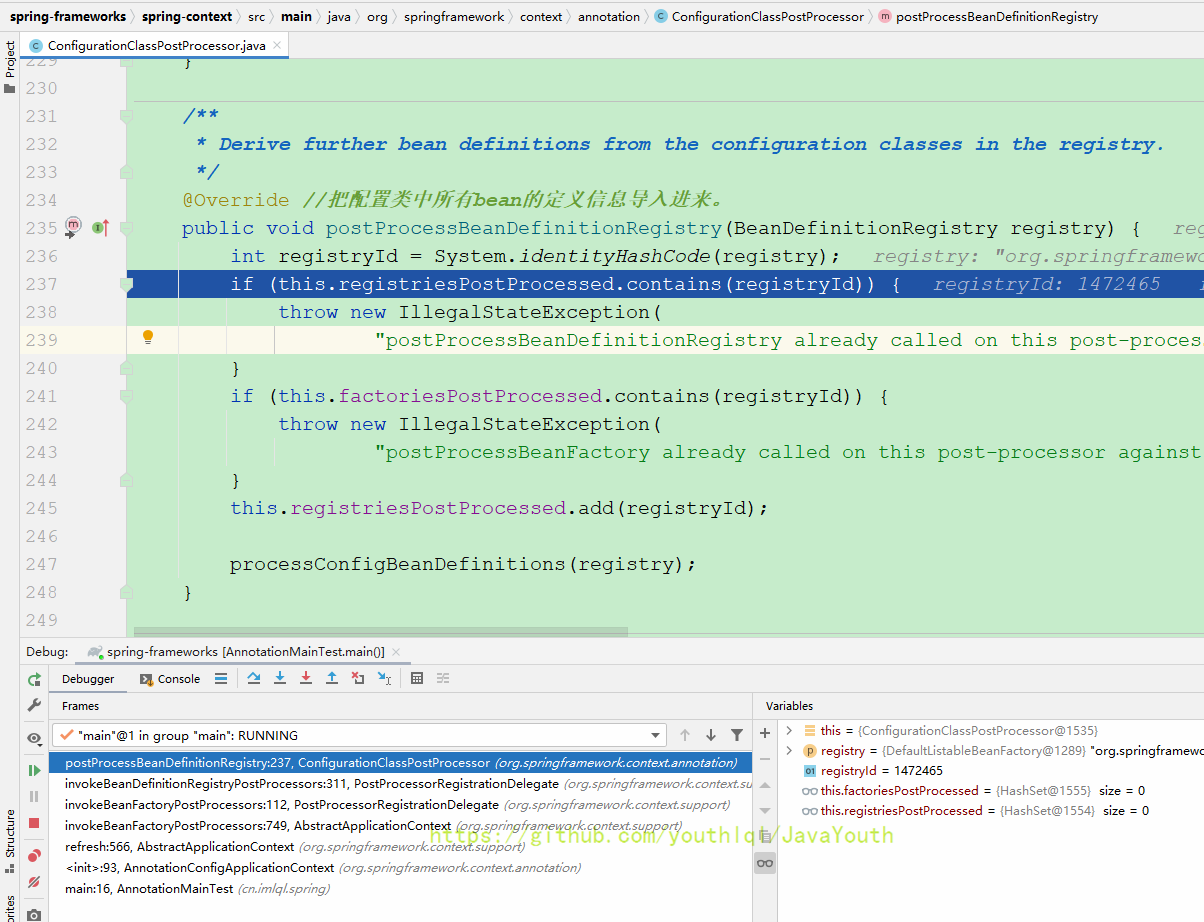 @@ -914,7 +914,7 @@ ConfigurationClassPostProcessor配置类的后置处理
这几个怎么来的我们后面说
-
@@ -914,7 +914,7 @@ ConfigurationClassPostProcessor配置类的后置处理
这几个怎么来的我们后面说
- +
+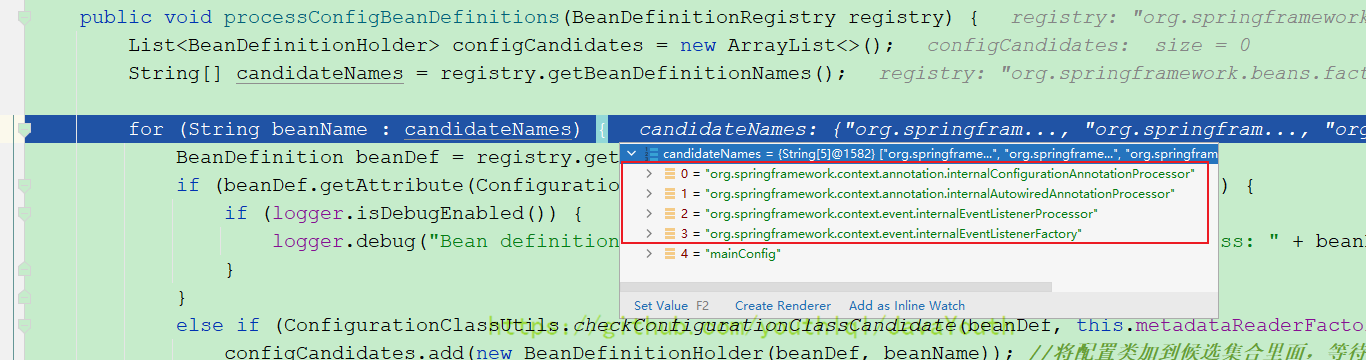 diff --git a/docs/spring-sourcecode-v1/03.第3章-后置处理器和Bean生命周期.md b/docs/spring-sourcecode-v1/03.第3章-后置处理器和Bean生命周期.md
index fbd84a3..f6701d1 100644
--- a/docs/spring-sourcecode-v1/03.第3章-后置处理器和Bean生命周期.md
+++ b/docs/spring-sourcecode-v1/03.第3章-后置处理器和Bean生命周期.md
@@ -250,7 +250,7 @@ public class MainTest {
### 流程图-Bean生命周期与后置处理器
-
diff --git a/docs/spring-sourcecode-v1/03.第3章-后置处理器和Bean生命周期.md b/docs/spring-sourcecode-v1/03.第3章-后置处理器和Bean生命周期.md
index fbd84a3..f6701d1 100644
--- a/docs/spring-sourcecode-v1/03.第3章-后置处理器和Bean生命周期.md
+++ b/docs/spring-sourcecode-v1/03.第3章-后置处理器和Bean生命周期.md
@@ -250,7 +250,7 @@ public class MainTest {
### 流程图-Bean生命周期与后置处理器
- +
+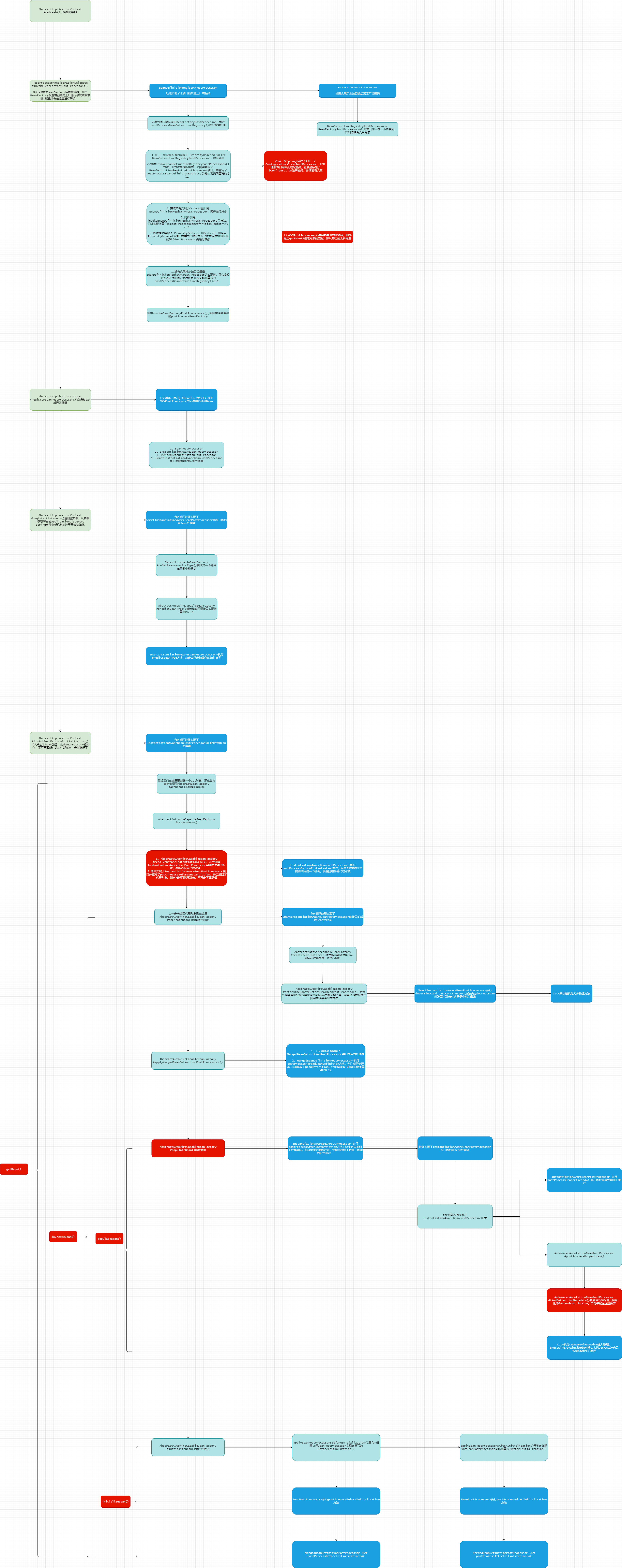 ### BeanPostProcessor-执行无参构造
@@ -258,7 +258,7 @@ public class MainTest {
#### Debug调用栈
-
### BeanPostProcessor-执行无参构造
@@ -258,7 +258,7 @@ public class MainTest {
#### Debug调用栈
- +
+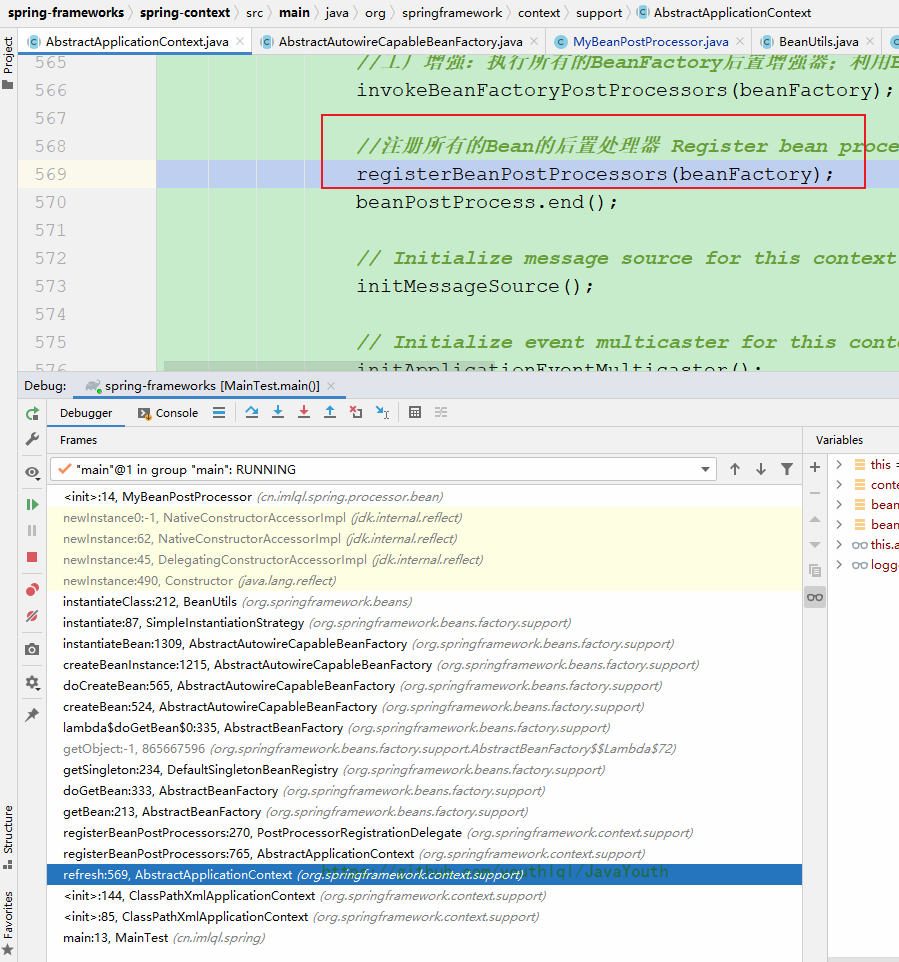 #### AbstractApplicationContext#registerBeanPostProcessors()注册Bean后置处理器
@@ -345,7 +345,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
- Bean工厂后置处理器调用的是`invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory , List )`
- Bean后置处理器调用的是`registerBeanPostProcessors(ConfigurableListableBeanFactory , AbstractApplicationContext )`
-
#### AbstractApplicationContext#registerBeanPostProcessors()注册Bean后置处理器
@@ -345,7 +345,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
- Bean工厂后置处理器调用的是`invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory , List )`
- Bean后置处理器调用的是`registerBeanPostProcessors(ConfigurableListableBeanFactory , AbstractApplicationContext )`
- +
+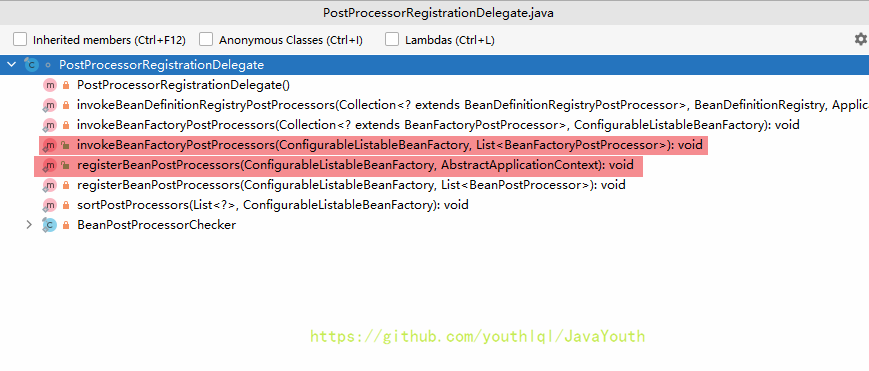 @@ -355,7 +355,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
> 2. BeanFactoryPostProcessor是先执行完每一个的无参构造和实现的几个方法,再去执行下一个BeanFactoryPostProcessor
> 3. BeanPostProcessor是先执行所有BeanPostProcessor的无参构造,再执行所有BeanPostProcessor实现的方法。
-
@@ -355,7 +355,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
> 2. BeanFactoryPostProcessor是先执行完每一个的无参构造和实现的几个方法,再去执行下一个BeanFactoryPostProcessor
> 3. BeanPostProcessor是先执行所有BeanPostProcessor的无参构造,再执行所有BeanPostProcessor实现的方法。
- +
+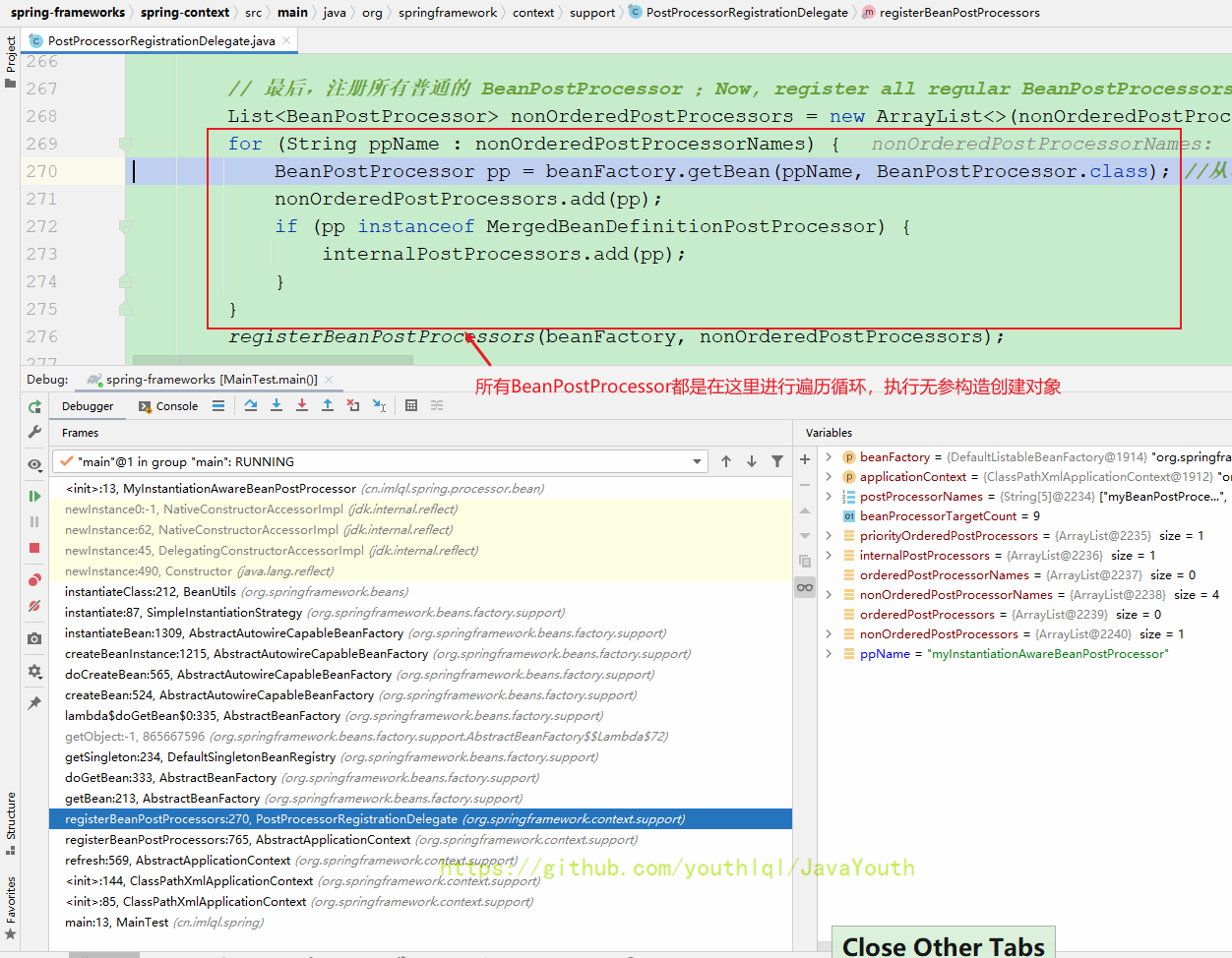 ### MergedBeanDefinitionPostProcessor-执行无参构造
@@ -365,7 +365,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
同上
-
### MergedBeanDefinitionPostProcessor-执行无参构造
@@ -365,7 +365,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
同上
- +
+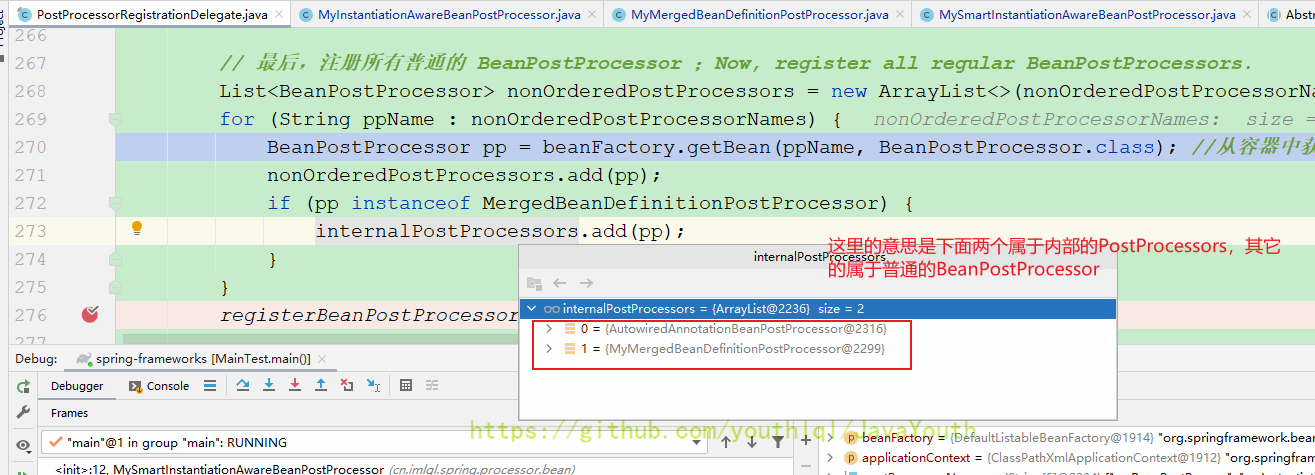 @@ -375,7 +375,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
#### Debug调用栈
-
@@ -375,7 +375,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
#### Debug调用栈
- +
+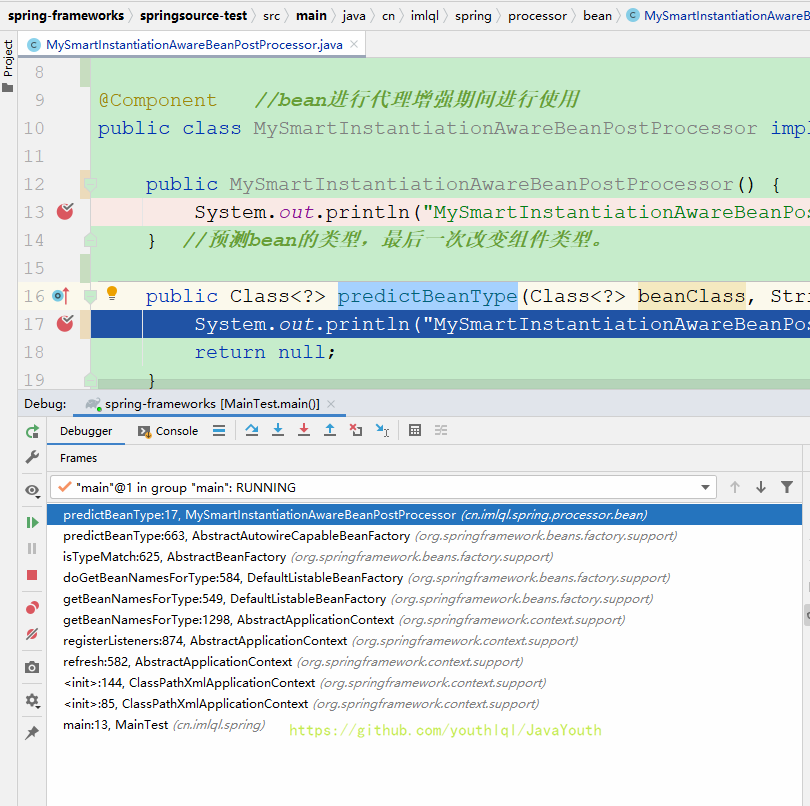 @@ -542,7 +542,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
3. 判断是不是想要的类型。
3. 这里有没有优化空间,再存一个BeanType=>BeanName的对应关系?但是这样的关系是一对多的,同一个BeanType下可能有多个beanName,Spring可能是考虑到空间成本,没有这样弄。
-
@@ -542,7 +542,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
3. 判断是不是想要的类型。
3. 这里有没有优化空间,再存一个BeanType=>BeanName的对应关系?但是这样的关系是一对多的,同一个BeanType下可能有多个beanName,Spring可能是考虑到空间成本,没有这样弄。
- +
+ @@ -554,7 +554,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
2. 我们来看看此时单例池里有哪些对象
-
@@ -554,7 +554,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
2. 我们来看看此时单例池里有哪些对象
- +
+ ```java
protected boolean isTypeMatch(String name, ResolvableType typeToMatch, boolean allowFactoryBeanInit)
@@ -687,13 +687,13 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
在此方法里为什么Cat会进来两次呢?往后面看
-
```java
protected boolean isTypeMatch(String name, ResolvableType typeToMatch, boolean allowFactoryBeanInit)
@@ -687,13 +687,13 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
在此方法里为什么Cat会进来两次呢?往后面看
- +
+ ### InstantiationAwareBeanPostProcessor-执行postProcessBeforeInstantiation方法
#### Debug调用栈
-
### InstantiationAwareBeanPostProcessor-执行postProcessBeforeInstantiation方法
#### Debug调用栈
- +
+ #### AbstractApplicationContext#finishBeanFactoryInitialization()完成BeanFactory初始化
@@ -746,7 +746,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
2. 上面我们也看了只有Cat的对象还没创建,还没初始化,所以下面就开始创建对象了。
-
#### AbstractApplicationContext#finishBeanFactoryInitialization()完成BeanFactory初始化
@@ -746,7 +746,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
2. 上面我们也看了只有Cat的对象还没创建,还没初始化,所以下面就开始创建对象了。
- +
+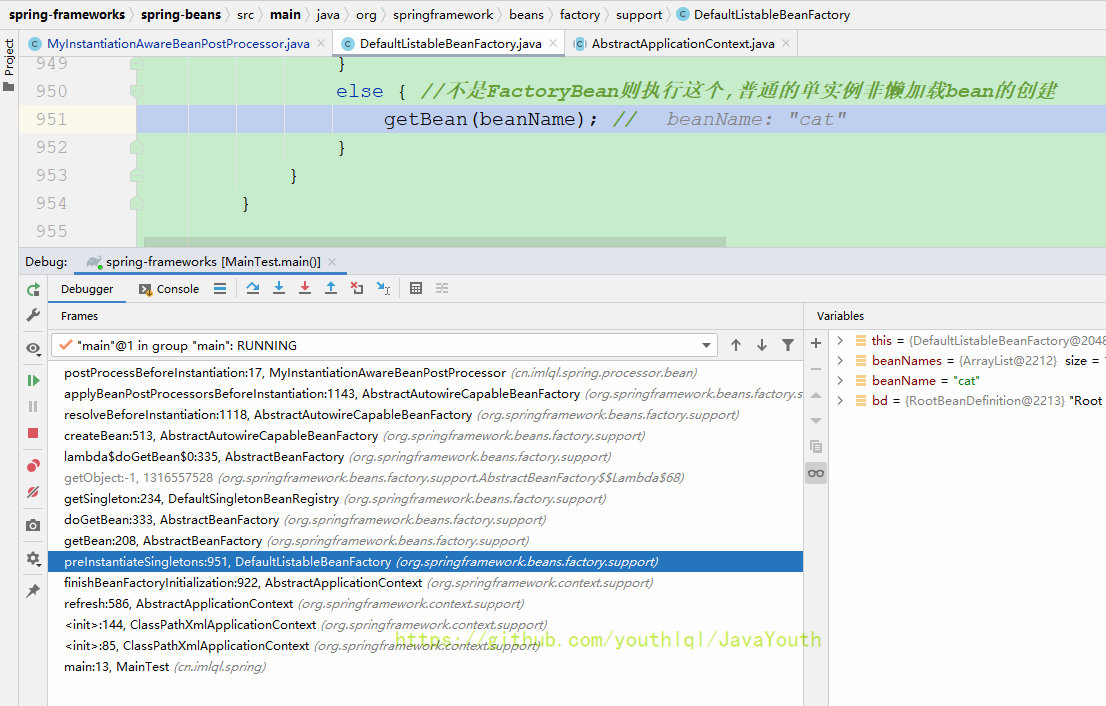 @@ -860,7 +860,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
#### Debug调用栈
-
@@ -860,7 +860,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
#### Debug调用栈
- +
+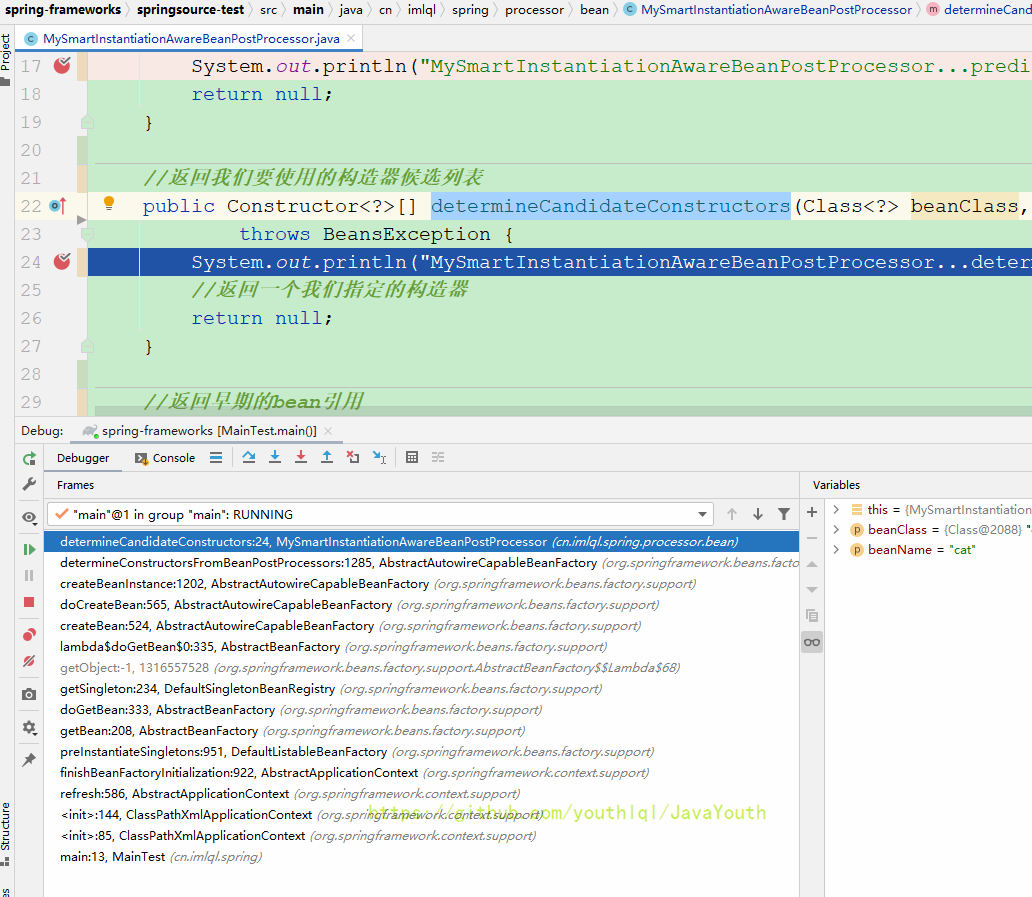 > 前面还是一样的执行逻辑,直接来到下面
@@ -1003,7 +1003,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
1. 实例提供者:
-
> 前面还是一样的执行逻辑,直接来到下面
@@ -1003,7 +1003,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
1. 实例提供者:
- +
+ @@ -1025,7 +1025,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
### Cat-执行无参构造方法
-
@@ -1025,7 +1025,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
### Cat-执行无参构造方法
- +
+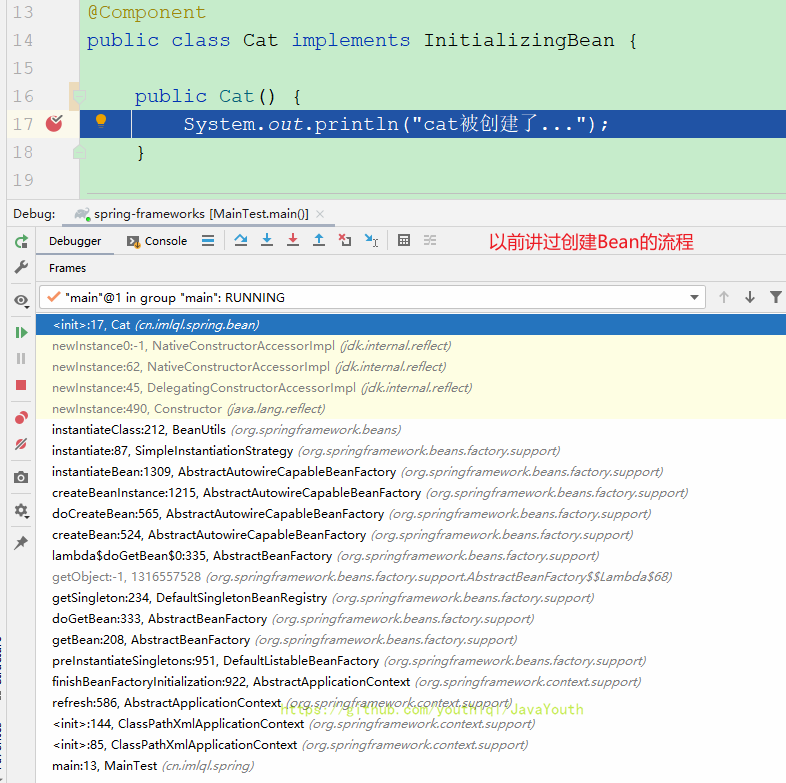 @@ -1039,7 +1039,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
#### Debug调用栈
-
@@ -1039,7 +1039,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
#### Debug调用栈
- +
+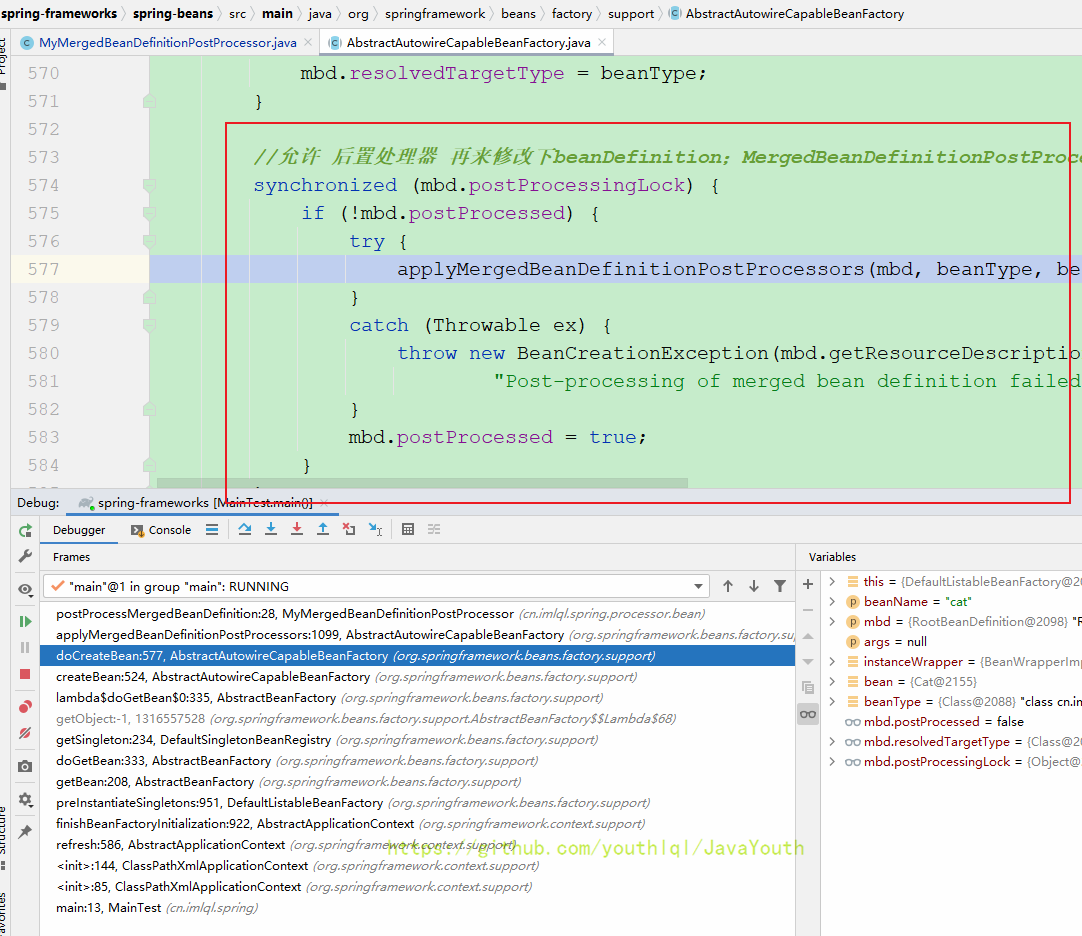 @@ -1061,7 +1061,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
#### Debug调用栈
-
@@ -1061,7 +1061,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
#### Debug调用栈
- +
+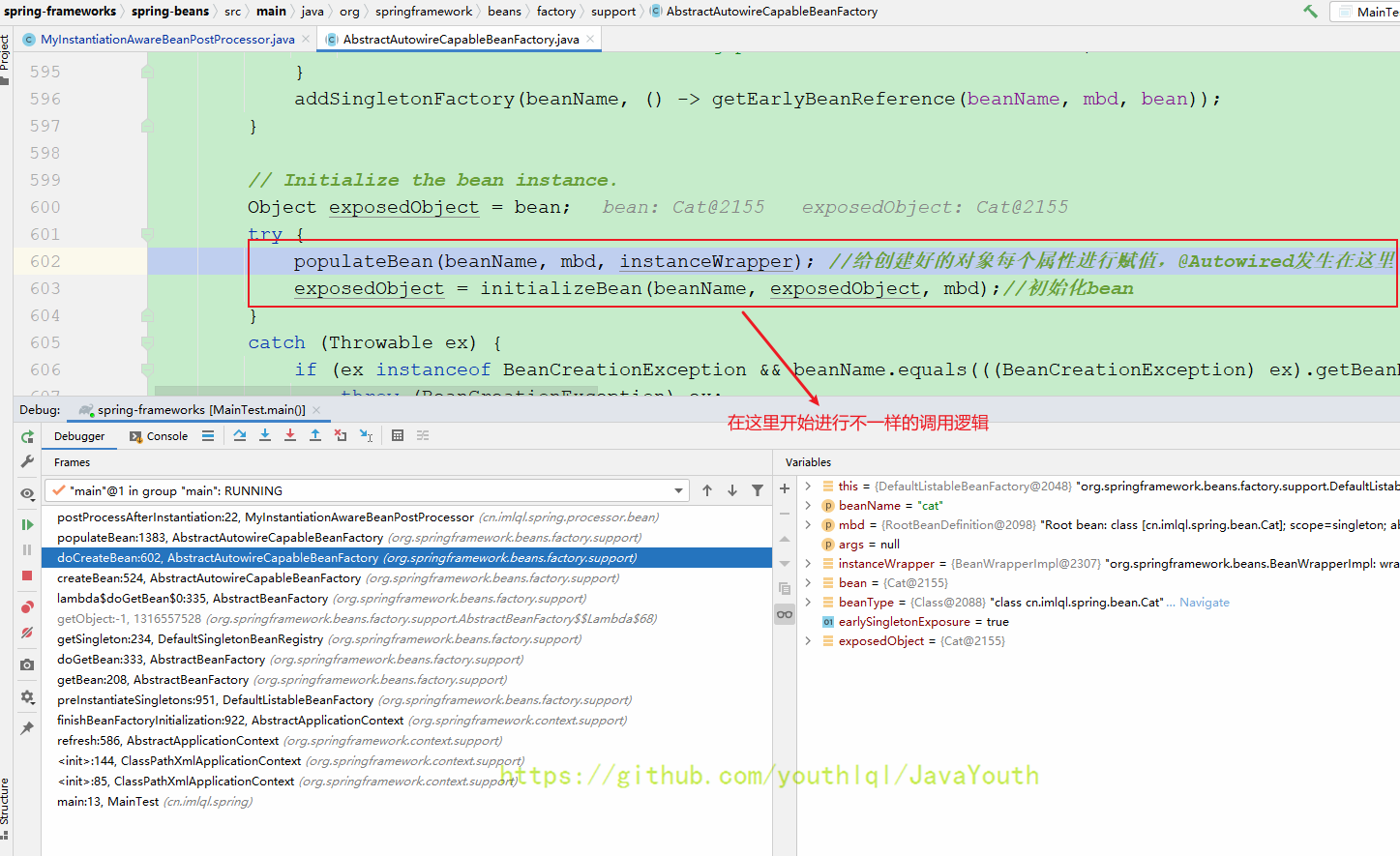 #### AbstractAutowireCapableBeanFactory#populateBean()属性赋值
@@ -1141,7 +1141,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
}
```
-
#### AbstractAutowireCapableBeanFactory#populateBean()属性赋值
@@ -1141,7 +1141,7 @@ protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFa
}
```
- +
+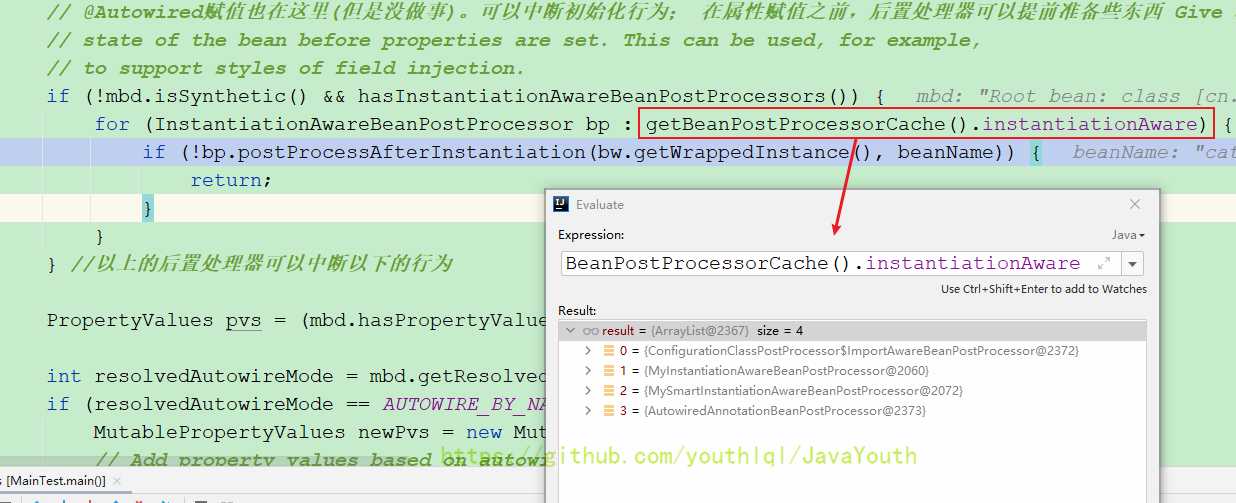 @@ -1193,7 +1193,7 @@ public void setValue(@Nullable Object value) throws Exception { //name setName
#### Debug调用栈
-
@@ -1193,7 +1193,7 @@ public void setValue(@Nullable Object value) throws Exception { //name setName
#### Debug调用栈
- +
+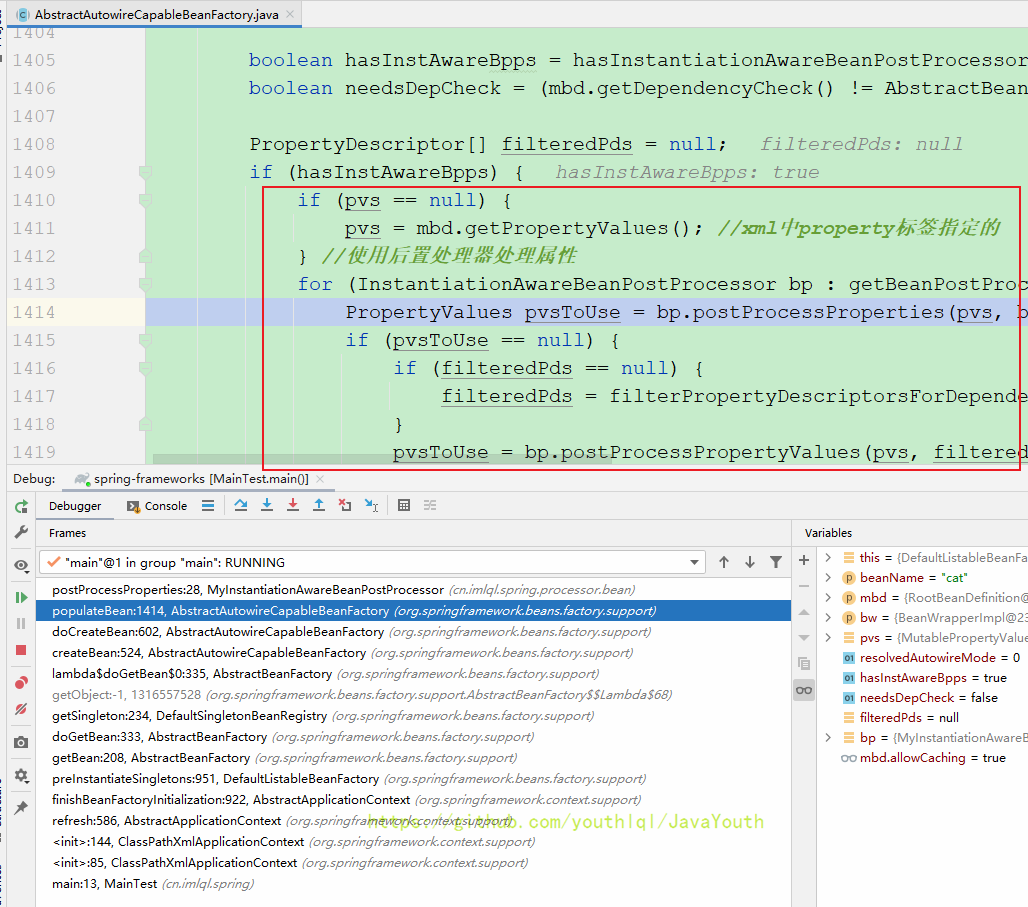 @@ -1201,7 +1201,7 @@ public void setValue(@Nullable Object value) throws Exception { //name setName
#### AutowiredAnnotationBeanPostProcessor#postProcessProperties()
-
@@ -1201,7 +1201,7 @@ public void setValue(@Nullable Object value) throws Exception { //name setName
#### AutowiredAnnotationBeanPostProcessor#postProcessProperties()
- +
+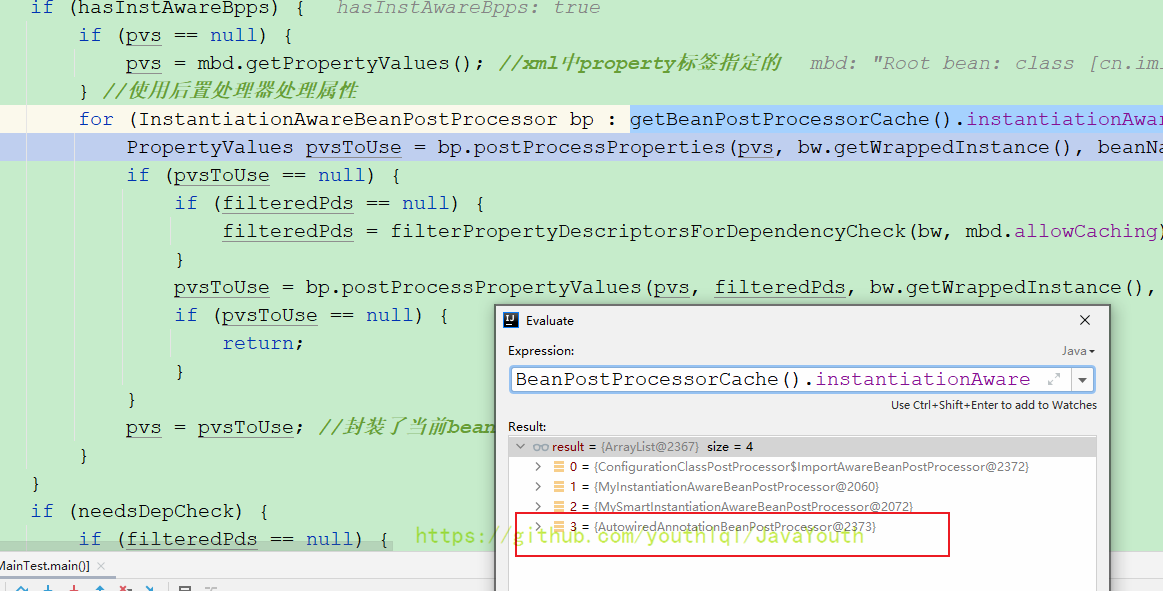 ```java
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {
@@ -1322,7 +1322,7 @@ public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, Str
#### Debug调用栈
-
```java
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {
@@ -1322,7 +1322,7 @@ public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, Str
#### Debug调用栈
- +
+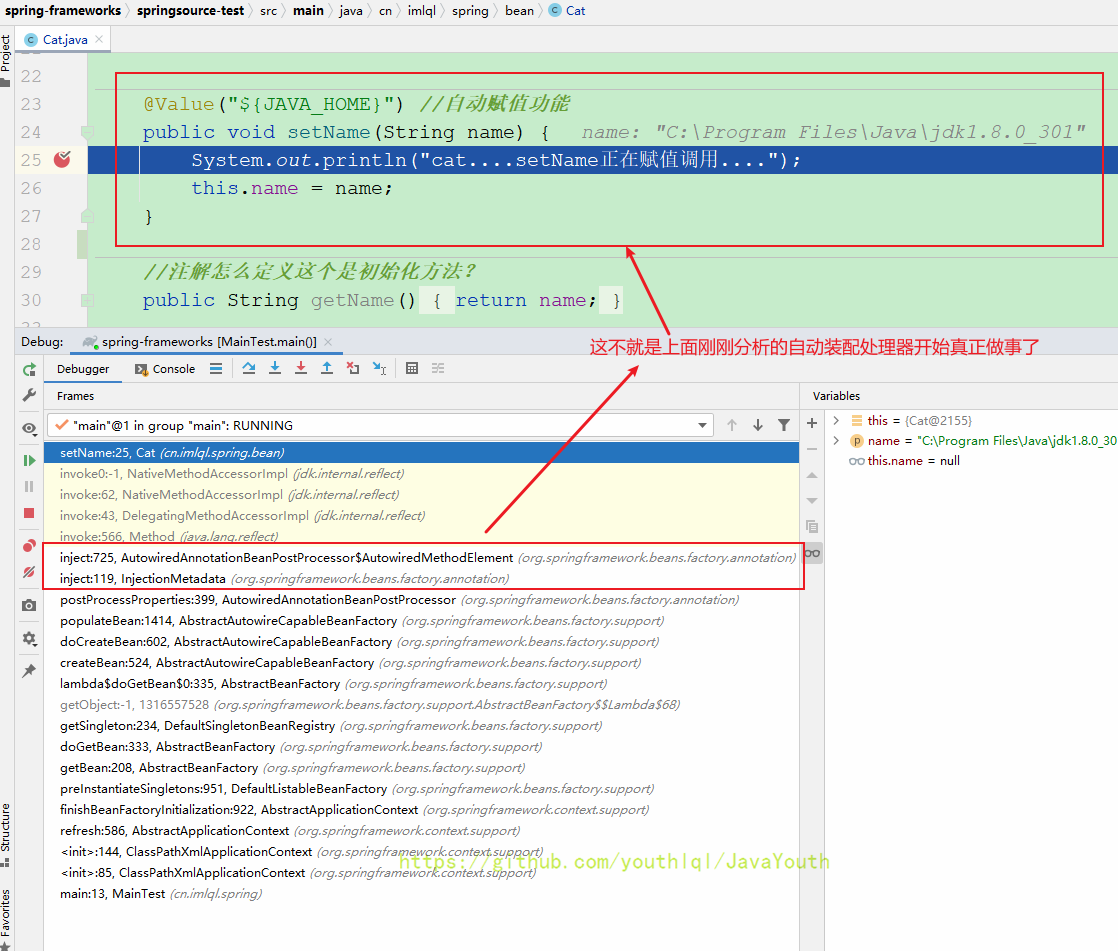 这也说明了,@Autowire,@Value赋值的时候会去找setXXX,这也是@Autowire的原理
@@ -1350,7 +1350,7 @@ public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, Str
#### Debug调用栈
-
这也说明了,@Autowire,@Value赋值的时候会去找setXXX,这也是@Autowire的原理
@@ -1350,7 +1350,7 @@ public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, Str
#### Debug调用栈
- +
+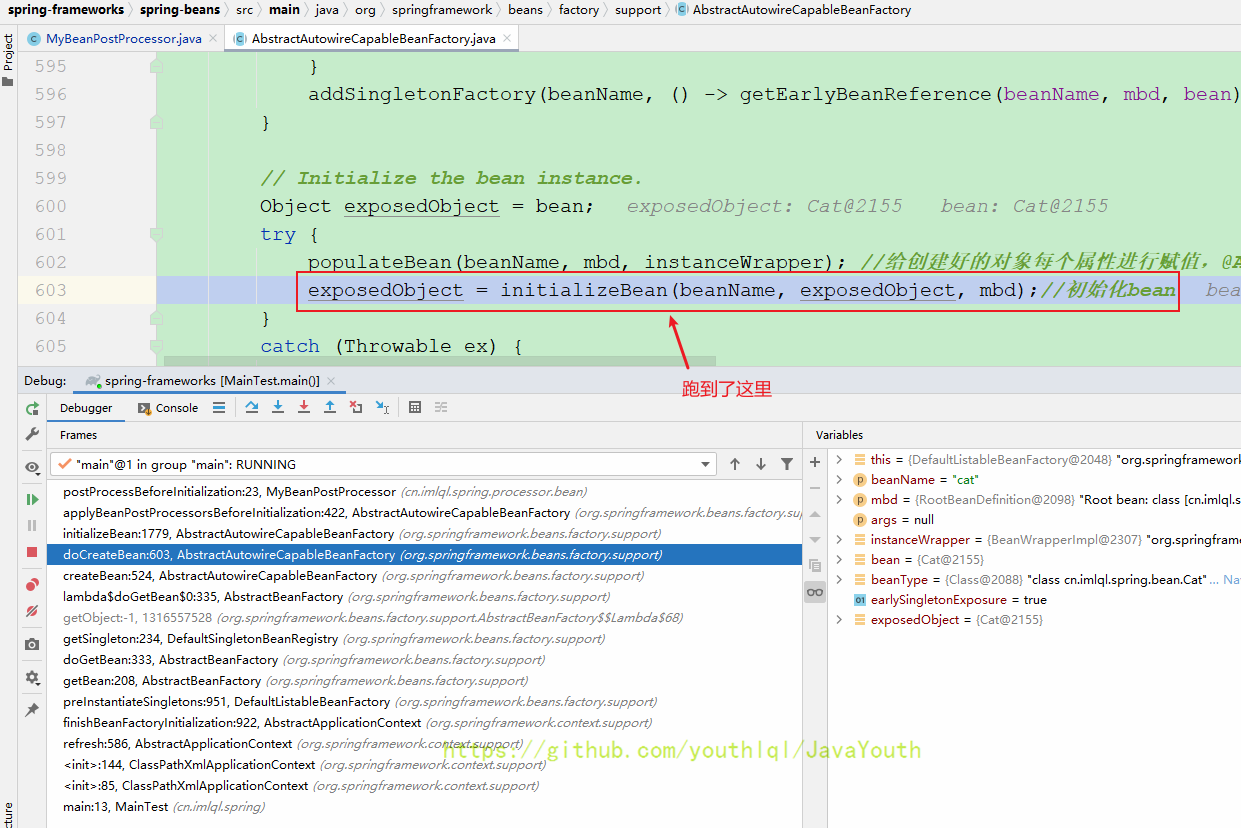 @@ -1461,7 +1461,7 @@ public Object postProcessBeforeInitialization(Object bean, String beanName) thro
#### Debug调用栈
-
@@ -1461,7 +1461,7 @@ public Object postProcessBeforeInitialization(Object bean, String beanName) thro
#### Debug调用栈
- +
+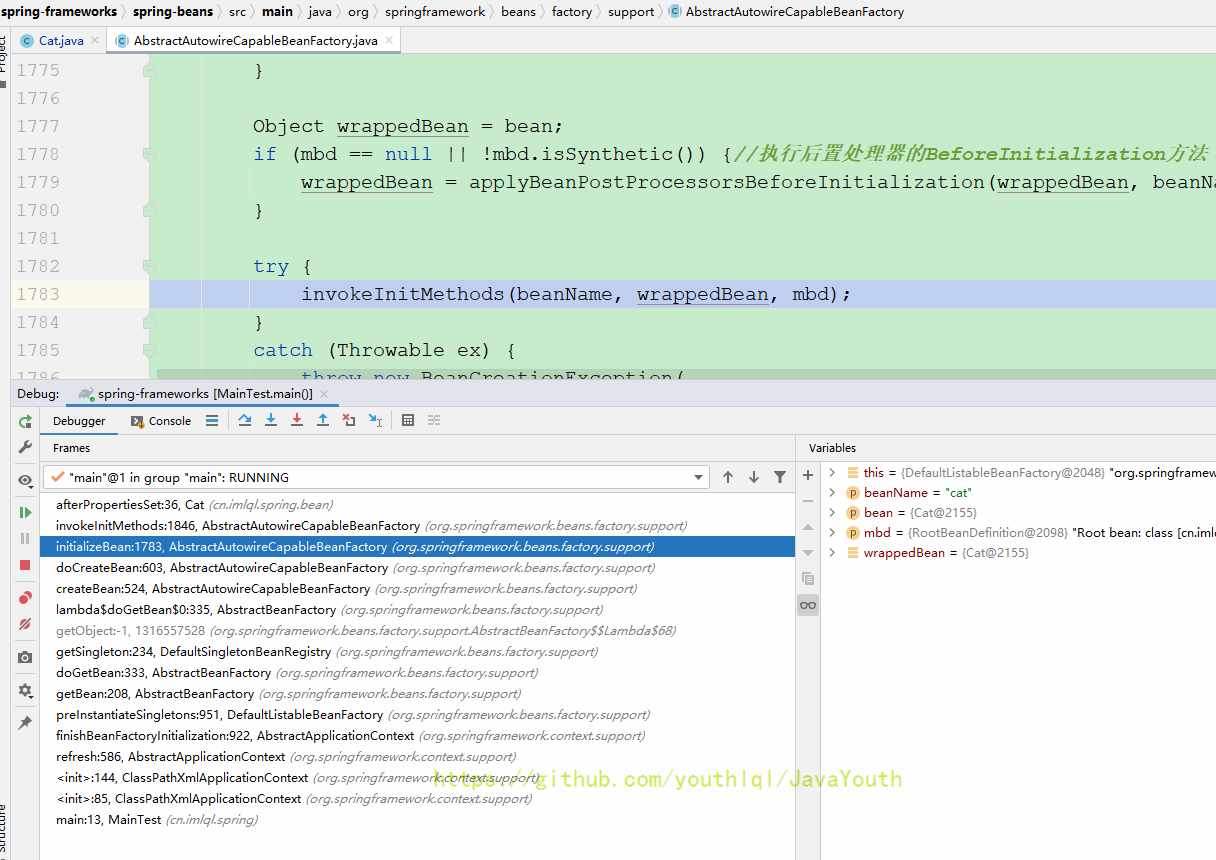 @@ -1513,7 +1513,7 @@ public Object postProcessBeforeInitialization(Object bean, String beanName) thro
#### Debug调用栈
-
@@ -1513,7 +1513,7 @@ public Object postProcessBeforeInitialization(Object bean, String beanName) thro
#### Debug调用栈
- +
+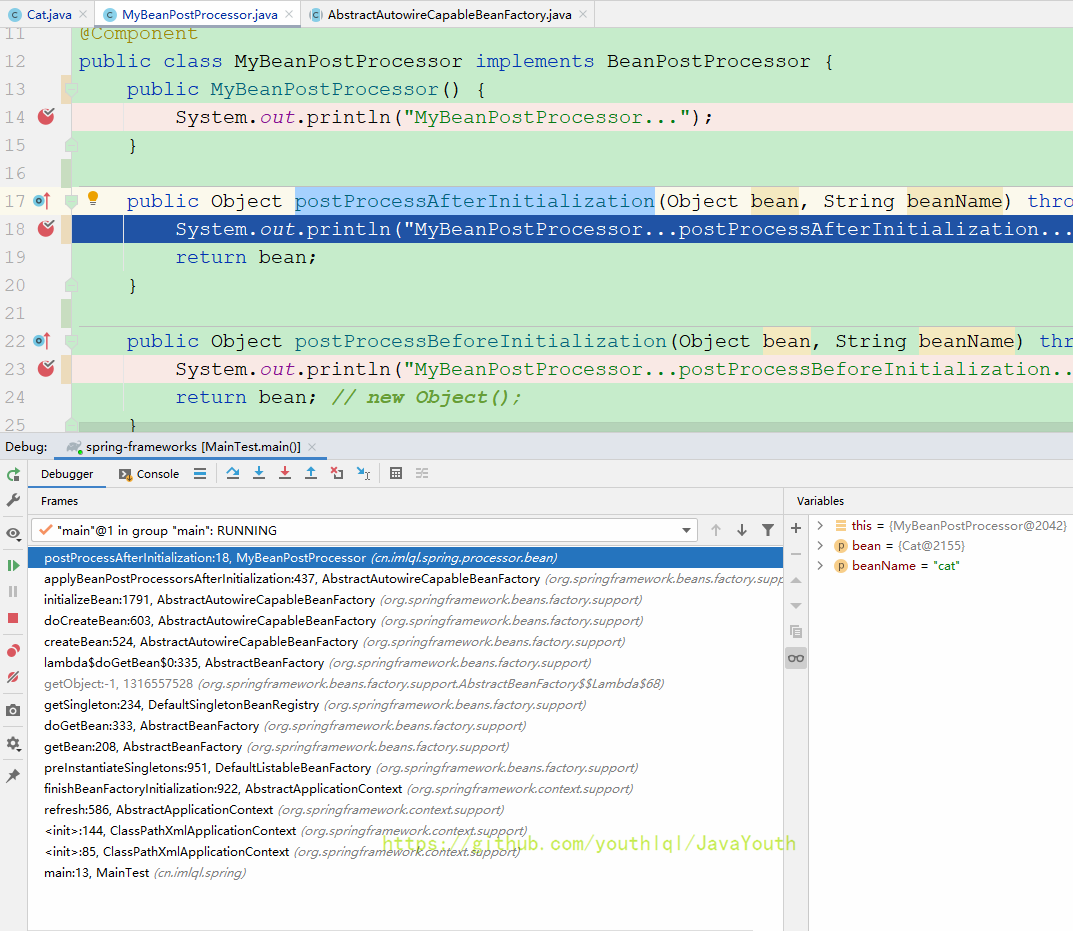 diff --git a/docs/spring-sourcecode-v1/04.第4章-Bean初始化流程.md b/docs/spring-sourcecode-v1/04.第4章-Bean初始化流程.md
index 90738b2..7500040 100644
--- a/docs/spring-sourcecode-v1/04.第4章-Bean初始化流程.md
+++ b/docs/spring-sourcecode-v1/04.第4章-Bean初始化流程.md
@@ -16,7 +16,7 @@ date: 2022-01-27 21:01:02
## 流程图-bean初始化流程
-
diff --git a/docs/spring-sourcecode-v1/04.第4章-Bean初始化流程.md b/docs/spring-sourcecode-v1/04.第4章-Bean初始化流程.md
index 90738b2..7500040 100644
--- a/docs/spring-sourcecode-v1/04.第4章-Bean初始化流程.md
+++ b/docs/spring-sourcecode-v1/04.第4章-Bean初始化流程.md
@@ -16,7 +16,7 @@ date: 2022-01-27 21:01:02
## 流程图-bean初始化流程
- +
+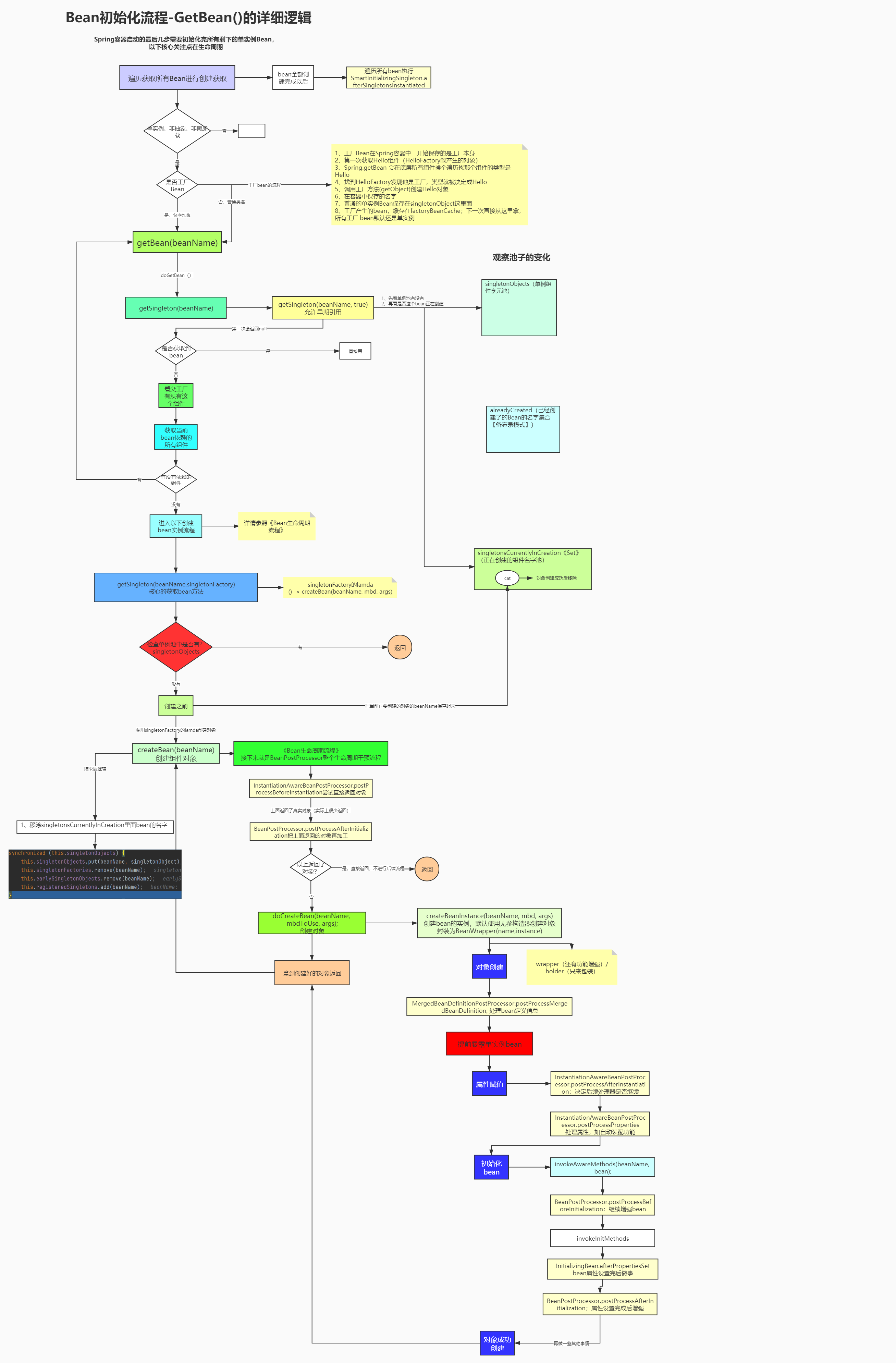 ## AbstractApplicationContext#refresh()
@@ -206,7 +206,7 @@ date: 2022-01-27 21:01:02
## 工厂Bean的初始化方式
-
## AbstractApplicationContext#refresh()
@@ -206,7 +206,7 @@ date: 2022-01-27 21:01:02
## 工厂Bean的初始化方式
- +
+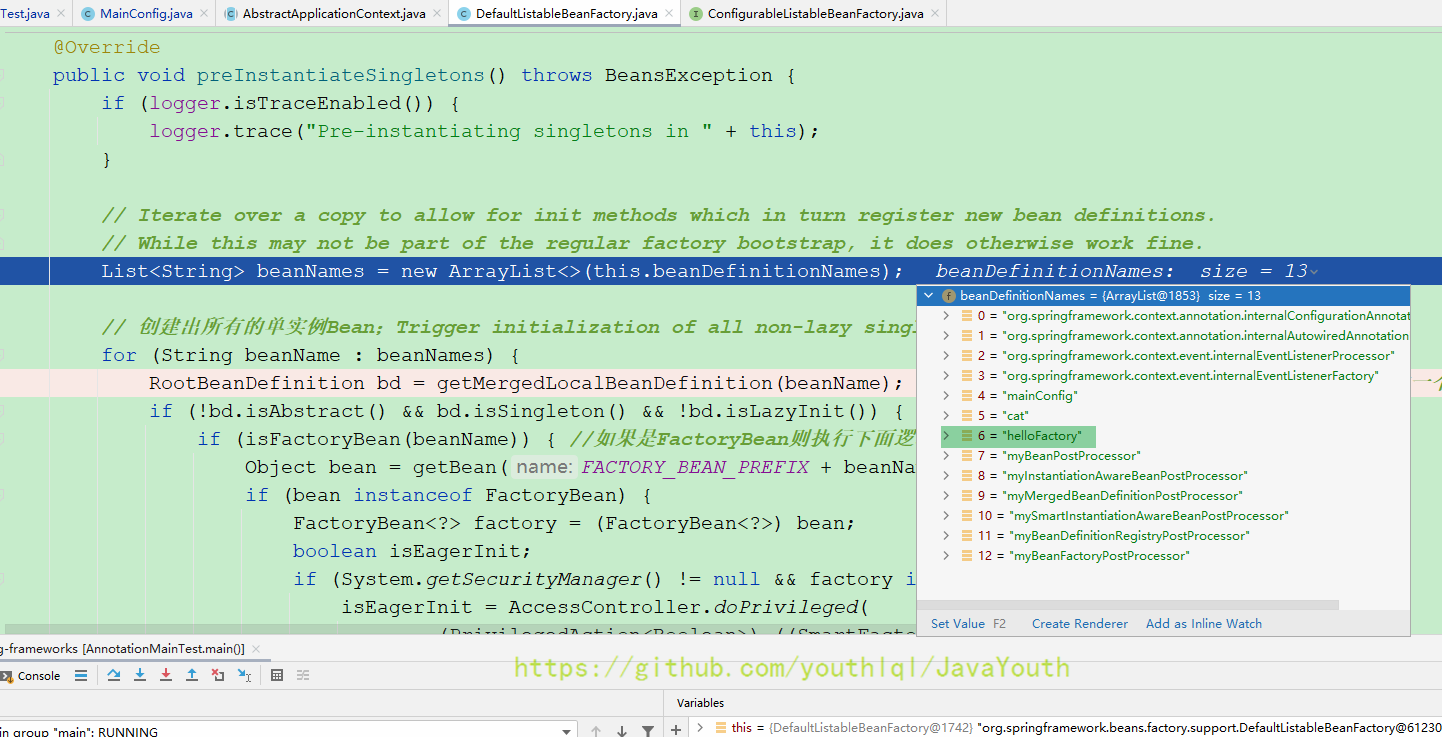 @@ -313,13 +313,13 @@ public class Hello {
从这里开始看调用链
-
@@ -313,13 +313,13 @@ public class Hello {
从这里开始看调用链
- +
+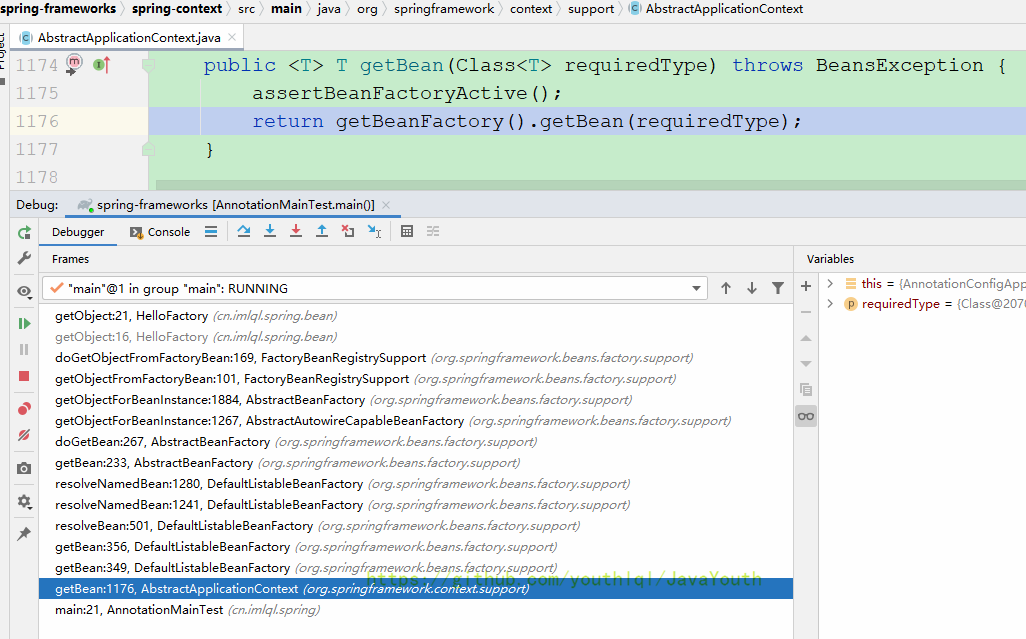 -
- +
+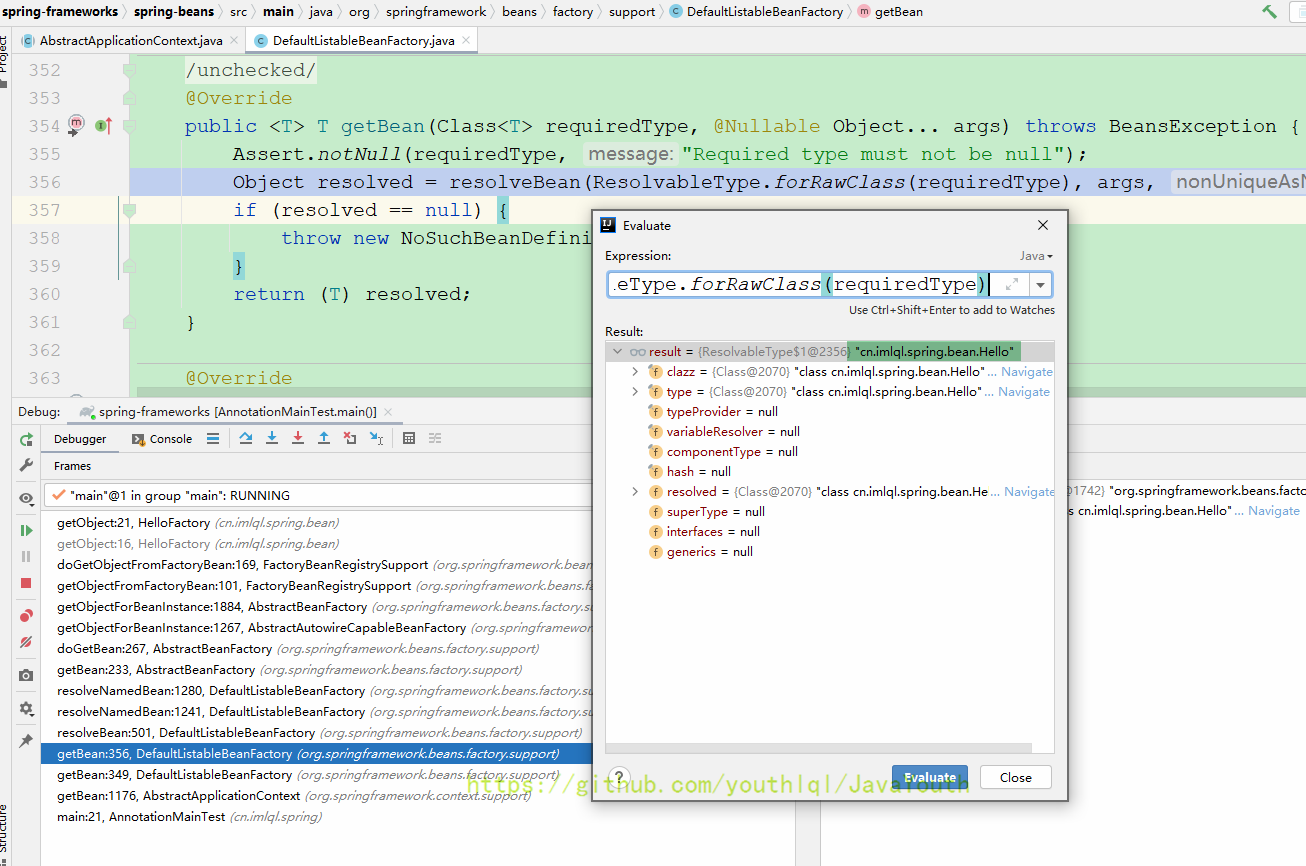 @@ -475,13 +475,13 @@ String FACTORY_BEAN_PREFIX = "&";
最后返回
-
@@ -475,13 +475,13 @@ String FACTORY_BEAN_PREFIX = "&";
最后返回
- +
+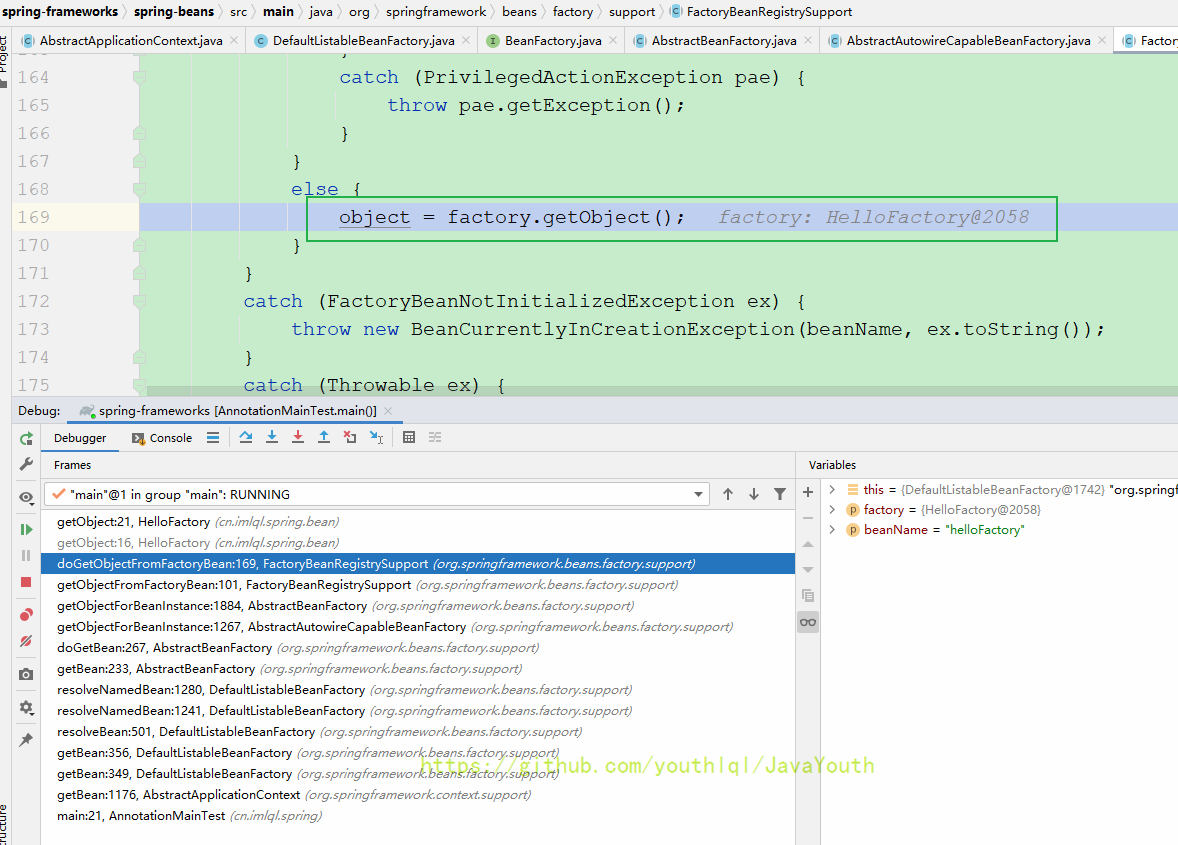 -
- +
+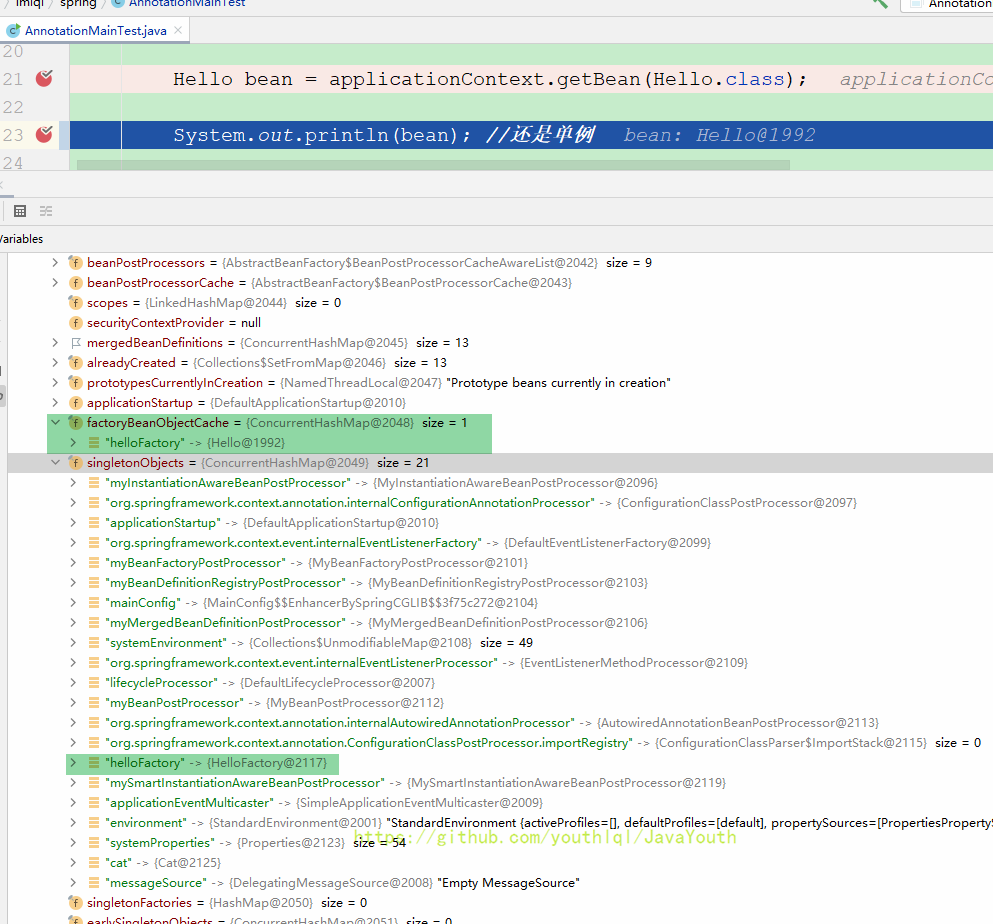 @@ -532,7 +532,7 @@ public class Cat implements InitializingBean, SmartInitializingSingleton {
### Debug调用栈
-
@@ -532,7 +532,7 @@ public class Cat implements InitializingBean, SmartInitializingSingleton {
### Debug调用栈
- +
+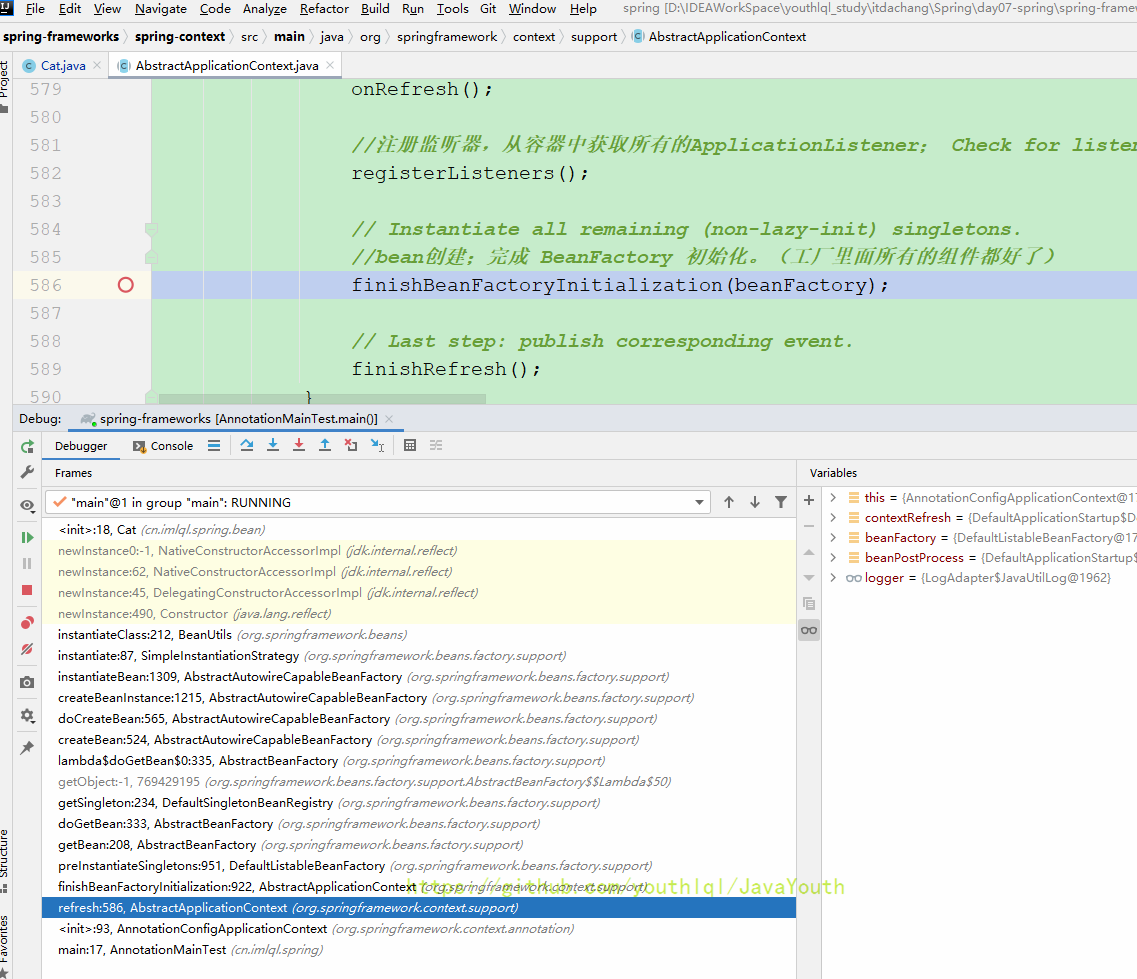 diff --git a/docs/spring-sourcecode-v1/05.第5章-容器刷新流程.md b/docs/spring-sourcecode-v1/05.第5章-容器刷新流程.md
index f7fa5eb..2a42cec 100644
--- a/docs/spring-sourcecode-v1/05.第5章-容器刷新流程.md
+++ b/docs/spring-sourcecode-v1/05.第5章-容器刷新流程.md
@@ -18,7 +18,7 @@ date: 2022-02-13 18:01:02
## 流程图-容器刷新
-
diff --git a/docs/spring-sourcecode-v1/05.第5章-容器刷新流程.md b/docs/spring-sourcecode-v1/05.第5章-容器刷新流程.md
index f7fa5eb..2a42cec 100644
--- a/docs/spring-sourcecode-v1/05.第5章-容器刷新流程.md
+++ b/docs/spring-sourcecode-v1/05.第5章-容器刷新流程.md
@@ -18,7 +18,7 @@ date: 2022-02-13 18:01:02
## 流程图-容器刷新
- +
+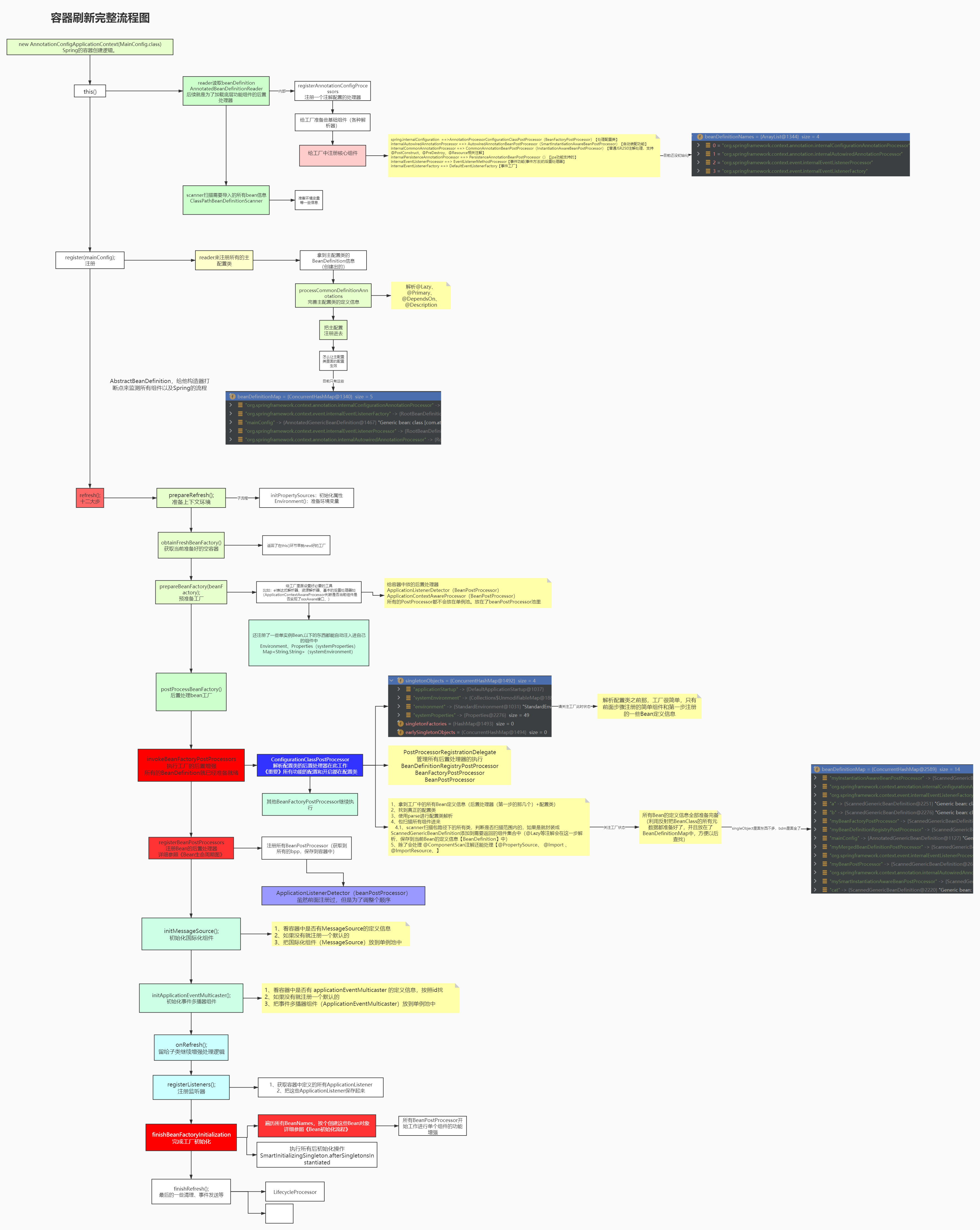 ## 容器创建
@@ -209,7 +209,7 @@ public class AnnotationMainTest {
上面的方法走完,我们可以看看到主要是下面4个后置处理器
-
## 容器创建
@@ -209,7 +209,7 @@ public class AnnotationMainTest {
上面的方法走完,我们可以看看到主要是下面4个后置处理器
- +
+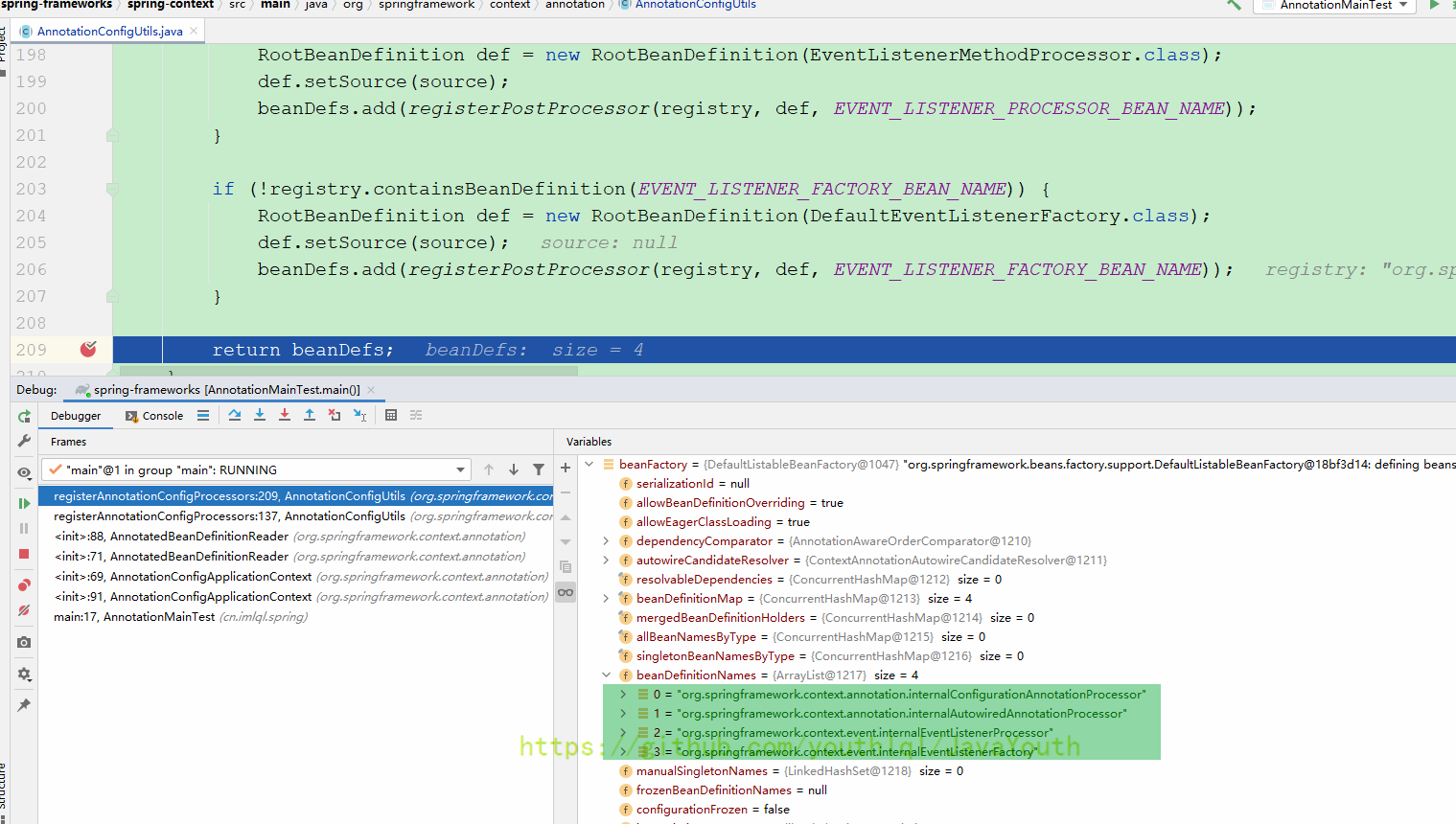 ##### RootBeanDefinition
@@ -360,7 +360,7 @@ public class AnnotationMainTest {
走完之后,注册中心肯定多了咱们的配置类
-
##### RootBeanDefinition
@@ -360,7 +360,7 @@ public class AnnotationMainTest {
走完之后,注册中心肯定多了咱们的配置类
- +
+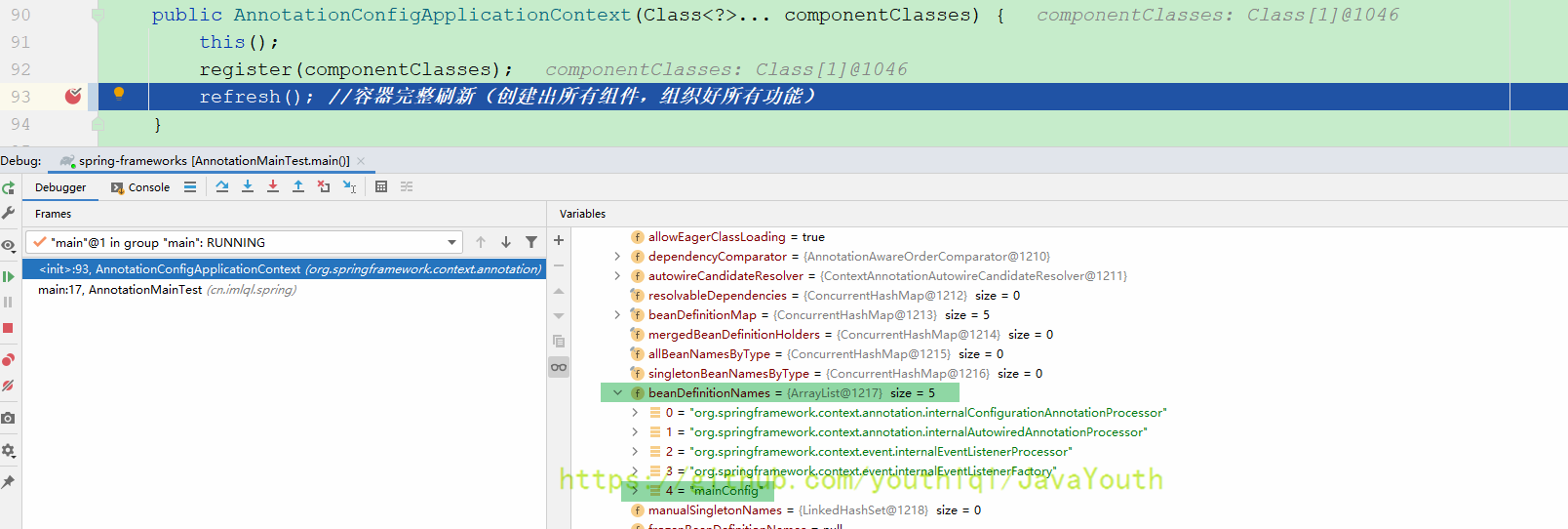 @@ -584,7 +584,7 @@ protected void initPropertySources() {
}
```
-
@@ -584,7 +584,7 @@ protected void initPropertySources() {
}
```
- +
+ @@ -607,11 +607,11 @@ protected void initPropertySources() {
这一步有个很关键的后置处理器
-
@@ -607,11 +607,11 @@ protected void initPropertySources() {
这一步有个很关键的后置处理器
- +
+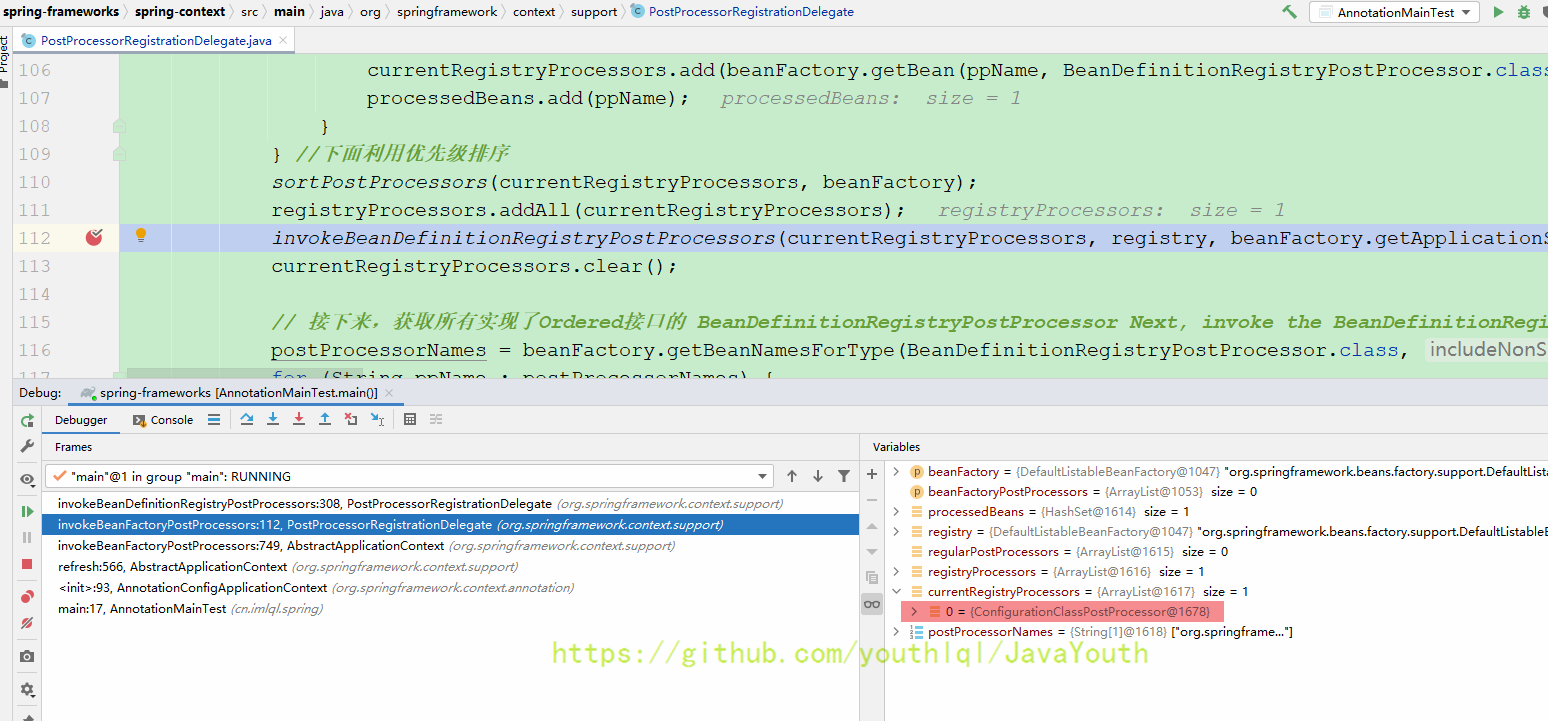 -
- +
+ @@ -746,7 +746,7 @@ protected void initPropertySources() {
-
@@ -746,7 +746,7 @@ protected void initPropertySources() {
- +
+ @@ -1043,7 +1043,7 @@ public class ClassPathBeanDefinitionScanner extends ClassPathScanningCandidateCo
拿到所有类(资源),不管你有没有标@Component注解。然后挨个遍历每一个资源是不是候选的组件(根据前面准备的一些条件,在这里进行判断)
-
@@ -1043,7 +1043,7 @@ public class ClassPathBeanDefinitionScanner extends ClassPathScanningCandidateCo
拿到所有类(资源),不管你有没有标@Component注解。然后挨个遍历每一个资源是不是候选的组件(根据前面准备的一些条件,在这里进行判断)
- +
+ @@ -1051,7 +1051,7 @@ public class ClassPathBeanDefinitionScanner extends ClassPathScanningCandidateCo
最后我们看一下执行完之后的BeanDefinition信息
-
@@ -1051,7 +1051,7 @@ public class ClassPathBeanDefinitionScanner extends ClassPathScanningCandidateCo
最后我们看一下执行完之后的BeanDefinition信息
- +
+ @@ -1309,7 +1309,7 @@ public class B {
这就是循环引用的场景,这种写法由于Spring内部获取Bean都是通过getBean方法来获取,就造成了下面的死循环。我们来看看Spring是怎么解决的。
-
@@ -1309,7 +1309,7 @@ public class B {
这就是循环引用的场景,这种写法由于Spring内部获取Bean都是通过getBean方法来获取,就造成了下面的死循环。我们来看看Spring是怎么解决的。
- +
+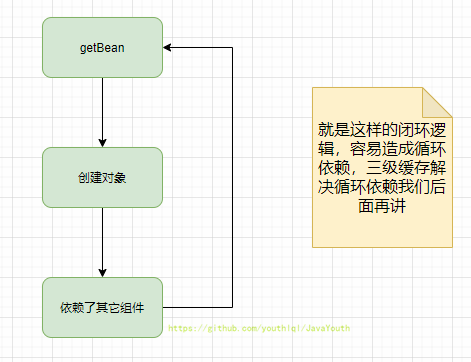 @@ -1568,16 +1568,16 @@ public class B {
1. pos_1位置先进入pos_3位置的`getSingleton(beanName, true)`,查看缓存中有没有A组件
-
@@ -1568,16 +1568,16 @@ public class B {
1. pos_1位置先进入pos_3位置的`getSingleton(beanName, true)`,查看缓存中有没有A组件
- +
+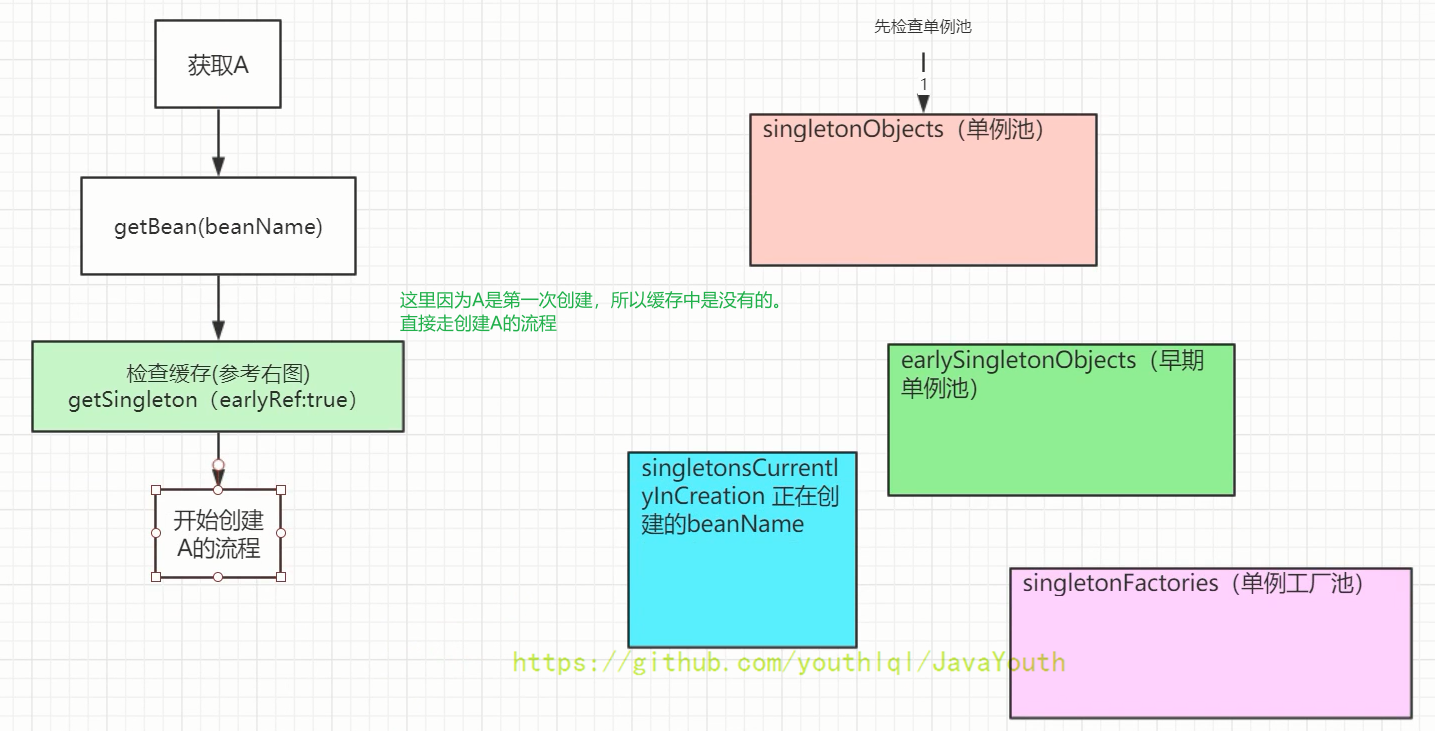 2. 然后走到pos_2调用pos_5的`getSingleton()`开始创建A的流程
3. 在pos_5的`getSingleton()`中走到pos_6的`beforeSingletonCreation()`,就变成下面这样
-
2. 然后走到pos_2调用pos_5的`getSingleton()`开始创建A的流程
3. 在pos_5的`getSingleton()`中走到pos_6的`beforeSingletonCreation()`,就变成下面这样
- +
+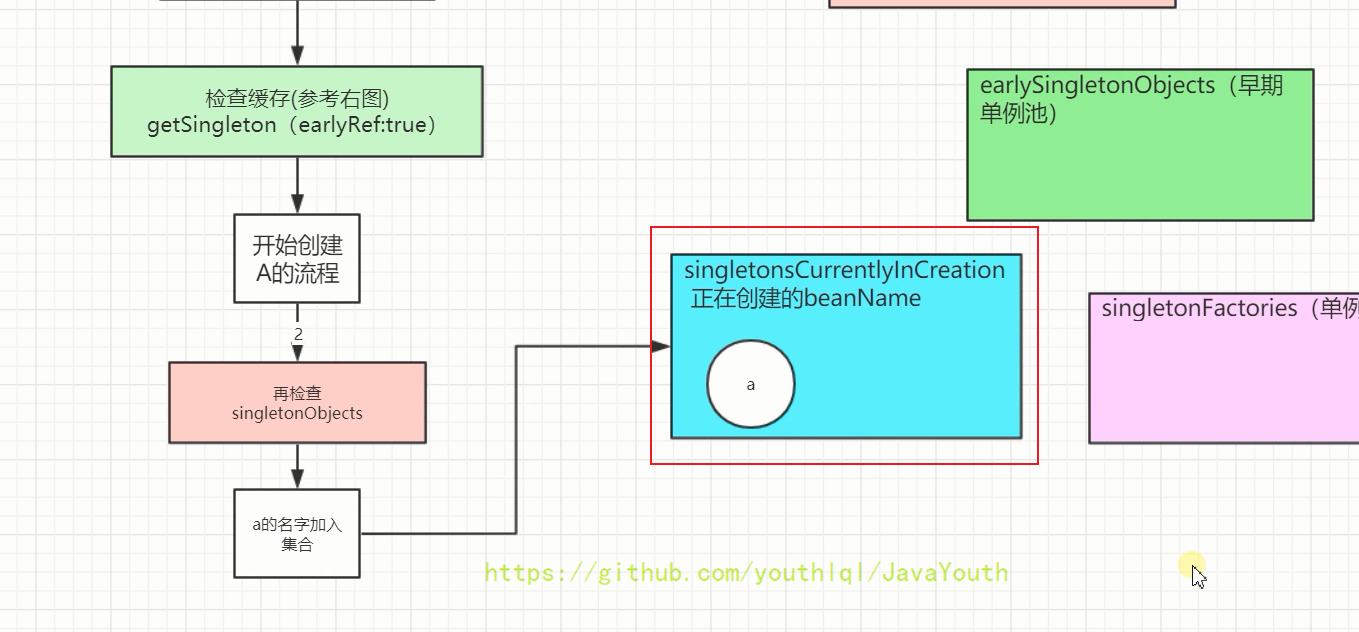 4. 接着pos_7的会调用pos_2的lamda表达式里的`createbean()`,里面再调用`doCreateBean()`。前面讲过不多说,最终调用A的无参构造(pos_8),创建完之后发现A的B属性是null。
-
4. 接着pos_7的会调用pos_2的lamda表达式里的`createbean()`,里面再调用`doCreateBean()`。前面讲过不多说,最终调用A的无参构造(pos_8),创建完之后发现A的B属性是null。
-  +
+  5.在pos_9处的`addSingletonFactory()`来准备解决循环引用
@@ -1594,7 +1594,7 @@ public class B {
}
```
-
5.在pos_9处的`addSingletonFactory()`来准备解决循环引用
@@ -1594,7 +1594,7 @@ public class B {
}
```
- +
+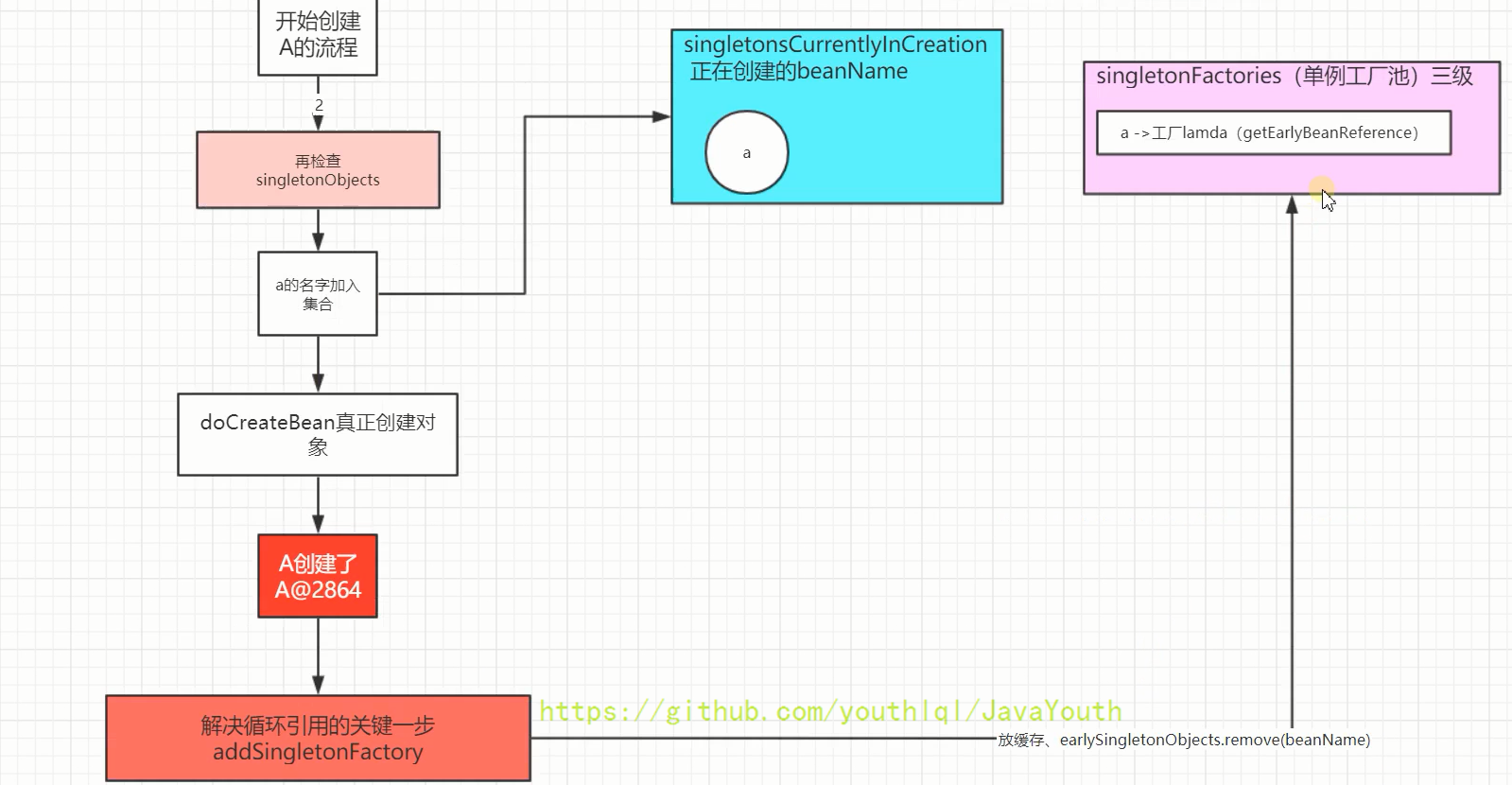 @@ -1662,11 +1662,11 @@ public class B {
通过前面讲过的AutowiredAnnotationBeanPostProcessor来注入B,最后发现要调用setB方法给B赋值
-
@@ -1662,11 +1662,11 @@ public class B {
通过前面讲过的AutowiredAnnotationBeanPostProcessor来注入B,最后发现要调用setB方法给B赋值
- +
+ 7. 继续走,发现要想获得B还是要调用getBean
-
7. 继续走,发现要想获得B还是要调用getBean
- +
+ ```java
public Object resolveCandidate(String beanName, Class requiredType, BeanFactory beanFactory)
@@ -1680,13 +1680,13 @@ public class B {
然后图就是这样子
-
```java
public Object resolveCandidate(String beanName, Class requiredType, BeanFactory beanFactory)
@@ -1680,13 +1680,13 @@ public class B {
然后图就是这样子
- +
+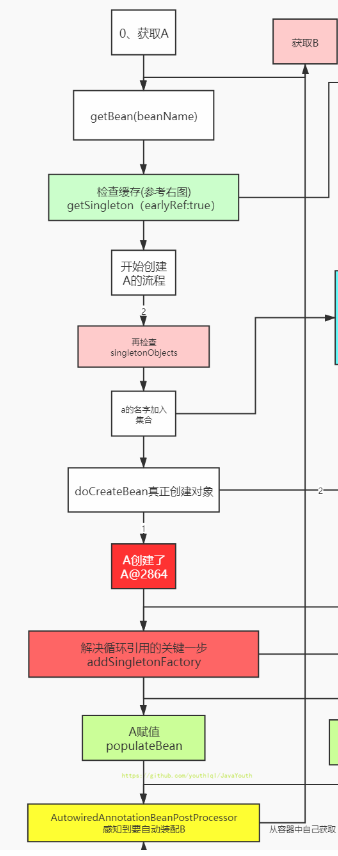 8. B也是走这一套
-
8. B也是走这一套
- +
+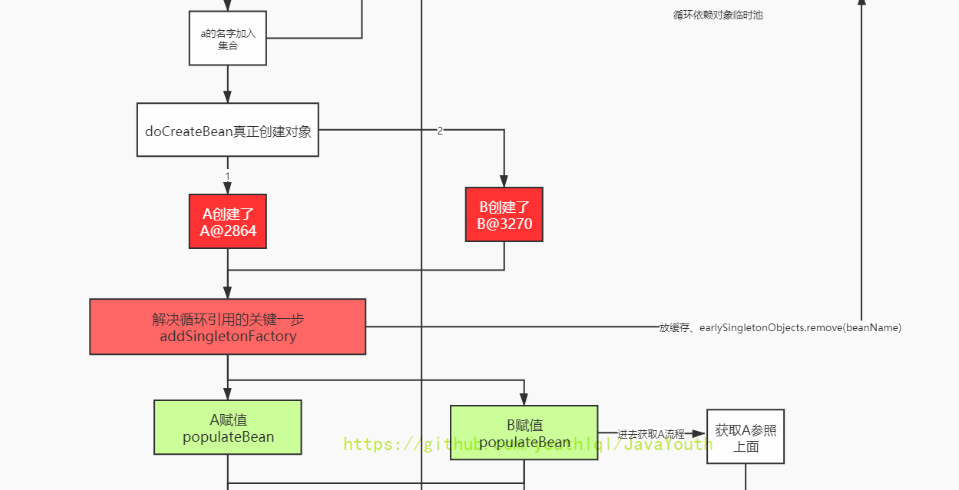 9. B为了获取A,还要再走一次getBean()流程,最终还是走到
@@ -1720,13 +1720,13 @@ public class B {
}
```
-
9. B为了获取A,还要再走一次getBean()流程,最终还是走到
@@ -1720,13 +1720,13 @@ public class B {
}
```
- +
+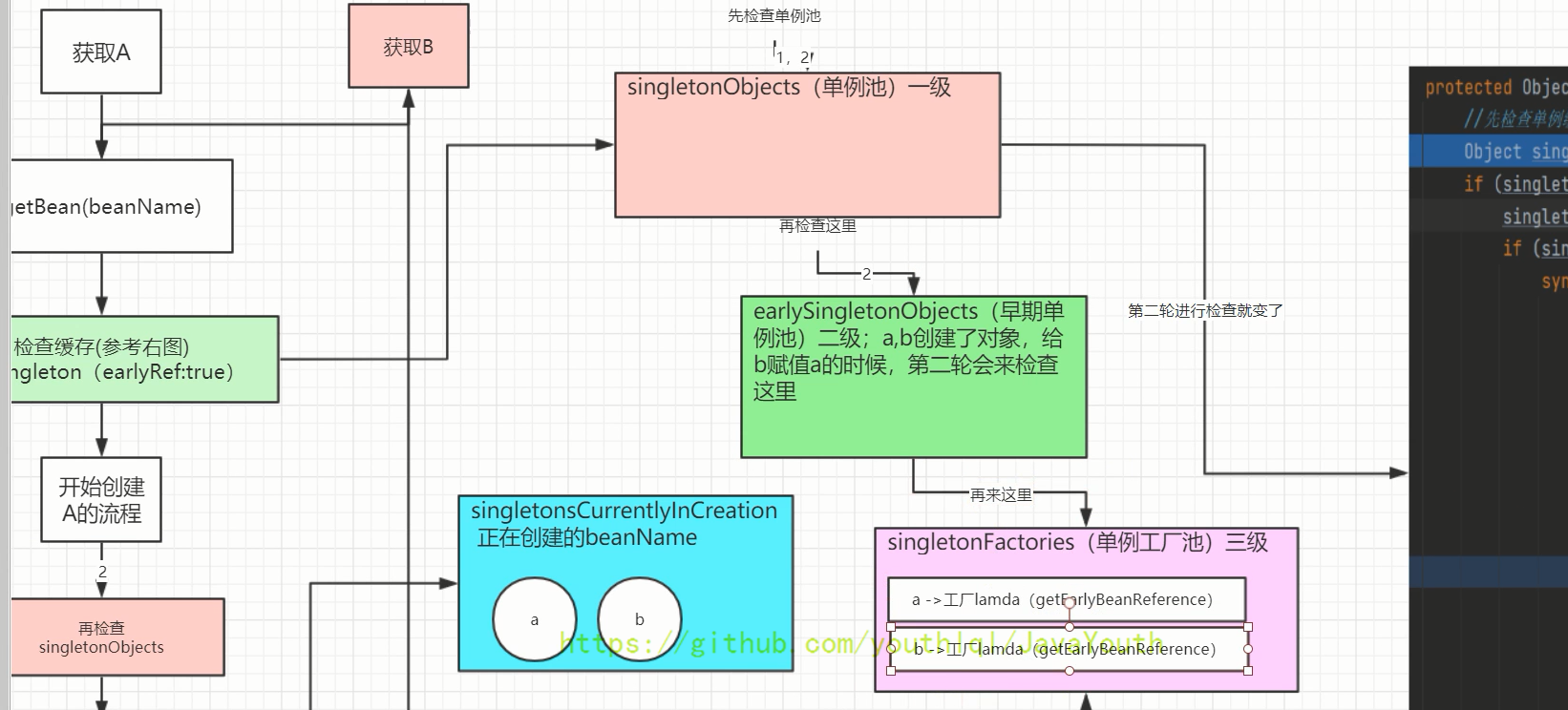 10.
-
10.
- +
+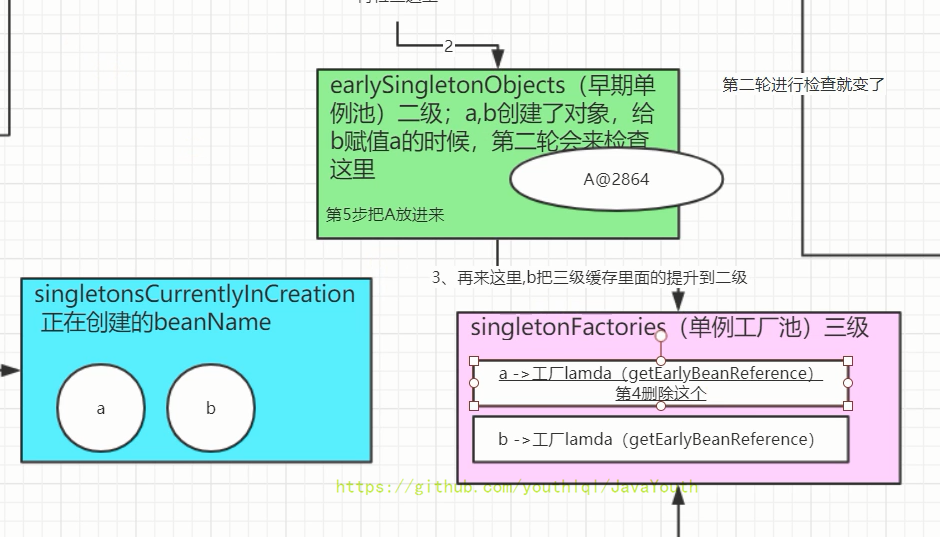 @@ -1739,7 +1739,7 @@ public class B {
12. B初始化完之后,回到getSingleton,把自己放到单例池里
-
@@ -1739,7 +1739,7 @@ public class B {
12. B初始化完之后,回到getSingleton,把自己放到单例池里
- +
+ ```java
protected void addSingleton(String beanName, Object singletonObject) {
@@ -1752,15 +1752,15 @@ protected void addSingleton(String beanName, Object singletonObject) {
}
```
-
```java
protected void addSingleton(String beanName, Object singletonObject) {
@@ -1752,15 +1752,15 @@ protected void addSingleton(String beanName, Object singletonObject) {
}
```
- +
+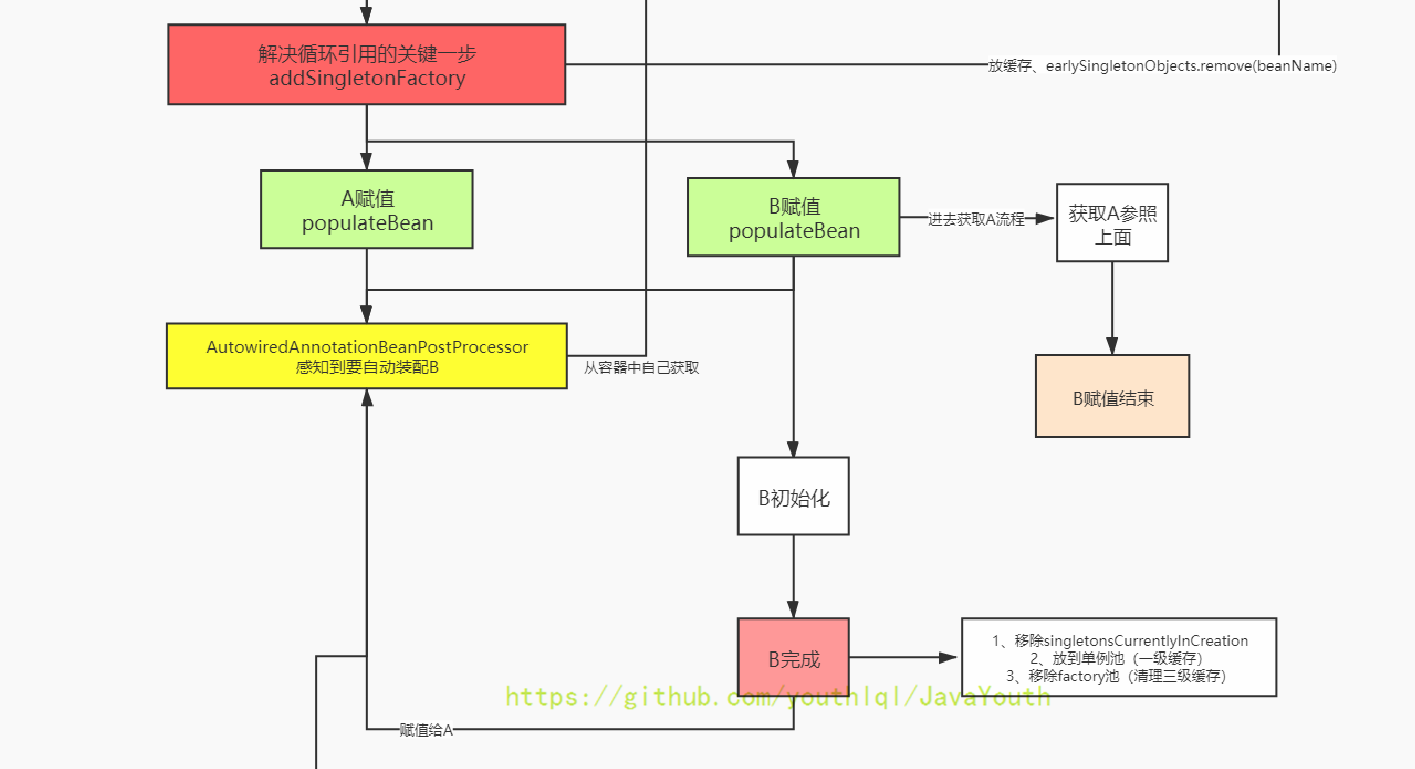 -
- +
+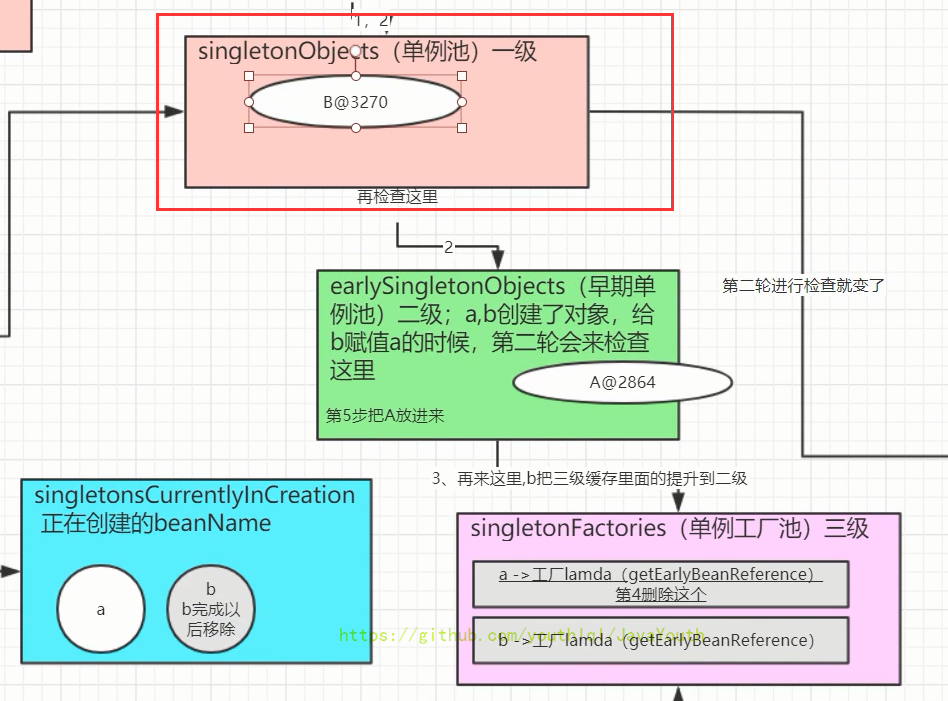 13. B全部结束之后回到A的流程,A赋值工作结束了,然后就开始A的初始化。初始化的过程中
-
13. B全部结束之后回到A的流程,A赋值工作结束了,然后就开始A的初始化。初始化的过程中
- +
+ ```java
protected void addSingleton(String beanName, Object singletonObject) {
@@ -1775,7 +1775,7 @@ protected void addSingleton(String beanName, Object singletonObject) {
-
```java
protected void addSingleton(String beanName, Object singletonObject) {
@@ -1775,7 +1775,7 @@ protected void addSingleton(String beanName, Object singletonObject) {
- +
+ @@ -1787,7 +1787,7 @@ protected void addSingleton(String beanName, Object singletonObject) {
-
@@ -1787,7 +1787,7 @@ protected void addSingleton(String beanName, Object singletonObject) {
- +
+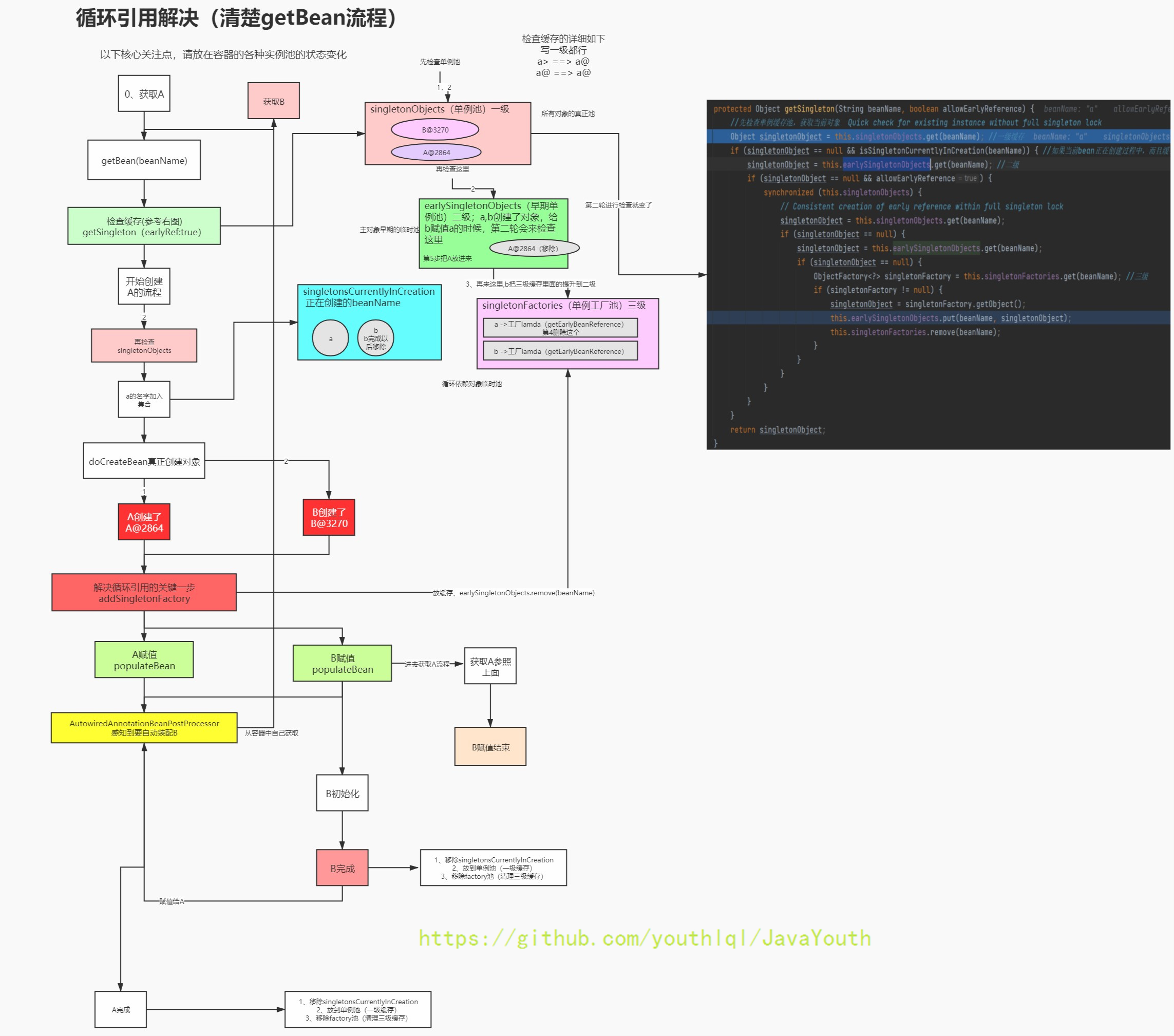 diff --git a/docs/suibi/我的校招-不完全知识点整理.md b/docs/suibi/我的校招-不完全知识点整理.md
index 5cb4af6..dc86854 100644
--- a/docs/suibi/我的校招-不完全知识点整理.md
+++ b/docs/suibi/我的校招-不完全知识点整理.md
@@ -435,7 +435,7 @@ public class JZ_056 {
}
```
-
diff --git a/docs/suibi/我的校招-不完全知识点整理.md b/docs/suibi/我的校招-不完全知识点整理.md
index 5cb4af6..dc86854 100644
--- a/docs/suibi/我的校招-不完全知识点整理.md
+++ b/docs/suibi/我的校招-不完全知识点整理.md
@@ -435,7 +435,7 @@ public class JZ_056 {
}
```
- +
+ 由上面代码可以看出来,this()方法可以调用本类的无参构造函数。如果本类继承的有父类,那么无参构造函数会有一个隐式的super()的存在。所以在同一个构造函数里面如果this()之后再调用super(),那么就相当于调用了两次super(),也就是调用了两次父类的无参构造,就失去了语句的意义,编译器也不会通过。
@@ -525,7 +525,7 @@ https://blog.csdn.net/striner/article/details/86375684
2. 遍历链表或调用红黑树相关的删除方法
3. 从 LinkedHashMap 维护的双链表中移除要删除的节点
-
由上面代码可以看出来,this()方法可以调用本类的无参构造函数。如果本类继承的有父类,那么无参构造函数会有一个隐式的super()的存在。所以在同一个构造函数里面如果this()之后再调用super(),那么就相当于调用了两次super(),也就是调用了两次父类的无参构造,就失去了语句的意义,编译器也不会通过。
@@ -525,7 +525,7 @@ https://blog.csdn.net/striner/article/details/86375684
2. 遍历链表或调用红黑树相关的删除方法
3. 从 LinkedHashMap 维护的双链表中移除要删除的节点
- +
+ @@ -537,7 +537,7 @@ https://blog.csdn.net/qq_36610462/article/details/83277524
## 集合继承结构
-
@@ -537,7 +537,7 @@ https://blog.csdn.net/qq_36610462/article/details/83277524
## 集合继承结构
- +
+ @@ -675,11 +675,11 @@ https://blog.csdn.net/puppylpg/article/details/80433271
这里我只截图下我准备的面试题目录,因为所有答案你都能在笔者的JVM文章里找到答案
-
@@ -675,11 +675,11 @@ https://blog.csdn.net/puppylpg/article/details/80433271
这里我只截图下我准备的面试题目录,因为所有答案你都能在笔者的JVM文章里找到答案
- +
+ -
- +
+ @@ -1335,7 +1335,7 @@ redis cluster 功能强大,直接集成了 replication 和 sentinel 的功能
## 存储引擎Innodb和Myisam的区别以及使用场景
-
@@ -1335,7 +1335,7 @@ redis cluster 功能强大,直接集成了 replication 和 sentinel 的功能
## 存储引擎Innodb和Myisam的区别以及使用场景
- +
+ @@ -2039,7 +2039,7 @@ snowflake 算法是 twitter 开源的分布式 id 生成算法,采用 Scala
## Bean生命周期
-
@@ -2039,7 +2039,7 @@ snowflake 算法是 twitter 开源的分布式 id 生成算法,采用 Scala
## Bean生命周期
- +
+ @@ -2199,7 +2199,7 @@ https://github.com/Snailclimb/springboot-guide/blob/master/docs/interview/spring
-
@@ -2199,7 +2199,7 @@ https://github.com/Snailclimb/springboot-guide/blob/master/docs/interview/spring
- +
+ @@ -2331,7 +2331,7 @@ private final Map earlySingletonObjects = new HashMap
+
@@ -2331,7 +2331,7 @@ private final Map earlySingletonObjects = new HashMap
+ @@ -2416,7 +2416,7 @@ https://blog.csdn.net/j04110414/article/details/78914787
-
@@ -2416,7 +2416,7 @@ https://blog.csdn.net/j04110414/article/details/78914787
- +
+ 从整个秒杀系统的架构其实和一般的互联网系统架构本身没有太多的不同,核心理念还是通过缓存、异步、限流来保证系统的高并发和高可用。下面从一笔秒杀交易的流程来描述下秒杀系统架构设计的要点:
从整个秒杀系统的架构其实和一般的互联网系统架构本身没有太多的不同,核心理念还是通过缓存、异步、限流来保证系统的高并发和高可用。下面从一笔秒杀交易的流程来描述下秒杀系统架构设计的要点: